Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Scable Inference of Topic Models by Stochastic ...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Atom
February 20, 2019
110
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Scable Inference of Topic Models by Stochastic Gradient MCMC
文献紹介
<文献情報>
横井 創磨, 佐藤 一誠, 中川 裕志
人工知能学会誌 Vol.31 No.6 p.AI30-C_1-9, 2016
Atom
February 20, 2019
More Decks by Atom
See All by Atom
YouTubeのチャット欄の配置変更 / Changing the layout of the YouTube chat field
roraidolaurent
0
13
文献紹介 / Structure-based Knowledge Tracing: An Influence Propagation View
roraidolaurent
0
120
文献紹介 / Knowledge Tracing with GNN
roraidolaurent
0
110
文献紹介 / Non-Intrusive Parametric Reduced Order Models withHigh-Dimensional Inputs via Gradient-Free Active Subspace
roraidolaurent
0
69
ニューラルネットワークのベイズ推論 / Bayesian inference of neural networks
roraidolaurent
2
2.9k
Graph Convolutional Networks
roraidolaurent
0
260
文献紹介 / A Probabilistic Annotation Model for Crowdsourcing Coreference
roraidolaurent
0
96
文献紹介Deep Temporal-Recurrent-Replicated-Softmax for Topical Trends over Time
roraidolaurent
0
140
文献紹介/ Bayesian Learning for Neural Dependency Parsing
roraidolaurent
0
140
Featured
See All Featured
SEOcharity - Dark patterns in SEO and UX: How to avoid them and build a more ethical web
sarafernandez
0
220
Visualizing Your Data: Incorporating Mongo into Loggly Infrastructure
mongodb
49
10k
Color Theory Basics | Prateek | Gurzu
gurzu
0
390
What does AI have to do with Human Rights?
axbom
PRO
1
2.2k
Making Projects Easy
brettharned
120
6.7k
Digital Ethics as a Driver of Design Innovation
axbom
PRO
1
340
Breaking role norms: Why Content Design is so much more than writing copy - Taylor Woolridge
uxyall
0
340
Noah Learner - AI + Me: how we built a GSC Bulk Export data pipeline
techseoconnect
PRO
0
220
Collaborative Software Design: How to facilitate domain modelling decisions
baasie
1
260
コードの90%をAIが書く世界で何が待っているのか / What awaits us in a world where 90% of the code is written by AI
rkaga
62
45k
Raft: Consensus for Rubyists
vanstee
141
7.6k
Impact Scores and Hybrid Strategies: The future of link building
tamaranovitovic
0
340
Transcript
Stochastic Gradient MCMC による スケーラブルなトピックモデルの推定 横井 創磨, 佐藤 一誠, 中川
裕志 文献紹介 2019/2/20 長岡技術科学大学 自然言語処理研究室 吉澤 亜斗武 人工知能学会誌 Vol.31 No.6 p.AI30-C_1-9, 2016
1. 概要 ・バッチ学習である周辺化ギブスサンプリング法(CGS)で提案 されてきた効率的なサンプル方法をstochastic gradient MCMCに使うことで,データとトピックの両方にスケーラブ ルに対応した新しいトピックモデルの推定方法を提案 ・バッチ学習における従来のMCMCのSotAよりも優れた効率・ 更新速度であることを実証した 2
2. はじめに ・伝統的なMCMCではデータサイズとトピック数が大きい場合 現実的な時間内にトピックモデルを推定できないという問題が あり,CGSを中心に改善が行われてきた. ・トピック数に関してはSparseLDA, AliasLDA, LightLDA など の手法が有効であると確認されている.
