Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
The Geometry of Multilingual Language Model Rep...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
hajime kiyama
August 31, 2023
Research
260
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
The Geometry of Multilingual Language Model Representations
Japansese explanation for SNLP2023
hajime kiyama
August 31, 2023
More Decks by hajime kiyama
See All by hajime kiyama
通時的な類似度行列に基づく単語の意味変化の分析
rudorudo11
0
330
Idiosyncrasies in Large Language Models
rudorudo11
0
63
People who frequently use ChatGPT for writing tasks are accurate and robust detectors of AI-generated text
rudorudo11
0
270
Analyzing Continuous Semantic Shifts with Diachronic Word Similarity Matrices.
rudorudo11
0
230
Using Synchronic Definitions and Semantic Relations to Classify Semantic Change Types
rudorudo11
0
100
Analyzing Semantic Change through Lexical Replacements
rudorudo11
0
370
意味変化分析に向けた単語埋め込みの時系列パターン分析
rudorudo11
1
210
Bridging Continuous and Discrete Spaces: Interpretable Sentence Representation Learning via Compositional Operations
rudorudo11
0
340
Word Sense Extension
rudorudo11
0
160
Other Decks in Research
See All in Research
【中間報告】国会議員の立法・政策実務を支える環境を巡る現状と課題
polipoli
0
220
機械学習で作った ポケモン対戦bot で 遊ぼう!
fufufukakaka
0
330
羽田新ルート運用6年の検証
1manken
0
160
CyberAgent AI Lab研修 / Social Implementation Anti-Patterns in AI Lab
chck
7
4.7k
コーディングエージェントとABNを再考
hf149
2
740
人間中心の意思決定支援AI
yukinobaba
PRO
6
3.1k
COFFEE-Japan PROJECT Impact Report(海ノ向こうコーヒー)
ontheslope
0
2k
討議:RACDA設立30周年記念都市交通フォーラム2026
trafficbrain
0
1k
第64回CV・PRML勉強会 論文紹介:Linguistic Priors for Visual Decoupling: Towards Symmetric Vision-Brain Alignment
sokikatayama
0
120
SAKURAONE: An Open Ethernet-based AI HPC System And Its Observed Workload Dynamics in a Single-Tenant LLM Development Environment
yuukit
1
400
RS-Agent: Automating Remote Sensing Tasks through Intelligent Agent
satai
2
340
Scalable dynamic origin-destination demand estimation enhanced by high-resolution satellite imagery data
satai
3
310
Featured
See All Featured
Building a Modern Day E-commerce SEO Strategy
aleyda
45
9.1k
Have SEOs Ruined the Internet? - User Awareness of SEO in 2025
akashhashmi
0
380
Between Models and Reality
mayunak
4
360
Context Engineering - Making Every Token Count
addyosmani
