Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
ビッグデータ処理データベースの全体像と使い分け 2018年version
Search
Recruit Technologies
September 21, 2018
Technology
1.6k
3
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
ビッグデータ処理データベースの全体像と使い分け 2018年version
2018/09/21_db tech showcase Tokyo 2018での、渡部の講演資料になります
Recruit Technologies
September 21, 2018
More Decks by Recruit Technologies
See All by Recruit Technologies
障害はチャンスだ! 障害を前向きに捉える
rtechkouhou
1
780
Flutter移行の苦労と、乗り越えた先に得られたもの
rtechkouhou
3
12k
ここ数年間のタウンワークiOSアプリのエンジニアのチャレンジ
rtechkouhou
1
1.6k
大規模環境をAWS Transit Gatewayで設計/移行する前に考える3つのポイントと移行への挑戦
rtechkouhou
1
2k
【61期 新人BootCamp】TOC入門
rtechkouhou
3
42k
【RTC新人研修 】 TPS
rtechkouhou
1
42k
Android Boot Camp 2020
rtechkouhou
0
42k
HTML/CSS
rtechkouhou
10
52k
TypeScript Bootcamp 2020
rtechkouhou
9
46k
Other Decks in Technology
See All in Technology
プロダクトだけじゃない、社内プロセスにおける自動化・省力化ノススメ
kakehashi
PRO
1
3.7k
cccccc
moznion
0
1.9k
Mastraエージェント、どのクラウドにデプロイする?
minorun365
PRO
2
180
なぜ私たちのSREプラクティスはなかなか機能しないのか 〜システムより先に組織を見る〜 / Why our SRE practices aren't really working
vtryo
3
3.7k
[2026-07-15] AI Ready なはずだったアーキテクチャと、見えてきた課題・次に目指す状態
wxyzzz
7
3.5k
Databricks 生成AIガバナンス実践ワークショップ / LLMOps-workshop
databricksjapan
0
110
SRE Next 2026 何でも屋からの脱却
bto
0
710
環境凍結という Toil を倒す -セルフサービス型 Ephemeral テスト環境の 設計と実践
shirouz
1
2.4k
End-to-Endで考える信頼性 — LINEアプリにおける クライアント開発×SRE連携の実践
maruloop
4
4.2k
AICoEでAIネイティブ組織への進化
yukiogawa
0
170
ボーイスカウトルールでメモリやスキルを改善しよう
azukiazusa1
4
1.1k
ソニー銀行におけるビジネスアジリティ向上のためのクラウドシフト戦略
srenext
0
240
Featured
See All Featured
The State of eCommerce SEO: How to Win in Today's Products SERPs - #SEOweek
aleyda
2
11k
Hiding What from Whom? A Critical Review of the History of Programming languages for Music
tomoyanonymous
3
930
Bootstrapping a Software Product
garrettdimon
PRO
307
120k
Utilizing Notion as your number one productivity tool
mfonobong
4
390
Imperfection Machines: The Place of Print at Facebook
scottboms
270
14k
Building Applications with DynamoDB
mza
96
7.1k
実際に使うSQLの書き方 徹底解説 / pgcon21j-tutorial
soudai
PRO
201
75k
The Power of CSS Pseudo Elements
geoffreycrofte
82
6.4k
Digital Ethics as a Driver of Design Innovation
axbom
PRO
1
340
Facilitating Awesome Meetings
lara
57
7k
Unsuck your backbone
ammeep
672
58k
Leo the Paperboy
mayatellez
8
1.9k
Transcript
(C) Recruit Technologies Co.,Ltd. All rights reserved. ビッグデータ処理データベースの全体像と使い分け 2018年version 2018/9/21
株式会社リクルートテクノロジーズ データテクノロジーラボ部 渡部徹太郎 db tech showcase Tokyo 2018