・データサイズに関しては,分割して計算を行った後に統合する という手法が提案されているが,収束が保証されない 3
2. はじめに ・ stochastic gradient MCMC はオンライン変分ベイズ法よりも 性能が良く,CGSが実行できないような大規模なデータにおい ても高速に実行が可能 ・効率的なサンプル方法をstochastic
gradient MCMC に最適化 することで,データサイズ・トピック数ともにスケール可能な 推定方法を提案 4
3. 関連研究(Latent Dirichlet Allocation) 5 LDAにおける単語確率の生成過程 (1) for トピック a
単語分布 ~Dir() (2) for 文書 a トピック分布 ~Dir() b for 番目のトークン in 文書 ⅰ. トピック ~Multi( ) ⅱ. 単語 ~Multi( )
3. 関連研究( SparseLDA, AliasLDA, LightLDA ) 6 SparseLDA:トピック数が大きいほどスパース性が現れること を利用し,非ゼロのみを計算(CGSの改善) AliasLDA
: SparseLDAにalias法とMH法を適用したもの 前処理でalias table を作り,それによりサンプリング メトロポリス・ヘイスティング法の棄却補正 LightLDA :AliasLDAにcycle proposal を適用してもの 因数ごとに交互にサンプリングをする
3. 関連研究(SGRLD) 7 ・stochastic gradient Riemannian Langevin dynamics ミニバッチでのサンプリングを可能とするSGLDを単体上の 確率ベクトルへ拡張したもの
・ Langevin Monte Carlo を確率的勾配降下法に拡張したもの ・正規化されていない単語分布に相当するパラメータについて ミニバッチごとに次の式で更新を行う
3. 関連研究(SGRLD) 8 ∗ = + 2 − + +
1 2 = � ∈ |,, [ − ] ステップサイズ = 1 + − , 正規化定数 , ノイズ コーパス全体のデータ , サブサンプルされたミニバッチデータ
・AliasLDAとLightLDAをSGRLDに最適化した, AliasSGRLDとLightSGRLD を提案. ・提案手法はalias tableをイテレーションにおいて使いまわせる ことを理論的に示されたものであり,サンプル数を確保できる 9 4. 提案手法
10 4. 提案手法 :コーパスに含まれているトピック数 :文書に含まれているトピック数
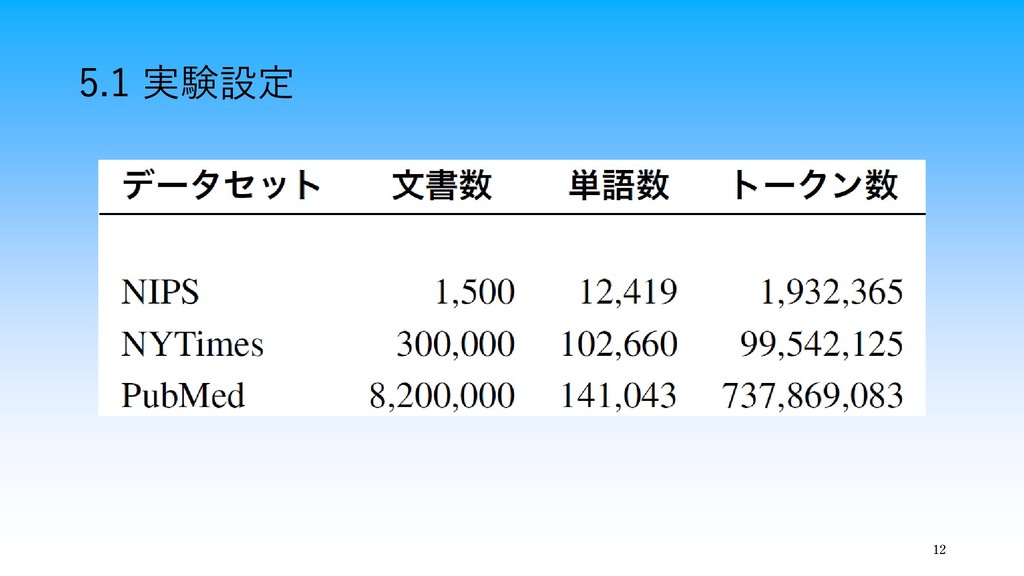
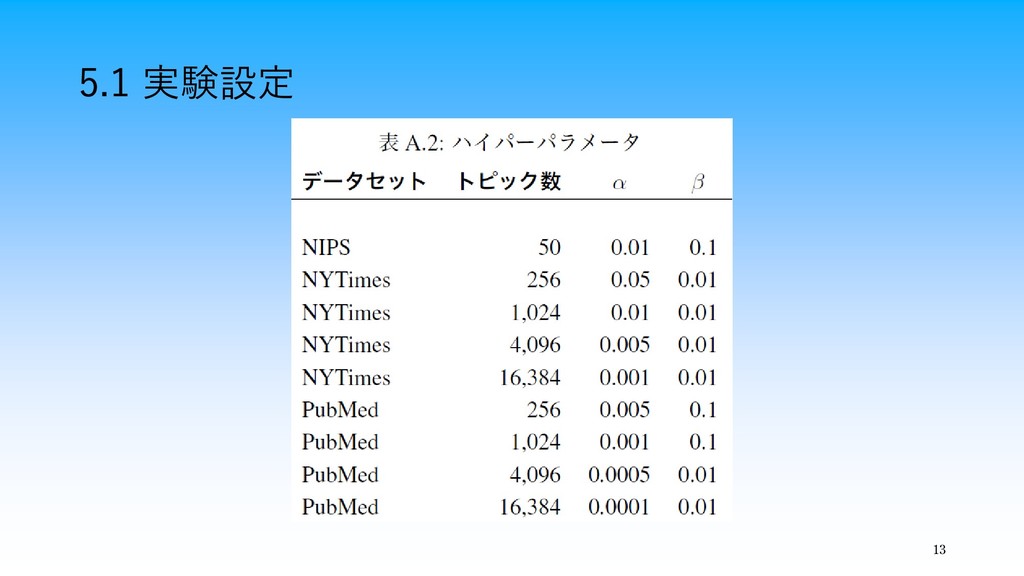
11 5.1 実験設定 ・ベースライン:SGRLD ・提案手法:AliasSGRLD, LightSGRLD ・データセット:NIPS, NYTimes, PubMed ・ミニバッチのデータ数
:24,000単語 ・イテレーション回数:200回, バーンイン回数:100回 ・ステップサイズ: =0.001, =10000, =0.6
12 5.1 実験設定
