Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
生成AI講座
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
uTaso
January 17, 2024
0
97
生成AI講座
uTaso
January 17, 2024
Tweet
Share
More Decks by uTaso
See All by uTaso
無駄無駄無駄無駄ァ‐‐‐‐ッ!
roboticsy
0
390
エンジニア向け『起業の科学』
roboticsy
0
410
Featured
See All Featured
Typedesign – Prime Four
hannesfritz
42
3k
Optimising Largest Contentful Paint
csswizardry
37
3.6k
SERP Conf. Vienna - Web Accessibility: Optimizing for Inclusivity and SEO
sarafernandez
1
1.3k
A Modern Web Designer's Workflow
chriscoyier
698
190k
We Are The Robots
honzajavorek
0
170
WENDY [Excerpt]
tessaabrams
9
36k
RailsConf & Balkan Ruby 2019: The Past, Present, and Future of Rails at GitHub
eileencodes
141
34k
Breaking role norms: Why Content Design is so much more than writing copy - Taylor Woolridge
uxyall
0
170
The SEO identity crisis: Don't let AI make you average
varn
0
330
Reality Check: Gamification 10 Years Later
codingconduct
0
2k
Performance Is Good for Brains [We Love Speed 2024]
tammyeverts
12
1.4k
The Spectacular Lies of Maps
axbom
PRO
1
530
Transcript
None
自己紹介 uたそ (ゆうたそ | ゆーたそ) 執行役員 CCO @ Ms.Engineer 自律ロボット,