(C) Recruit Technologies Co.,Ltd. All rights reserved. 自己紹介 {"ID" :"fetaro"
"名前":"渡部 徹太郎" "研究":"東京工業大学でデータベースと情報検索の研究" "仕事":{前職:["証券会社のオンライントレードシステムのWeb基盤", "オープンソースなら何でも。主にMongoDB,NoSQL"], 現職:["リクルート分析基盤のプラットフォームリーダ, BigQuery, Hortonworks, Oracle Exadata, EMR"] 副業:["コンサルタント,非常勤講師" ]} "エディタ":"emacs派", "趣味": ["自宅サーバ","麻雀"] } 1
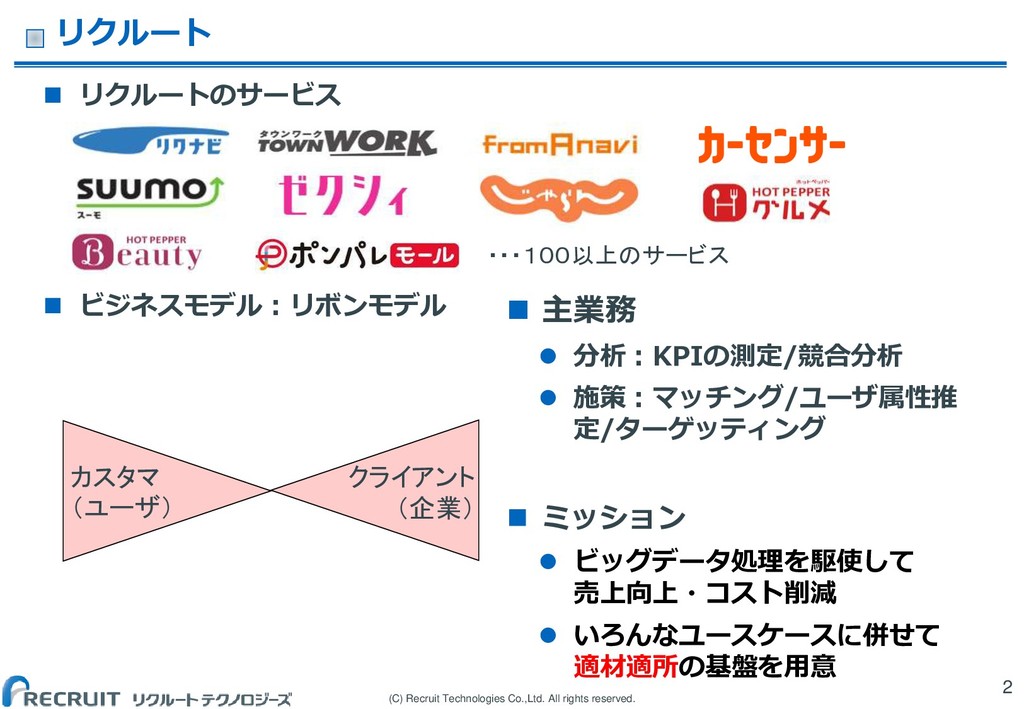
(C) Recruit Technologies Co.,Ltd. All rights reserved. リクルート リクルートのサービス
ビジネスモデル:リボンモデル 2 ・・・100以上のサービス カスタマ (ユーザ) クライアント (企業) 主業務 分析:KPIの測定/競合分析 施策:マッチング/ユーザ属性推 定/ターゲッティング ミッション ビッグデータ処理を駆使して 売上向上・コスト削減 いろんなユースケースに併せて 適材適所の基盤を用意
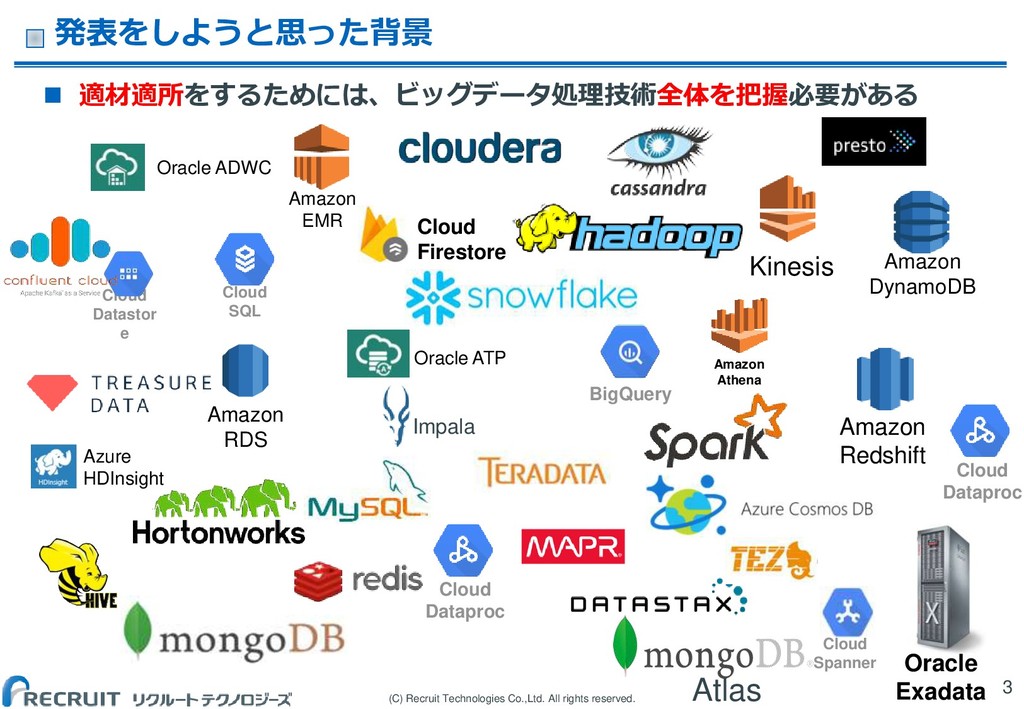
(C) Recruit Technologies Co.,Ltd. All rights reserved. 発表をしようと思った背景 適材適所をするためには、ビッグデータ処理技術全体を把握必要がある
3 Amazon DynamoDB Kinesis Amazon EMR Amazon Redshift Oracle Exadata Impala Azure HDInsight Atlas BigQuery Oracle ADWC Cloud Dataproc Oracle ATP Cloud Datastor e Cloud Spanner Cloud Dataproc Amazon Athena Amazon RDS Cloud SQL Cloud Firestore
(C) Recruit Technologies Co.,Ltd. All rights reserved. 目次 1. データベースの分類
2. データベースの紹介 3. その他ビッグデータ関連キーワードの説明 4. まとめ 4
(C) Recruit Technologies Co.,Ltd. All rights reserved. データベースの分類 5
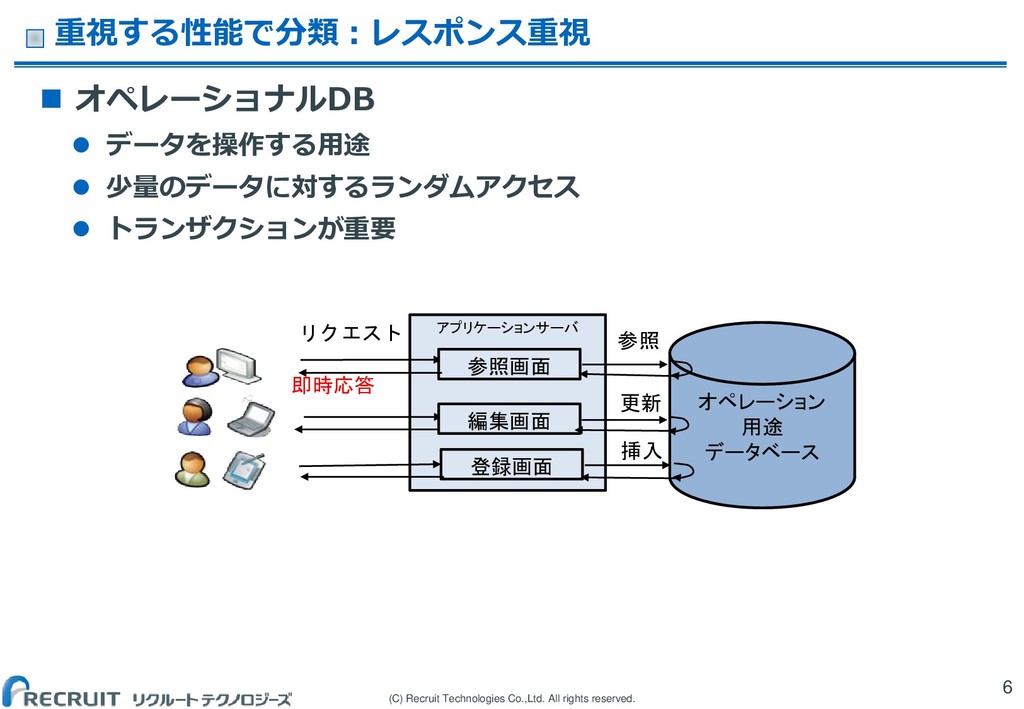
(C) Recruit Technologies Co.,Ltd. All rights reserved. 重視する性能で分類:レスポンス重視 6
オペレーショナルDB データを操作する用途 少量のデータに対するランダムアクセス トランザクションが重要 アプリケーションサーバ オペレーション 用途 データベース 登録画面 リクエスト 参照 更新 挿入 参照画面 編集画面 即時応答
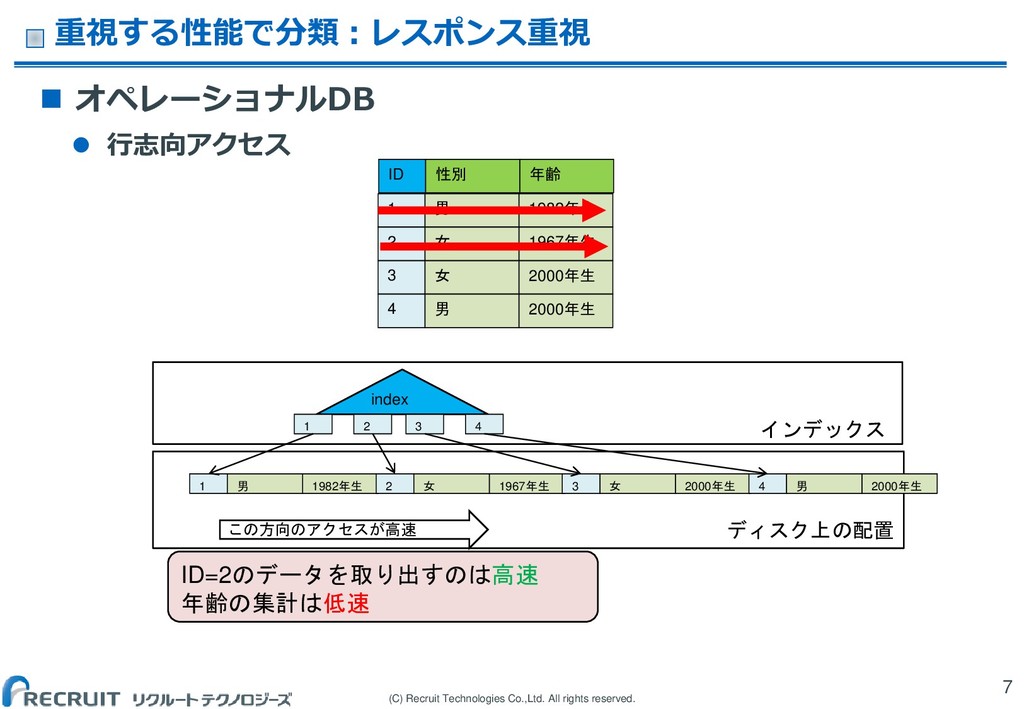
(C) Recruit Technologies Co.,Ltd. All rights reserved. 重視する性能で分類:レスポンス重視 7
オペレーショナルDB 行志向アクセス 1 1982年生 2 1967年生 3 2000年生 4 2000年生 男 女 女 男 ID 年齢 性別 ID=2のデータを取り出すのは高速 年齢の集計は低速 1 1982年生 男 2 1967年生 女 3 2000年生 女 4 2000年生 男 1 2 3 4 index この方向のアクセスが高速 インデックス ディスク上の配置
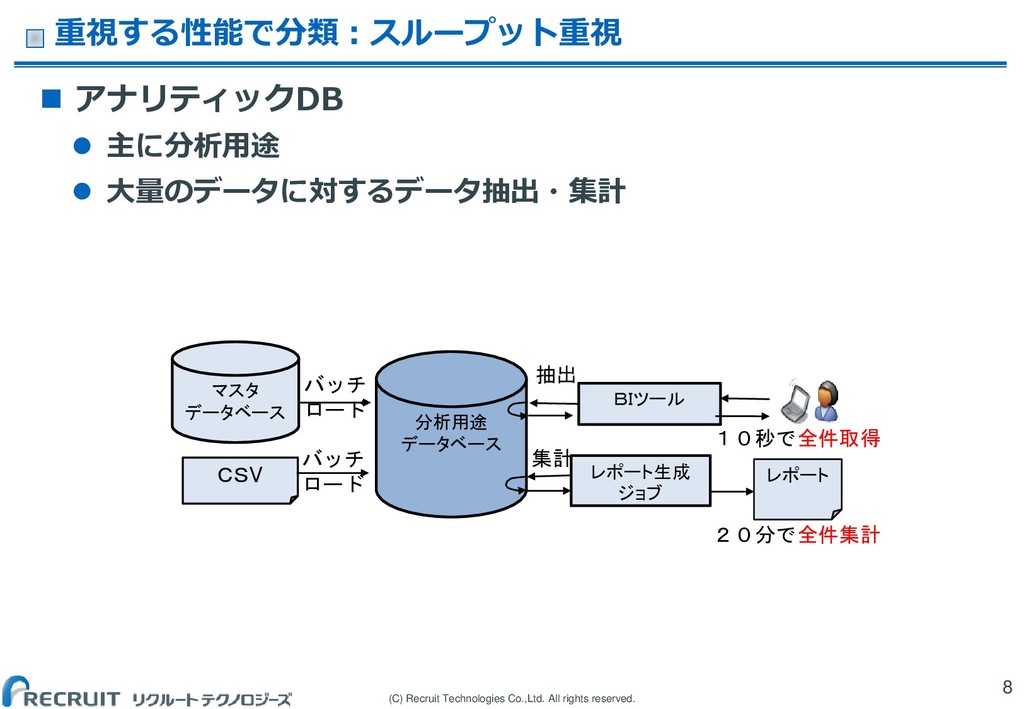
(C) Recruit Technologies Co.,Ltd. All rights reserved. 重視する性能で分類:スループット重視 8
アナリティックDB 主に分析用途 大量のデータに対するデータ抽出・集計 マスタ データベース BIツール 集計 バッチ ロード 分析用途 データベース レポート生成 ジョブ 抽出 CSV バッチ ロード レポート 20分で全件集計 10秒で全件取得
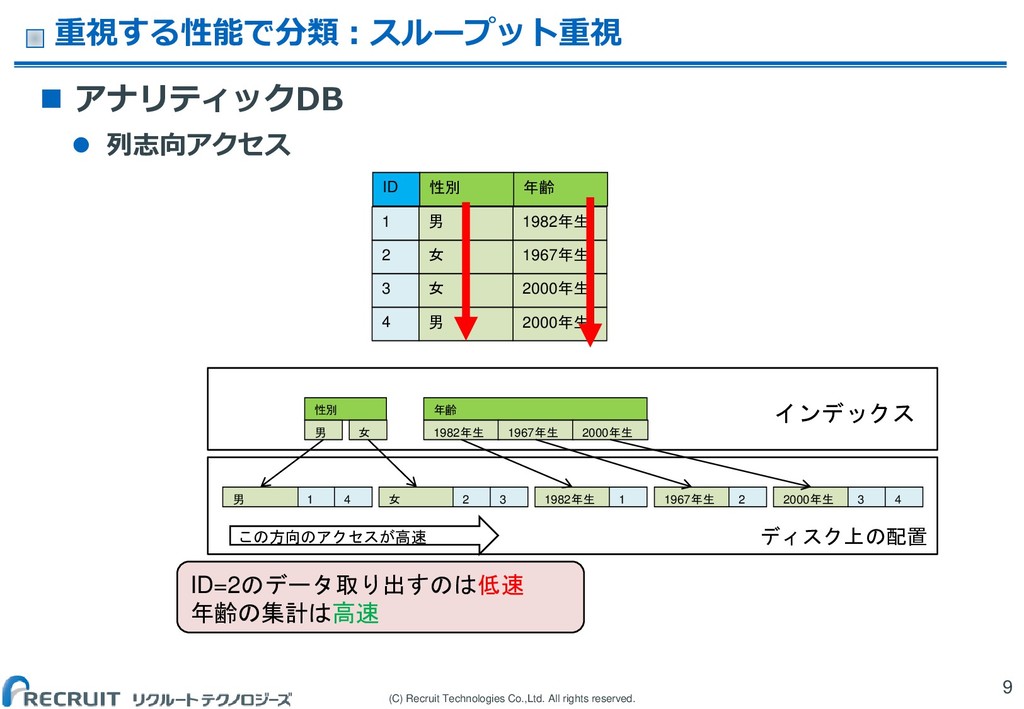
(C) Recruit Technologies Co.,Ltd. All rights reserved. 重視する性能で分類:スループット重視 9
アナリティックDB 列志向アクセス 1 1982年生 2 1967年生 3 2000年生 4 2000年生 男 女 女 男 ID 年齢 性別 メモリ 性別 男 女 1 男 4 女 1982年生 1967年生 2000年生 1 2 3 4 2 3 年齢 1982年生 1967年生 2000年生 ディスク上の配置 この方向のアクセスが高速 ID=2のデータ取り出すのは低速 年齢の集計は高速 インデックス
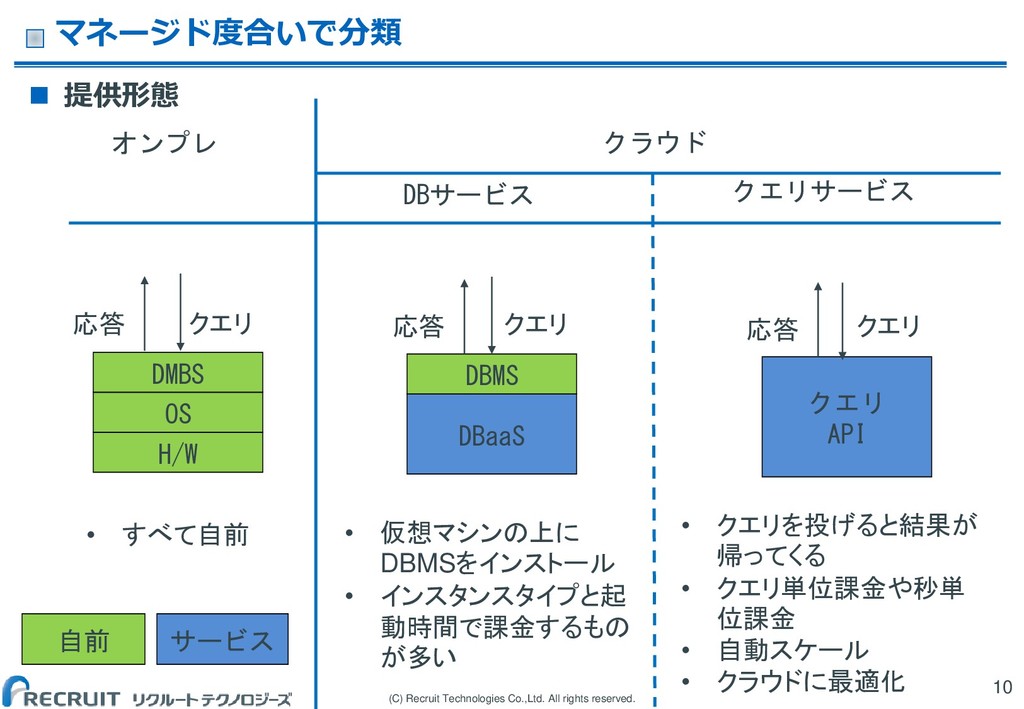
(C) Recruit Technologies Co.,Ltd. All rights reserved. 提供形態 マネージド度合いで分類
