Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
What Context Features Can Transformer Language ...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
hajime kiyama
August 31, 2023
100
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
What Context Features Can Transformer Language Models Use?
Japanese explanation
hajime kiyama
August 31, 2023
More Decks by hajime kiyama
See All by hajime kiyama
通時的な類似度行列に基づく単語の意味変化の分析
rudorudo11
0
330
Idiosyncrasies in Large Language Models
rudorudo11
0
63
People who frequently use ChatGPT for writing tasks are accurate and robust detectors of AI-generated text
rudorudo11
0
280
Analyzing Continuous Semantic Shifts with Diachronic Word Similarity Matrices.
rudorudo11
0
230
Using Synchronic Definitions and Semantic Relations to Classify Semantic Change Types
rudorudo11
0
110
Analyzing Semantic Change through Lexical Replacements
rudorudo11
0
370
意味変化分析に向けた単語埋め込みの時系列パターン分析
rudorudo11
1
210
Bridging Continuous and Discrete Spaces: Interpretable Sentence Representation Learning via Compositional Operations
rudorudo11
0
340
Word Sense Extension
rudorudo11
0
160
Featured
See All Featured
Visual Storytelling: How to be a Superhuman Communicator
reverentgeek
2
590
Six Lessons from altMBA
skipperchong
29
4.3k
Navigating the Design Leadership Dip - Product Design Week Design Leaders+ Conference 2024
apolaine
1
370
Exploring anti-patterns in Rails
aemeredith
3
440
Lessons Learnt from Crawling 1000+ Websites
charlesmeaden
PRO
1
1.4k
How People are Using Generative and Agentic AI to Supercharge Their Products, Projects, Services and Value Streams Today
