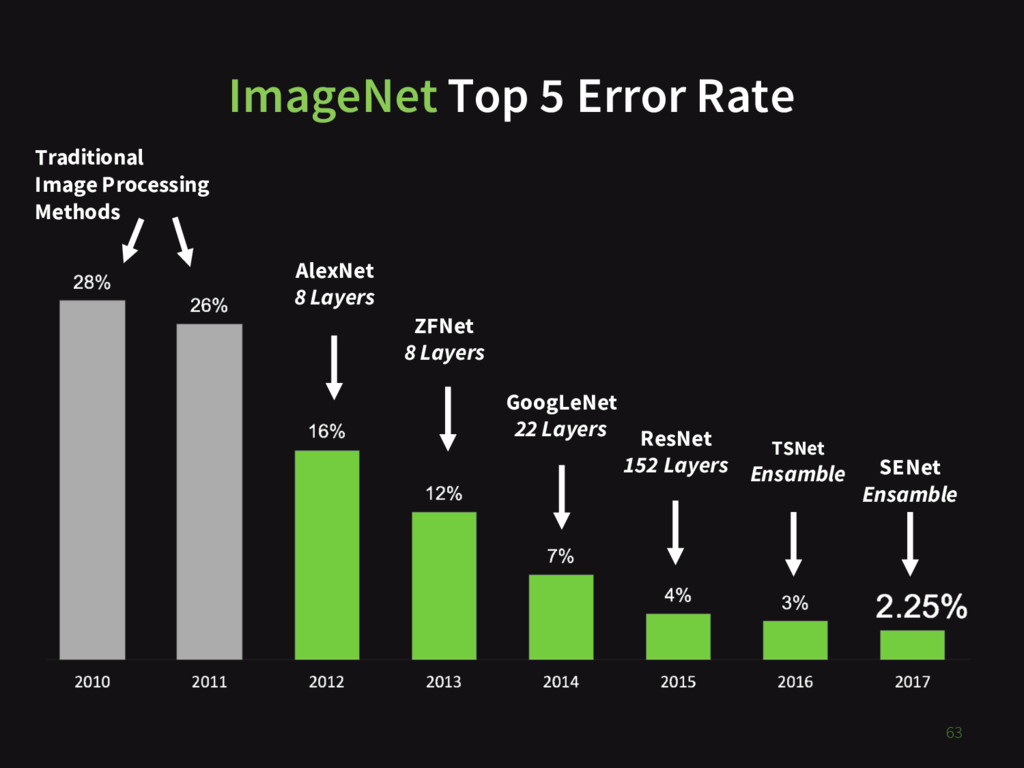
The state-of-the-art in image classification has skyrocketed thanks to the development of deep convolutional neural networks and increases in the amount of data and computing power available to train them. The top-5 error rate in the international ImageNet competition to predict which of 1000 classes an image belongs to has plummeted from 28% error in 2010 before deep learning to just 2.25% in 2017 (human level error is around 5%).
In addition to being able to classify objects in images (including not hotdogs), deep learning can be used to automatically generate captions for images, convert photos into paintings, detect cancer in pathology slide images, and help self-driving cars ‘see’.
