Description
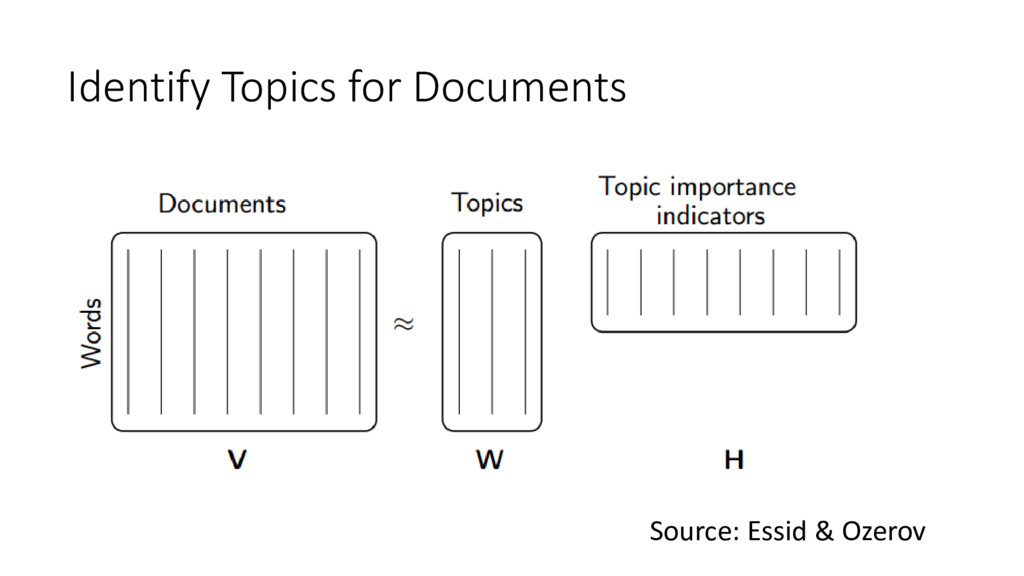
An introduction to randomized linear algebra (a recently developed field with huge implications for scientific computing) in Python with a detailed case study of randomized Singular Value Decomposition (SVD). We will look at the applications of using randomized SVD to find the topics of documents and to identify the background in a surveillance video.
Abstract
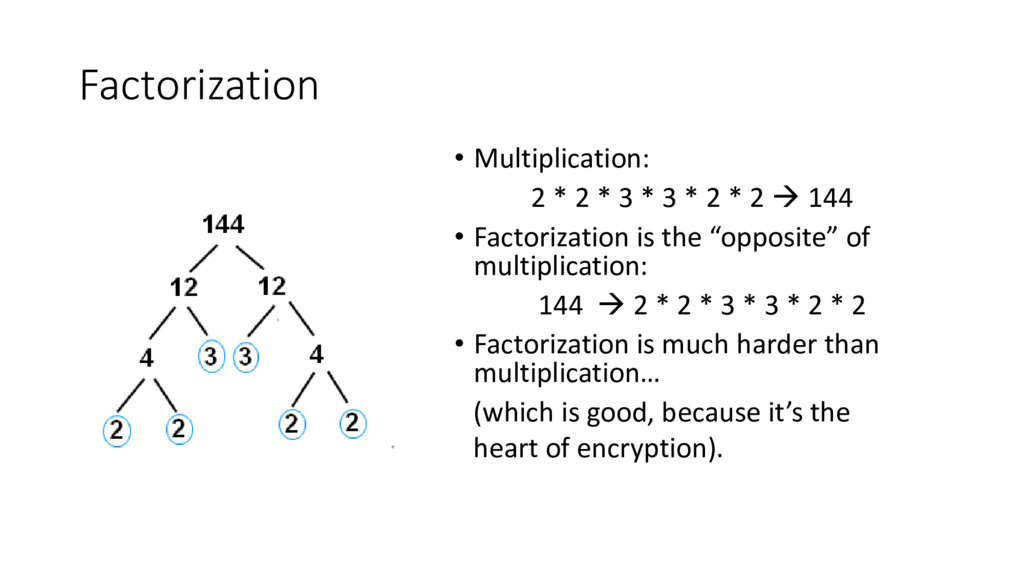
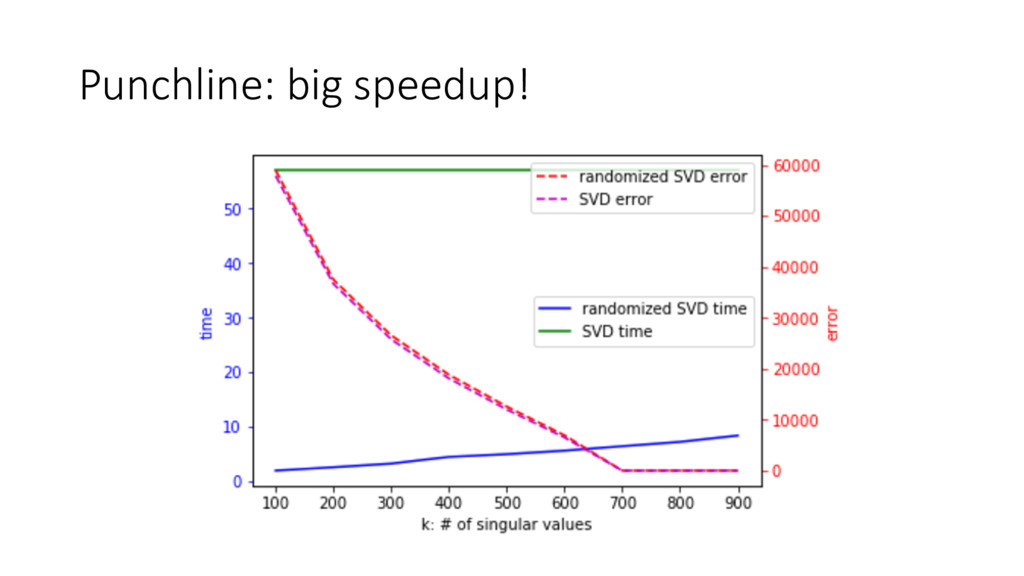
Linear algebra lies at the heart of much of data science, including deep learning, regression, and recommendation systems, and is also widely used in engineering, finance, and much