helenjbeal
1
230
A Soul's Torment
seathinner
6
3.1k
Color Theory Basics | Prateek | Gurzu
gurzu
0
390
Git: the NoSQL Database
bkeepers
PRO
432
67k
4 Signs Your Business is Dying
shpigford
187
22k
Helping Users Find Their Own Way: Creating Modern Search Experiences
danielanewman
31
3.2k
From π to Pie charts
rasagy
0
230
Transcript
What Context Features Can Transformer Language Models Use? Joe O’Connor
Jacob Andreas ACL 2021 発表者 : B4 木山 朔 発表日 : 6/15 1
概要 • Transformerベースの言語モデルは数百-千の前のトークンの文脈を使用 • どのような文脈情報がモデル予測に役立つか? • 語彙や構造的な情報を削除し,有益な情報を測定 ◦ V-information[Xu+2020] を用いて分析
◦ 中距離,長距離の文脈で実験 ◦ 語順の入れ替え,名詞以外の単語の削除など ◦ ある破壊的操作では削除できる情報は 15%未満 • 長い文脈がlow perplexityにとって重要であると示唆 ◦ 詳細な構文や命題の内容よりも長い文脈の方が重要 2
手法 1/5 • V-information[Xu+2020] ◦ Vの任意の予測変数によって, XからYに関する余分な情報が どれだけ抽出されるかを表す ▪ Y
