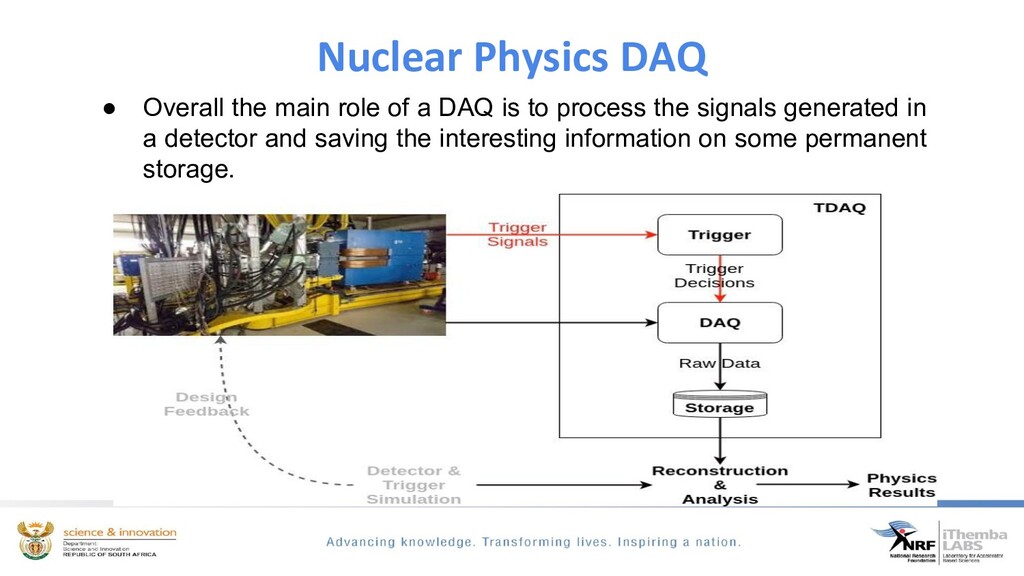
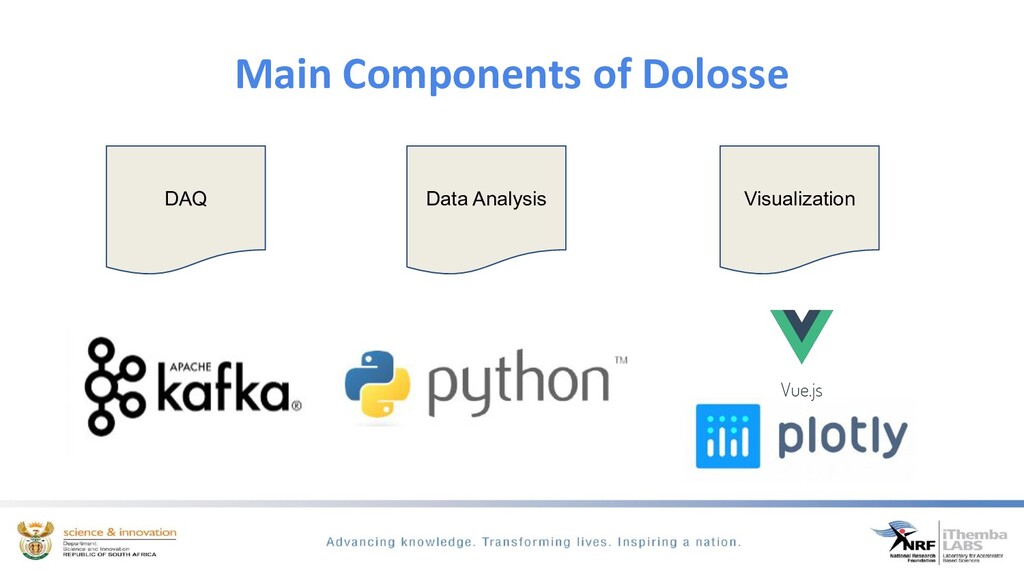
In this talk we will introduce key concepts and techniques of triggering and nuclear physics data acquisition. We will then discuss the development of a new distributed data acquisition software system developed for the subatomic and materials research experimental facilities at iThemba LABS, using python and open source streaming tools.
