interoperable with Apache Hadoop Improves efficiency through: » In-‐memory computing primitives » General computation graphs Improves usability through: » Rich APIs in Scala, Java, Python » Interactive shell Up to 100× faster (2-‐10× on disk) Often 5× less code
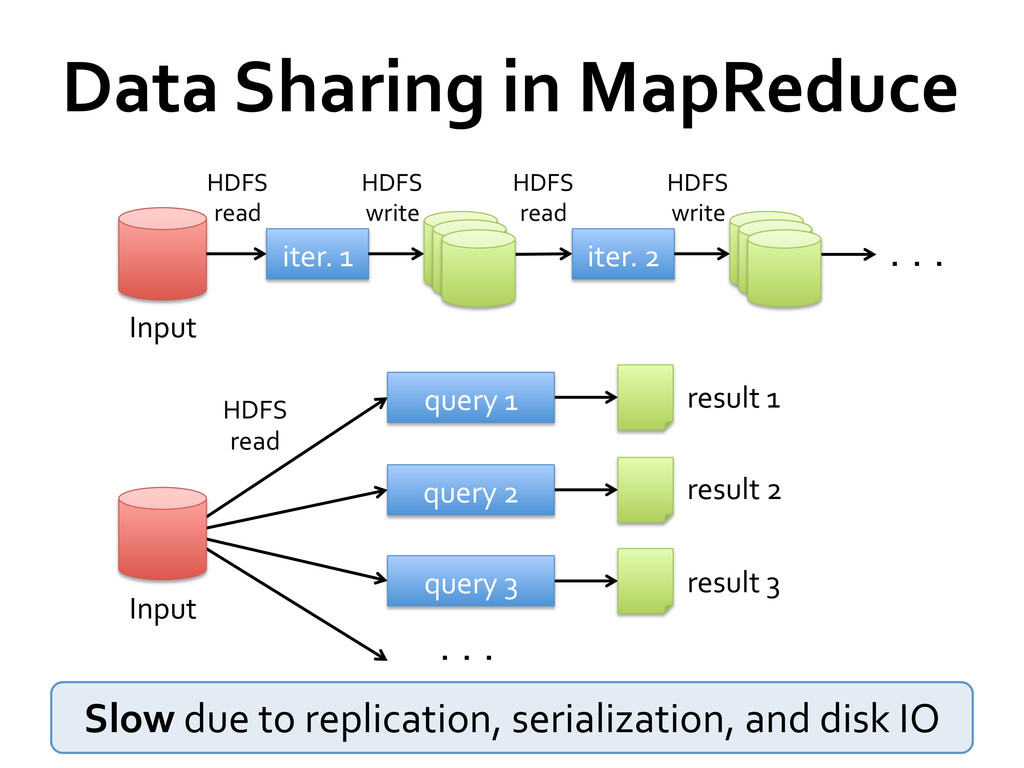
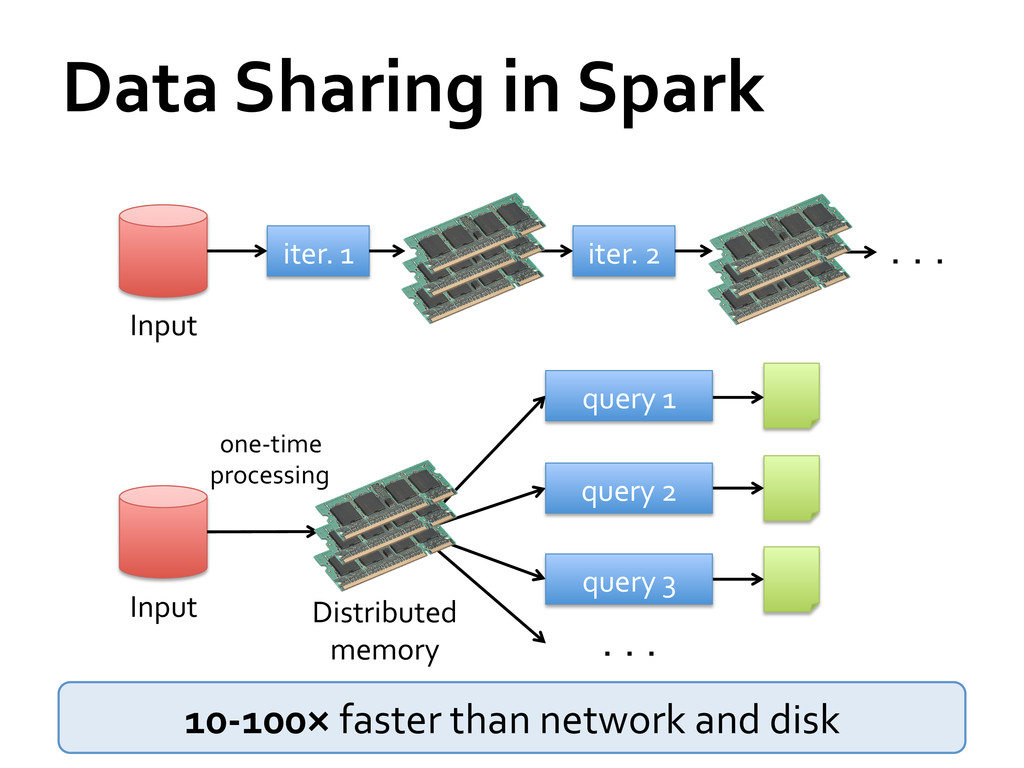
data analysis But as soon as it got popular, users wanted more: » More complex, multi-‐pass analytics (e.g. ML, graph) » More interactive ad-‐hoc queries » More real-‐time stream processing All 3 need faster data sharing across parallel jobs
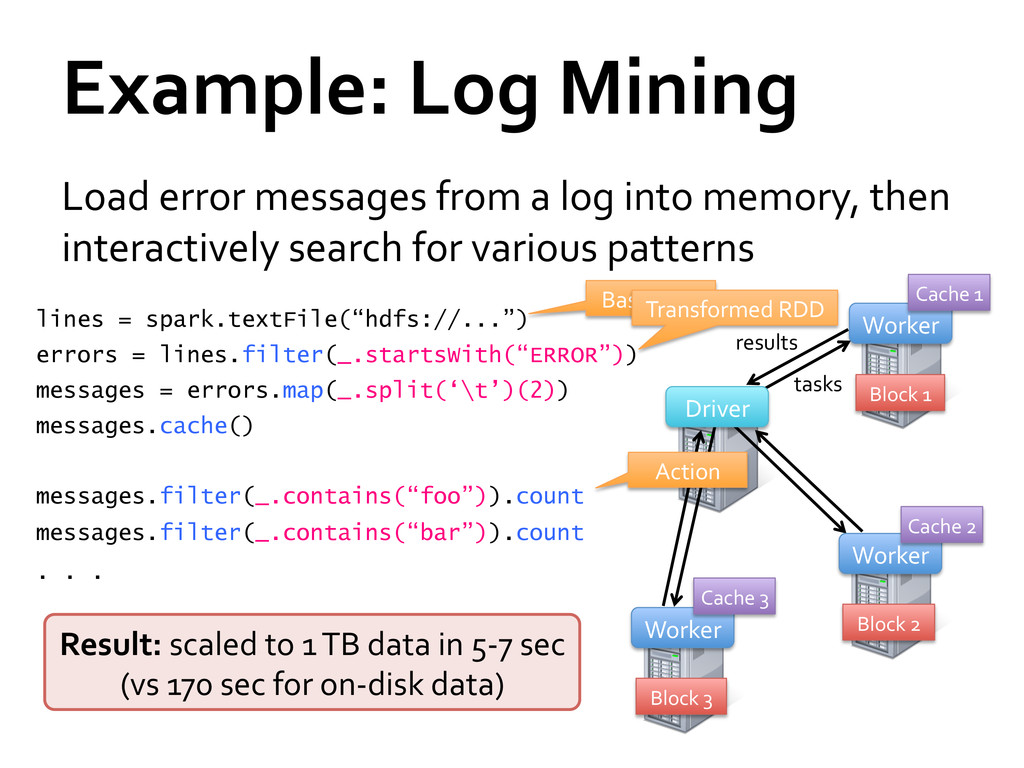
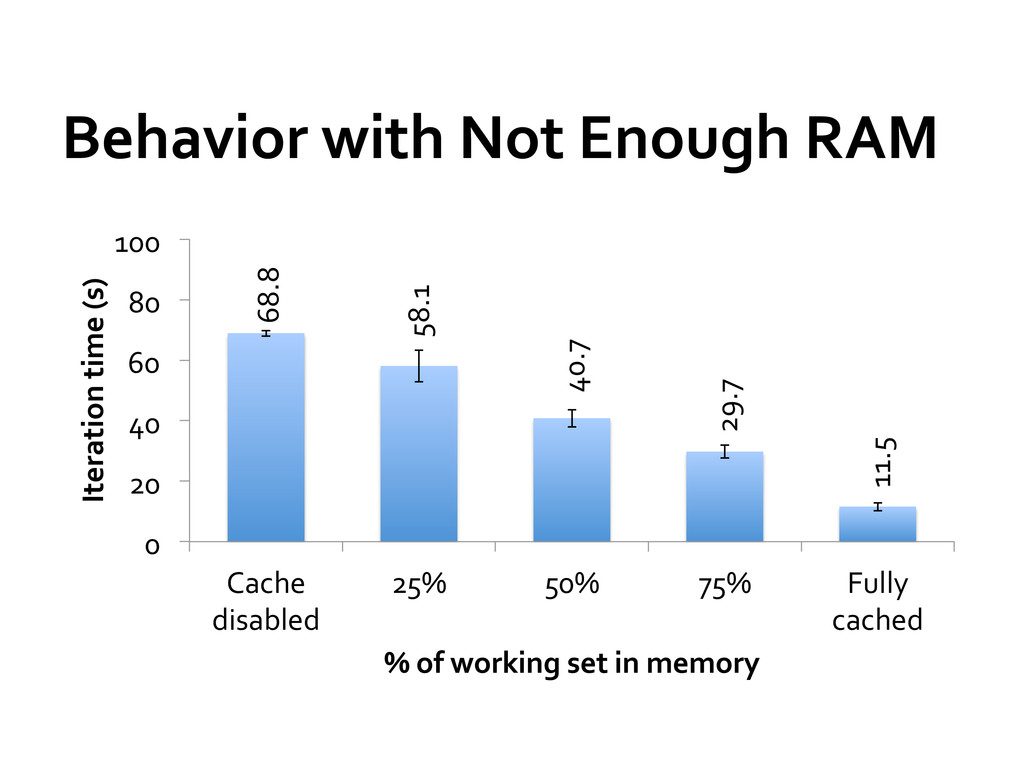
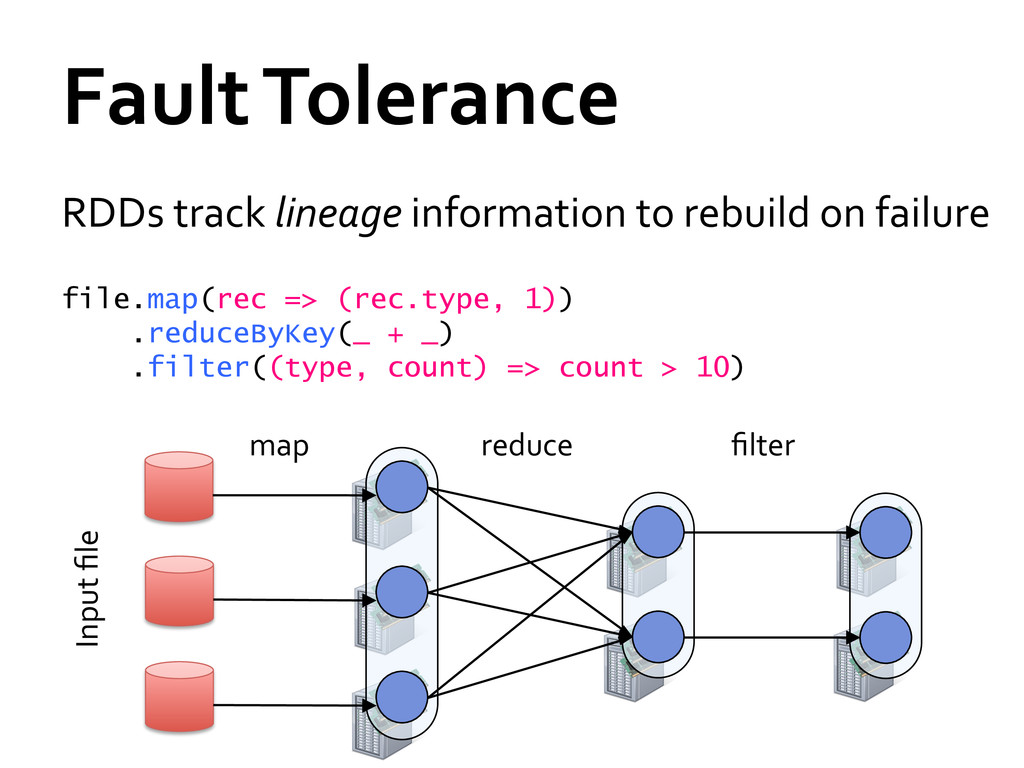
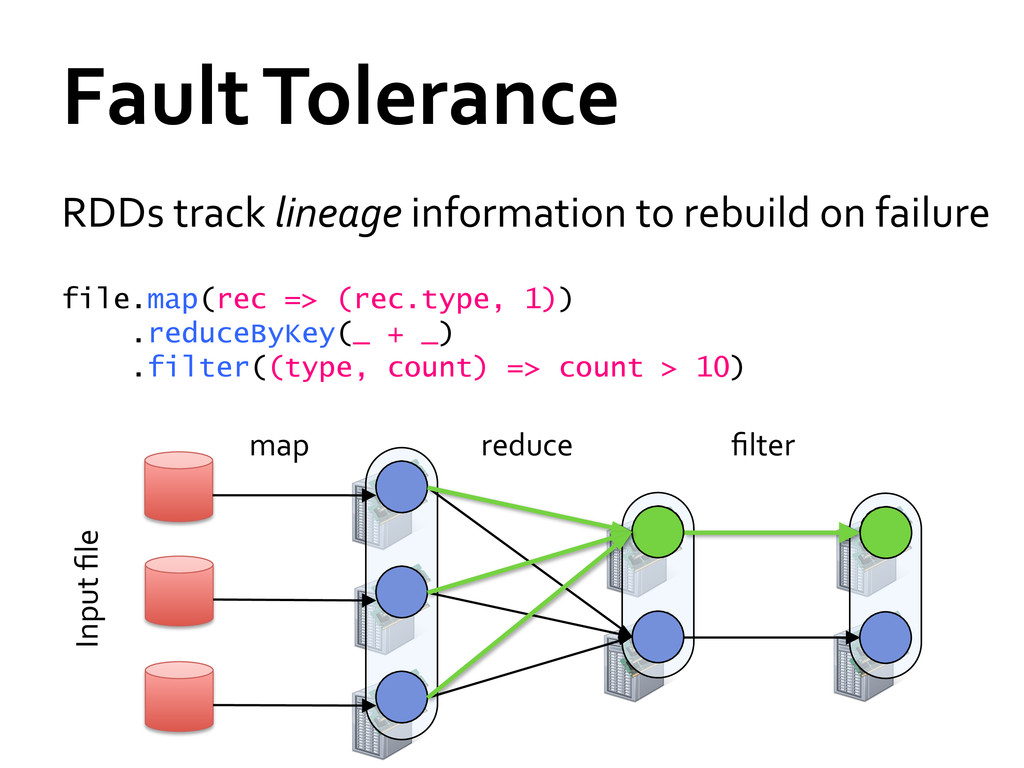
» Distributed collections of objects that can be cached in memory across