40)) (wedding, ((greek, 5), 40)) (evil, ((dead, 3), 16)) (offers, (combination, 1, 20)) (home, (alabama, 5, 40)) (greek, (wedding, 5, 40)) (dead, (evil, 3, 16)) (offers, 81) (home, 36) (greek, 24) (dead, 20) (String, Int) (String, ((String, Int), Int)) (String, (String, Int, Int)) (offers, ((combination, 1, 20), 81)) (home, ((alabama, 5, 40), 36)) (greek, ((wedding, 5, 40), 24)) (dead, ((evil, 3, 16), 20)) (String,((String, Int, Int), Int)) join (combination, offers, 1, 20, 81) (alabama, home, 5, 40, 36) (wedding, greek, 5, 40, 24) (evil, dead, 3, 16, 20) (String, String, Int, Int, Int) map =(a, b, [a, b]の頻度, aの頻度, bの頻度) 前ページ 最後 pmiSrc bFreq
{kind=link}
{kind=link}
{kind=link}
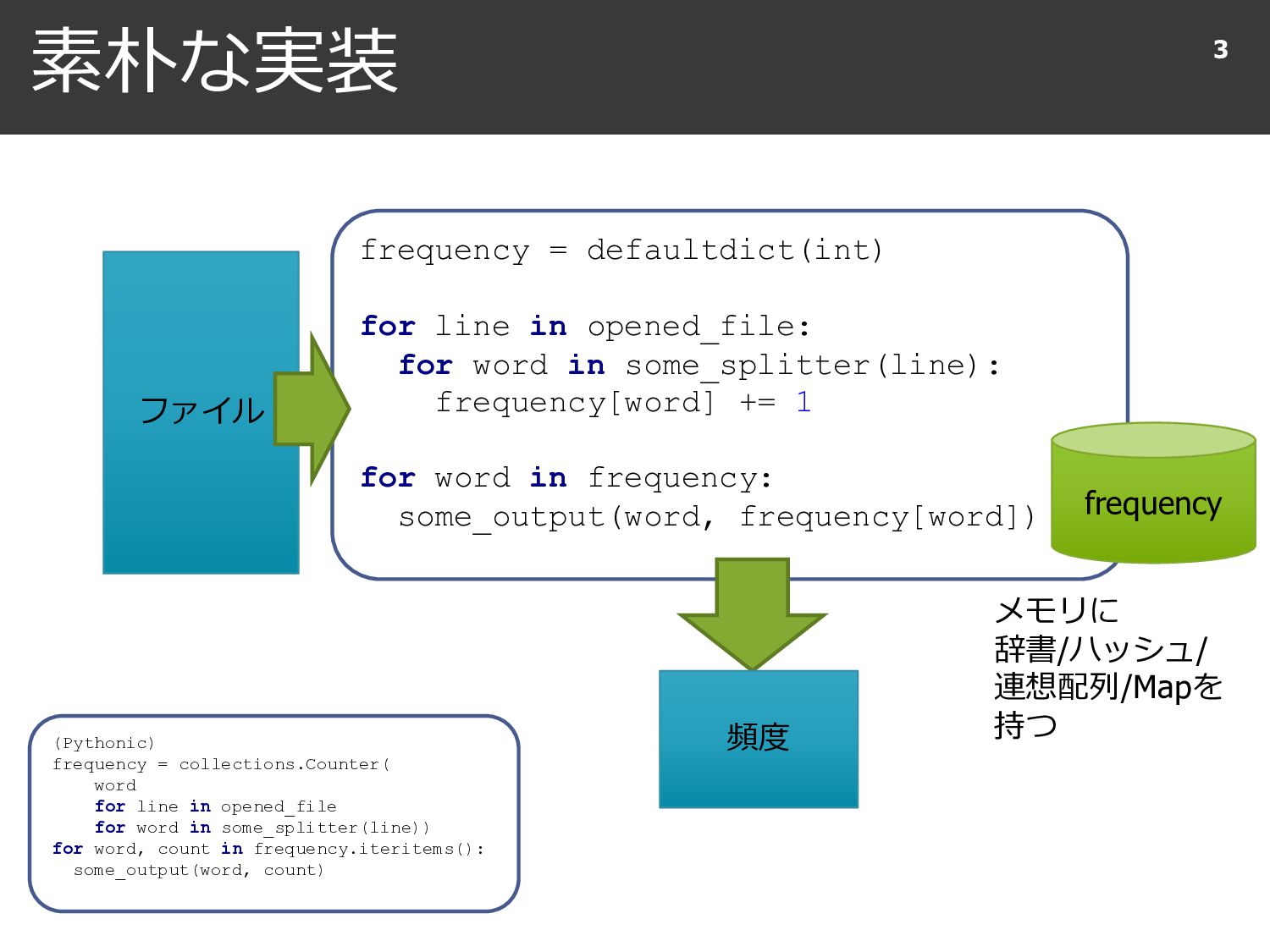{kind=link}
{kind=link}
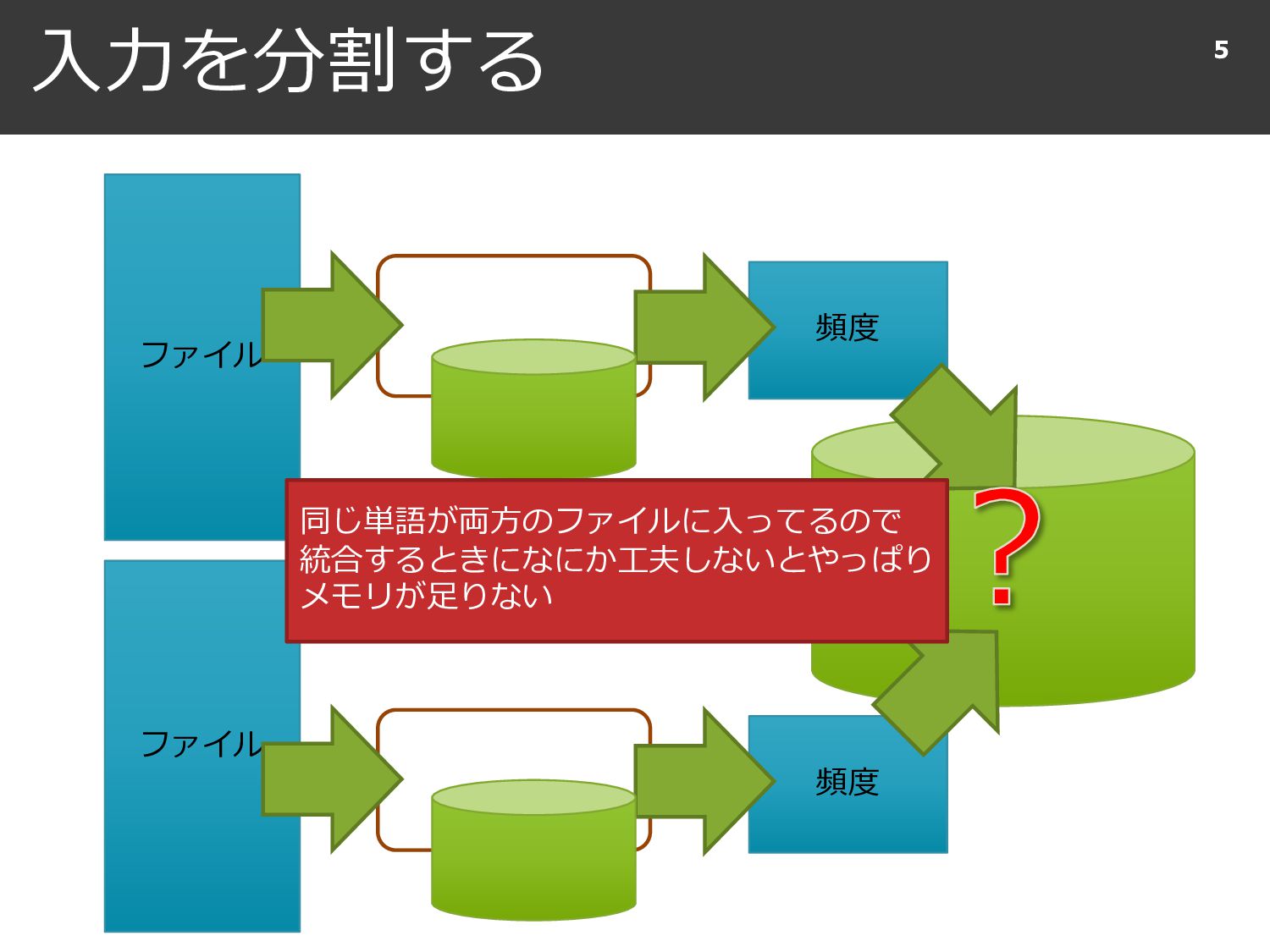{kind=link}
{kind=link}
![組み合わせる 7 f = [defaultdict(int) for i in range(2)] for](https://files.speakerdeck.com/presentations/ba5fd7c3401e4970a773ecc5fcce2cfa/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