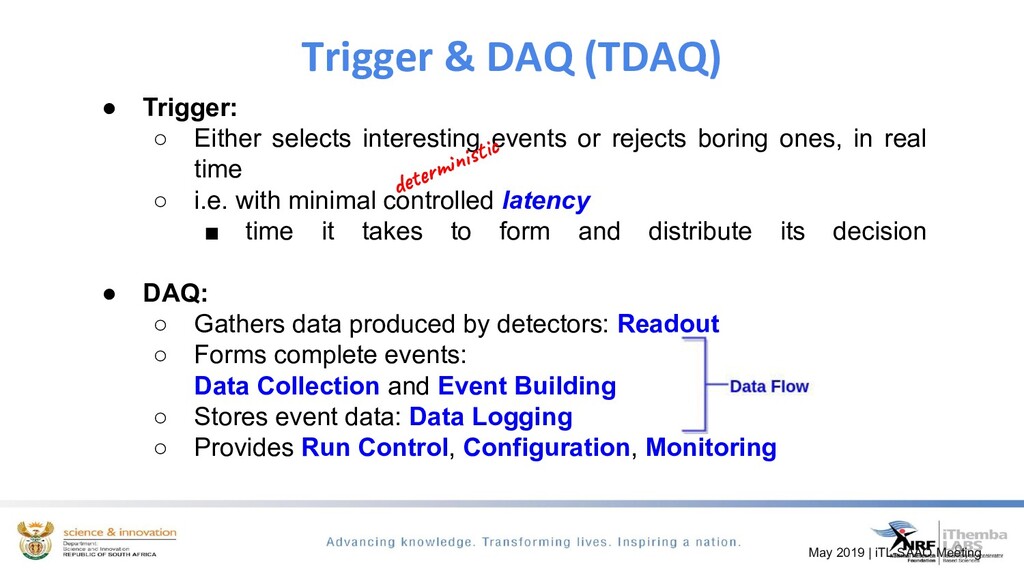
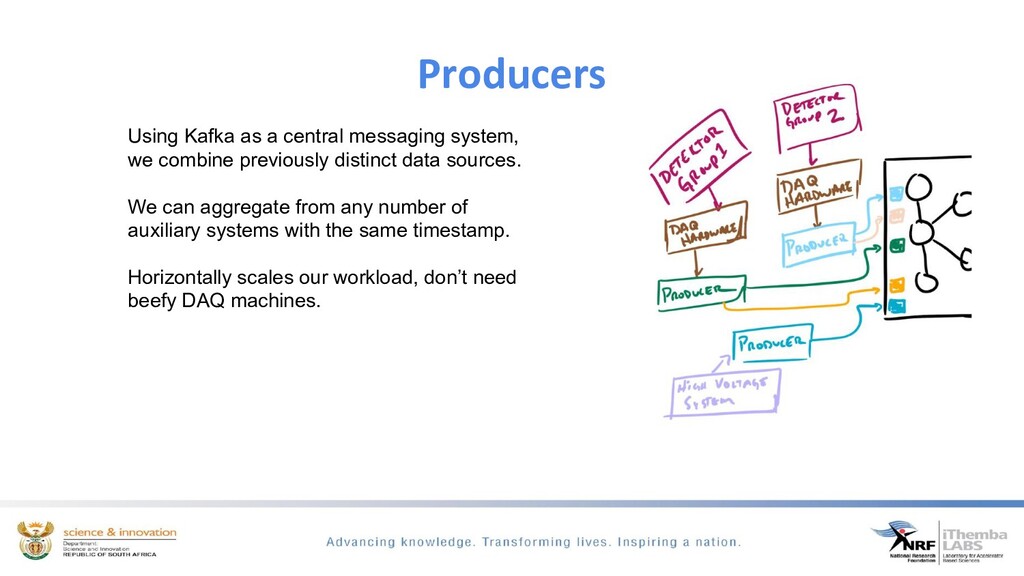
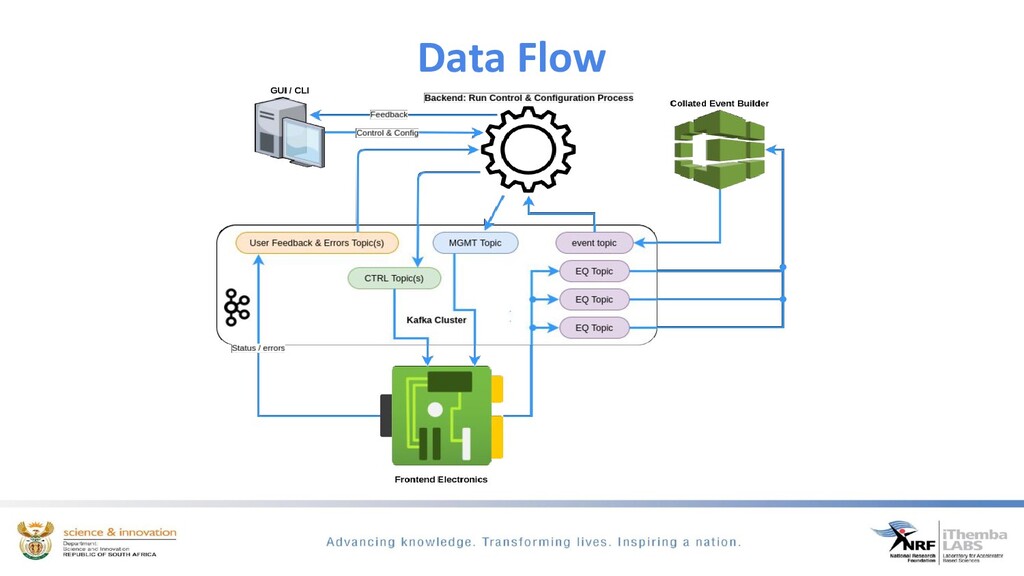
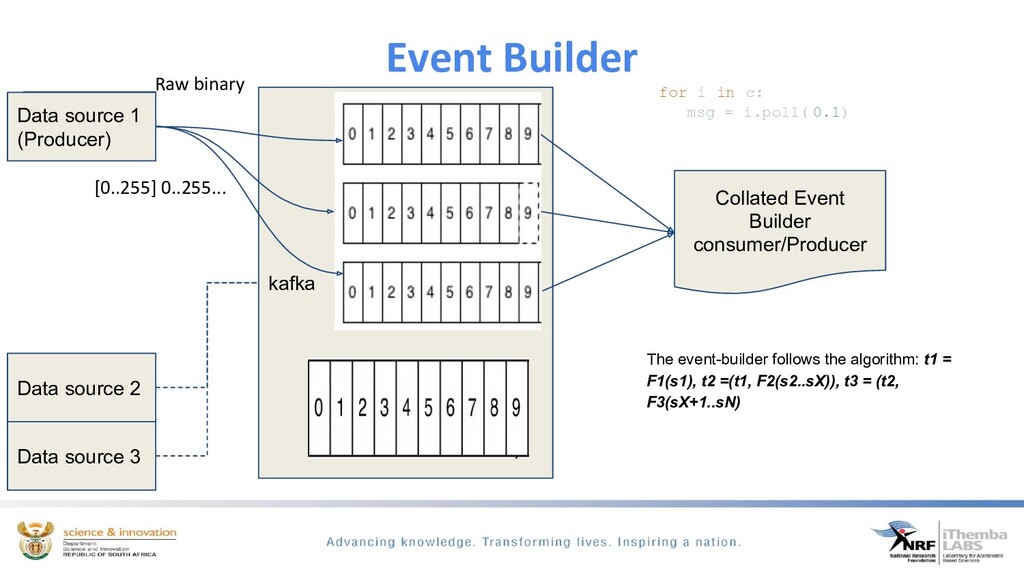
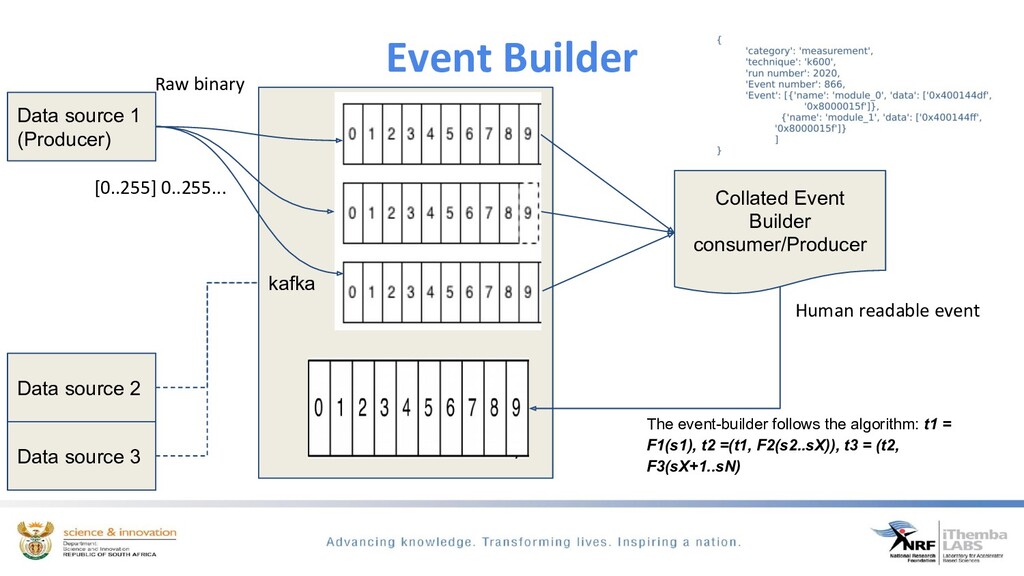
The discussion will show how we use Apache kafka to modernise our DAQ systems. Apache Kafka is a distributed messaging system which we use to build a DAQ system that has a multi-producer, multi-consumer model. This discussion will focus on how we use kafka to configure experimental runs, monitor and control the run and the data acquisition of real-time physics events.
