incredibly fast. • With a standard configuration it never runs out of space; the oldest entries are cleared to make way for new entries. Redis doesn't do this by default, if at all. • Its entire raison d'être is caching. Single Responsibility Principal at its finest.
a locally cached version of the page. • When specified as public, cached pages will be served from a reverse proxy cache (e.g. Nginx, Varnish, Squid, rack-cache). • Returns the largest net performance gains as no rendering occurs on the application. • On Heroku you'll most likely end up using rack-cache, which still results in hits to your dynos. • More complicated to implement with pages containing user-specific data. Can be mitigated through asynchronous loading with JavaScript.
is a combination of the model name, ID, and #updated_at timestamp. • Used by default when you use a record inside a cache call, e.g. Rails.cache.fetch(@product) would look for a key like “products/18-20130418142307”. • Read up on how these will improve in Rails 4: http://bit.ly/14yQQQ5 http://blog.remarkablelabs.com/2012/12/russian-doll-caching-cache-digests-rails-4-countdown-to-2013
more segmented caching, easier to implement with lots of user-specific data. • Uses the #cache_key method on records passed to the cache call. • Equivalent to the lower-level implementation; Rails.cache.fetch()
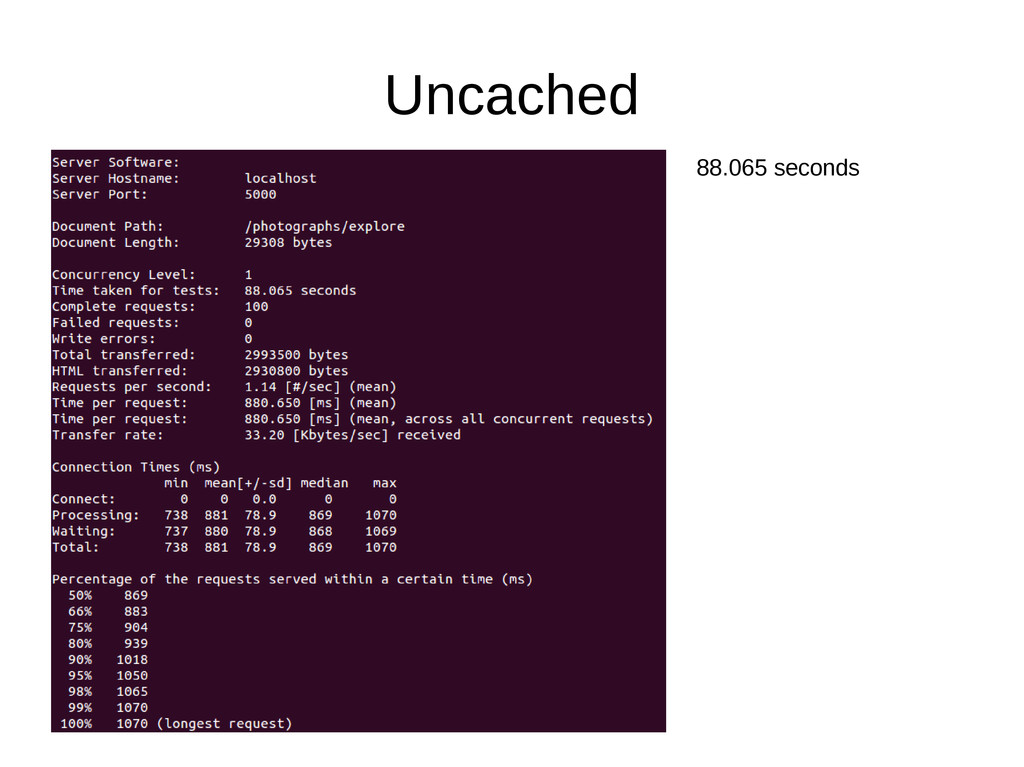
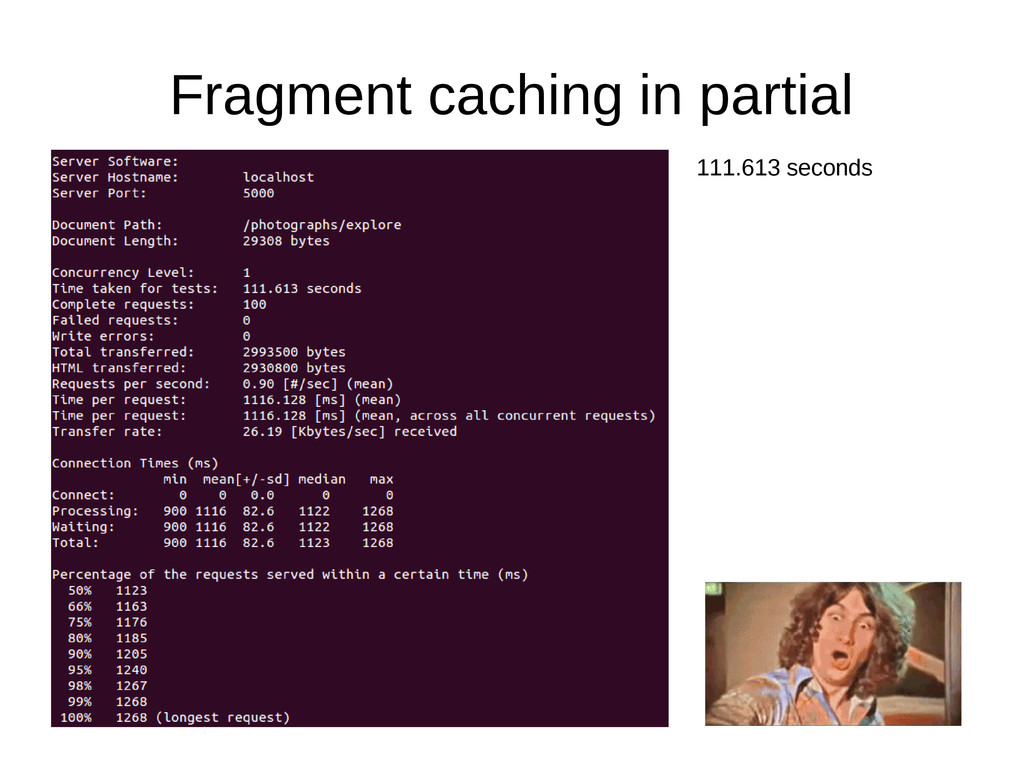
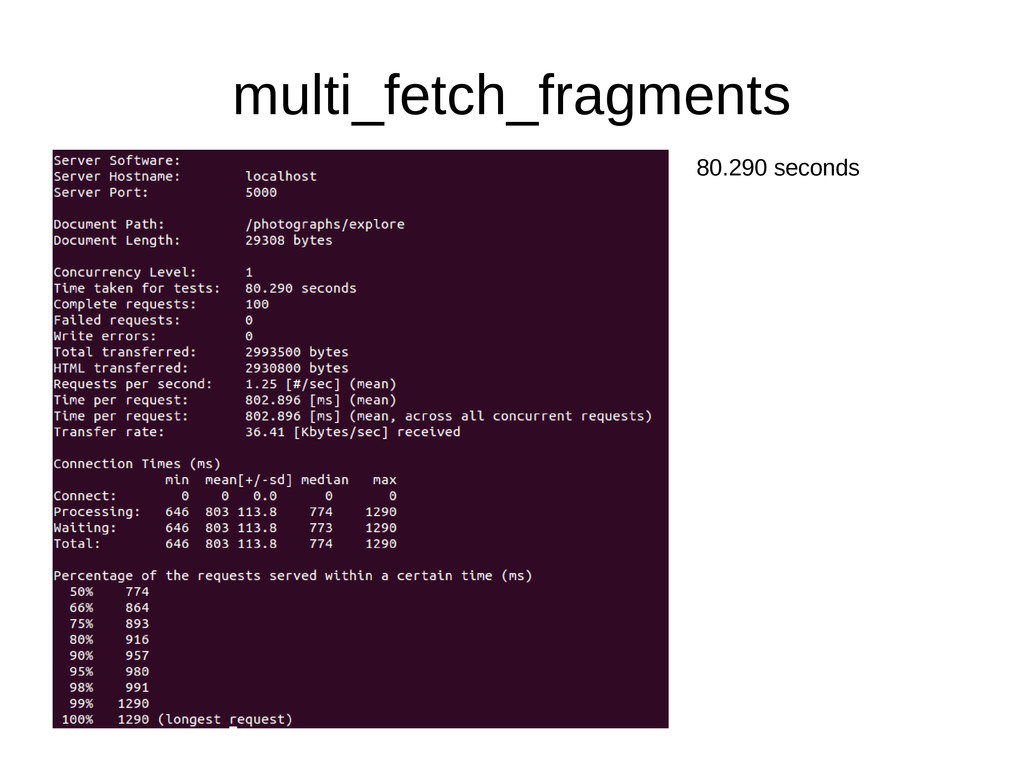
~1ms • Performing 100 cache reads on a page means ~100ms reading from the cache • Most cache libraries support a multi-read method, resulting in only a single read for those 100 items • n8/multi_fetch_fragments caches partials loaded for collections, using a multi-read. The following are examples of -n 100 -c 1 requests against a page of photographs from https://photographer.io (running locally). Running on Puma -t 4:8 on Ruby 2.0.0-p0
elsewhere in your application, e.g. in models. • Use it to cache responses from APIs, map/reduce results, etc. • Most often used via Rails.cache.fetch(), which is the same system behind fragment caching.
