Overview
It's never been easier to use all manner of interesting computing devices such as multicore CPUs, GPUs and FPGAs using OpenCL, an open heterogeneous computing standard, supported by major hardware vendors: Intel, NVIDIA, AMD, ARM, etc. And it's never been easier to use OpenCL via the excellent Python bindings,
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
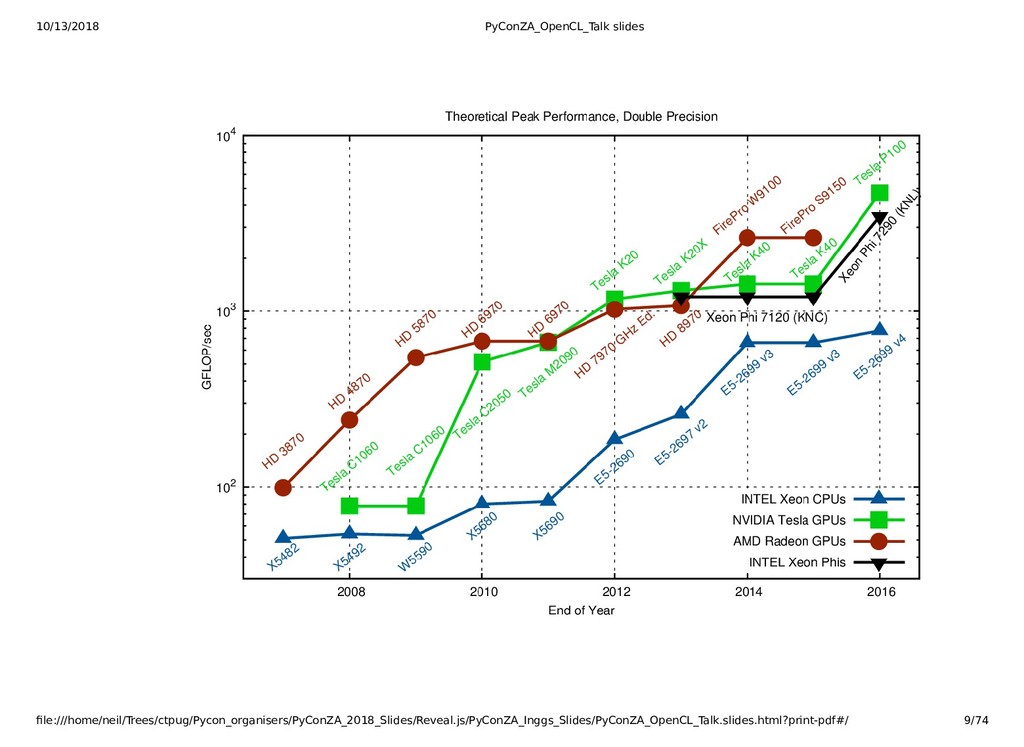{kind=link}
{kind=link}
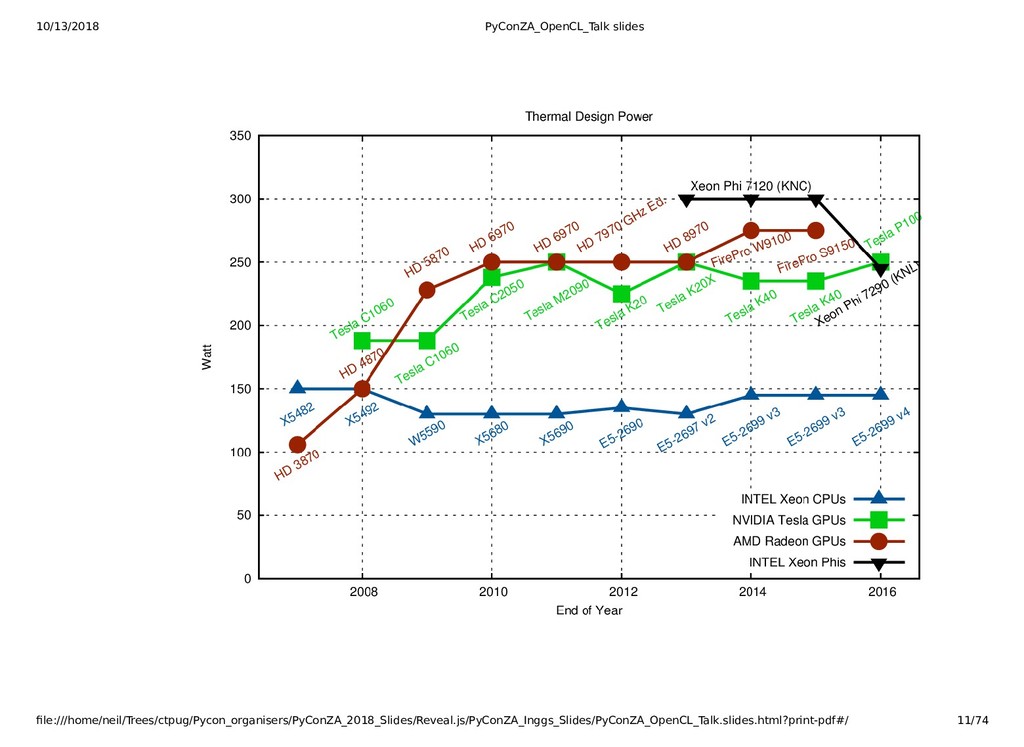{kind=link}
{kind=link}
{kind=link}
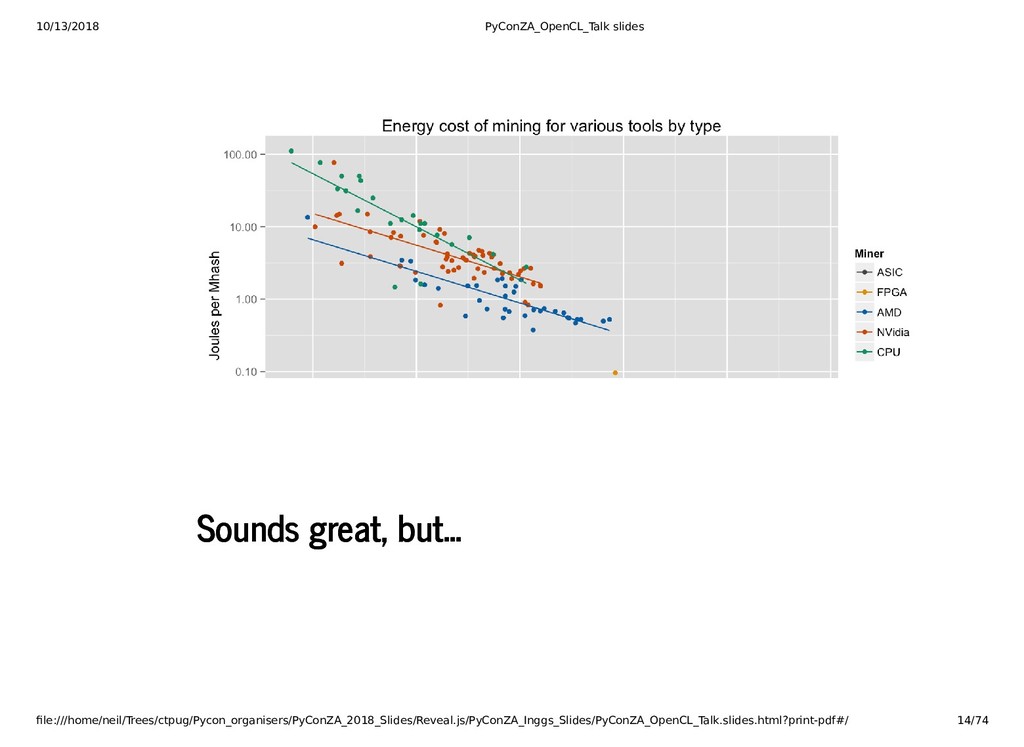{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![10/13/2018 PyConZA_OpenCL_Talk slides file:///home/neil/Trees/ctpug/Pycon_organisers/PyConZA_2018_Slides/Reveal.js/PyConZA_Inggs_Slides/PyConZA_OpenCL_Talk.slides.html?print-pdf#/ 