The talk will give an overview of the cutting edge in the field and some of the core mathematical concepts behind the models. It will also include a short code-first tutorial to show how easy it is to get started using deep learning for computer vision in python…
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![What is a neuron? 24 • 3 inputs [x1,x2,x3] •](https://files.speakerdeck.com/presentations/fd7a82941b6644b3a02960291643a247/slide_23.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
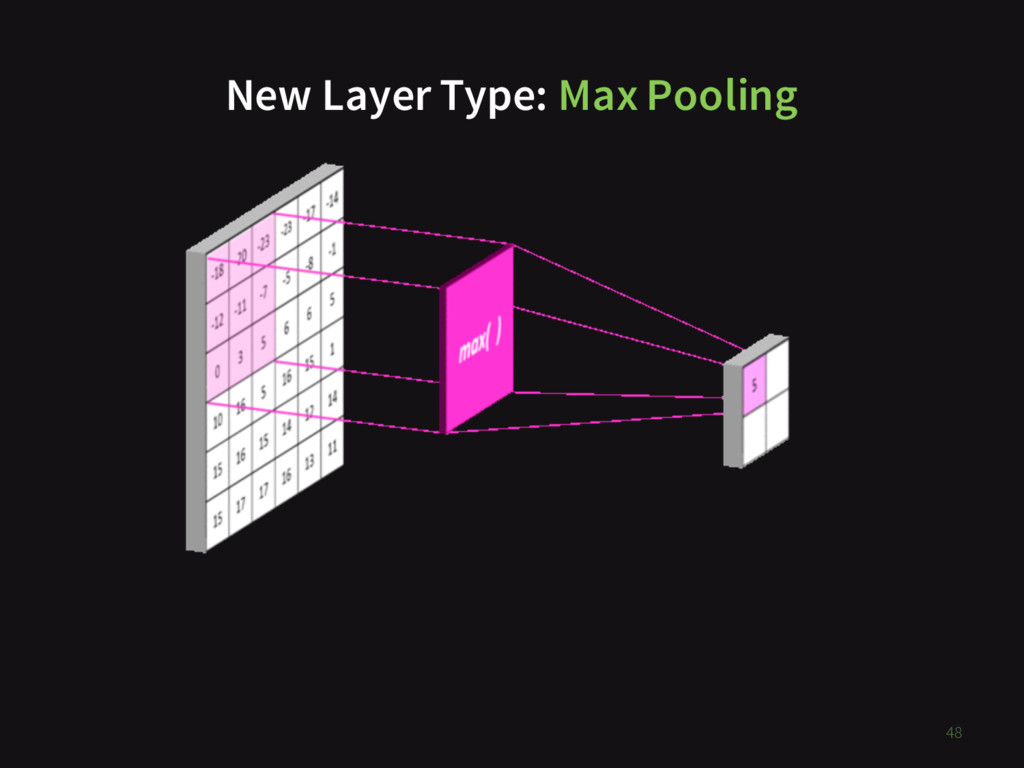{kind=link}
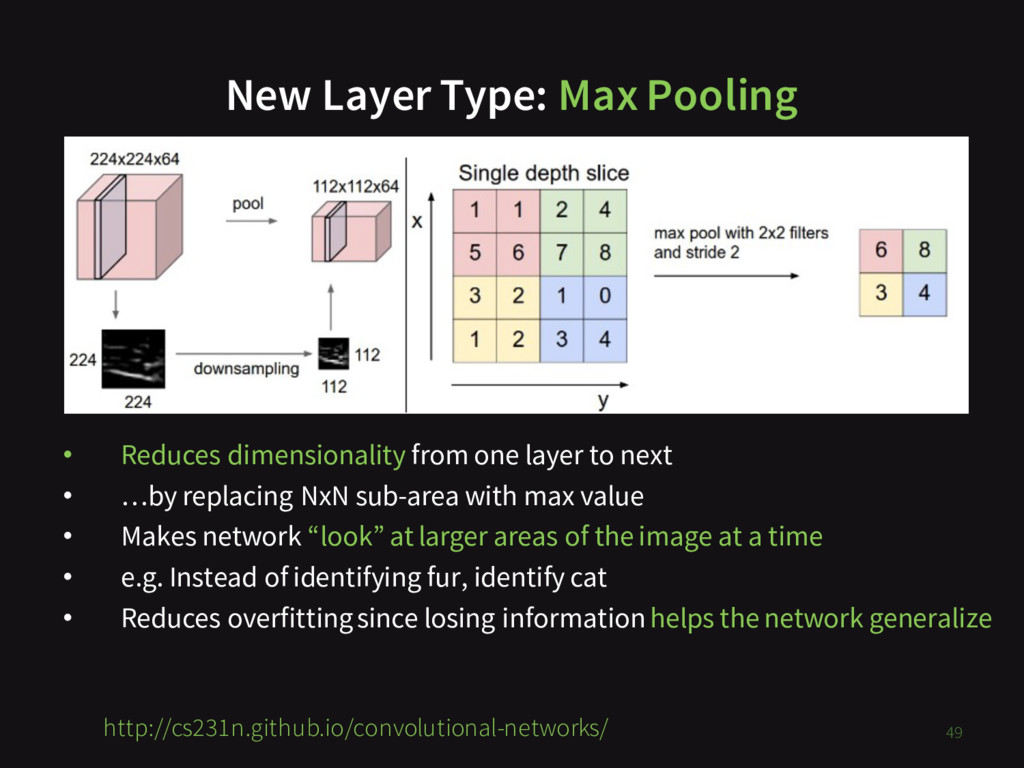{kind=link}
{kind=link}
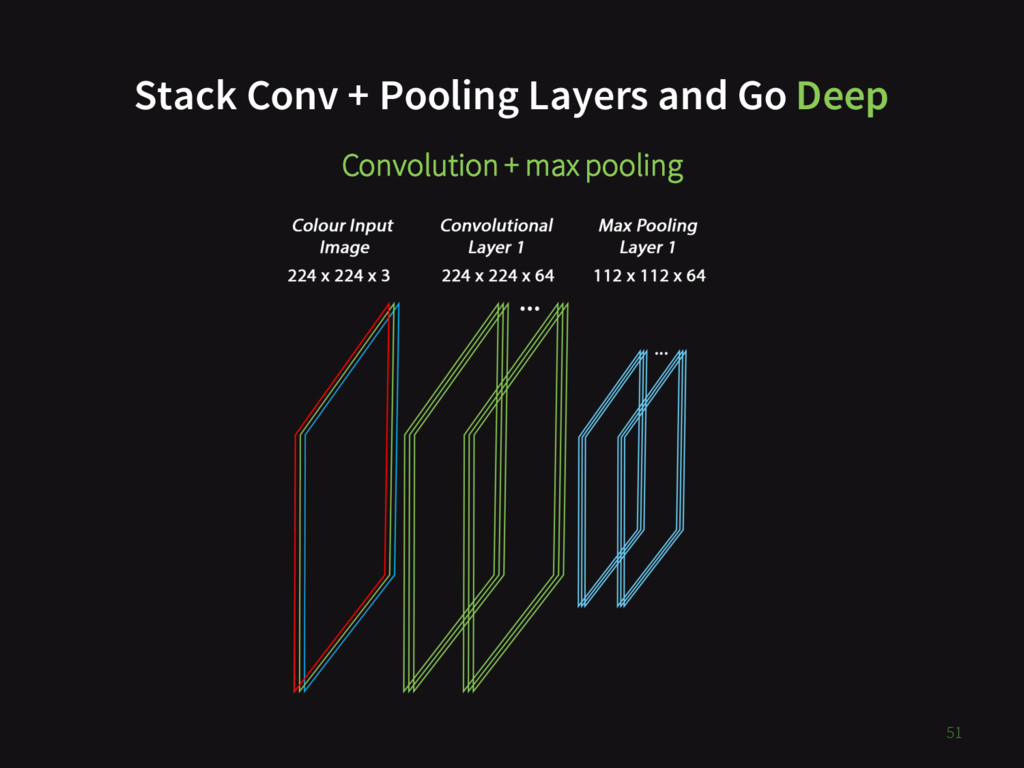{kind=link}
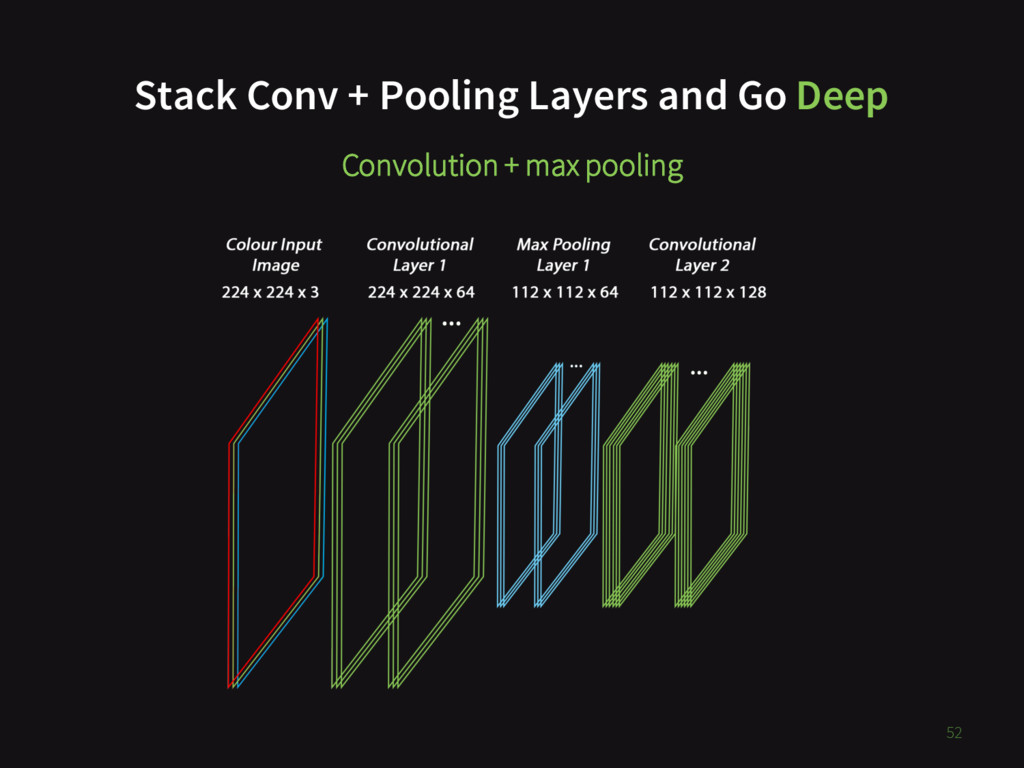{kind=link}
