Apache Kafka is great for building a large scale distributed data bus. Even a small cluster will happily accept and store thousands of messages per second, and make them available to consumers with low latency.
Kafka was chosen as the solution to our publish-subscribe infrastructure at Takealot.com. It supports our event-driven systems on the website, in the warehouses and in the office, as well as our analytics and machine learning projects.
This talk will
* introduce the basic Kafka principles that make things work,
* outline how Kafka fits in with the rest of our architecture,
* cover some of the practicalities of building Python-based Kafka services,
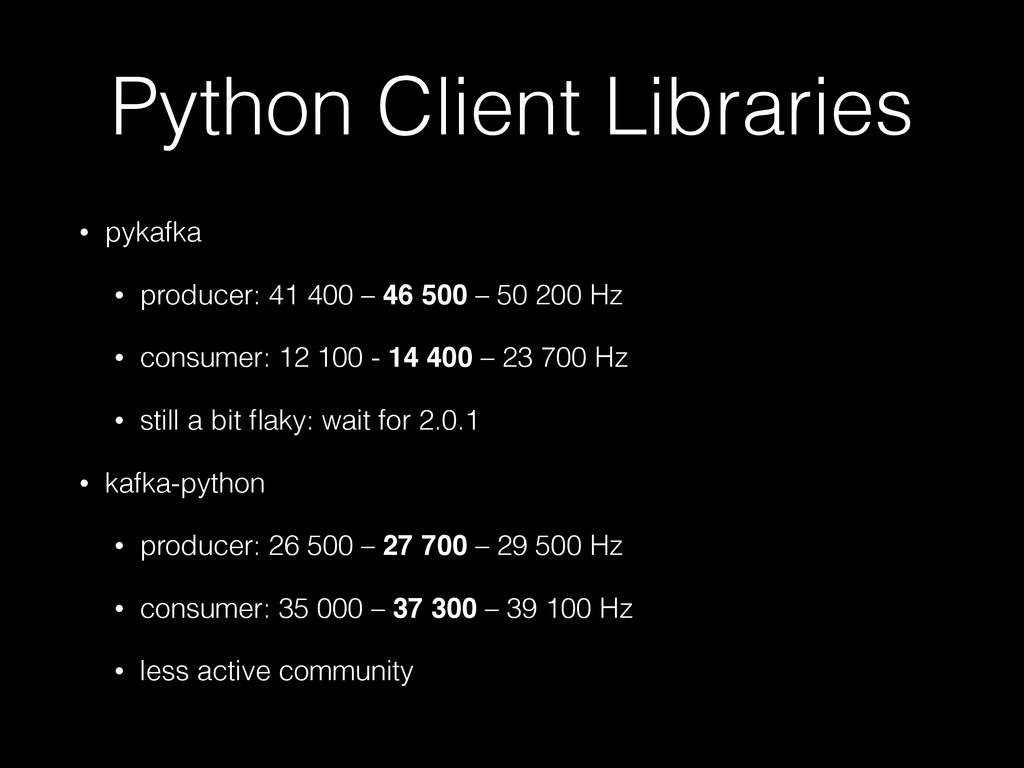
* compare the two main Python libraries for Kafka, namely kafka-python (https://github.com/mumrah/kafka-python) and pykafka (https://github.com/Parsely/pykafka),
* demonstrate some practical applications at Takealot.com.
Join in if you are interested in scalable distributed infrastructure.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}