of terabytes of data • Takes tens of days to read on single computer • Need lots of cheap computers • This fixes speed problem (15 minutes on 1000 computers), but.. • Reliability problems • In large clusters, computers fail every day • Cluster size is not fixed • Need common infrastructure • Must be efficient and reliable Thursday, March 25, 2010
software for reliable, scalable, distributed computing. • Apache Core • Distributed File system - Distributes files • Map/Reduce - Distributes computational work • Written in Java • Runs on • commodity hardware • OS X, Windows, Linux, Solaris Thursday, March 25, 2010
large file storage with a default block size of 64MB (compared to 4 or 8 KB in ext3) • Each block on multiple machines • Each block replicated across servers(Usually 3 copies by default) • Inspired by GFS • Integrates well with MapReduce • Uses Linux but separate namespace Thursday, March 25, 2010
• Inspired by Lisp, ML like functional languages • Gains efficiency from • Streaming through data, reducing seeks • Pipelining and lower communication overhead • Simpler Model • Not a Silver bullet, but good for high data intensive applications • Log processing • Web index building Thursday, March 25, 2010
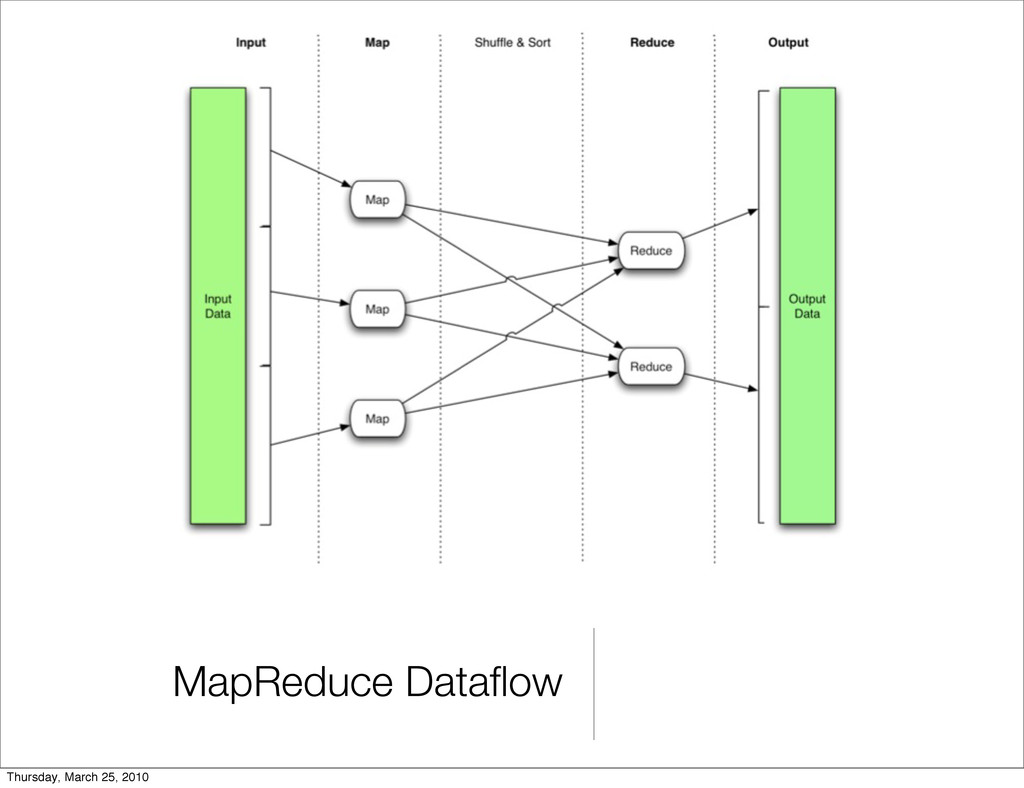