: ターゲット単語 ▪ X : 文脈 ▪ V : パラメトリックモデルのクラス ▪ p1 : Xにアクセスできないモデル ▪ p2 : Xにアクセスできるモデル 3
手法 2/5 • どの文脈のどのような情報がモデルに利用されているか? ◦ 例:ターゲットトークンから 5トークン以上離れたところでは名詞しか抽出しない ▪ X_{i:j} :
i番目からj-1番目のトークン列 ▪ nouns : 名詞のみを抽出する関数 4
手法 3/5 • ablated context : ablation関数で処理されたcontext ◦ f :
アブレーション ◦ k : 整数のオフセット • ablated negative log-likelihood : ablateされた負の対数尤度関数 5
手法 4/5 • 各ablation (f) の使用可能な情報への影響を測定 ◦ 0に近いほど情報が削除されない ◦ 1に近いほど情報が削除される
◦ どれだけ情報が失われるかを測る • 直感的説明 ◦ k個のtokenに対してfを適応した情報を, fを適用していない情報で割る 6
手法 5/5 • (7)式を改良 ◦ ホールドアウトやバッチ処理に対応 ◦ この手法を用いて評価 ◦ |X|
: 文字列のデータセットサイズ ◦ f : アブレーション ◦ l : アブレーションを行う範囲 ◦ m,n : l+mからl+nまでの 尤度計算の対象を選択 • ablationを適応しないとき ◦ L(θ,m ∼ n)で表現する. 7
実験設定 • モデル ◦ GPT-2モデル[Radford+2019] ◦ デフォルトのハイパーパラメータ [Wolf+2020] • 訓練データ
◦ WikiText-103データセット[Merity+2016] • 前処理 ◦ abletionのみ適応 • 品詞タグ付け ◦ spaCy[Honnibal+2020] 8
