Description
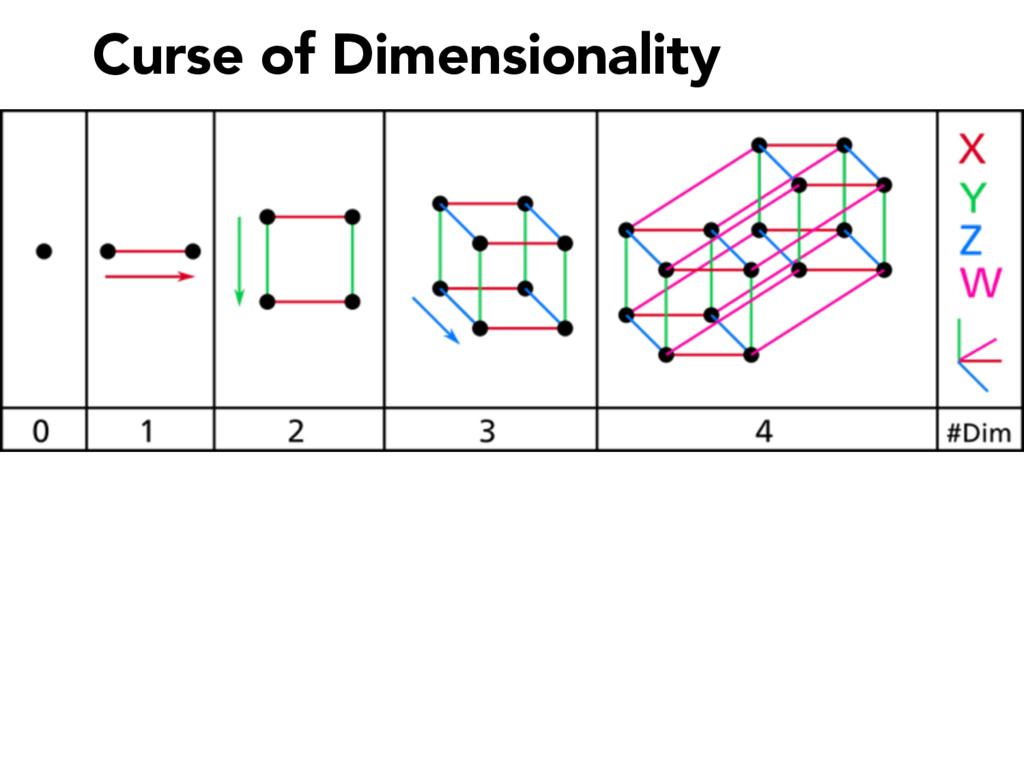
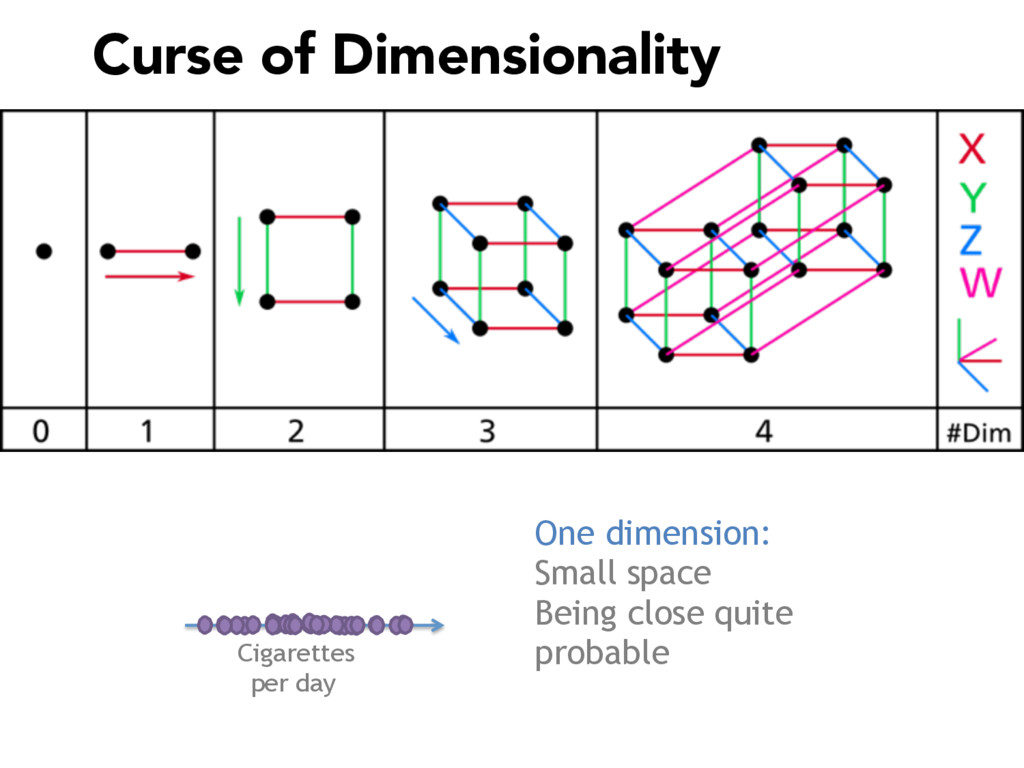
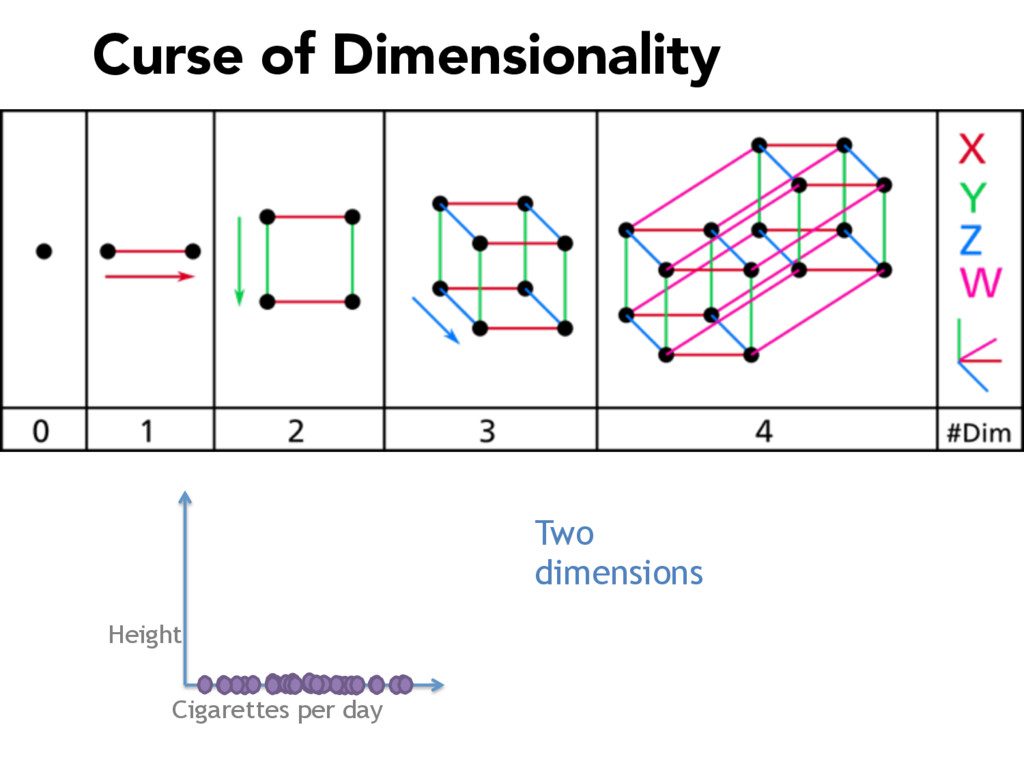
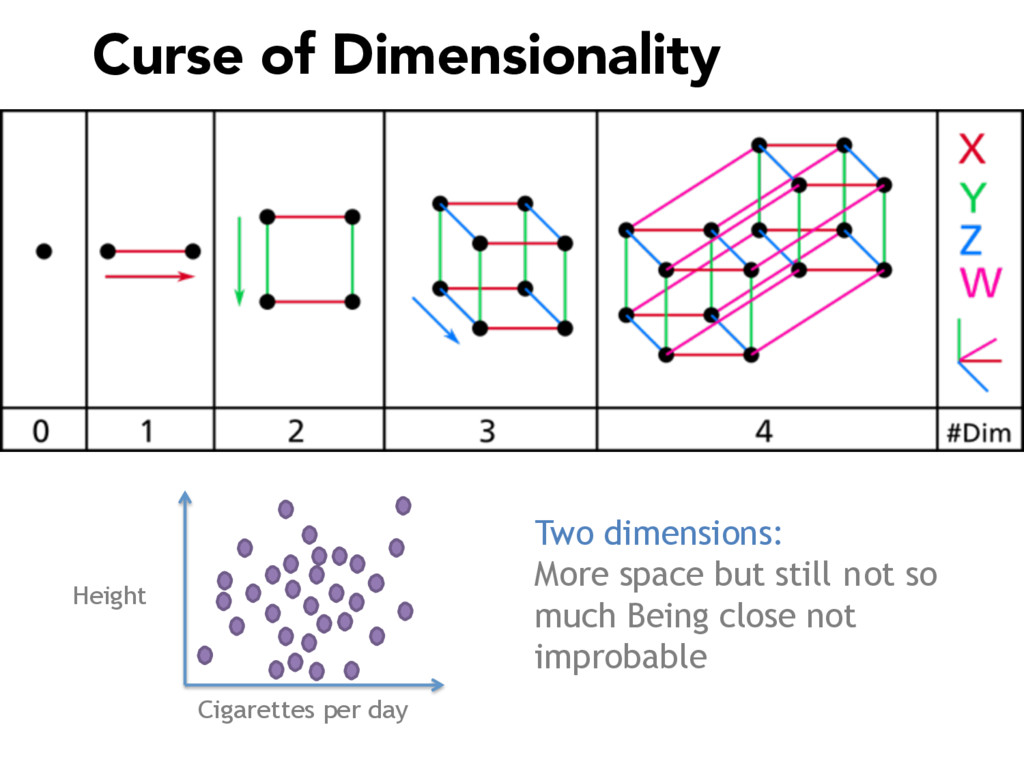
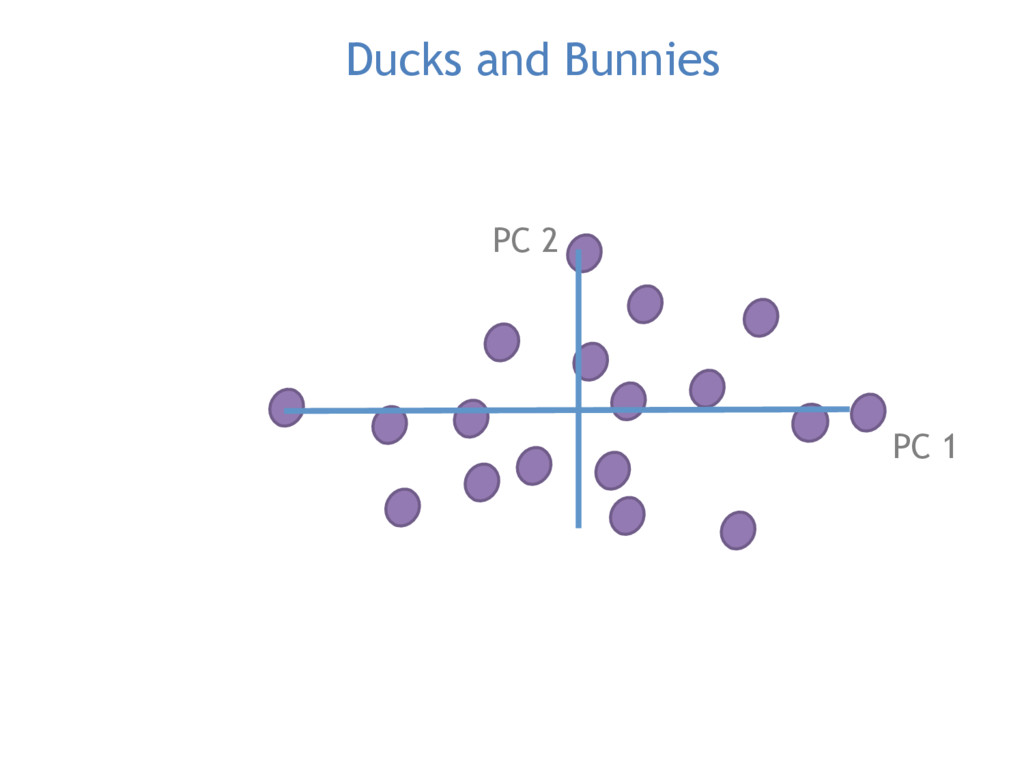
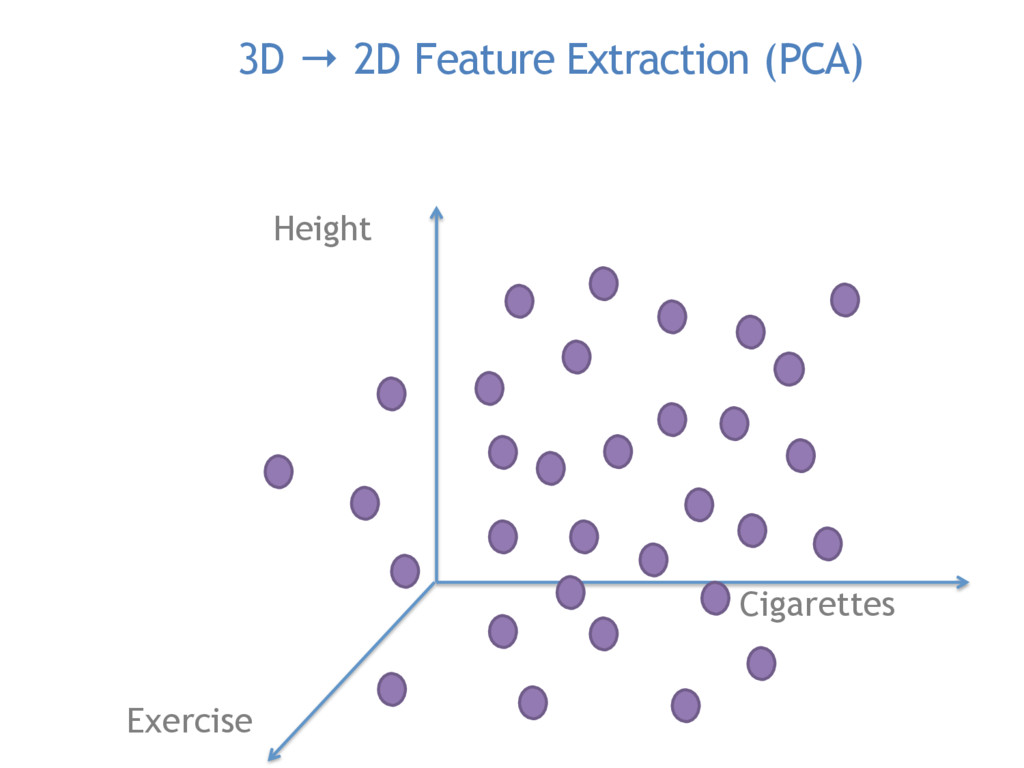
