Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
[論文解説] mPLUG-DocOwl2: High-resolution Compressi...
Search
Reon Kajikawa
November 30, 2025
21
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
[論文解説] mPLUG-DocOwl2: High-resolution Compressing for OCR-free Multi-page Document Understanding
複数の文書画像を効率よく扱うMLLM(DocOwl2)を紹介する
Reon Kajikawa
November 30, 2025
More Decks by Reon Kajikawa
See All by Reon Kajikawa
[論文解説] Not All Negatives are Equal: Label Aware Contrastive Loss for Fine grained Text Classification
reon131
0
25
[論文解説] Disentangled Learning with Synthetic Parallel Data for Text Style Transfer
reon131
0
19
[論文解説] Large Language Models can Contrastively Refine their Generation for Better Sentence Representation Learning
reon131
0
26
[論文解説] SentiCSE: A Sentiment-aware Contrastive Sentence Embedding Framework with Sentiment-guided Textual Similarity
reon131
0
39
[論文解説] Text Embeddings Reveal (Almost) As Much As Text
reon131
0
150
[論文解説] OssCSE: Overcoming Surface Structure Bias in Contrastive Learning for Unsupervised Sentence Embedding
reon131
0
18
[論文解説] Sentence Representations via Gaussian Embedding
reon131
0
130
[論文解説] Unsupervised Learning of Style-sensitive Word Vectors
reon131
0
31
[論文解説] One Embedder, Any Task: Instruction-Finetuned Text Embeddings
reon131
0
53
Featured
See All Featured
How to build a perfect <img>
jonoalderson
1
5.8k
Performance Is Good for Brains [We Love Speed 2024]
tammyeverts
12
1.7k
First, design no harm
axbom
PRO
2
1.2k
What’s in a name? Adding method to the madness
productmarketing
PRO
24
4.1k
Dominate Local Search Results - an insider guide to GBP, reviews, and Local SEO
greggifford
PRO
0
210
Build your cross-platform service in a week with App Engine
jlugia
234
18k
Balancing Empowerment & Direction
lara
6
1.2k
Lightning talk: Run Django tests with GitHub Actions
sabderemane
0
220
Accessibility Awareness
sabderemane
1
150
Writing Fast Ruby
sferik
630
63k
Improving Core Web Vitals using Speculation Rules API
sergeychernyshev
21
1.5k
The #1 spot is gone: here's how to win anyway
tamaranovitovic
3
1.1k
Transcript
mPLUG-DocOwl2: High-resolution Compressing for OCR-free Multi-page Document Understanding aAlibaba Group,
Renmin University of China ACL 2025 URL:https://aclanthology.org/2025.acl-long.291/ 発表者:M2 梶川 怜恩
視覚文書理解に特化したMLLM(mPLUG-DocOwl2 [1]) • 高解像度の文書画像のトークン数を圧縮するアーキテクチャの開発 • 視覚文書理解ベンチにおいて、視覚トークン数を削減しつつ、高性能を確認 1 Overview [1] https://github.com/X-PLUG/mPLUG-DocOwl/tree/main/DocOwl2
文書解析をMLLMに行わせる流れが来ている • 質問応答、文献調査、OCR処理など • OCR-freeなので、OCRエラーによる性能劣化がないのが魅力 2 マルチモーダル大規模言語モデル(MLLM)× 文書解析
高解像度な画像にも対応できるようになったため • ViT(224×224)→ LLaVA(336×336)→ 現行(Higher resolution) • 文書画像は自然画像に比べて情報量が多い(高解像度な画像は細かな情報を表示可能) 3 なぜこの流れが生まれたか?