比較手法 • 訓練時の条件 ◦ no infomation ▪ L(θ,0 ∼ 512)を最小にするように学習
◦ full infomation ▪ L(θ,512 ∼ 1024)を最小にするように学習 ◦ ablation model ▪ L(θ,f,512 : 0 ∼ 512)を最小にするように学習 • 評価時の条件 ◦ 中距離の条件 : L(·,f, 512 : 0 ∼ 256) ◦ 長距離の条件 : L(·,f, 512 : 256 ∼ 512) • ablation ◦ 単語の順序と文の順序 ◦ 品詞の抽出と単語の頻度 9
全体の語順 例 10 文章内で1-gramでshufle 文章内で3-gramでshuffle
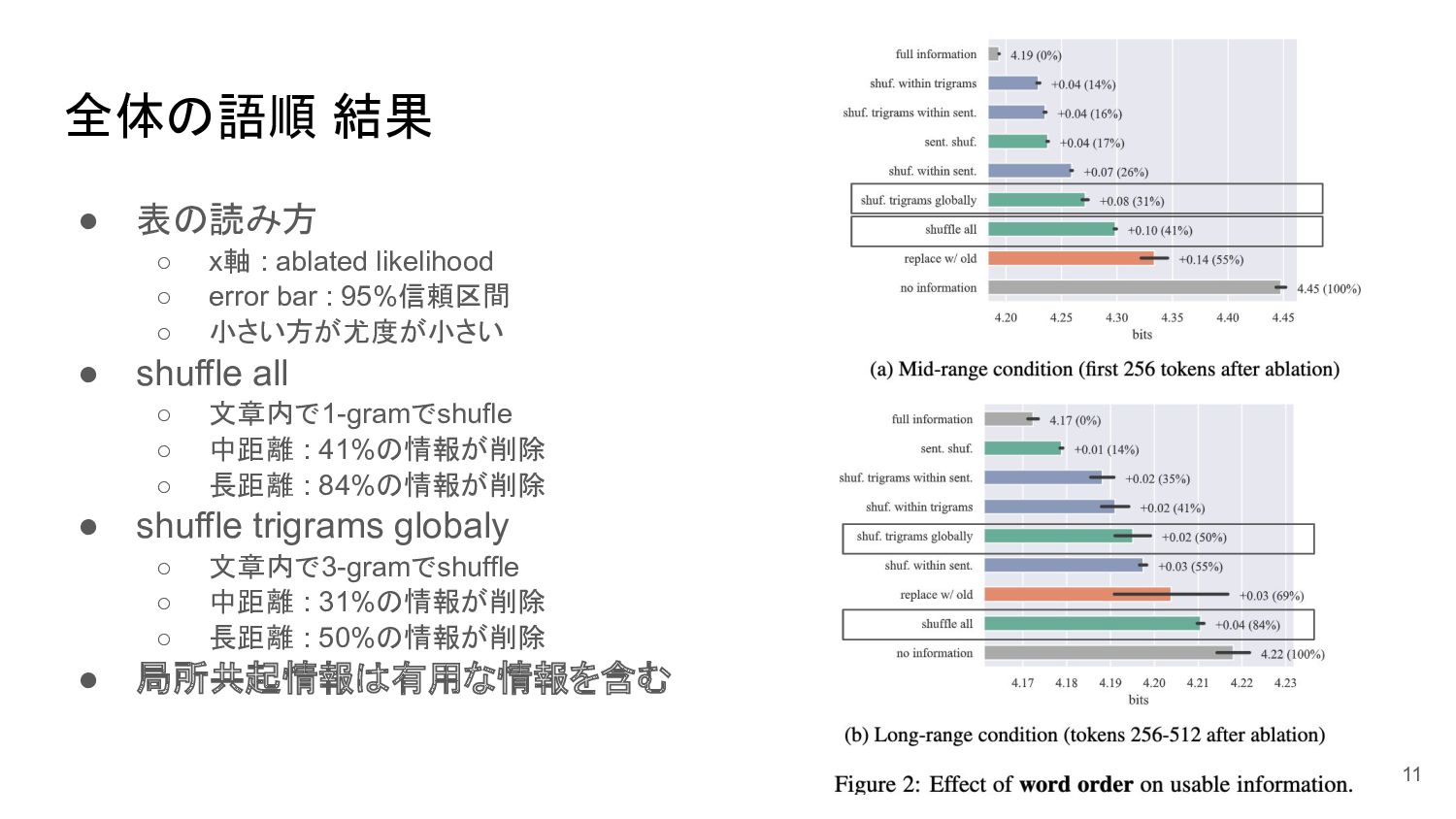
全体の語順 結果 • 表の読み方 ◦ x軸 : ablated likelihood ◦
error bar : 95%信頼区間 ◦ 小さい方が尤度が小さい • shuffle all ◦ 文章内で1-gramでshufle ◦ 中距離 : 41%の情報が削除 ◦ 長距離 : 84%の情報が削除 • shuffle trigrams globaly ◦ 文章内で3-gramでshuffle ◦ 中距離 : 31%の情報が削除 ◦ 長距離 : 50%の情報が削除 • 局所共起情報は有用な情報を含む 11
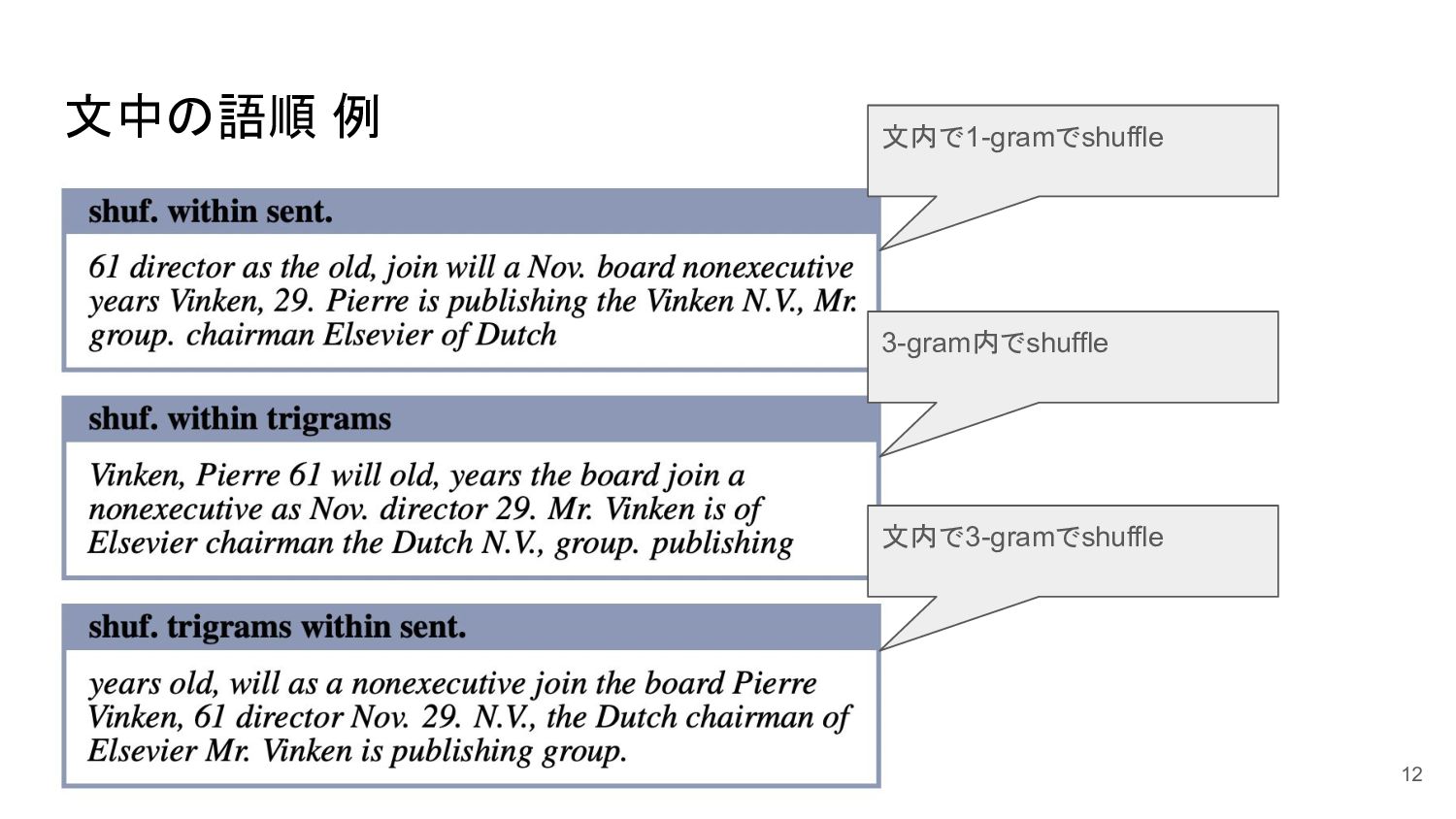
文中の語順 例 12 文内で1-gramでshuffle 文内で3-gramでshuffle 3-gram内でshuffle
文中の語順 結果 • shuffle within sentence ◦ 文内で1-gramでshuffle ◦ 中距離