9
1k
Designing for humans not robots
tammielis
254
26k
Noah Learner - AI + Me: how we built a GSC Bulk Export data pipeline
techseoconnect
PRO
0
210
Design and Strategy: How to Deal with People Who Don’t "Get" Design
morganepeng
133
19k
Everyday Curiosity
cassininazir
0
240
Tell your own story through comics
letsgokoyo
1
980
How to Talk to Developers About Accessibility
jct
2
270
How to Get Subject Matter Experts Bought In and Actively Contributing to SEO & PR Initiatives.
livdayseo
0
150
KATA
mclloyd
PRO
35
15k
Transcript
発表者:木山 朔 東京都立大学 M1 最先端NLP2023 1 ※スライド中の図表は指定がない限りは論文からの引用となります。 EMNLP2022
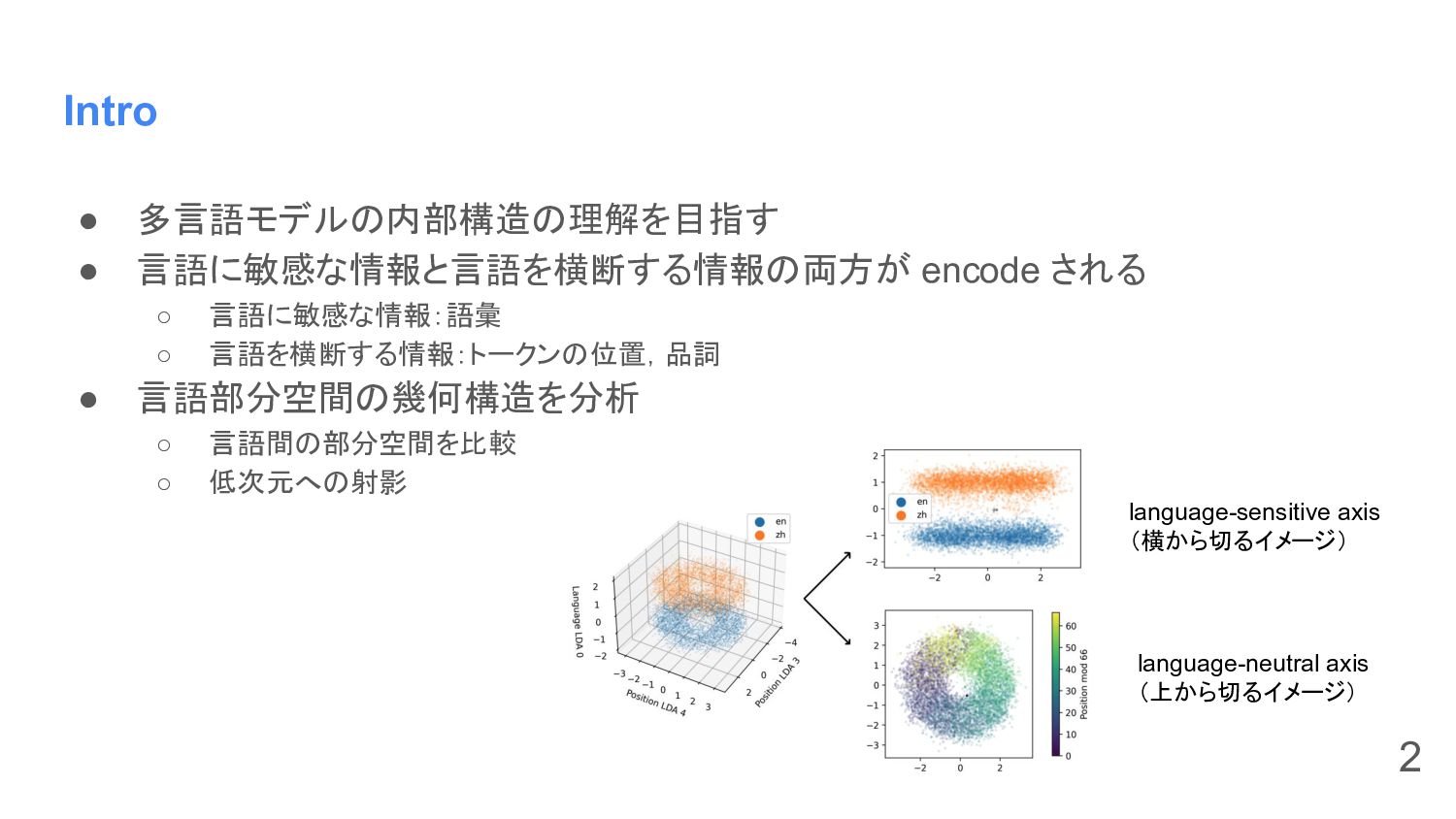
Intro • 多言語モデルの内部構造の理解を目指す • 言語に敏感な情報と言語を横断する情報の両方が encode される ◦ 言語に敏感な情報:語彙 ◦
言語を横断する情報:トークンの位置,品詞 • 言語部分空間の幾何構造を分析 ◦ 言語間の部分空間を比較 ◦ 低次元への射影 2 language-sensitive axis (横から切るイメージ) language-neutral axis (上から切るイメージ)
Related work • 多言語モデルがどのような情報を encode するか? ◦ 言語間の平均表現距離 [Rama et
al., 2020] [Choenni and Shutova, 2020] [Liang et al., 2021] ▪ 言語間の差異に相関,類型的特徴の予測に使用可能 ◦ 構文情報 [Chi et al., 2020] ◦ トークン頻度 [Rajaee and Pilehvar, 2022] ◦ 言語平均の変換による文検索 [Libovický et al., 2020] [Pires et al., 2019] • 多言語モデルの埋め込み空間の幾何学的な形状については分析されていない ◦ 上記の研究は特定の特徴に焦点を当てている ◦ 幾何学的な分析がなされていない ◦ 言語部分空間から特徴を encodeする軸を特定 3