10 H/W OS DMBS DBaaS DBMS クエリ API クエリ クエリ クエリ サービス 自前 • すべて自前 • 仮想マシンの上に DBMSをインストール • インスタンスタイプと起 動時間で課金するもの が多い • クエリを投げると結果が 帰ってくる • クエリ単位課金や秒単 位課金 • 自動スケール • クラウドに最適化 オンプレ クラウド DBサービス クエリサービス 応答 応答 応答
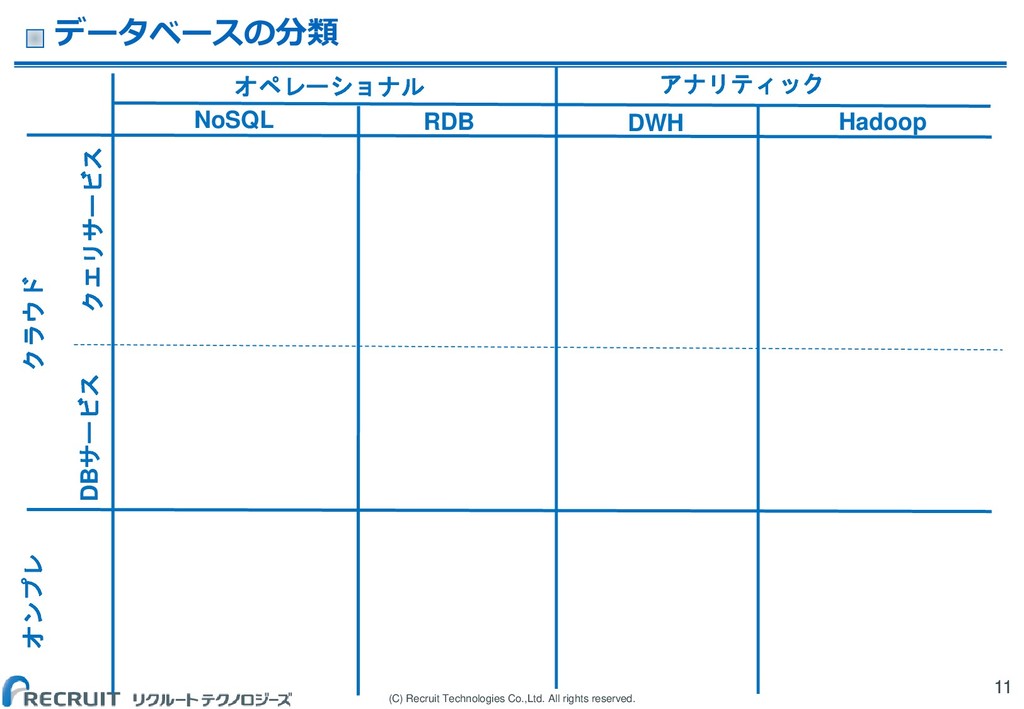
(C) Recruit Technologies Co.,Ltd. All rights reserved. データベースの分類 11 Hadoop
RDB NoSQL クラウド DWH オンプレ クエリサービス DBサービス オペレーショナル アナリティック
(C) Recruit Technologies Co.,Ltd. All rights reserved. Exadata BigQuery Amazon
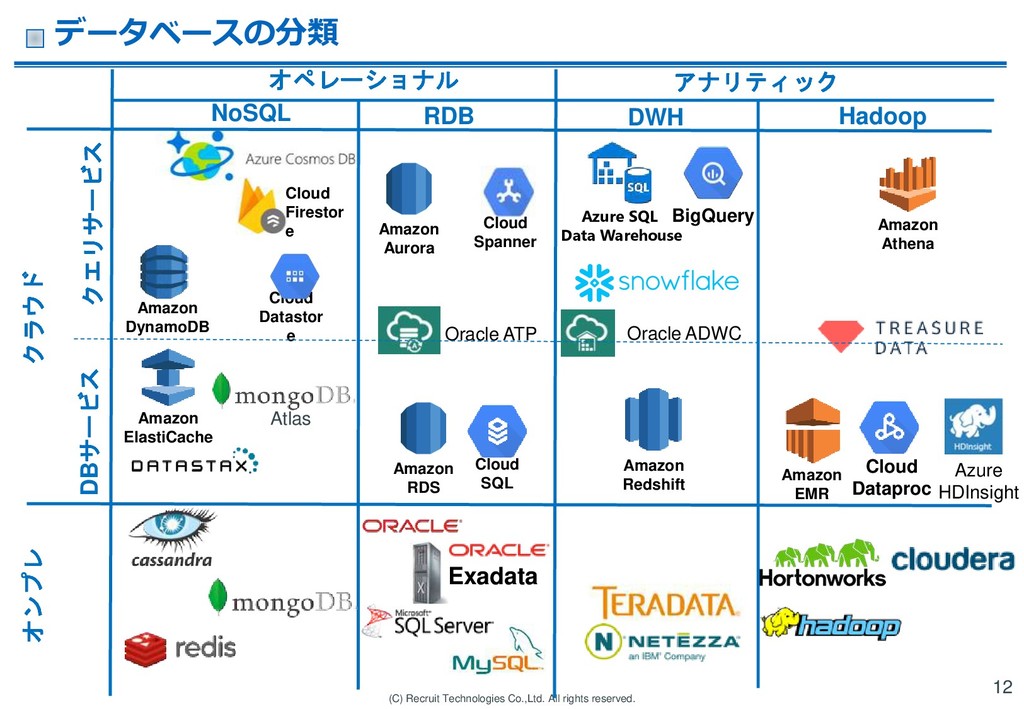
RDS Amazon ElastiCache Oracle ADWC Amazon Redshift Amazon EMR Cloud Dataproc Amazon DynamoDB Oracle ATP Amazon Athena Azure HDInsight Hadoop RDB NoSQL Cloud Datastor e Cloud Spanner Amazon Aurora Cloud SQL クラウド Atlas DWH Azure SQL Data Warehouse オンプレ クエリサービス DBサービス Cloud Firestor e オペレーショナル アナリティック データベースの分類 12
(C) Recruit Technologies Co.,Ltd. All rights reserved. Exadata BigQuery Amazon
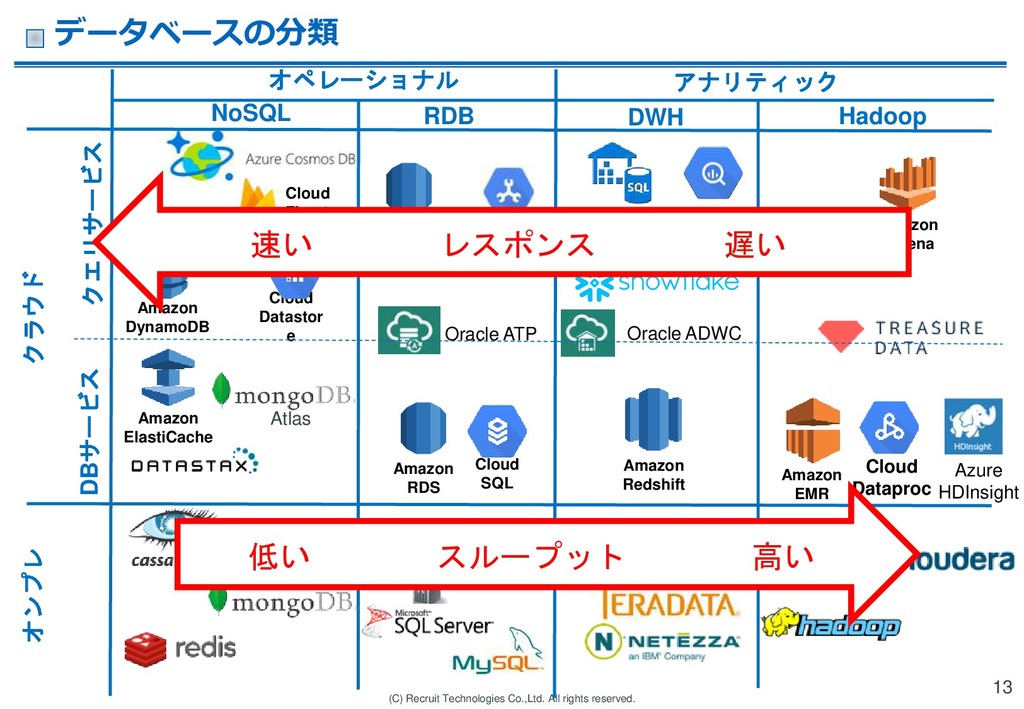
RDS Amazon ElastiCache Oracle ADWC Amazon Redshift Amazon EMR Cloud Dataproc Amazon DynamoDB Oracle ATP Amazon Athena Azure HDInsight Hadoop RDB NoSQL Cloud Datastor e Cloud Spanner Amazon Aurora Cloud SQL クラウド Atlas DWH Azure SQL Data Warehouse オンプレ クエリサービス DBサービス Cloud Firestor e オペレーショナル アナリティック データベースの分類 13 速い レスポンス 遅い 低い スループット 高い
(C) Recruit Technologies Co.,Ltd. All rights reserved. Exadata BigQuery Amazon
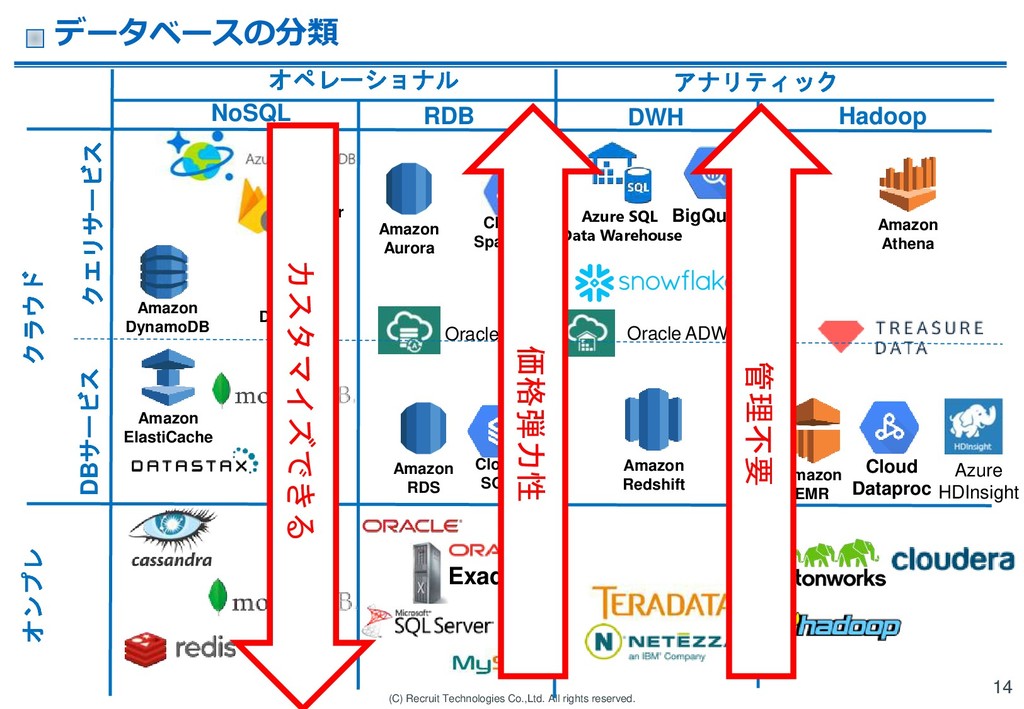
RDS Amazon ElastiCache Oracle ADWC Amazon Redshift Amazon EMR Cloud Dataproc Amazon DynamoDB Oracle ATP Amazon Athena Azure HDInsight Hadoop RDB NoSQL Cloud Datastor e Cloud Spanner Amazon Aurora Cloud SQL クラウド Atlas DWH Azure SQL Data Warehouse オンプレ クエリサービス DBサービス Cloud Firestor e オペレーショナル アナリティック データベースの分類 14 管理不要 カスタマイズできる 価格弾力性
(C) Recruit Technologies Co.,Ltd. All rights reserved. Exadata BigQuery Amazon
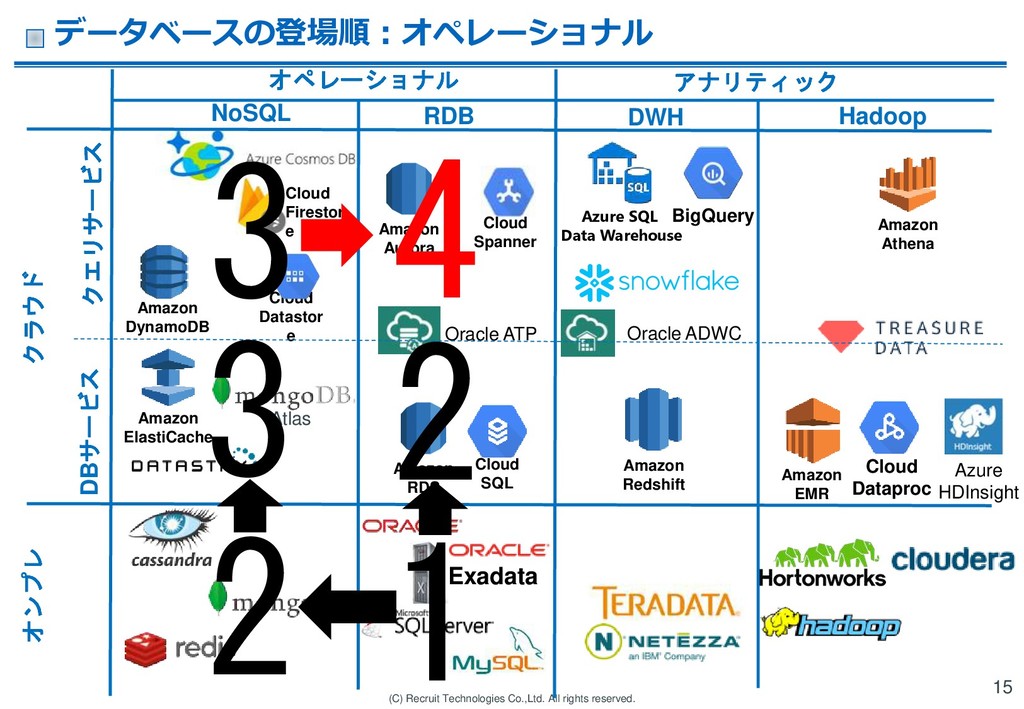
RDS Amazon ElastiCache Oracle ADWC Amazon Redshift Amazon EMR Cloud Dataproc Amazon DynamoDB Oracle ATP Amazon Athena Azure HDInsight Hadoop RDB NoSQL Cloud Datastor e Cloud Spanner Amazon Aurora Cloud SQL クラウド Atlas DWH Azure SQL Data Warehouse オンプレ クエリサービス DBサービス Cloud Firestor e オペレーショナル アナリティック データベースの登場順:オペレーショナル 15 1 2 2 3 3 4
(C) Recruit Technologies Co.,Ltd. All rights reserved. Exadata BigQuery Amazon
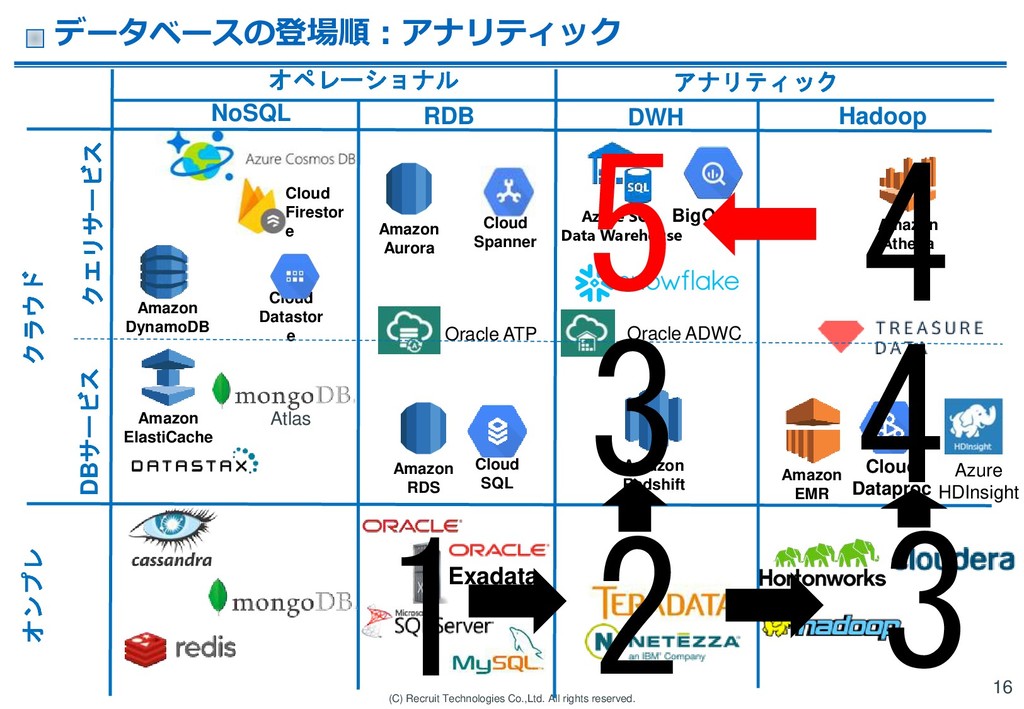
RDS Amazon ElastiCache Oracle ADWC Amazon Redshift Amazon EMR Cloud Dataproc Amazon DynamoDB Oracle ATP Amazon Athena Azure HDInsight Hadoop RDB NoSQL Cloud Datastor e Cloud Spanner Amazon Aurora Cloud SQL クラウド Atlas DWH Azure SQL Data Warehouse オンプレ クエリサービス DBサービス Cloud Firestor e オペレーショナル アナリティック データベースの登場順:アナリティック 16 1 2 3 4 3 5 4
