Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
TF-IDF
Search
Atom
March 07, 2019
130
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
TF-IDF
Atom
March 07, 2019
More Decks by Atom
See All by Atom
YouTubeのチャット欄の配置変更 / Changing the layout of the YouTube chat field
roraidolaurent
0
13
文献紹介 / Structure-based Knowledge Tracing: An Influence Propagation View
roraidolaurent
0
120
文献紹介 / Knowledge Tracing with GNN
roraidolaurent
0
110
文献紹介 / Non-Intrusive Parametric Reduced Order Models withHigh-Dimensional Inputs via Gradient-Free Active Subspace
roraidolaurent
0
69
ニューラルネットワークのベイズ推論 / Bayesian inference of neural networks
roraidolaurent
2
2.9k
Graph Convolutional Networks
roraidolaurent
0
260
文献紹介 / A Probabilistic Annotation Model for Crowdsourcing Coreference
roraidolaurent
0
96
文献紹介Deep Temporal-Recurrent-Replicated-Softmax for Topical Trends over Time
roraidolaurent
0
140
文献紹介/ Bayesian Learning for Neural Dependency Parsing
roraidolaurent
0
140
Featured
See All Featured
Leadership Guide Workshop - DevTernity 2021
reverentgeek
1
320
Marketing Yourself as an Engineer | Alaka | Gurzu
gurzu
0
260
Speed Design
sergeychernyshev
33
1.9k
Dealing with People You Can't Stand - Big Design 2015
cassininazir
367
27k
From π to Pie charts
rasagy
0
230
Technical Leadership for Architectural Decision Making
baasie
3
440
Are puppies a ranking factor?
jonoalderson
1
3.7k
Put a Button on it: Removing Barriers to Going Fast.
kastner
60
4.4k
Balancing Empowerment & Direction
lara
6
1.2k
SEO in 2025: How to Prepare for the Future of Search
ipullrank
3
3.6k
A Modern Web Designer's Workflow
chriscoyier
698
190k
How To Stay Up To Date on Web Technology
chriscoyier
790
250k
Transcript
TF-IDF法 文書検索の基礎 第9回 B3勉強会 2019/3/7 長岡技術科学大学 自然言語処理研究室 吉澤 亜斗武
参考文献・資料 [1] 黒橋禎夫,柴田知秀:自然言語処理概論,サイエンス社(2016) [2] Dheeraj Mekala et al. : Sparse
Composite Document Vectors using soft clustering over distributional representations https://www.arxiv-vanity.com/papers/1612.06778/ [3] @fufufukakaka :文書ベクトルをお手軽に高い精度で作れるSCDVって実際 どうなのか日本語コーパスで実験した(EMNLP2017) https://qiita.com/fufufukakaka/items/a7316273908a7c400868 2
Contents (1) 転置インデックス (2) 語の重要度(TF-IDF法) (3) TF-IDF法における文書ベクトル (4) SCDVについて 3
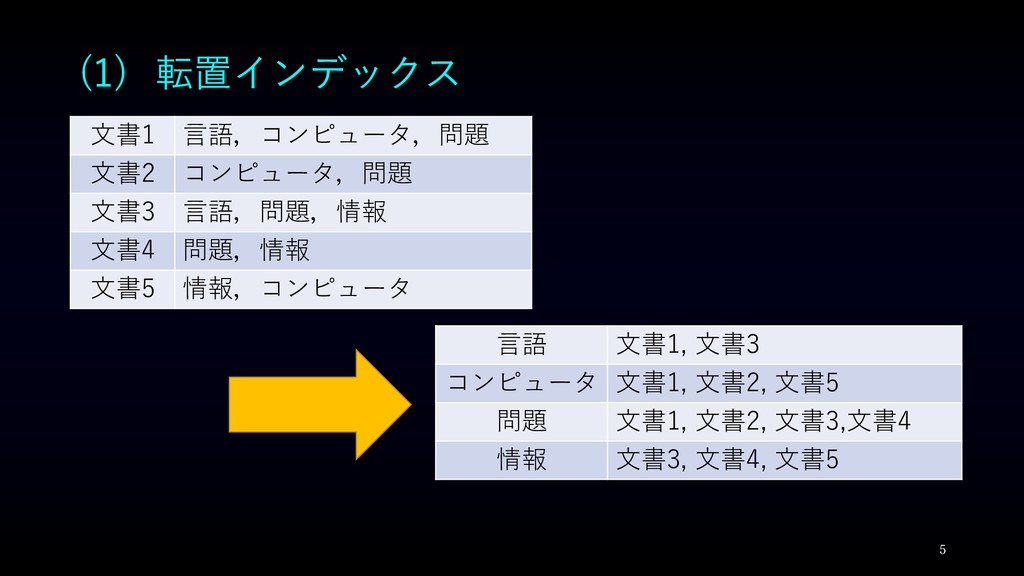
(1) 転置インデックス 転置インデックス(inversed index) ・単語がどの文書に出現するかを事前に調べて置き, 索引としたもの. ・出現位置などもインデックスしているものもあり, 複合語などの検索も可能となる. 4
(1) 転置インデックス 5 文書1 言語,コンピュータ,問題 文書2 コンピュータ,問題 文書3 言語,問題,情報 文書4
問題,情報 文書5 情報,コンピュータ 言語 文書1, 文書3 コンピュータ 文書1, 文書2, 文書5 問題 文書1, 文書2, 文書3,文書4 情報 文書3, 文書4, 文書5
(2) 語の重要度(TF-IDF法) 6 クエリ(query):検索したい語集合や自然文 文書をクエリに対する関連度によってランキングしたい. → 語の重要度に基づいて関連度を計算する. TF(term frequency):文書 における語
の頻度 , TFが大きいほど,その文書と語は強く関連している.