19/74 In [2]: ocl_platforms = (platform.name](https://files.speakerdeck.com/presentations/20635ab8ce2f4b9a9dac98e3f83d7e2e/slide_18.jpg){kind=link}
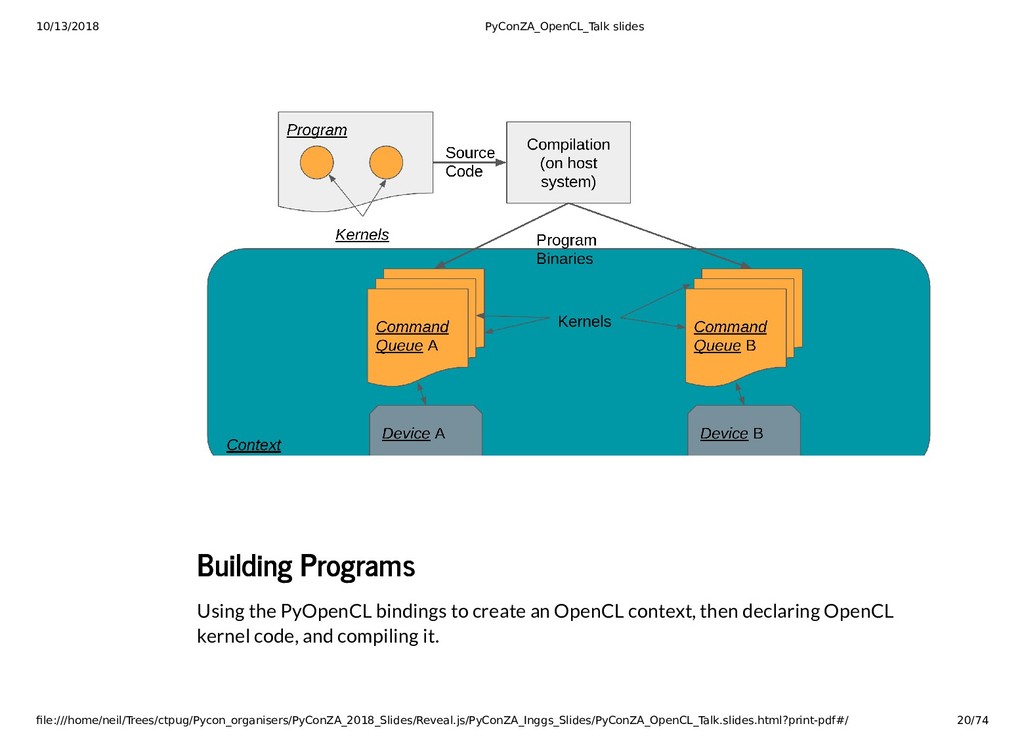{kind=link}
{kind=link}
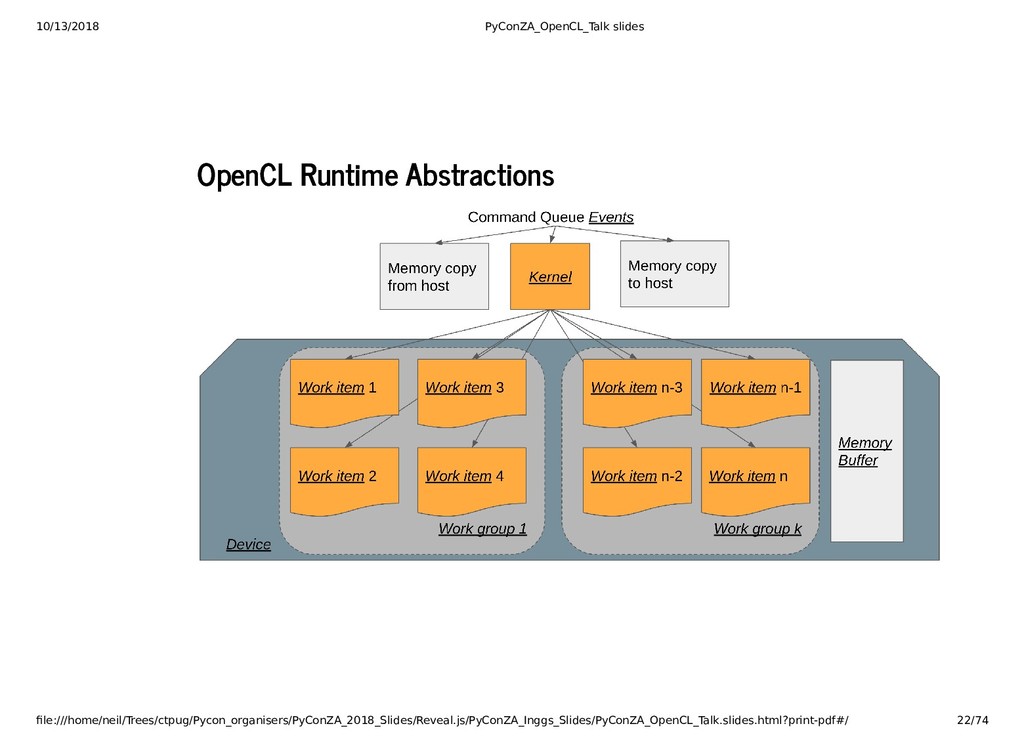{kind=link}
{kind=link}
![10/13/2018 PyConZA_OpenCL_Talk slides file:///home/neil/Trees/ctpug/Pycon_organisers/PyConZA_2018_Slides/Reveal.js/PyConZA_Inggs_Slides/PyConZA_OpenCL_Talk.slides.html?print-pdf#/ 24/74 In [6]: def run_ocl_kernel(queue, kernel,](https://files.speakerdeck.com/presentations/20635ab8ce2f4b9a9dac98e3f83d7e2e/slide_23.jpg){kind=link}