文書画像 自然画像 猫が壁から 顔出ししている 愛媛大学工学部「コン ピュータ科学コース」の 紹介ページ。このコース は、AIとIoT技術を学ぶ ことに焦点を当てている。 学習内容として、…
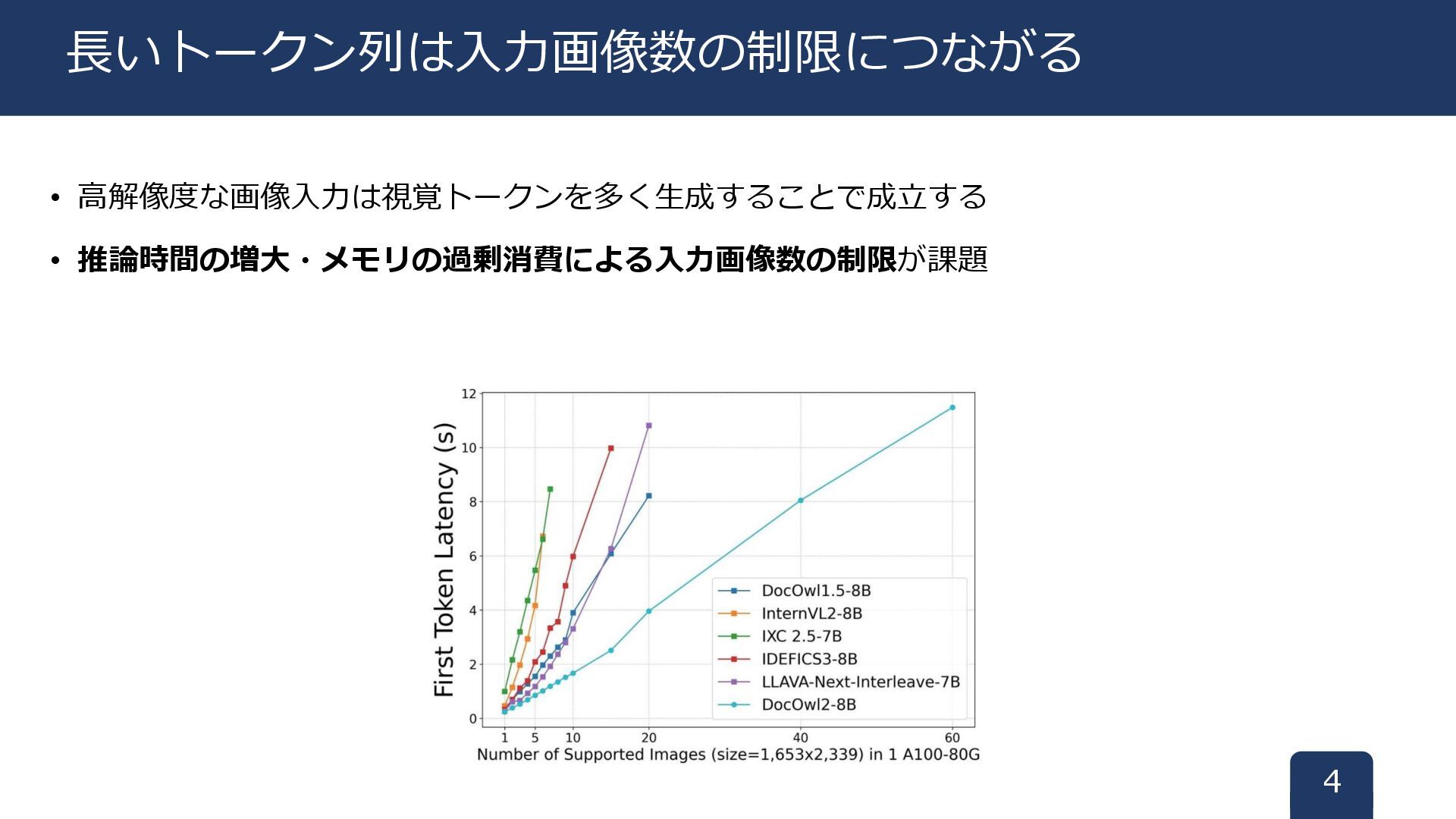
• 高解像度な画像入力は視覚トークンを多く生成することで成立する • 推論時間の増大・メモリの過剰消費による入力画像数の制限が課題 4 長いトークン列は入力画像数の制限につながる
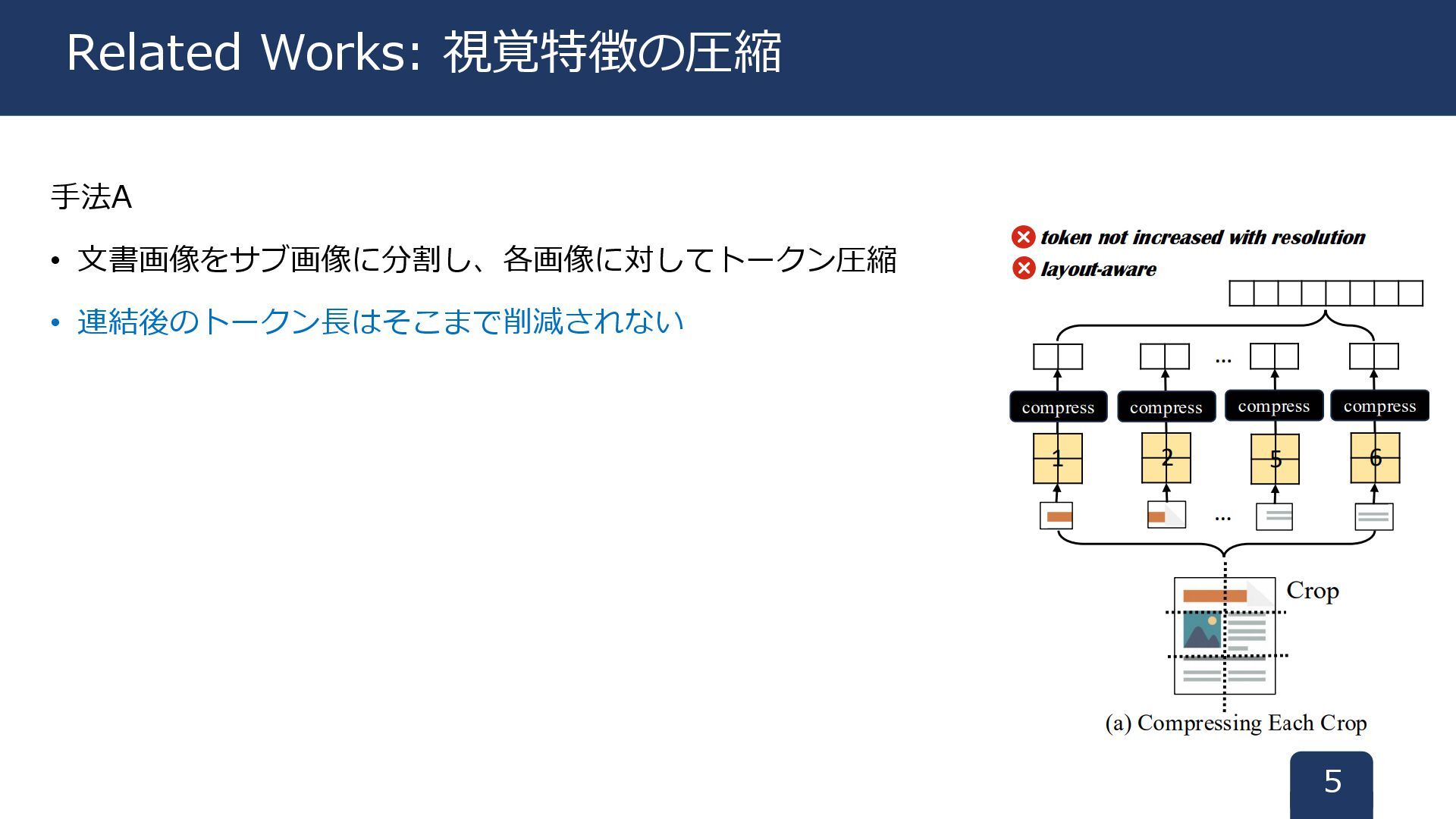