(2) 語の重要度(TF-IDF法) 7 DF(document frequency):ある語 を含む文書の頻度 IDF(inversed document frequency) DFの逆数に対数をとったもの.
𝑖𝑖𝑖𝑖 = log 𝑑𝑑 −1 IDFが大きいほど,語 は稀な頻度で文書に現れることを表す. TF-IDF法:語の重要度を以下のように定義する. 𝑡𝑡 , × 𝑖𝑖𝑖𝑖
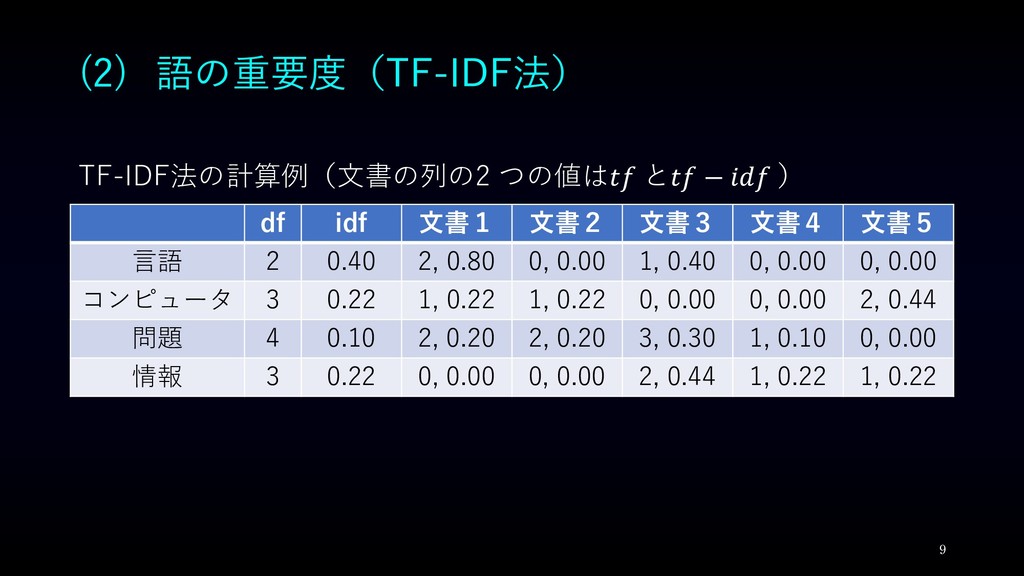
(2) 語の重要度(TF-IDF法) 8 先ほどの転置インデックスを例にして, TF-IDFを求めてみる. 簡単のため,TFを頻度ではなく,出現回数とする. 例えば,「文書1」に対する「言語」の重要度を求める. 𝑡𝑡 言語, 文書1
= 2 とし, 𝑖𝑖𝑖𝑖 言語 = log 2 5 −1 ≅ 0.40 ∴ 𝑡𝑡 言語, 文書1 × 𝑖𝑖𝑖𝑖 言語 = 0.80
(2) 語の重要度(TF-IDF法) 9 df idf 文書1 文書2 文書3 文書4 文書5
言語 2 0.40 2, 0.80 0, 0.00 1, 0.40 0, 0.00 0, 0.00 コンピュータ 3 0.22 1, 0.22 1, 0.22 0, 0.00 0, 0.00 2, 0.44 問題 4 0.10 2, 0.20 2, 0.20 3, 0.30 1, 0.10 0, 0.00 情報 3 0.22 0, 0.00 0, 0.00 2, 0.44 1, 0.22 1, 0.22 TF-IDF法の計算例(文書の列の2 つの値は𝑡𝑡 と𝑡𝑡 − 𝑖𝑖𝑖𝑖 )
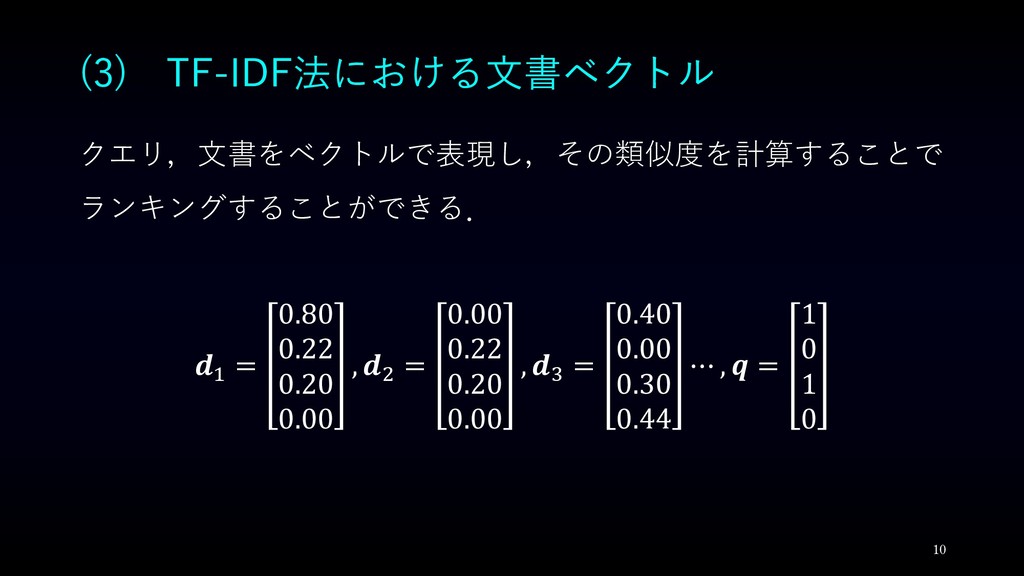
(3) TF-IDF法における文書ベクトル 10 クエリ,文書をベクトルで表現し,その類似度を計算することで ランキングすることができる. 1 = 0.80 0.22 0.20
0.00 , 2 = 0.00 0.22 0.20 0.00 , 3 = 0.40 0.00 0.30 0.44 ⋯ , = 1 0 1 0
