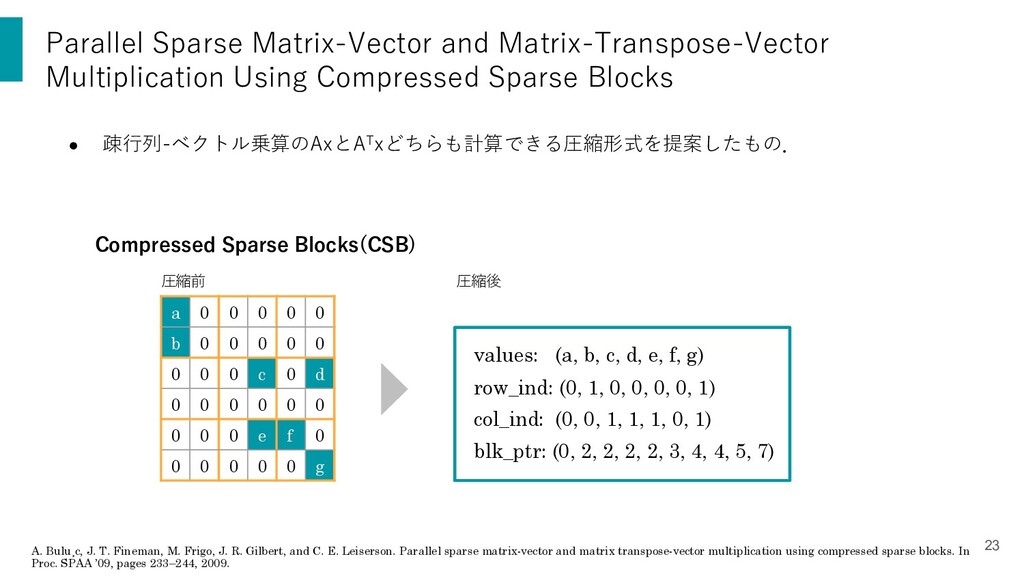
• 疎⾏列-ベクトル乗算のAxとATxどちらも計算できる圧縮形式を提案したもの. A. Bulu¸c, J. T. Fineman, M. Frigo, J. R. Gilbert, and C. E. Leiserson. Parallel sparse matrix-vector and matrix transpose-vector multiplication using compressed sparse blocks. In Proc. SPAA ’09, pages 233–244, 2009. 圧縮前 a 0 0 0 0 0 b 0 0 0 0 0 0 0 0 c 0 d 0 0 0 0 0 0 0 0 0 e f 0 0 0 0 0 0 g 圧縮後 Compressed Sparse Blocks(CSB) values: (a, b, c, d, e, f, g) row_ind: (0, 1, 0, 0, 0, 0, 1) col_ind: (0, 0, 1, 1, 1, 0, 1) blk_ptr: (0, 2, 2, 2, 2, 3, 4, 4, 5, 7) 23
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![研究の背景及び動機 DNNの学習・推論には膨⼤な演算処理が必要であり,この処理に時間を要する. GPUのメモリ容量や演算処理性能の制約が⼤きな課題となっている[1]. [1] Cheng, Yu, et al. "A survey](https://files.speakerdeck.com/presentations/99c838524304420eb9c2c68f7afdb127/slide_5.jpg){kind=link}
{kind=link}
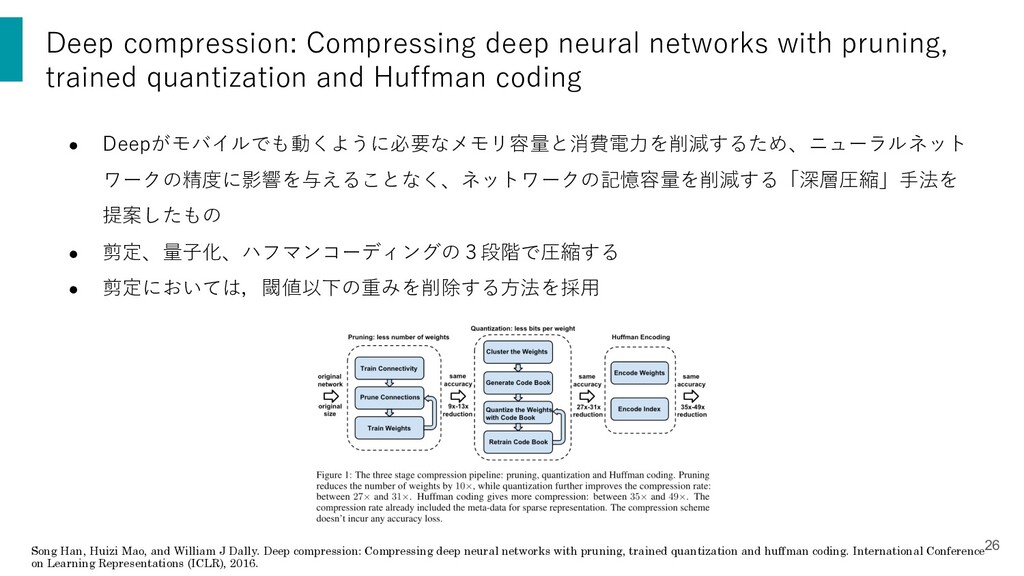
![剪定の概要とトレードオフ [4] Song Han, Huizi Mao, and William J Dally.](https://files.speakerdeck.com/presentations/99c838524304420eb9c2c68f7afdb127/slide_7.jpg){kind=link}
![⾮構造な疎⾏列の演算⾼速化⼿法 [6] Trevor Gale, Matei Zaharia, Cliff Young, and Erich](https://files.speakerdeck.com/presentations/99c838524304420eb9c2c68f7afdb127/slide_8.jpg){kind=link}