機械学習, HMI LowCode開発基盤 FW, In-mem KVS, SearchEngine, RemoteConfig
話すこと • 人工知能の概要と位置付け • 統計的手法から現在の生成AIブームまでの流れ • ニューラルネットワークの基礎的な知識 • LLMとニューラルネットワークの関係性 •
機械学習モデルの課題感
話さないこと • 物理レイヤー(非ノイマン型コンピュータ)の話 • 簡単じゃない数学の話 • 機械学習モデルの作り方 • 自然言語以外のモデルの話
知能とは何か?
知的な機械に聞いてみた ChatGPT: 「知能」とは、情報を理解し、問題を解決し、学習する能力を指します。 これには、論理的思考、理解、自己認識、学習、感情的知識、推論、計画、 創造性、問題解決などが含まれます。知能は人間だけでなく、動物やコン ピュータプログラム(人工知能)にも見られる特性です。 Bard: 知能とは、環境に適応し、問題解決をめざして思考を行うなどの知的機能 の総称です。 知能の定義は、心理学、認知科学、哲学など、さまざまな分野で長年にわ
たって議論されてきました。現在のところ、統一的な定義は存在せず、さ まざまな側面から知能を捉える考え方が存在します。
チューリングテスト • チューリングテストとは、特定のタスクに対して機械のふるま いが人間と同等であるか、またはそれと区別がつかない程度か を確かめるためのテストです。 ※人間が知的ふるまいをしているという前提に立っています。 -> 現在の機械学習モデルの性能評価も、タスクに対するパフォーマ ンスで計測されることが多いです。
機械学習手法の 歴史
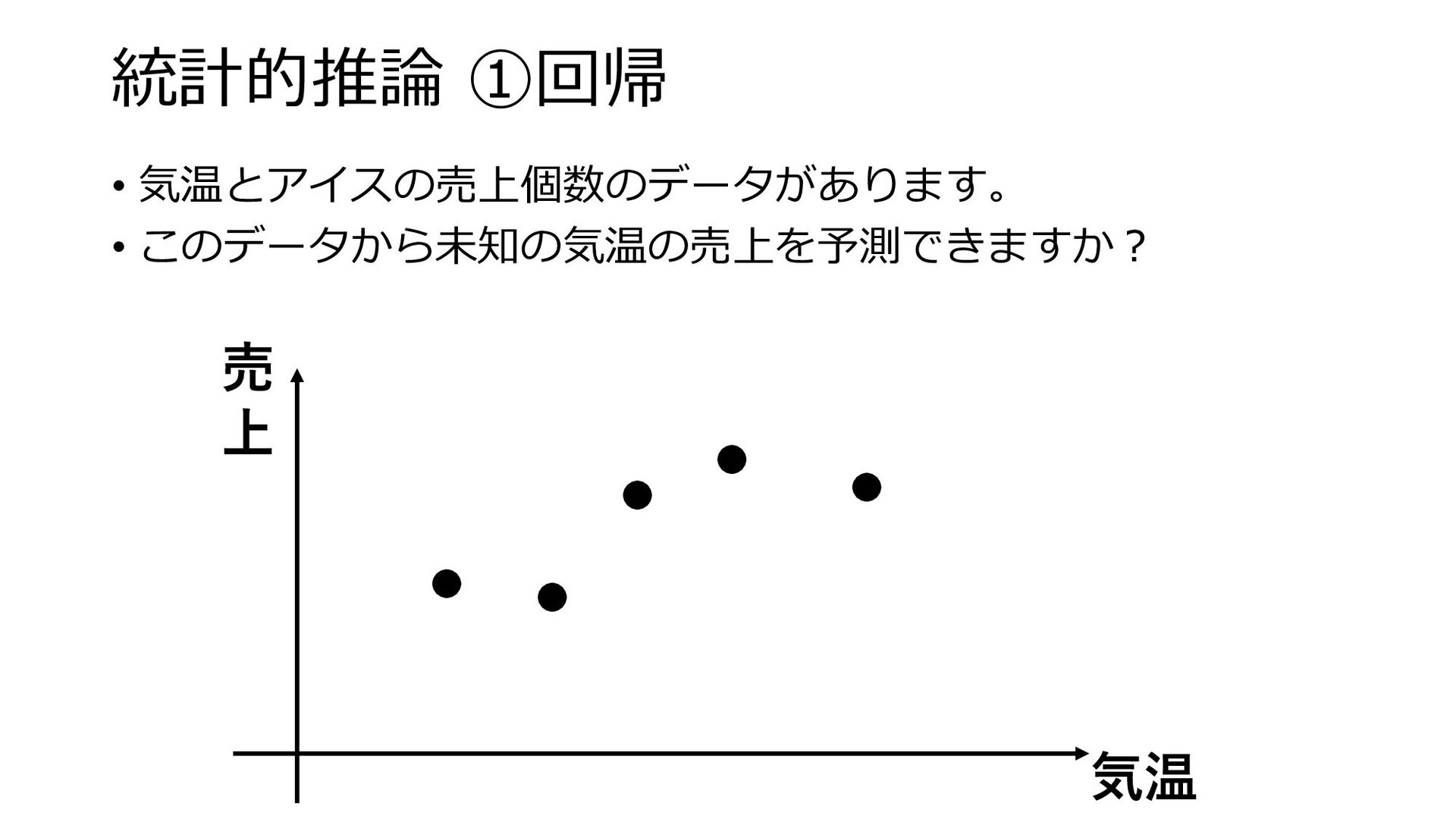
統計的推論 ①回帰 • 気温とアイスの売上個数のデータがあります。 • このデータから未知の気温の売上を予測できますか? 売 上 気温
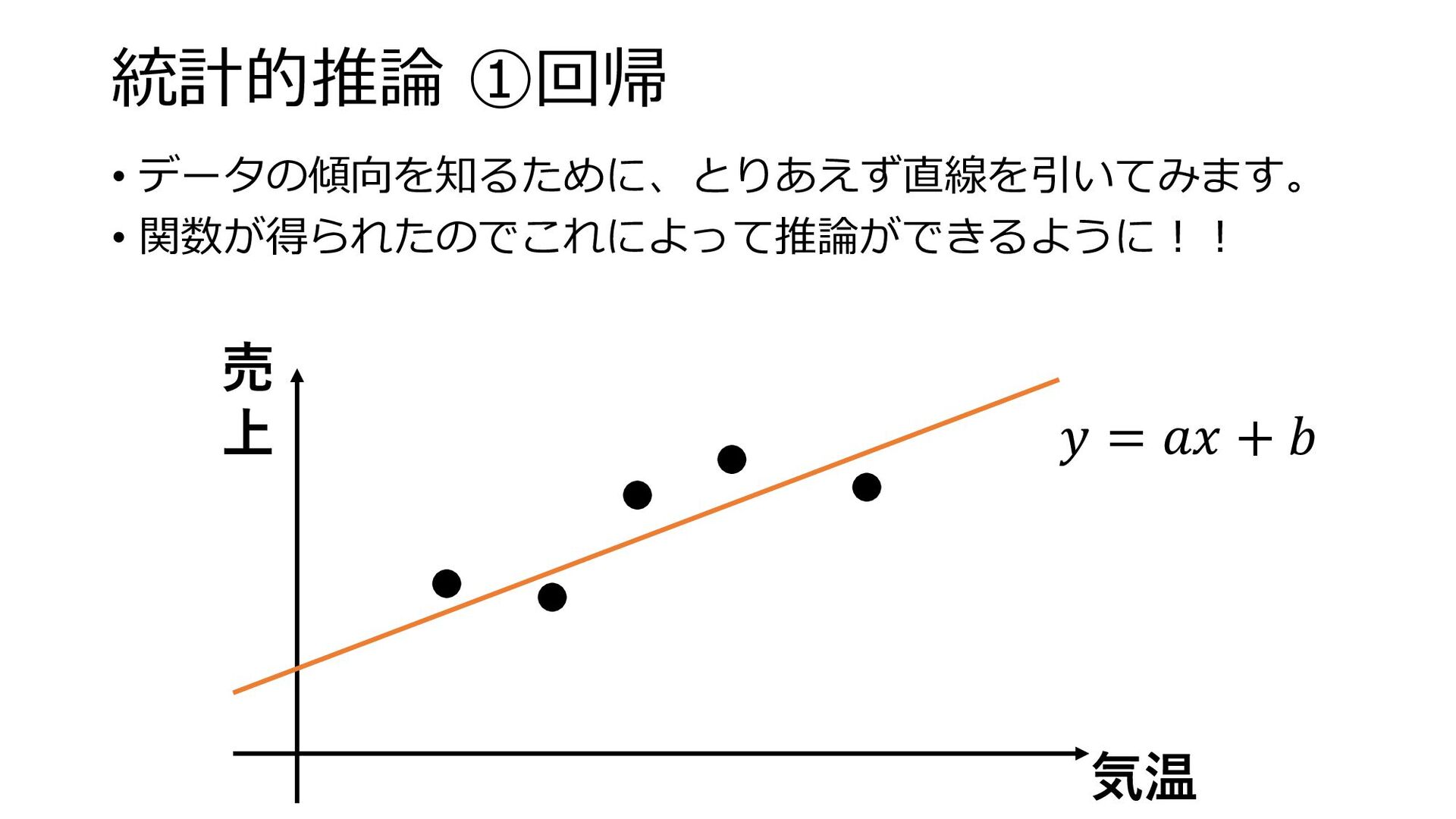
統計的推論 ①回帰 • データの傾向を知るために、とりあえず直線を引いてみます。 • 関数が得られたのでこれによって推論ができるように!! 売 上 気温 𝑦
= 𝑎𝑥 + 𝑏
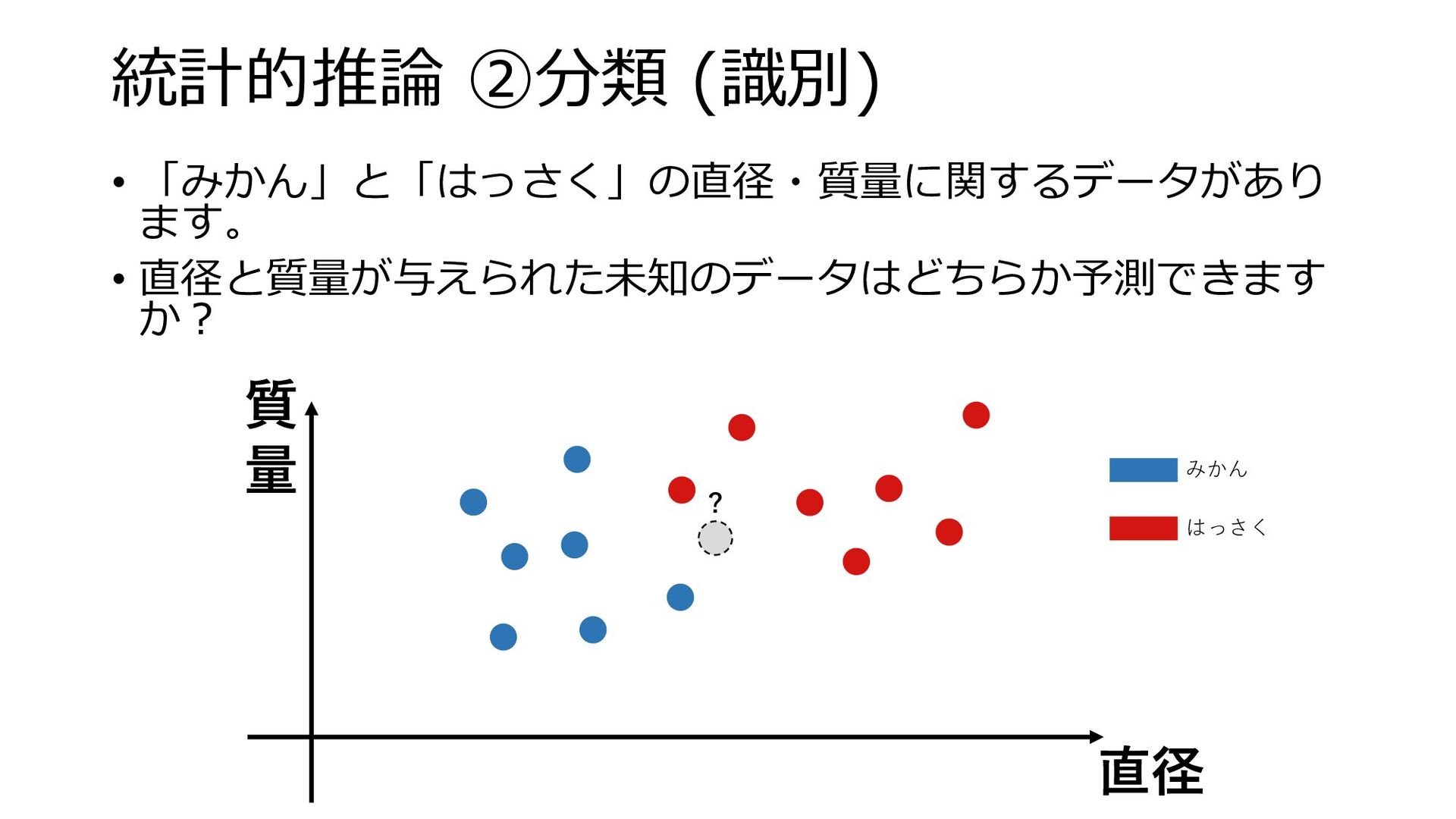
統計的推論 ②分類 (識別) • 「みかん」と「はっさく」の直径・質量に関するデータがあり ます。 • 直径と質量が与えられた未知のデータはどちらか予測できます か? 質
量 直径 みかん はっさく ?
