a lot to Apache Cassandra™ • 400+ customers (25 of the Fortune 100), 400+ employees • Headquarter in San Francisco Bay area • EU headquarter in London, offices in France and Germany • Datastax Enterprise = OSS Cassandra + extra features 3
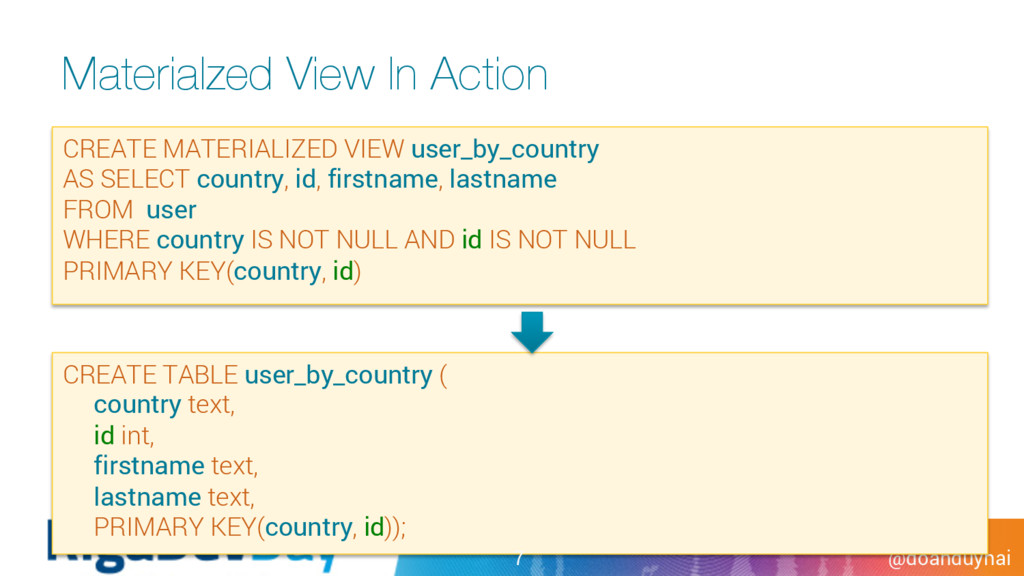
text, lastname text, PRIMARY KEY(country, id)); Materialzed View In Action CREATE MATERIALIZED VIEW user_by_country AS SELECT country, id, firstname, lastname FROM user WHERE country IS NOT NULL AND id IS NOT NULL PRIMARY KEY(country, id) 7
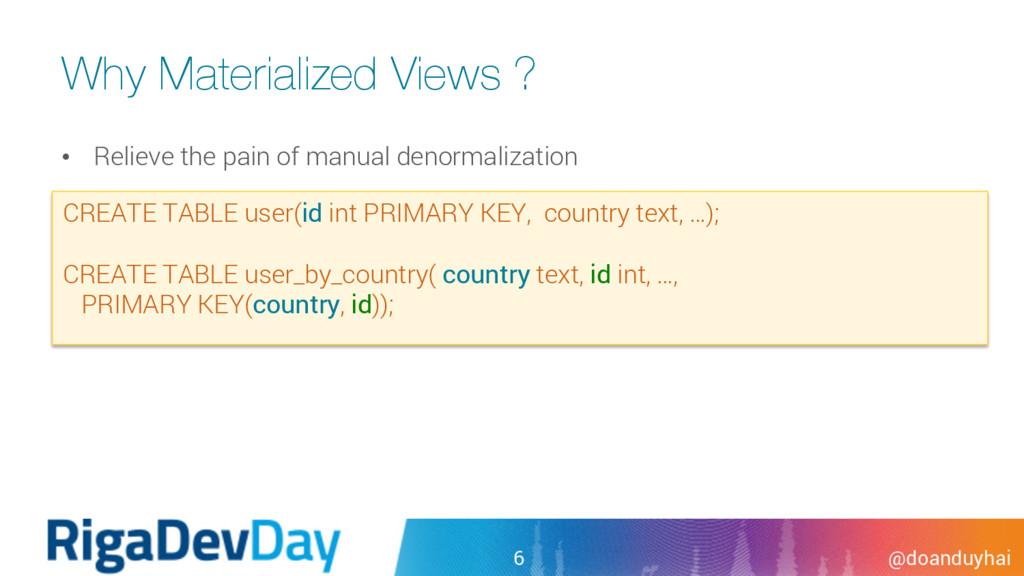
• MV better because no client-server network traffic for read-before-write • MV better because less network traffic for multiple views (client-side BATCH) • Makes developer life easier à priceless 10
• MV better because single node read (secondary index can hit many nodes) • MV better because single read path (secondary index = read index + read data) 11
FUNCTION [IF NOT EXISTS] [keyspace.]functionName (param1 type1 , param2 type2 , …) CALLED ON NULL INPUT | RETURNS NULL ON NULL INPUT RETURNS returnType LANGUAGE language AS $$ // source code here $$; 23
FUNCTION [IF NOT EXISTS] [keyspace.]functionName (param1 type1 , param2 type2 , …) CALLED ON NULL INPUT | RETURNS NULL ON NULL INPUT RETURNS returnType LANGUAGE language AS $$ // source code here $$; Param name to refer to in the code Type = Cassandra type 24
FUNCTION [IF NOT EXISTS] [keyspace.]functionName (param1 type1 , param2 type2 , …) CALLED ON NULL INPUT | RETURNS NULL ON NULL INPUT RETURNS returnType LANGUAGE language // j AS $$ // source code here $$; Always called Null-check mandatory in code 25