(C) Recruit Technologies Co.,Ltd. All rights reserved. Exadata BigQuery Amazon
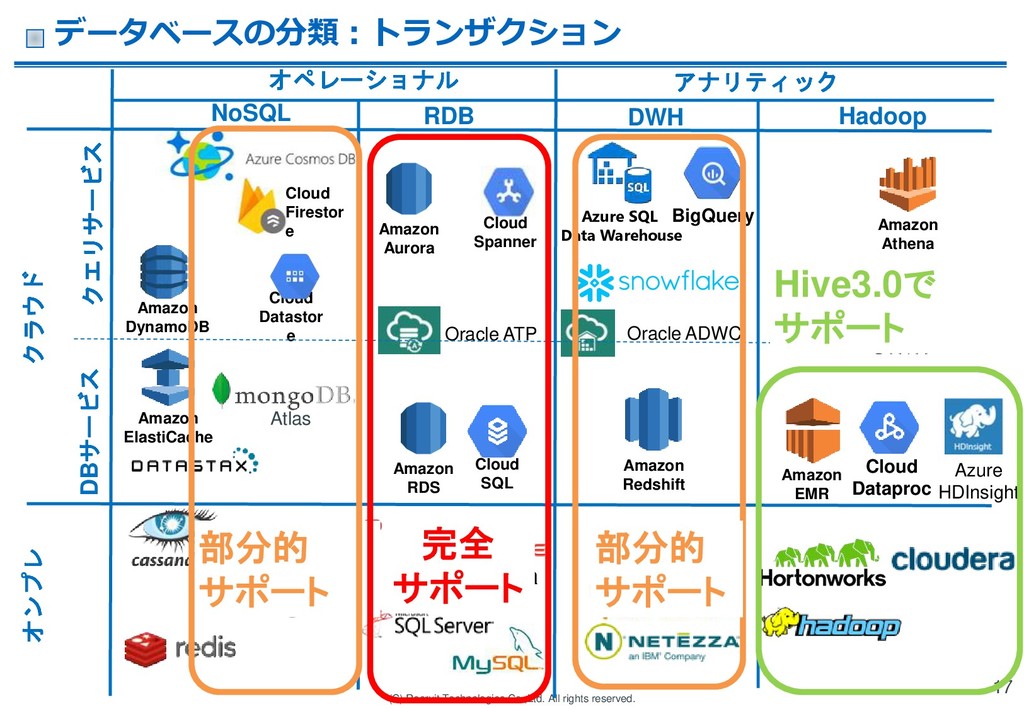
RDS Amazon ElastiCache Oracle ADWC Amazon Redshift Amazon EMR Cloud Dataproc Amazon DynamoDB Oracle ATP Amazon Athena Azure HDInsight Hadoop RDB NoSQL Cloud Datastor e Cloud Spanner Amazon Aurora Cloud SQL クラウド Atlas DWH Azure SQL Data Warehouse オンプレ クエリサービス DBサービス Cloud Firestor e オペレーショナル アナリティック データベースの分類:トランザクション 17 部分的 サポート 完全 サポート 部分的 サポート Hive3.0で サポート
(C) Recruit Technologies Co.,Ltd. All rights reserved. Exadata BigQuery Amazon
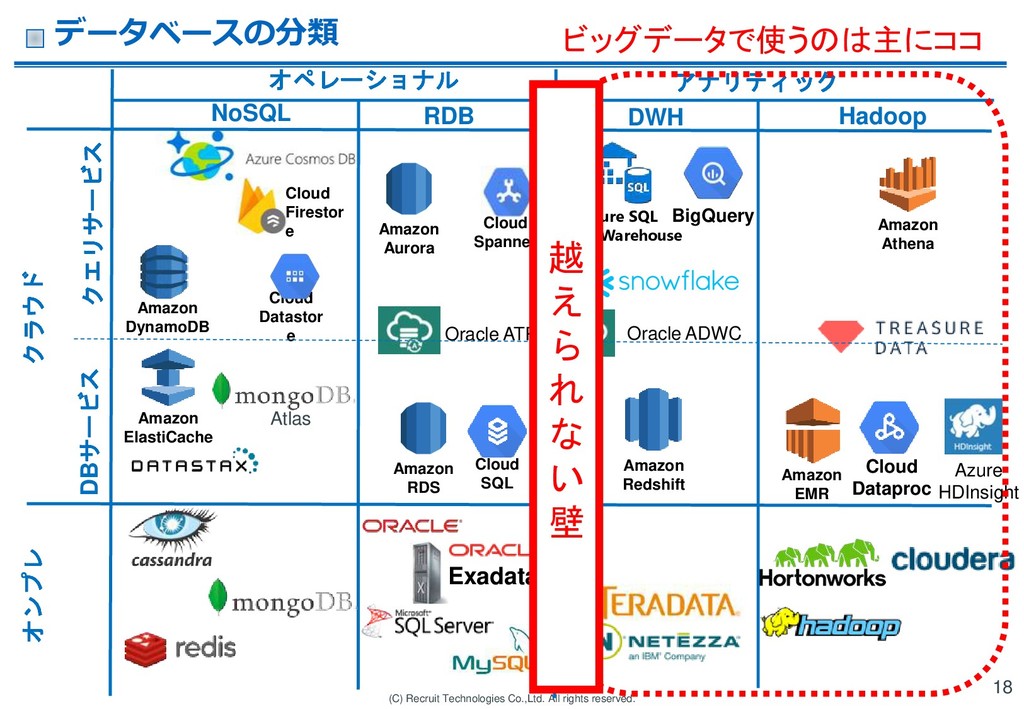
RDS Amazon ElastiCache Oracle ADWC Amazon Redshift Amazon EMR Cloud Dataproc Amazon DynamoDB Oracle ATP Amazon Athena Azure HDInsight Hadoop RDB NoSQL Cloud Datastor e Cloud Spanner Amazon Aurora Cloud SQL クラウド Atlas DWH Azure SQL Data Warehouse オンプレ クエリサービス DBサービス Cloud Firestor e オペレーショナル アナリティック データベースの分類 18 ビッグデータで使うのは主にココ 越 え ら れ な い 壁
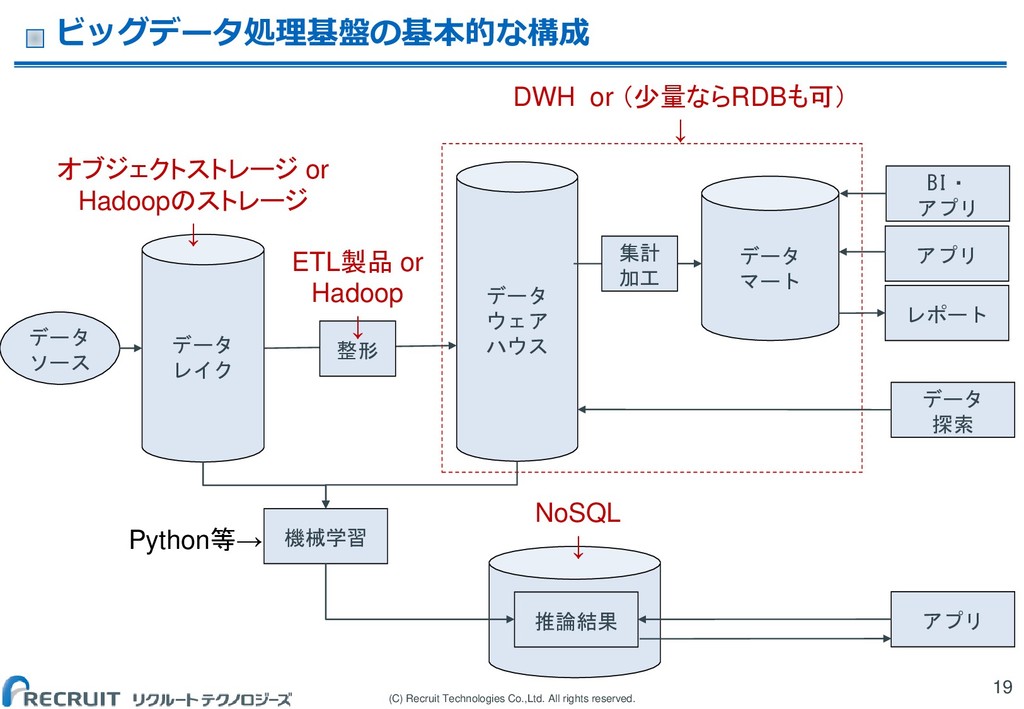
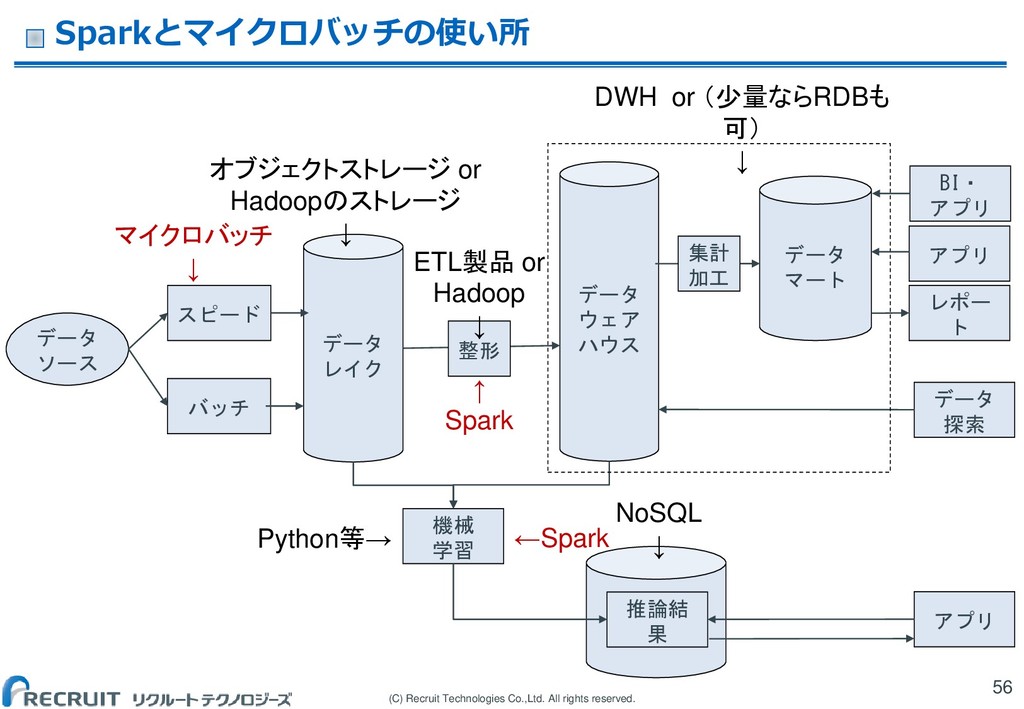
(C) Recruit Technologies Co.,Ltd. All rights reserved. ビッグデータ処理基盤の基本的な構成 19 データ
レイク データ ウェア ハウス 機械学習 データ ソース BI・ アプリ データ 探索 データ マート レポート 推論結果 アプリ 整形 DWH or (少量ならRDBも可) ↓ NoSQL ↓ オブジェクトストレージ or Hadoopのストレージ ↓ 集計 加工 アプリ ETL製品 or Hadoop ↓ Python等→
(C) Recruit Technologies Co.,Ltd. All rights reserved. データベースの紹介 20
(C) Recruit Technologies Co.,Ltd. All rights reserved. オペレーショナルDB └RDB 21
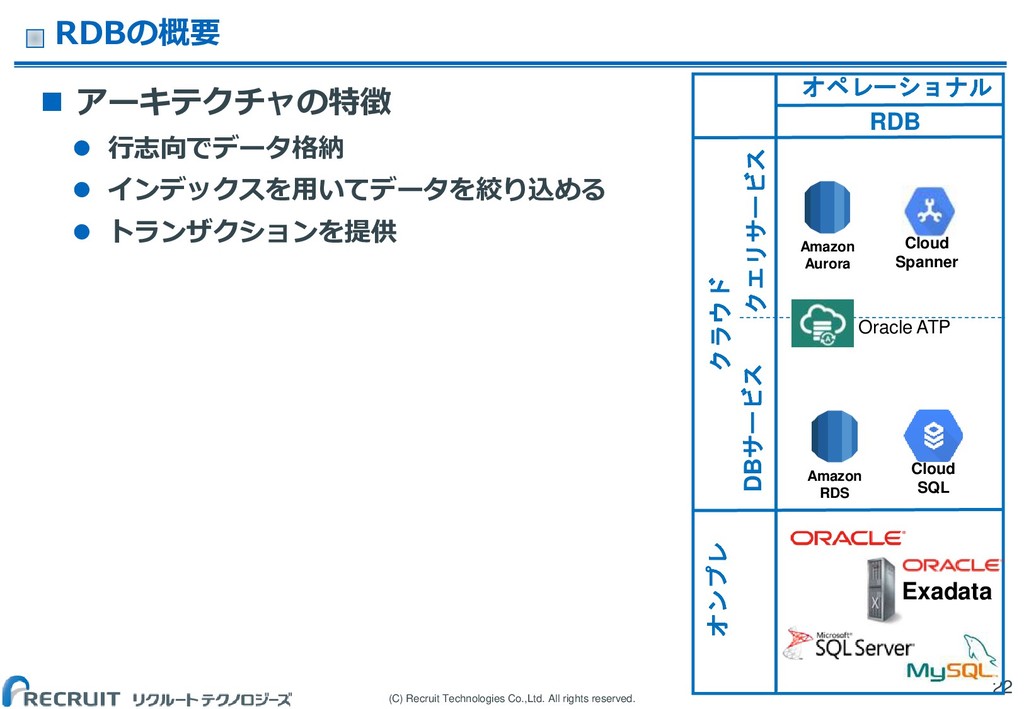
(C) Recruit Technologies Co.,Ltd. All rights reserved. RDBの概要 アーキテクチャの特徴
行志向でデータ格納 インデックスを用いてデータを絞り込める トランザクションを提供 22 オペレーショナル RDB クラウド クエリサービス DBサービス オンプレ Exadata Amazon RDS Oracle ATP Cloud Spanner Amazon Aurora Cloud SQL
(C) Recruit Technologies Co.,Ltd. All rights reserved. ストレージノード ストレージノード ストレージノード
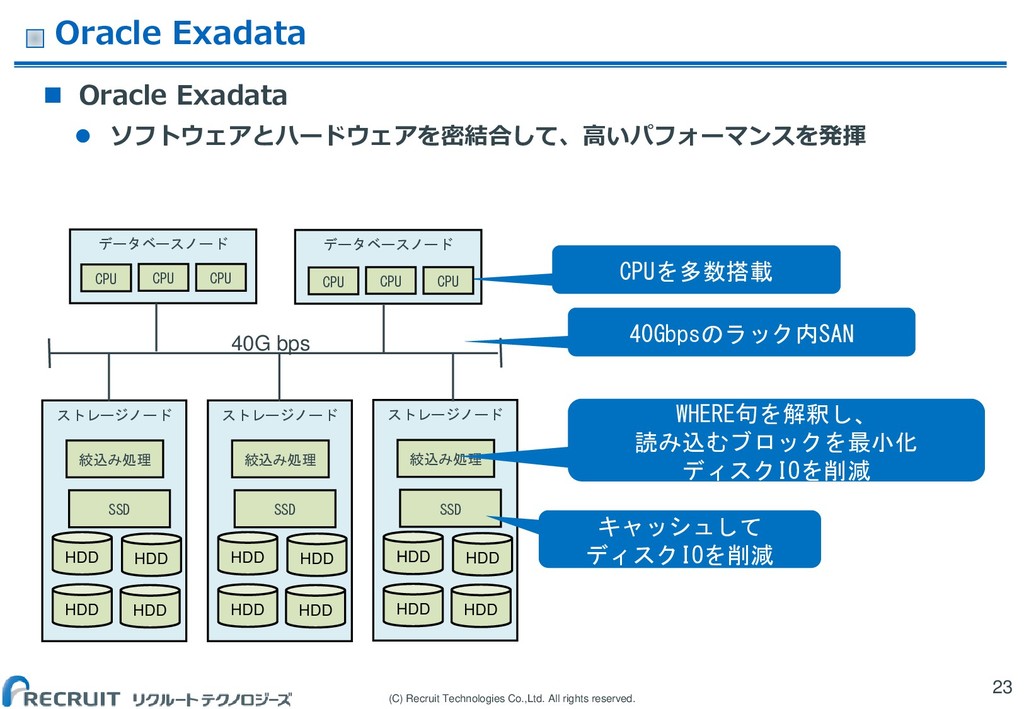
Oracle Exadata Oracle Exadata ソフトウェアとハードウェアを密結合して、高いパフォーマンスを発揮 23 データベースノード HDD SSD 絞込み処理 HDD HDD HDD HDD SSD 絞込み処理 HDD HDD HDD HDD SSD 絞込み処理 HDD HDD HDD データベースノード CPU WHERE句を解釈し、 読み込むブロックを最小化 ディスクIOを削減 キャッシュして ディスクIOを削減 CPUを多数搭載 40Gbpsのラック内SAN CPU CPU CPU CPU CPU 40G bps
(C) Recruit Technologies Co.,Ltd. All rights reserved. Google Cloud Spanner
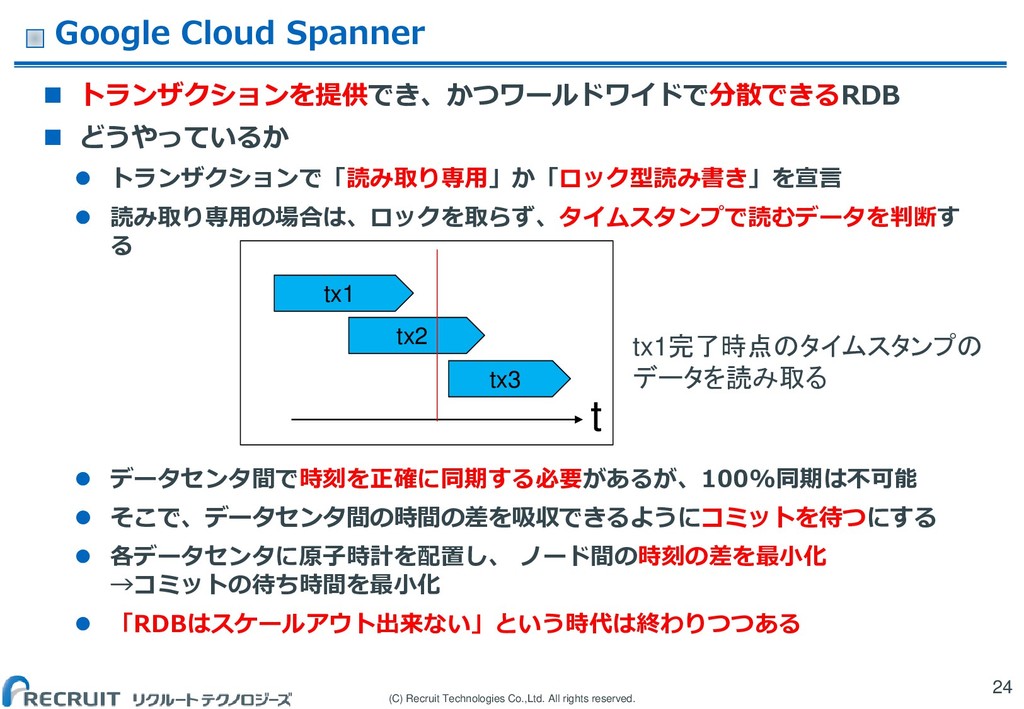