{kind=link}
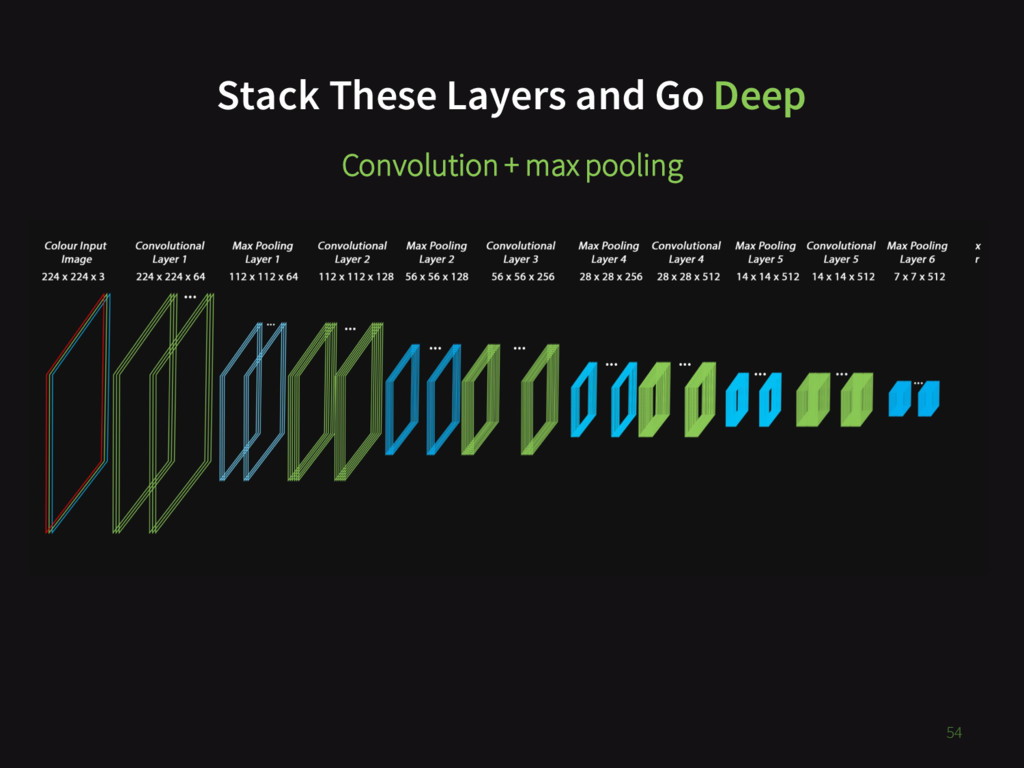{kind=link}
{kind=link}
{kind=link}
![Softmax Convert scores ∈ ℝ to probabilities ∈ [0,1] Final](https://files.speakerdeck.com/presentations/fd7a82941b6644b3a02960