![10/13/2018 PyConZA_OpenCL_Talk slides file:///home/neil/Trees/ctpug/Pycon_organisers/PyConZA_2018_Slides/Reveal.js/PyConZA_Inggs_Slides/PyConZA_OpenCL_Talk.slides.html?print-pdf#/ 25/74 In [7]: def check_sum_results(a,b,c): c_ref](https://files.speakerdeck.com/presentations/20635ab8ce2f4b9a9dac98e3f83d7e2e/slide_24.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
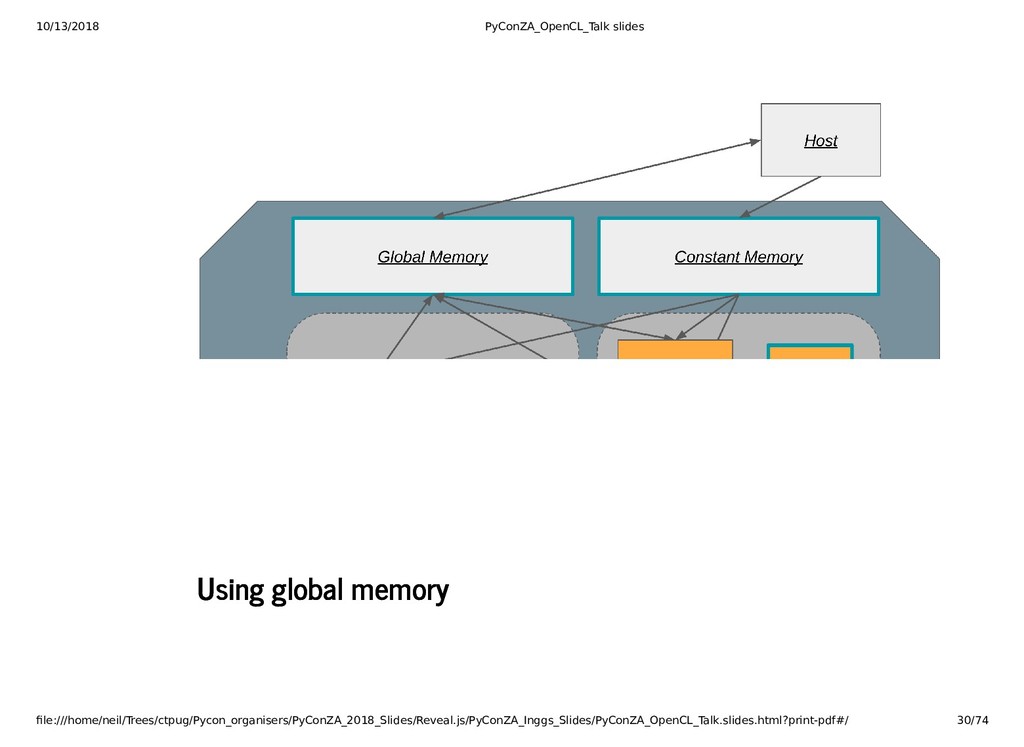{kind=link}
![10/13/2018 PyConZA_OpenCL_Talk slides file:///home/neil/Trees/ctpug/Pycon_organisers/PyConZA_2018_Slides/Reveal.js/PyConZA_Inggs_Slides/PyConZA_OpenCL_Talk.slides.html?print-pdf#/ 31/74 In [12]: def create_input_memory(context, input_arrays):](https://files.speakerdeck.com/presentations/20635ab8ce2f4b9a9dac98e3f83d7e2e/slide_30.jpg){kind=link}
