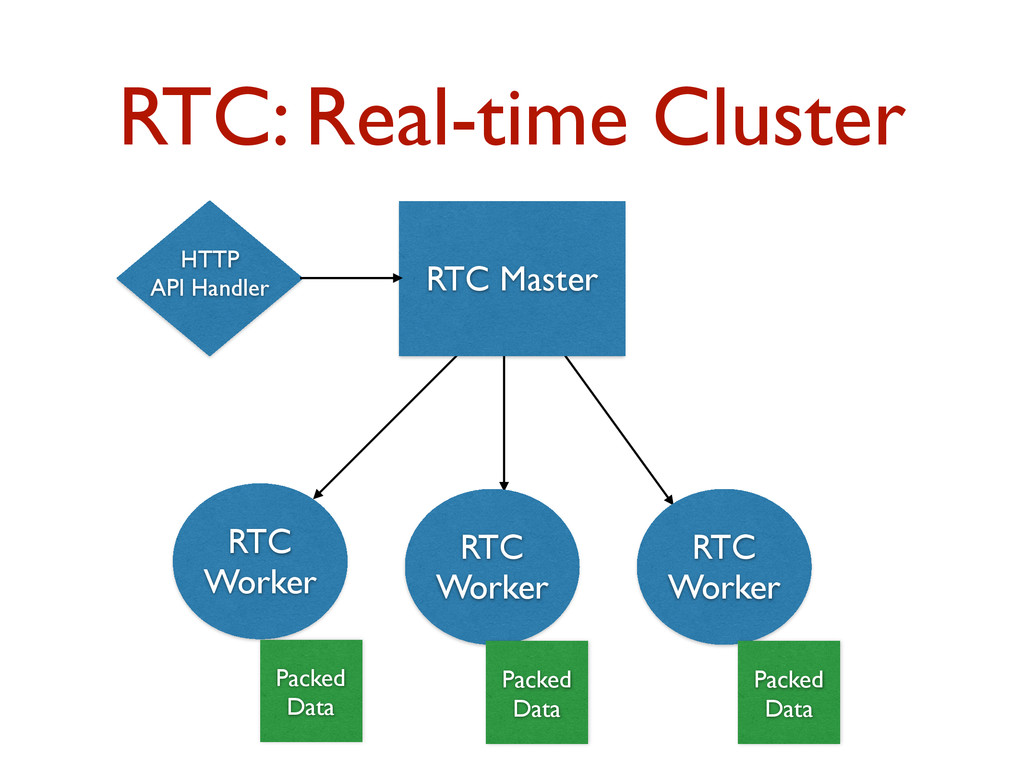
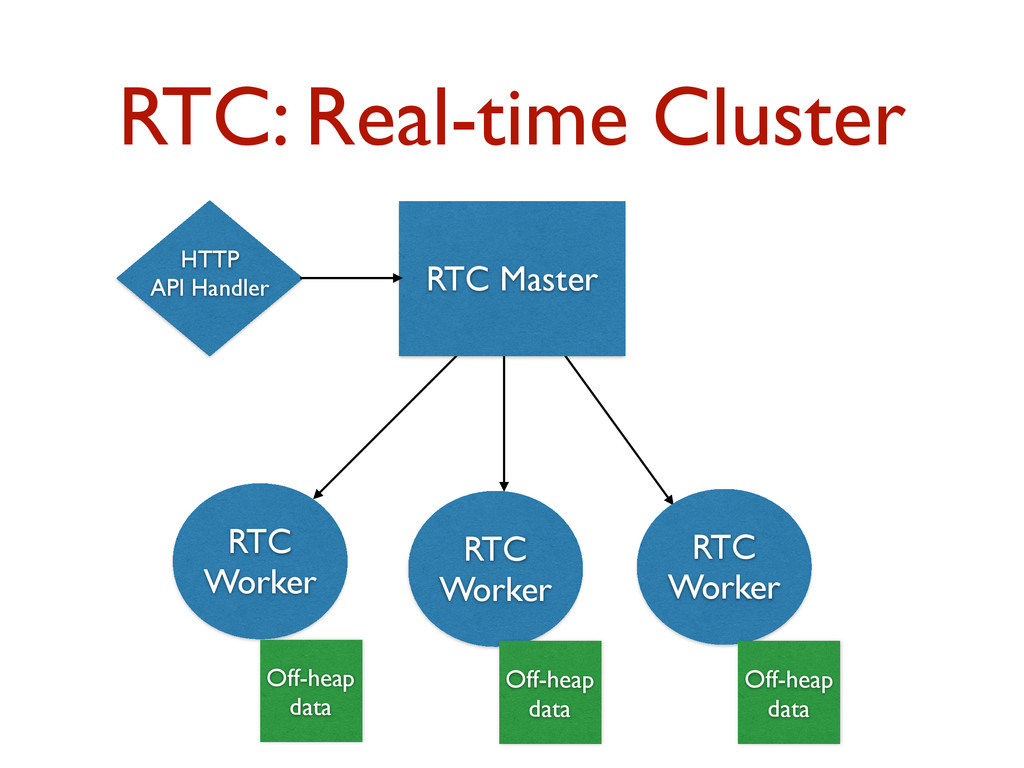
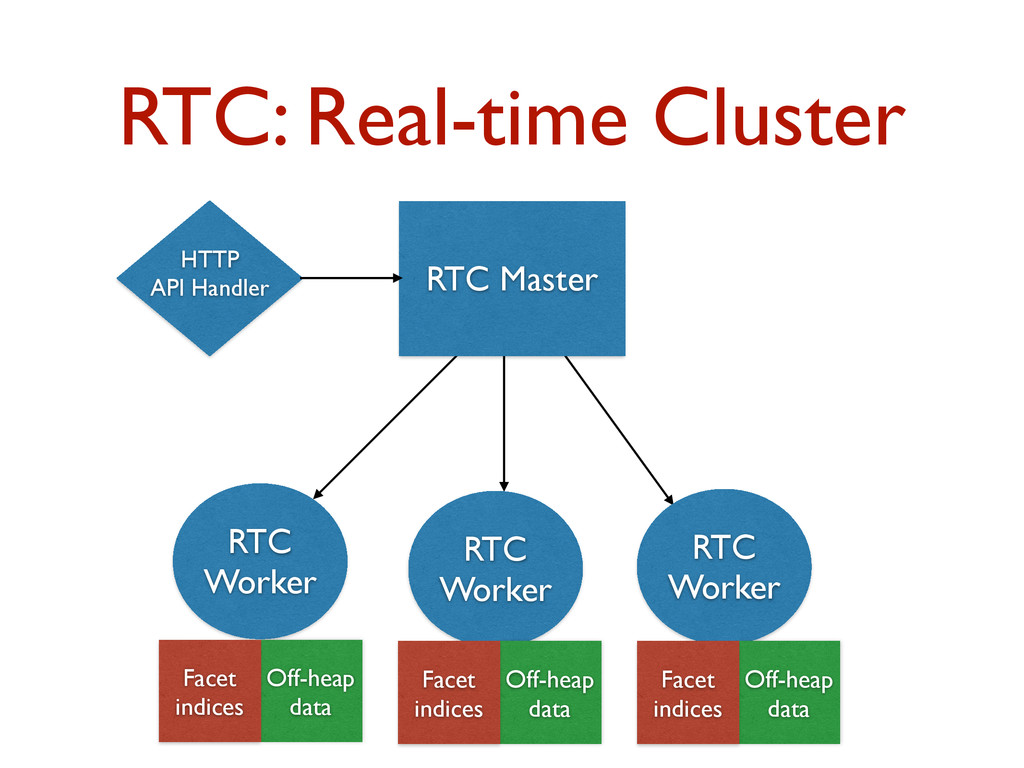
Building interactive data analytics products on top of large volumes of data is challenging. This talk will outline Quantifind's infrastructure story for building analytics software. We will describe the infrastructure that we originally built on top of existing systems such as Spark/Hadoop. However, the bulk of this talk will focus on a new, custom distributed system that we have built in-house for our predictive analytics software. This new system includes a distributed, in-memory, real-time computing platform that supports fast interactive querying against large volumes of compacted raw data that isn't pre-aggregated. This infrastructure can be viewed as an in-memory combination of map/reduce style computation and indexed structures built from bit sets to offsets in the compacted data. Akka Cluster sits at the core of this system for distributed communication between nodes. We will discuss why we chose to build our own system as well as tips and tricks that we've learned along the way for pushing the JVM for these types of systems.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}