GraphX is a new graph processing system on Spark. GraphX enables algorithms to blend graph and tabular views of graph data and can easily express graph parallel abstractions like GraphLab and Pregel. GraphX borrows many of the optimizations from the GraphLab platform to enable efficient distributed graph computation. This is work-in-progress.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
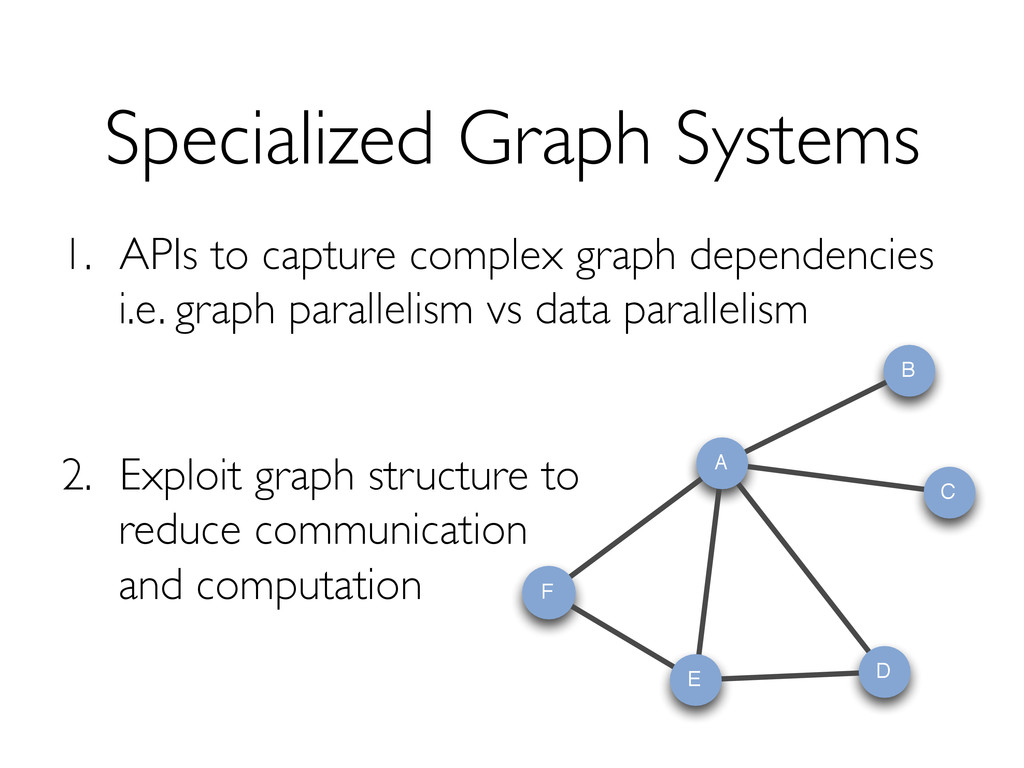{kind=link}
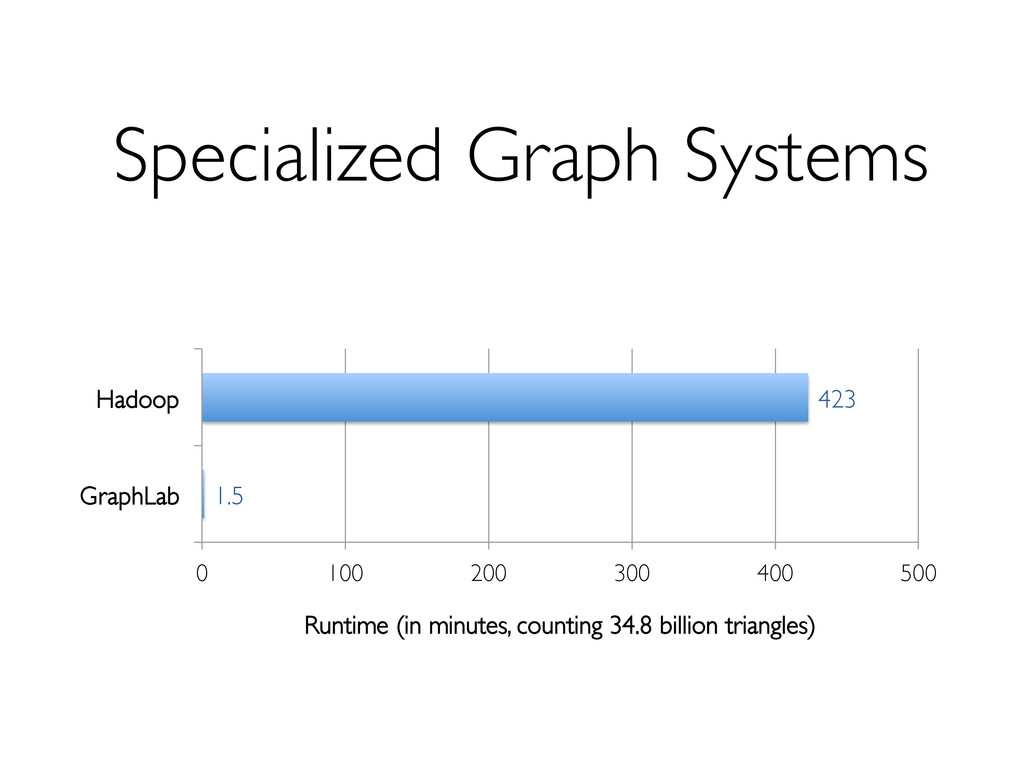{kind=link}
{kind=link}
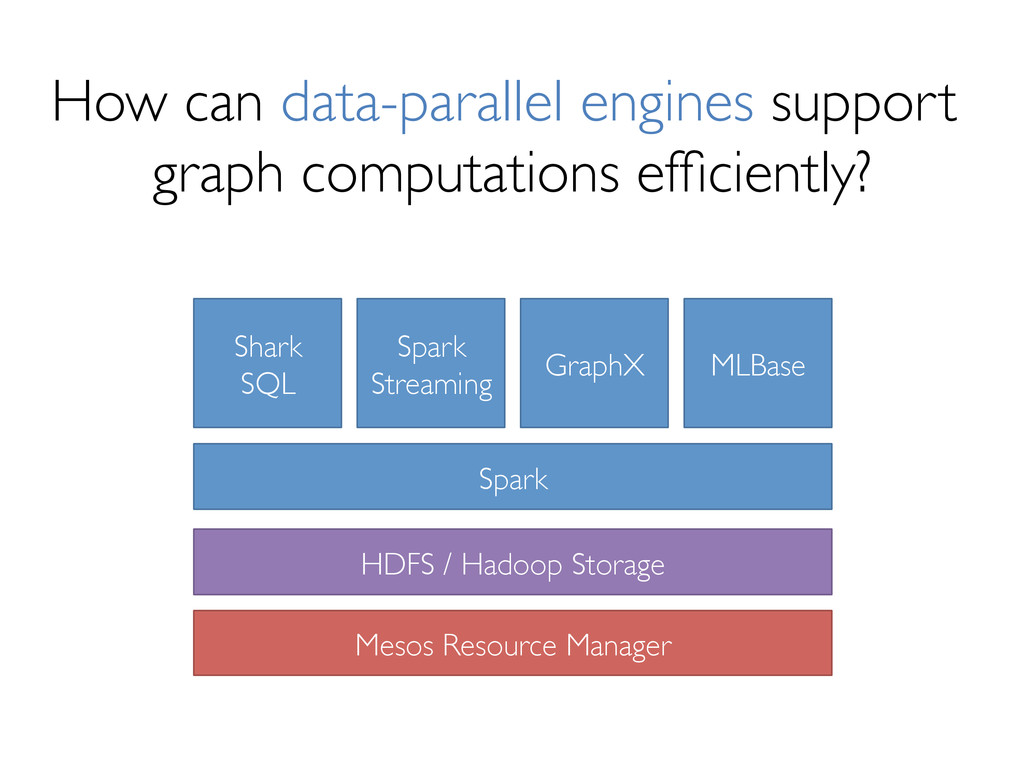