"The future of the cloud changes the role of the SRE. In a large company where you are deploying your service on infrastructure built/managed in-house the SRE has the home field advantage of understanding the intricacies of that infrastructure. With more and more startups launching in the cloud which are maintained by the vendor, the local SREs role offers different challenges. Rich has launched several businesses on AWS and he will talk about his journey towards incorporating reliability into products and ensuring the development team had access to the information needed to improve their services. He will share the highlights of what he’s learned about Amazon’s Web Services and what it took for him to make it work for his companies."
Presented at SRECon in Santa Clara, May 30th 2014.
Also available from https://richadams.me/talks/srecon14/\
(Note: I didn't chose the title :p)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
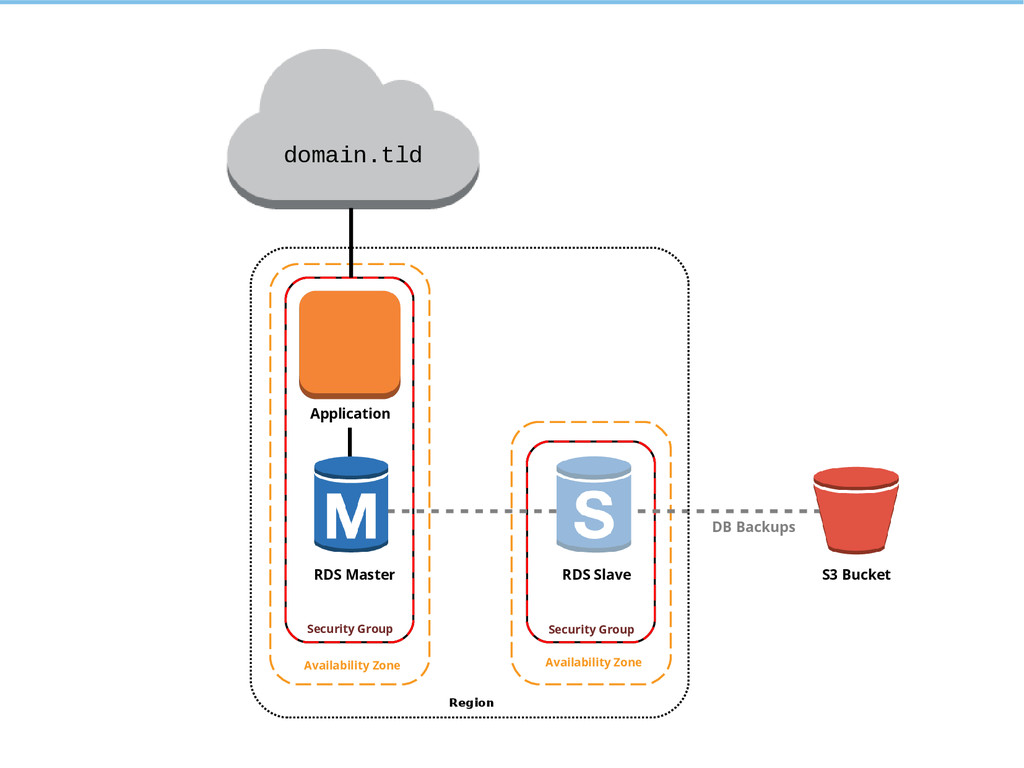{kind=link}
{kind=link}
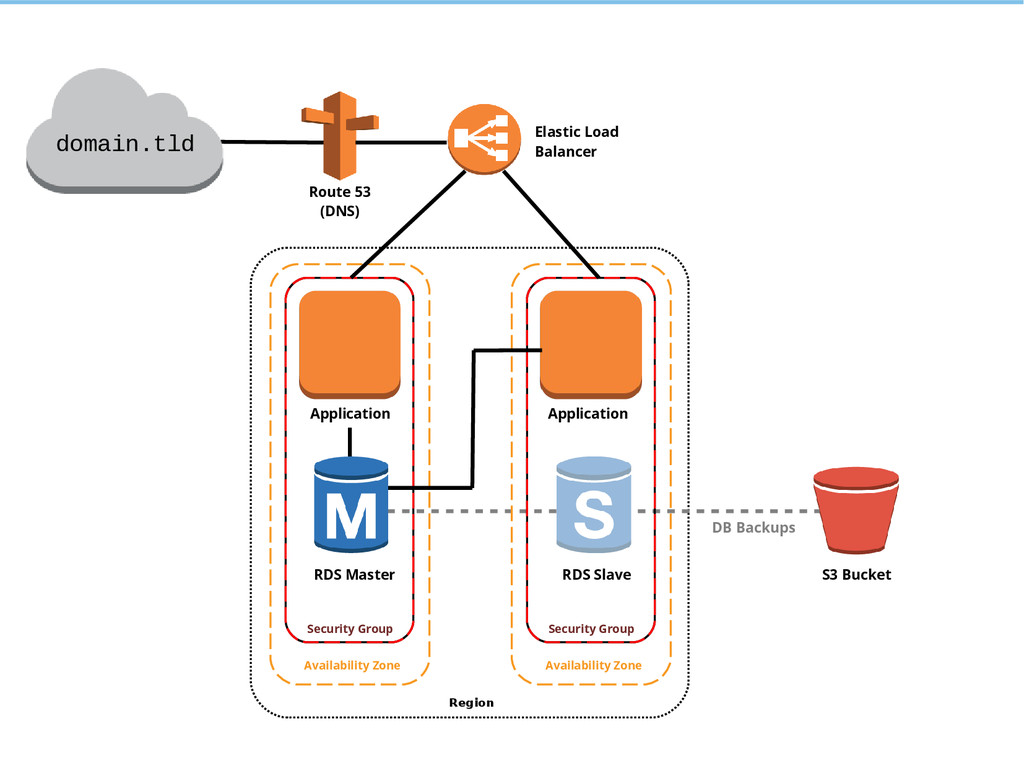{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
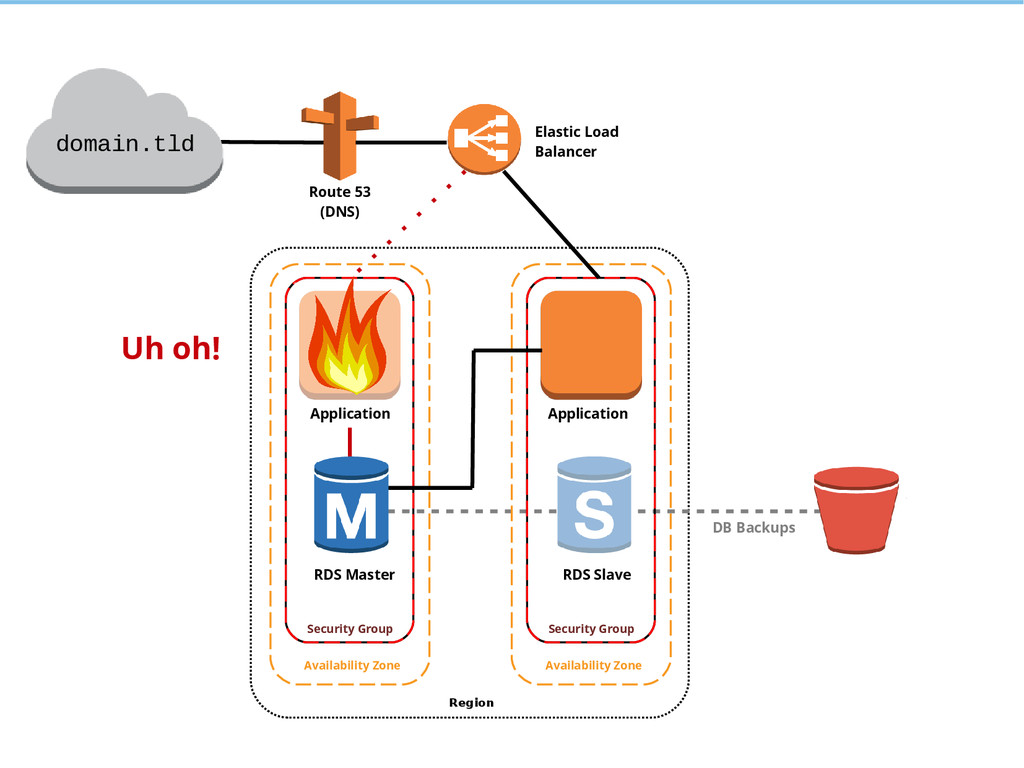{kind=link}
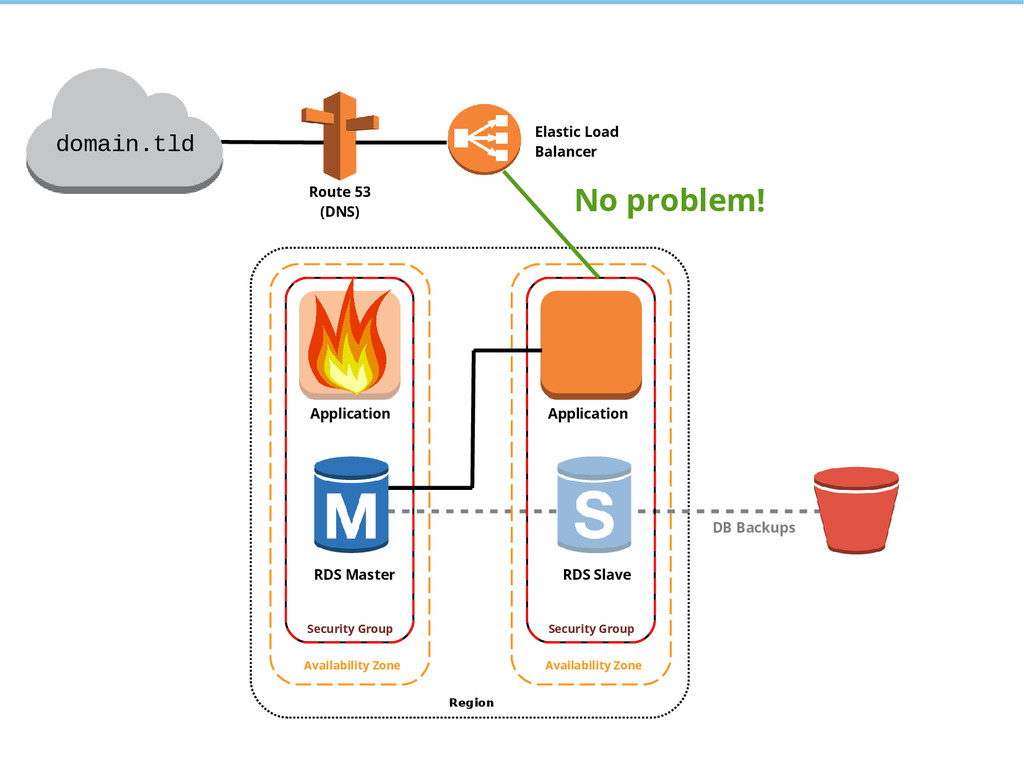{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