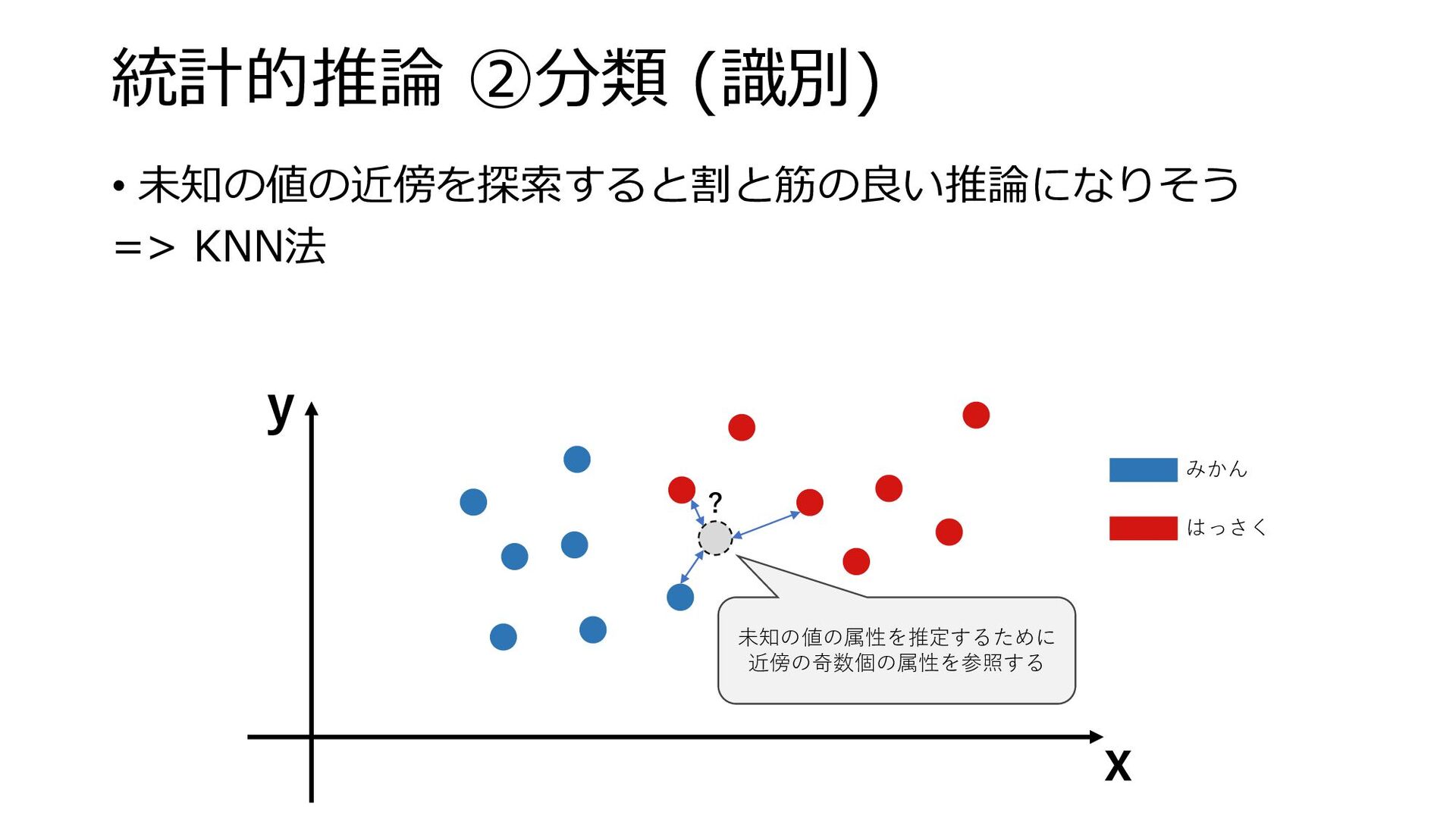
統計的推論 ②分類 (識別) • 未知の値の近傍を探索すると割と筋の良い推論になりそう => KNN法 y x ?
未知の値の属性を推定するために 近傍の奇数個の属性を参照する みかん はっさく
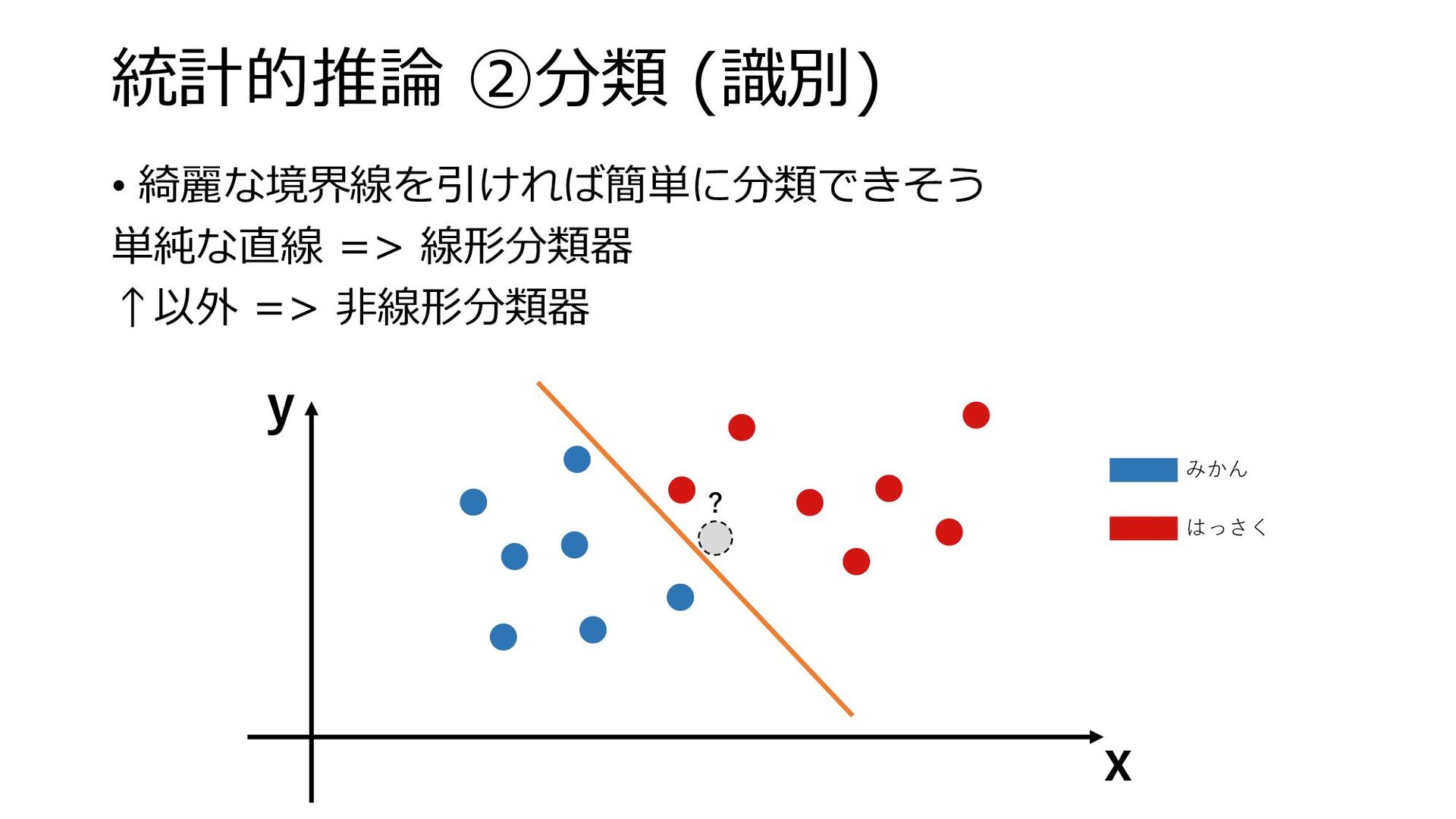
統計的推論 ②分類 (識別) • 綺麗な境界線を引ければ簡単に分類できそう 単純な直線 => 線形分類器 ↑以外 =>
非線形分類器 y x ? みかん はっさく
統計的推論のまとめ • 既存のデータ群から目的に応じた “関数” を作成するアプロー チが主流。 • 比較的小さなモデルなので、コンピューティングリソースの消 費が少ない(計算量などは考慮したい) •
スモールデータとの相性は非常によいので、現場でよく使われ る。
ニューラル ネットワーク
これは何の 写真ですか? https://www.irasutoya.com/2014/02/blog-post_10.html