![10/13/2018 PyConZA_OpenCL_Talk slides file:///home/neil/Trees/ctpug/Pycon_organisers/PyConZA_2018_Slides/Reveal.js/PyConZA_Inggs_Slides/PyConZA_OpenCL_Talk.slides.html?print-pdf#/ 32/74 In [15]: a = numpy.random.rand(N).astype(numpy.float32)](https://files.speakerdeck.com/presentations/20635ab8ce2f4b9a9dac98e3f83d7e2e/slide_31.jpg){kind=link}
{kind=link}
![10/13/2018 PyConZA_OpenCL_Talk slides file:///home/neil/Trees/ctpug/Pycon_organisers/PyConZA_2018_Slides/Reveal.js/PyConZA_Inggs_Slides/PyConZA_OpenCL_Talk.slides.html?print-pdf#/ 34/74 In [18]: %timeit run_ocl_kernel(nvidia_queue, nvidia_program.sum_batched,](https://files.speakerdeck.com/presentations/20635ab8ce2f4b9a9dac98e3f83d7e2e/slide_33.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![10/13/2018 PyConZA_OpenCL_Talk slides file:///home/neil/Trees/ctpug/Pycon_organisers/PyConZA_2018_Slides/Reveal.js/PyConZA_Inggs_Slides/PyConZA_OpenCL_Talk.slides.html?print-pdf#/ 40/74 In [21]: intel_platform = [platform](https://files.speakerdeck.com/presentations/20635ab8ce2f4b9a9dac98e3f83d7e2e/slide_39.jpg){kind=link}
![10/13/2018 PyConZA_OpenCL_Talk slides file:///home/neil/Trees/ctpug/Pycon_organisers/PyConZA_2018_Slides/Reveal.js/PyConZA_Inggs_Slides/PyConZA_OpenCL_Talk.slides.html?print-pdf#/ 41/74 In [22]: for device in](https://files.speakerdeck.com/presentations/20635ab8ce2f4b9a9dac98e3f83d7e2e/slide_40.jpg){kind=link}
![10/13/2018 PyConZA_OpenCL_Talk slides file:///home/neil/Trees/ctpug/Pycon_organisers/PyConZA_2018_Slides/Reveal.js/PyConZA_Inggs_Slides/PyConZA_OpenCL_Talk.slides.html?print-pdf#/ 