Language subspace • モデル:XLM-R [Conneau et al., 2020a] ◦ RoBERTa
ベースで100言語を学習 • データセット:OSCAR [Abadji et al., 2021] ◦ web のテキストデータ ◦ 各系列が512トークンを含むように文を連結 ◦ 言語ごとに 262k の文脈を使用 ◦ 言語ごとに対応は取れていない • 特異値分解 (SVD) を用いて88言語をアフィン変換 ◦ モデルとデータセットの両方に出現する言語を対象 ◦ ここでのアフィン変換:平均によるシフトを行い,線形変換 4
• 言語Aに対する部分空間を定義 ◦ 言語内の分散を最大化する k方向を使ってアフィン部分空間を定義 ◦ 平均化した埋め込みを使って特異値分解することで求める ◦ kは部分空間が言語Aの全分散の90%を占めるように定義 Affine
language subspaces 5
Affine subspaces accounted for language modeling performance • ターゲット言語Aに対する perplexity
を評価する ◦ 射影前後の埋め込み表現の perplexity の比を評価 ◦ 言語A以外の言語Bでの評価も実施 ◦ 言語Aの部分空間に射影した埋め込み表現を用意 ◦ 言語Aで平均化し,言語Bの部分空間に射影したものも比較 6
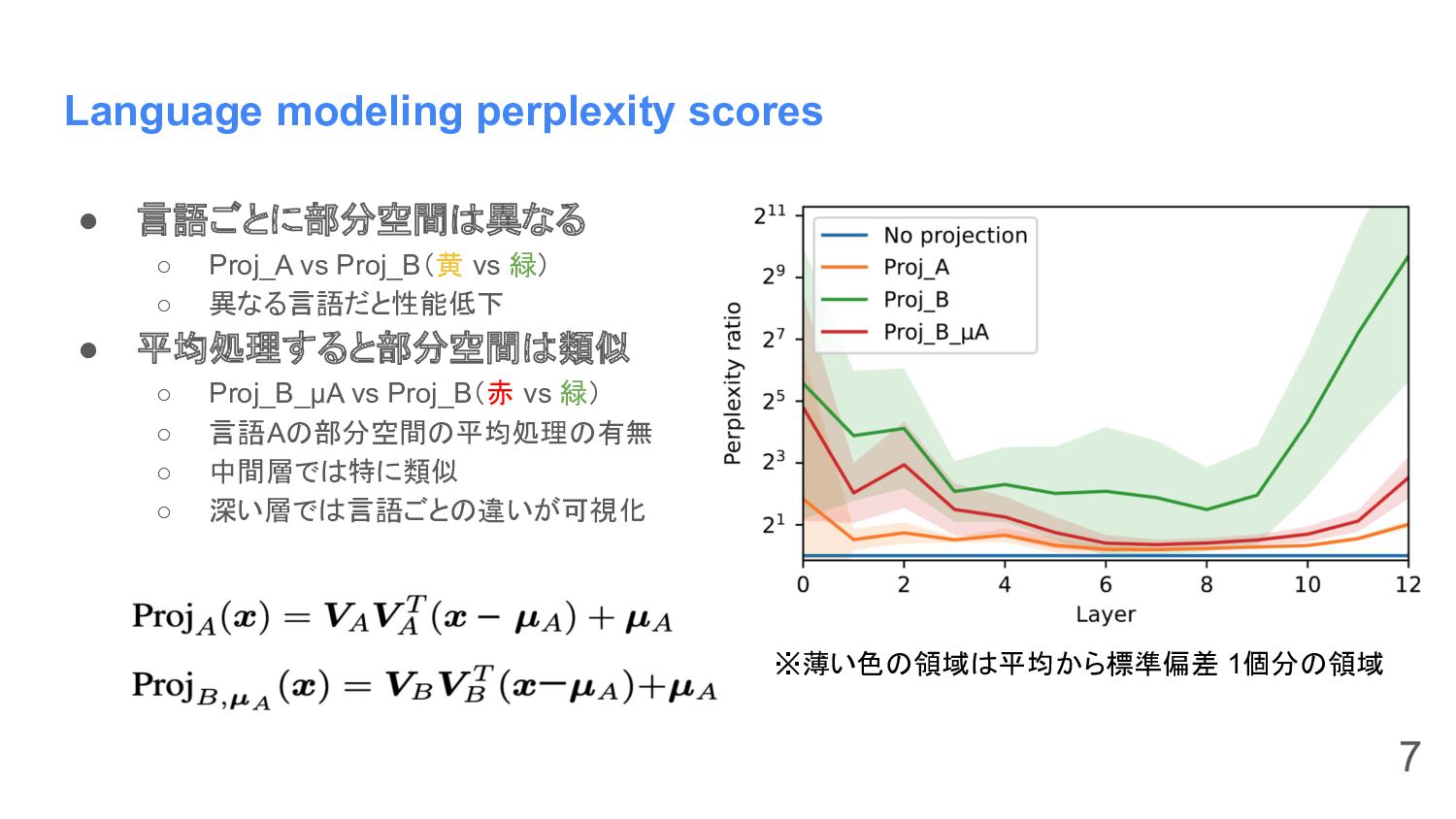
Language modeling perplexity scores • 言語ごとに部分空間は異なる ◦ Proj_A vs Proj_B(黄
vs 緑) ◦ 異なる言語だと性能低下 • 平均処理すると部分空間は類似 ◦ Proj_B_μA vs Proj_B(赤 vs 緑) ◦ 言語Aの部分空間の平均処理の有無 ◦ 中間層では特に類似 ◦ 深い層では言語ごとの違いが可視化 7 ※薄い色の領域は平均から標準偏差 1個分の領域
Subspace dinstance • 特異値分解から各言語の主軸と対応する分散が特定可能 • 軸と分散を共分散行列 K として定義 • (1)
式の距離を用いて評価 [Bonnabel and Sepulchre, 2009] ◦ 部分空間の平均を無視できる指標 ◦ 88の言語部分空間間のペアワイズ距離を算出 ◦ λ_i: の固有値 8
