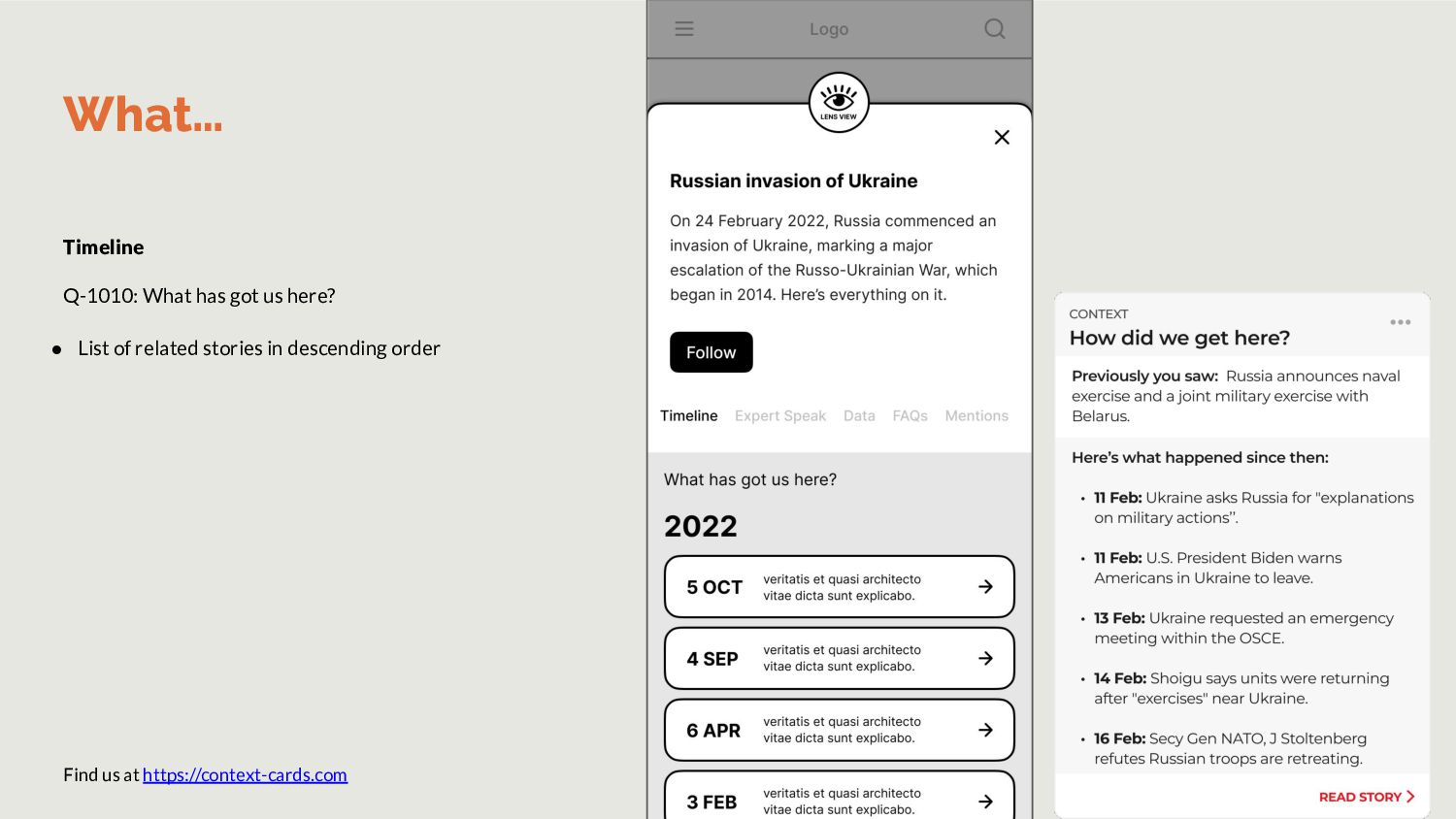
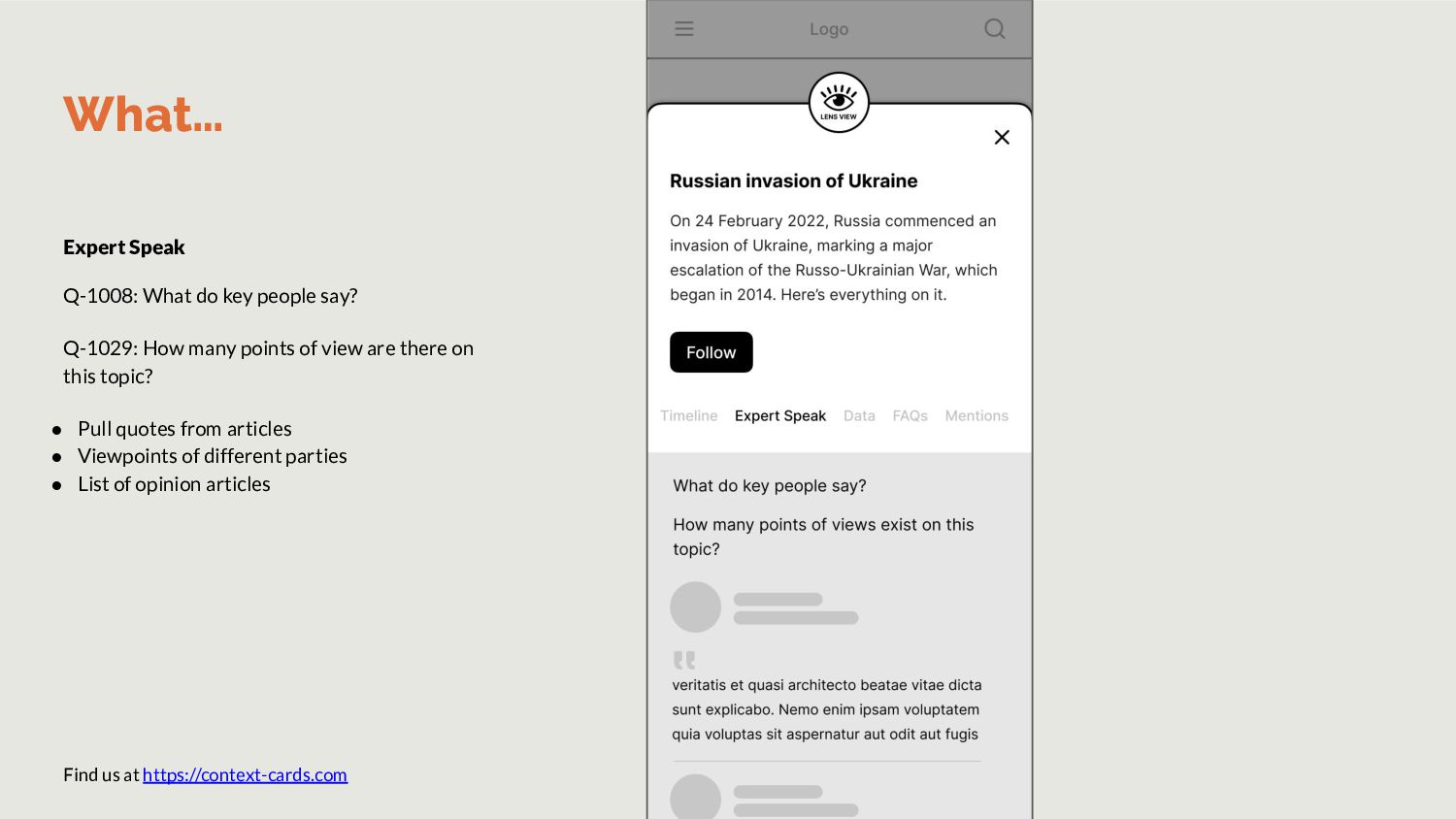
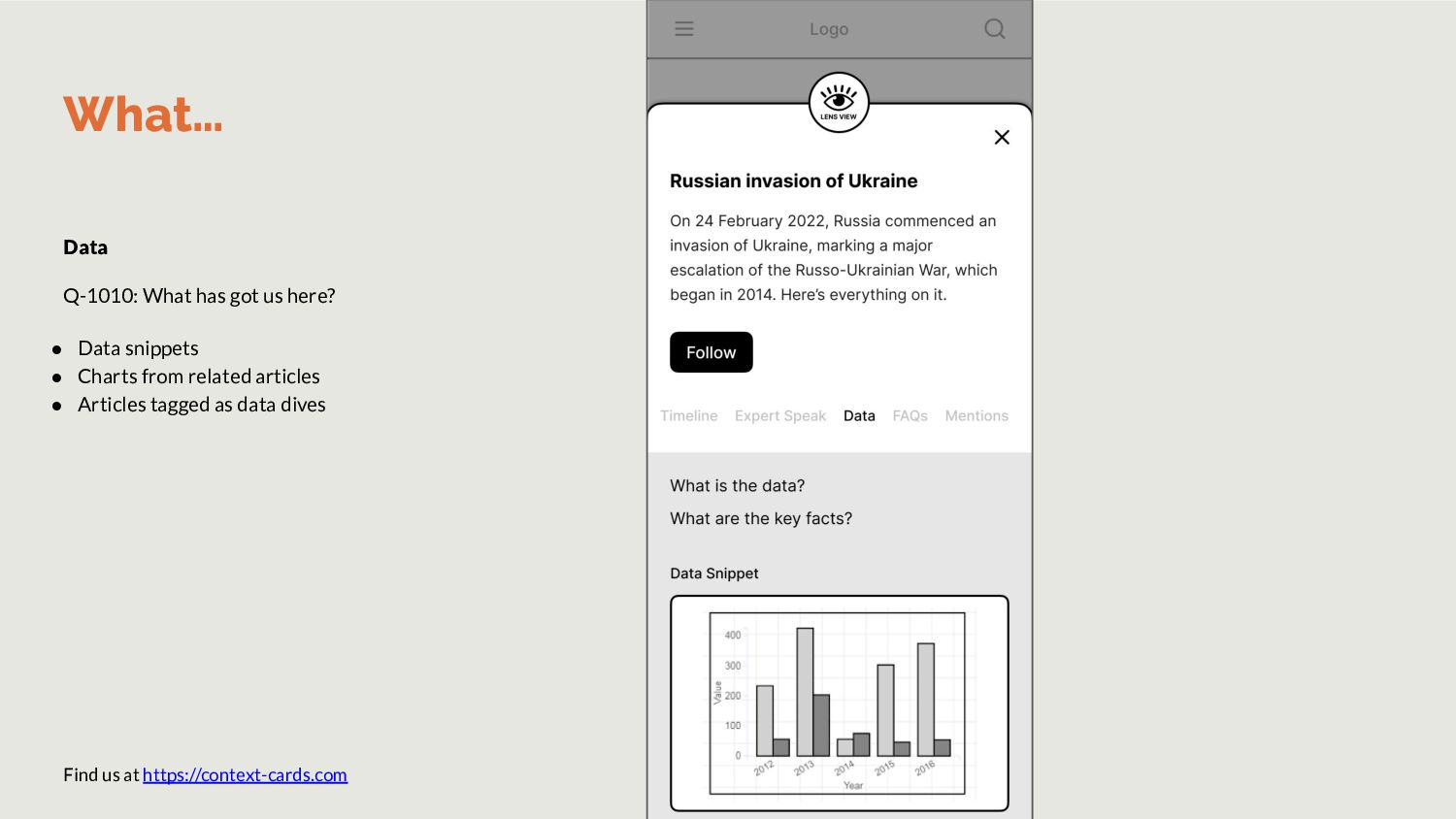