(3) TF-IDF法における文書ベクトル 11 cos 1 , = 0.83 cos 2
, = 0.48 cos 3 , = 0.74 cos 4 , = 0.30 cos 5 , = 0.00 検索のランキングは,文書1,文書3,文書2,文書4,文書5 となる.
(3) TF-IDF法における文書ベクトル 12 問題点:言語の構造や意味(多義性や同義性)を考慮してない TF, IDFによる類似度の計算方法を変えたり, Word2Vec, Doc2Vec, SCDV, DoCoVを用いるなどの手法を用い
て類似文書検索を模索しているのが現状.
(4) SCDVについて 13 SCDV(Sparse Composite Document Vectors) word2vecのベクトル空間を混合ガウスモデルを用いてクラスタ リングして、各単語がどのトピックに属しているのか、それを考 慮したベクトル空間に修正し,スパース性を持たせたもの.
(4) SCDVについて 14 引用[2]
(4) SCDVについて 15 引用[2]
{kind=link}
![参考文献・資料 [1] 黒橋禎夫,柴田知秀:自然言語処理概論,サイエンス社(2016) [2] Dheeraj Mekala et al. : Sparse](https://files.speakerdeck.com/presentations/dd5e24b6feee46dbb75ec5035c1cd07b/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![(4) SCDVについて 14 引用[2]](https://files.speakerdeck.com/presentations/dd5e24b6feee46dbb75ec5035c1cd07b/slide_13.jpg){kind=link}
![(4) SCDVについて 15 引用[2]](https://files.speakerdeck.com/presentations/dd5e24b6feee46dbb75ec5035c1cd07b/slide_14.jpg){kind=link}