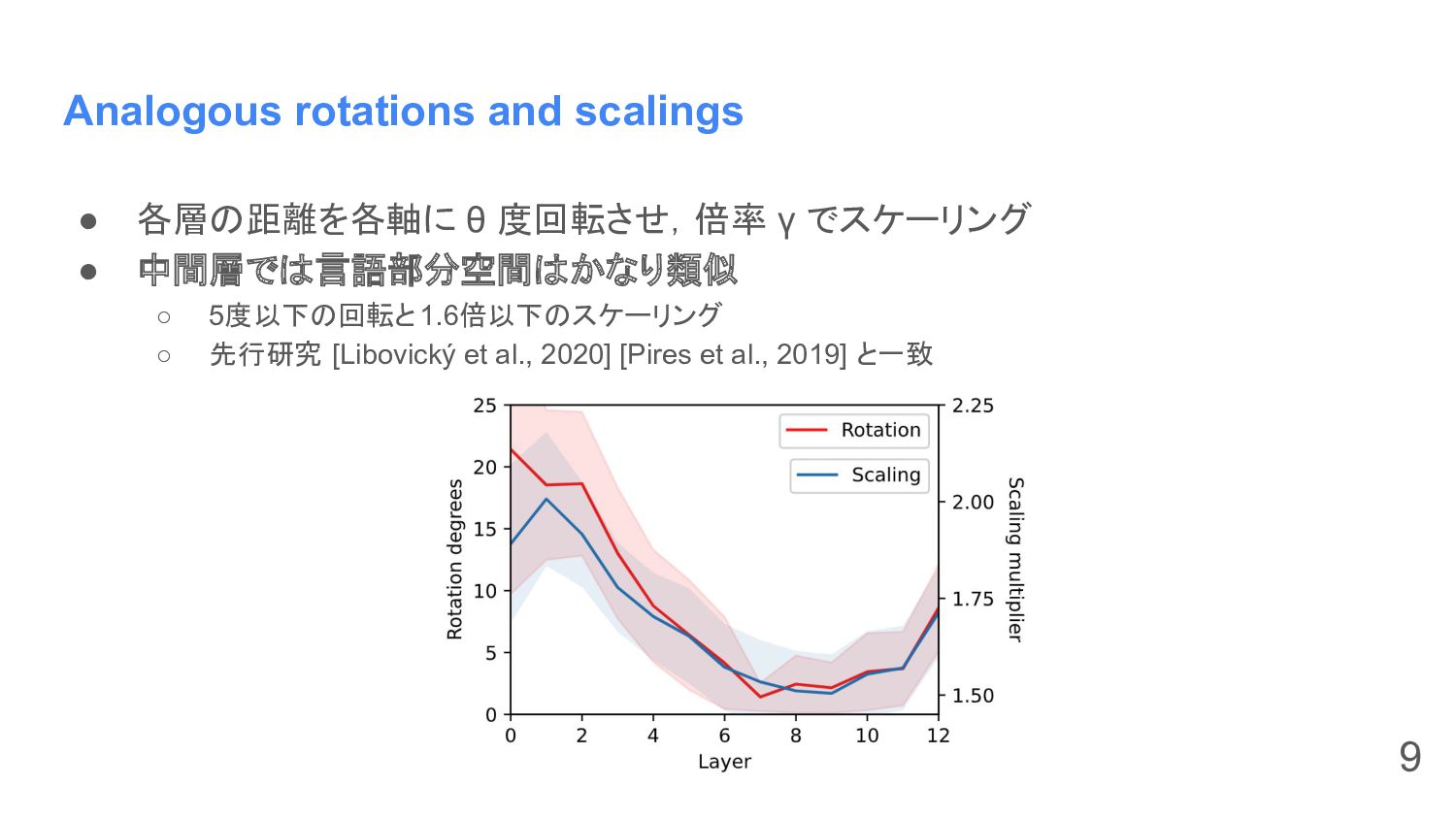
Analogous rotations and scalings • 各層の距離を各軸に θ 度回転させ,倍率 γ でスケーリング
• 中間層では言語部分空間はかなり類似 ◦ 5度以下の回転と1.6倍以下のスケーリング ◦ 先行研究 [Libovický et al., 2020] [Pires et al., 2019] と一致 9
Language-sensitive axes • 言語感受性 (Language-sensitive) ◦ 言語Aと言語Bが異なる分布を持つ ▪ 入力言語で変化する情報 •
言語部分空間は平均化すると似たような空間となる • 一方で言語部分空間における平均の違いが存在 ◦ 言語特有の情報を持つ軸が存在するのでは? • 言語感受性について分析 ◦ 言語平均のシフトはターゲット言語の語彙を誘発させる ◦ LDA による分析により言語族の観点で分離する軸を発見 10
Inducing target language vocabulary • 言語固有の語彙を定義 ◦ OSCAR コーパスの10億個のトークンを対象 ◦
1e-6の頻度を持つトークン集合をその言語の語彙と定義 ◦ 複数言語に共通するトークンを除外 • 言語モデリングで予測されたトークンが評価言語の語彙かどうかを判定 ◦ 言語Aの系列に対して言語モデリングを実施 ◦ 別の言語Bの部分空間に射影した際にターゲット言語の割合を調べる ▪ 平均のシフトなども考慮 11
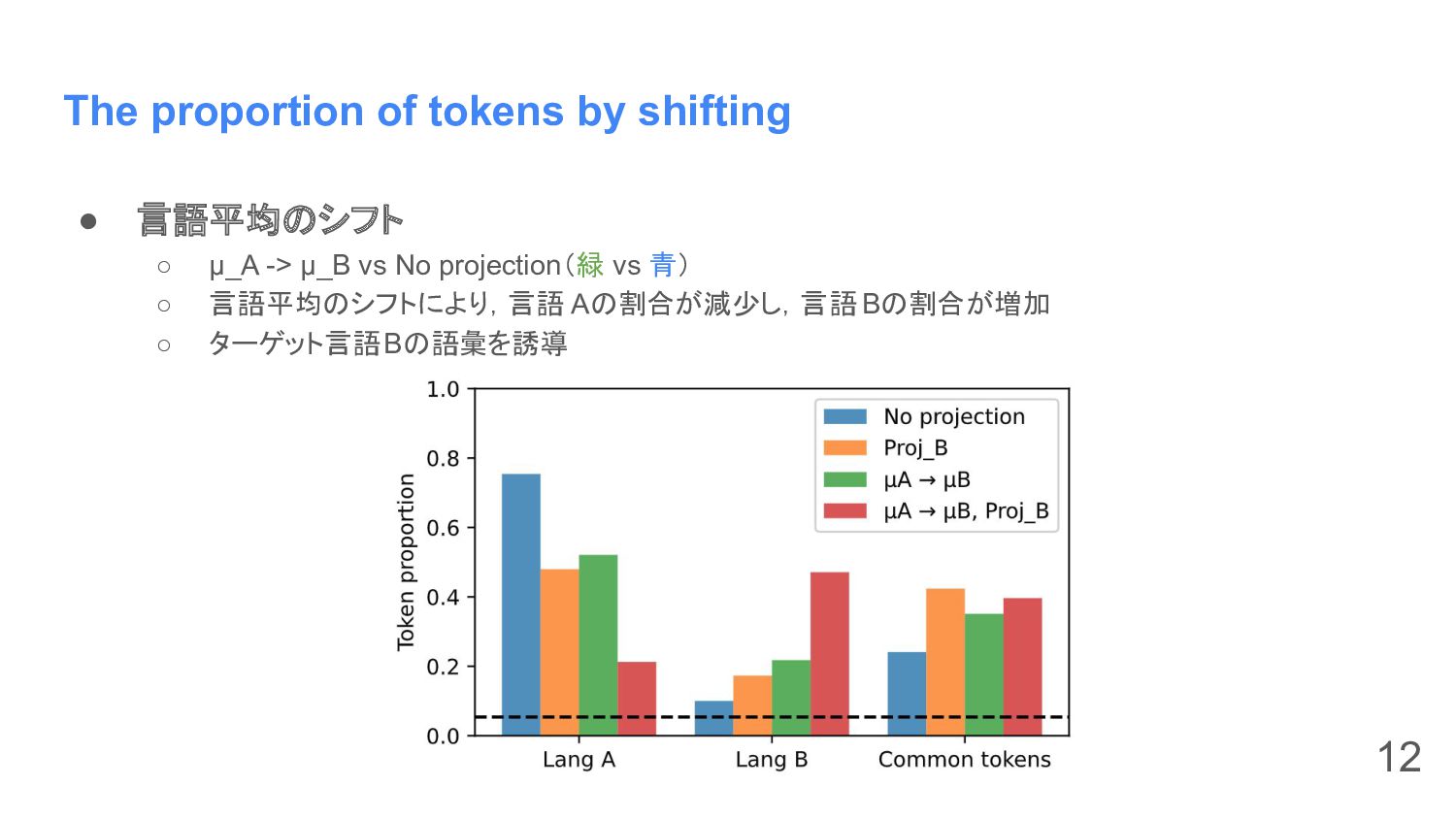
The proportion of tokens by shifting • 言語平均のシフト ◦ μ_A
-> μ_B vs No projection(緑 vs 青) ◦ 言語平均のシフトにより,言語 Aの割合が減少し,言語 Bの割合が増加 ◦ ターゲット言語Bの語彙を誘導 12
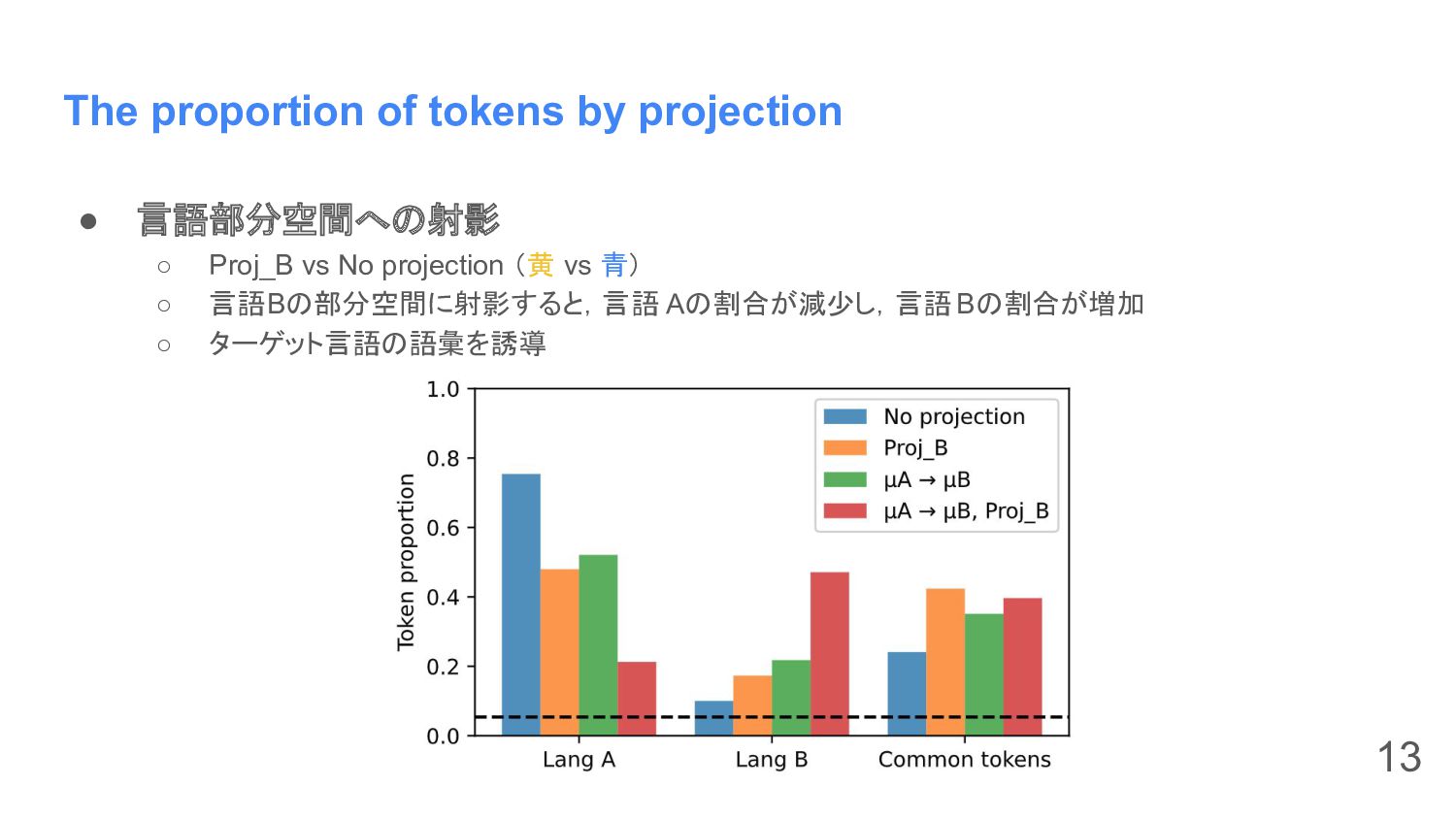
The proportion of tokens by projection • 言語部分空間への射影 ◦ Proj_B
vs No projection (黄 vs 青) ◦ 言語Bの部分空間に射影すると,言語 Aの割合が減少し,言語 Bの割合が増加 ◦ ターゲット言語の語彙を誘導 13
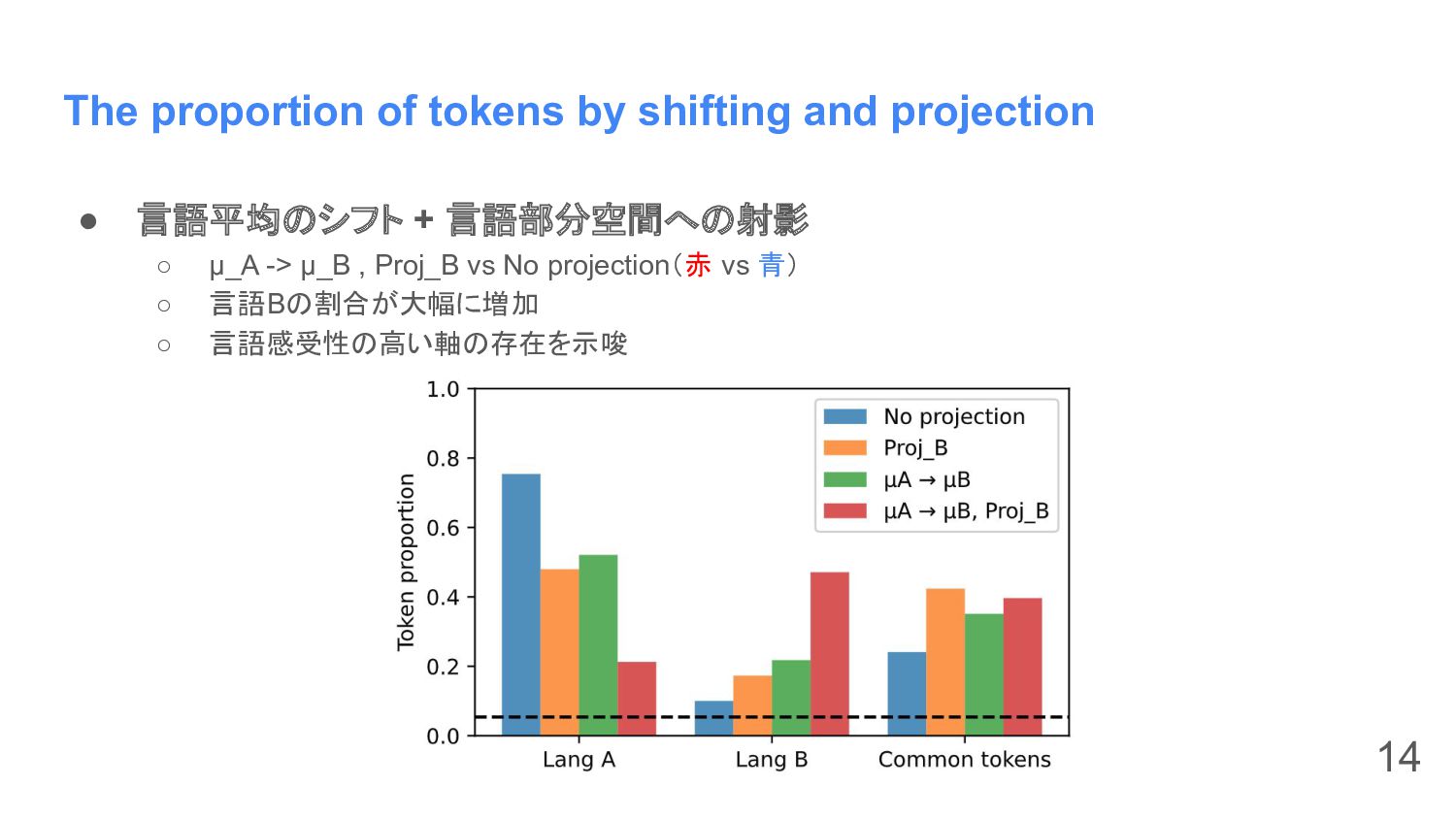
The proportion of tokens by shifting and projection • 言語平均のシフト