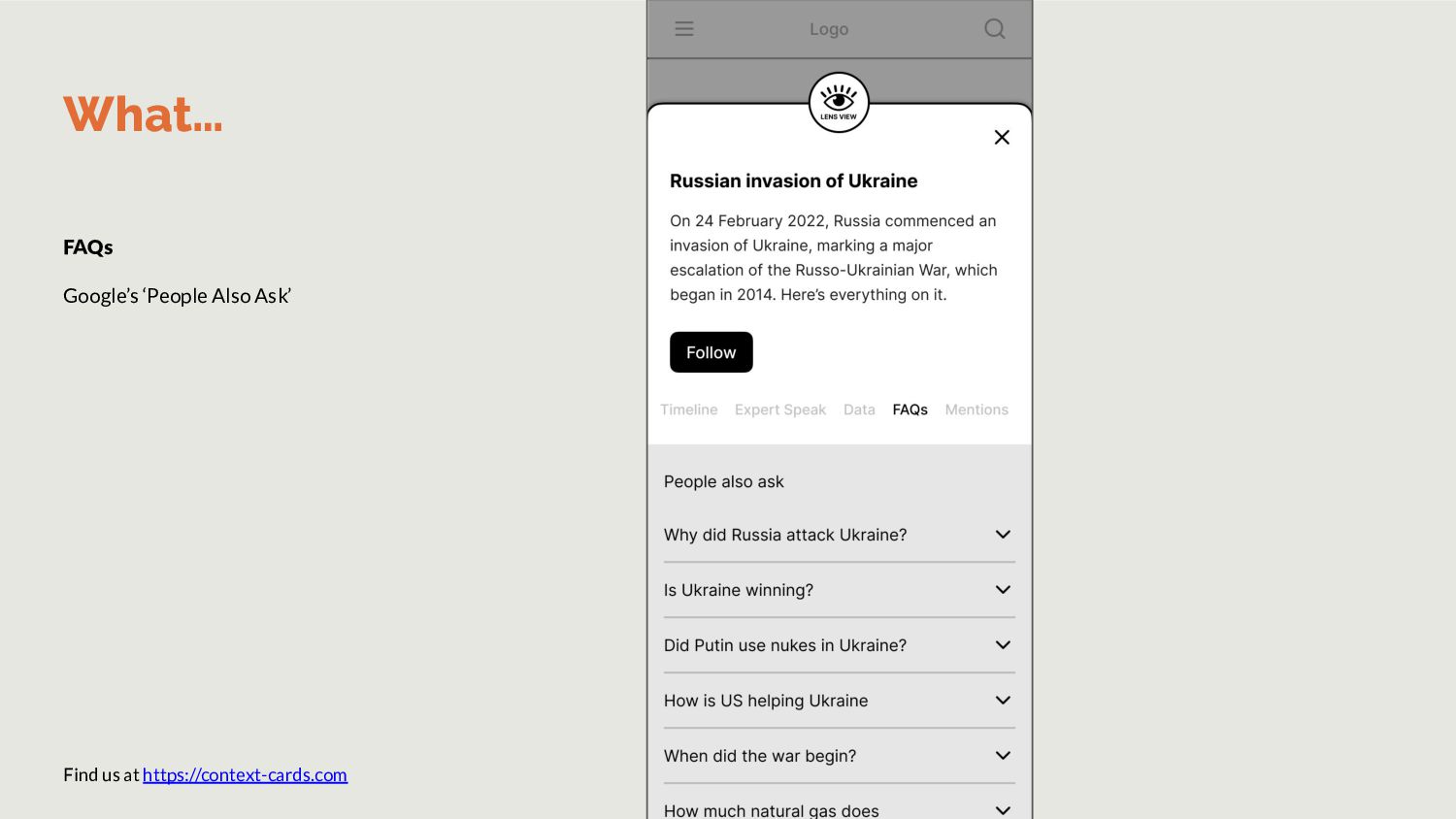
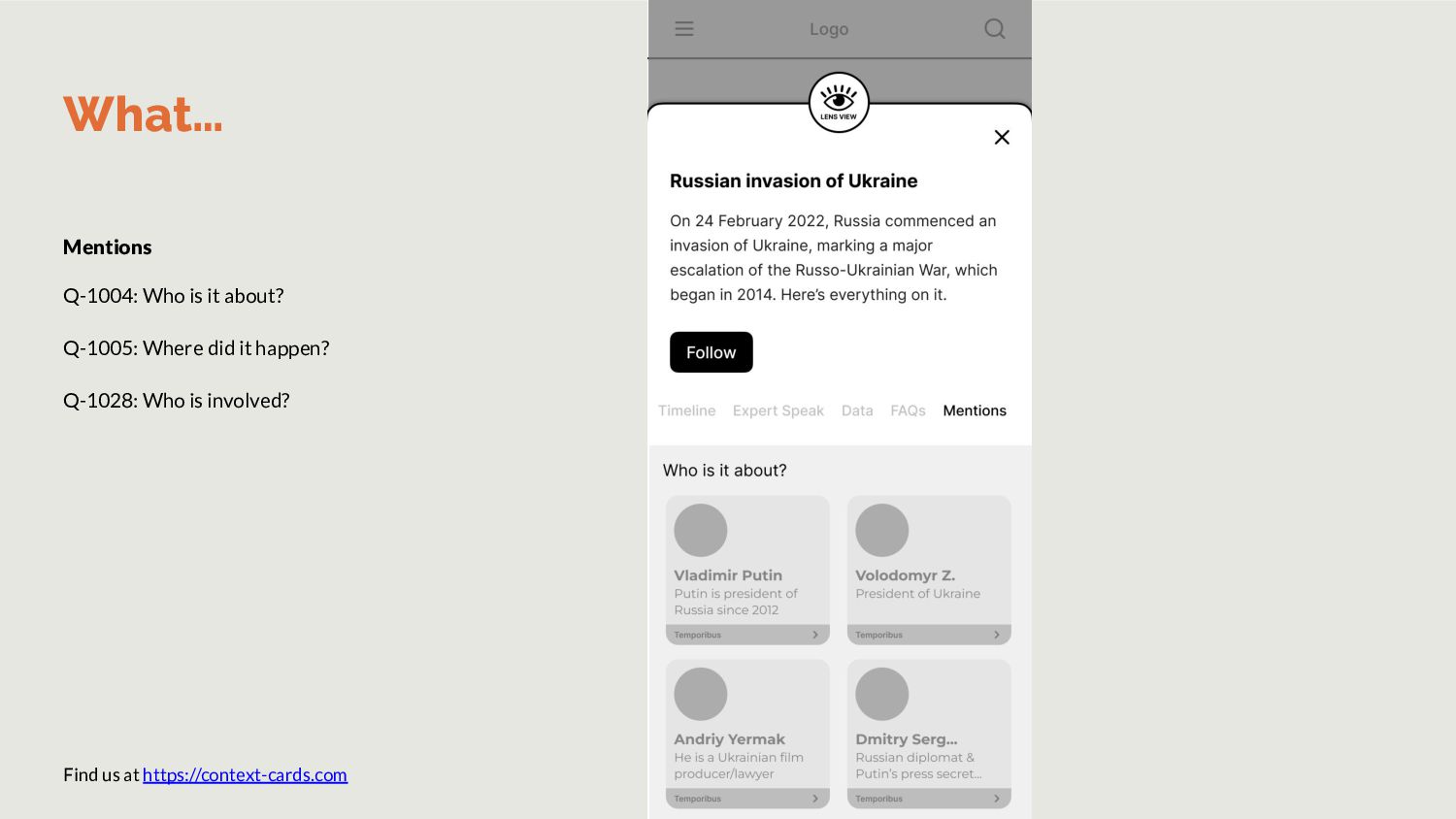
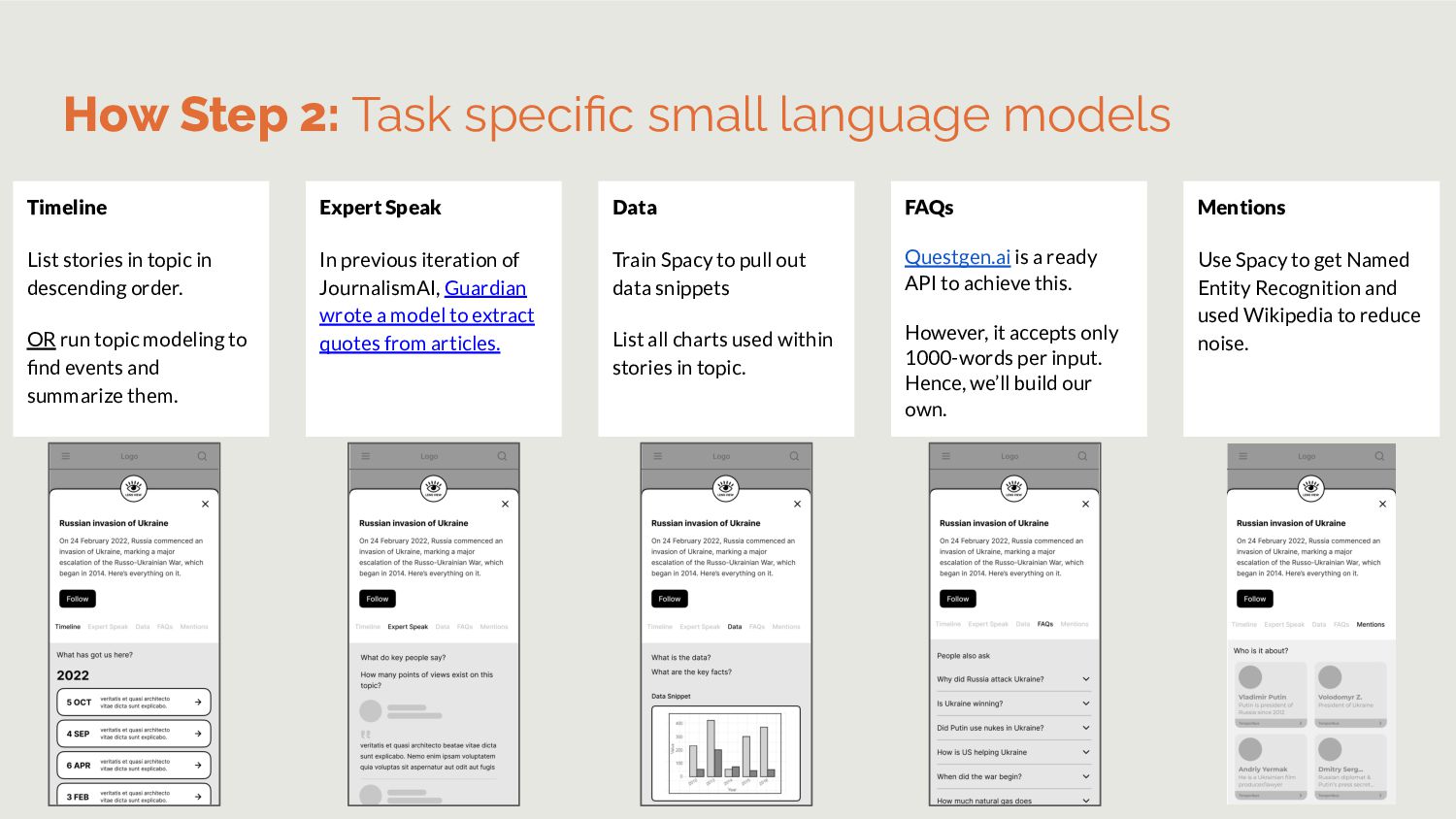