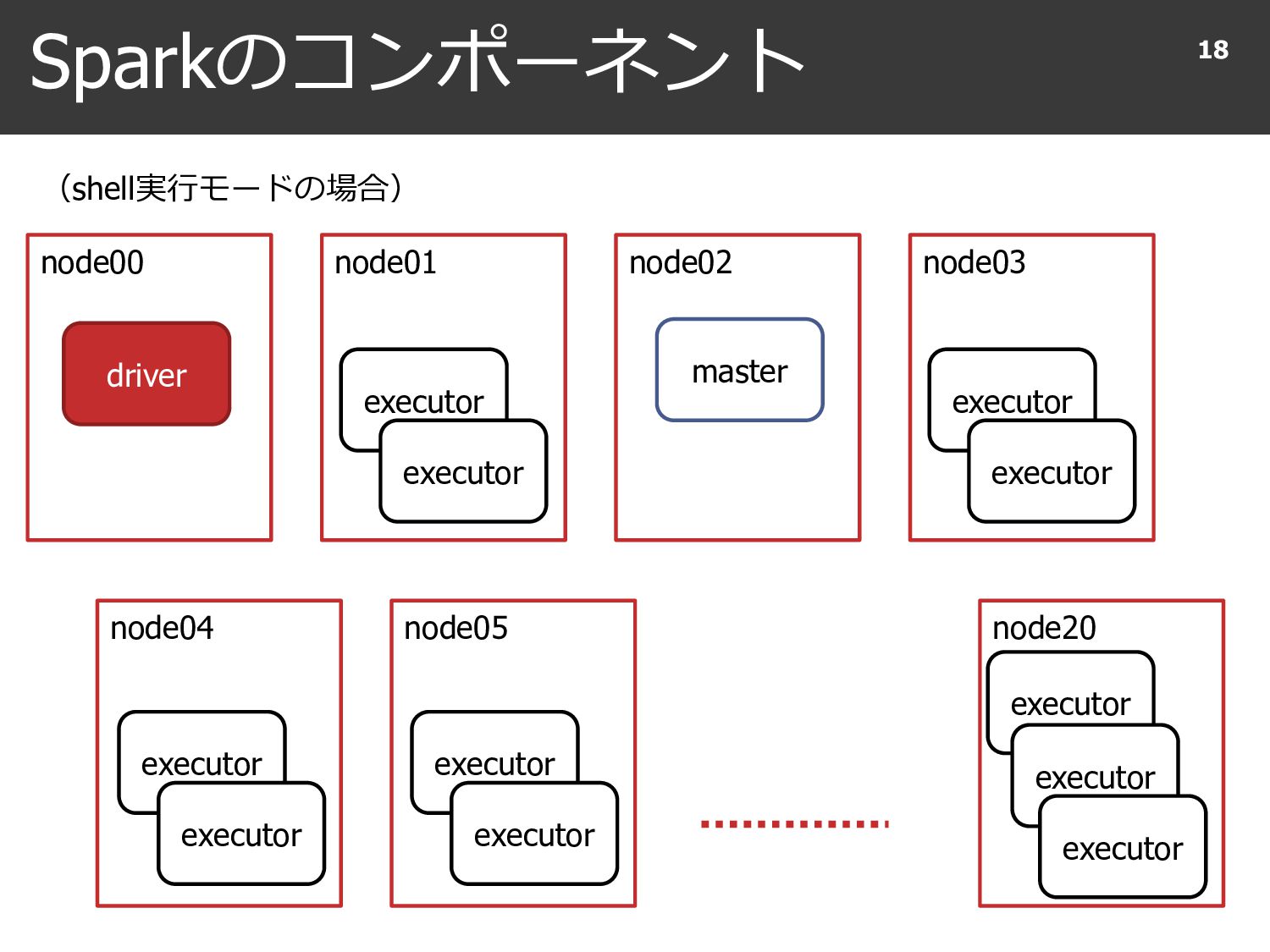{kind=link}
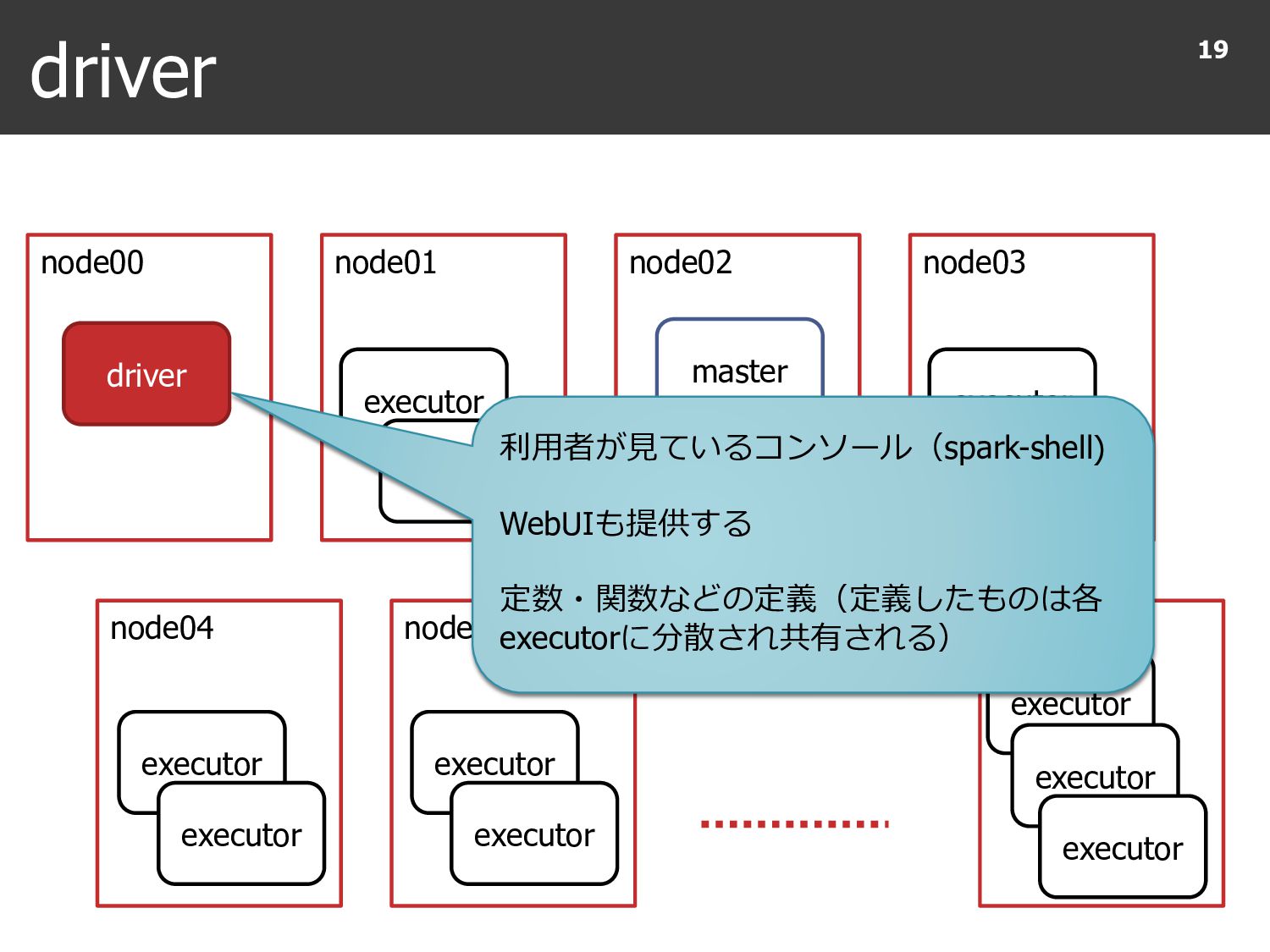{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
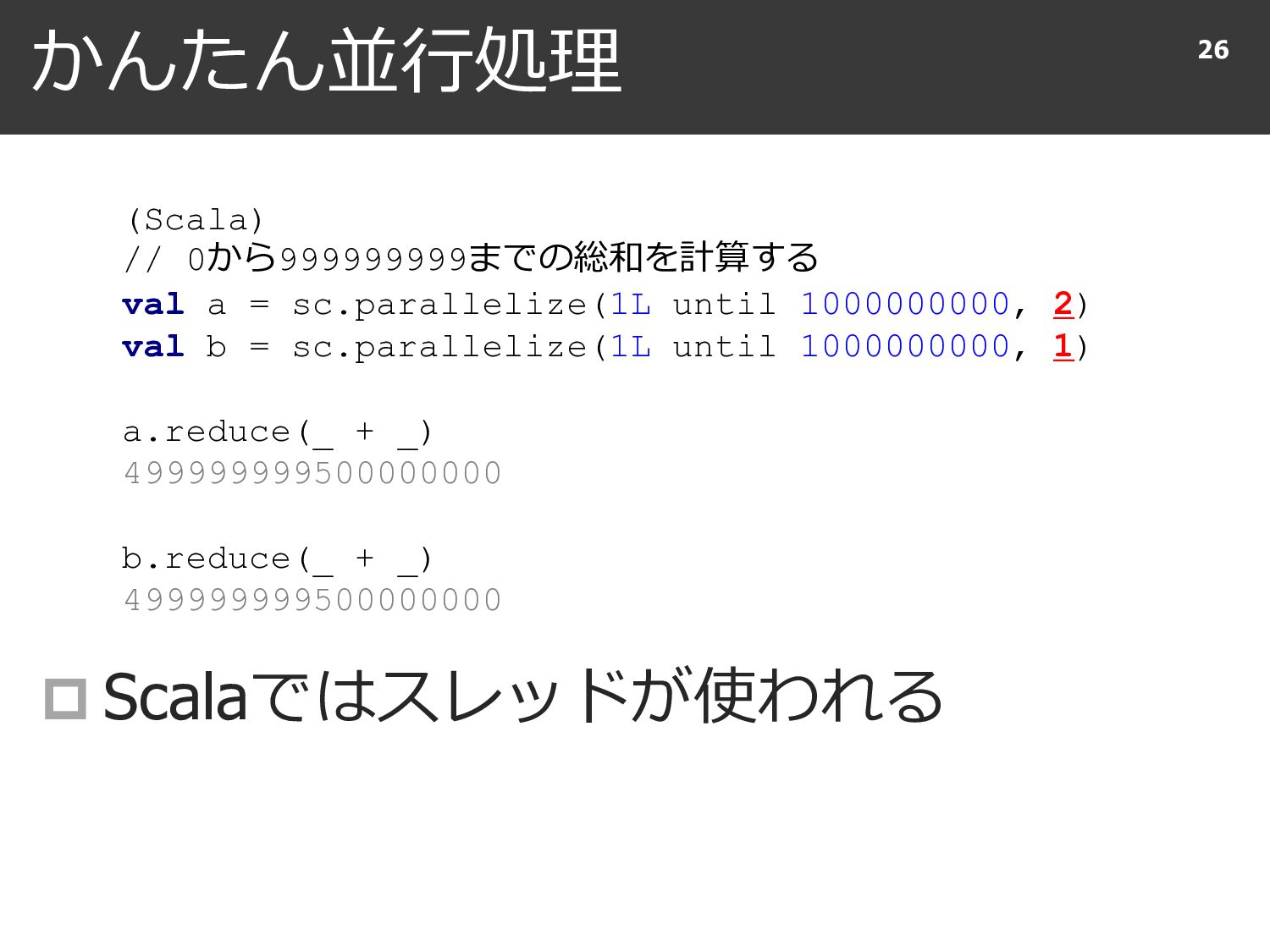{kind=link}
{kind=link}
{kind=link}
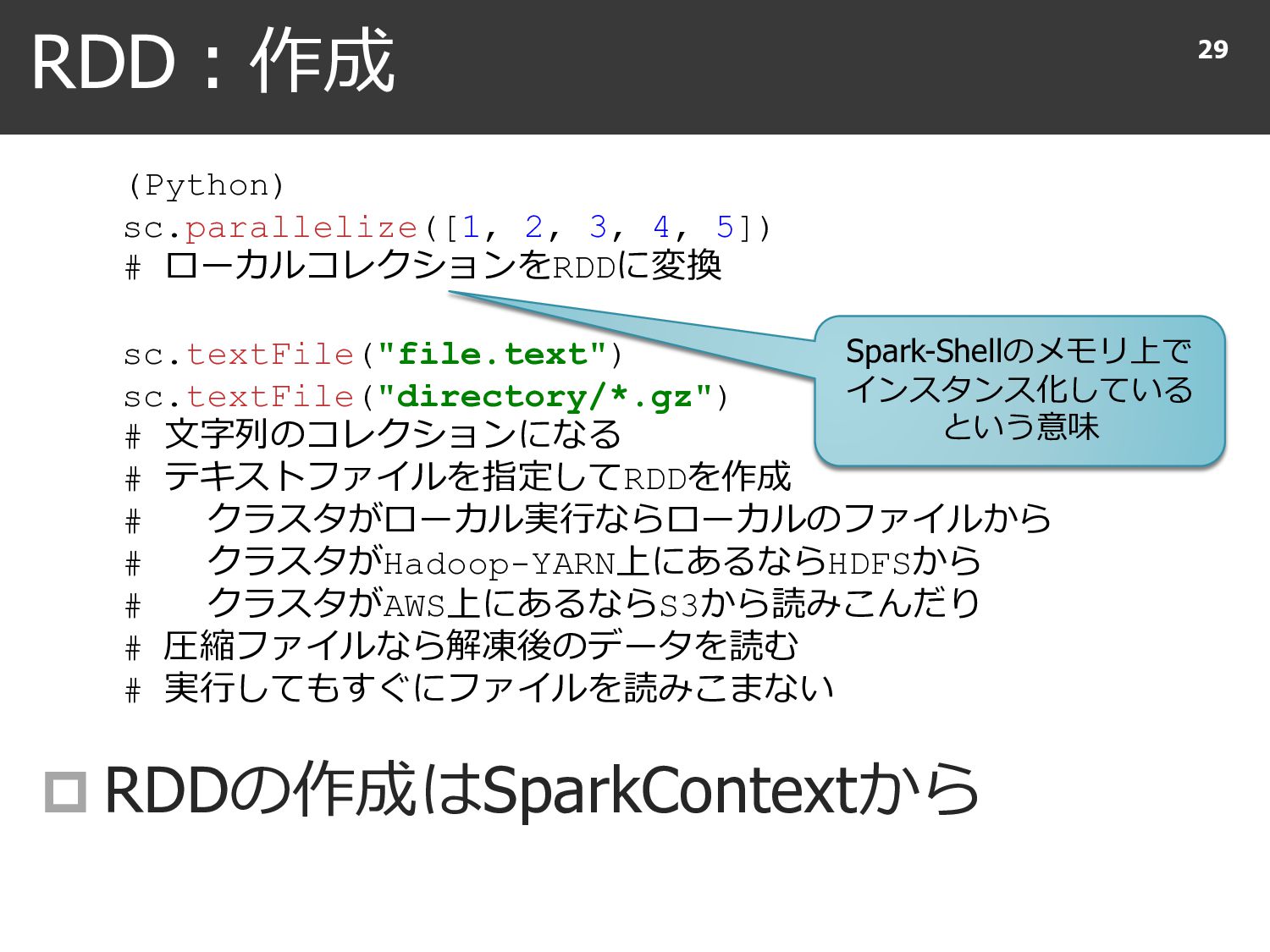{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