人間はスゴイ!! • 今までの経験から、初めて見聞きする対象でもある程度の識別 ができる。 • はじめて歩く地面でも転ばない。 => 人間を模した知的なモデルを作ろう! => ニューラルネットワーク
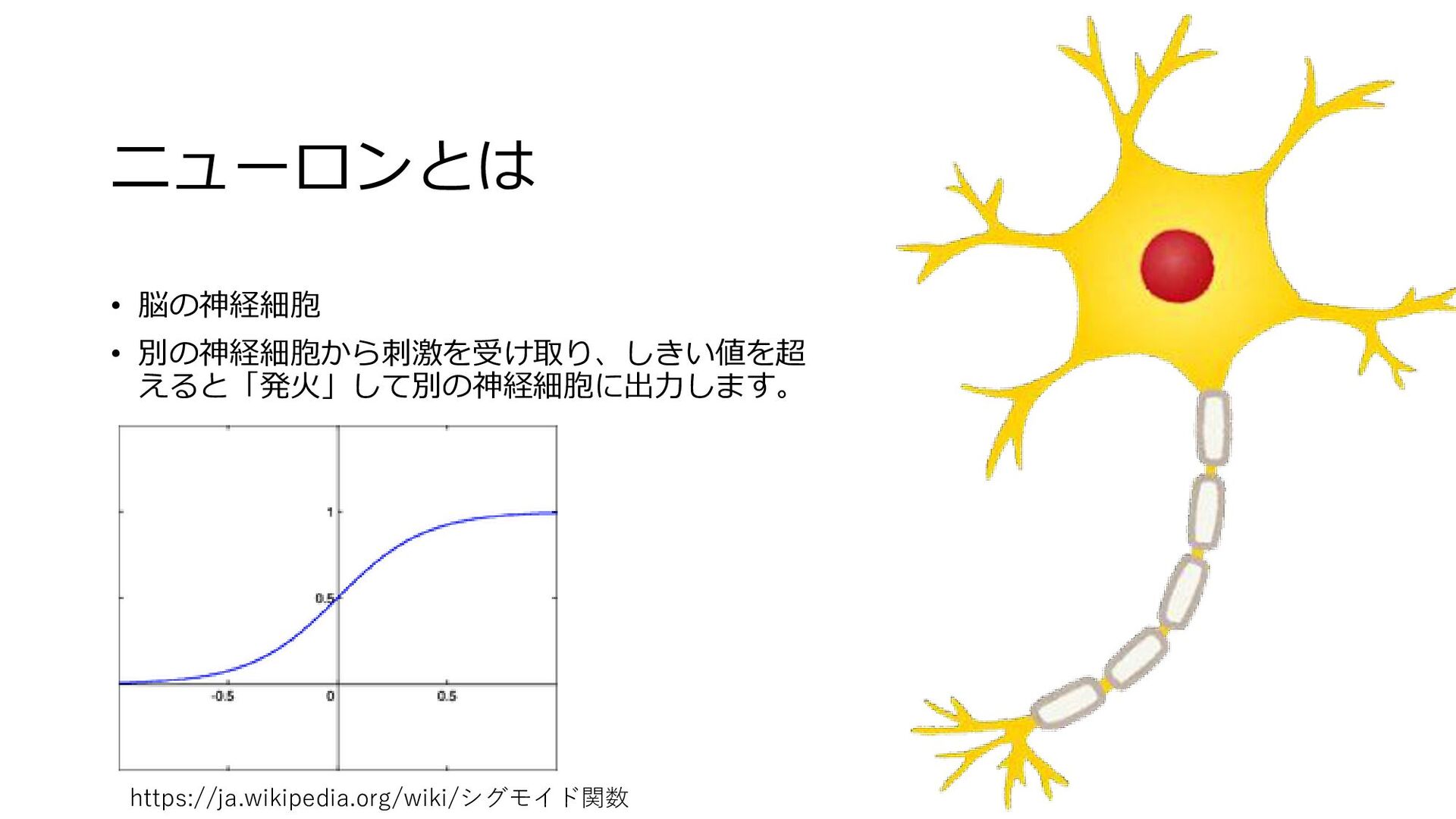
ニューロンとは • 脳の神経細胞 • 別の神経細胞から刺激を受け取り、しきい値を超 えると「発火」して別の神経細胞に出力します。 https://ja.wikipedia.org/wiki/シグモイド関数
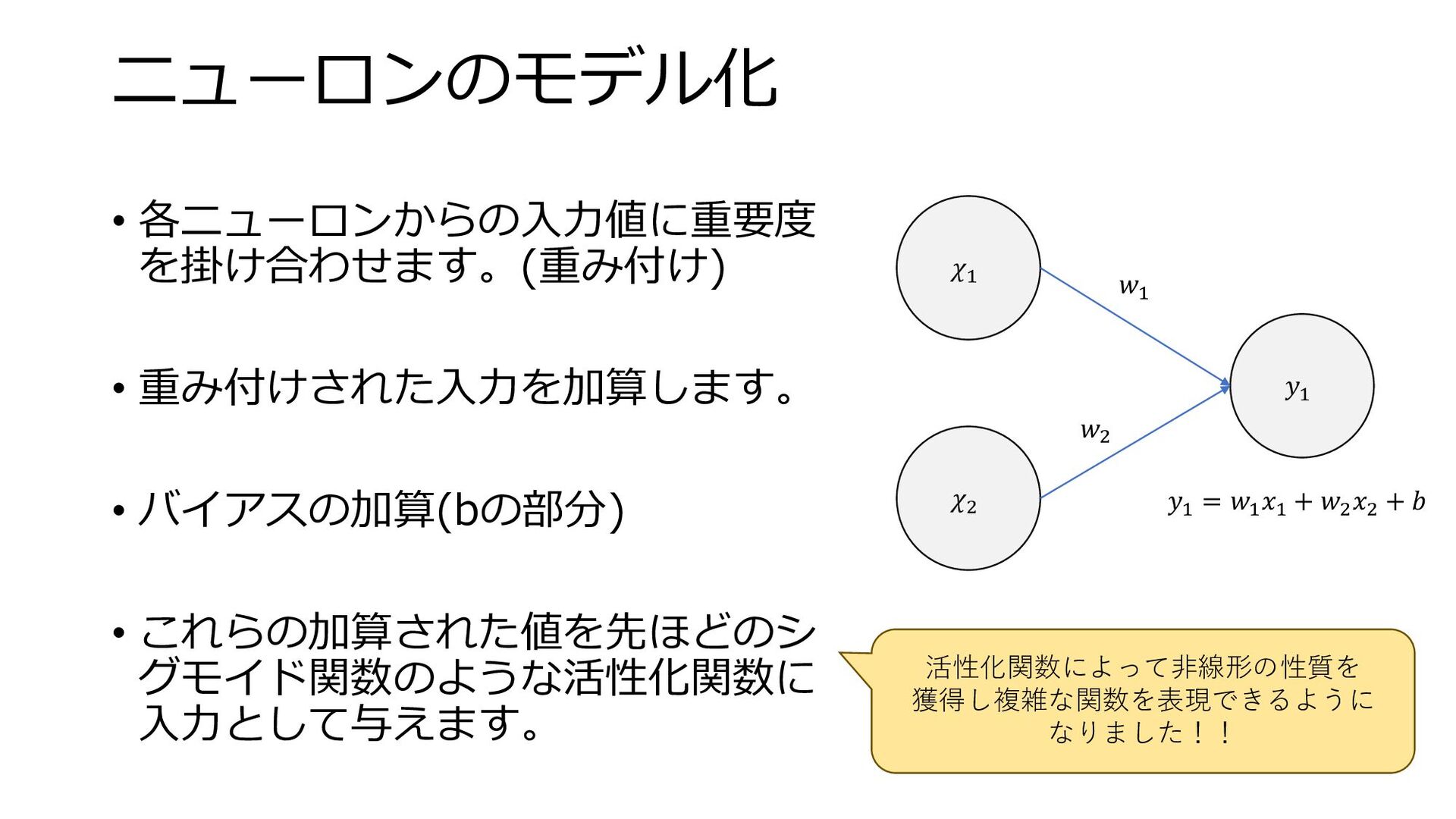
ニューロンのモデル化 • 各ニューロンからの入力値に重要度 を掛け合わせます。(重み付け) • 重み付けされた入力を加算します。 • バイアスの加算(bの部分) • これらの加算された値を先ほどのシ
グモイド関数のような活性化関数に 入力として与えます。 𝜒1 𝜒2 𝑦1 𝑤1 𝑤2 𝑦1 = 𝑤1 𝑥1 + 𝑤2 𝑥2 + 𝑏 活性化関数によって非線形の性質を 獲得し複雑な関数を表現できるように なりました!!