{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Resilient Distributed Graphs def vertices: RDD[Vertex] def edges: RDD[Edge] def](https://files.speakerdeck.com/presentations/54456000afd70130683e4a6d87cb55da/slide_11.jpg){kind=link}
{kind=link}
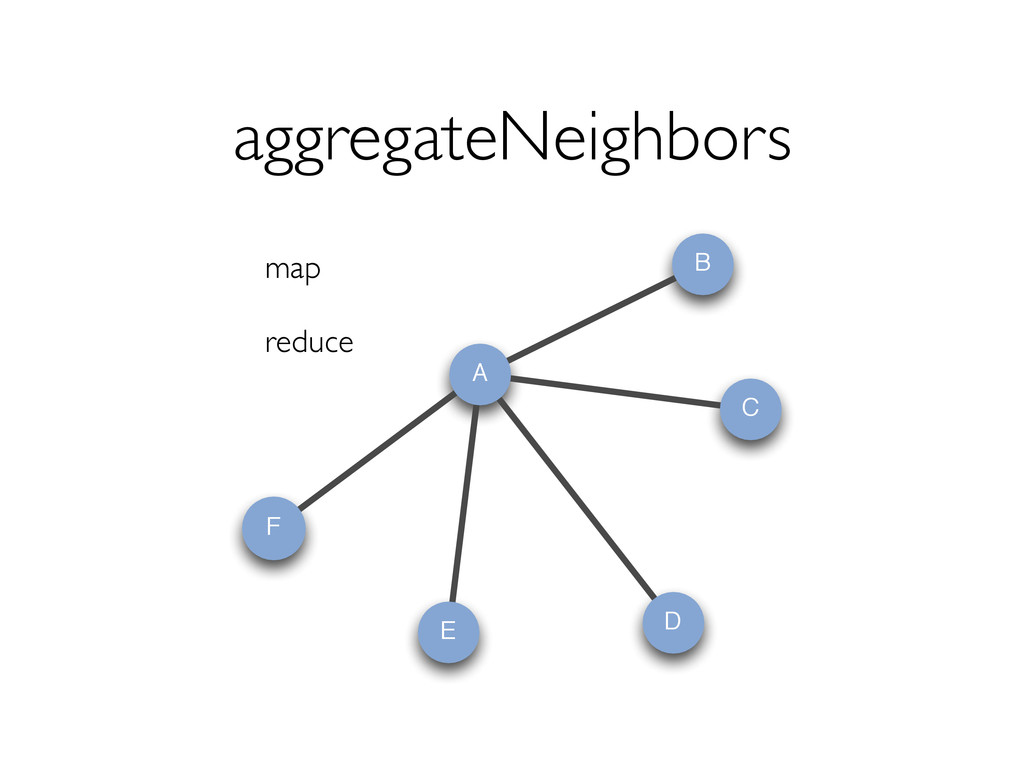{kind=link}
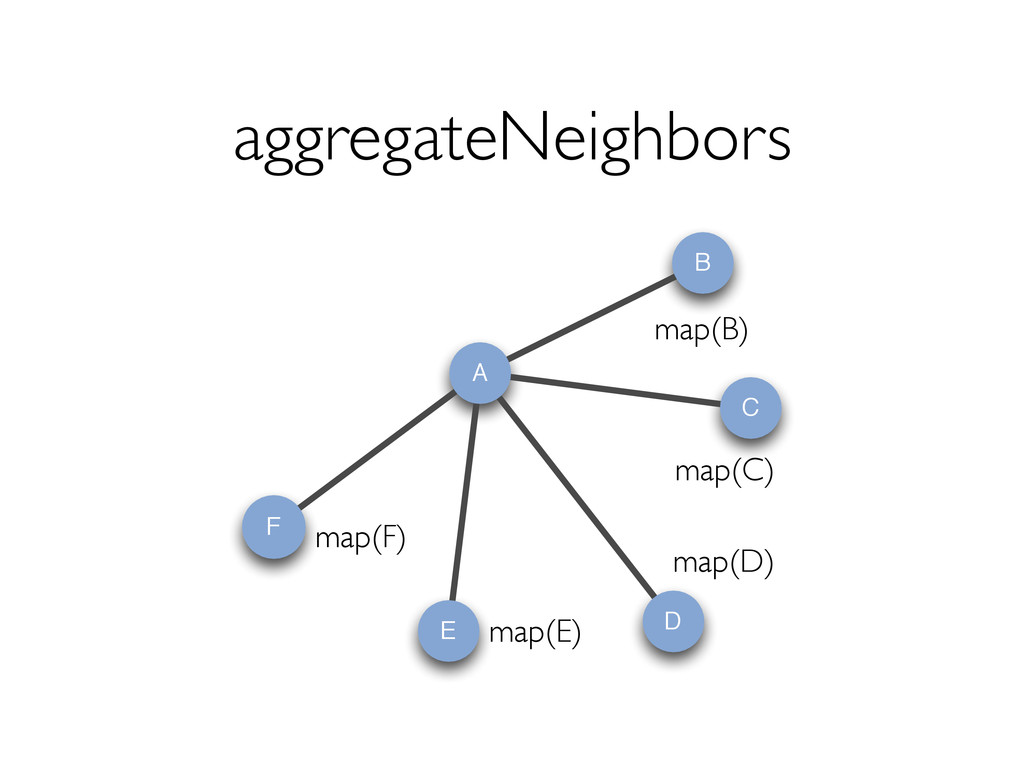{kind=link}