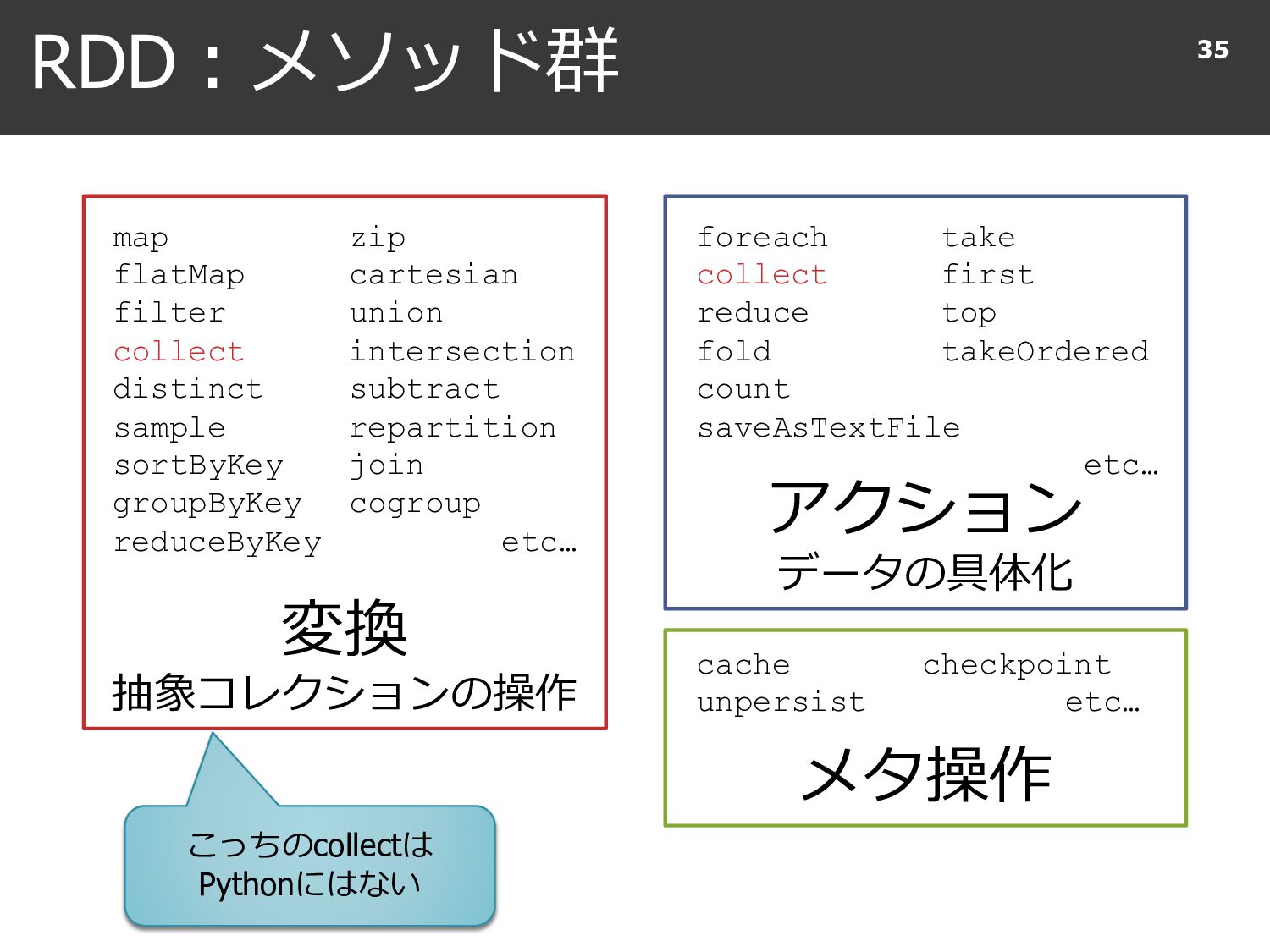{kind=link}
{kind=link}
{kind=link}
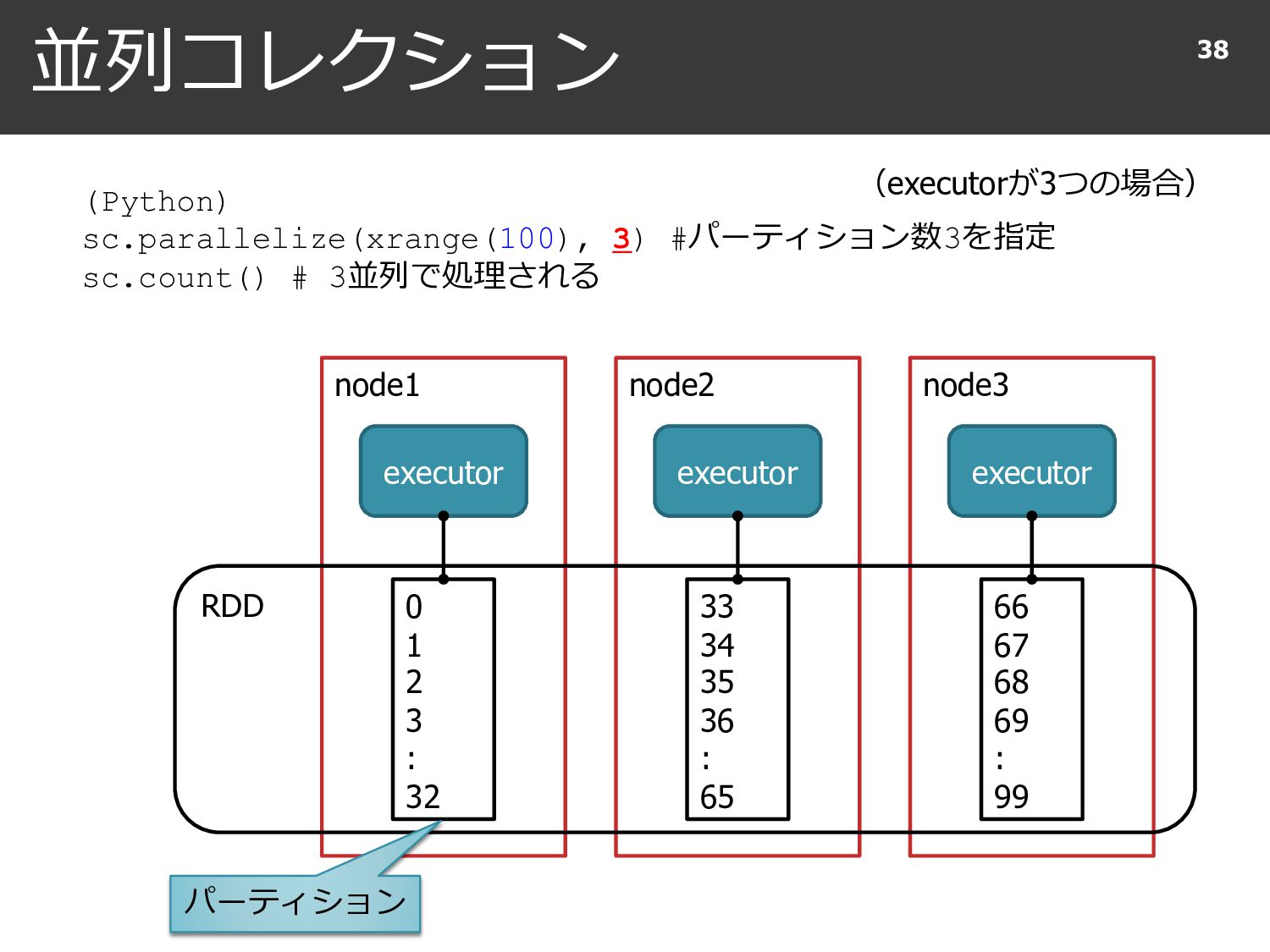{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
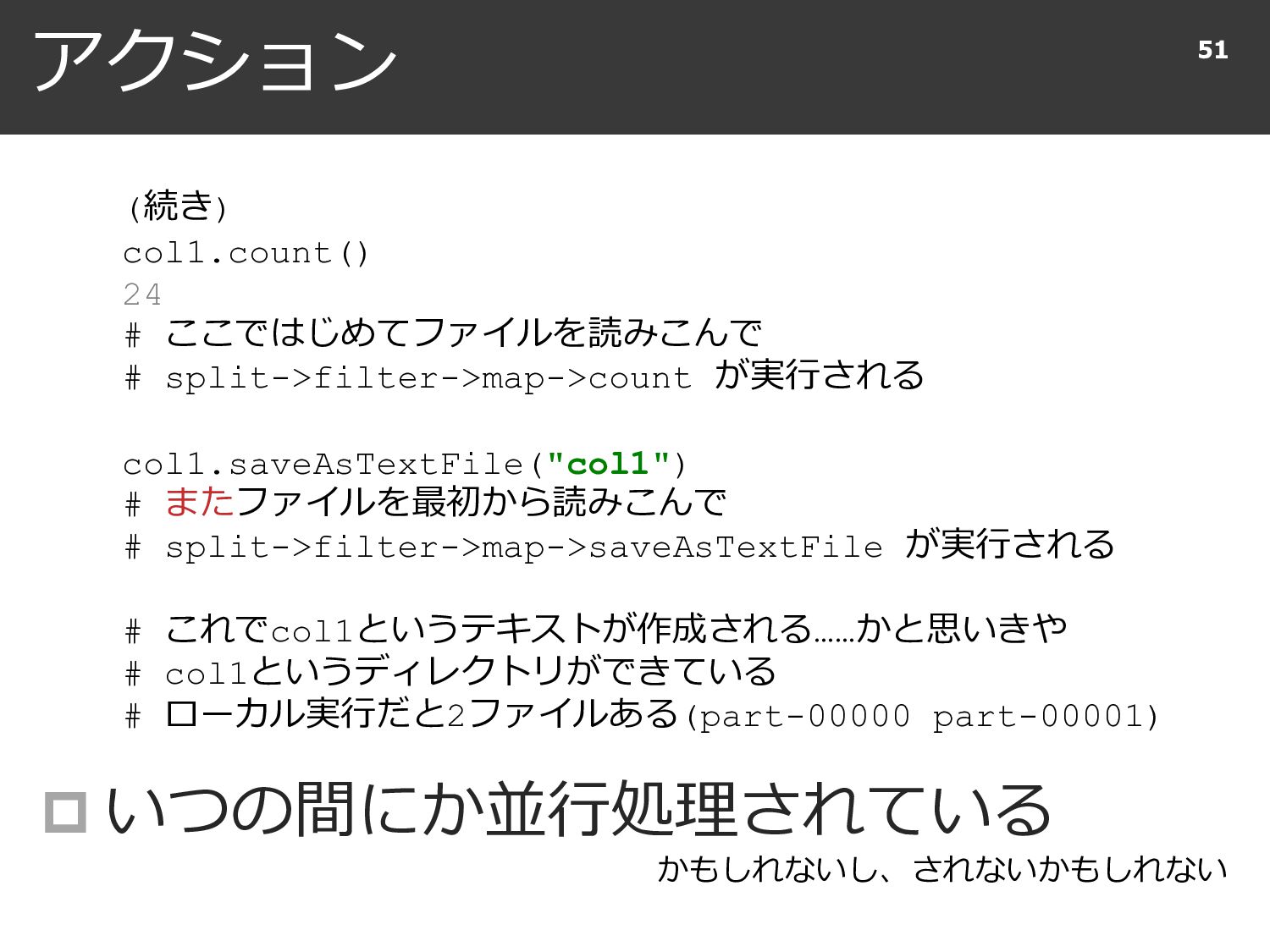{kind=link}
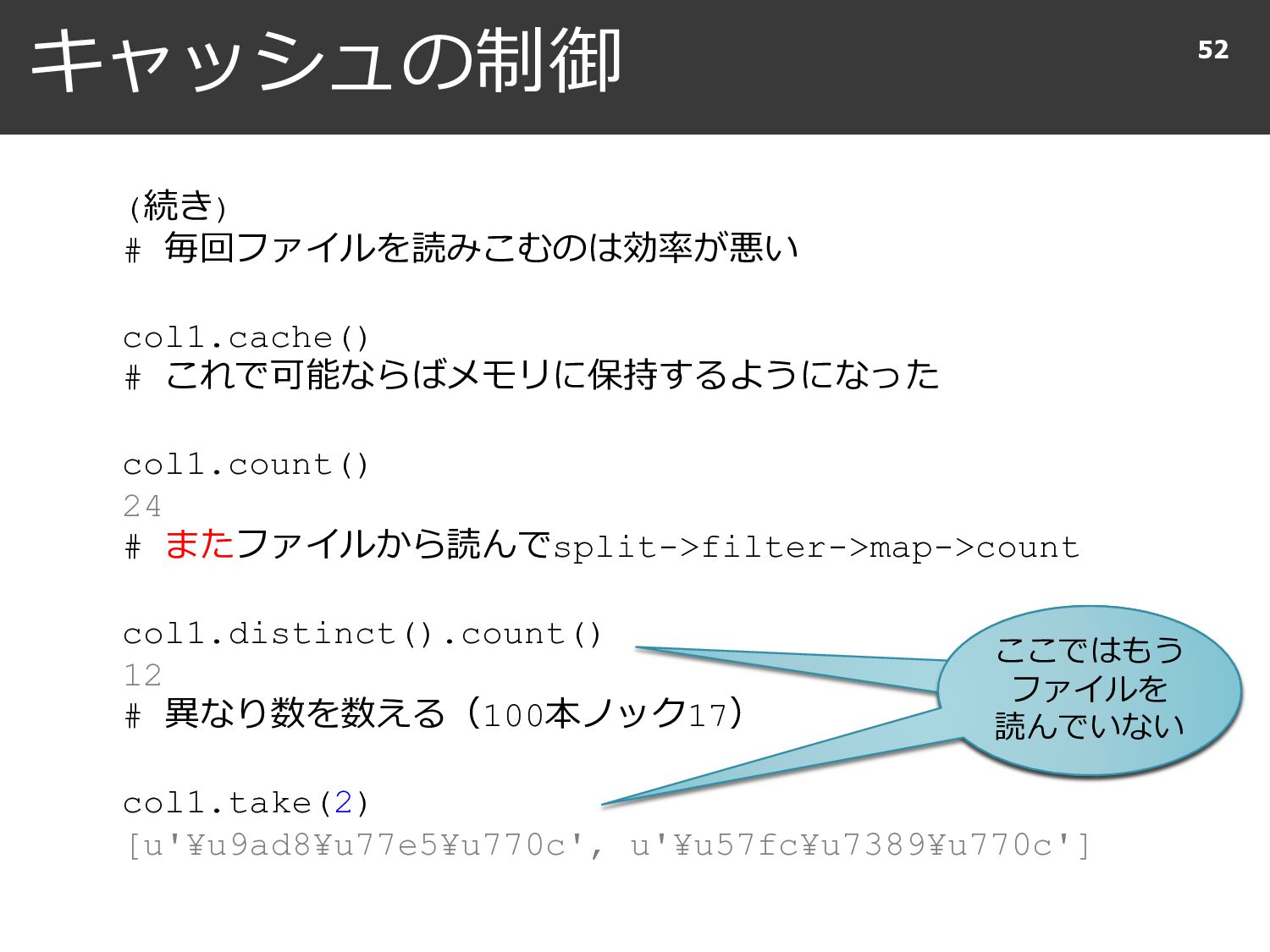{kind=link}
![もうちょっと変換 53 (続き) # 2カラム⽬でソート sorted_by_col2 = tuples.sortBy(lambda x: x[1])](https://files.speakerdeck.com/presentations/ba5fd7c3401e4970a773ecc5fcce2cfa/slide_53.jpg){kind=link}
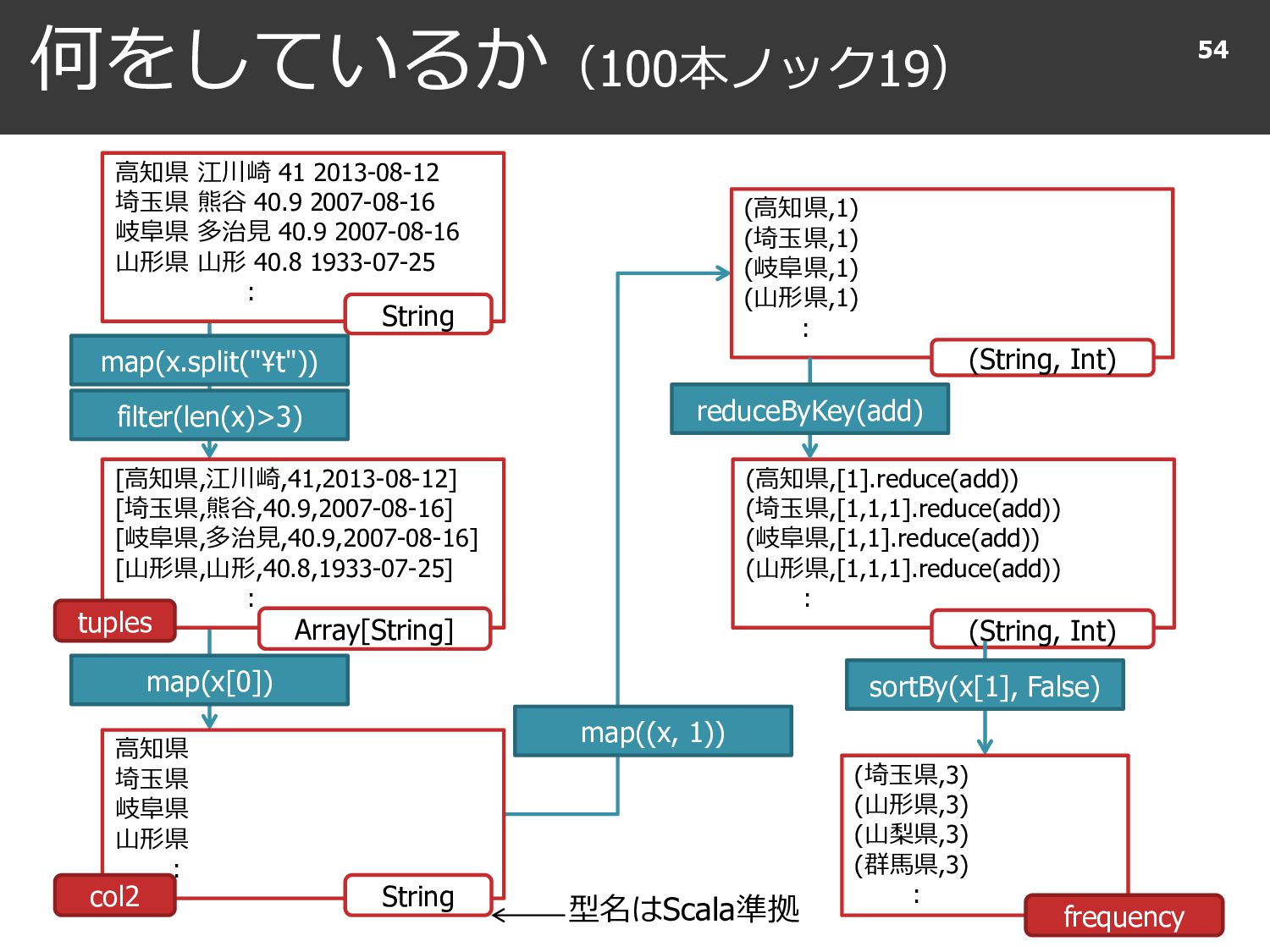{kind=link}
{kind=link}
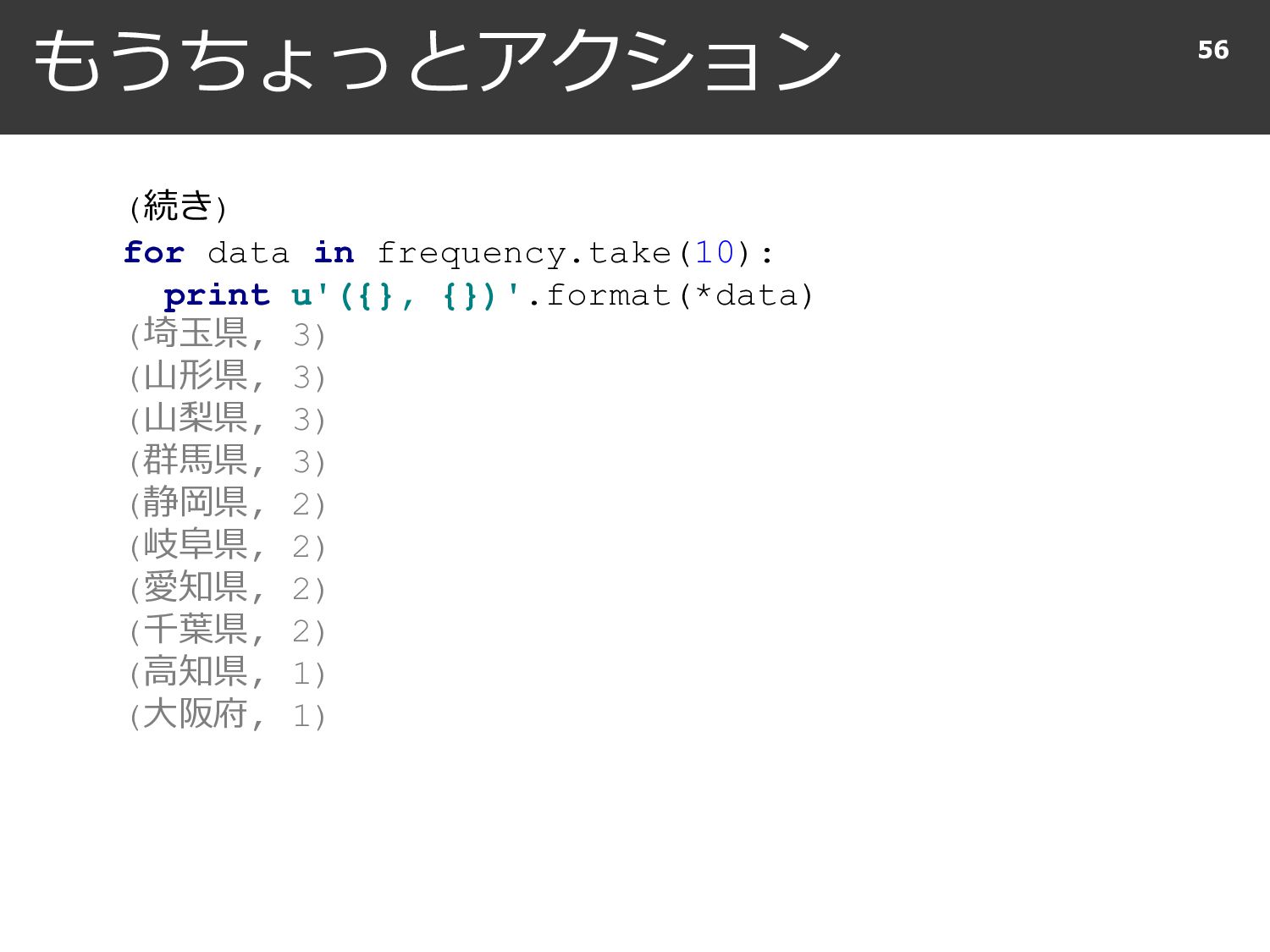{kind=link}
{kind=link}
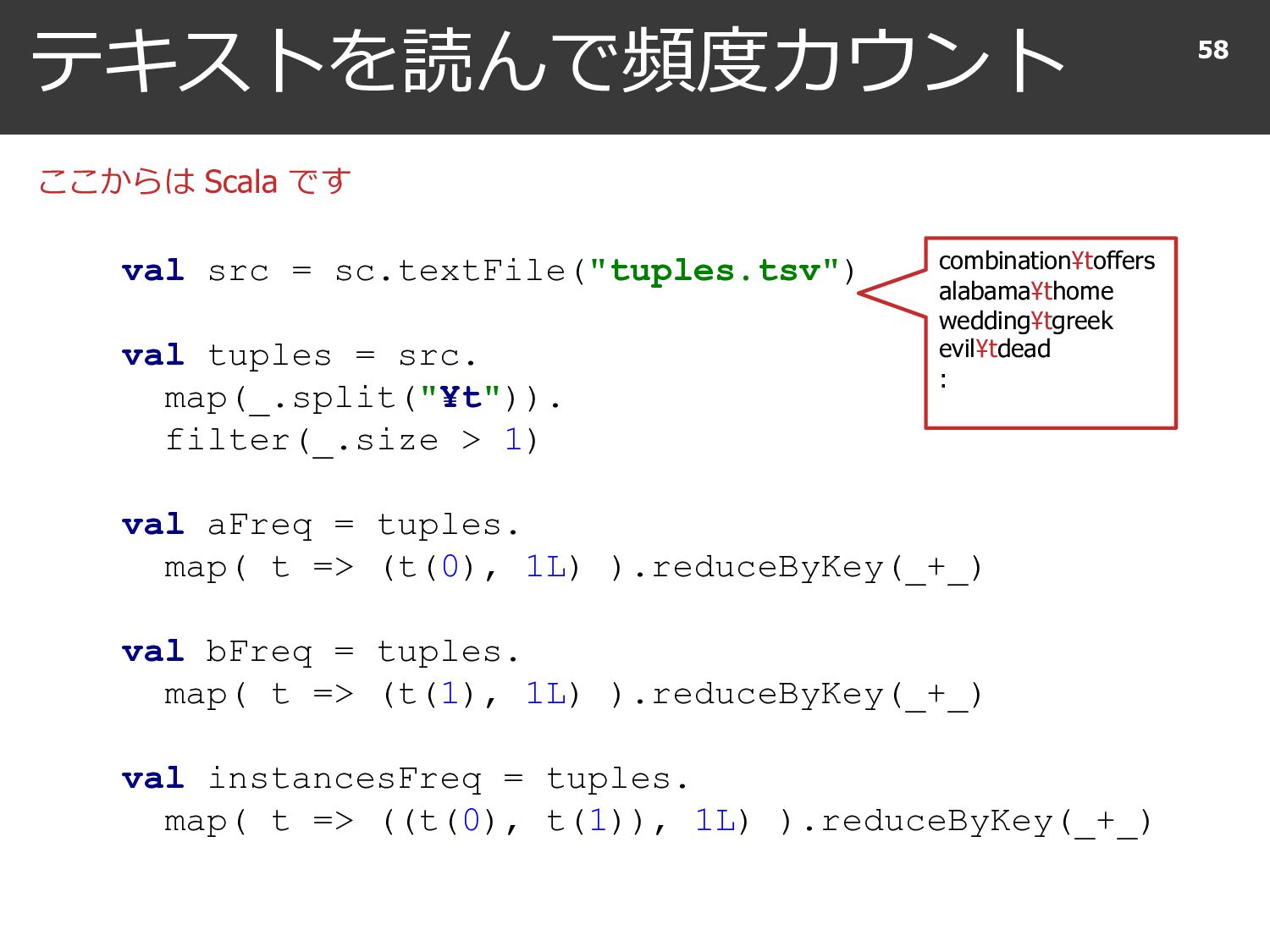{kind=link}
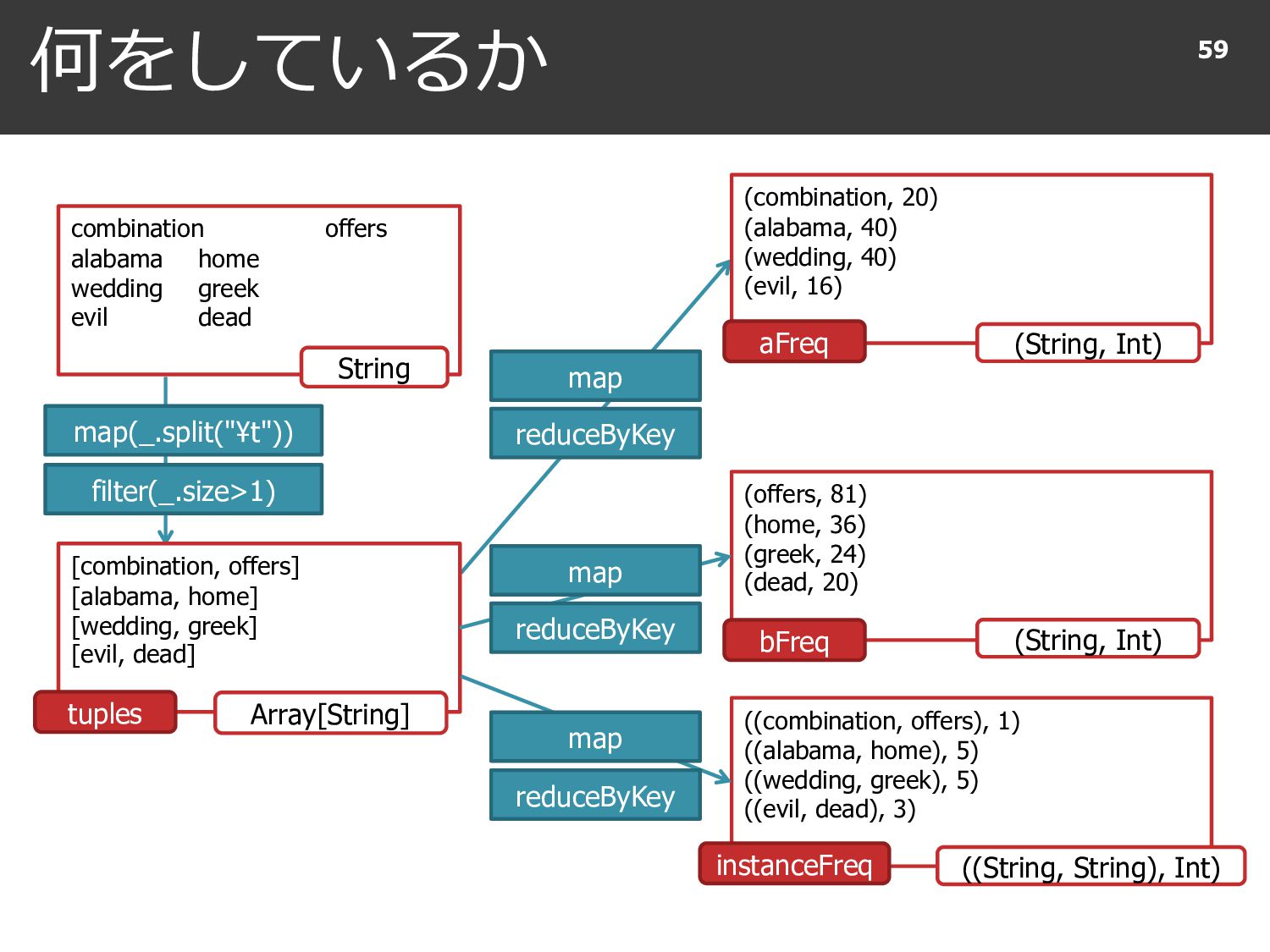{kind=link}