手法A • 文書画像をサブ画像に分割し、各画像に対してトークン圧縮 • 連結後のトークン長はそこまで削減されない 5 Related Works: 視覚特徴の圧縮
手法A • 文書画像をサブ画像に分割し、各画像に対してトークン圧縮 • 連結後のトークン長はそこまで削減されない 手法B • 文書画像内の特定のトークン or 学習可能なクエリを使用する
• 得られるトークン列は、文書のレイアウト情報を保持する保証なし 6 Related Works: 視覚特徴の圧縮
本手法 • 画像のグローバルな特徴をクエリとして利用 • トークン数の削減・レイアウト情報の保持を実現 DocOwl2 文書画像の新しい圧縮モジュールを適用したMLLM 7 Our Methods:
High-resolution DocCompressor
提案手法 8
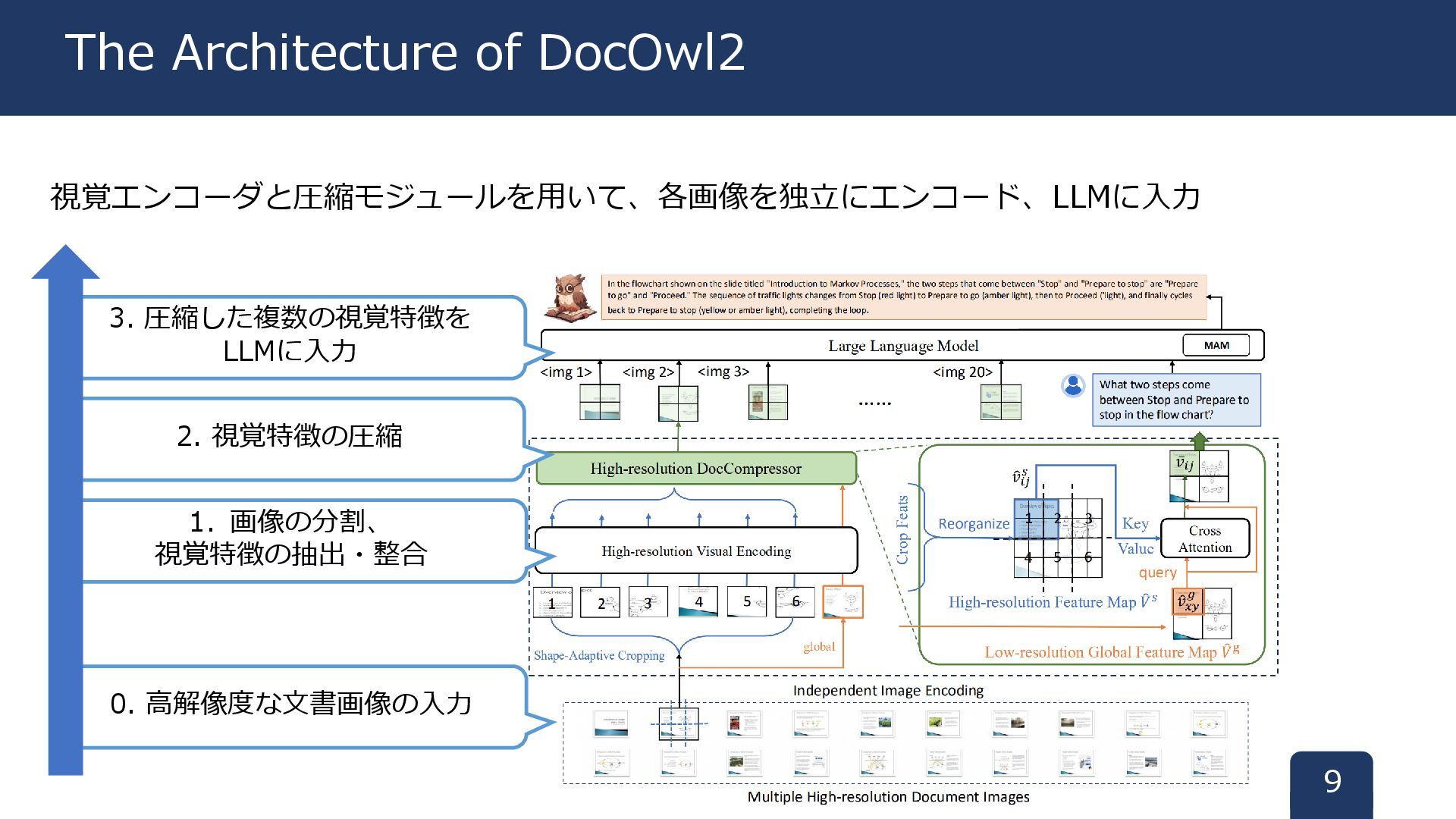
視覚エンコーダと圧縮モジュールを用いて、各画像を独立にエンコード、LLMに入力 9 The Architecture of DocOwl2 1. 画像の分割、 視覚特徴の抽出・整合 2.