cluster » Manipulated through parallel operators » Automatically recomputed on failure Programming interface » Functional APIs in Scala, Java, Python » Interactive use from Scala shell
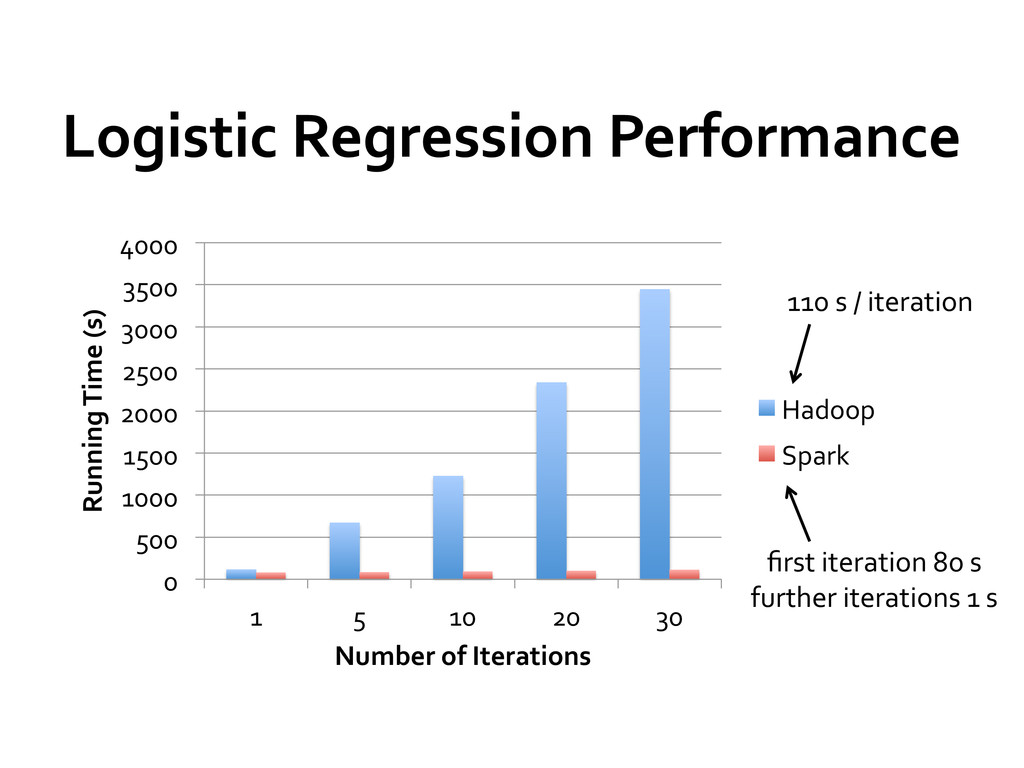
1500 2000 2500 3000 3500 4000 1 5 10 20 30 Running Time (s) Number of Iterations Hadoop Spark 110 s / iteration first iteration 80 s further iterations 1 s
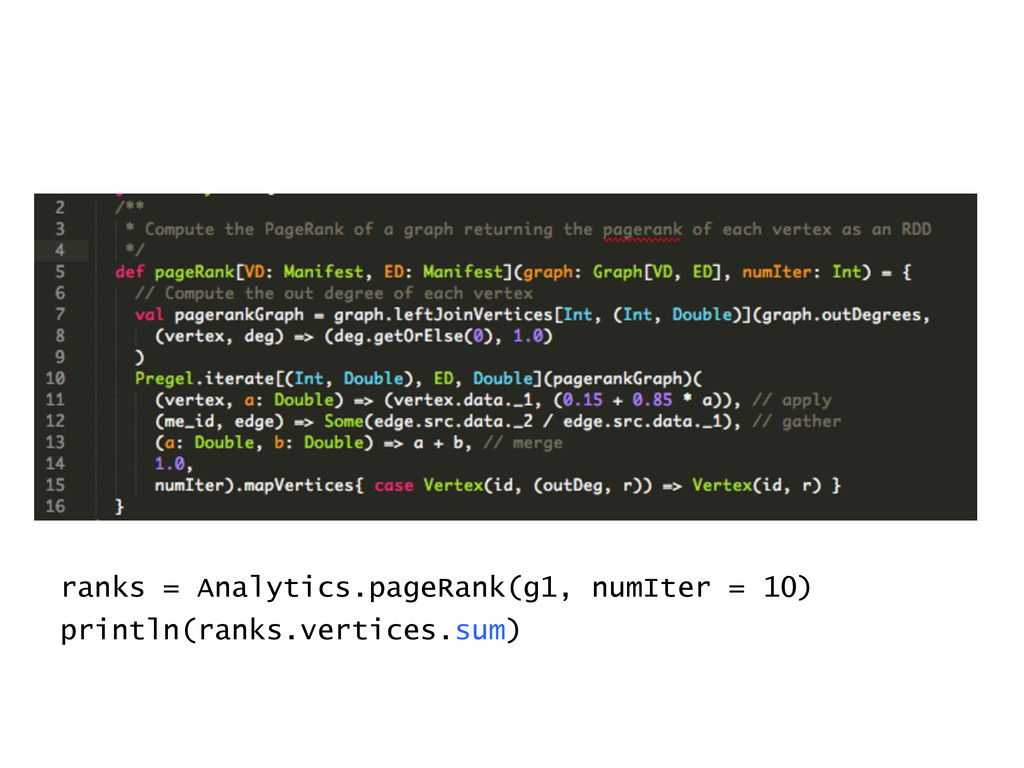