more. The basic linear algebra techniques of matrix products and decompositions have super-linear runtimes, and therefore speeding them up is of vital importance. Counter-intuitively, recent advances have shown that the key to doing this is to take advantage of random matrices. We will see how to use random matrices to dramatically speed up the widely used singular value decomposition, a method that is used in least squares regression, PCA, general matrix inverses, and more.
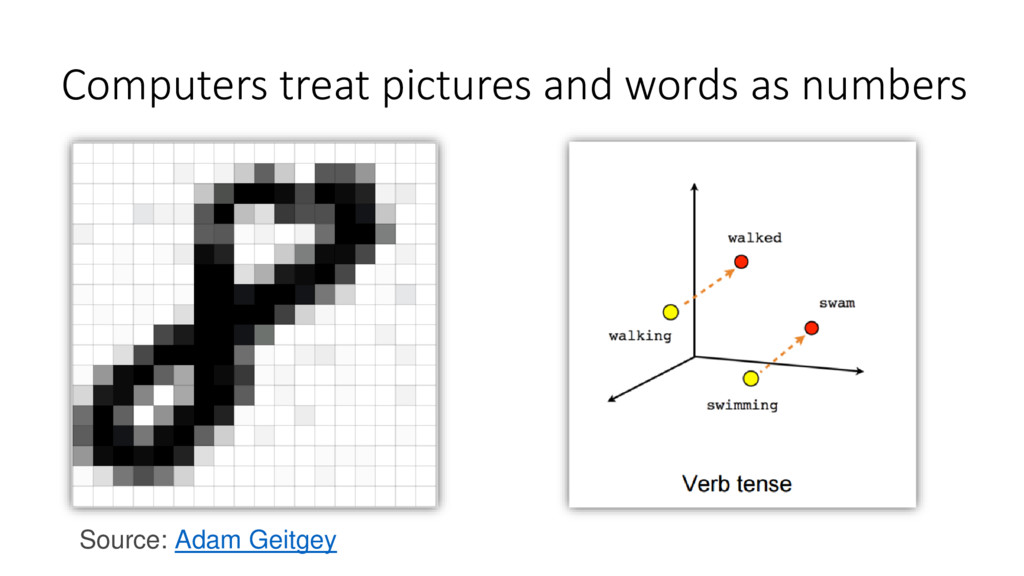
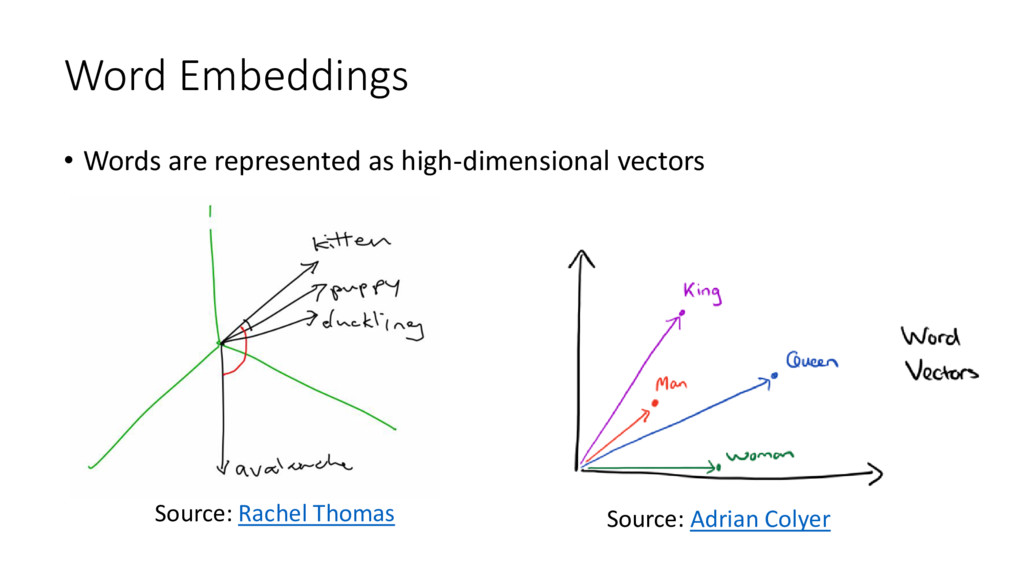
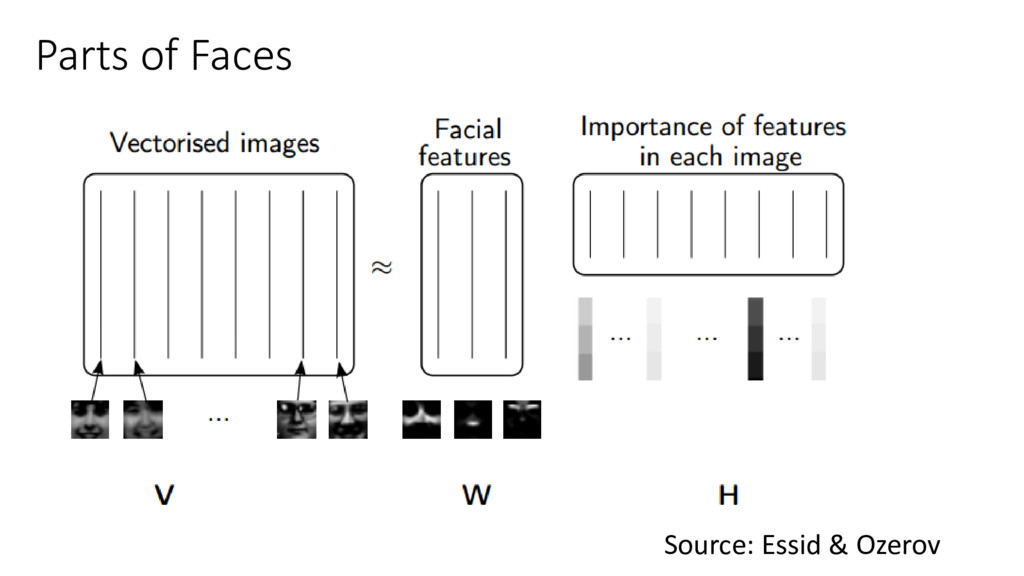
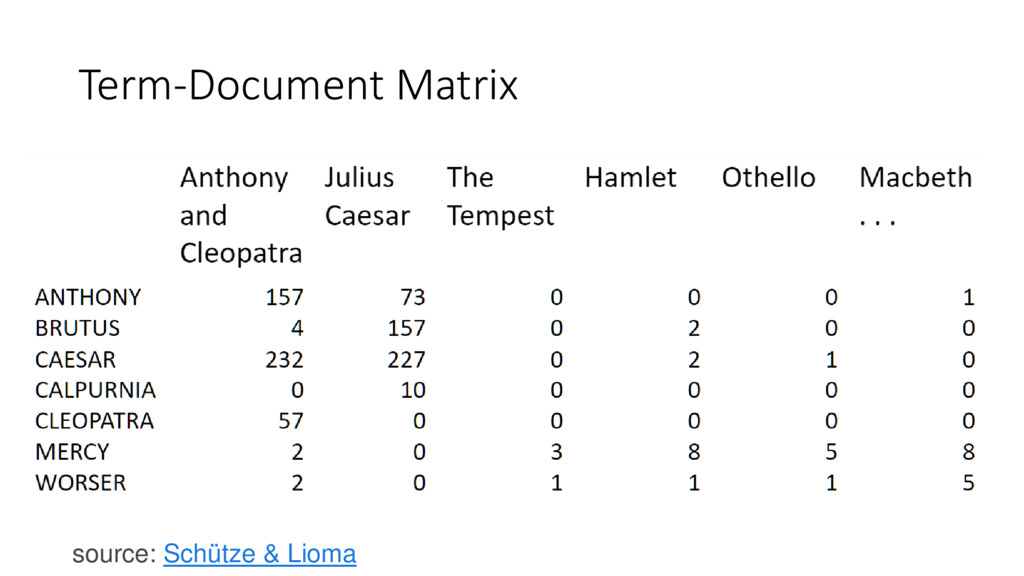