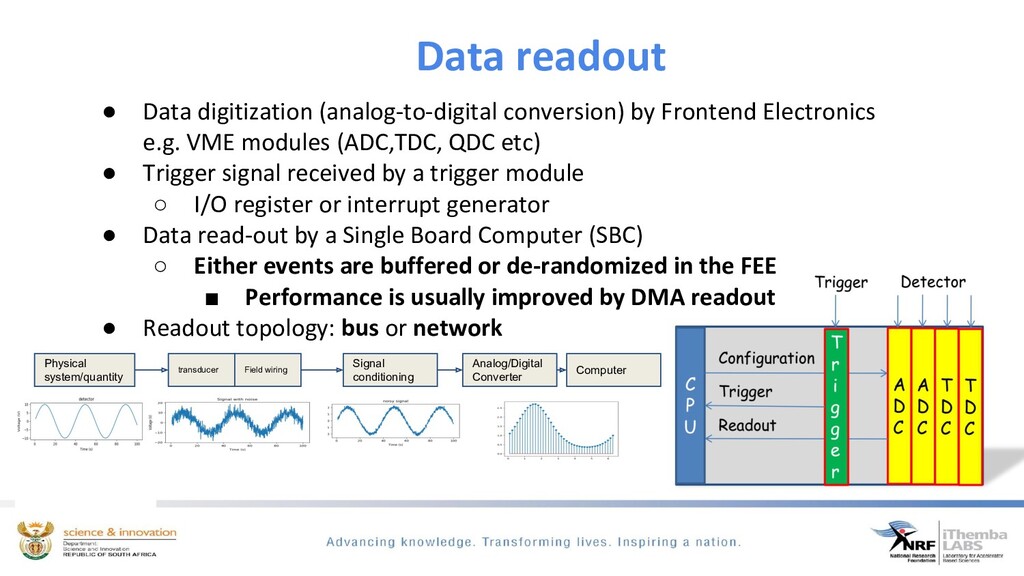
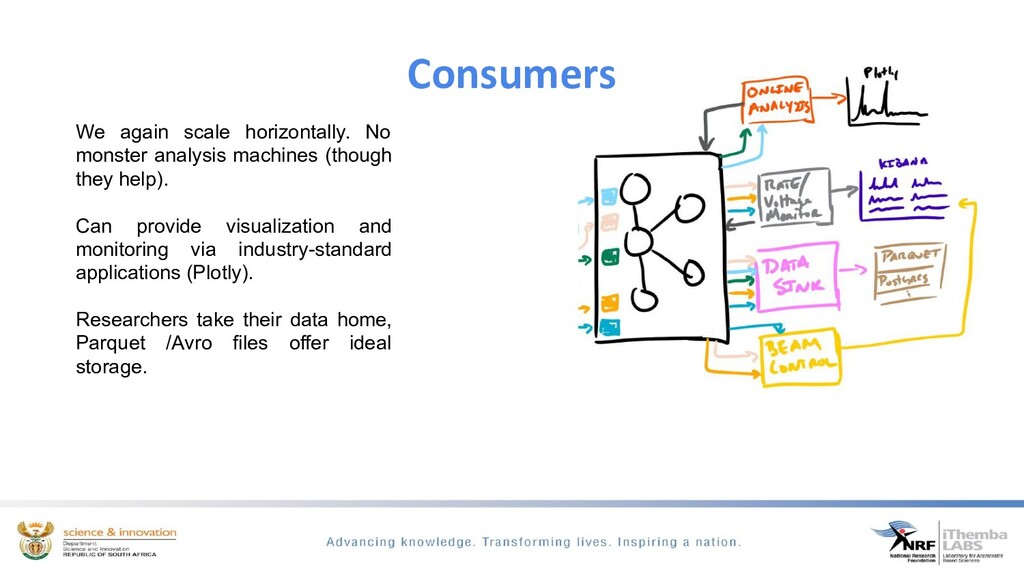
We ingest time-series scientific data from dedicated spectroscopy hardware modules, filtering to determine if we have event coincidence between these different modules, build an interesting physics event from this data and exposing it for easy analysis and visualisation through the python ecosystem. By using kafka the need for heavy processing servers/PC’s are eliminated.
iThemba Laboratory for Accelerator-Based Sciences (LABS) is a national infrastructure platform of the National Research Foundation (NRF) specialising in particle accelerator-based sciences and engineering, with offices in Cape Town and Johannesburg. It has a number of particle accelerators used for basic research in material sciences, subatomic physics as well as production of radio-pharmaceuticals for local and international markets
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Baie Dankie. Rea leboha. Enkosi. Thank you. [email protected] [email protected]](https://files.speakerdeck.com/presentations/43a8fa33bb5c42be9a66966f54237721/slide_34.jpg){kind=link}