視覚特徴の圧縮 3. 圧縮した複数の視覚特徴を LLMに入力 0. 高解像度な文書画像の入力
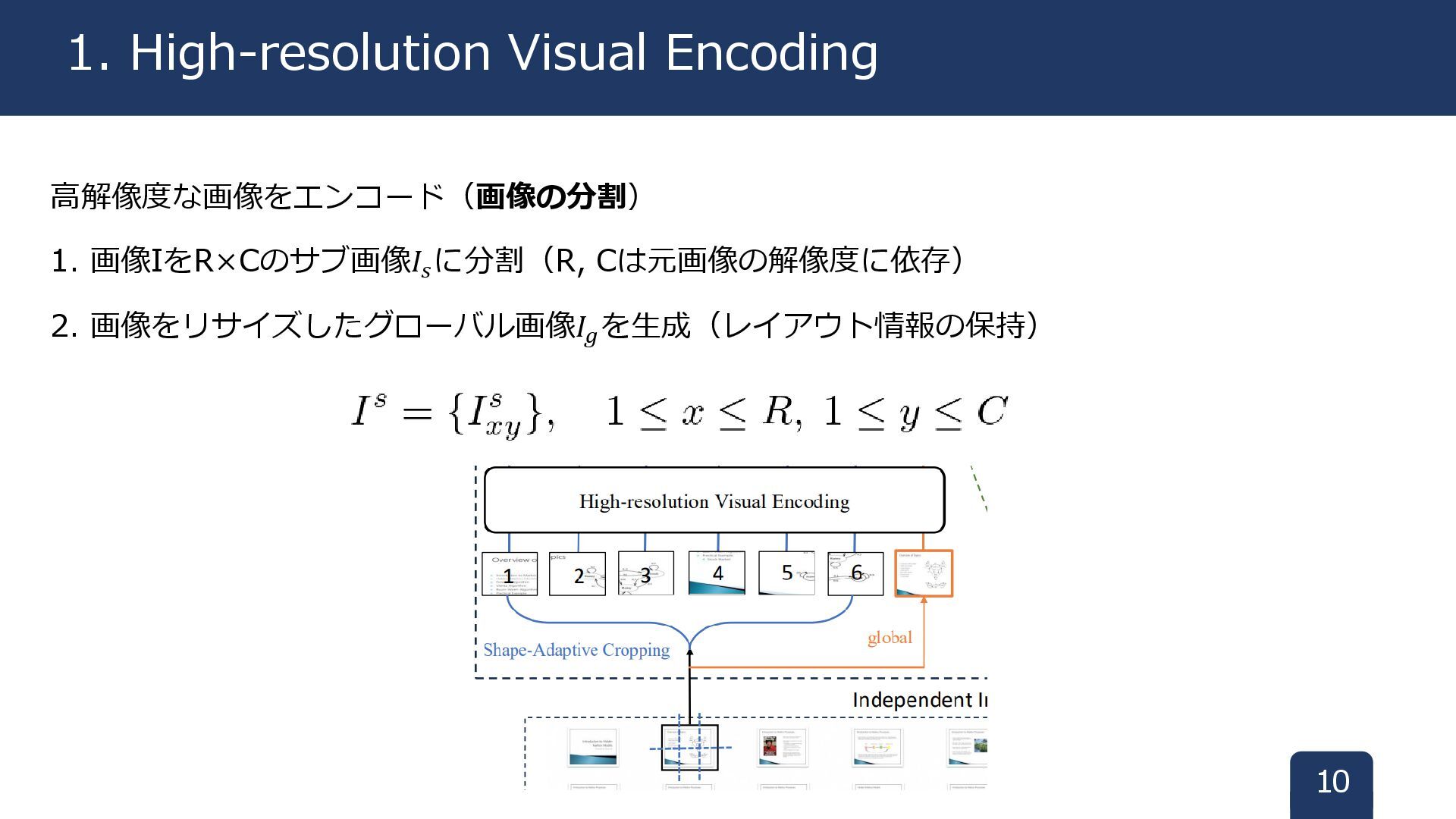
高解像度な画像をエンコード(画像の分割) 1. 画像IをR×Cのサブ画像𝐼𝑠 に分割(R, Cは元画像の解像度に依存) 2. 画像をリサイズしたグローバル画像𝐼𝑔 を生成(レイアウト情報の保持) 10 1.