トランザクションを提供でき、かつワールドワイドで分散できるRDB どうやっているか トランザクションで「読み取り専用」か「ロック型読み書き」を宣言 読み取り専用の場合は、ロックを取らず、タイムスタンプで読むデータを判断す る データセンタ間で時刻を正確に同期する必要があるが、100%同期は不可能 そこで、データセンタ間の時間の差を吸収できるようにコミットを待つにする 各データセンタに原子時計を配置し、 ノード間の時刻の差を最小化 →コミットの待ち時間を最小化 「RDBはスケールアウト出来ない」という時代は終わりつつある 24 tx2 tx1 tx3 t tx1完了時点のタイムスタンプの データを読み取る
(C) Recruit Technologies Co.,Ltd. All rights reserved. Oracle ATP(Autonomous Transaction
Processing) OracleCloudで提供されるOLTP DBサービス 2018/8に発表 99.995%のuptimeをSLAとして保証(計画停止含む) 自動オプティマイズ • DB自身が、インデックス・メモリ・パーティション・SQL実行計画などを自動的に最適 化する。 高いパフォーマンス • Oracle Exadataをインフラとして動作する 高いスケーラビリティ • Oracle RAC上に構築され、物理サーバの制約を超えてスケールする 常時オンライン • 自動パッチ適用、高可用化構成、スキーマアップデートなどにより、常にオンラインを維 持する 25 https://cloud.oracle.com/opc/paas/ebooks/ATP-eBook-final.pdf
(C) Recruit Technologies Co.,Ltd. All rights reserved. RDBの所感 「RDBはスケールアウトできない」という時代は終わりつつある
RDBの代名詞であるOracle社がクラウドに全力投資。それぐらいクラウド な時代 26
(C) Recruit Technologies Co.,Ltd. All rights reserved. オペレーショナルDB └NoSQL 27
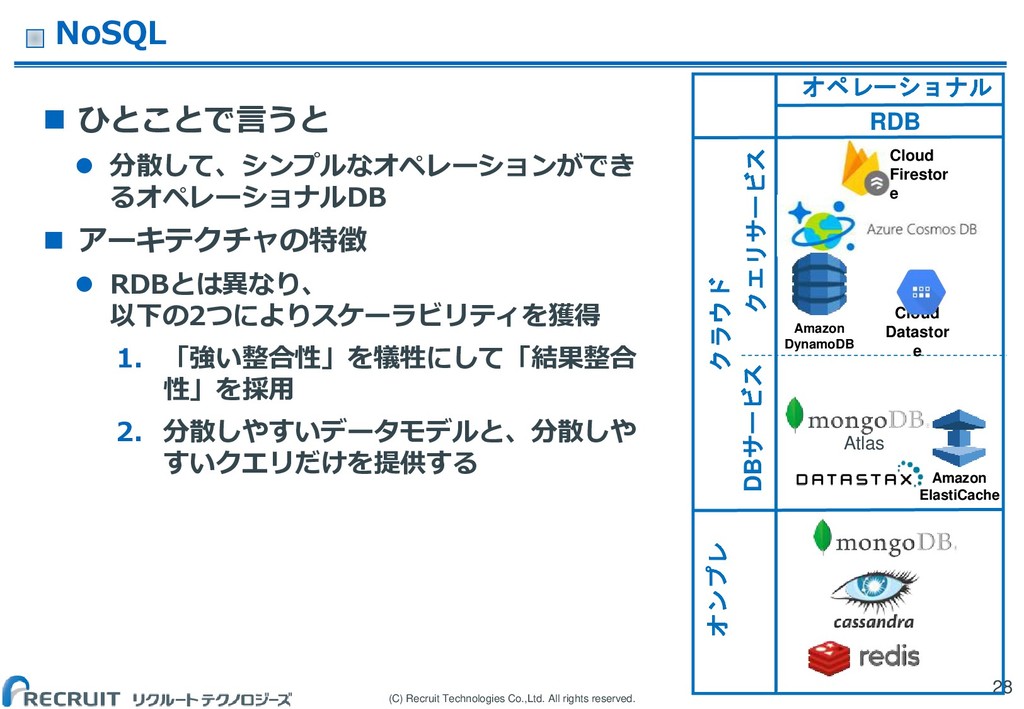
(C) Recruit Technologies Co.,Ltd. All rights reserved. NoSQL ひとことで言うと
分散して、シンプルなオペレーションができ るオペレーショナルDB アーキテクチャの特徴 RDBとは異なり、 以下の2つによりスケーラビリティを獲得 1. 「強い整合性」を犠牲にして「結果整合 性」を採用 2. 分散しやすいデータモデルと、分散しや すいクエリだけを提供する 28 オペレーショナル RDB クラウド オンプレ Amazon ElastiCache Amazon DynamoDB Cloud Datastor e Atlas クエリサービス DBサービス Cloud Firestor e
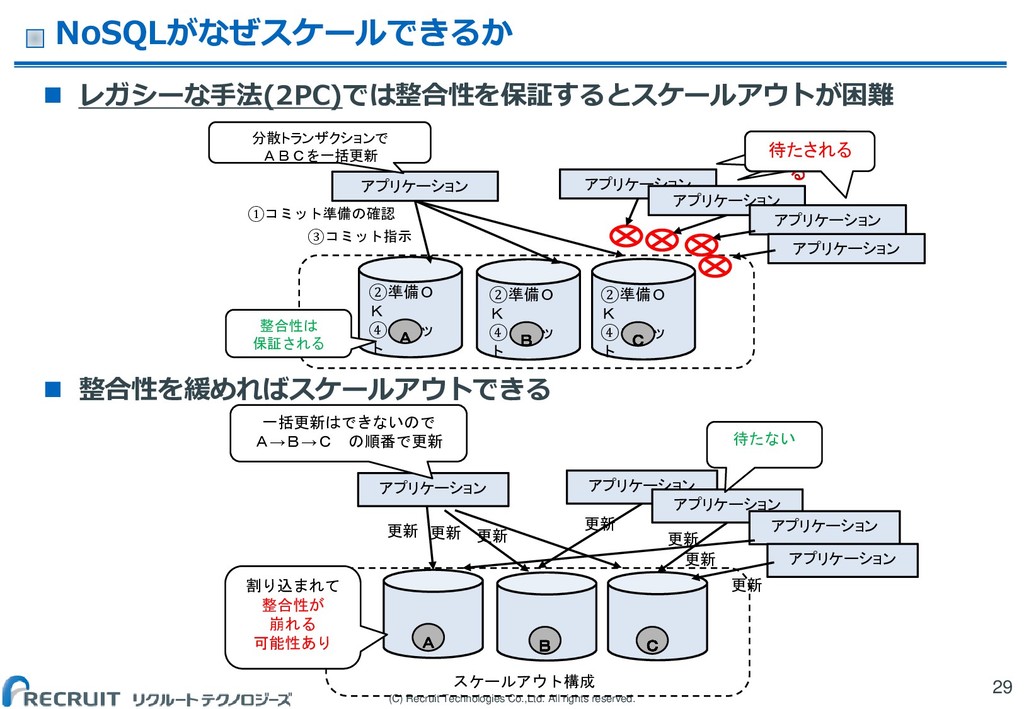
(C) Recruit Technologies Co.,Ltd. All rights reserved. NoSQLがなぜスケールできるか レガシーな手法(2PC)では整合性を保証するとスケールアウトが困難
整合性を緩めればスケールアウトできる 29 アプリケーション アプリケーション 整合性は 保証される ②準備O K ④コミッ ト ②準備O K ④コミッ ト ②準備O K ④コミッ ト ①コミット準備の確認 ③コミット指示 アプリケーション アプリケーション 待たされ る A B C 分散トランザクションで ABCを一括更新 アプリケーション 待たされ る 待たされる アプリケーション スケールアウト構成 更新 一括更新はできないので A→B→C の順番で更新 A B C 更新 アプリケーション アプリケーション アプリケーション アプリケーション 更新 更新 更新 待たない 更新 更新 割り込まれて 整合性が 崩れる 可能性あり
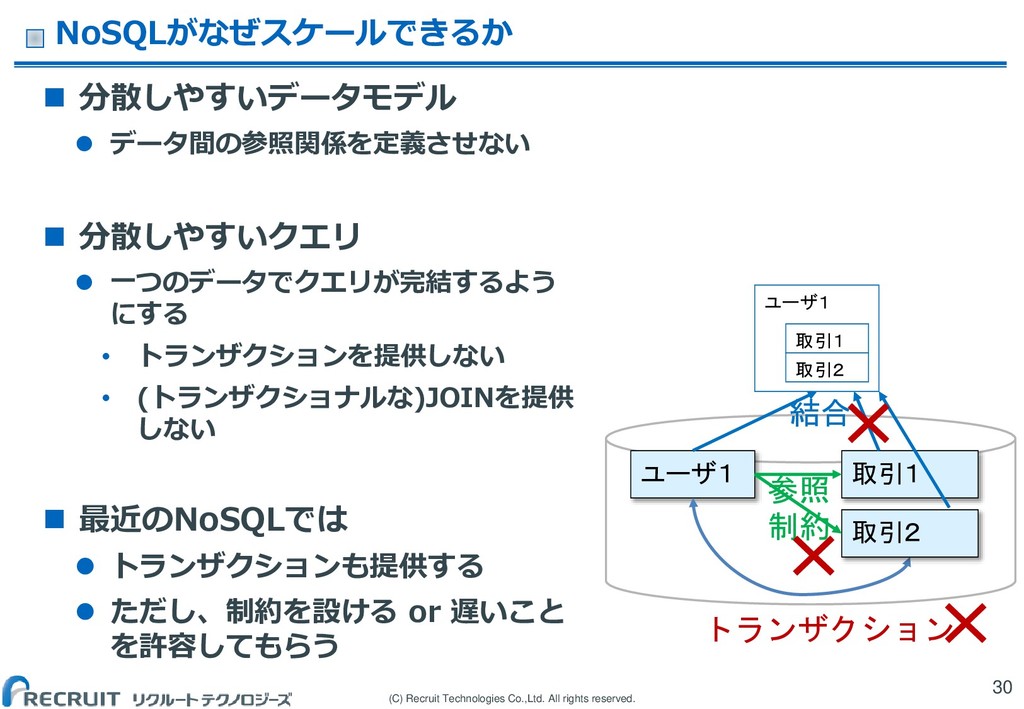
(C) Recruit Technologies Co.,Ltd. All rights reserved. NoSQLがなぜスケールできるか 分散しやすいデータモデル
データ間の参照関係を定義させない 分散しやすいクエリ 一つのデータでクエリが完結するよう にする • トランザクションを提供しない • (トランザクショナルな)JOINを提供 しない 最近のNoSQLでは トランザクションも提供する ただし、制約を設ける or 遅いこと を許容してもらう 30 ユーザ1 取引1 取引2 ユーザ1 取引1 トランザクション 取引2 参照 制約 結合
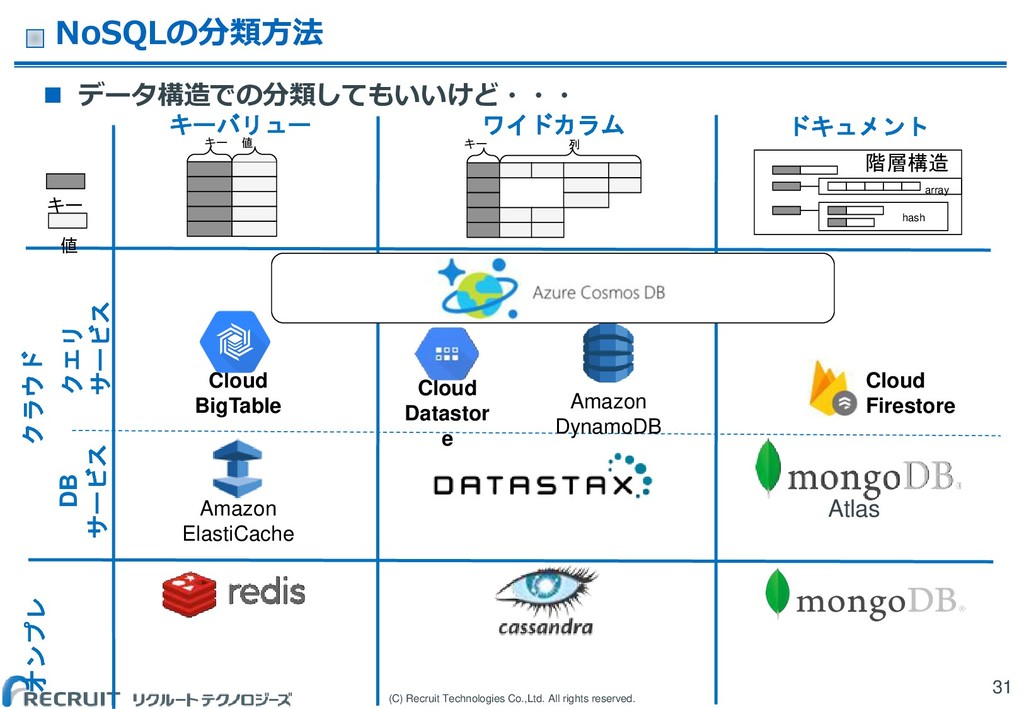
(C) Recruit Technologies Co.,Ltd. All rights reserved. ワイドカラム キーバリュー クラウド
ドキュメント オンプレ NoSQLの分類方法 31 キー 値 キー 値 キー 列 Amazon ElastiCache Amazon DynamoDB array hash 階層構造 Cloud Datastor e Atlas データ構造での分類してもいいけど・・・ クエリ サービス DB サービス Cloud Firestore Cloud BigTable
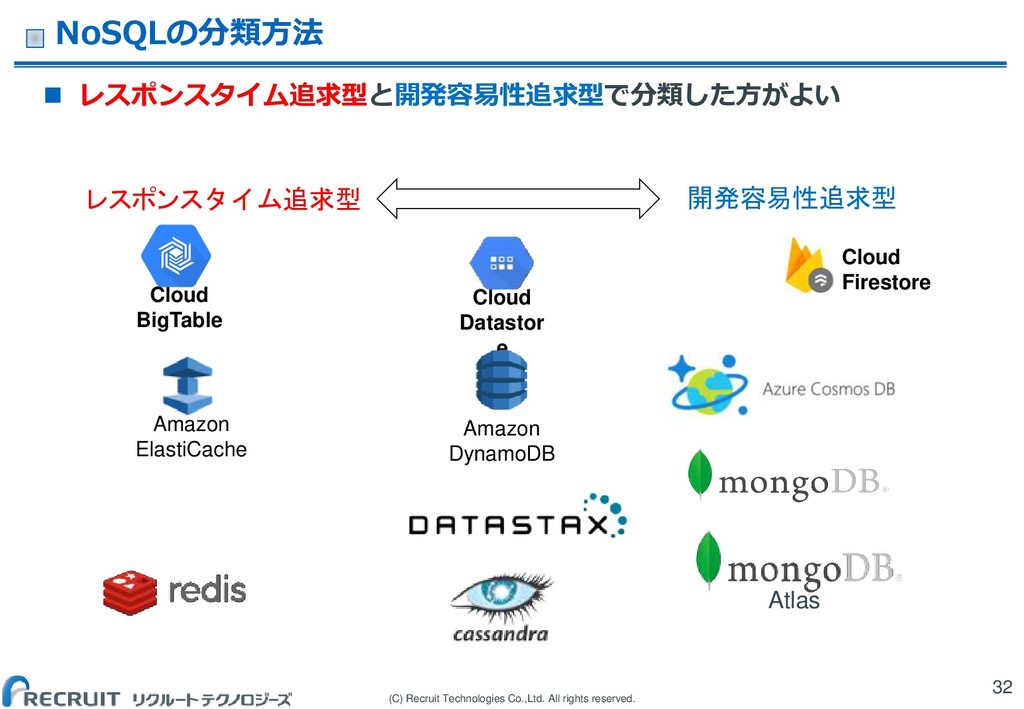
(C) Recruit Technologies Co.,Ltd. All rights reserved. NoSQLの分類方法 レスポンスタイム追求型と開発容易性追求型で分類した方がよい