Attendees will learn how language and video data can be represented as matrices with numpy. I will explain what Singular Value Decomposition (SVD) is conceptually and how randomized SVD gives us a huge improvement in speed. We will see applications in Python of using randomized SVD to find the topics of a group of documents and identify the background in a surveillance video. I will introduce all math concepts needed so there are no prerequisites, although familiarity with data processing will be helpful.
Bio
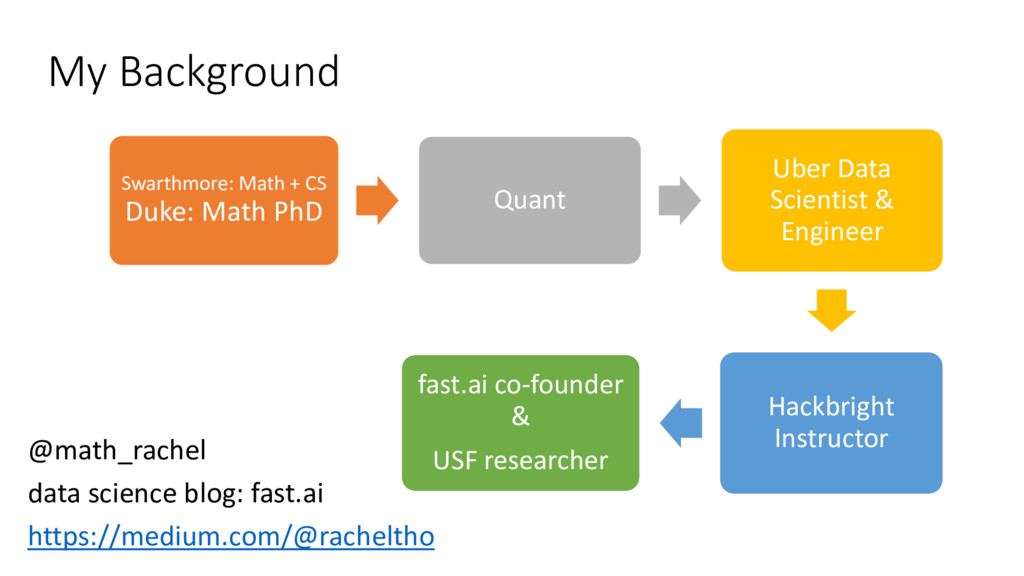
Rachel Thomas is co-founder of fast.ai, which is making deep learning more accessible, and a researcher-in-residence at University of San Francisco Data Institute. Rachel has a mathematics PhD from Duke and has previously worked as a quant, a data scientist + backend engineer at Uber, and a full-stack software instructor at Hackbright.
Rachel was selected by Forbes as one of 20 "Incredible Women Advancing A.I. Research." She co-created the course "Practical Deep Learning for Coders," which is available for free at course.fast.ai and >50,000 students have started it. Her writing has made the front page of Hacker News 4x, the top 5 list on Medium, and been translated into Chinese, Spanish, & Portuguese. She is on twitter @math_rachel
Video: https://www.youtube.com/watch?v=7i6kBz1kZ-A
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}