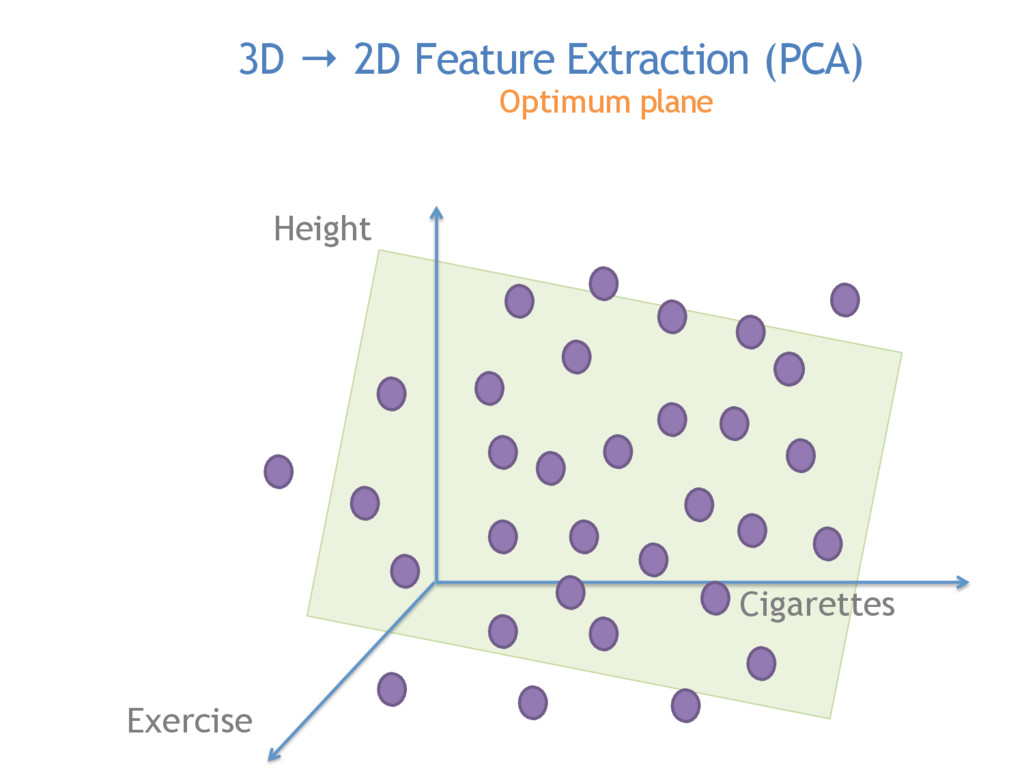
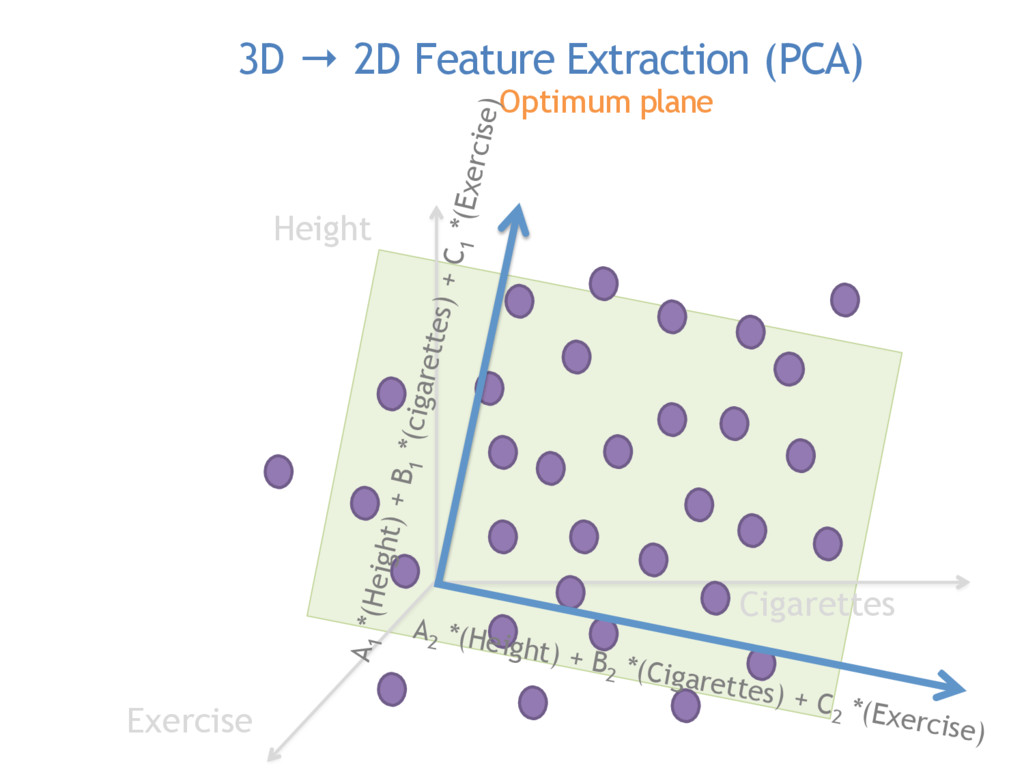
Commonly used in image recognition, speech to text and text analysis, Principal Components Analysis (or PCA) separates the signal from the noise in your data and reduces your dimensionality so that meaningful analyses can be performed.