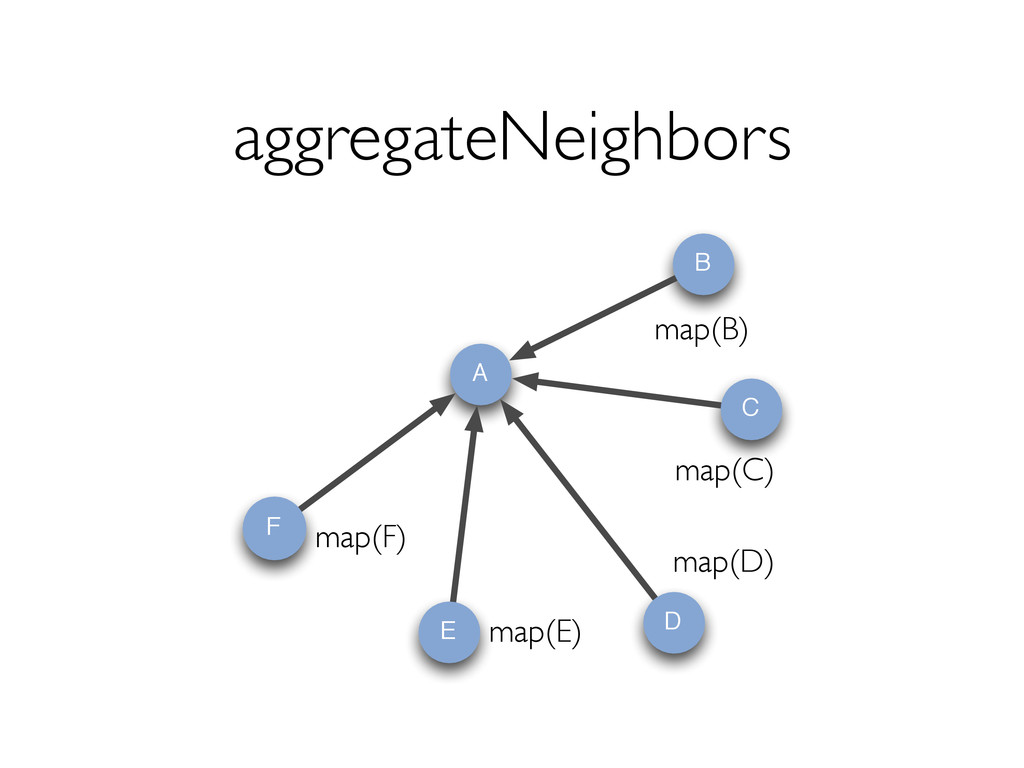{kind=link}
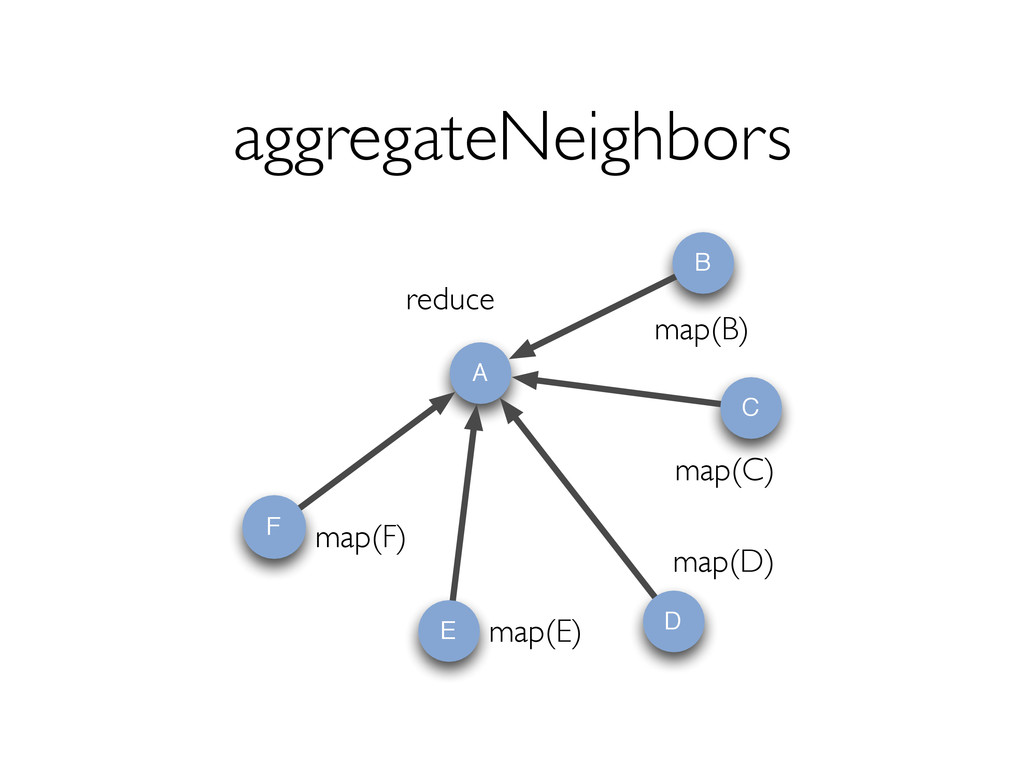{kind=link}
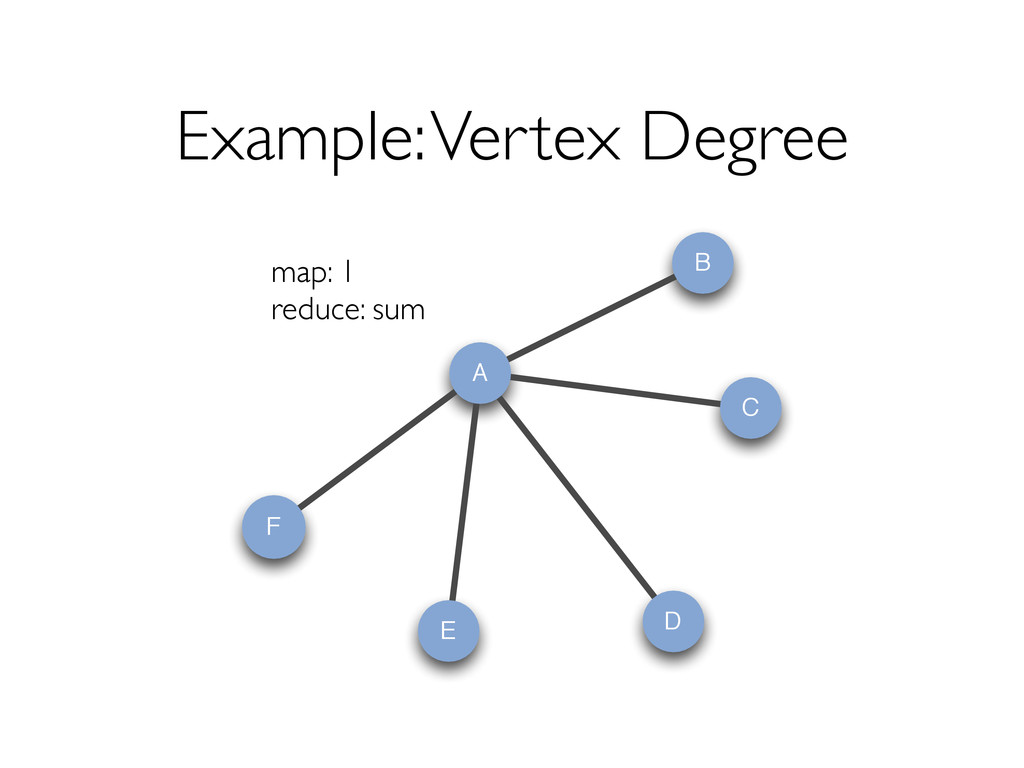{kind=link}
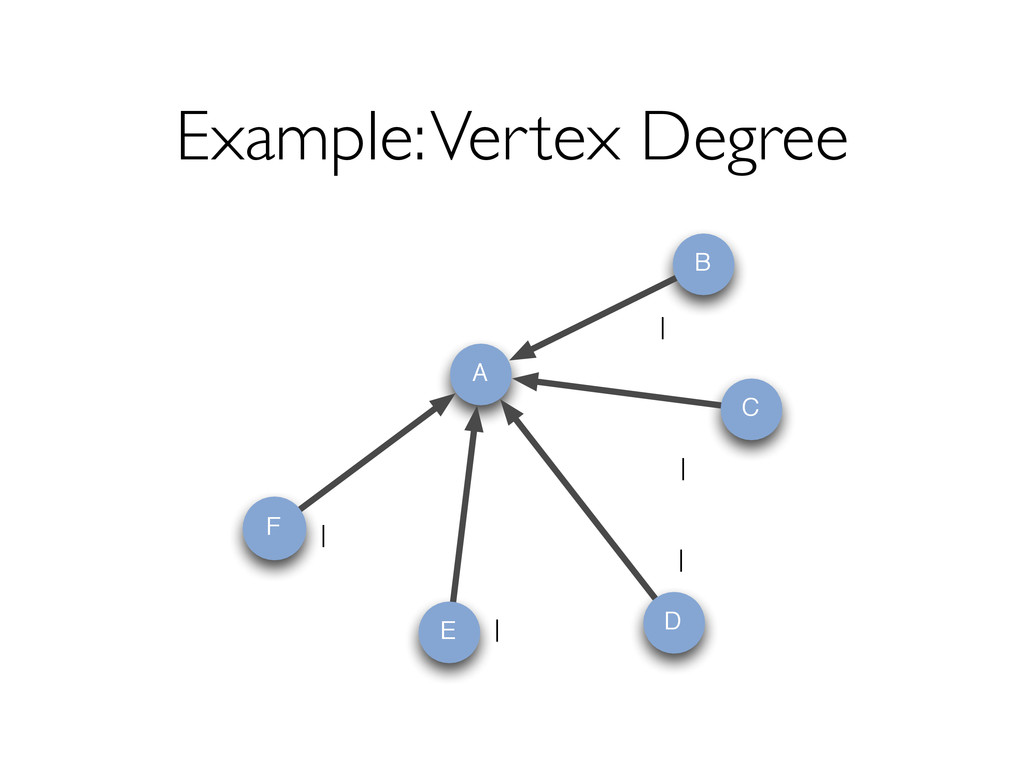{kind=link}