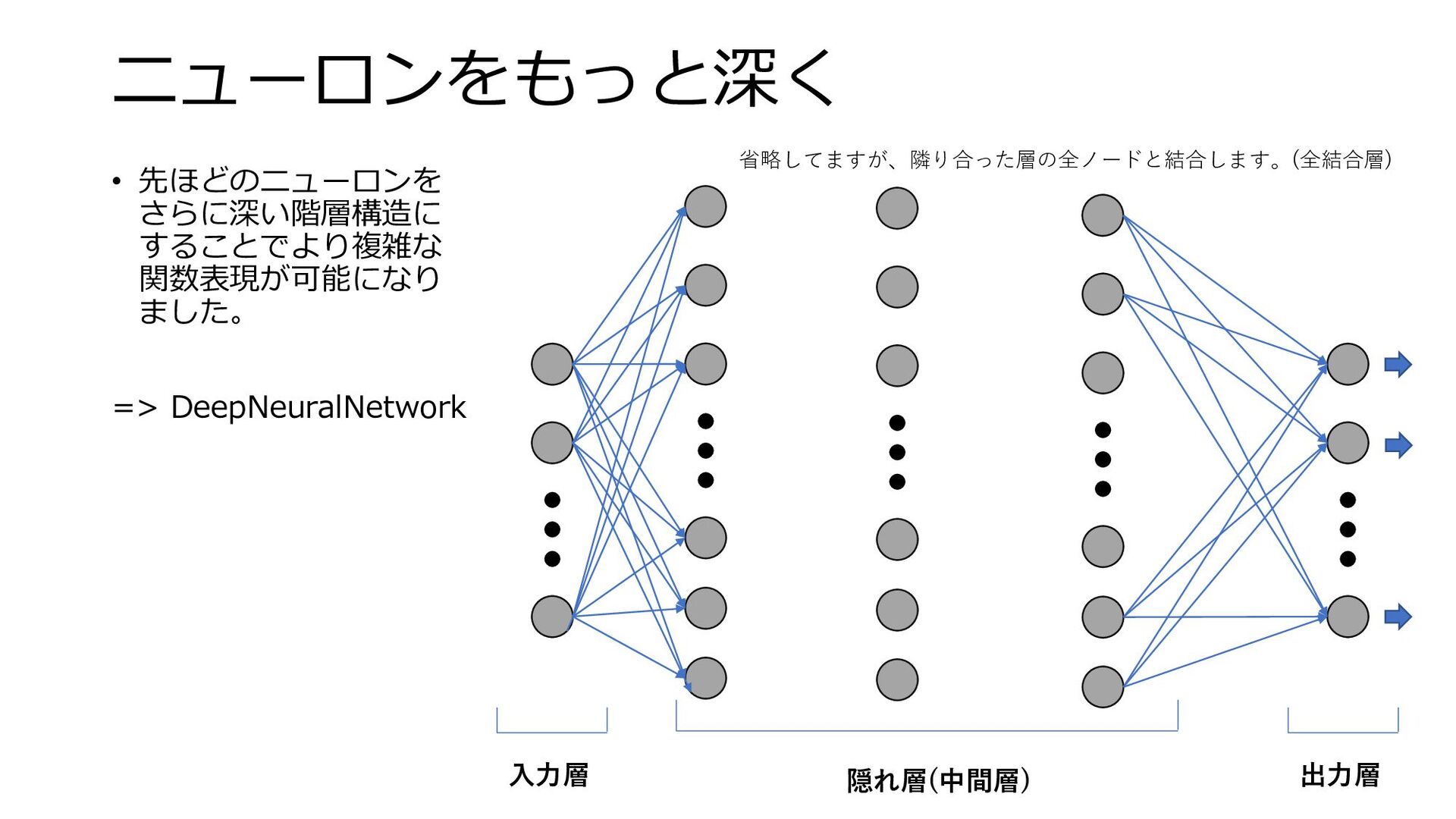
ニューロンをもっと深く • 先ほどのニューロンを さらに深い階層構造に することでより複雑な 関数表現が可能になり ました。 => DeepNeuralNetwork 入力層
出力層 隠れ層(中間層) 省略してますが、隣り合った層の全ノードと結合します。(全結合層)
NNは関数 入力層 出力層 隠れ層(中間層) 猫: 0.82 犬: 0.07 ワニ: 0.003
ニューラルネットワークまとめ • NNはヒトの脳の神経回路を模した機械学習モデル。 • NNも統計的推論と同様に関数としてふるまう。 • 重み・バイアス・活性化関数によって複雑な関数表現を獲得。 • 学習方法や固定的なニューロン構成など、実際にヒトの学習過 程とは異なるプロセスだという指摘もある。
• また、処理負荷が高いことも課題。(ヒトの脳は約20W)
大規模言語モデル
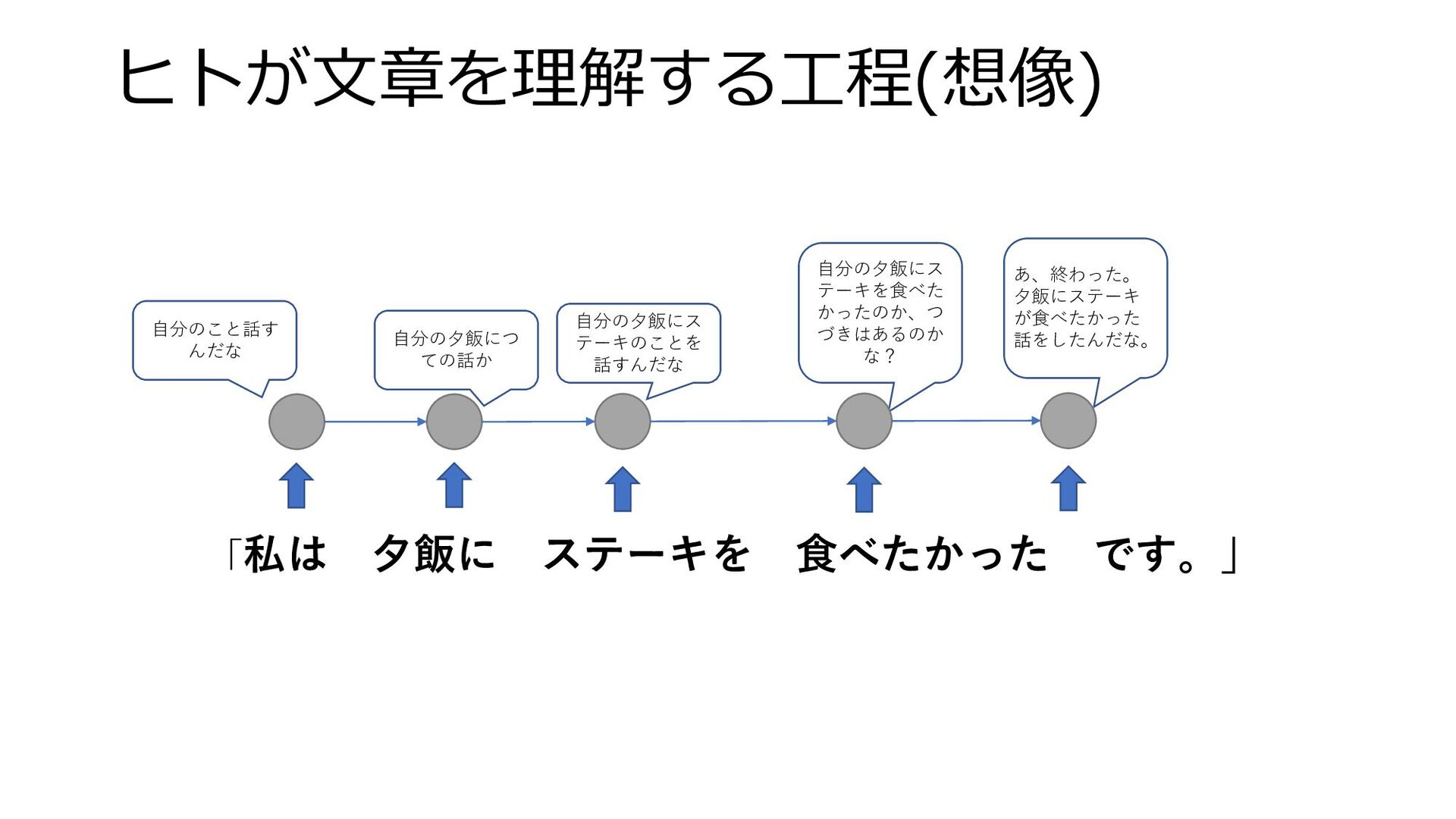
ヒトが文章を理解する工程(想像) 「私は 夕飯に ステーキを 食べたかった です。」 自分のこと話す んだな 自分の夕飯にス テーキのことを
話すんだな 自分の夕飯につ ての話か 自分の夕飯にス テーキを食べた かったのか、つ づきはあるのか な? あ、終わった。 夕飯にステーキ が食べたかった 話をしたんだな。
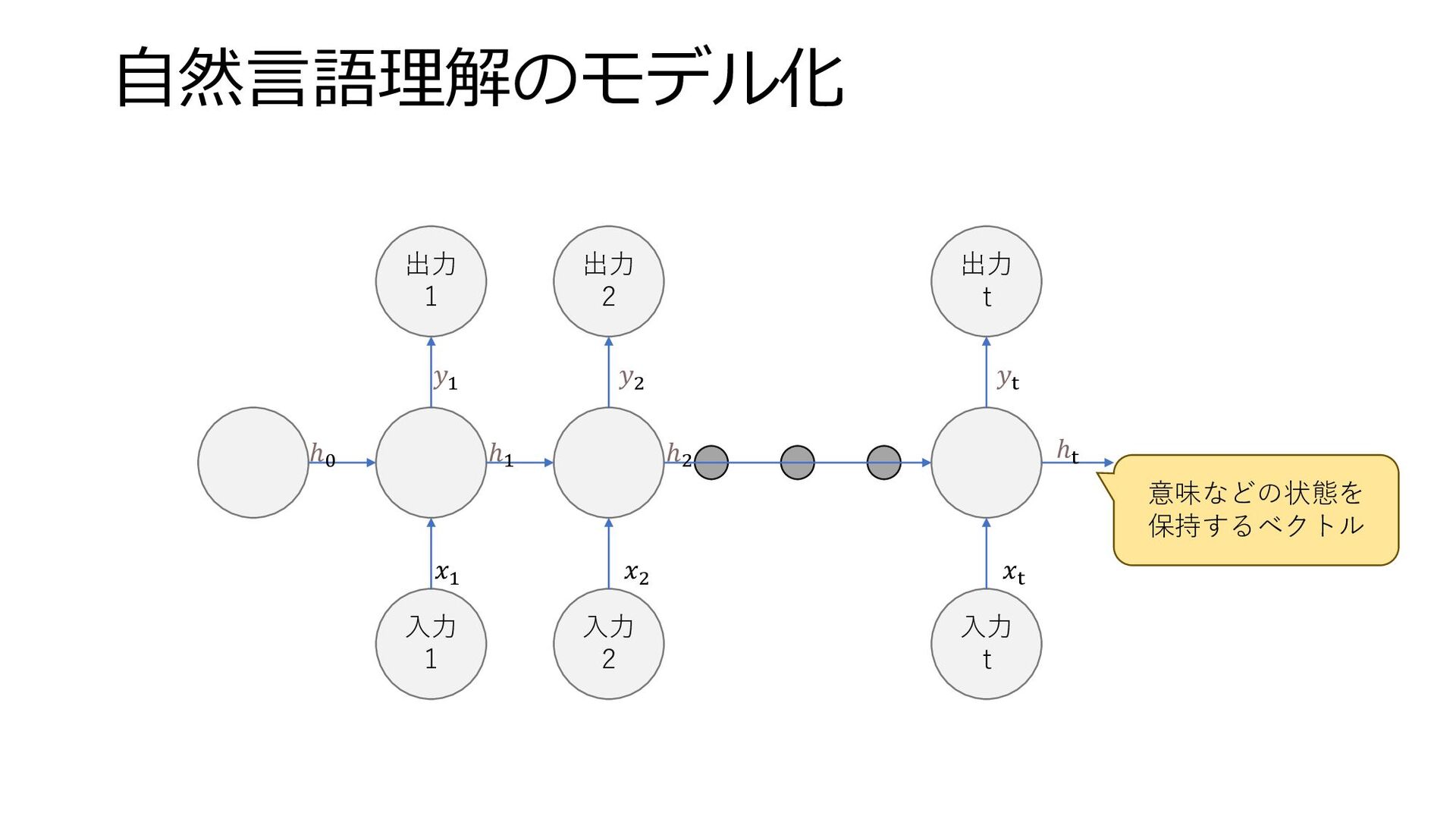