291643a247/slide_56.jpg){kind=link}
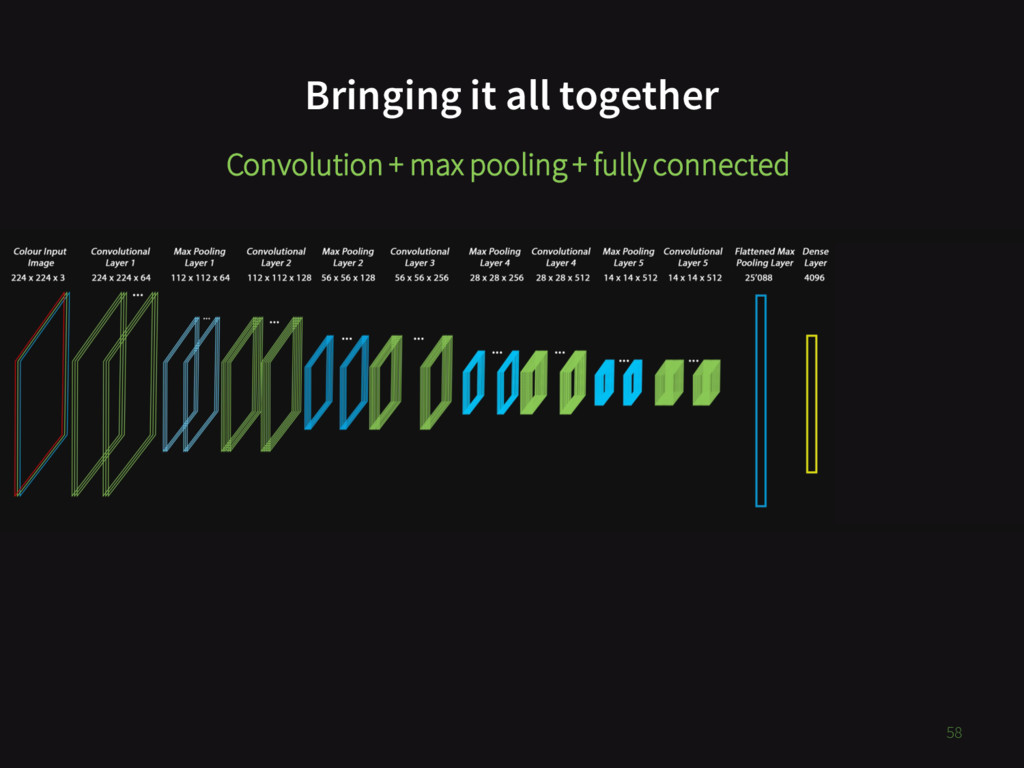{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
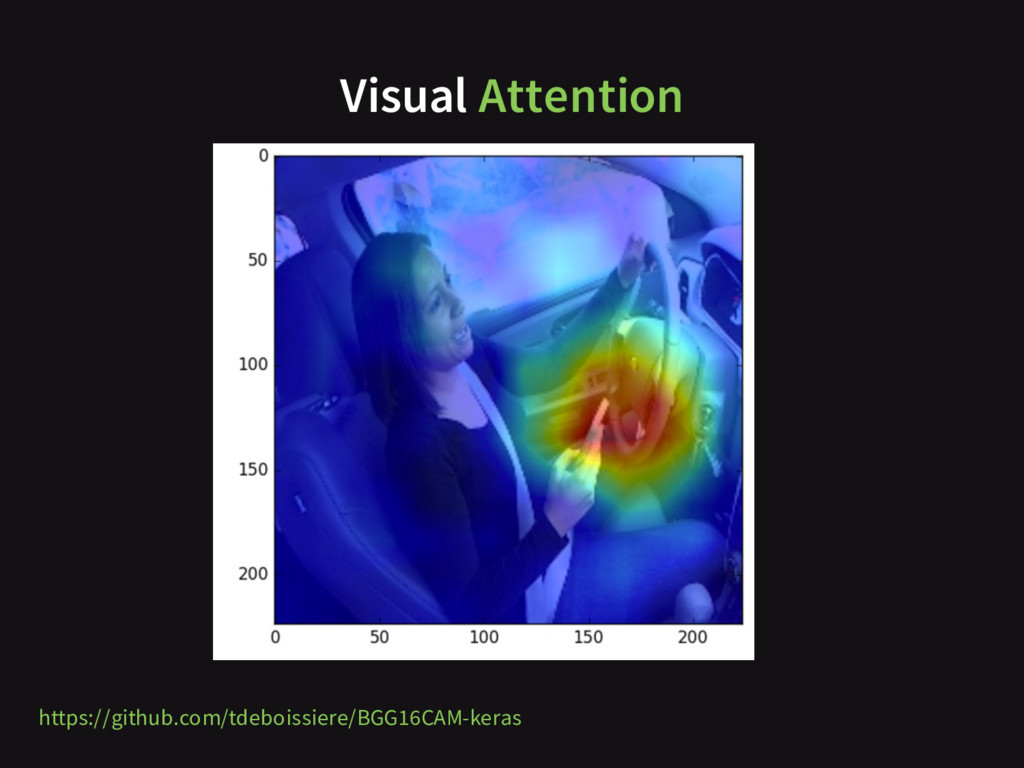{kind=link}
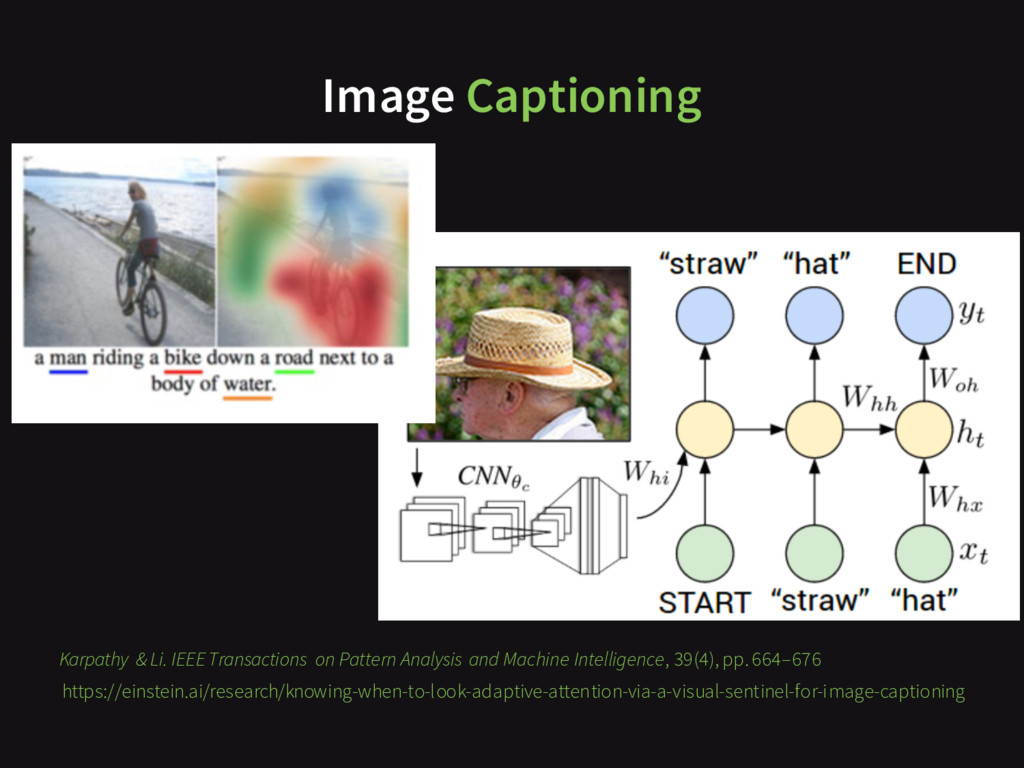{