42/74 property_string_args = (property_name,device.get_info(processing_propert ies[property_name])) print("{}:](https://files.speakerdeck.com/presentations/20635ab8ce2f4b9a9dac98e3f83d7e2e/slide_41.jpg){kind=link}
{kind=link}
![10/13/2018 PyConZA_OpenCL_Talk slides file:///home/neil/Trees/ctpug/Pycon_organisers/PyConZA_2018_Slides/Reveal.js/PyConZA_Inggs_Slides/PyConZA_OpenCL_Talk.slides.html?print-pdf#/ 44/74 In [23]: !clinfo Number of](https://files.speakerdeck.com/presentations/20635ab8ce2f4b9a9dac98e3f83d7e2e/slide_43.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![10/13/2018 PyConZA_OpenCL_Talk slides file:///home/neil/Trees/ctpug/Pycon_organisers/PyConZA_2018_Slides/Reveal.js/PyConZA_Inggs_Slides/PyConZA_OpenCL_Talk.slides.html?print-pdf#/ 62/74 In [24]: %timeit run_ocl_kernel(nvidia_queue, nvidia_program.sum16,](https://files.speakerdeck.com/presentations/20635ab8ce2f4b9a9dac98e3f83d7e2e/slide_61.jpg){kind=link}
{kind=link}
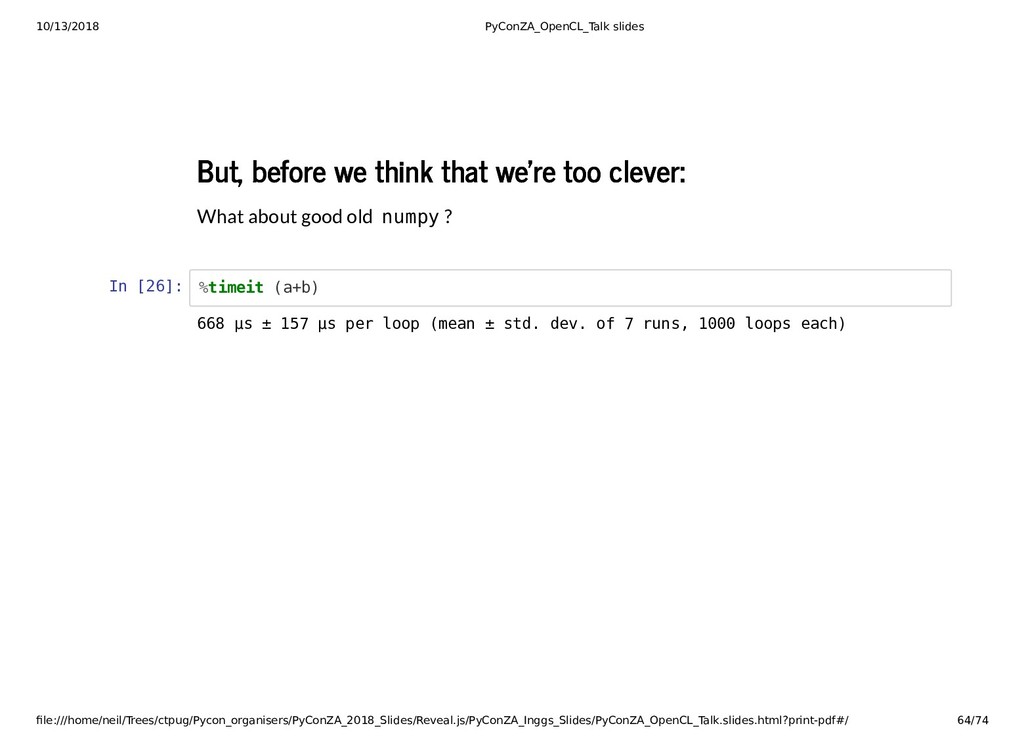{kind=link}
{kind=link}
![10/13/2018 PyConZA_OpenCL_Talk slides file:///home/neil/Trees/ctpug/Pycon_organisers/PyConZA_2018_Slides/Reveal.js/PyConZA_Inggs_Slides/PyConZA_OpenCL_Talk.slides.html?print-pdf#/ 66/74 In [29]: %timeit (a+b)**power Ca(t)veats](https://files.speakerdeck.com/presentations/20635ab8ce2f4b9a9dac98e3f83d7e2e/slide_65.jpg){kind=link}
{kind=link}
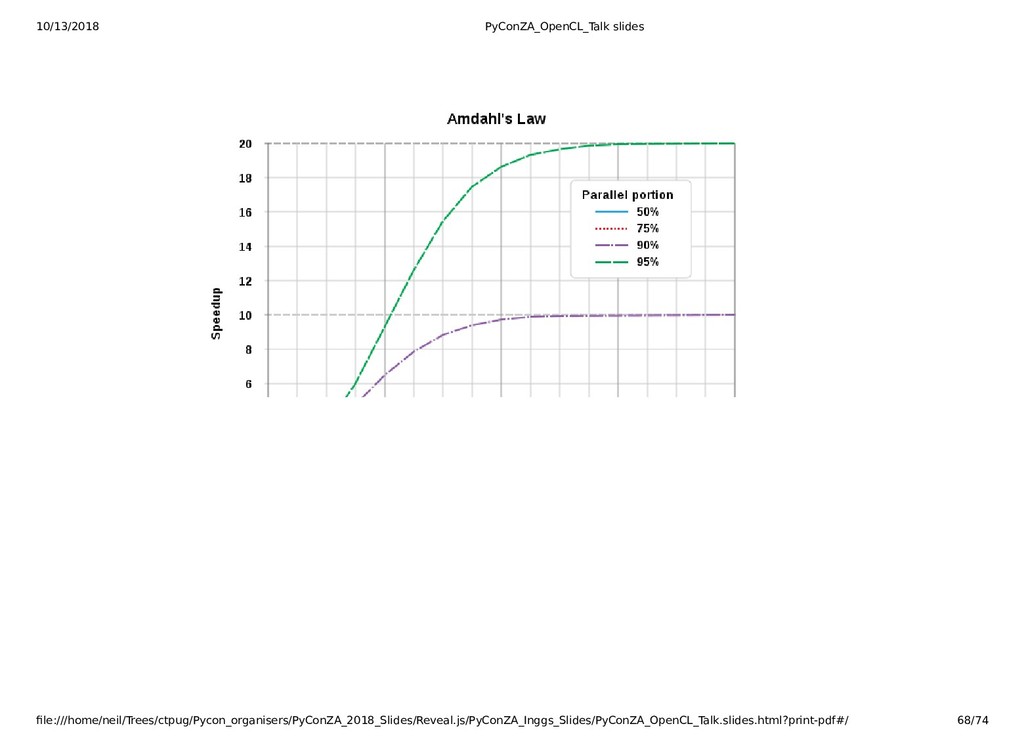{kind=link}
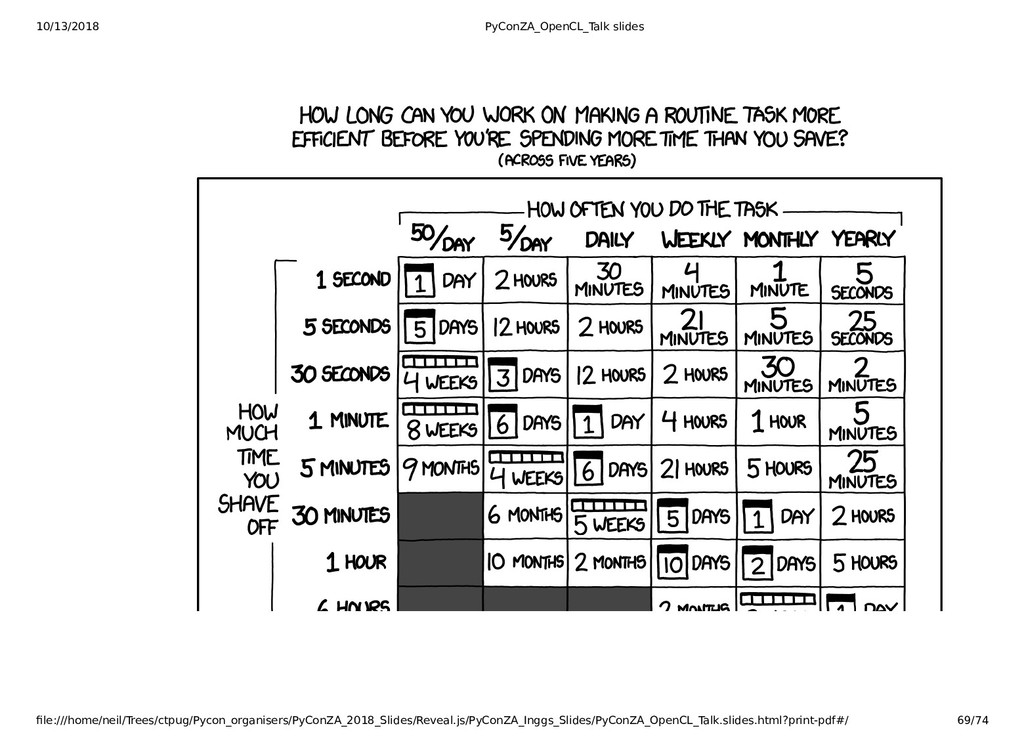{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}