32 Cloud Datastor e Atlas Cloud Firestore Cloud BigTable Amazon ElastiCache レスポンスタイム追求型 開発容易性追求型 Amazon DynamoDB
(C) Recruit Technologies Co.,Ltd. All rights reserved. MongoDB MongoDB
JSONをデータモデルとして扱うDB Mongoクエリ言語でデータ操作 インデックスや集計など、アプリケーション開発に便利な機能が多い アプリフレームワークに組み込まれ、JSONストアとして広く使われている Version 4.0ではトランザクションをサポート MongoDB Atlas MongoDBサービス AWS,Azure,GCP上で利用可能 Web画面からMongoDBをデプロイして利用できる 自動監視、自動アラート、自動バックアップ、ポイントインタイムリカバリ、自 動ローリングアップデートなど、多くの管理タスクが自動化されている 33 db.person.find( {"name":"watanabe","age": 30 } ).limit(3)
(C) Recruit Technologies Co.,Ltd. All rights reserved. Cloud Firestore
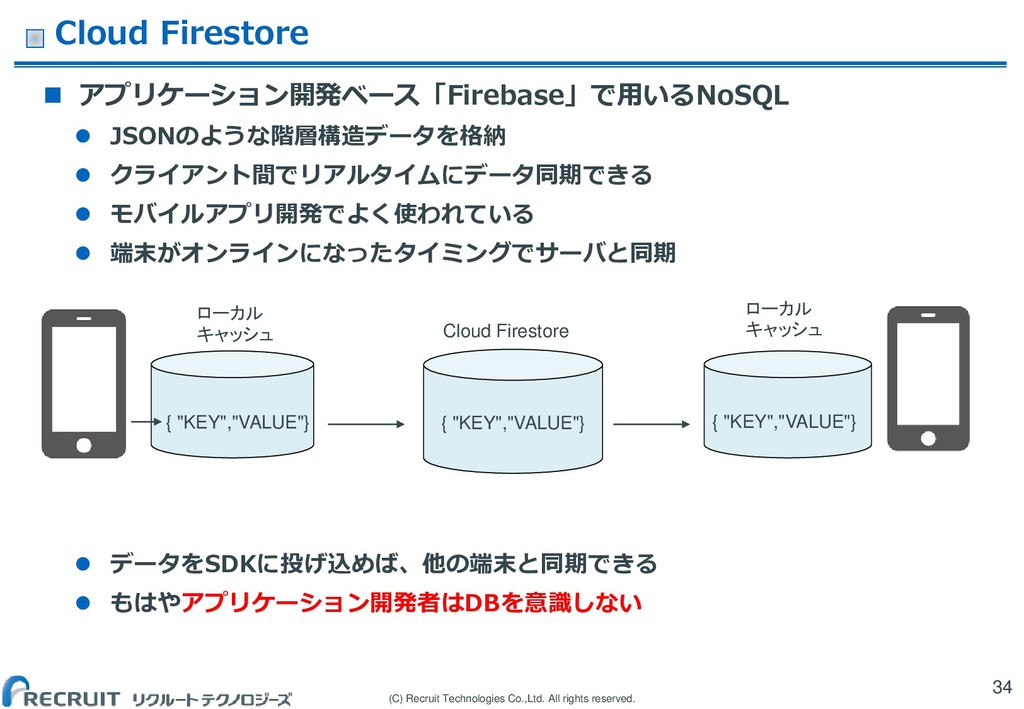
アプリケーション開発ベース「Firebase」で用いるNoSQL JSONのような階層構造データを格納 クライアント間でリアルタイムにデータ同期できる モバイルアプリ開発でよく使われている 端末がオンラインになったタイミングでサーバと同期 データをSDKに投げ込めば、他の端末と同期できる もはやアプリケーション開発者はDBを意識しない 34 ローカル キャッシュ { "KEY","VALUE"} Cloud Firestore { "KEY","VALUE"} { "KEY","VALUE"} ローカル キャッシュ
(C) Recruit Technologies Co.,Ltd. All rights reserved. NoSQLの所感 レスポンスを追求するDBと、開発容易性を追求するDBに分かれてきた
開発容易性を追求するDBでは以下の機能を拡張 DBサービス化、クエリサービス化 トランザクションサポート SQLサポート マルチモデルサポート 35
(C) Recruit Technologies Co.,Ltd. All rights reserved. アナリティックDB └Hadoop 36
(C) Recruit Technologies Co.,Ltd. All rights reserved. Hadoop 37 アナリティクス
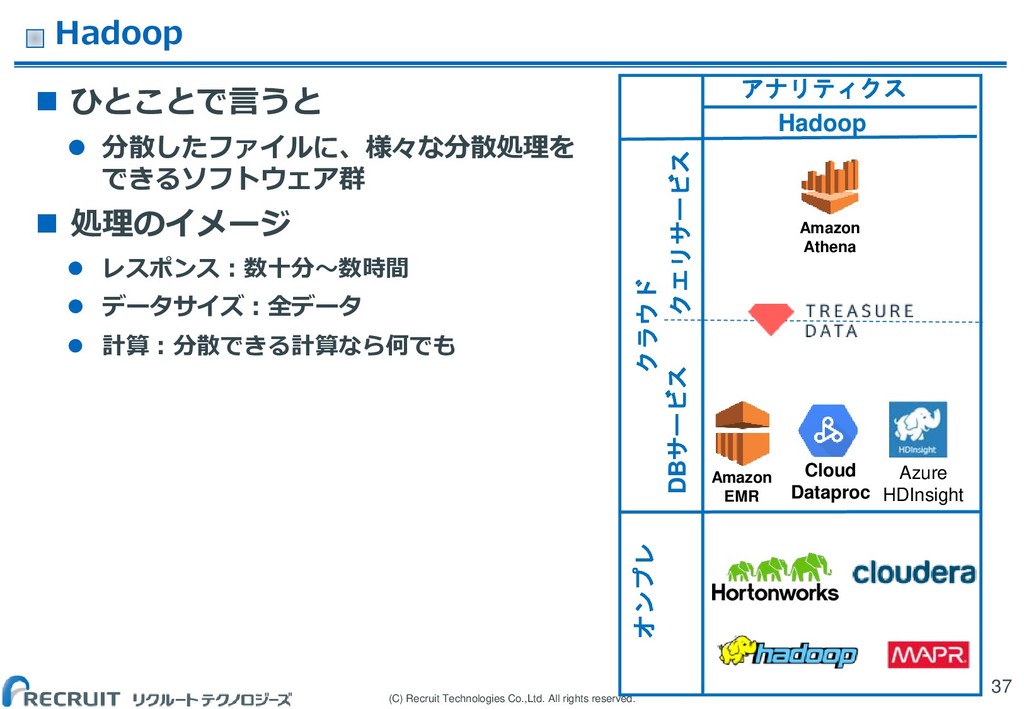
Hadoop クラウド オンプレ Amazon EMR Cloud Dataproc Amazon Athena Azure HDInsight クエリサービス DBサービス ひとことで言うと 分散したファイルに、様々な分散処理を できるソフトウェア群 処理のイメージ レスポンス:数十分〜数時間 データサイズ:全データ 計算:分散できる計算なら何でも
(C) Recruit Technologies Co.,Ltd. All rights reserved. Hadoop アーキテクチャ
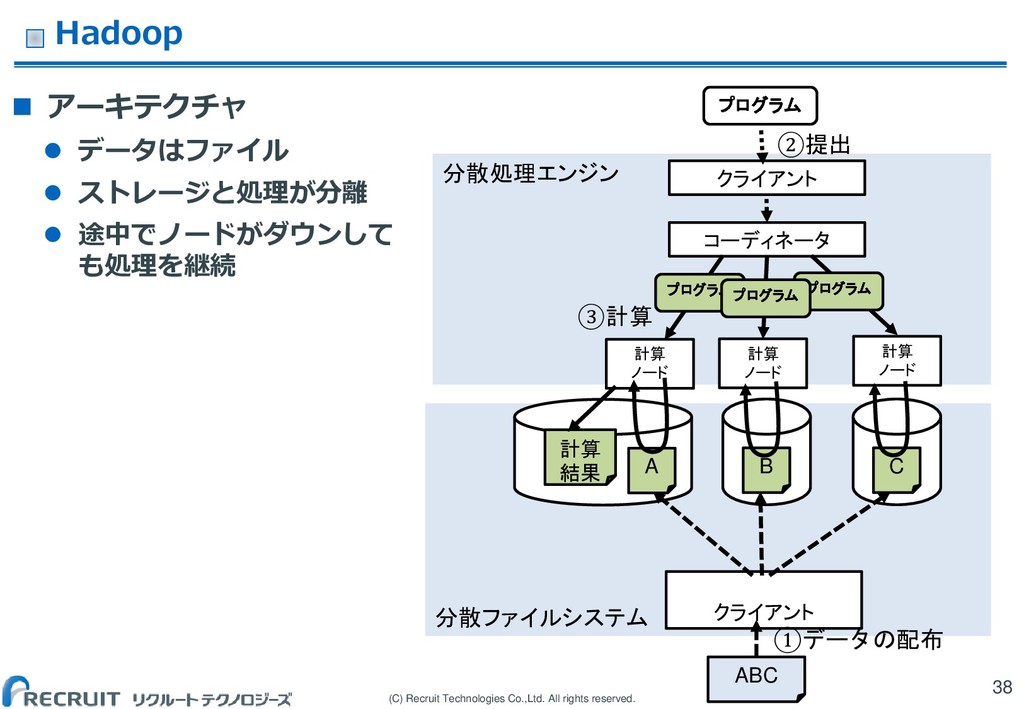
データはファイル ストレージと処理が分離 途中でノードがダウンして も処理を継続 38 分散ファイルシステム 分散処理エンジン ABC A B C クライアント 計算 ノード 計算 ノード 計算 ノード コーディネータ ①データの配布 ②提出 ③計算 計算 結果 プログラム プログラム クライアント プログラム プログラム
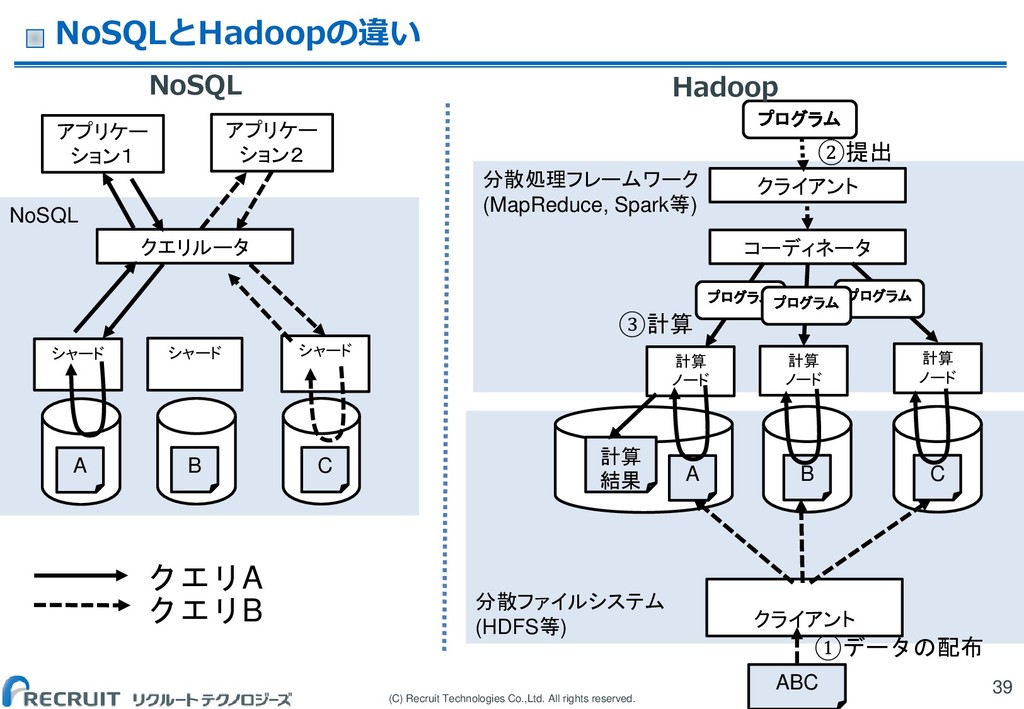
(C) Recruit Technologies Co.,Ltd. All rights reserved. NoSQLとHadoopの違い NoSQL 39
分散ファイルシステム (HDFS等) 分散処理フレームワーク (MapReduce, Spark等) ABC A B C クライアント 計算 ノード 計算 ノード 計算 ノード コーディネータ ①データの配布 ②提出 ③計算 計算 結果 プログラム プログラム クライアント プログラム プログラム NoSQL シャード シャード シャード A クエリルータ B C アプリケー ション2 アプリケー ション1 クエリA クエリB Hadoop
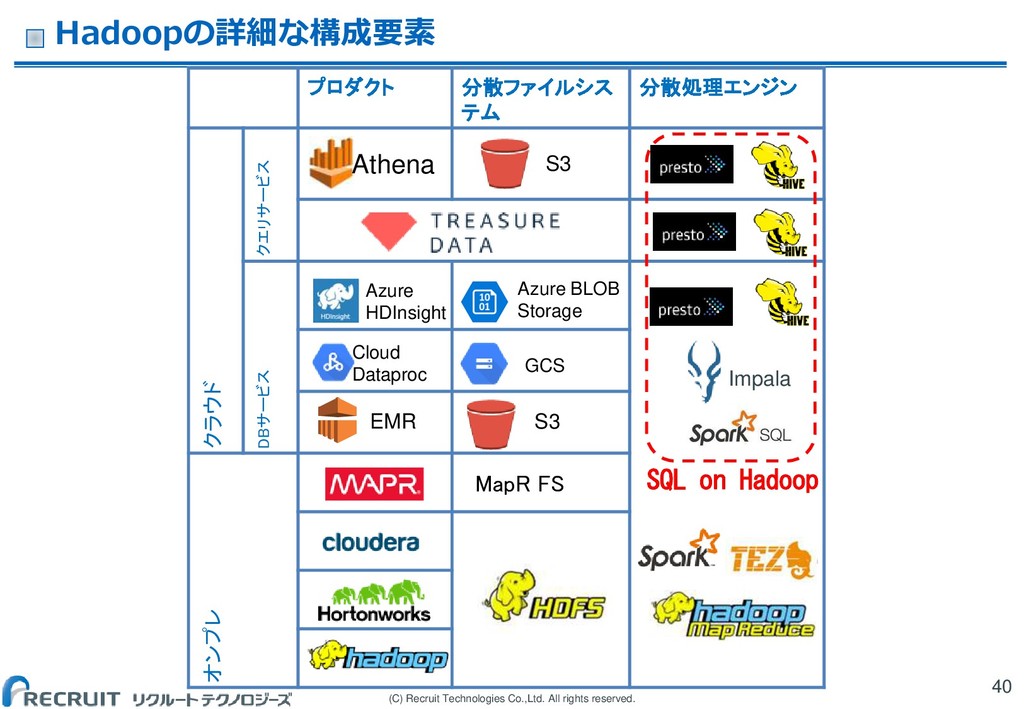
(C) Recruit Technologies Co.,Ltd. All rights reserved. Hadoopの詳細な構成要素 40 プロダクト
分散ファイルシス テム 分散処理エンジン クラウド クエリサービス DBサービス オンプレ EMR S3 Impala Cloud Dataproc GCS Athena SQL on Hadoop S3 Azure BLOB Storage Azure HDInsight MapR FS
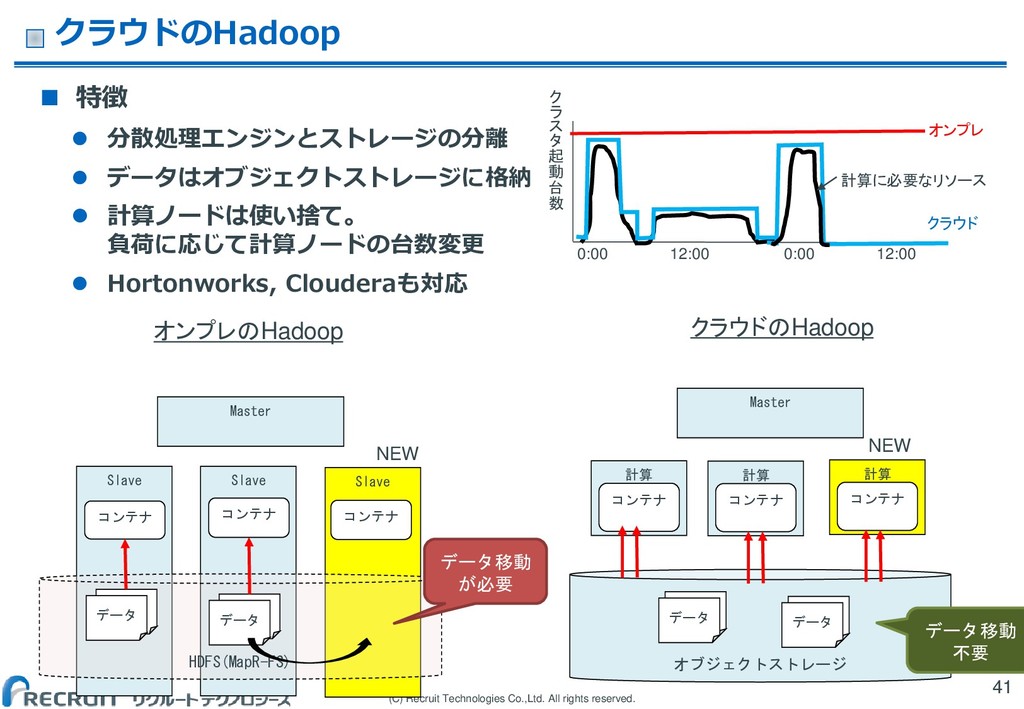
(C) Recruit Technologies Co.,Ltd. All rights reserved. クラウドのHadoop 特徴