+ 言語部分空間への射影 ◦ μ_A -> μ_B , Proj_B vs No projection(赤 vs 青) ◦ 言語Bの割合が大幅に増加 ◦ 言語感受性の高い軸の存在を示唆 14
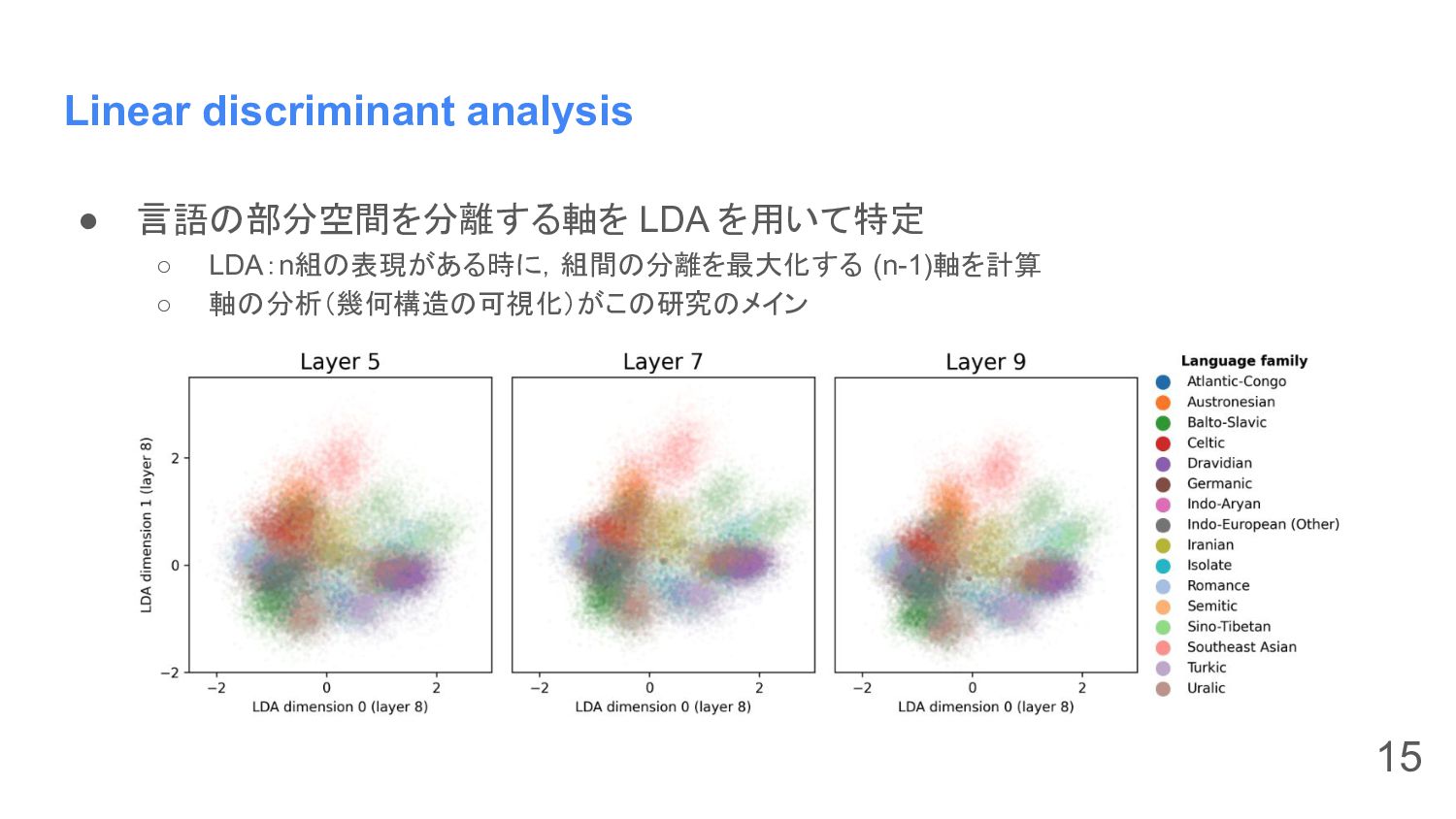
Linear discriminant analysis • 言語の部分空間を分離する軸を LDA を用いて特定 ◦ LDA:n組の表現がある時に,組間の分離を最大化する (n-1)軸を計算
◦ 軸の分析(幾何構造の可視化)がこの研究のメイン 15
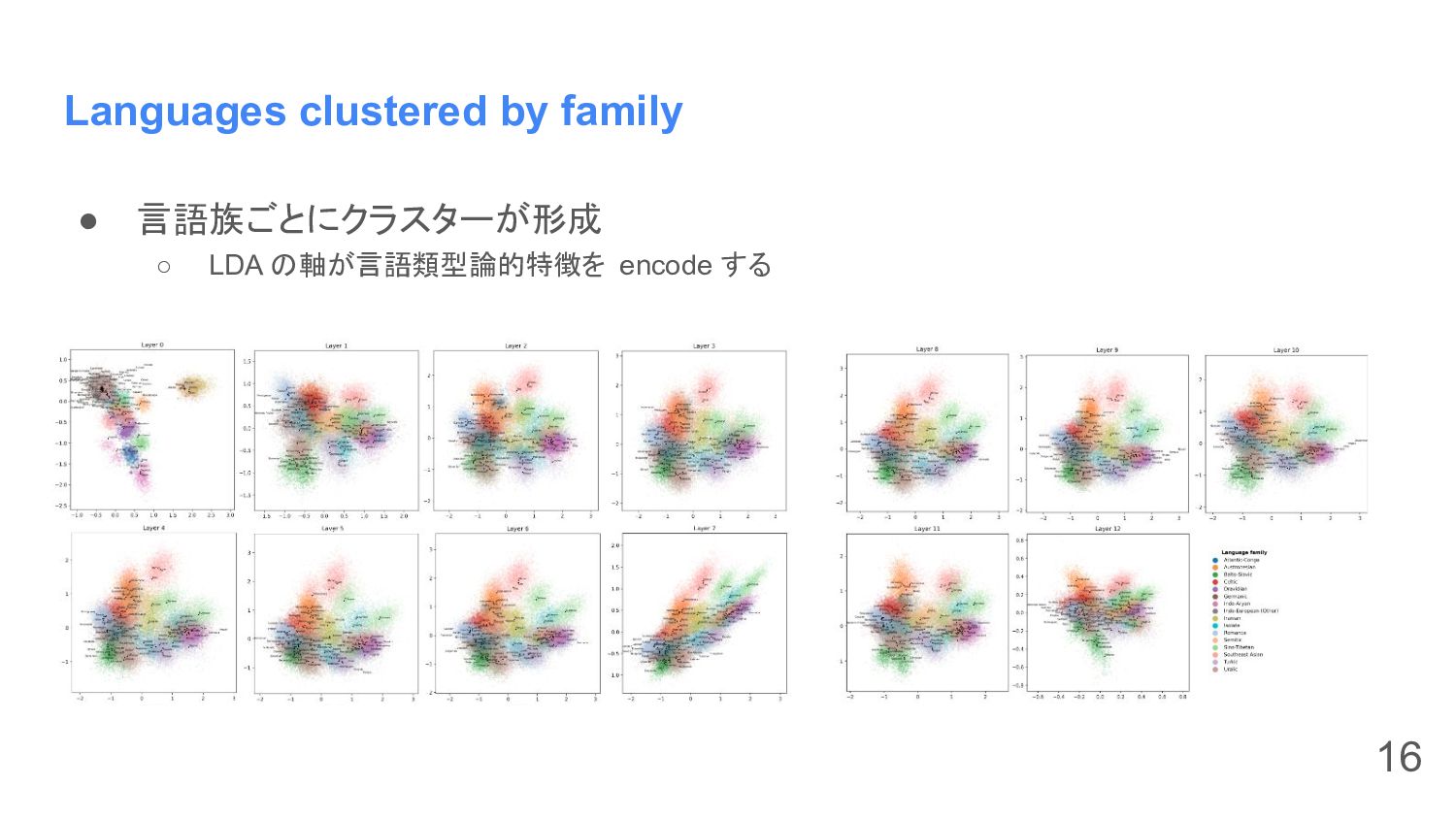
Languages clustered by family • 言語族ごとにクラスターが形成 ◦ LDA の軸が言語類型論的特徴を encode
する 16
Languages clustered by family • 言語感受性の高い軸は中間層で安定 ◦ 5-9層はかなり類似した射影 ◦ 意味情報を処理していると考えられる
17
Language-neutral axes • 言語中立性 (Language-neutral) ◦ 言語Aと言語Bが似たような分布を持つ ▪ 入力言語で変化しない情報 •
多言語モデルでは言語に敏感な軸で言語固有の情報を encode する • 言語中立的な軸はどのような情報を encode するか? • LDA で分析 ◦ トークン位置 ◦ 品詞 18
Position axes were language-neutral • XLM-R は Transformer 層の前に絶対位置埋め込みを行う ◦
トークンの位置は言語中立的に encode されるはず • 言語が異なっても位置によって形状が決まる ◦ 言語の違いが影響を及ぼさない ◦ 言語中立的な情報 19
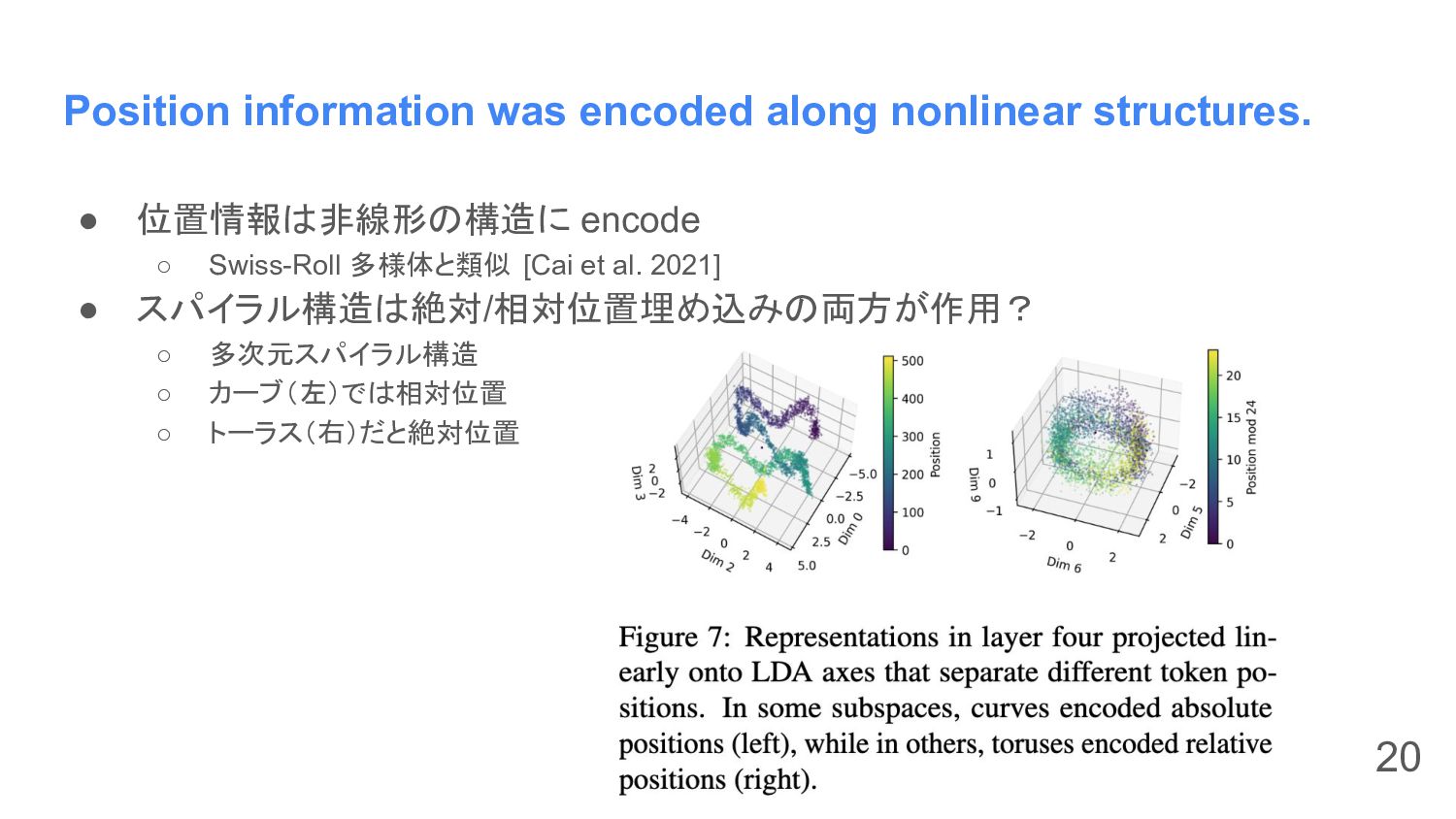
Position information was encoded along nonlinear structures. • 位置情報は非線形の構造に encode
◦ Swiss-Roll 多様体と類似 [Cai et al. 2021] • スパイラル構造は絶対/相対位置埋め込みの両方が作用? ◦ 多次元スパイラル構造 ◦ カーブ(左)では相対位置 ◦ トーラス(右)だと絶対位置 20
Position representations were stable across layers • 位置情報は層を超えて安定 ◦ 他の層(2層-11層)でも似たような曲線が獲得可能