FUNCTION [IF NOT EXISTS] [keyspace.]functionName (param1 type1 , param2 type2 , …) CALLED ON NULL INPUT | RETURNS NULL ON NULL INPUT RETURNS returnType LANGUAGE language // jav AS $$ // source code here $$; If any input is null, function execution is skipped and return null 26
AGGREGATE [IF NOT EXISTS] [keyspace.]aggregateName(type1 , type2 , …) SFUNC accumulatorFunction STYPE stateType [FINALFUNC finalFunction] INITCOND initCond; Only type, no param name State type Initial state type 31
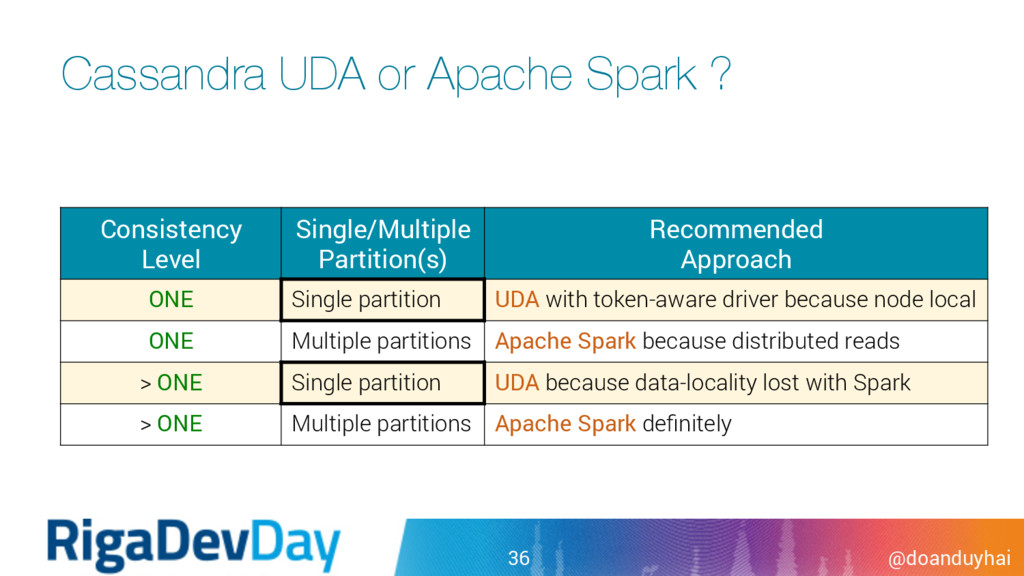
! • Execute UDA on a large number of rows (106 for ex.) • single fat partition • multiple partitions • full table scan • à Increase client-side timeout • default Java driver timeout = 12 secs
Single/Multiple Partition(s) Recommended Approach ONE Single partition UDA with token-aware driver because node local ONE Multiple partitions Apache Spark because distributed reads > ONE Single partition UDA because data-locality lost with Spark > ONE Multiple partitions Apache Spark definitely
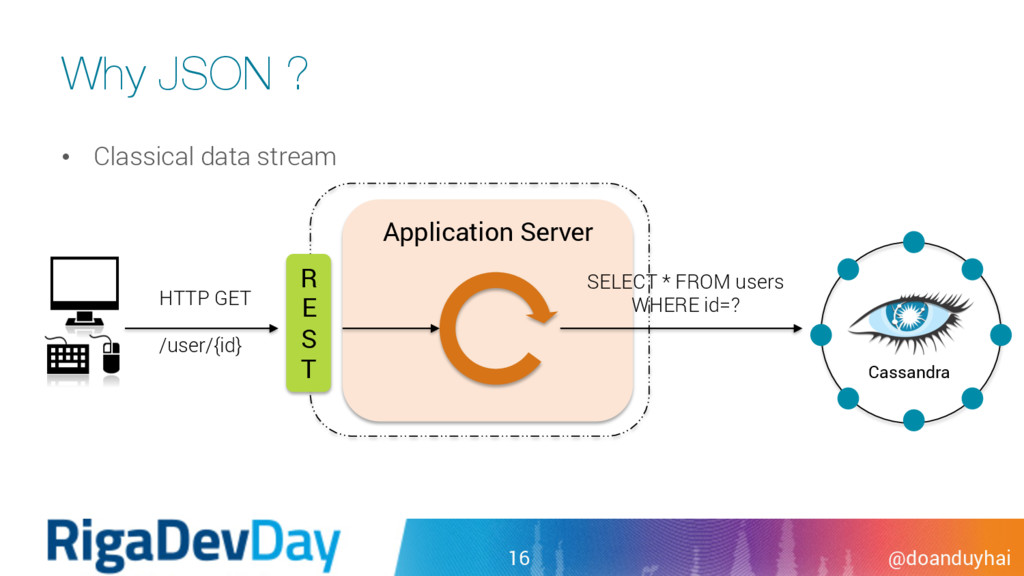
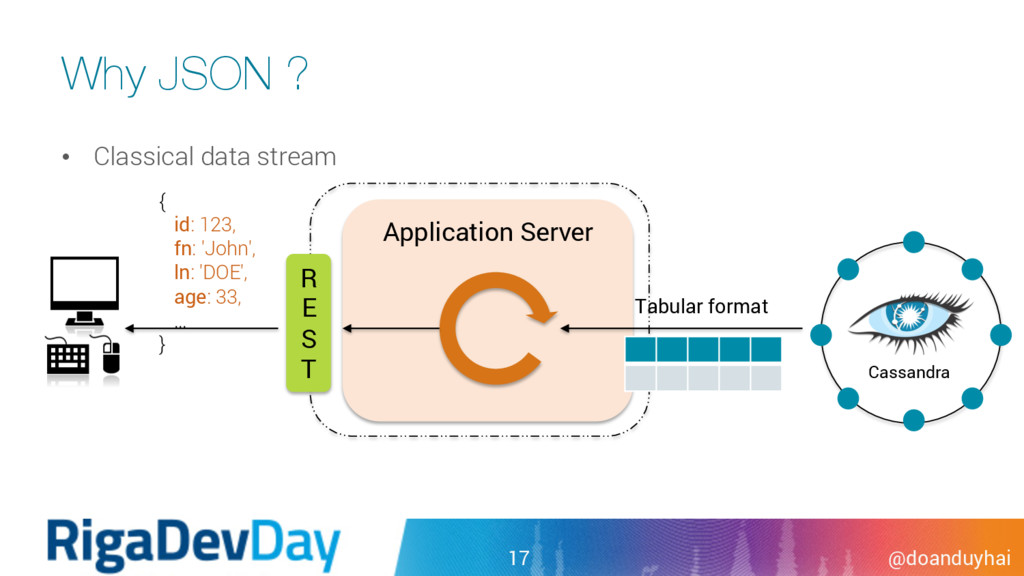
was always a pain point for Cassandra • limited search predicates (=, <=, <, > and >= only) • limited scope (only on primary key columns) • Existing secondary index performance is poor • reversed-index • use Cassandra itself as index storage … • limited predicate ( = ). Inequality predicate = full cluster scan 39
• Extended predicates (=, inequalities, LIKE %) • Full text search (tokenizers, stop-words, stemming …) • Query Planner to optimize AND predicates • NO, we don’t use Apache Lucene 40