High-resolution Visual Encoding
高解像度な画像をエンコード(視覚特徴の抽出・整合) 3. ViTを用いて各サブ画像・グローバル画像の視覚特徴を抽出 4. 各サブ画像・グローバル画像に対して、vision-to-textモジュール(H-Reducer)を適用 畳み込み層→全結合層で視覚特徴をLLMのテキスト特徴空間に整合する 11 1. High-resolution Visual
Encoding 𝑉はh×(w/4)× መ 𝑑 መ 𝑑はLLMのhidden state次元
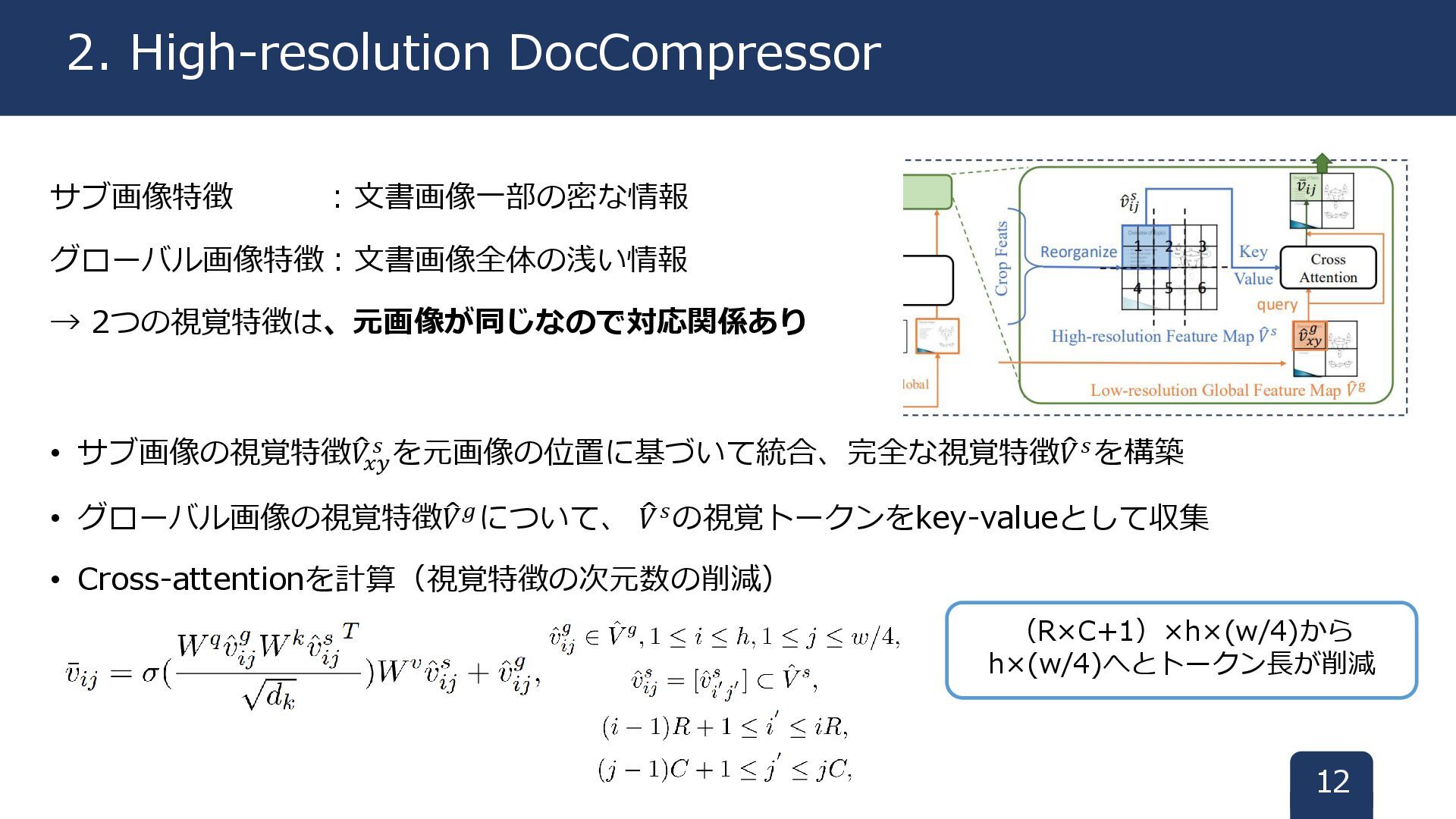
サブ画像特徴 :文書画像一部の密な情報 グローバル画像特徴:文書画像全体の浅い情報 → 2つの視覚特徴は、元画像が同じなので対応関係あり • サブ画像の視覚特徴 𝑉 𝑥𝑦 𝑠
を元画像の位置に基づいて統合、完全な視覚特徴 𝑉𝑠を構築 • グローバル画像の視覚特徴 𝑉𝑔について、 𝑉𝑠の視覚トークンをkey-valueとして収集 • Cross-attentionを計算(視覚特徴の次元数の削減) 12 2. High-resolution DocCompressor (R×C+1)×h×(w/4)から h×(w/4)へとトークン長が削減
LLMに複数文書画像を入力する • 視覚特徴に順序トークン<img num>を結合 → LLMが画像の視覚特徴を区別し、画像の入力順序を理解しやすくする目的 複数画像に対するLLMのデコード処理 13 3. Multi-image
Modeling with LLM • [… , … ]: 結合操作 • 𝑛: 画像枚数 • 𝑃𝑥 (1 ≤ 𝑥 ≤ 𝑛): 順序トークンのベクトル • 𝑉 𝑥 : 各画像の視覚特徴 • 𝑌: 出力文
3段階の学習 1. 単一画像を用いた事前学習 • 圧縮後の視覚特徴が文書の構造認識を十分にエンコード(捉えられる)ようにする • 文書解析(図表、画像のparsing) 2. 複数画像の継続事前学習 •