◦ 各層で言語中立的な軸に沿った表現を変換することが示唆 21
Part-of-speech • token の品詞を encode する軸を調査 ◦ モデルに直接入力されていない点に注意 ◦ モデルが教師なしで名詞や動詞などの特徴を捉える必要
• Universal Dependency [Nivre et al., 2020] を使用 ◦ それぞれの品詞タグに対し 8k 個を一様にサンプリング • LDA による分析 ◦ n 次元に対する投影は n+1 個のPOSタグが必要 ◦ POS タグの表現を分離する n 個の軸を用意 22
POS axes were language-neutral and stable across layers • 言語とは無関係に品詞ごとにプロットされている
◦ 品詞ごとにクラスタリングに近いような表現 ◦ 構文情報は言語間で共有された線形部分空間で整列 [Chi et al. 2020] 23
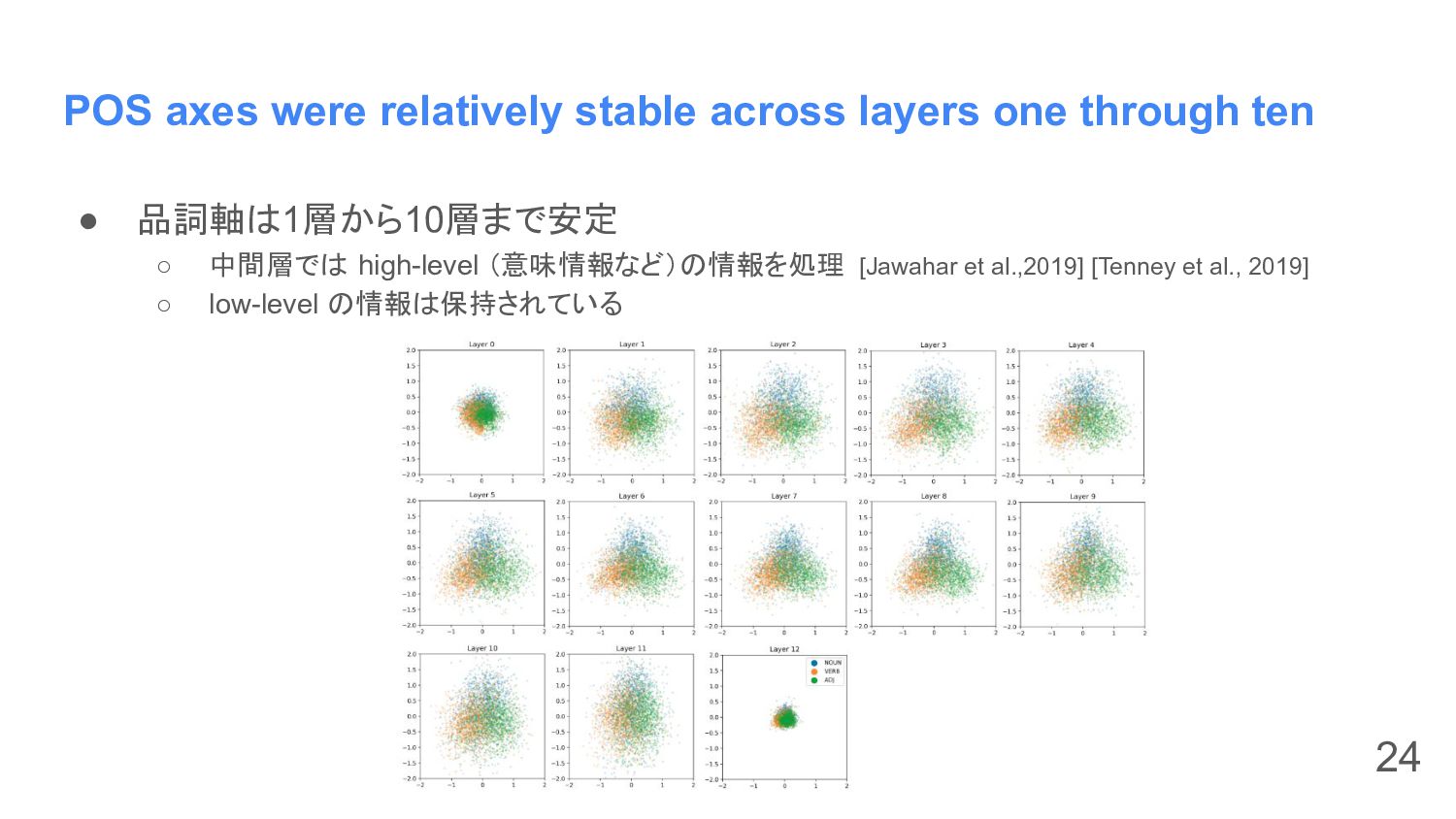
POS axes were relatively stable across layers one through ten
• 品詞軸は1層から10層まで安定 ◦ 中間層では high-level (意味情報など)の情報を処理 [Jawahar et al.,2019] [Tenney et al., 2019] ◦ low-level の情報は保持されている 24
Multilingual structure (1/3) • 言語部分空間は言語感受性の高い軸があれば重ならない ◦ 要は言語間で分割できる軸が言語感受性の軸であるため,分離可能ということ • future work
◦ language-sensitivity を定量的に定義できるか? 25
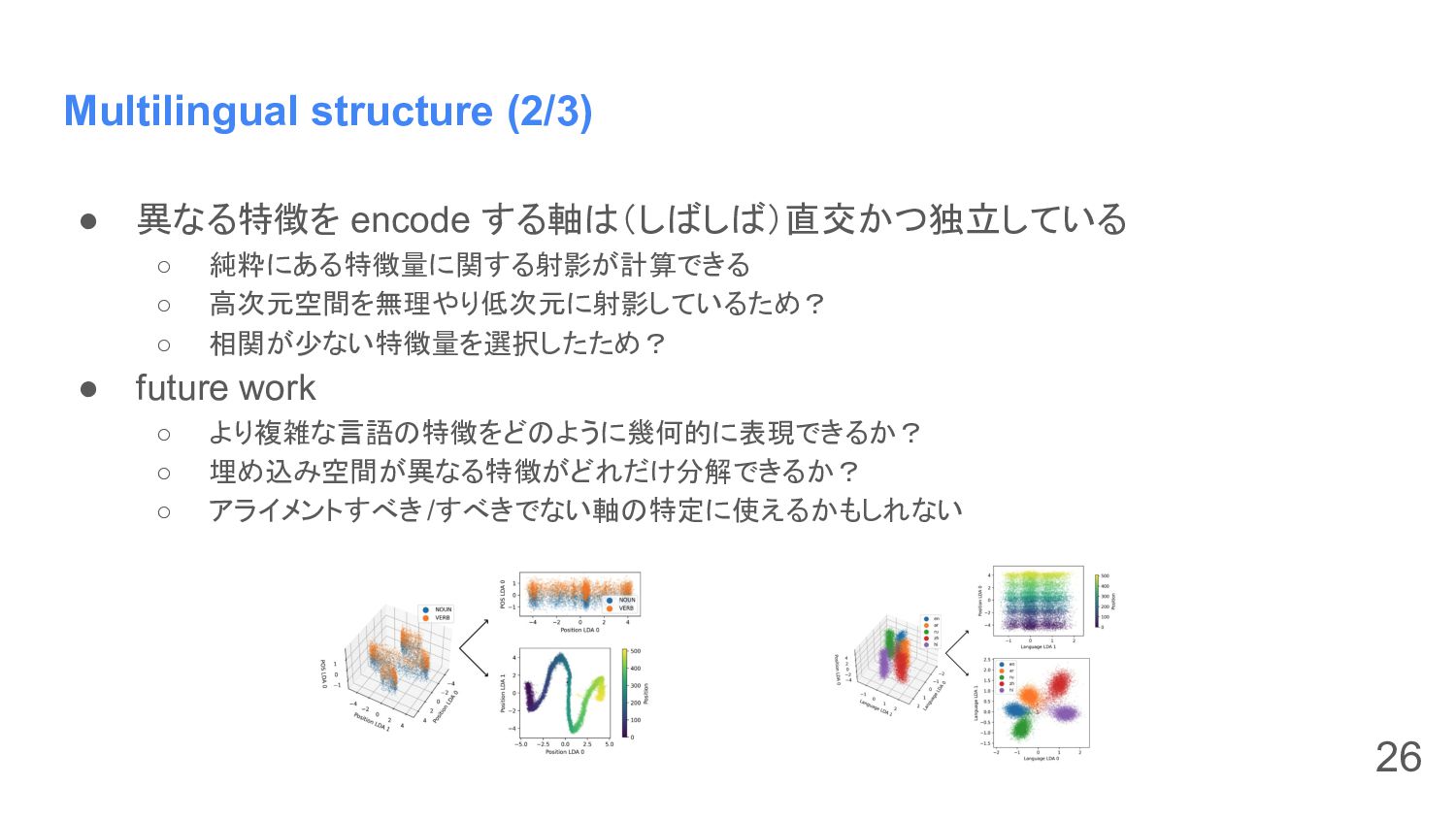
Multilingual structure (2/3) • 異なる特徴を encode する軸は(しばしば)直交かつ独立している ◦ 純粋にある特徴量に関する射影が計算できる ◦
高次元空間を無理やり低次元に射影しているため? ◦ 相関が少ない特徴量を選択したため? • future work ◦ より複雑な言語の特徴をどのように幾何的に表現できるか? ◦ 埋め込み空間が異なる特徴がどれだけ分解できるか? ◦ アライメントすべき/すべきでない軸の特定に使えるかもしれない 26
Multilingual structure (3/3) • 多言語モデルの中間層では,言語族,トークン位置,POSは安定してencode ◦ 特定の情報は保持されたまま変化されることが示唆 • future work
