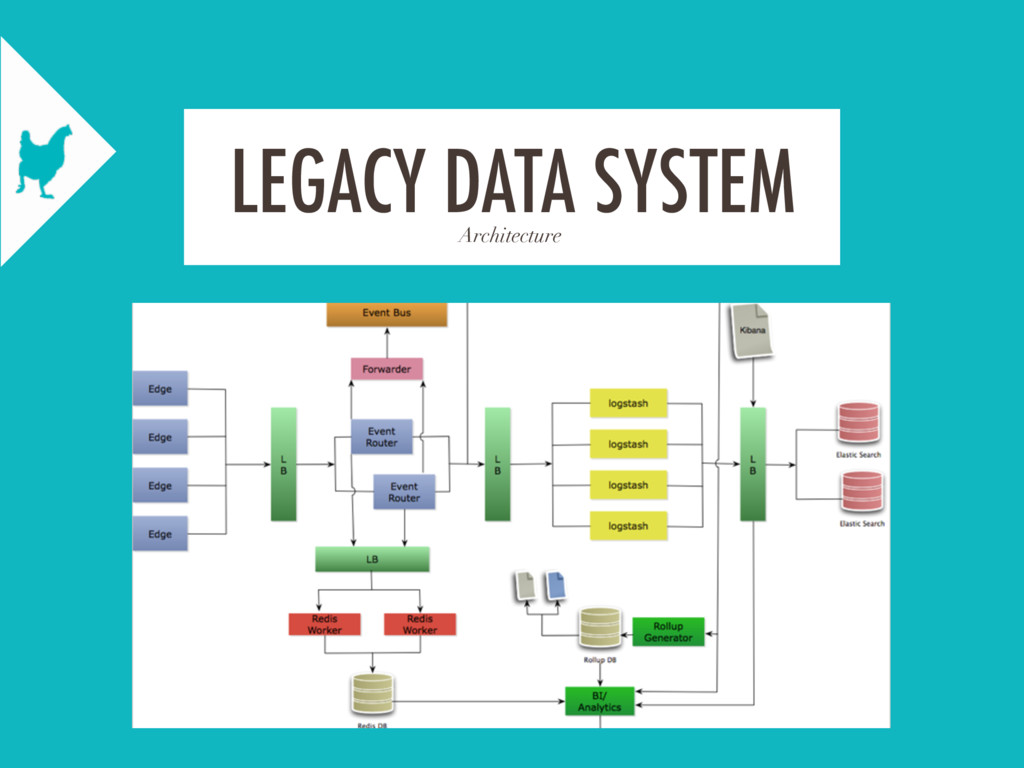
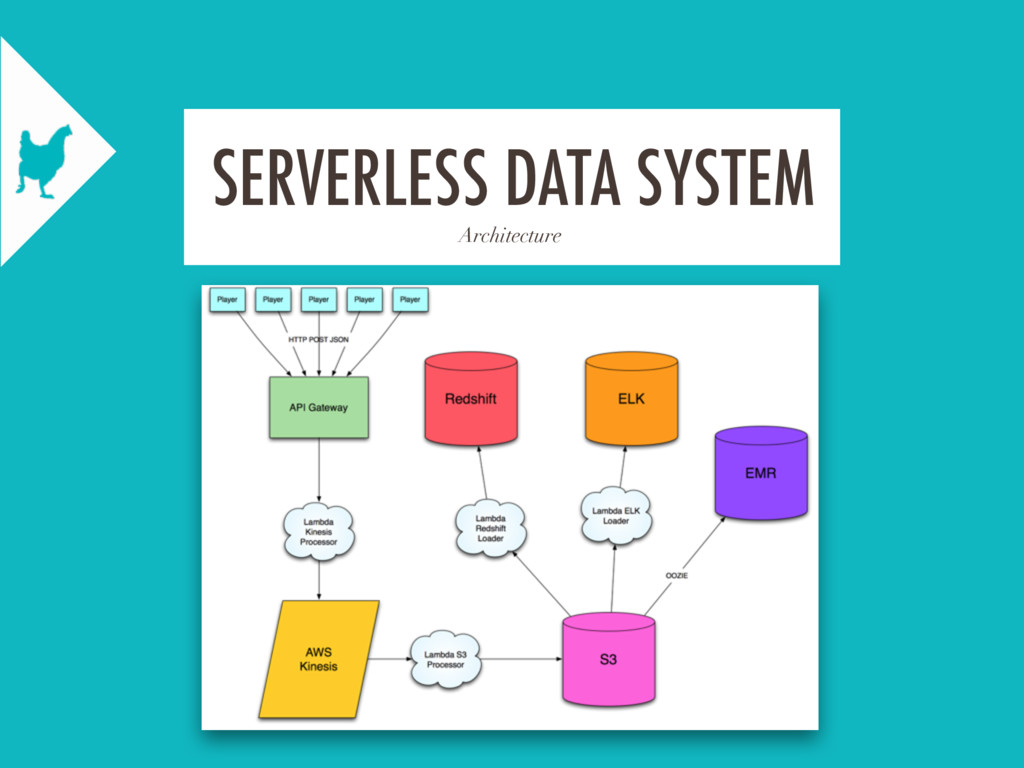
At Scripps Networks Living, we operate a network of video players generating around 100 million events per day. In order to process, store, and analyze this data, we operate batch and realtime data pipelines based off of Lambda Architecture principles. After outgrowing our original events system, we rebuilt it from the ground up based on AWS Services and the learnings from our original system.
https://us.pycon.org/2016/schedule/presentation/2237/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}