: 26%の情報が削除 ◦ 長距離 : 55%の情報が削除 • shuffle within trigram ◦ 3-gram内でshuffle ◦ 中距離 : 14%の情報が削除 ◦ 長距離 : 41%の情報が削除 • shuffle trigram within sentence ◦ 文内で3-gramでshuffle ◦ 中距離 : 16%の情報が削除 ◦ 長距離 : 35%の情報が削除 • 局所共起情報や文内での単語の順番 は有益な情報を含む 13
文/セクションの順序 例 14 文単位でshuffle 入力をソース文章の直前 512tokenに置換
文/セクションの順序 結果 • shuffle sentence ◦ 文単位でshuffle ◦ 中距離 :
17%の情報が削除 ◦ 長距離 : 14%の情報が削除 ◦ 細かい単語の順序,グローバルな位置は 有益でない • replace with old ◦ 入力をソース文章の直前 512tokenに置換 ◦ 中距離 : 55%の情報が削除 ◦ 長距離 : 69%の情報が削除 ◦ 長期な文脈は単にトピックの情報源ではない ◦ 同じテーマに関する以前のテキストは 情報がないこともある 15
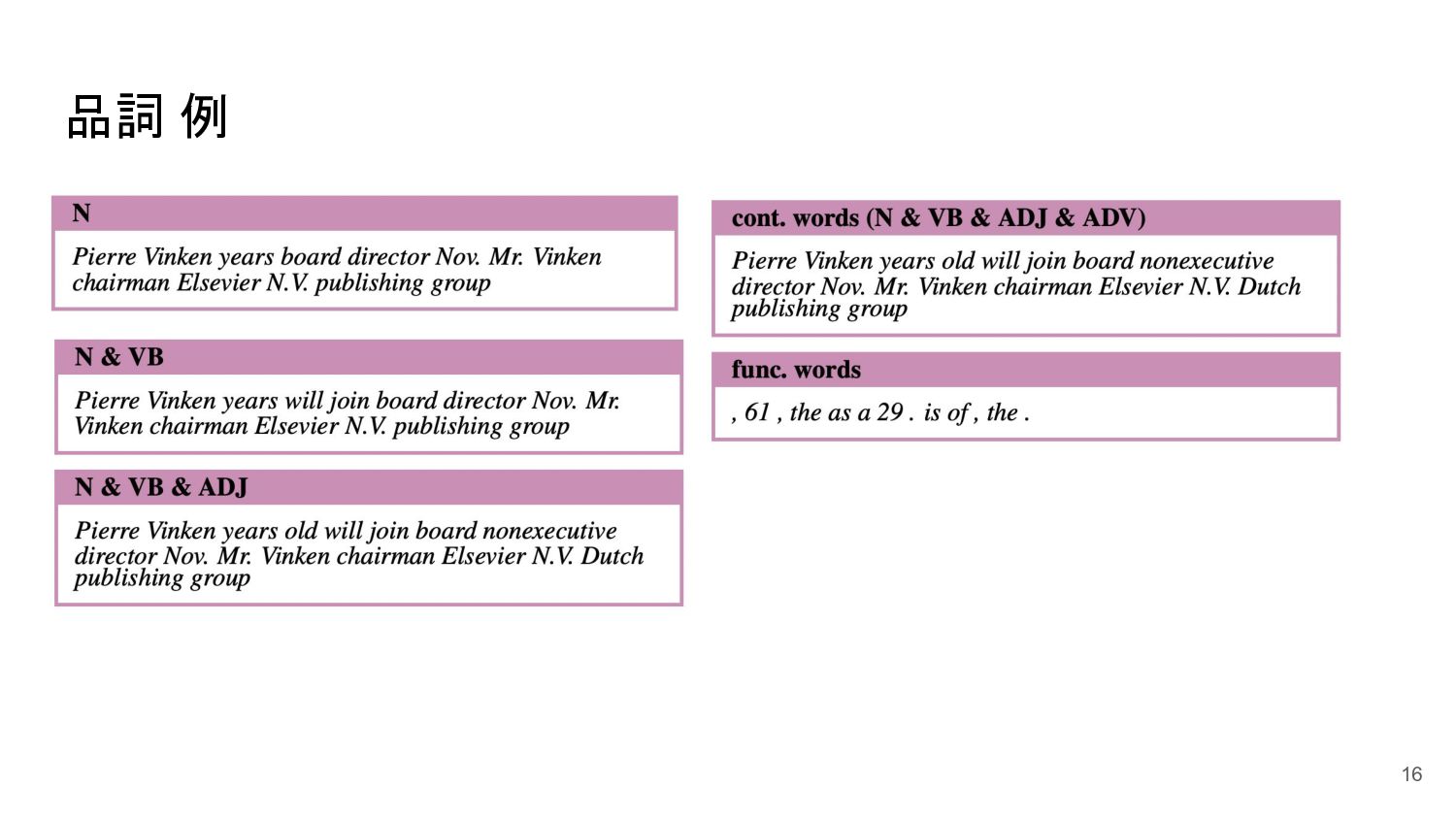
品詞 例 16
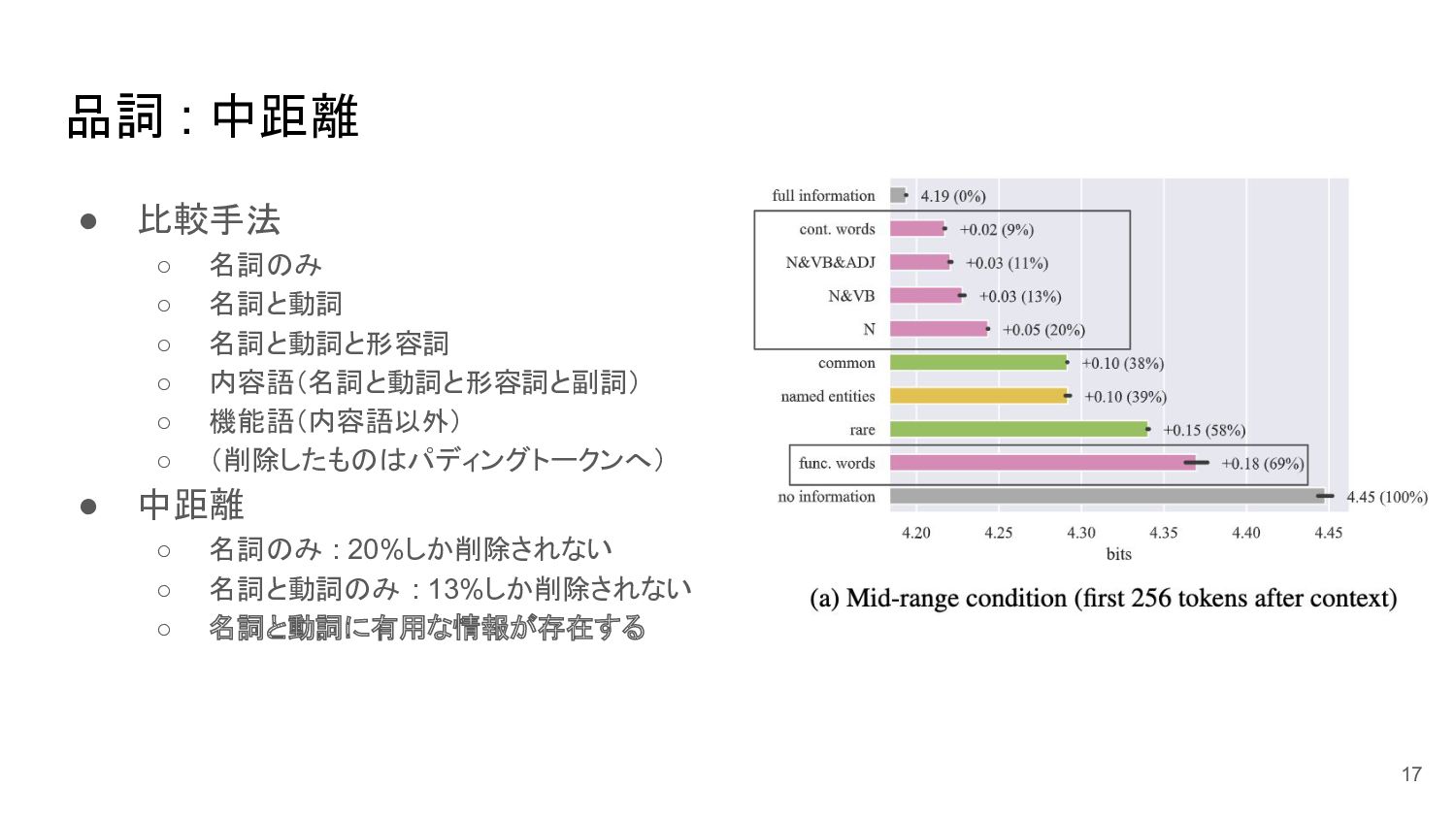
品詞 : 中距離 • 比較手法 ◦ 名詞のみ ◦ 名詞と動詞 ◦
名詞と動詞と形容詞 ◦ 内容語(名詞と動詞と形容詞と副詞) ◦ 機能語(内容語以外) ◦ (削除したものはパディングトークンへ) • 中距離 ◦ 名詞のみ : 20%しか削除されない ◦ 名詞と動詞のみ : 13%しか削除されない ◦ 名詞と動詞に有用な情報が存在する 17
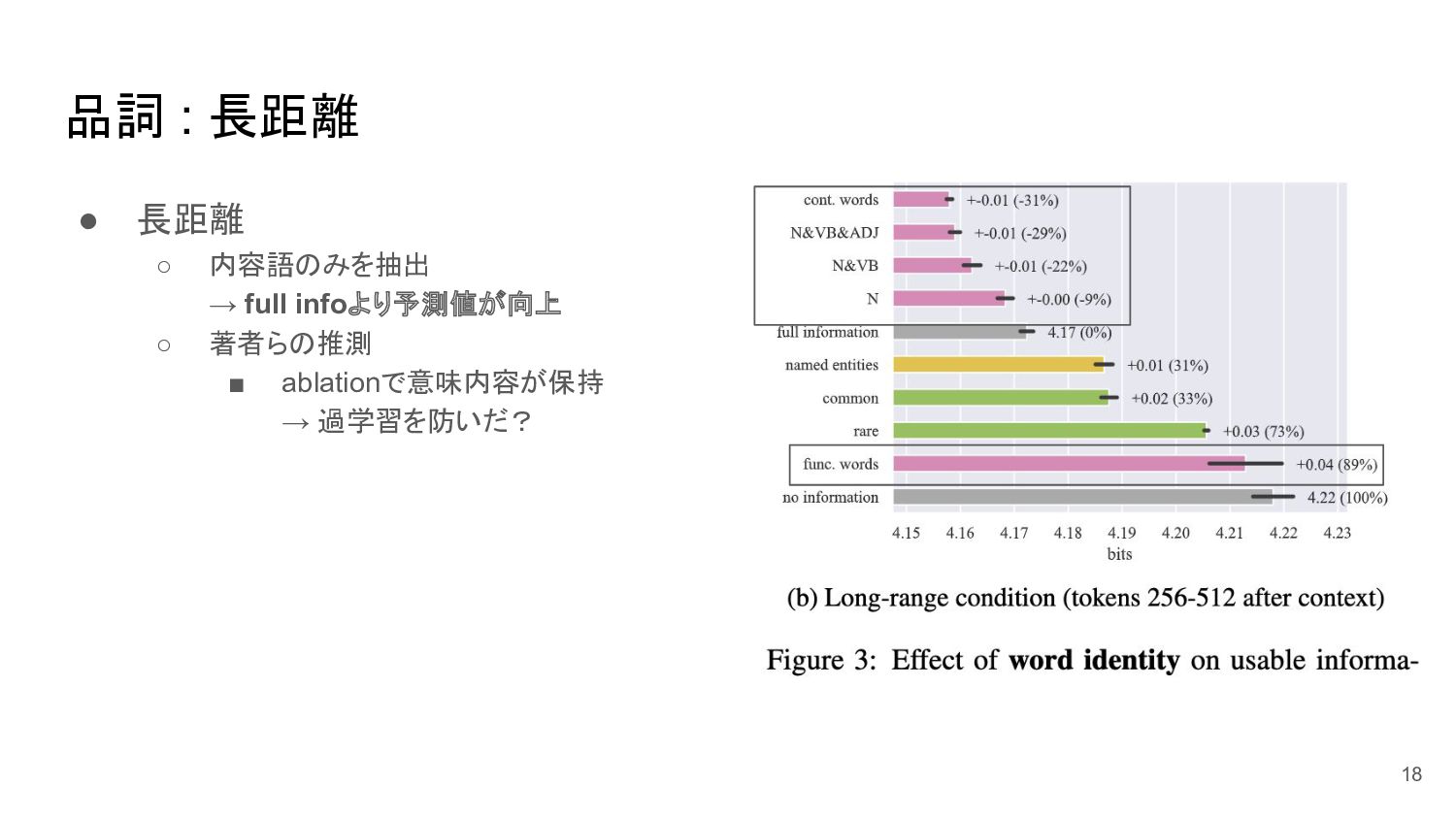
