Share
Video Object Segmentation using Teacher-Student Adaptation in a Human Robot Interaction (HRI) Setting を題材にLTしました.
{kind=link}
![論文の概要 • 新規物体のセグメンテーションを人とロボットの対話的作業を 通した Adaptation により学習する手法を提案 • 対話的学習の動作を含む家具のセグメンテーション済ビデオ データセット(IVOS)の作成 [1]](https://files.speakerdeck.com/presentations/f0479d2d8354491c9b31dd69971c48c1/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![実際のロボット環境におけるタスク • タスクが物体把持などのケースでは対象物体が手元にあるケースが多い → 人が対話的に対象物体の情報を提供することが可能 • 対話的学習を用いることで、より容易に関心物体の学習が可能では? 対話的学習を用いた視点でセグメンテーションの学習をしよう! [1] https://msiam.github.io/ivos/](https://files.speakerdeck.com/presentations/f0479d2d8354491c9b31dd69971c48c1/slide_5.jpg){kind=link}
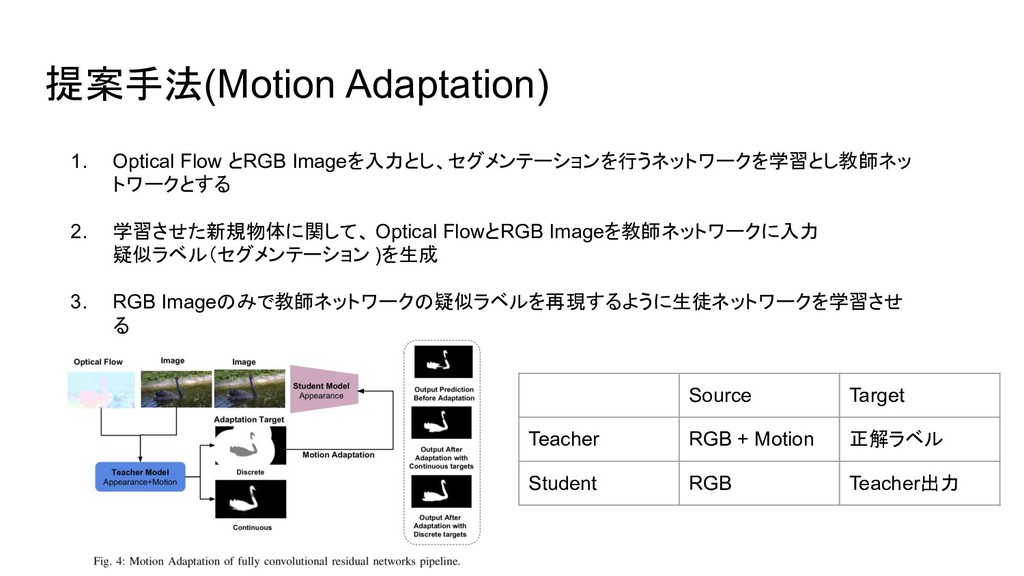{kind=link}
{kind=link}
{kind=link}
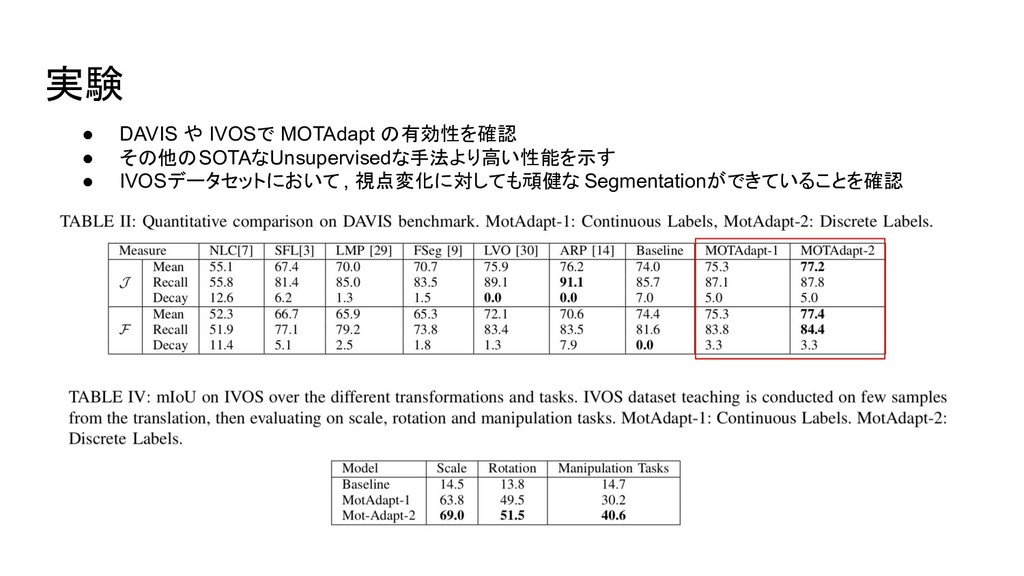{kind=link}
{kind=link}