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
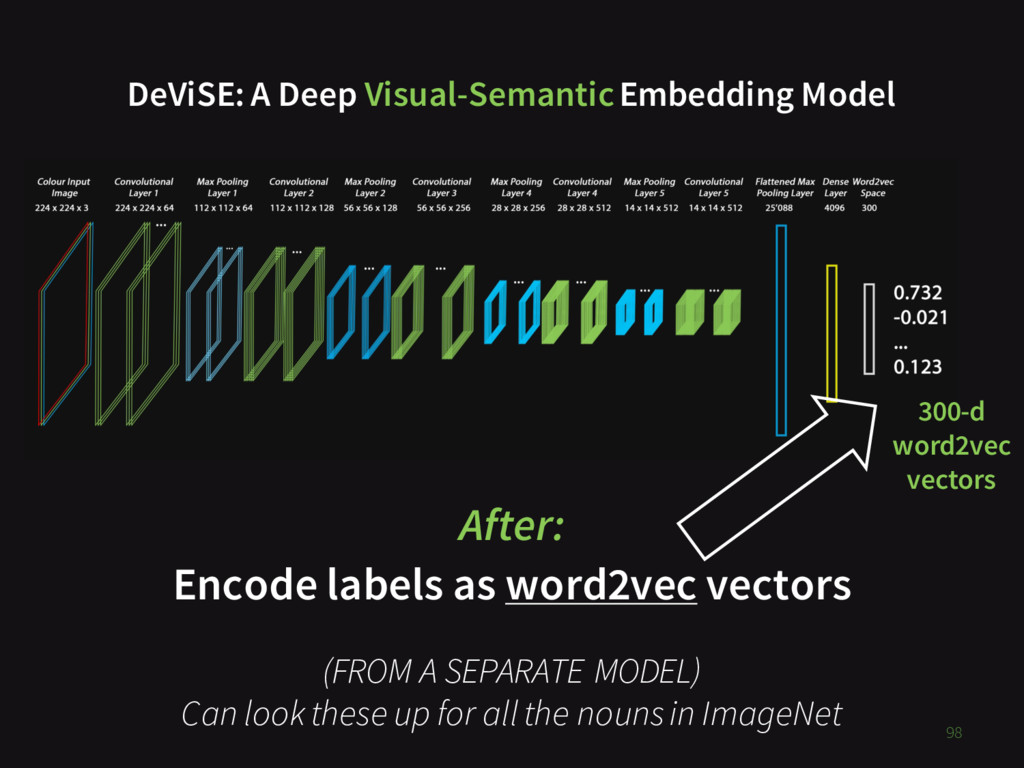{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
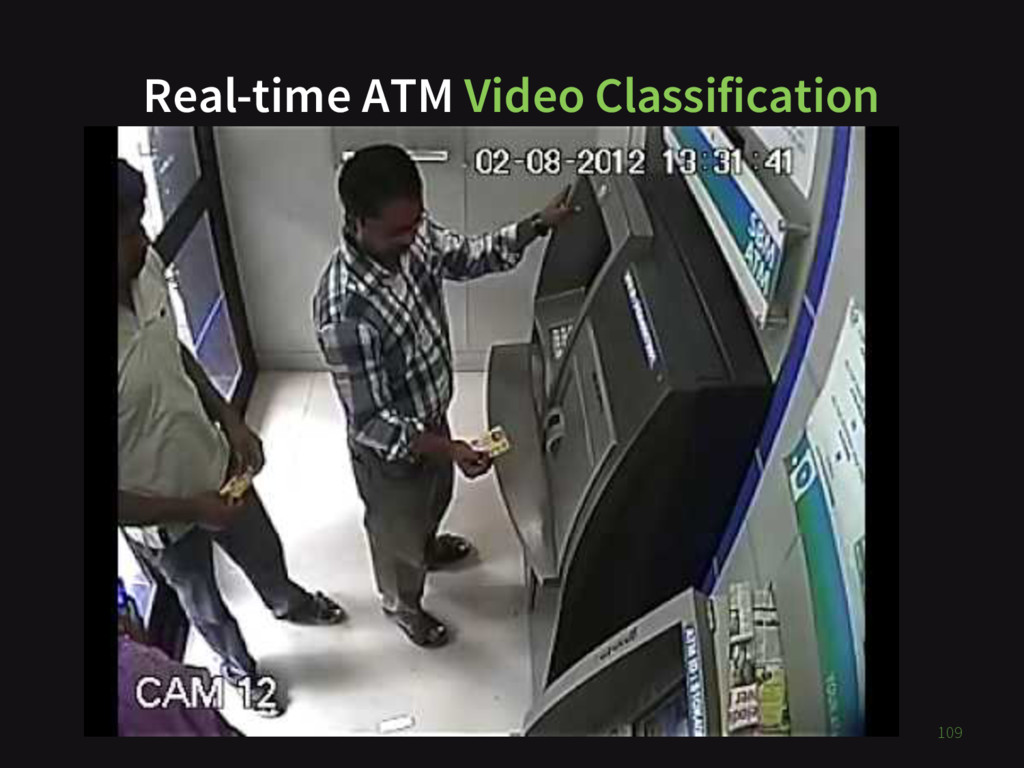{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}