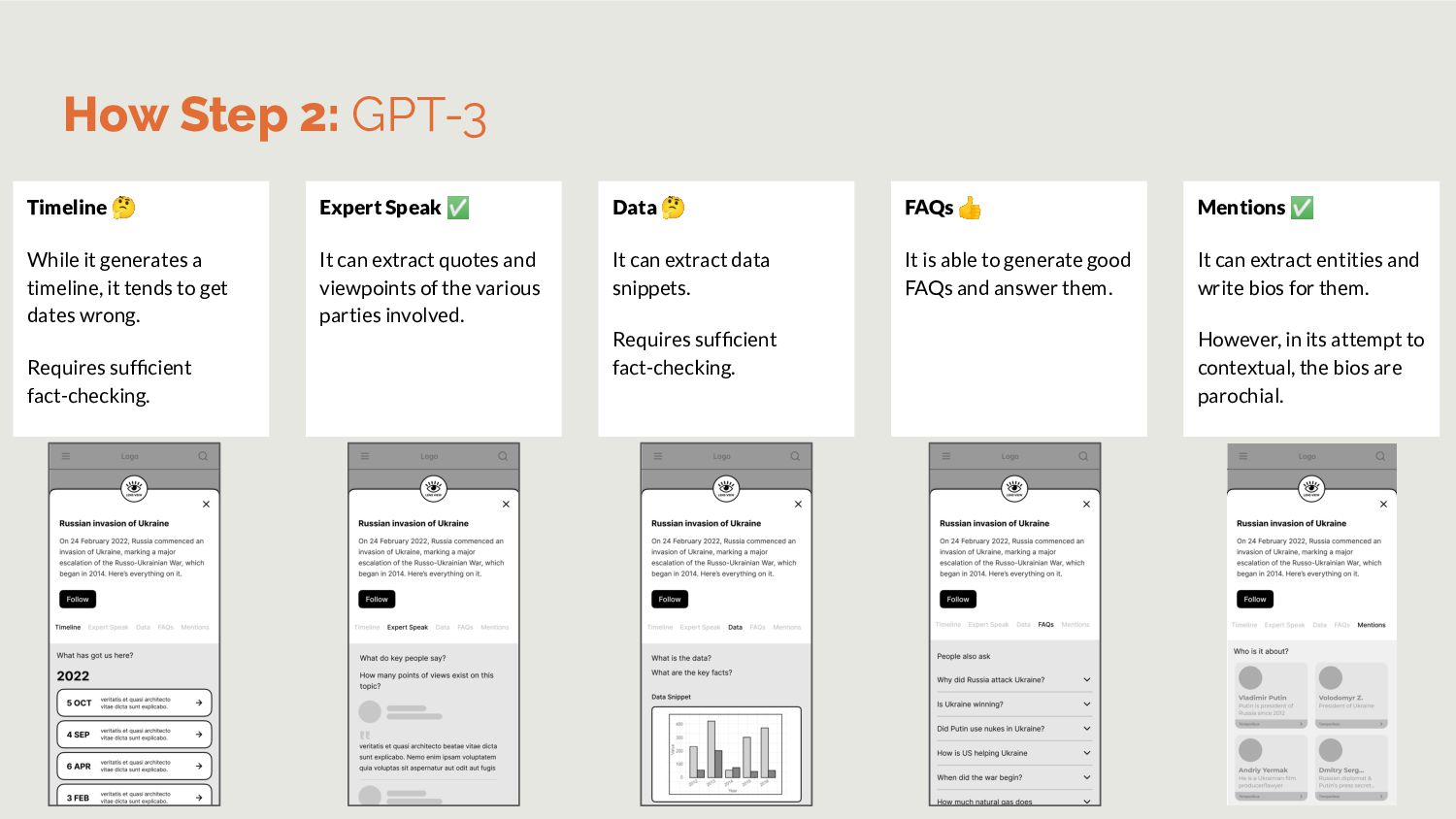
Wikipedia to reduce noise. FAQs Questgen.ai is a ready API to achieve this. However, it accepts only 1000-words per input. Hence, we’ll build our own. Data Train Spacy to pull out data snippets List all charts used within stories in topic. Timeline List stories in topic in descending order. OR run topic modeling to find events and summarize them. How Step 2: Task specific small language models Expert Speak In previous iteration of JournalismAI, Guardian wrote a model to extract quotes from articles.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}