自然言語理解のモデル化 入力 1 入力 2 入力 t 出力 1 出力
2 出力 t 𝑥1 𝑥2 𝑥t 𝑦1 𝑦2 𝑦t ℎt ℎ2 ℎ1 ℎ0 意味などの状態を 保持するベクトル
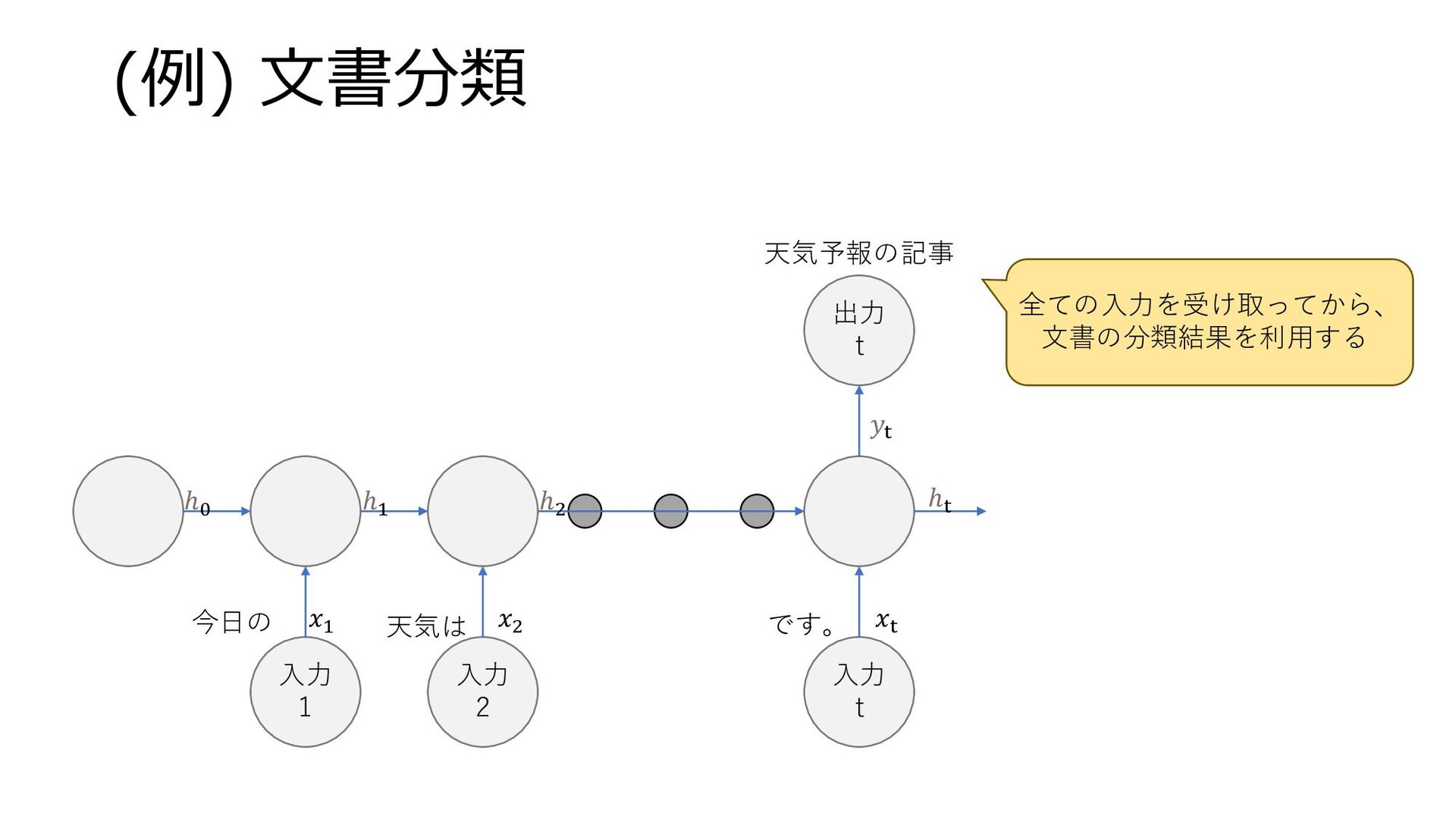
(例) 文書分類 入力 1 入力 2 入力 t 出力 t
𝑥1 𝑥2 𝑥t 𝑦t ℎt ℎ2 ℎ1 ℎ0 今日の 天気は です。 天気予報の記事 全ての入力を受け取ってから、 文書の分類結果を利用する
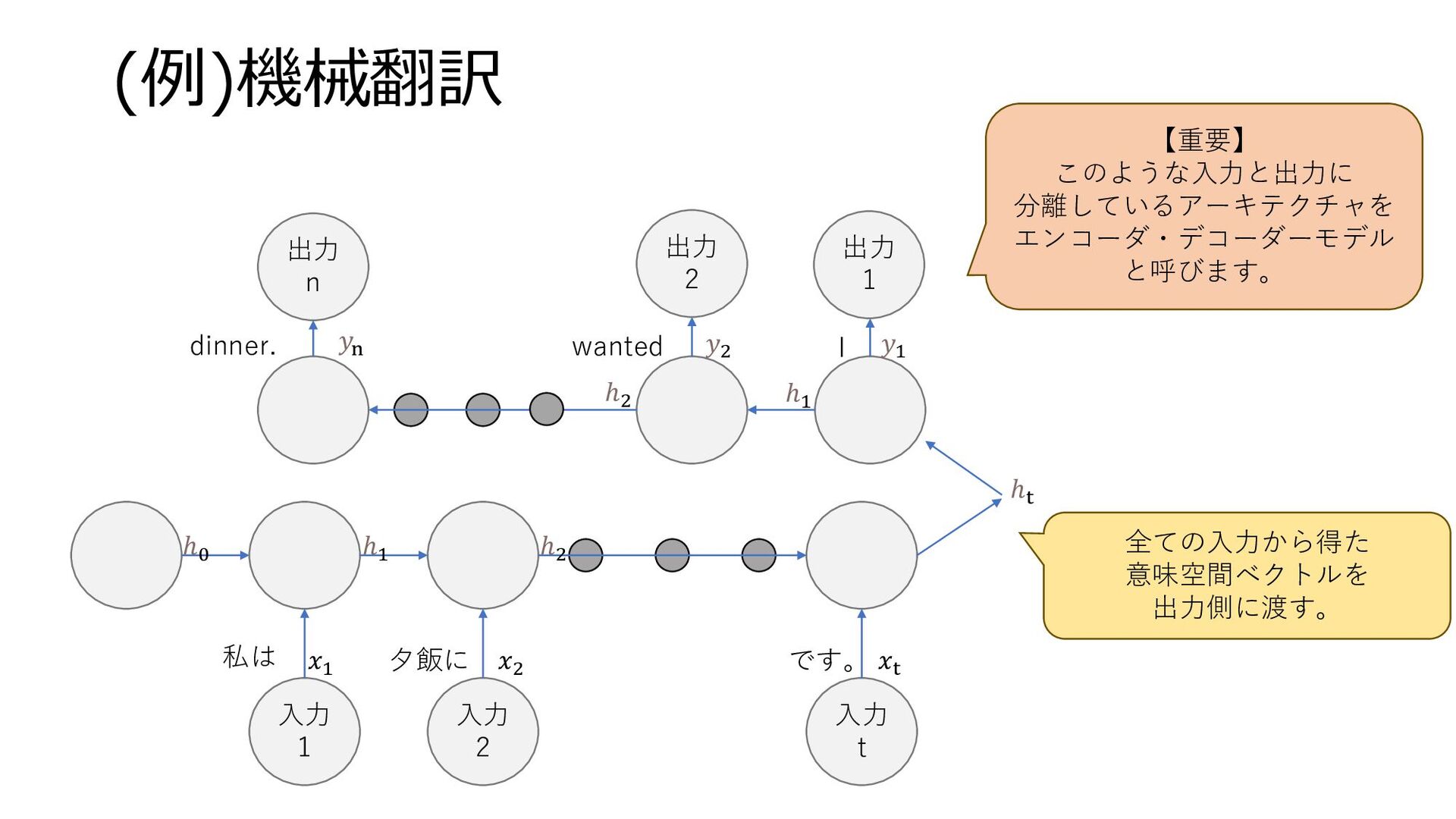
(例)機械翻訳 入力 1 入力 2 入力 t 𝑥1 𝑥2 𝑥t
ℎt ℎ2 ℎ1 ℎ0 ℎ1 ℎ2 出力 1 出力 2 出力 n 私は 夕飯に です。 I 𝑦1 𝑦2 wanted dinner. 𝑦n 全ての入力から得た 意味空間ベクトルを 出力側に渡す。 【重要】 このような入力と出力に 分離しているアーキテクチャを エンコーダ・デコーダーモデル と呼びます。
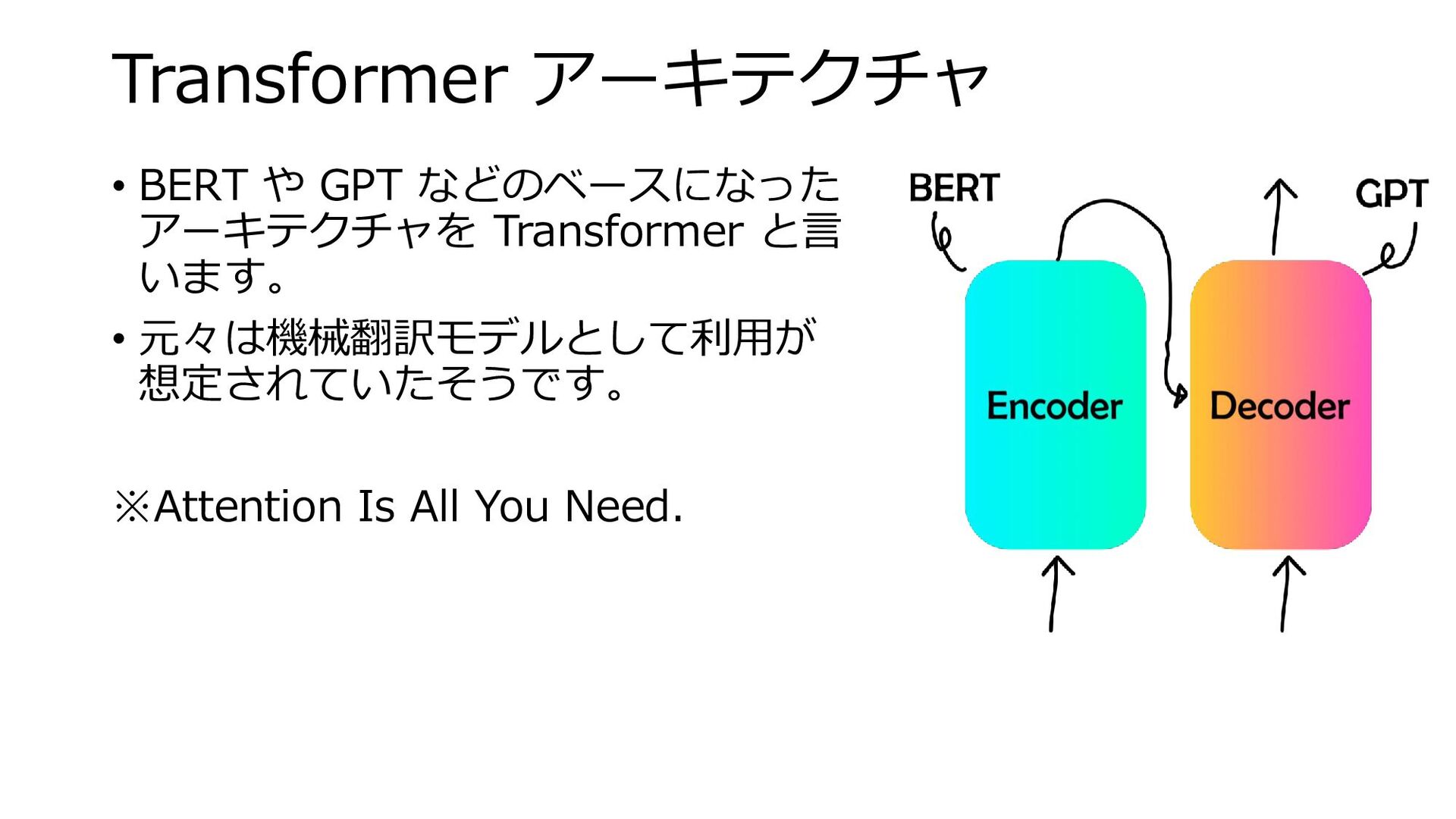
Transformer アーキテクチャ • BERT や GPT などのベースになった アーキテクチャを Transformer と言
います。 • 元々は機械翻訳モデルとして利用が 想定されていたそうです。 ※Attention Is All You Need.