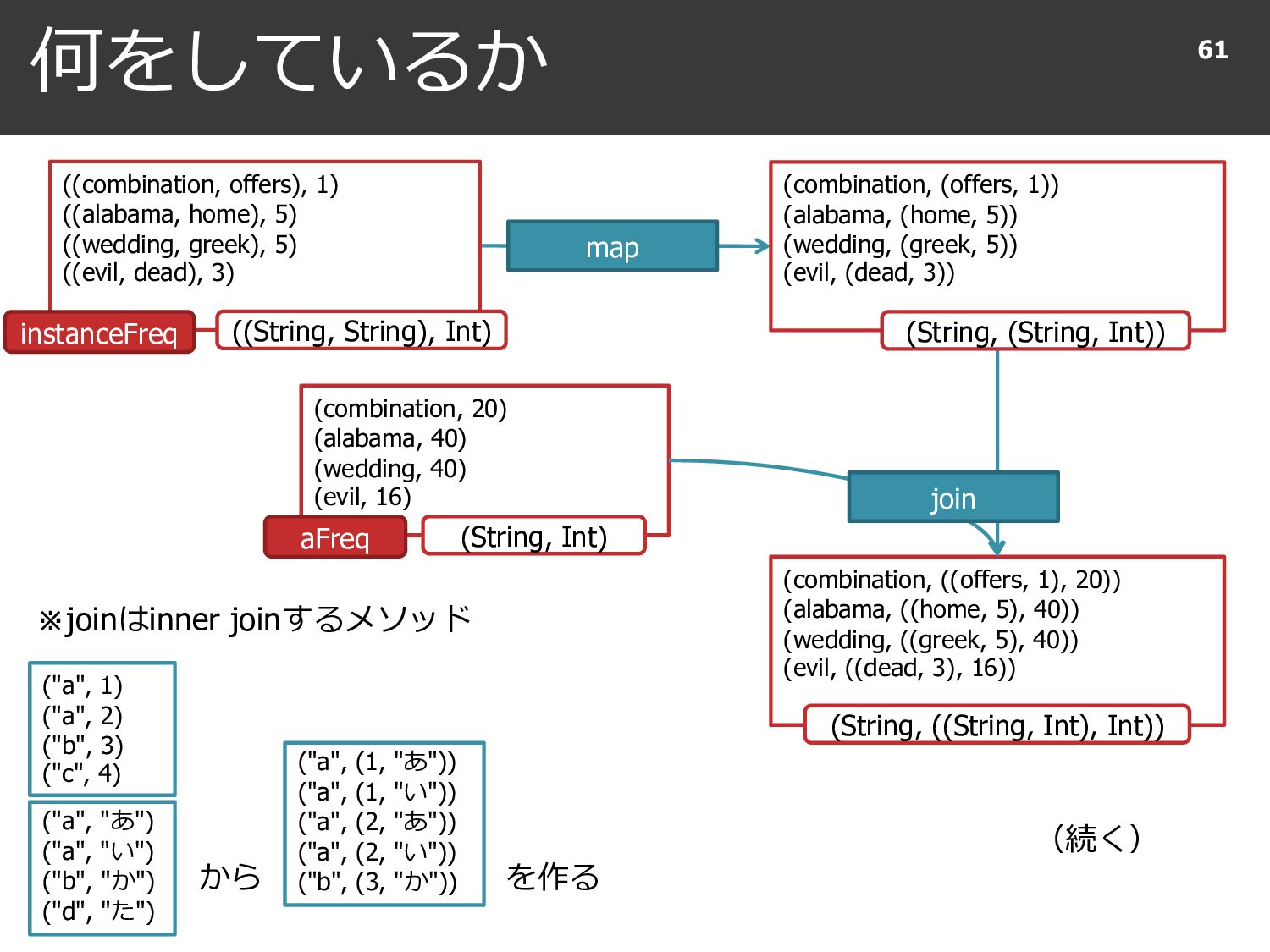
{kind=link}
{kind=link}
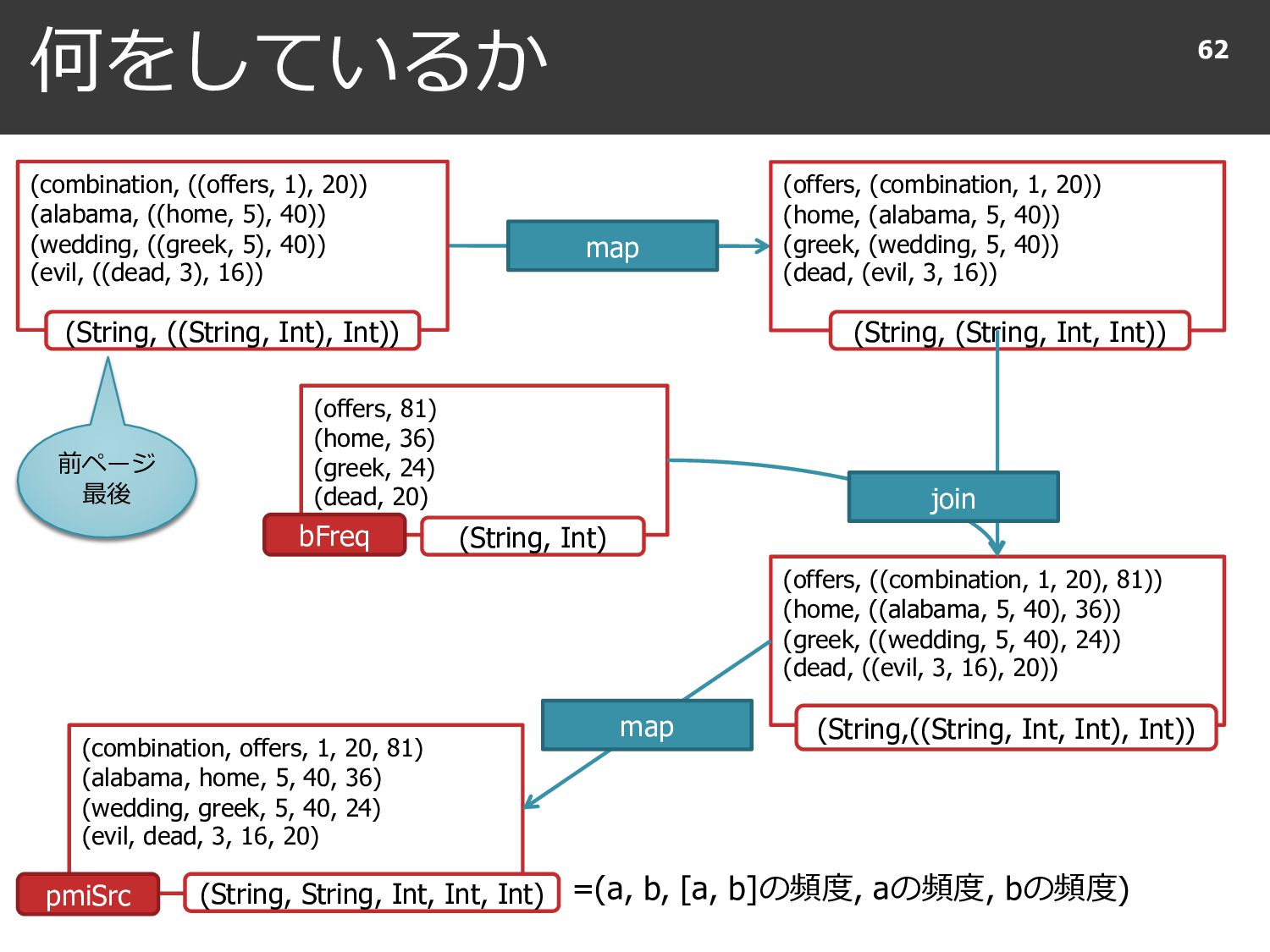{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
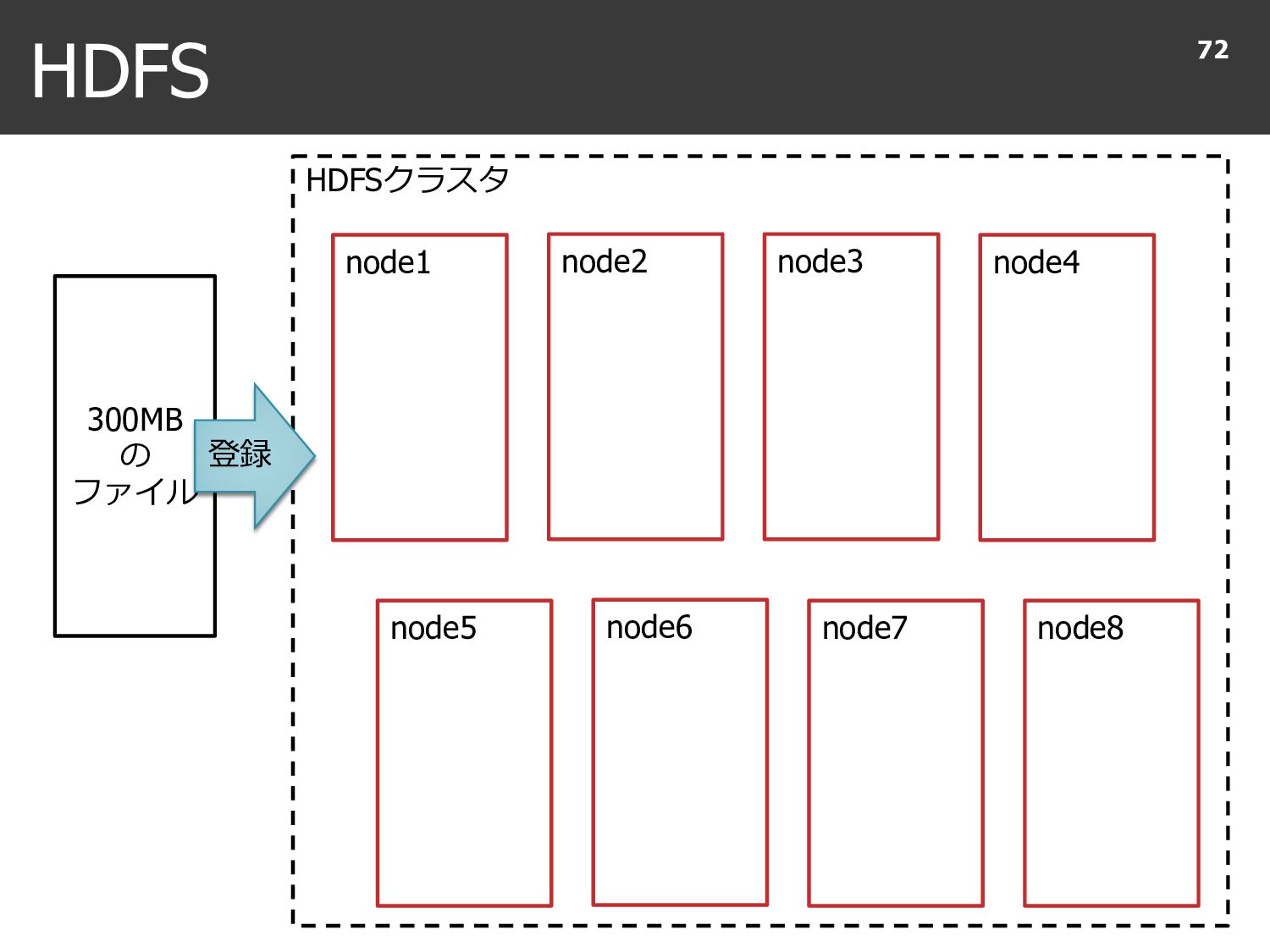{kind=link}
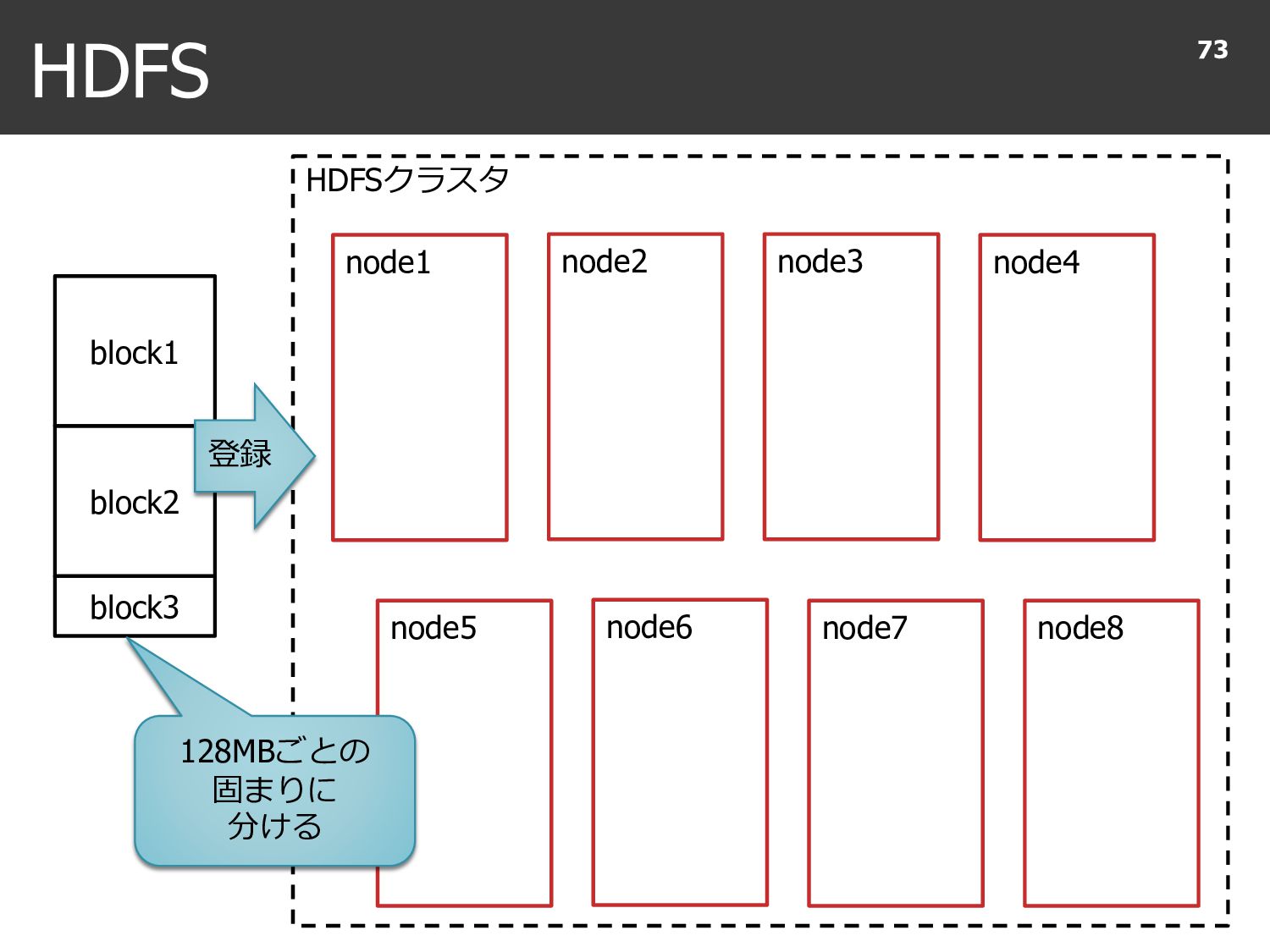{kind=link}