data in parallel • Done by dividing workload across large number of machines • All data elements in MapReduce are immutable • Conceptually, MapReduce programs transform lists of input data elements into lists of output data elements. How? Lets see... Thursday, March 25, 2010
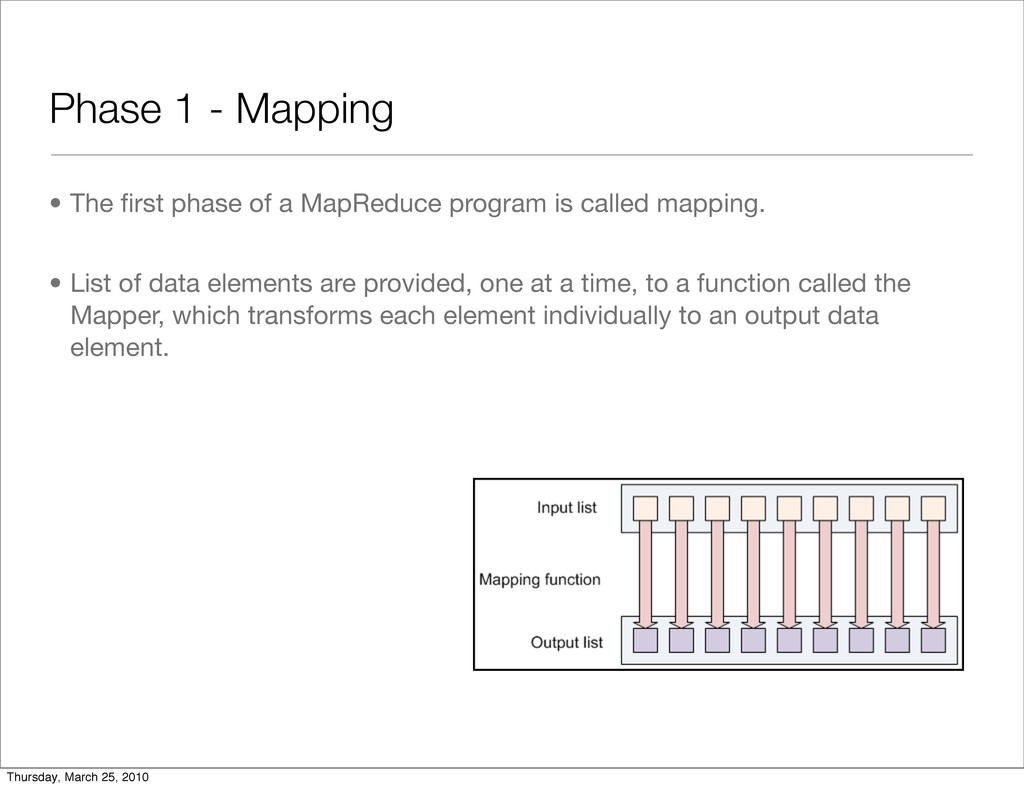
MapReduce program is called mapping. • List of data elements are provided, one at a time, to a function called the Mapper, which transforms each element individually to an output data element. Thursday, March 25, 2010
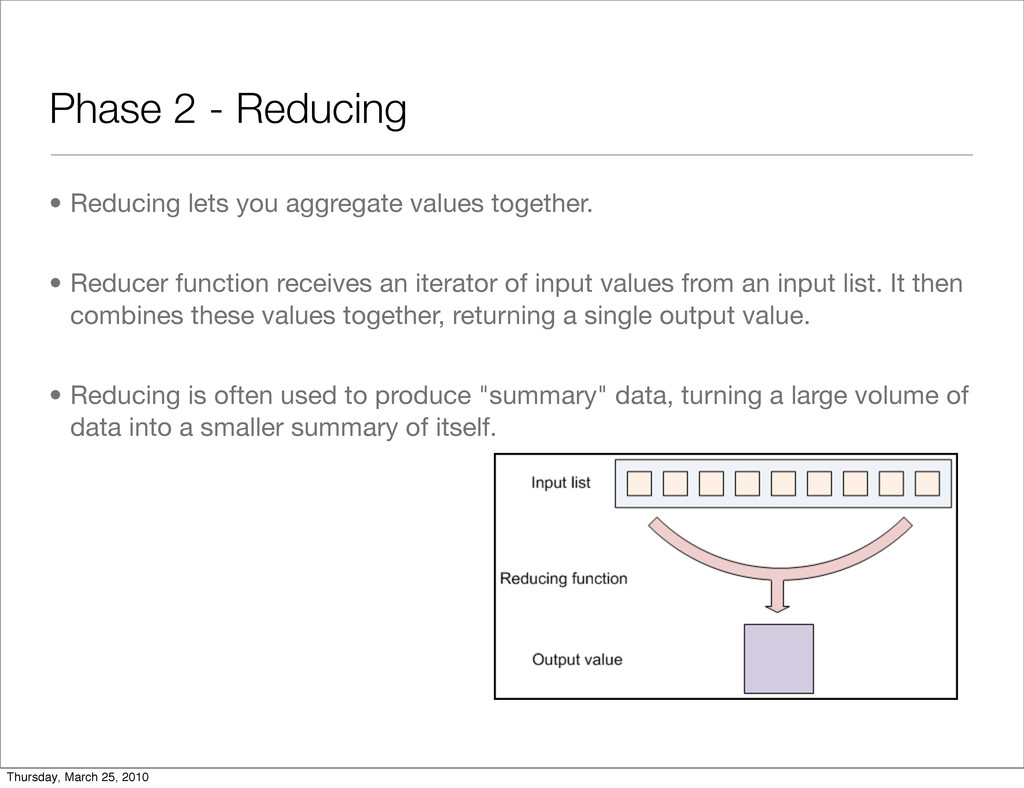
together. • Reducer function receives an iterator of input values from an input list. It then combines these values together, returning a single output value. • Reducing is often used to produce "summary" data, turning a large volume of data into a smaller summary of itself. Thursday, March 25, 2010
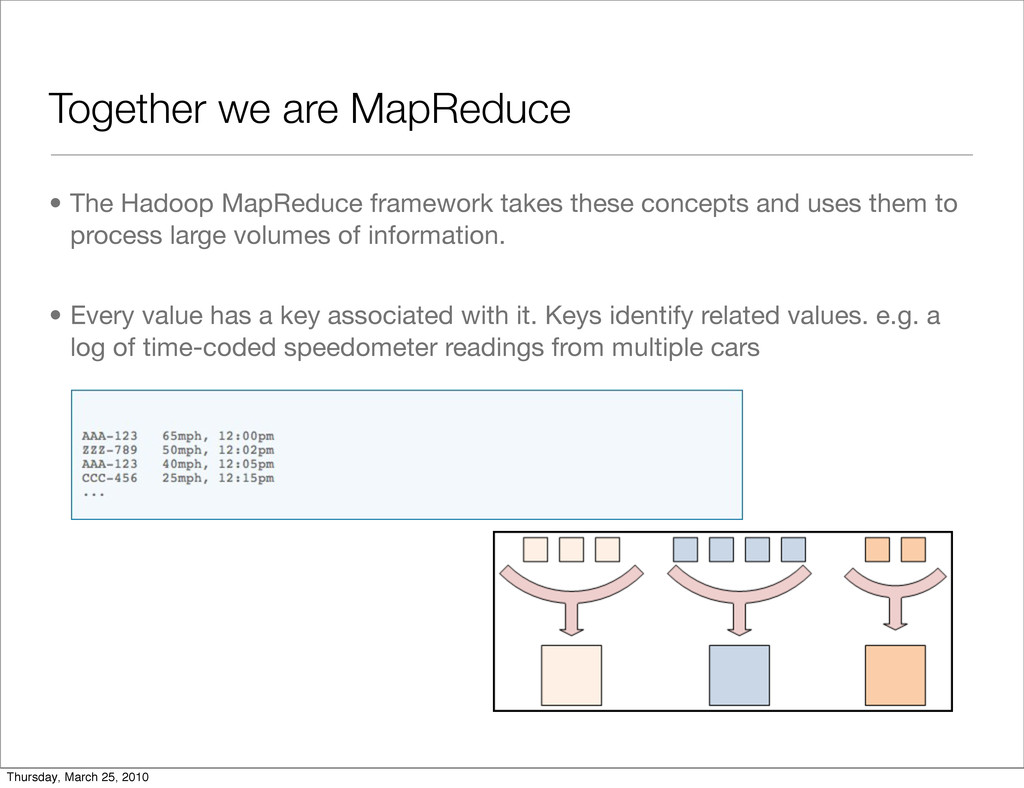
these concepts and uses them to process large volumes of information. • Every value has a key associated with it. Keys identify related values. e.g. a log of time-coded speedometer readings from multiple cars Thursday, March 25, 2010
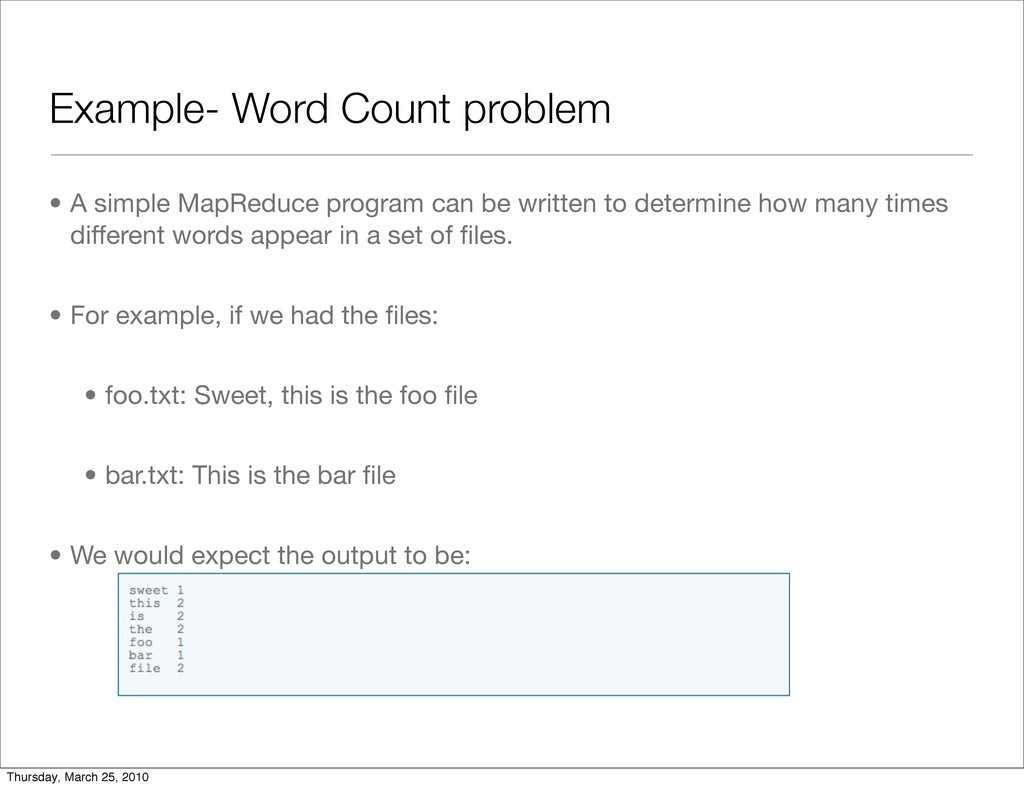
