We could easily overfit machine learning with the data we have, but the quest to reduce the generalization errors, have pushed the Machine Learning researchers to implement new algorithms, and one of the criteria in Supervised Machine Learning, the balance of data distributions is important, but most of the real-life datasets are imbalanced, and this gives the zeal to study new algorithms to drive business and research forward. There are various methods at the data level and at algorithm level that solves this problem, we will discuss both of them and try to implement both the methods, in this hands-on session.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
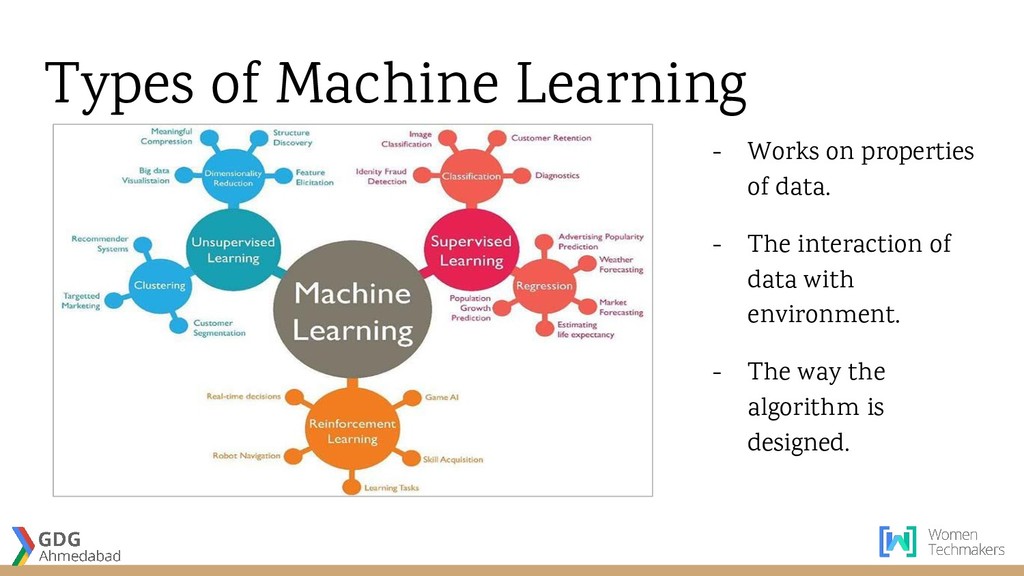{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
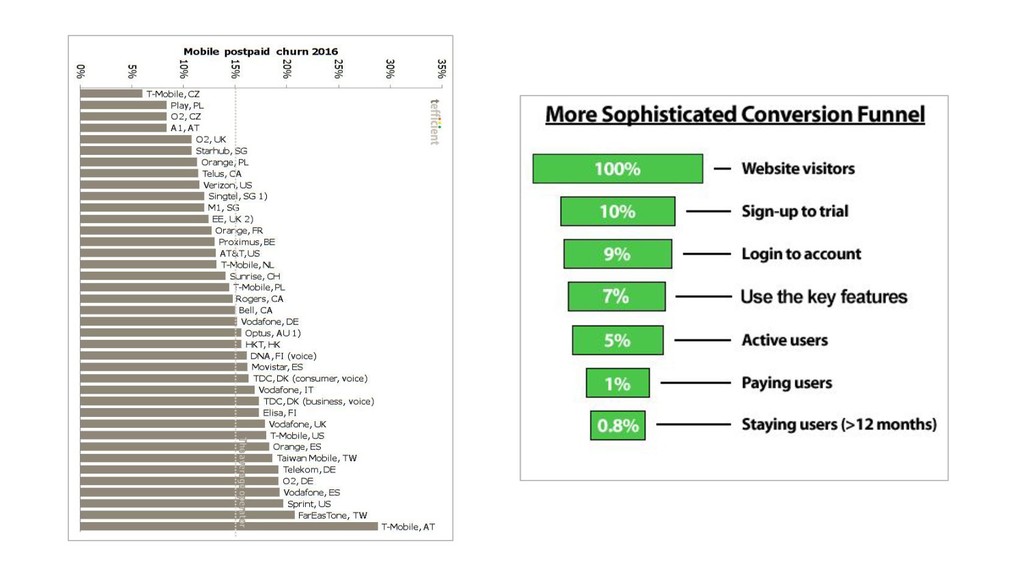{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}