GPT-n GPT(Generative Pre-trained Transformer) みなさんご存じ「ChatGPT」など対話システムや 文章の生成器として活用されています。 Pre-tarained & Fine-tunung という新しいパラダイムを作った。
特徴①: 1つのモデルで多様なタスクに対応できるようになった。 特徴②: 専門モデルを作成するための必要学習データ量が減った。
GPT-n の学習方法 次単語予測 メリット - 自然な文章の流れをモデルが学習できる。 - 単語の意味表現をモデルが獲得できる。 - ラベル付きの学習データが不要。
私は カレーを ???
BERT(バート | ベルト) BERT (Bidirectional Encoder Representations from Transformers) BERT
は様々な自然言語系のタスクで高精度のパフォーマンスを発揮したモデルです。 Google のセマンティック検索でも利用されていたり、かなり普及しています。 特徴①: 単語の意味表現を獲得。 => テキストマイニング。固有表現抽出 特徴②: 文脈の理解。 => 文書分類。
BERTの学習方法 ①マスク&推論 ②次文章予測 私は カレーを 食べたい。 [MASK] 私は カレーを 食べたい。
私は カレーを 食べたい。 [MASK] 私は カレーを 食べたい。 スーパーでカレー粉を購入した。 私は カレーを 食べたい。 私は昨年イギリスに留学した。
基盤モデル • 事前学習とファインチューニング • 言語の基礎を理解した汎用的なモデルを構築 • 専門的なデータを追加で学習させて専門的なモデルを構築 • メリット •
マシンリソースの節約 • スモールデータの活用 • OSSの基盤モデルがあるので使ってみてください。(rinnaなど)
AGIに向けて(個人的な意見) • 前提として、基盤モデルはドンドン賢くなる。 • チューニングは以前より軽量とはいえ、依然高コスト。 => チューニングよりもプロンプトエンジニアリング ※個人的意見です。 ※GPTs も同じマインドな気がします。
※後半でやる LangChain もそのためのツールです。
生成モデルの課題感 • ライセンス • 学習データ、ソースコード、モデル、生成物の著作権・ライセンス • バイアス • 学習データの偏り、学習データ品質の劣化。 •
非倫理的利用 • フェイクニュース • ウィルスソフトや兵器利用など • 技術的課題 • エネルギー消費、説明可能性。
質疑応答
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![BERTの学習方法 ①マスク&推論 ②次文章予測 私は カレーを 食べたい。 [MASK] 私は カレーを 食べたい。](https://files.speakerdeck.com/presentations/a0652a4613304c068fb1f8e8329e6dd5/slide_31.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}