品詞 : 長距離 • 長距離 ◦ 内容語のみを抽出 → full infoより予測値が向上
◦ 著者らの推測 ▪ ablationで意味内容が保持 → 過学習を防いだ? 18
固有名詞と単語の頻度 例 19
固有名詞と単語の頻度 結果 • named entities ◦ 名詞以外の削除より性能が低下 ◦ 中/長距離共に3分の1程度の情報が削除 •
word frequency ◦ common/rare words どっちが重要? ◦ 品詞と比べるとかなり削除されている ◦ commonの方が削除量が小さい ◦ common wordsが重要 20
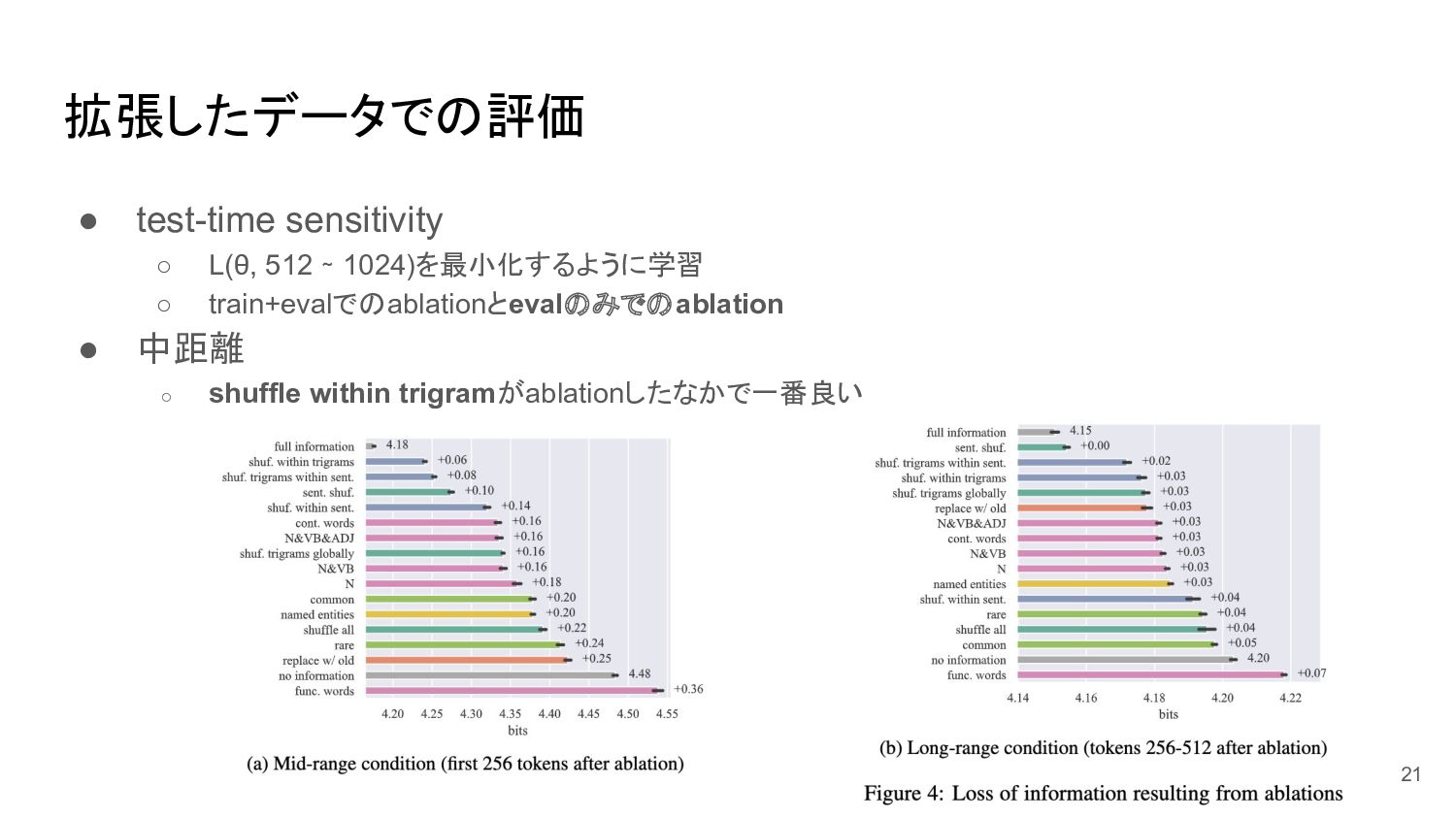
拡張したデータでの評価 21 • test-time sensitivity ◦ L(θ, 512 ∼ 1024)を最小化するように学習
◦ train+evalでのablationとevalのみでのablation • 中距離 ◦ shuffle within trigramがablationしたなかで一番良い
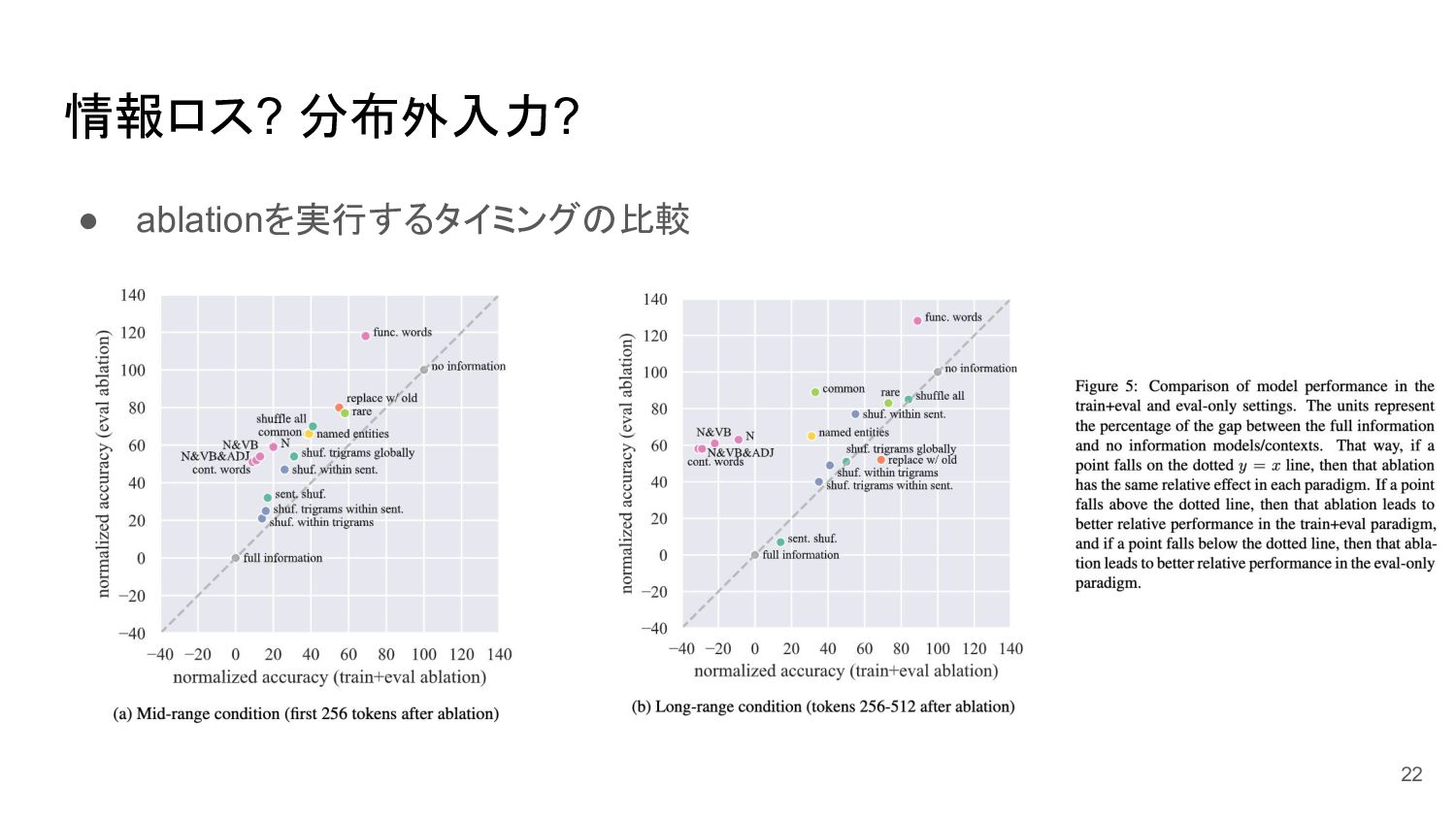
情報ロス? 分布外入力? • ablationを実行するタイミングの比較 22
より良い言語モデルを作れるのか? • 追加実験 ◦ 名詞と動詞のみをablateする実験を拡張 ◦ パディングトークンを,予測単語よりも後ろの名詞と動詞に置換 ◦ 置換前後と比べての性能 ◦
中距離 : + 0.2% ◦ 長距離 : - 0.6% ◦ 著者らの仮定と一致 ▪ 情報を削除すると過学習しなくなり情報を追加すると過学習する 23
まとめ • どのtransformerモデルが長距離文脈の構造/意味的情報に使えるか? ◦ 内容語と局所的な順序 (3-gram内のシャッフル)が使える ◦ 他の情報を除去してもモデルの予測精度にほとんど影響しない ◦ 文書を同定する情報や固有名詞の情報では,予測精度が大きく低下
• 削除された文脈に基づき学習/テストを行い評価 ◦ これまでは評価時の削除の影響で評価 ◦ 訓練時+評価時,評価時のみの削除を比較 ◦ 今後のモデル化研究の出発点 24
{kind=link}
![概要 • Transformerベースの言語モデルは数百-千の前のトークンの文脈を使用 • どのような文脈情報がモデル予測に役立つか? • 語彙や構造的な情報を削除し,有益な情報を測定 ◦ V-information[Xu+2020] を用いて分析](https://files.speakerdeck.com/presentations/20130c1a5bf64caa8062dc7655b6d26b/slide_1.jpg){kind=link}
![手法 1/5 • V-information[Xu+2020] ◦ Vの任意の予測変数によって, XからYに関する余分な情報が どれだけ抽出されるかを表す ▪ Y](https://files.speakerdeck.com/presentations/20130c1a5bf64caa8062dc7655b6d26b/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![実験設定 • モデル ◦ GPT-2モデル[Radford+2019] ◦ デフォルトのハイパーパラメータ [Wolf+2020] • 訓練データ](https://files.speakerdeck.com/presentations/20130c1a5bf64caa8062dc7655b6d26b/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}