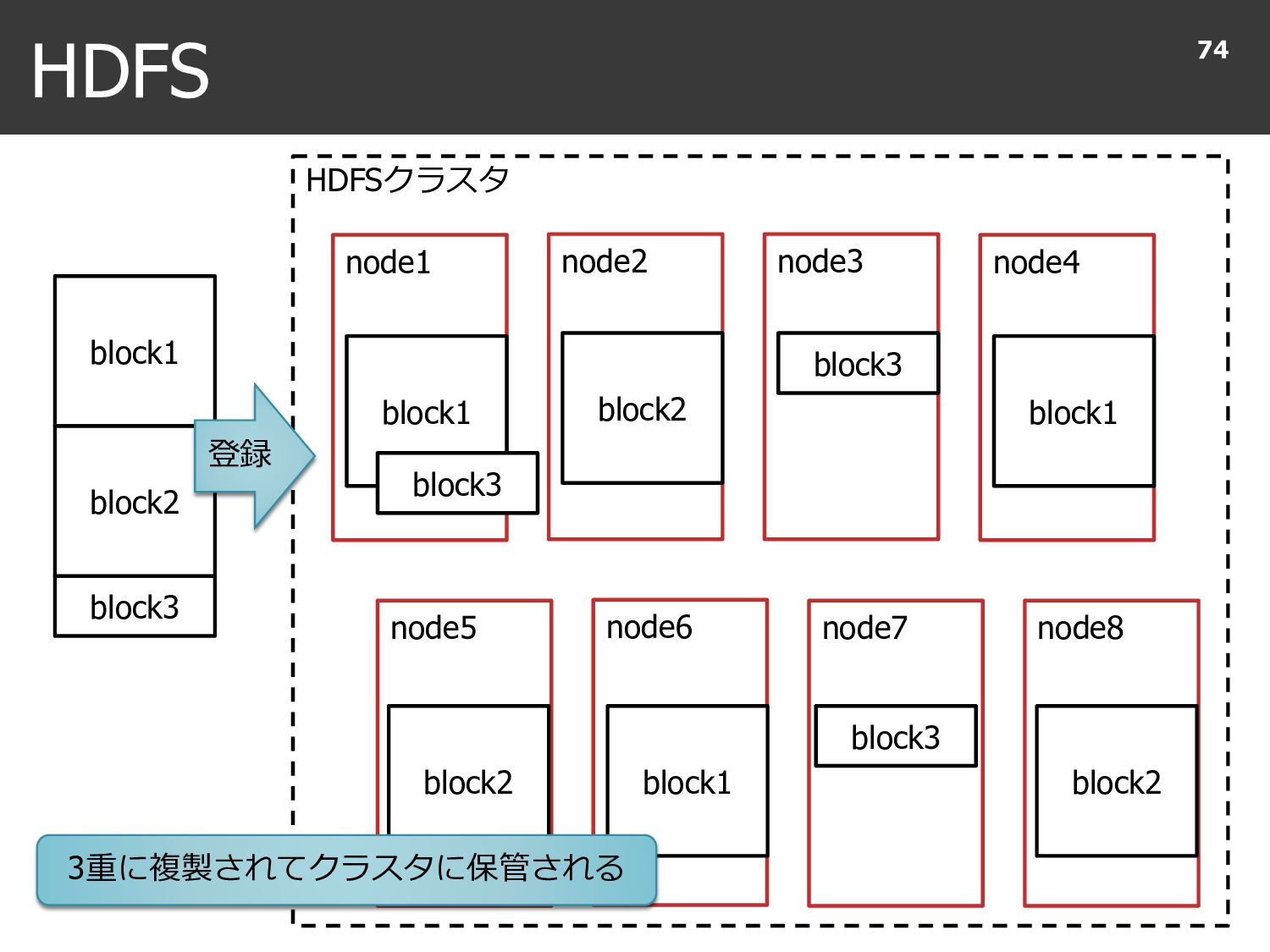{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
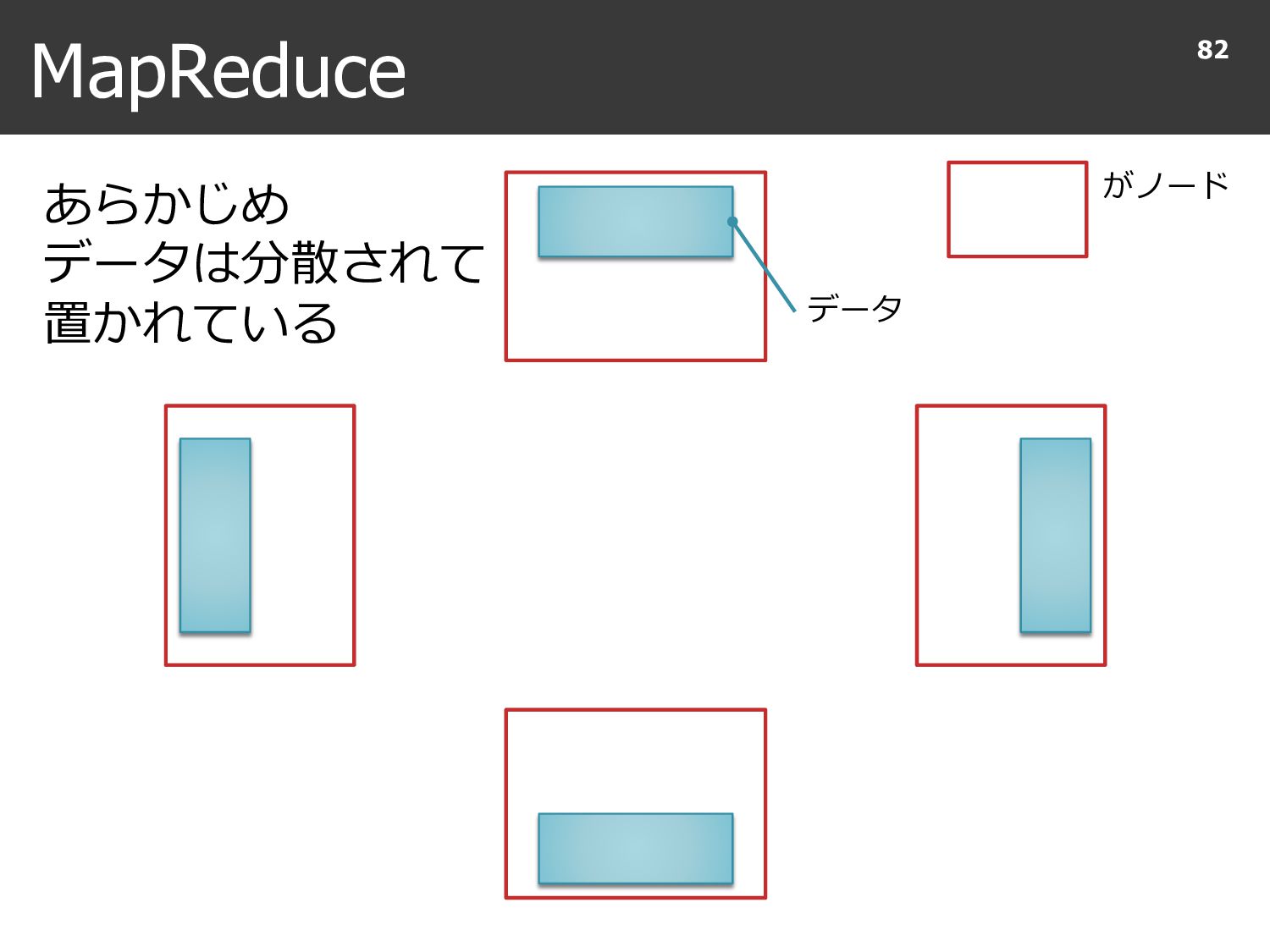{kind=link}
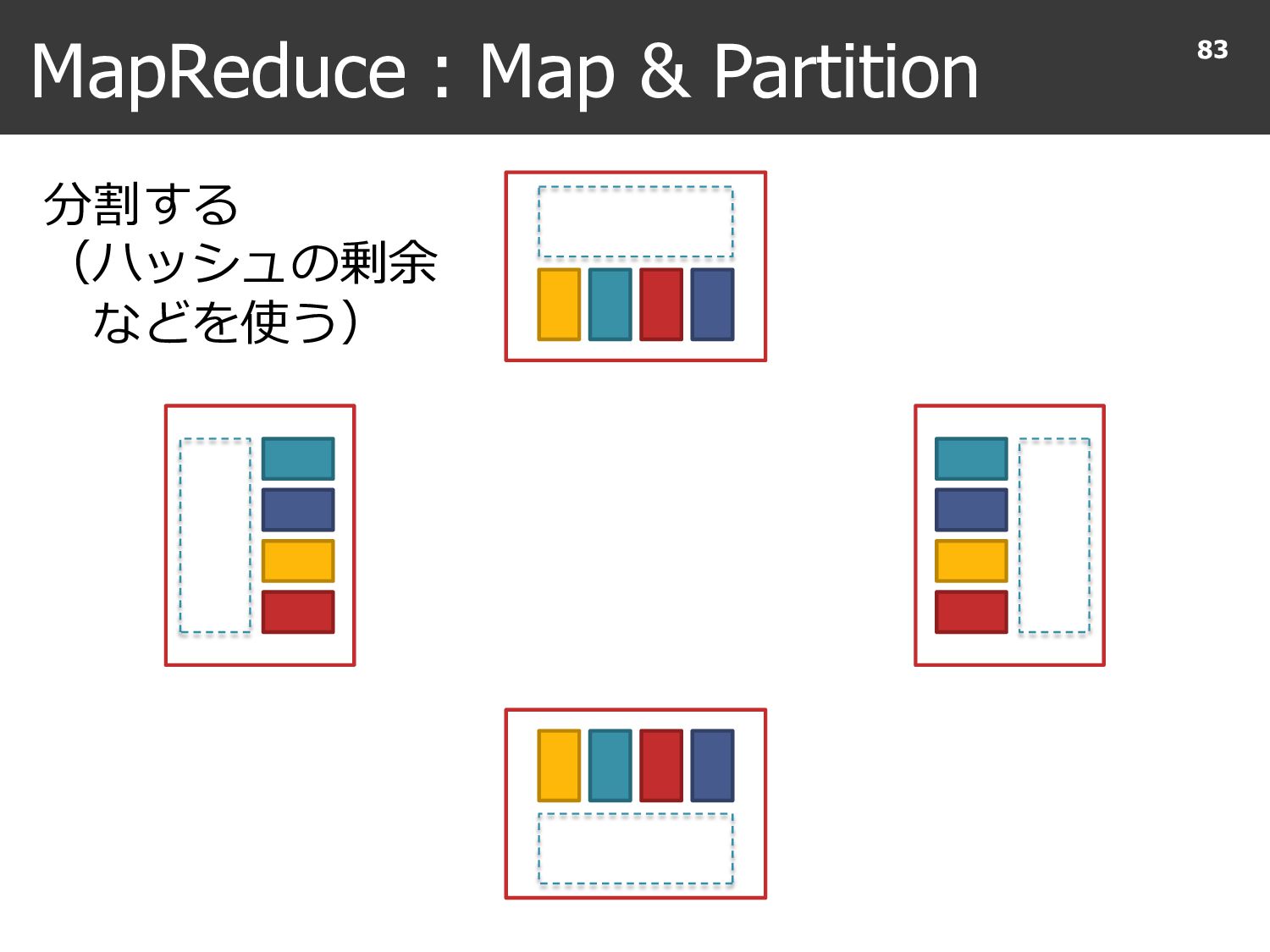{kind=link}
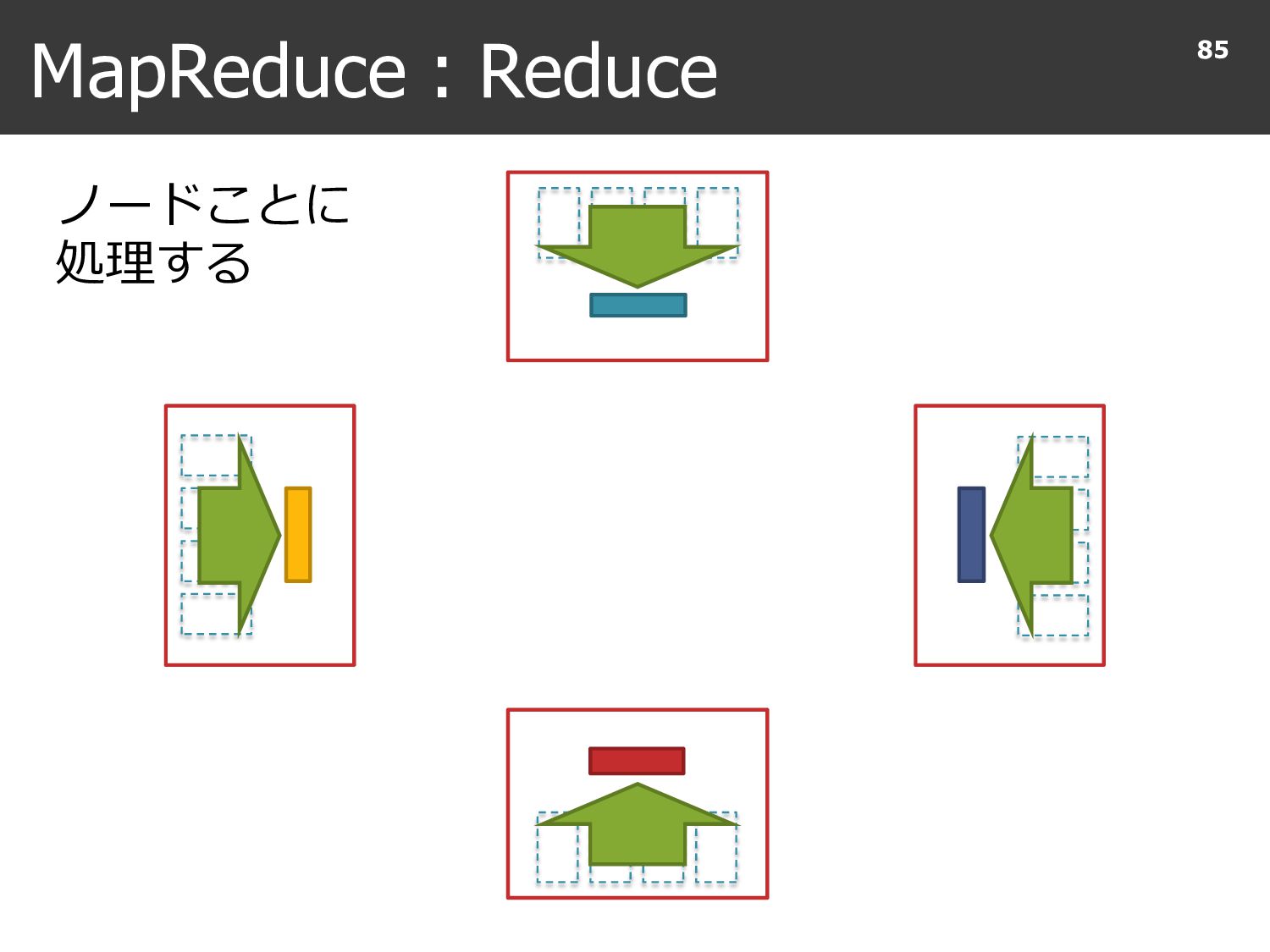
{kind=link}
{kind=link}
{kind=link}
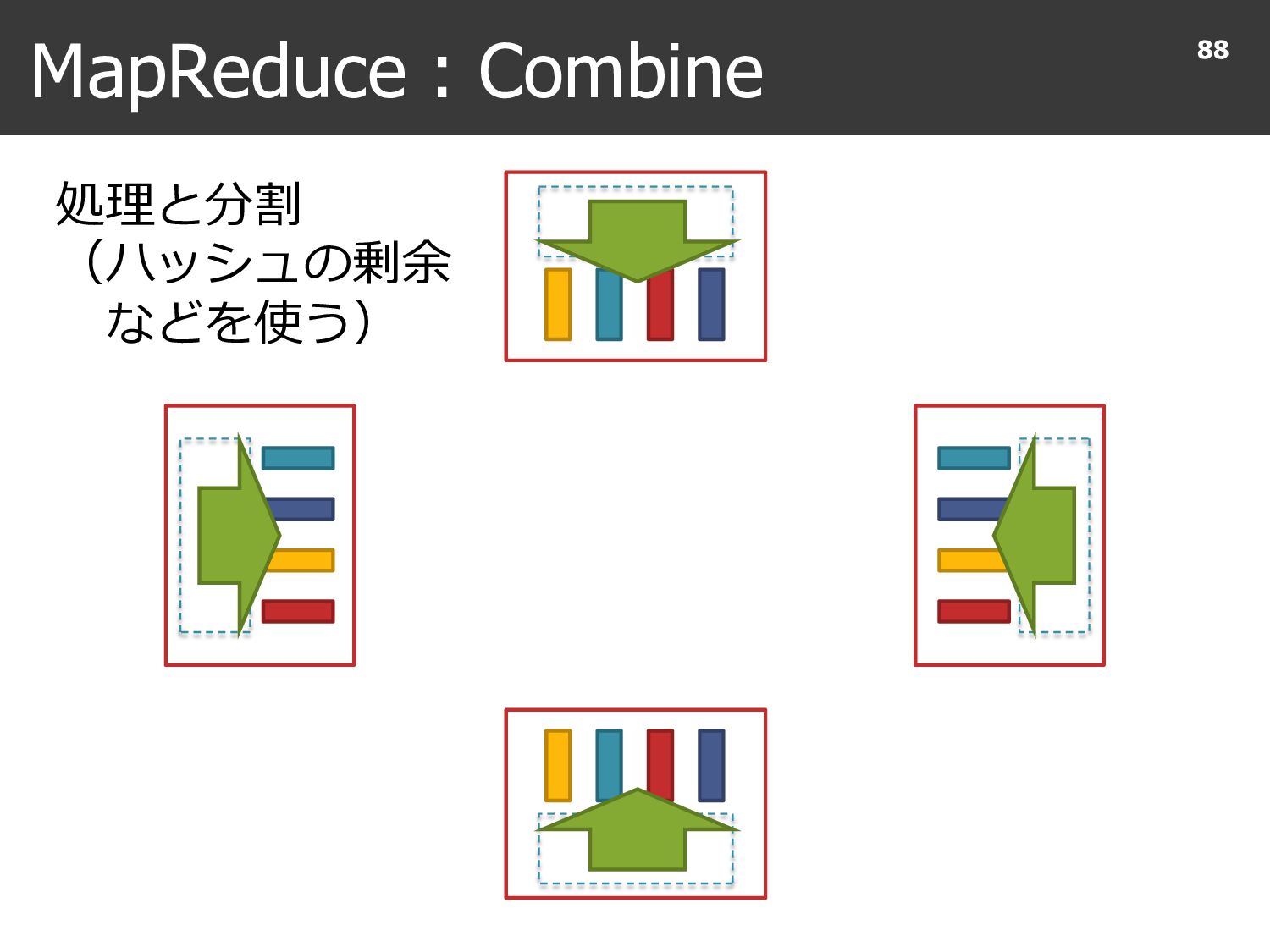
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}