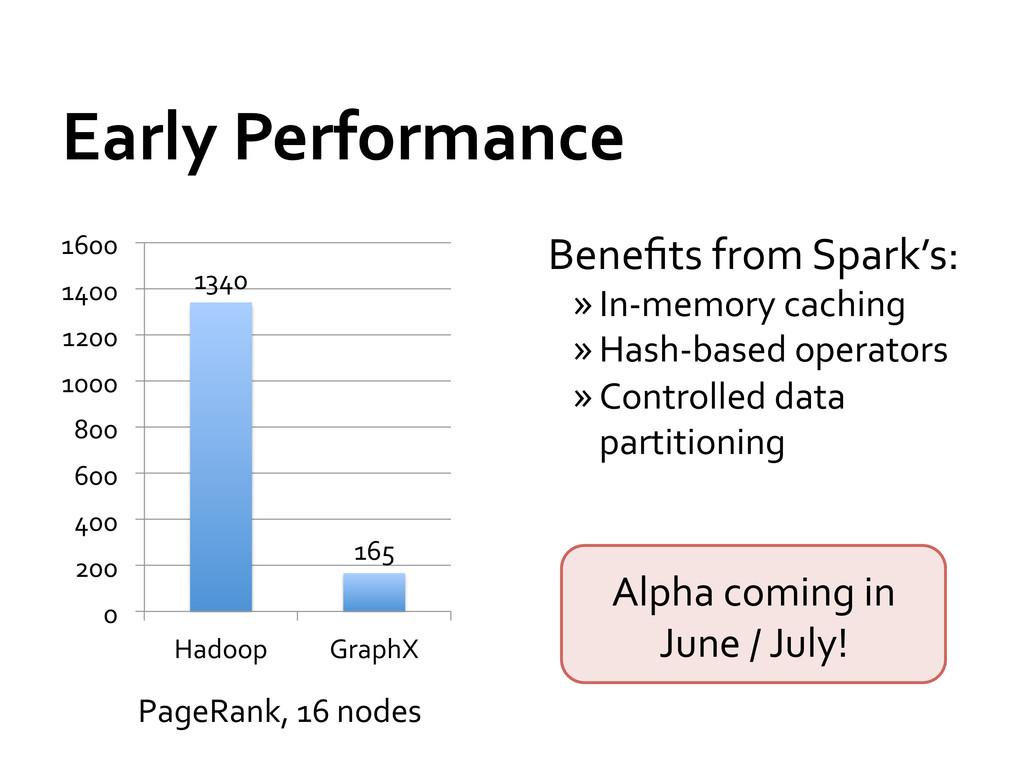
(Extract, transform, load) » Consumption of graph output » Fault-‐tolerance » Use the Scala REPL for interactive graph mining Programmability: leveraging Scala/Spark API » Implemented GraphLab / Pregel APIs in 20 loc » PageRank in 5 loc
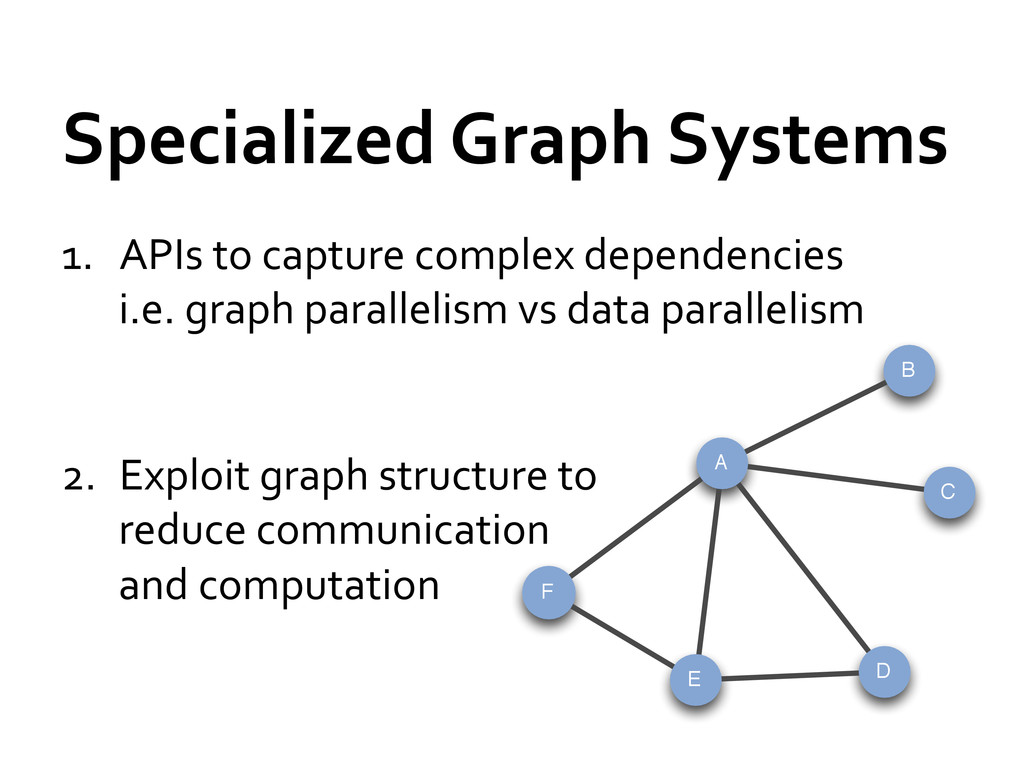
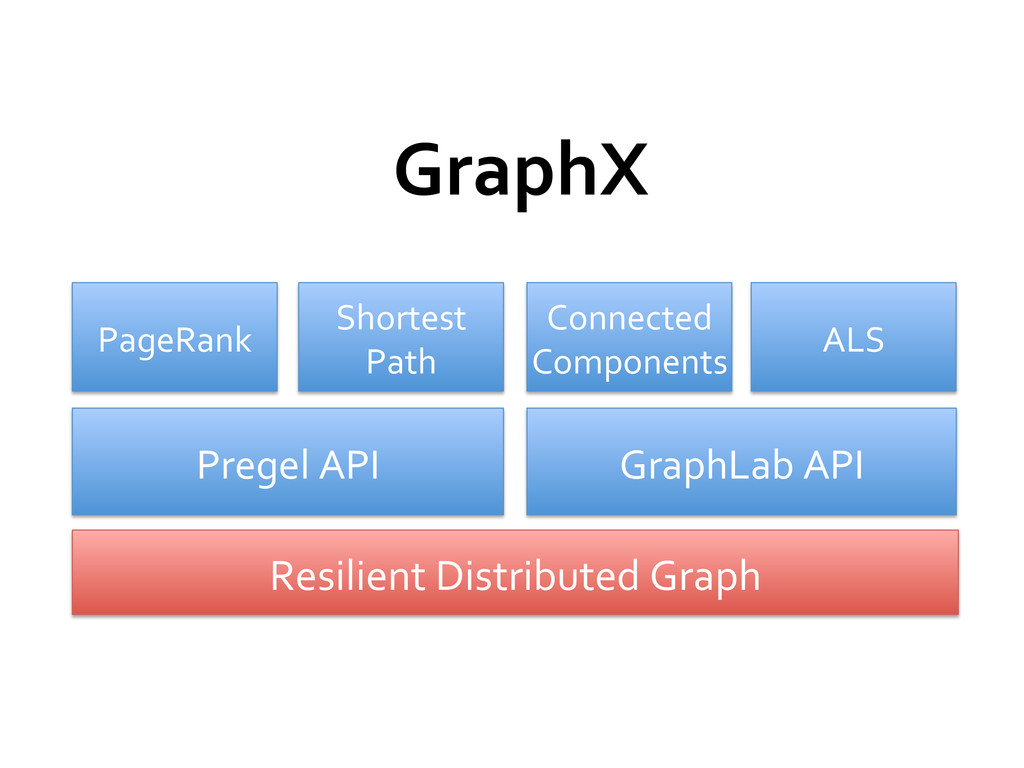