cache before resorting to the database. • Writes objects to the cache after being fetched from the database. • Deletes relevant cache entries when records are updated. • Currently using 'identity_cache' from Shopify. • Performance gains as simple fetches, e.g. Product.find(1) are largely offloaded to the cache.
for every foreign key, e.g. 'user_id'. • Eager load associations in queries. • Use NewRelic to assess hot spots and inefficient queries. • Ensure your assets are served from a CDN or rack-cache. • Use Puma, it's currently the fastest production-ready Ruby server. • Use Sidekiq, it's significantly faster than Resque or DelayedJob.
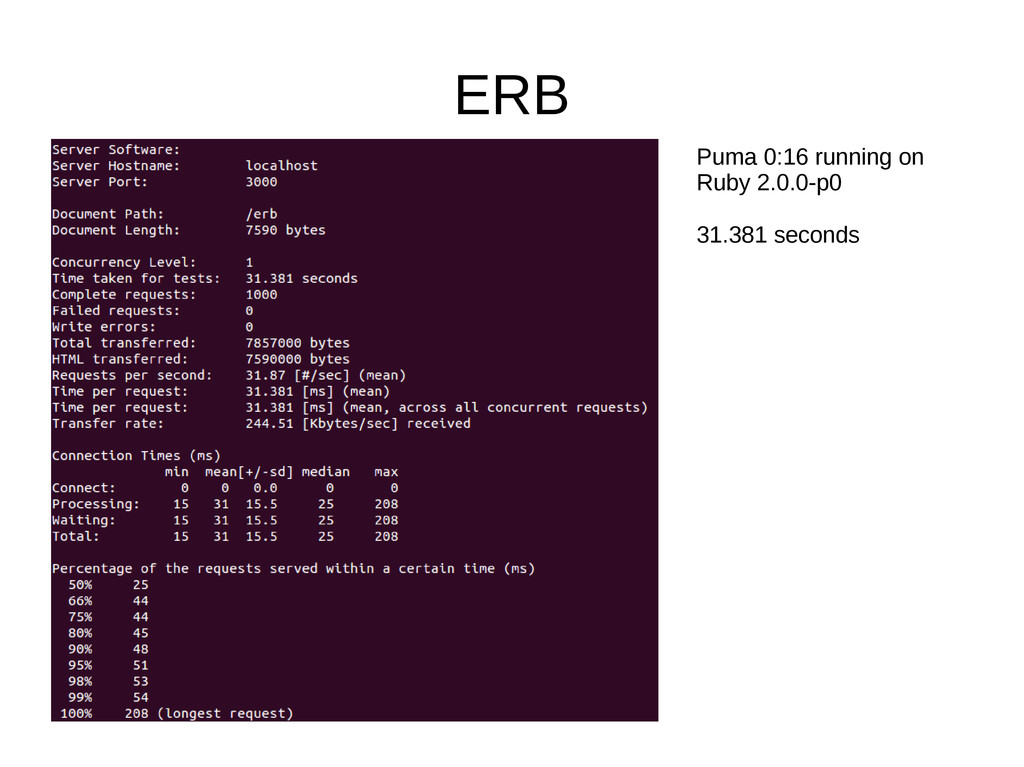
