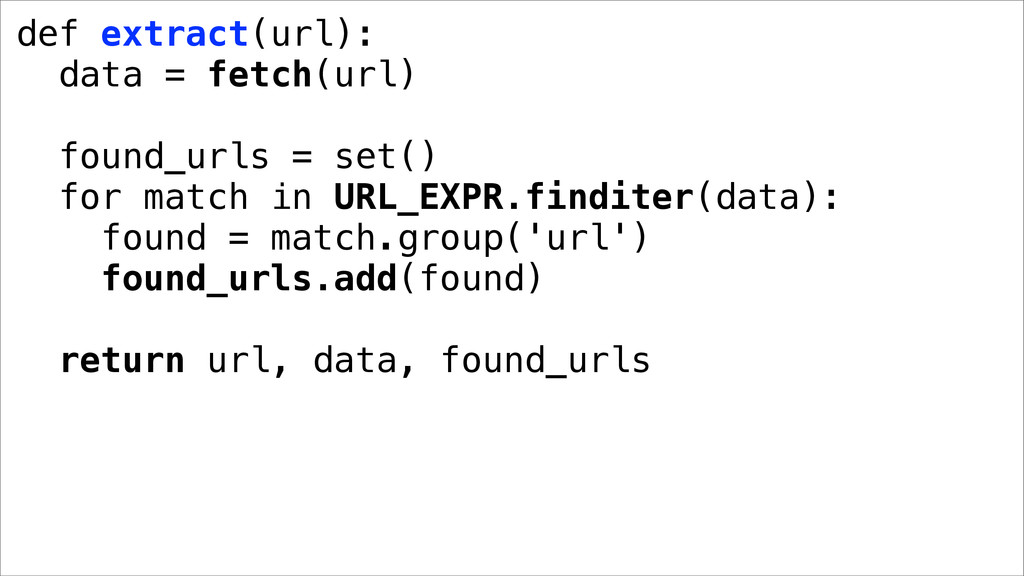
if depth > MAX_DEPTH: continue _, data, found = extract(url) result.append((depth, url, data)) # GIL for url in found: fetchq.put((depth + 1, url)) finally: fetchq.task_done()
depth in range(MAX_DEPTH + 1): batch = yield from ex_multi_async(to_fetch) to_fetch = [] for url, data, found in batch: results.append((depth, url, data)) to_fetch.extend(found) return results
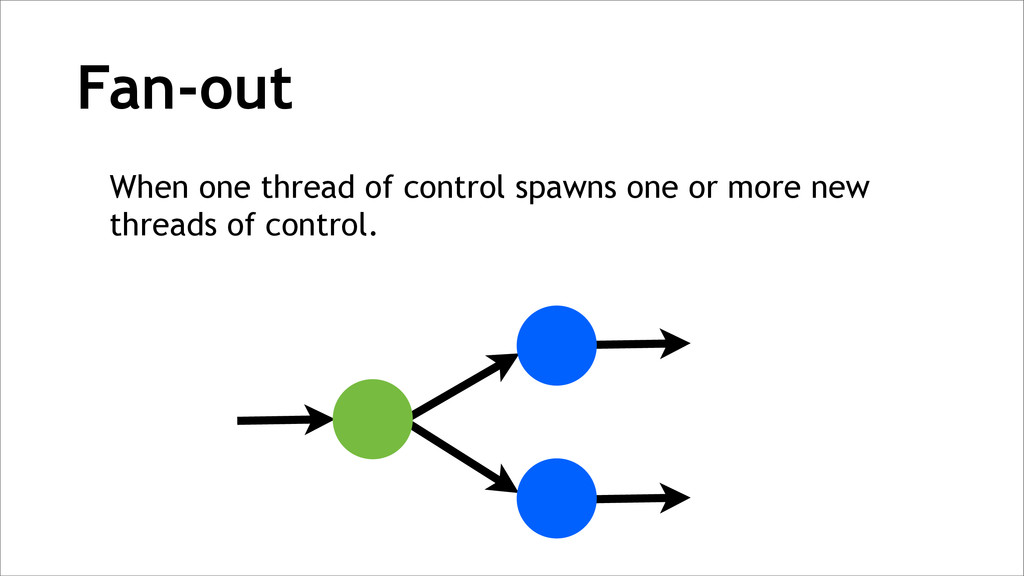
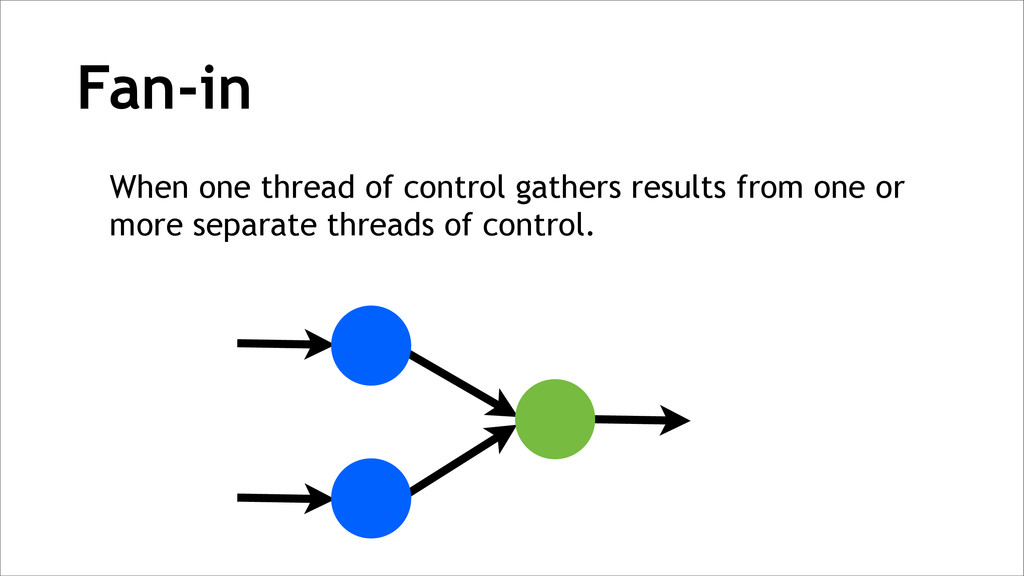
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![def crawl(to_fetch=[]): results = [] for depth in range(MAX_DEPTH +](https://files.speakerdeck.com/presentations/d6ec8190a3e8013145083607ee153eb8/slide_15.jpg){kind=link}
![def extract_multi(to_fetch): results = [] for url in to_fetch: x](https://files.speakerdeck.com/presentations/d6ec8190a3e8013145083607ee153eb8/slide_16.jpg){kind=link}
![>> crawl([‘http://example.com’]) [ (‘http://example.com’, ‘<data>’, set([...])), (‘.../bar’, ‘<data>’, set([...])), (‘.../foo’,](https://files.speakerdeck.com/presentations/d6ec8190a3e8013145083607ee153eb8/slide_17.jpg){kind=link}
{kind=link}
![def crawl_parallel(url): fetchq = Queue() result = [] f =](https://files.speakerdeck.com/presentations/d6ec8190a3e8013145083607ee153eb8/slide_19.jpg){kind=link}
{kind=link}
![>> crawl_parallel(‘http://example.com’) [ (‘http://example.com’, ‘...’, set([...])), (‘.../bar’, ‘...’, set([...])), (‘.../foo’,](https://files.speakerdeck.com/presentations/d6ec8190a3e8013145083607ee153eb8/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![# Old way def crawl(to_fetch=[]): results = [] for depth](https://files.speakerdeck.com/presentations/d6ec8190a3e8013145083607ee153eb8/slide_32.jpg){kind=link}