分散処理エンジンとストレージの分離 データはオブジェクトストレージに格納 計算ノードは使い捨て。 負荷に応じて計算ノードの台数変更 Hortonworks, Clouderaも対応 41 Slave Slave Slave HDFS(MapR-FS) オブジェクトストレージ Master データ データ コンテナ データ データ コンテナ データ データ データ データ 計算 コンテナ Master コンテナ 計算 コンテナ 計算 コンテナ オンプレのHadoop クラウドのHadoop NEW NEW データ移動 が必要 データ移動 不要 0:00 12:00 0:00 12:00 ク ラ ス タ 起 動 台 数 オンプレ クラウド 計算に必要なリソース
(C) Recruit Technologies Co.,Ltd. All rights reserved. 最新のHive 3.0
DWHの機能を拡充してきている オブジェクトストレージやRDBとJOINできるように ACIDトランザクション マテリアライズド・ビュー リザルトキャッシュ 行単位・カラム単位制御 同時実行制御。重いクエリをどかして、軽いクエリが流れるようにする制御 一つのクエリで、ACIDテーブルとリアルタイムデータの両方にクエリできるよう に 42
(C) Recruit Technologies Co.,Ltd. All rights reserved. Hadoopの所感 正直、みんなオンプレHadoopの運用に疲れてきた。なのでクラウドで使う
べき 本来の全量データ加工だけではなく、DWH用途に進化してきた 43
(C) Recruit Technologies Co.,Ltd. All rights reserved. アナリティックDB └DWH 44
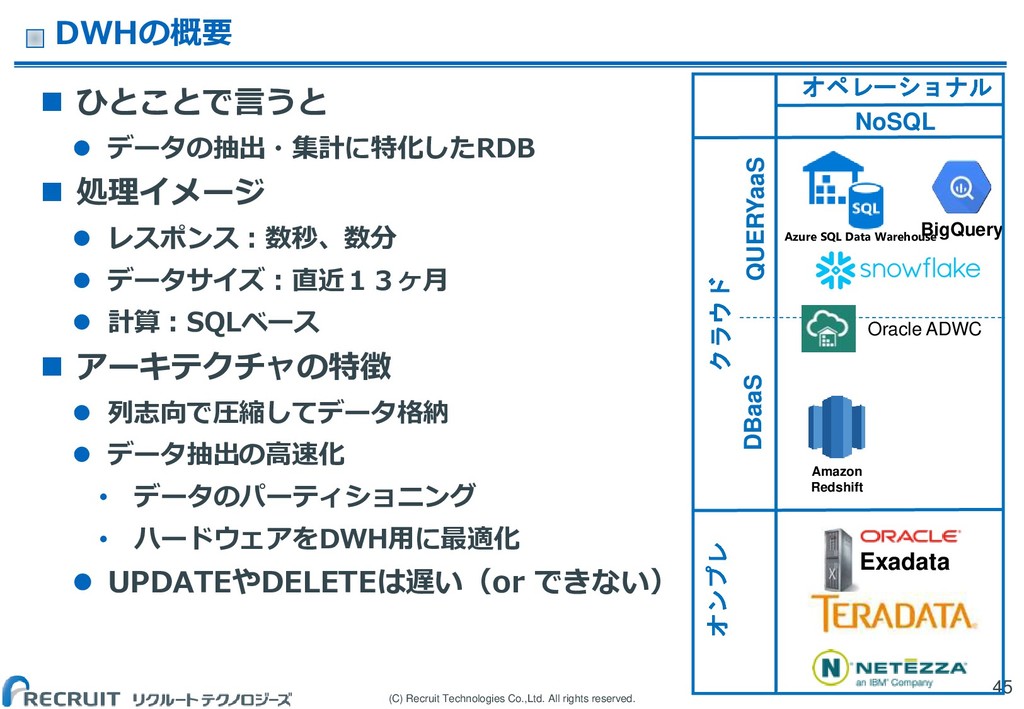
(C) Recruit Technologies Co.,Ltd. All rights reserved. DWHの概要 ひとことで言うと
データの抽出・集計に特化したRDB 処理イメージ レスポンス:数秒、数分 データサイズ:直近13ヶ月 計算:SQLベース アーキテクチャの特徴 列志向で圧縮してデータ格納 データ抽出の高速化 • データのパーティショニング • ハードウェアをDWH用に最適化 UPDATEやDELETEは遅い(or できない) 45 オペレーショナル NoSQL クラウド QUERYaaS DBaaS オンプレ Exadata BigQuery Oracle ADWC Amazon Redshift Azure SQL Data Warehouse
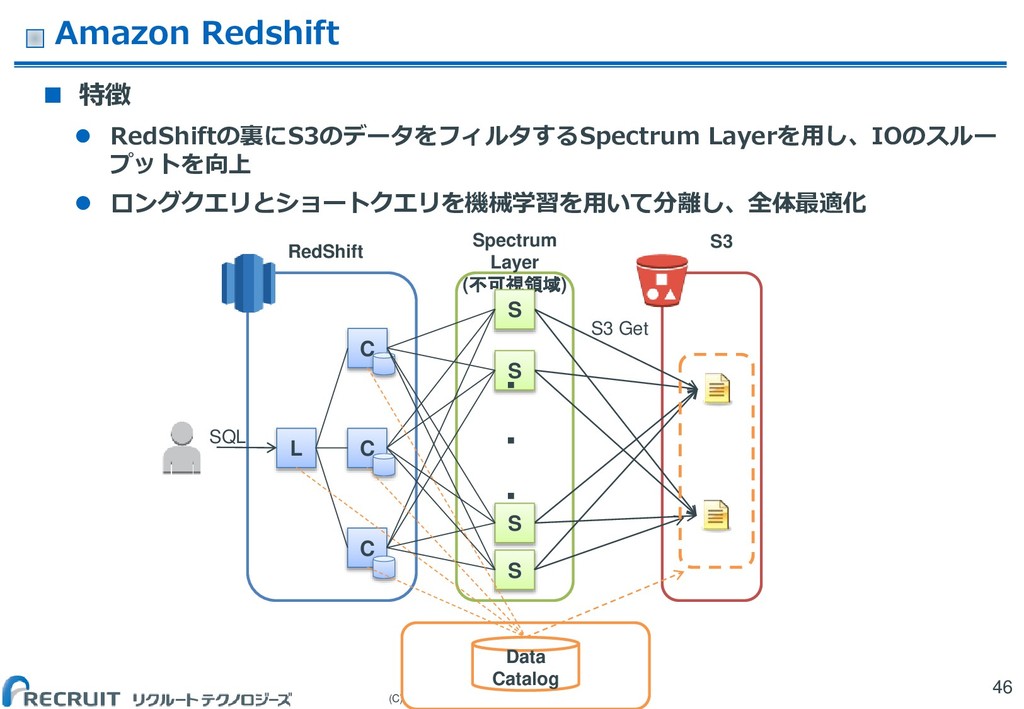
(C) Recruit Technologies Co.,Ltd. All rights reserved. Amazon Redshift
特徴 RedShiftの裏にS3のデータをフィルタするSpectrum Layerを用し、IOのスルー プットを向上 ロングクエリとショートクエリを機械学習を用いて分離し、全体最適化 46 Spectrum Layer (不可視領域) Data Catalog L C C C SQL S3 Get S S S S ・ ・ ・ S3 RedShift
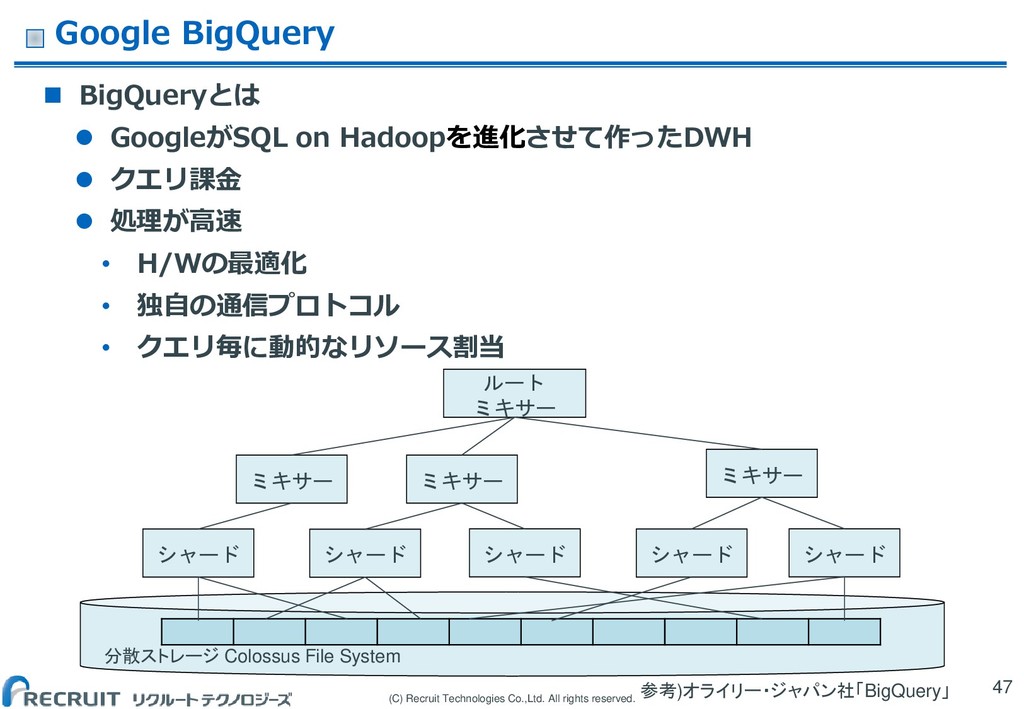
(C) Recruit Technologies Co.,Ltd. All rights reserved. Google BigQuery
BigQueryとは GoogleがSQL on Hadoopを進化させて作ったDWH クエリ課金 処理が高速 • H/Wの最適化 • 独自の通信プロトコル • クエリ毎に動的なリソース割当 47 分散ストレージ Colossus File System シャード シャード シャード シャード シャード ミキサー ミキサー ミキサー ルート ミキサー 参考)オライリー・ジャパン社「BigQuery」
(C) Recruit Technologies Co.,Ltd. All rights reserved. Google BigQuery
Webブラウザでクエリ開発 URLでテーブル共有可能 Googleアカウントとの統合 ユーザアカウント管理不要 データ共有 1クリックでデータ共有可能。ETL不要 BigQuery上で企業間データ交換できるプラットフォームが登場 機械学習:BigQueryML BigQueryにあるデータを移動すること無く機械学習できる pythonベースの機械学習では困難だった大量データの扱いが簡単に スケジュールドクエリ SQLの中にスケジュールを書くと定期実行してくれる cronやジョブスケジューラ不要 コラボレーション:Colaboratory jupyter notebookでBigQueryのクエリと結果をチームで共有 48
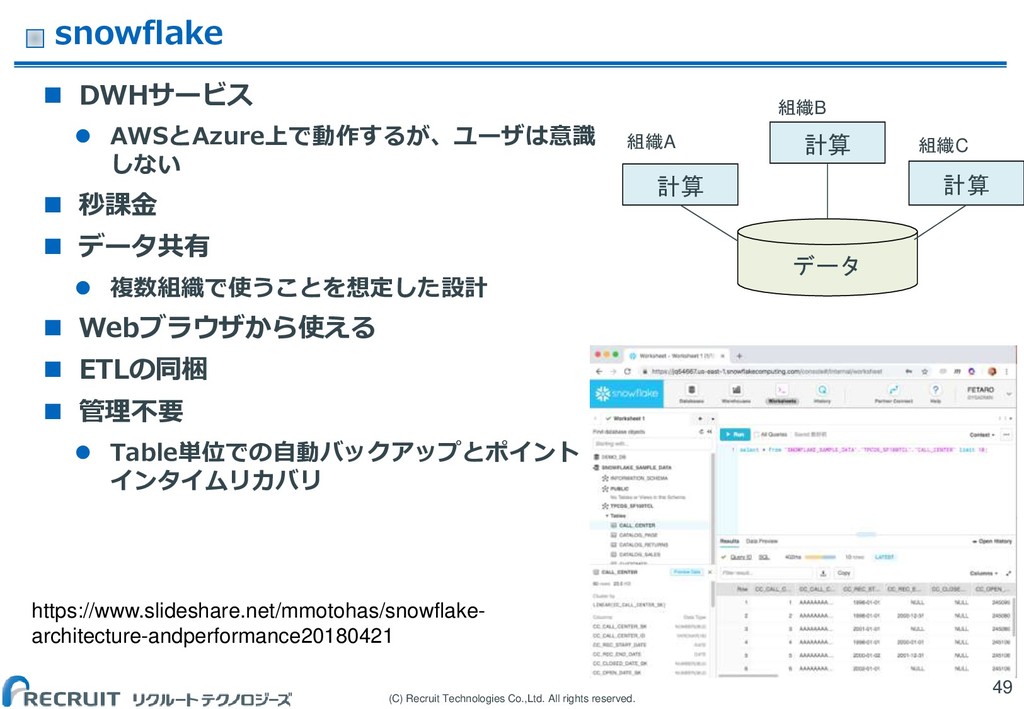
(C) Recruit Technologies Co.,Ltd. All rights reserved. snowflake DWHサービス
AWSとAzure上で動作するが、ユーザは意識 しない 秒課金 データ共有 複数組織で使うことを想定した設計 Webブラウザから使える ETLの同梱 管理不要 Table単位での自動バックアップとポイント インタイムリカバリ 49 https://www.slideshare.net/mmotohas/snowflake- architecture-andperformance20180421 データ 計算 計算 計算 組織A 組織B 組織C