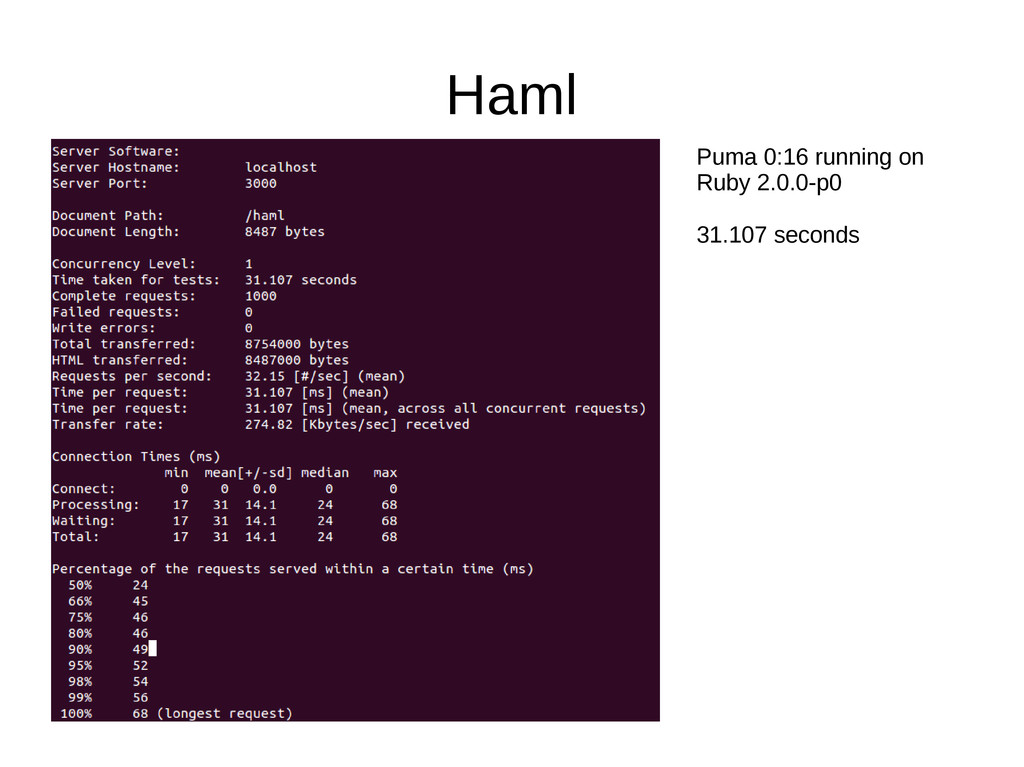
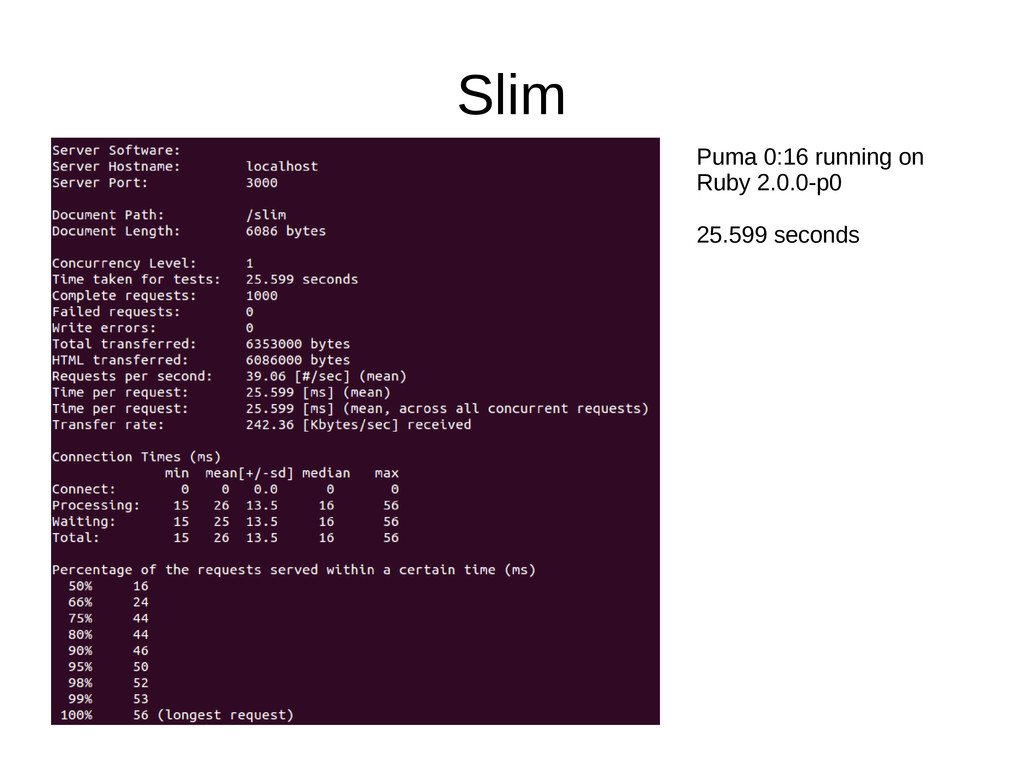
though not as much as it used to be (Haml has gotten much better) • Following benchmarks using https://github.com/klaustopher/hamlerbslim Benchmarks running on the following machine: • Ubuntu 13.04 • Ruby 2.0.0-p0 • Intel i5 2500k running at 4.2GHz • 8GB DD3 RAM • Samsung 830 128GB SSD
following thread config: – On a standard dyno (512MB RAM); 4:8 – On a large dyno (1GB RAM); 8:16 These seem to be the optimum counts from my testing when running on Ruby 2.0. You will get better performance on JRuby but your compiled slug size will be much larger and you need to use JRuby locally.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}