![既存⼿法の課題 CSR形式での圧縮を⽤いた⼿法では,転置⾏列への対応は困難[7] • ⾏列演算毎にCSR形式から転置⾏列へ変換をすることは,メモリアクセスが少なくとも2回発⽣(転置 ⾏列変換と⾏列演算)することになる. • 列のインデックスを圧縮するCompressed Sparse Column(CSC)形式を保持することも考えられるが, メモリ⾮効率.](https://files.speakerdeck.com/presentations/99c838524304420eb9c2c68f7afdb127/slide_9.jpg){kind=link}
{kind=link}
![研究のアプローチ [7] Aydın Buluç, Jeremy T. Fineman, Matteo Frigo, John](https://files.speakerdeck.com/presentations/99c838524304420eb9c2c68f7afdb127/slide_11.jpg){kind=link}
![研究の⼿順 剪定が適⽤されたDNNで⾏われる疎⾏列-密⾏列乗算に焦点を当てる. DNNのモデルおよびデータセットは所与のものとする. [8] Carl Yang, Aydin Buluc, and John](https://files.speakerdeck.com/presentations/99c838524304420eb9c2c68f7afdb127/slide_12.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
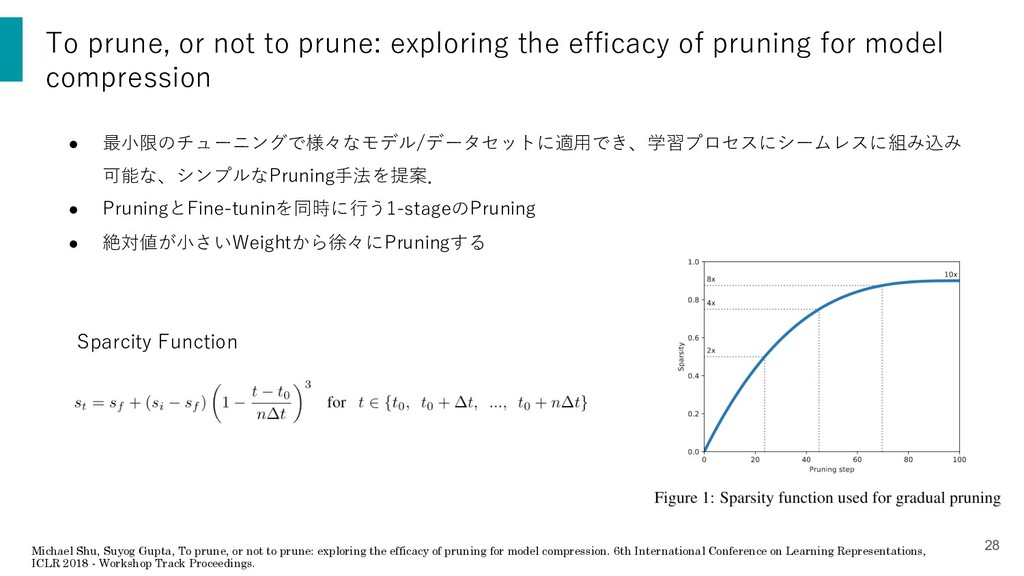{kind=link}
{kind=link}
![[1] Yu Cheng, Duo Wang, Pan Zhou, and Tao Zhang.](https://files.speakerdeck.com/presentations/99c838524304420eb9c2c68f7afdb127/slide_30.jpg){kind=link}
![[6] Trevor Gale, Matei Zaharia, Cliff Young, and Erich Elsen.](https://files.speakerdeck.com/presentations/99c838524304420eb9c2c68f7afdb127/slide_31.jpg){kind=link}
![[11] Scott Gray, Alec Radford, and Diederik Kingma. 2017. GPU](https://files.speakerdeck.com/presentations/99c838524304420eb9c2c68f7afdb127/slide_32.jpg){kind=link}