13 5.1 実験設定
14 5.1 実験設定 ・学習の評価: コーパスから予め除外したテストデータを用いてperplexity (学習した単語確率とテストデータの単語頻度の相違の程度) によって評価 perp = exp(−
∑𝑤𝑤𝑖𝑖 log(𝑖𝑖 |𝑡𝑡 , , ) )
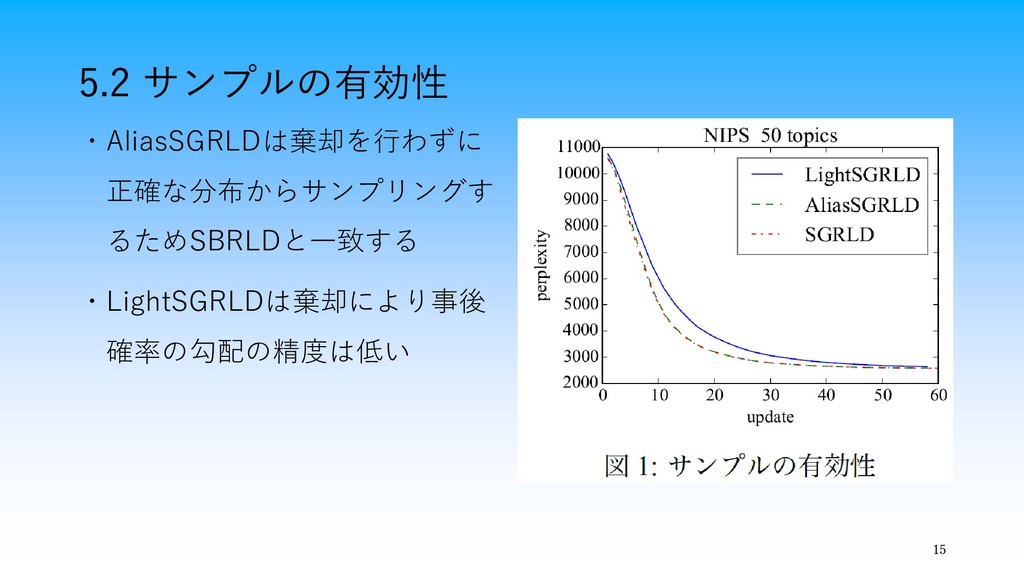
15 5.2 サンプルの有効性 ・AliasSGRLDは棄却を行わずに 正確な分布からサンプリングす るためSBRLDと一致する ・LightSGRLDは棄却により事後 確率の勾配の精度は低い
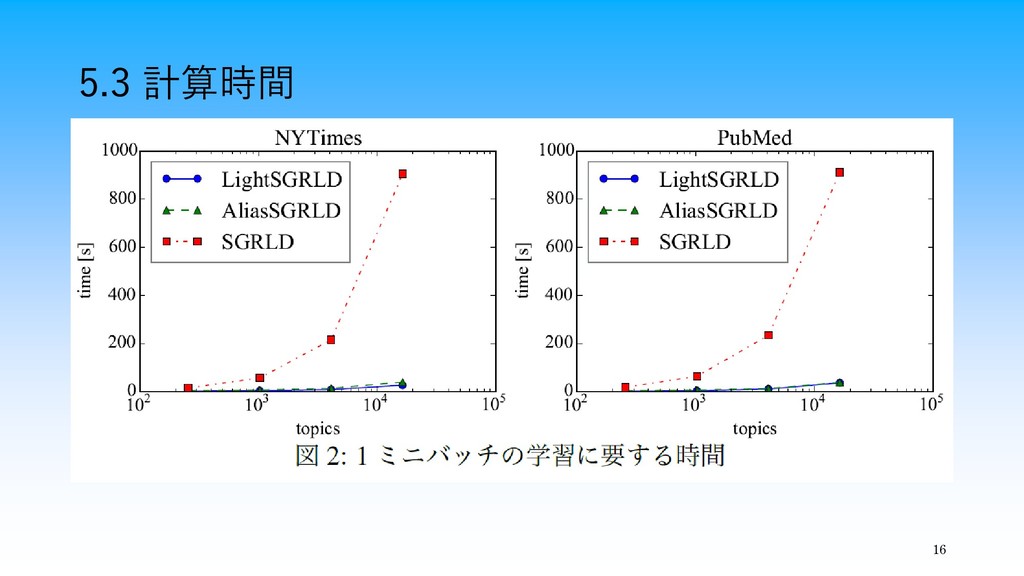
16 5.3 計算時間
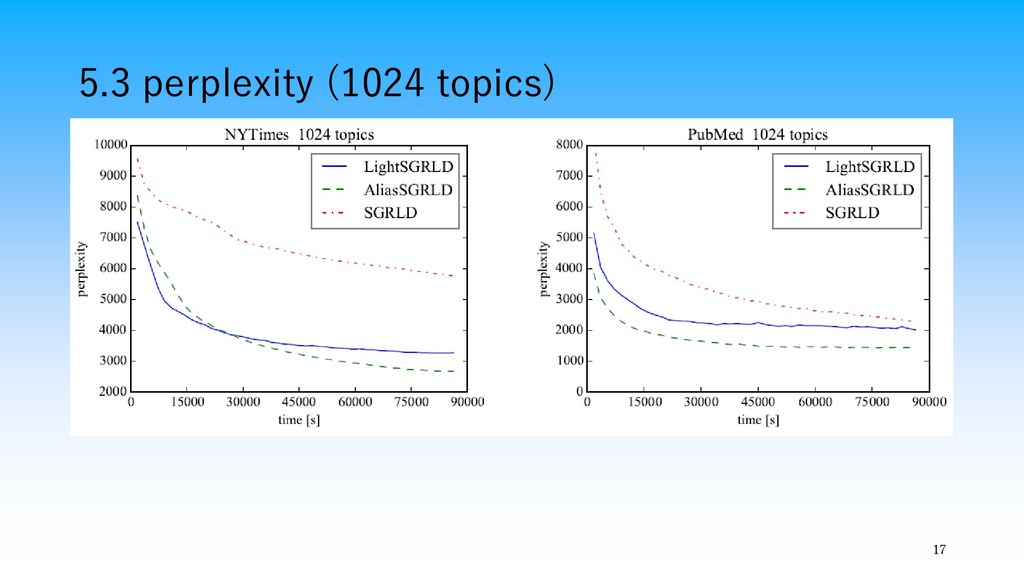
17 5.3 perplexity (1024 topics)
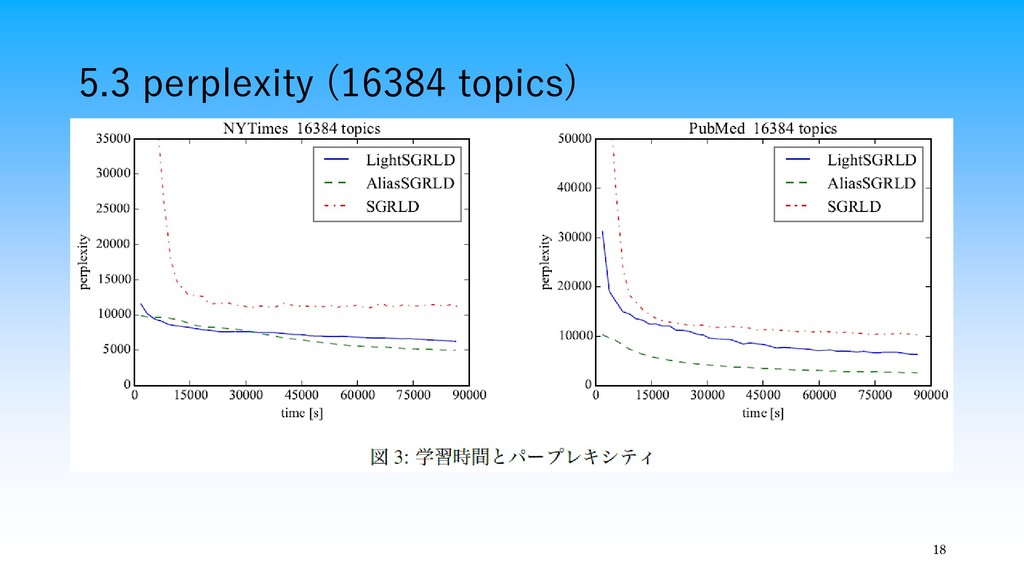
18 5.3 perplexity (16384 topics)
・CGSで提案されてきた効率的なサンプル方法をstochastic gradient MCMCに使うことで,スケーラブルなトピックモデ ルの推定方法を提案 ・提案手法は大規模コーパスかつトピックス数が大きい状況でも 高速に実行可能 ・特にAliasSGRLDは収束・更新速度ともに優れていることを 確認した 19 6.
まとめ
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}