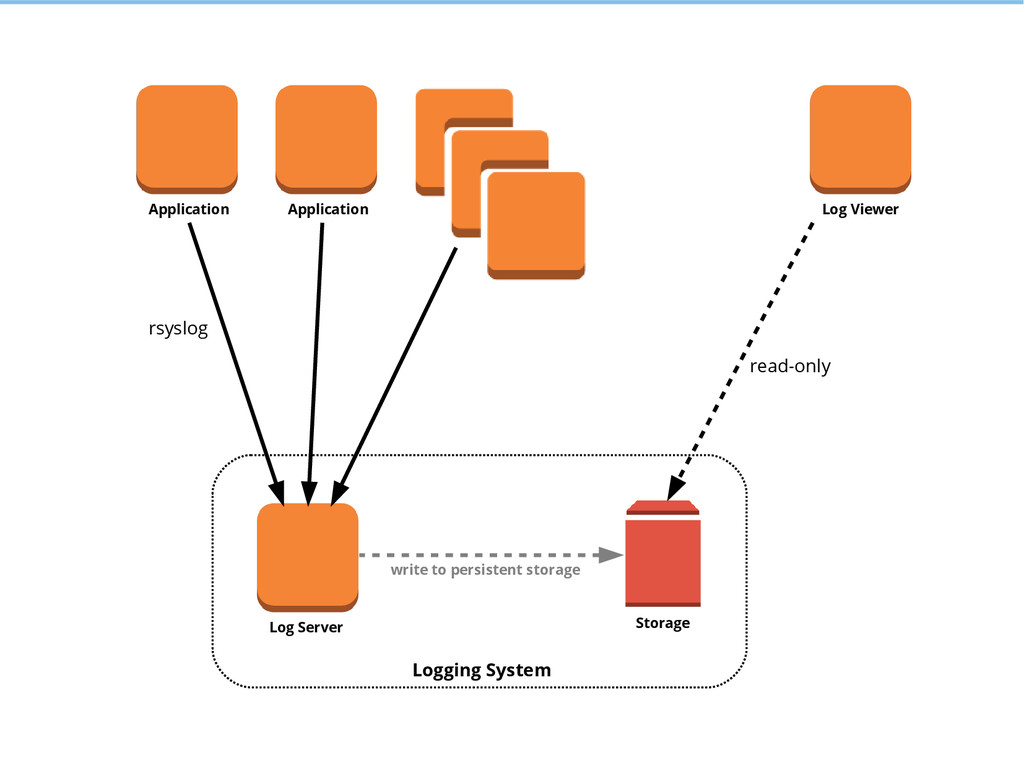{kind=link}
{kind=link}
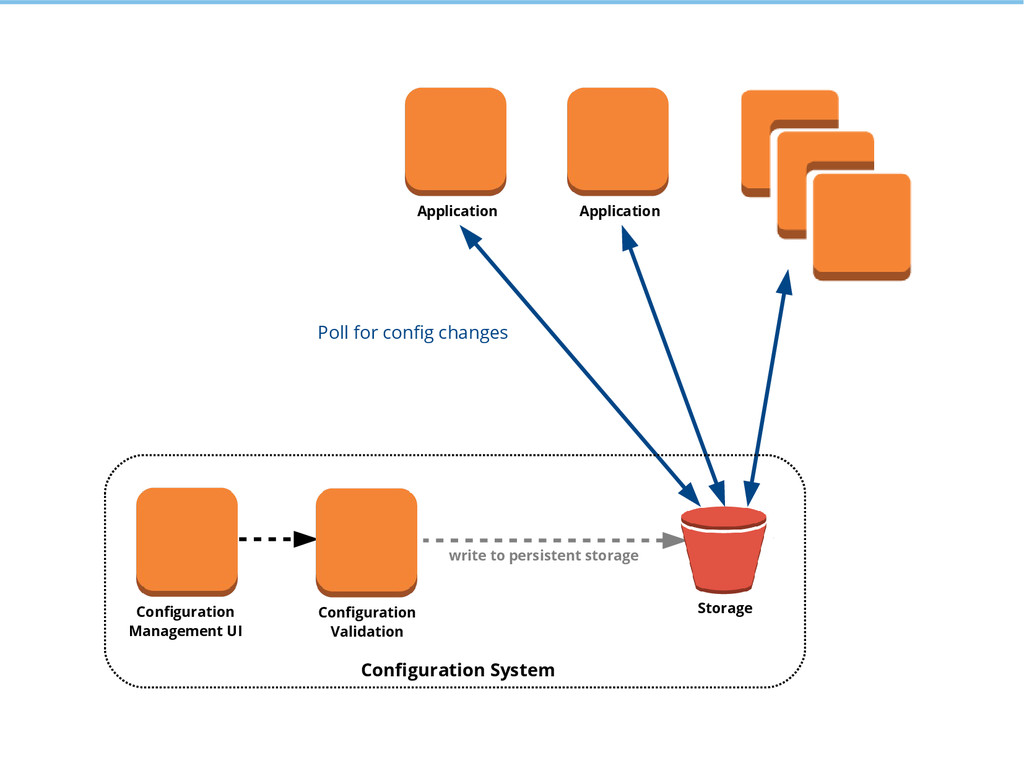{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
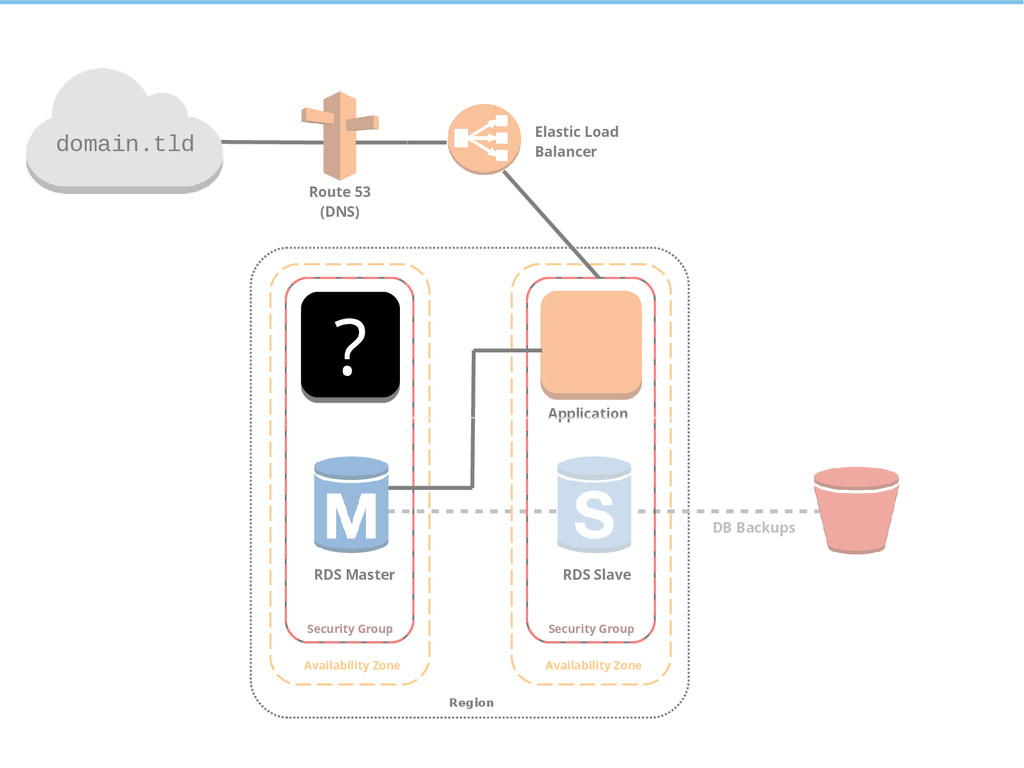{kind=link}
{kind=link}
{kind=link}
{kind=link}
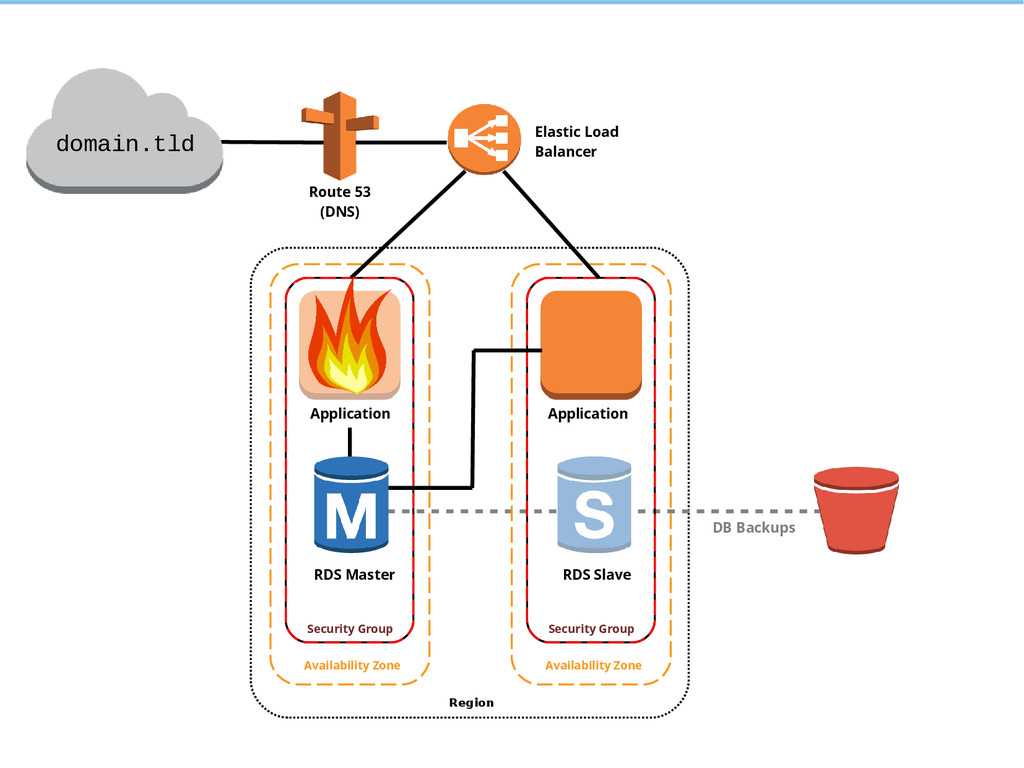{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}