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![@doanduyhai How to create an UDF ? CREATE [OR REPLACE]](https://files.speakerdeck.com/presentations/e43aea58efa247419d2c0c44e1c8b513/slide_22.jpg){kind=link}
![@doanduyhai How to create an UDF ? CREATE [OR REPLACE]](https://files.speakerdeck.com/presentations/e43aea58efa247419d2c0c44e1c8b513/slide_23.jpg){kind=link}
![@doanduyhai How to create an UDF ? CREATE [OR REPLACE]](https://files.speakerdeck.com/presentations/e43aea58efa247419d2c0c44e1c8b513/slide_24.jpg){kind=link}
![@doanduyhai How to create an UDF ? CREATE [OR REPLACE]](https://files.speakerdeck.com/presentations/e43aea58efa247419d2c0c44e1c8b513/slide_25.jpg){kind=link}
![@doanduyhai How to create an UDF ? CREATE [OR REPLACE]](https://files.speakerdeck.com/presentations/e43aea58efa247419d2c0c44e1c8b513/slide_26.jpg){kind=link}
![@doanduyhai How to create an UDF ? CREATE [OR REPLACE]](https://files.speakerdeck.com/presentations/e43aea58efa247419d2c0c44e1c8b513/slide_27.jpg){kind=link}
{kind=link}
{kind=link}
![@doanduyhai How to create an UDA ? CREATE [OR REPLACE]](https://files.speakerdeck.com/presentations/e43aea58efa247419d2c0c44e1c8b513/slide_30.jpg){kind=link}
![@doanduyhai How to create an UDA ? CREATE [OR REPLACE]](https://files.speakerdeck.com/presentations/e43aea58efa247419d2c0c44e1c8b513/slide_31.jpg){kind=link}
![@doanduyhai How to create an UDA ? CREATE [OR REPLACE]](https://files.speakerdeck.com/presentations/e43aea58efa247419d2c0c44e1c8b513/slide_32.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![@doanduyhai [email protected] https://academy.datastax.com/ Thank You 45 We’re hiring !](https://files.speakerdeck.com/presentations/e43aea58efa247419d2c0c44e1c8b513/slide_44.jpg){kind=link}