Modern genome editing techniques such as CRISPR-Cas9 are revolutionizing the way we discover and treat the root genetic causes of disease. Many of the most popular tools and libraries in this cutting edge application are written in Python. This talk will provide a general, software-centric introduction to the exciting new area of genome editing, describe the central string search, machine learning, and data management problems involved, and review how Python frameworks and libraries are used today to solve these problems in Production in order to benefit human health. This talk assumes no prior lab experience: only a proficiency with Python and curiosity!
https://us.pycon.org/2017/schedule/presentation/621/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
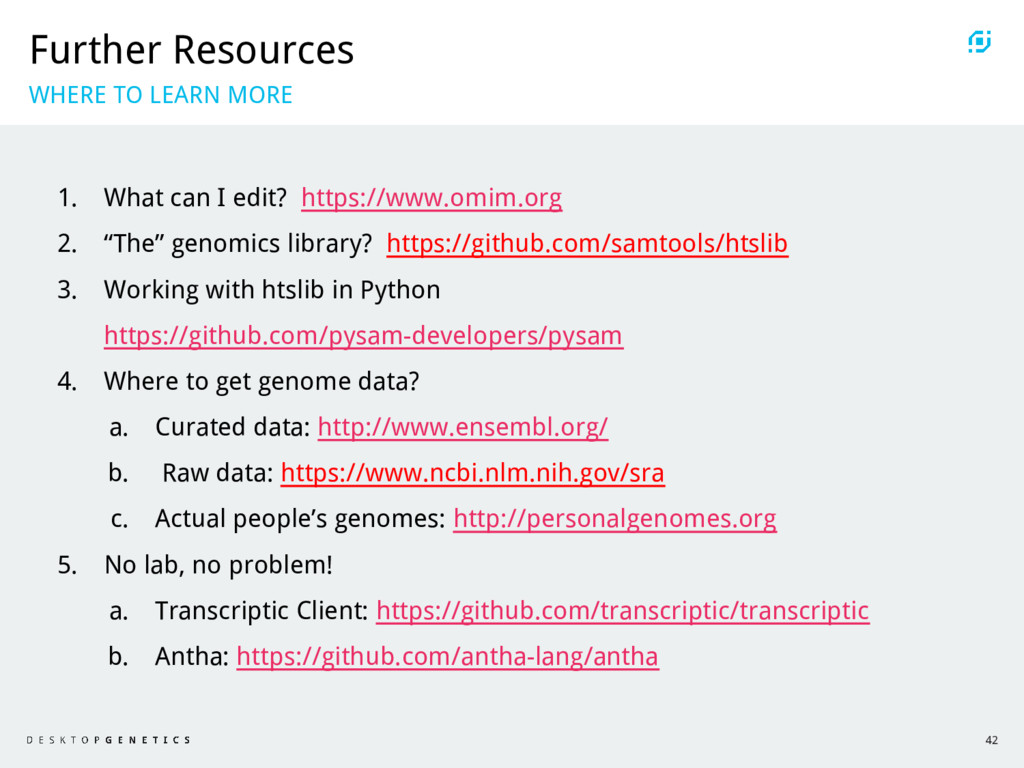{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![© Desktop Genetics Ltd. 2017 [email protected]](https://files.speakerdeck.com/presentations/c2254e768d9b4f54b0a4d9fab59506c2/slide_46.jpg){kind=link}