be written to determine how many times different words appear in a set of files. • For example, if we had the files: • foo.txt: Sweet, this is the foo file • bar.txt: This is the bar file • We would expect the output to be: Thursday, March 25, 2010
each word in file-contents: emit (word, 1) reducer (word, values): sum = 0 for each value in values: sum = sum + value emit (word, sum) Thursday, March 25, 2010
Improved load balancing & faster recovery from failed tasks • Automatic re-execution on failure • In a large cluster, some nodes are always slow • Framework re-executes failed tasks • Locality optimizations • With large data, bandwidth to data is a problem • Map-Reduce + HDFS is a very effective solution • Map-Reduce queries HDFS for locations of input data • Map tasks are scheduled close to the inputs when possible Thursday, March 25, 2010
SQL calls against an indexed/tuned database response back in milliseconds. Hadoop does not do this. • Hadoop stores data in files, and does not index them. • If you want to find something, you have to run a MapReduce job going through all the data. • However, There is a project adding a column-table database on top of Hadoop - HBase. Thursday, March 25, 2010
SAN-hosted FS • Hadoop HDFS cheats, delivering high local data access rates by running code near the data, instead of being fast at shipping the data remotely. • Instead of using RAID controllers, it uses non-RAIDed storage across multiple machines. • It is not currently Highly Available. The Namenode is a Single Point of Failure. • It does not currently offer real security. Thursday, March 25, 2010
of Hadoop • Provides tools for • Easy data summarization • Adhoc querying • Analysis of large datasets data stored in Hadoop files. You have no idea how heavy your data is. Ask me! Thursday, March 25, 2010
data sets that consists of a high-level language for expressing data analysis programs • A high-level data-flow language and execution framework for parallel computation. • Pig's language layer is called Pig Latin • Subproject of Hadoop I’m Pig. And I speak Pig Latin. No! It is not as tough as Latin and you can’t learn it using Rosetta Stone! Thursday, March 25, 2010
random, realtime read/write access to Big Data. • For hosting of very large tables -- billions of rows X millions of columns -- atop clusters of commodity hardware. Thursday, March 25, 2010
distributed systems. • Built on top of the Hadoop Distributed File System (HDFS) and Map/Reduce framework. • Includes a flexible and powerful toolkit for displaying, monitoring and analyzing results to make the best use of the collected data. Thursday, March 25, 2010
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}