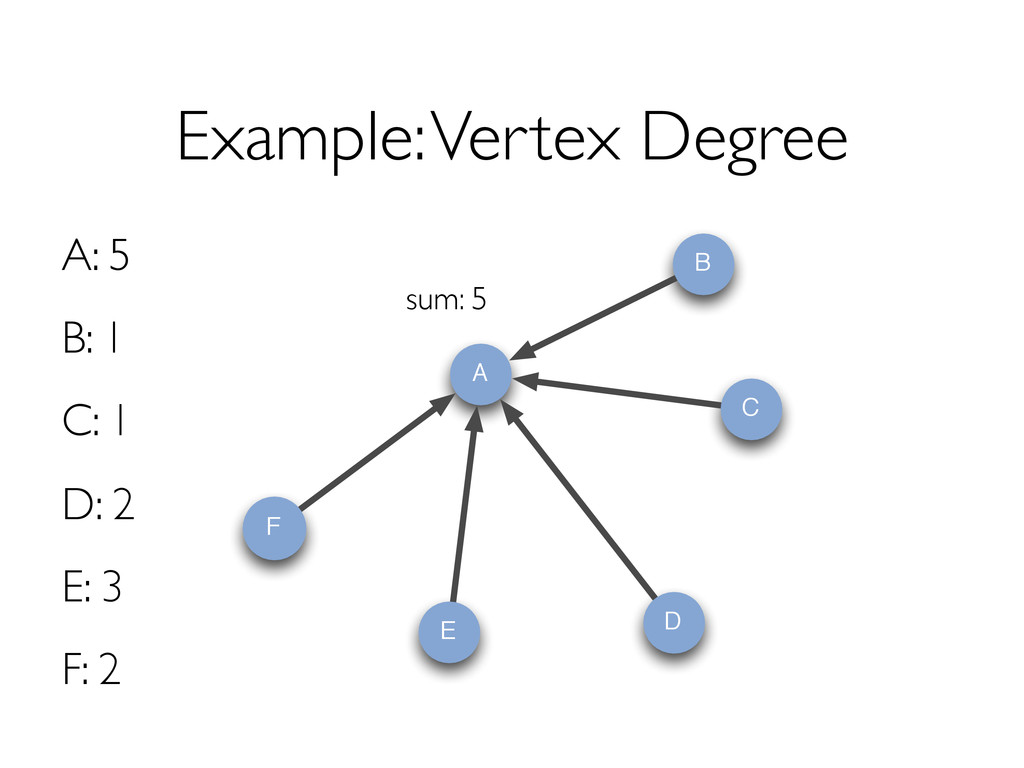{kind=link}
{kind=link}
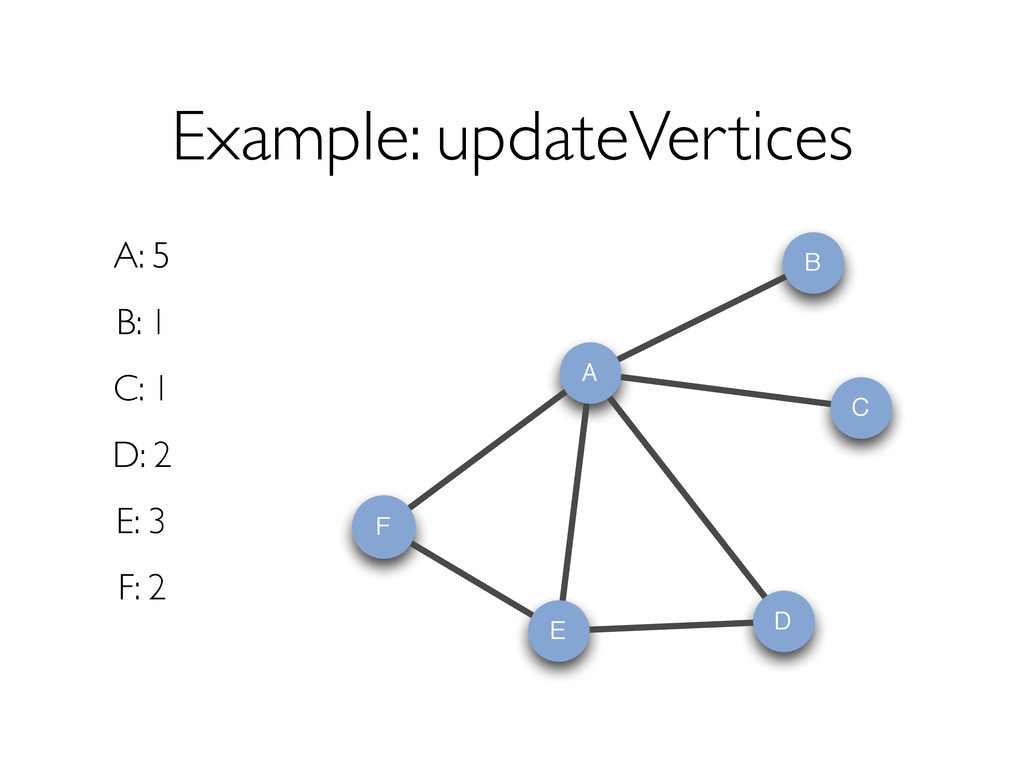{kind=link}
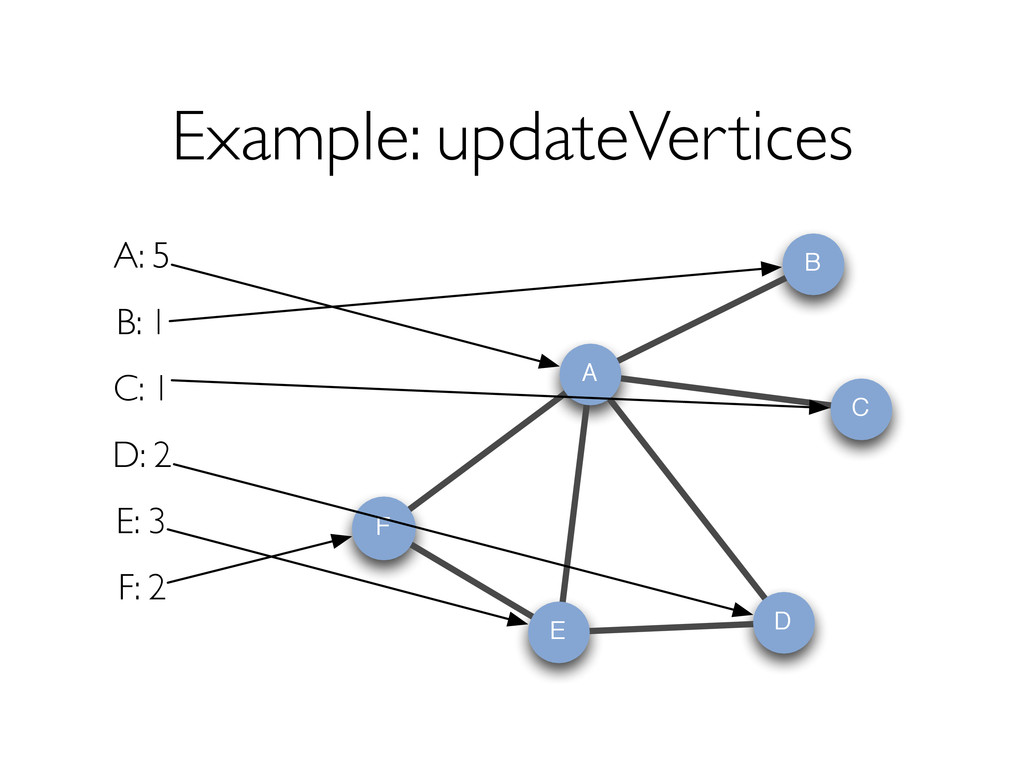{kind=link}