画像間の関連付け力を身につける • i. Multi-page Text Parsing: 文書中の連続ページを入力し、指定したページ番号のテキストを解析 • ii. Multi-page Text Lookup: 1,2ページ分のテキストを入力し、テキストが含まれる該当ページを予測 3. マルチタスク追加学習 • 単一、複数ページを入力とした、視覚文書理解タスクの指示チューニング • 通常のVQA, 説明付きVQA 14 4. Model Training
評価実験 15
学習データ • 学習1. DocStruct4M(画像から文書構造を認識) • 学習2. MP-DocStruct1M(複数画像から文書構造を認識)、DocStruct4M(破滅的な忘却の対策) • 学習3. DocDownstream-1.0(複数のVQAデータ)、DocReason25K(説明付きVQA)
評価方法 • 文書画像、ビデオを対象とした視覚文書理解ベンチマーク(情報抽出、VQA) • 単一・複数ページでそれぞれ評価 ああ あ あ あ あ 16 Experiments settings
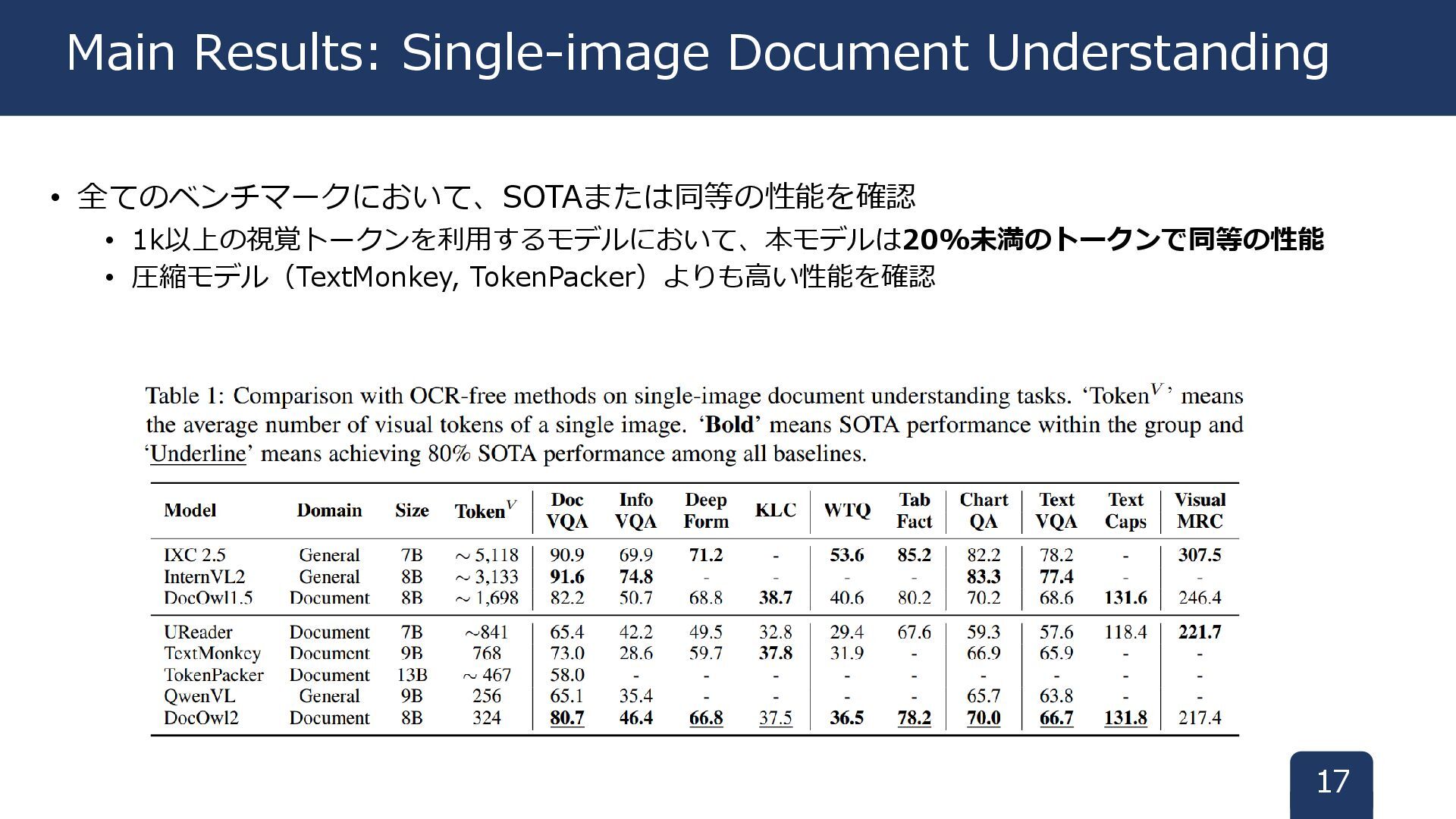
• 全てのベンチマークにおいて、SOTAまたは同等の性能を確認 • 1k以上の視覚トークンを利用するモデルにおいて、本モデルは20%未満のトークンで同等の性能 • 圧縮モデル(TextMonkey, TokenPacker)よりも高い性能を確認 17 Main Results:
Single-image Document Understanding
性能(ANLS)と処理速度(FTL)において、SOTAを確認 → 本モデルが視覚文書理解力とトークン効率性の両立に優れている 18 Main Results: Multi-page/Video Document Understanding
• r1: DocVQA、MP-DocVQA(1 page)において良好な性能だが、ページ数が多くなるにつ れ苦戦する • r2, 3: 複数画像の理解力が向上。10ページを超える文書で顕著な向上を確認 •