» Immutable, partitioned set of vertices and edges » Constructed using RDD[Edge] and RDD[Vertex] Additional set of primitives (3 functions) for graph computations » Able to express most graph algorithms (PageRank, Shortest Path, Connected Components, ALS, …) » Implemented GraphLab / Pregel in 20 lines of code
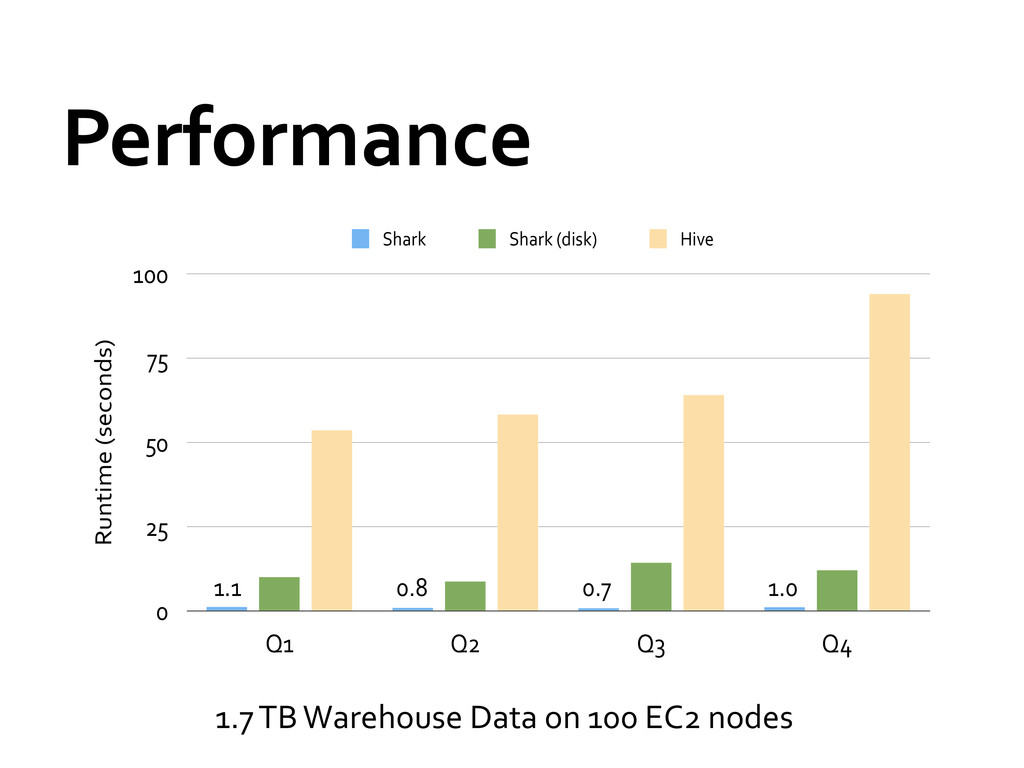
» Support both SQL and complex analytics » Up to 100X faster than Apache Hive Compatible with