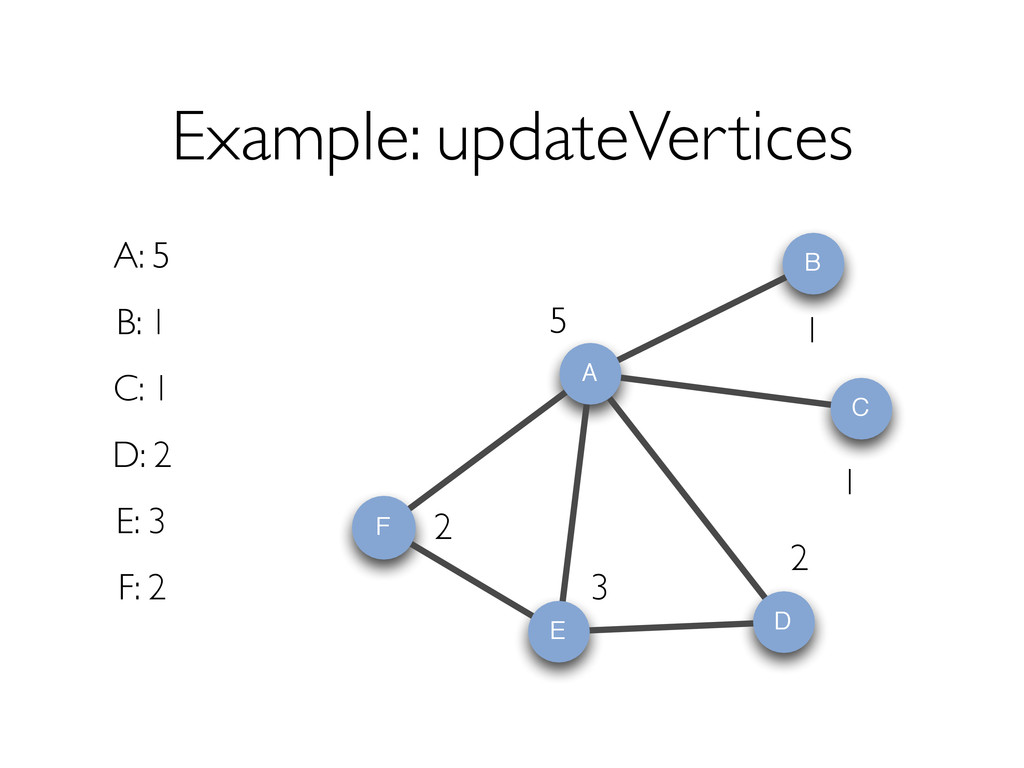{kind=link}
{kind=link}
{kind=link}
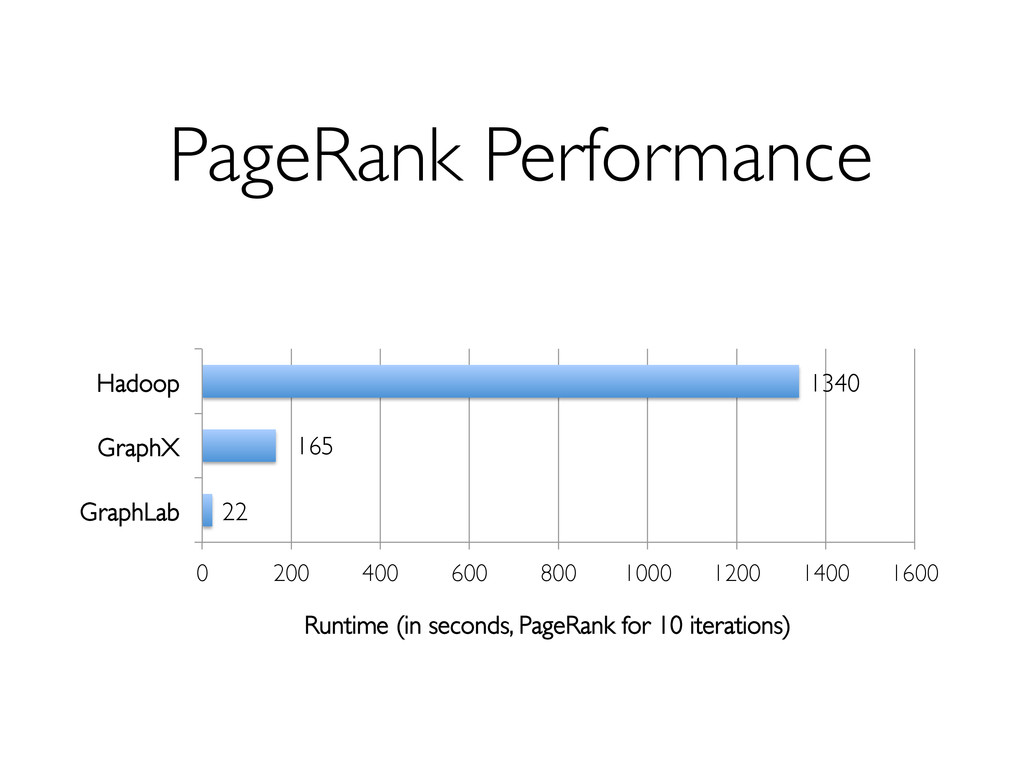{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}