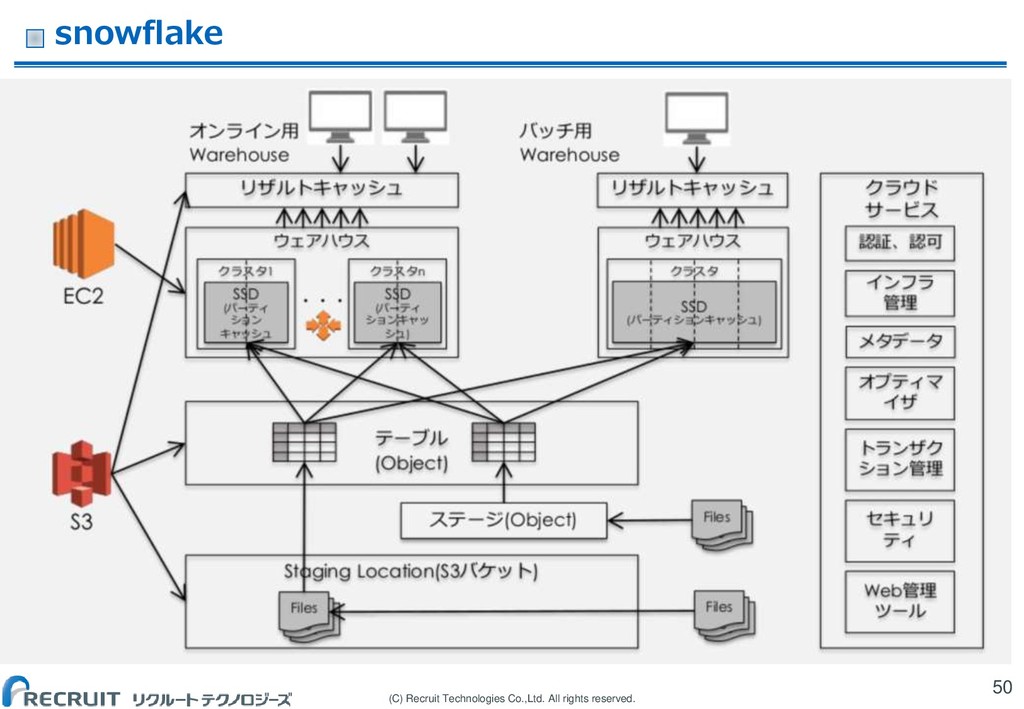
(C) Recruit Technologies Co.,Ltd. All rights reserved. snowflake 50
(C) Recruit Technologies Co.,Ltd. All rights reserved. Oracle ADWC(Autonomous Data
Warehouse Cloud) 2017/10に発表 Oracle Cloud上で提供されるDWHサービス Exadataの上に作られていて、列志向処理, 圧縮, 分散処理ができる コンピュートとストレージの分離、ダウンタイムなし、リソース消費の料金 体系 Oracle object store, S3, オンプレからデータロードできる WebベースのSQL notebook、データ共有が可能 Redshift, SQL Serverからのマイグレーション機能 自動パッチ、バックアップ、パフォーマンス最適化 51 http://www.oracle.com/technetwork/database/bi-datawarehousing/adwc-ebook-4081945.pdf
(C) Recruit Technologies Co.,Ltd. All rights reserved. DWHの所感 BigQuery,
snowflake, Oracle ADWC, いずれもDB以外の似たような機 能を拡充している。これが時代の潮流だろう。 今後のDWHでは以下の機能が実現されていくだろう。 Webブラウザから使える 標準SQL クエリ課金 クラウドのオブジェクトストレージにあるデータを扱える 会社・組織を意識したデータ共有の仕組み 会社・組織を意識したアカウント管理 機械学習へのシームレスな連携 可視化ツールへのシームレスな連携 ETL同梱 メタデータ管理 ジョブ管理 52
(C) Recruit Technologies Co.,Ltd. All rights reserved. その他ビッグデータ関連キーワードの説明 53
(C) Recruit Technologies Co.,Ltd. All rights reserved. Spark Spark
データサイエンティストのために作られた分析ライブラリ群 Hadoopが無くても動く データベースではない • データ蓄積はHadoopのHDFSでもよいし、そうでなくても良い 以下の様なものが含まれる • Spark 本体 :メモリベースで集計などをする • Spark MLib:機械学習 • Spark SQL:SQLライクなインターフェース • Spark Stream:マイクロバッチ Azure databricks / databricks on AWS クラウドで利用できるSparkベースの分析プラットフォーム サービス Sparkクラスタの管理・ジョブ管理・notebookによるコラボ レーション等、データサイエンスに集中できるような周辺機能 を提供している。 54
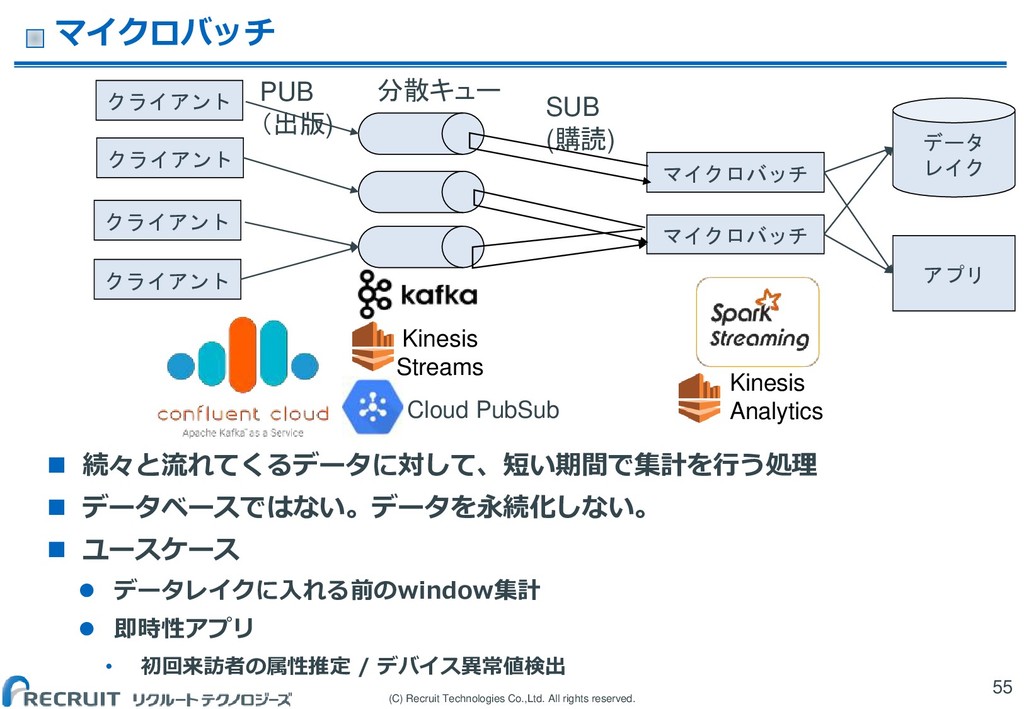
(C) Recruit Technologies Co.,Ltd. All rights reserved. マイクロバッチ 続々と流れてくるデータに対して、短い期間で集計を行う処理
データベースではない。データを永続化しない。 ユースケース データレイクに入れる前のwindow集計 即時性アプリ • 初回来訪者の属性推定 / デバイス異常値検出 55 Kinesis Analytics Kinesis Streams マイクロバッチ マイクロバッチ PUB (出版) SUB (購読) 分散キュー クライアント クライアント クライアント クライアント Cloud PubSub データ レイク アプリ
(C) Recruit Technologies Co.,Ltd. All rights reserved. Sparkとマイクロバッチの使い所 56 データ
レイク データ ウェア ハウス 機械 学習 データ ソース BI・ アプリ データ 探索 データ マート レポー ト 推論結 果 アプリ 整形 DWH or (少量ならRDBも 可) ↓ NoSQL ↓ オブジェクトストレージ or Hadoopのストレージ ↓ 集計 加工 アプリ ETL製品 or Hadoop ↓ ←Spark スピード バッチ マイクロバッチ ↓ ↑ Spark Python等→
(C) Recruit Technologies Co.,Ltd. All rights reserved. まとめ 57
(C) Recruit Technologies Co.,Ltd. All rights reserved. まとめ データベースを分類
重視する性能での分類:オペレーショナル/アナリティック マネージド度合いでの分類:オンプレ/DBサービス/クエリサービス RDB トランザクションがスケールする時代 RDBの代名詞Oracle社もクラウド全力投資 NoSQL レスポンス性能追求と開発容易性追求で分類すべき 開発容易性を追求するとDBを意識しない状態になる Hadoop クラウド&オブジェクトストレージ利用が当たり前に HiveはDWHの機能を拡張 DWH クエリサービスが今後の主戦場 DB以外の周辺機能が差別化ポイント 58
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}