Apache Hive » HiveQL, UDF/UDAF, SerDes, Scripts » Runs on existing Hive warehouses In use at Yahoo! for fast in-‐memory OLAP
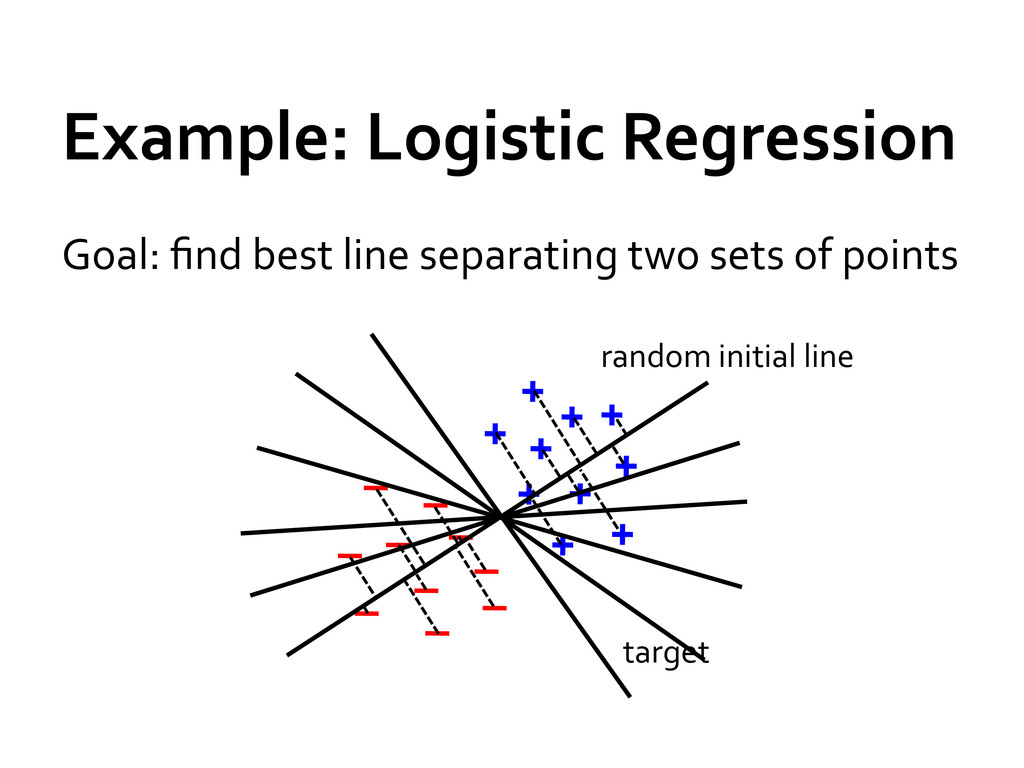
machine learning All share the same set of workers and caches def logRegress(points: RDD[Point]): Vector { var w = Vector(D, _ => 2 * rand.nextDouble - 1) for (i <- 1 to ITERATIONS) { val gradient = points.map { p => val denom = 1 + exp(-p.y * (w