Abstract
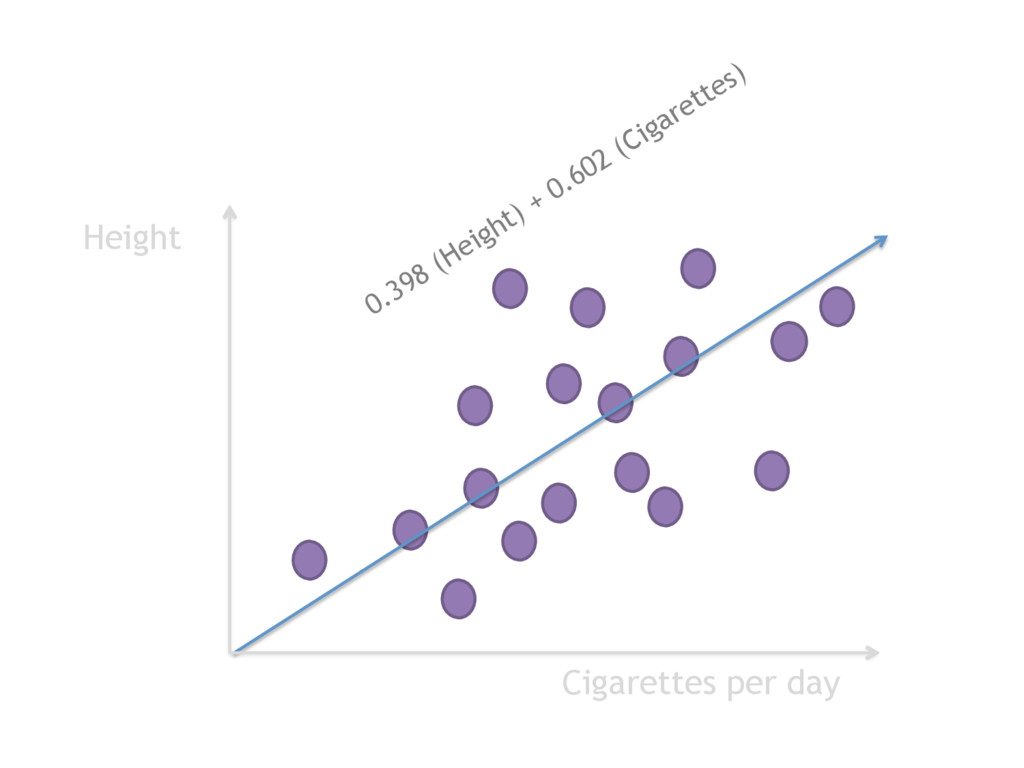
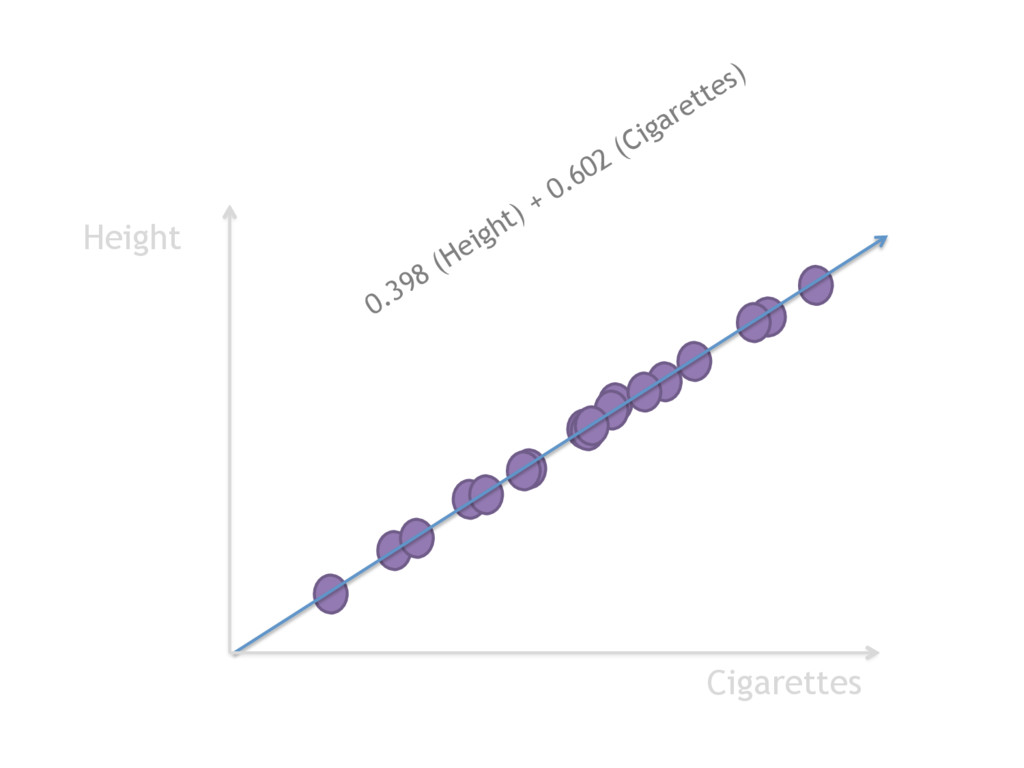
PCA is vital for reducing high dimensional models with sparsity issues, without sacrificing the information contributed by each feature. In this talk, I will be explaining what happens under the hood during PCA, making the code and math accessible and interpretable.
Bio
Rumman comes to data science from a quantitative social science background. Prior to joining Metis, she was a data scientist at Quotient Technology, where she used retailer transaction data to build an award-winning media targeting model. Her industry experience ranges from public policy, to economics, and consulting. Her prior clients include the World Bank, the Vera Institute of Justice, and the Los Angeles County Museum of the Arts. She holds two undergraduate degrees from MIT, a Masters in Quantitative Methods of the Social Sciences from Columbia, and she is currently finishing her Political Science PhD from the University of California, San Diego. Her dissertation uses machine learning techniques to determine whether single-industry towns have a broken political process. Her passion lies in teaching and learning from teaching. In her spare time, she teaches and practices yoga, reads comic books, and works on her podcast.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}