◦ 特定の情報が層を超えてどのように保持されるのか? 27
conclusion • 多言語モデル (XLM-R) において言語部分空間を分析 • 2つの軸の存在を示唆 ◦ 言語感受性の高い軸:語彙,言語族 ◦
言語中立性の高い軸: token 位置,品詞 • 埋め込み空間の直交する軸に射影することで特徴を encode する ◦ 下流タスクや多言語学習で効率よく encode できることが示唆 28
limitation • モデルとデータセット内の言語 ◦ 言語的多様性が制限される • データセットの品質 ◦ 各言語のデータのサイズ,品質が異なる ◦
サイズが小さく,品質が良くないものでは傾向が異なる可能性 • XLM-R のみの分析 ◦ モデル,ハイパラなど変えると変化する可能性 ◦ GPTシリーズの中身の埋め込みの分析も気になるところ 29
補足:Language-sensitive vs Language-neutral • 言語感受性 (Language-sensitive) ◦ ある表現が部分空間に投影される時,入力言語の identityと高い相互情報量を持つ ◦
言語Aと言語Bが異なる分布を持つ ▪ 入力言語で変化する情報 • 言語中立性 (Language-neutral) ◦ ある表現が部分空間に投影される時,入力言語の identityと低い相互情報量を持つ ◦ 言語Aと言語Bが似たような分布を持つ ▪ 入力言語で変化しない情報 30
補足:Language-sensitive vs. Language-neutral axes • 各言語における平均と分散をみることで判別可能 • 言語中立性の高い軸 ◦ 各言語部分空間の平均が等しく,分散が小さい軸
◦ 各言語部分空間の平均が等しく,分散が大きい軸 • 言語感受性の高い軸 ◦ 言語Aで分散が大きく,言語 Bで分散が小さい軸 ◦ 平均が等しくなく,分散が同程度に高い軸 ◦ 平均が等しくなく,分散が同程度に低い軸 31
{kind=link}
{kind=link}
{kind=link}
![Language subspace • モデル:XLM-R [Conneau et al., 2020a] ◦ RoBERTa](https://files.speakerdeck.com/presentations/a460ee9e209946608683c0b36d60034a/slide_3.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}