dot p.x)) (1 / denom - 1) * p.y * p.x }.reduce(_ + _) w -= gradient } w } val users = sql2rdd("SELECT * FROM user u JOIN comment c ON c.uid=u.uid") val features = users.mapRows { row => new Vector(extractFeature1(row.getInt("age")), extractFeature2(row.getStr("country")), ...)} val trainedVector = logRegress(features.cache())
» Online exercises (EC2) » Docs and API guides Easy to run in local mode, standalone clusters, Apache Mesos, YARN or EC2 Training camp at Berkeley in August
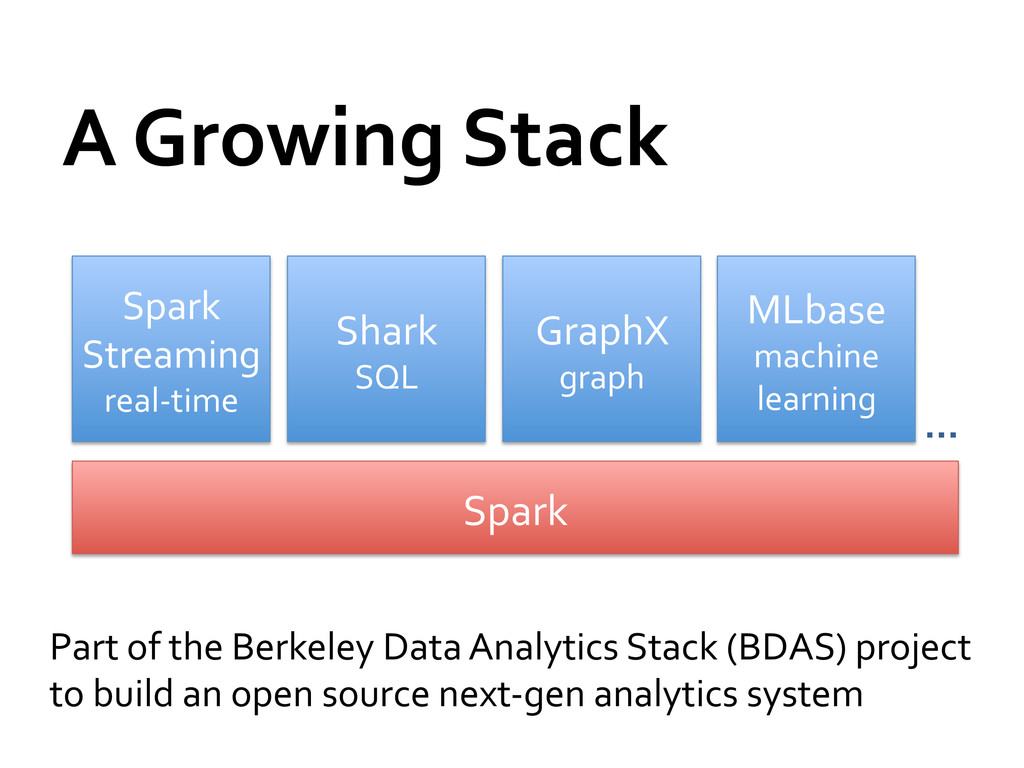
» More complex analytics (e.g. machine learning) » More interactive ad-‐hoc queries » More real-‐time stream processing Spark is a fast, unified platform for these apps Look for our training camp at Berkeley this August! spark-‐project.org
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}