![@asyncio.coroutine def crawl_async(to_fetch=[]): results = [] for depth in range(MAX_DEPTH](https://files.speakerdeck.com/presentations/d6ec8190a3e8013145083607ee153eb8/slide_33.jpg){kind=link}
![# Old way def extract_multi(to_fetch): results = [] for url](https://files.speakerdeck.com/presentations/d6ec8190a3e8013145083607ee153eb8/slide_34.jpg){kind=link}
![@asyncio.coroutine def ex_multi_async(to_fetch): results = [] for url in to_fetch:](https://files.speakerdeck.com/presentations/d6ec8190a3e8013145083607ee153eb8/slide_35.jpg){kind=link}
{kind=link}
![@asyncio.coroutine def ex_multi_async(to_fetch): results = [] for url in to_fetch:](https://files.speakerdeck.com/presentations/d6ec8190a3e8013145083607ee153eb8/slide_37.jpg){kind=link}
![@asyncio.coroutine def ex_multi_async(to_fetch): futures, results = [], [] for url](https://files.speakerdeck.com/presentations/d6ec8190a3e8013145083607ee153eb8/slide_38.jpg){kind=link}
![@asyncio.coroutine # No changes def crawl_async(to_fetch=[]): results = [] for](https://files.speakerdeck.com/presentations/d6ec8190a3e8013145083607ee153eb8/slide_39.jpg){kind=link}
![>> crawl_async([‘http://example.com’]) [ (‘http://example.com’, ‘...’, set([...])), (‘.../bar’, ‘...’, set([...])), (‘.../foo’,](https://files.speakerdeck.com/presentations/d6ec8190a3e8013145083607ee153eb8/slide_40.jpg){kind=link}
{kind=link}
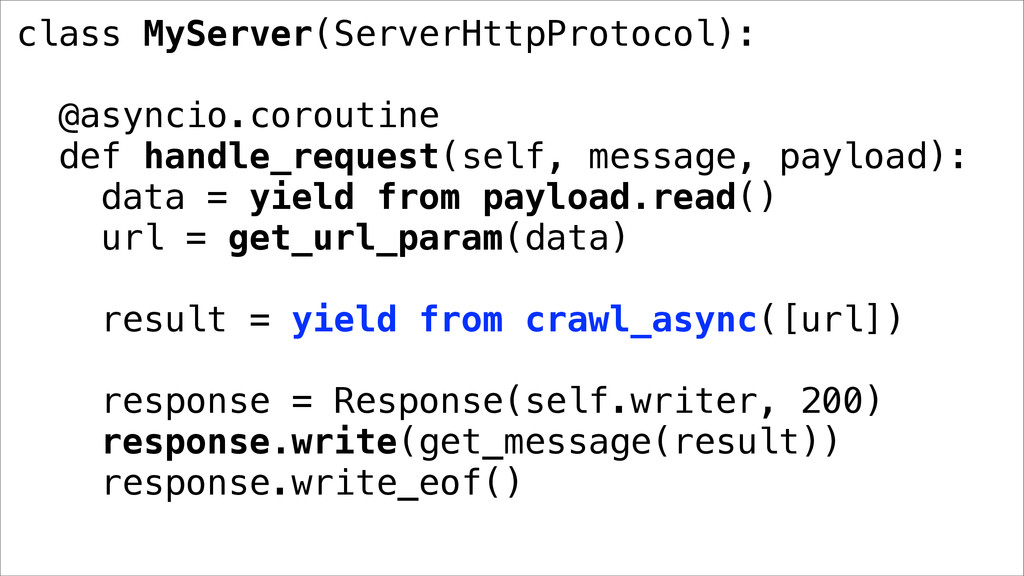{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}