r4: 全てのページ数において、最高性能を確認 19 Ablation Study: Three-stage Training
DocCompressorとMLPとの学習におけるVRAM消費を比較 • DocCompressorはLLMへの入力長を圧縮するため、LLM側のActを大幅削減 • 最終的な消費量はMLPと比べて大幅に少ない 20 Analyses: VRAM Consumption of
DocCompressor ※ Act: モデルの計算中に発生するベクトルであり、一時的なメモリコストとなる
Conclusion • 効率的なOCR-freeの視覚文書理解MLLM(DocOwl2)を開発 • DocCompressorにより、メモリ効率を維持しながら複数ページのタスクで高い性能を確認 Limitation • DocCompressorは、追加学習が必要になる • vision-to-textモジュールとLLMの間に位置するため
• 別のモジュール、モデルで学習する際に、同様に学習しなければならない → DocCompressorの追加学習のコストを削減する手法を確立させる必要がある 21 Conclusion & Limitation
{kind=link}
![視覚文書理解に特化したMLLM(mPLUG-DocOwl2 [1]) • 高解像度の文書画像のトークン数を圧縮するアーキテクチャの開発 • 視覚文書理解ベンチにおいて、視覚トークン数を削減しつつ、高性能を確認 1 Overview [1] https://github.com/X-PLUG/mPLUG-DocOwl/tree/main/DocOwl2](https://files.speakerdeck.com/presentations/4d92bdb13b9c452c8b3403c73c2fb2ab/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}