Drives open source Spark development, and offers a cloud service (Databricks Cloud) Largest organization contributing to Spark > Over 1000 patches in the past year
Usability, stability, and performance MLlib/SQL/Streaming: Expanded feature set and performance Around ~40% of mailing list traffic is about these libraries.
tools Native JSON support Native Parquet support and optimizations 1.2 Support for Hive 0.13 External data sources API (Avro, Cassandra, etc). Native ORC support
extraction utilities (word2vec, tf-idf) Statistics library 1.2 Pipeline-based interface to all algorithms Many new algorithms including Random Forests Stable API for GraphX
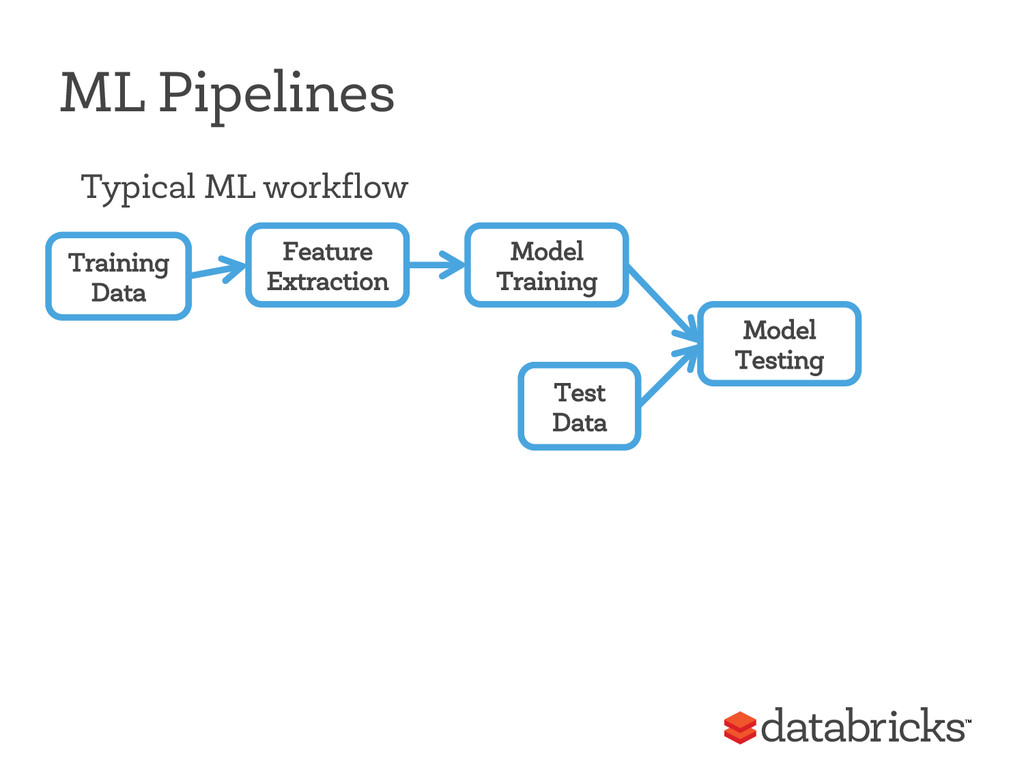
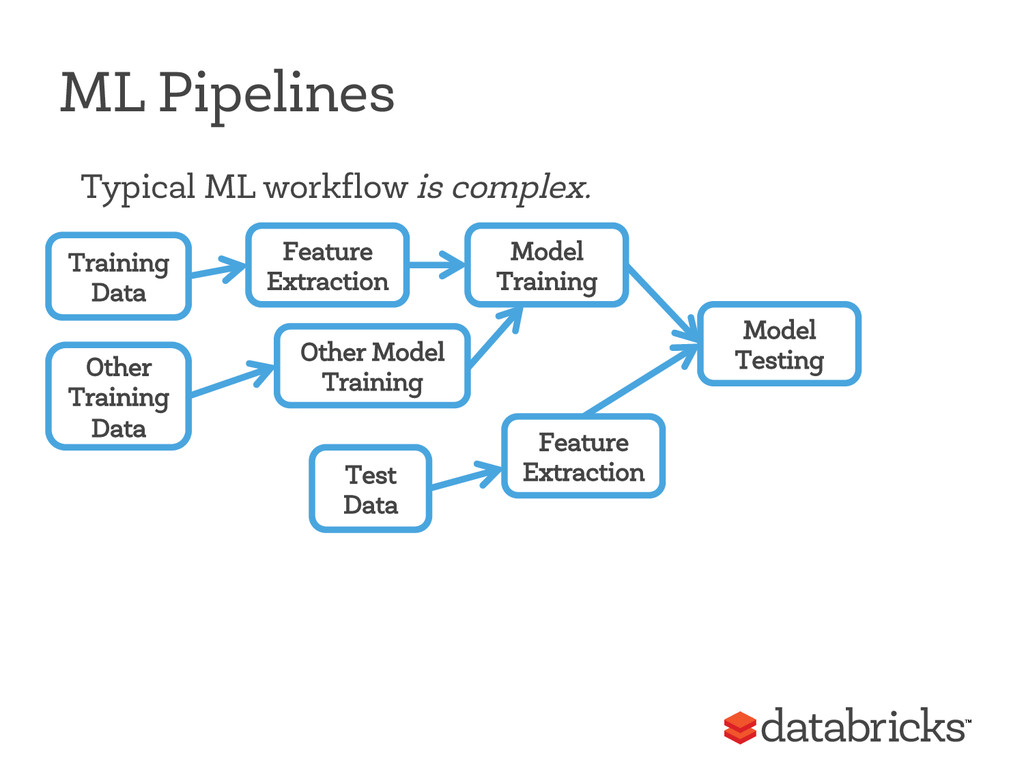
• Handle many data types (features) • Keep metadata about features • Select subsets of features for different parts of pipeline • Join groups of features ML Dataset = SchemaRDD Under development
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
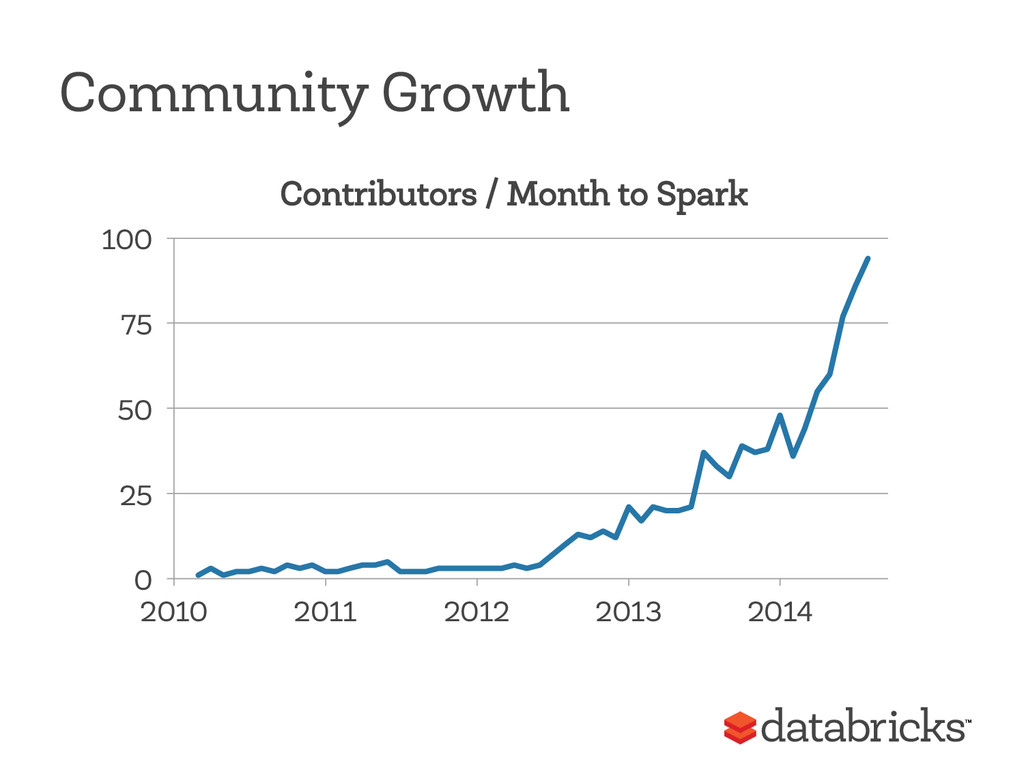{kind=link}
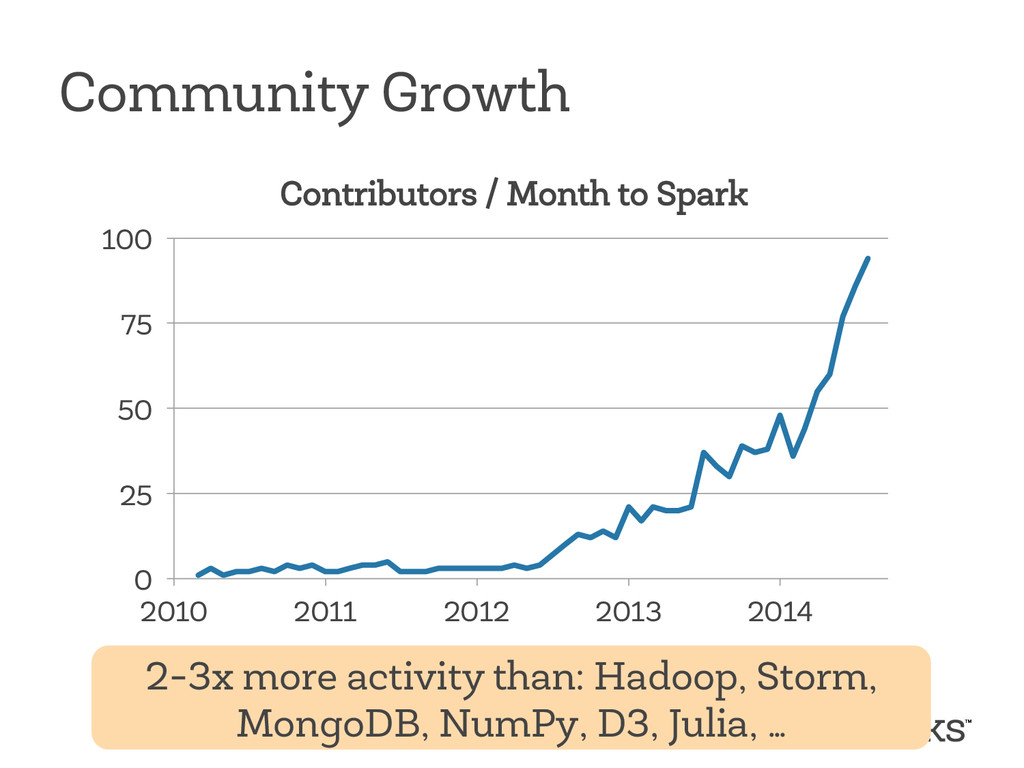{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
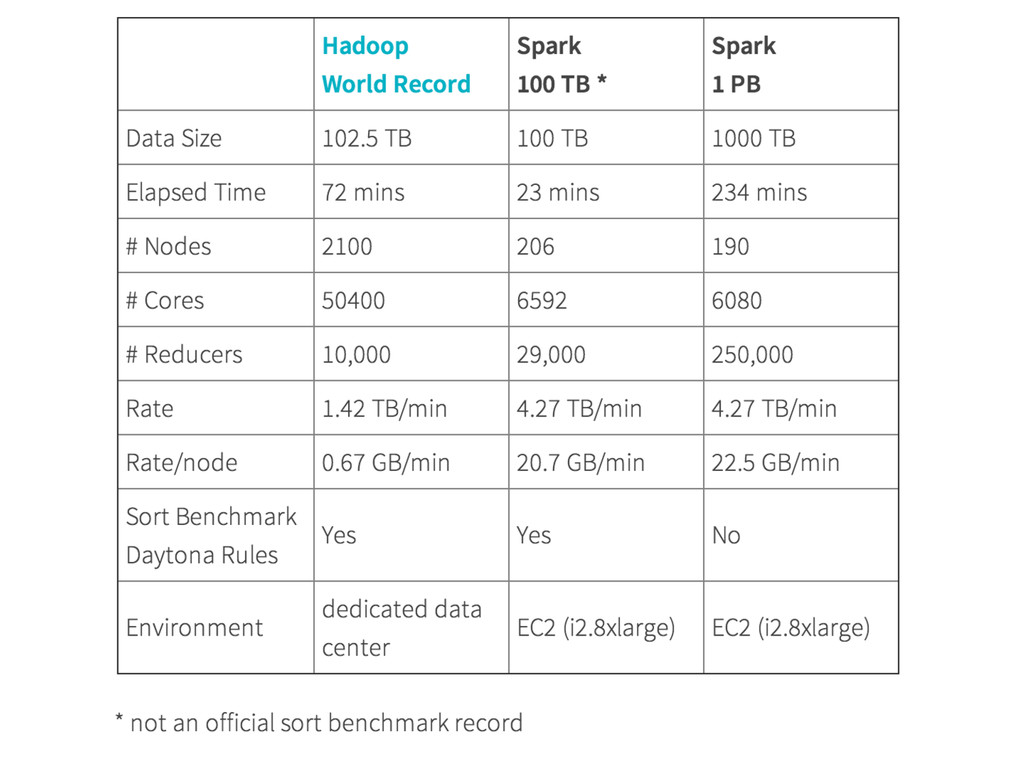{kind=link}
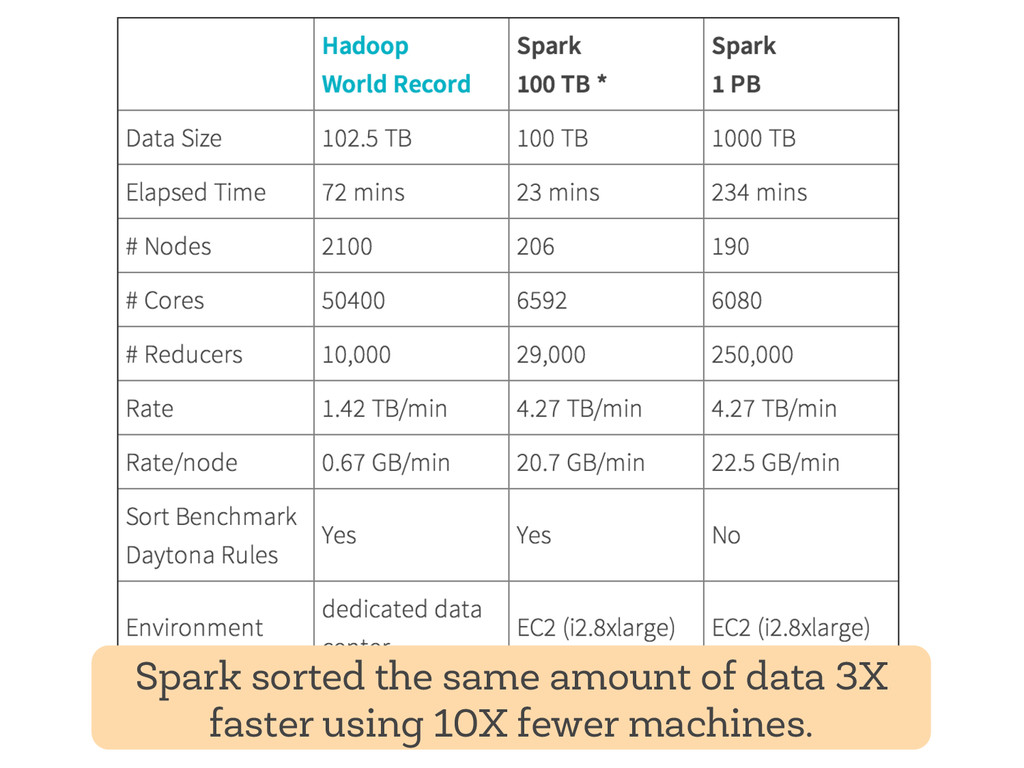{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}