Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Multiplying Matrices Without Multiplying
Search
ryoherisson
September 03, 2021
Research
840
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Multiplying Matrices Without Multiplying
CompML勉強会での論文"Multiplying Matrices Without Multiplying"の紹介資料.
ryoherisson
September 03, 2021
More Decks by ryoherisson
See All by ryoherisson
論文紹介: tSNE-CUDA
ryoherisson
0
520
疎行列圧縮フォーマットの紹介
ryoherisson
0
960
Neural Network Pruning
ryoherisson
0
780
CompML: Introduction to Neural Network Pruning
ryoherisson
1
18k
Deep Neural NetworkのためのGPU演算処理高速化に関する研究
ryoherisson
0
19k
CompML: Precision and Recall for Time Series
ryoherisson
0
310
CompML CUDA C Hello World!
ryoherisson
0
210
Other Decks in Research
See All in Research
Scalable dynamic origin-destination demand estimation enhanced by high-resolution satellite imagery data
satai
3
350
Overview of AGRODEP Activities and Current Status: Dr. Seraphin Niyonsenga
akademiya2063
PRO
0
110
Anthropic が提案する LLM の内部状態を自然言語で説明可能にした Natural Language Autoencoders / Natural Language Autoencoders Produce Unsupervised Explanations of LLM Activations
shunk031
0
150
JICA QUEST 共創×革新プログラム Impact Report(海ノ向こうコーヒー)
ontheslope
0
200
SOTAのさらに先へ:厳しい推論制約下での高性能モデルのPost-Training
analokmaus
0
1.4k
Dual Quadric表現を用いた動的物体追跡とRGB-D・IMU制約の密結合によるオドメトリ推定
nanoshimarobot
0
440
敵対生成プロンプト同時探索による内省型プロンプト最適化
kinoue_smarthr
0
310
AIエージェント時代のLLM-jpモデルのあるべき姿
k141303
0
510
Data Visualization Tools in the Age of AI
flekschas
0
170
データサイエンティストの就労意識~2015 → 2026 一般(個人)会員アンケートより
datascientistsociety
PRO
0
230
IA for theory
gpeyre
0
260
2026 東京科学大 情報通信系 研究室紹介 (大岡山)
icttitech
0
4k
Featured
See All Featured
Money Talks: Using Revenue to Get Sh*t Done
nikkihalliwell
0
390
Leo the Paperboy
mayatellez
8
1.9k
Let's Do A Bunch of Simple Stuff to Make Websites Faster
chriscoyier
508
140k
Design and Strategy: How to Deal with People Who Don’t "Get" Design
morganepeng
133
19k
Digital Ethics as a Driver of Design Innovation
axbom
PRO
1
340
Breaking role norms: Why Content Design is so much more than writing copy - Taylor Woolridge
uxyall
0
350
Building Better People: How to give real-time feedback that sticks.
wjessup
370
20k
KATA
mclloyd
PRO
35
15k
Ruling the World: When Life Gets Gamed
codingconduct
0
280
A better future with KSS
kneath
240
18k
So, you think you're a good person
axbom
PRO
2
2.1k
実際に使うSQLの書き方 徹底解説 / pgcon21j-tutorial
soudai
PRO
201
75k
Transcript
CompML Multiplying Matrices Without Multiplying - 論⽂紹介 - Ryohei Izawa
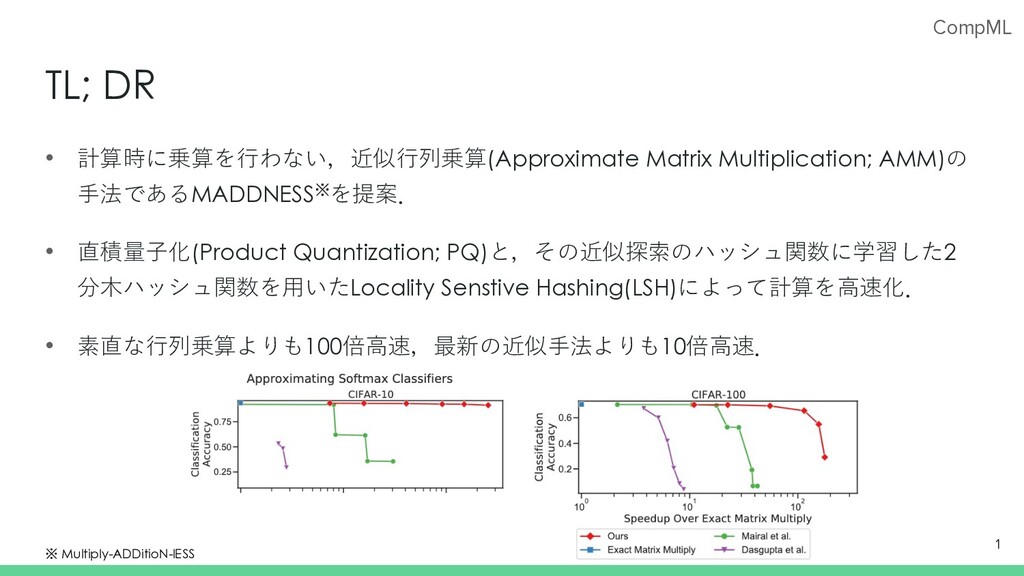
CompML TL; DR • 計算時に乗算を⾏わない,近似⾏列乗算(Approximate Matrix Multiplication; AMM)の ⼿法であるMADDNESS※を提案. •
直積量⼦化(Product Quantization; PQ)と,その近似探索のハッシュ関数に学習した2 分⽊ハッシュ関数を⽤いたLocality Senstive Hashing(LSH)によって計算を⾼速化. • 素直な⾏列乗算よりも100倍⾼速,最新の近似⼿法よりも10倍⾼速. 1 ※ Multiply-ADDitioN-lESS
CompML AMMの概要
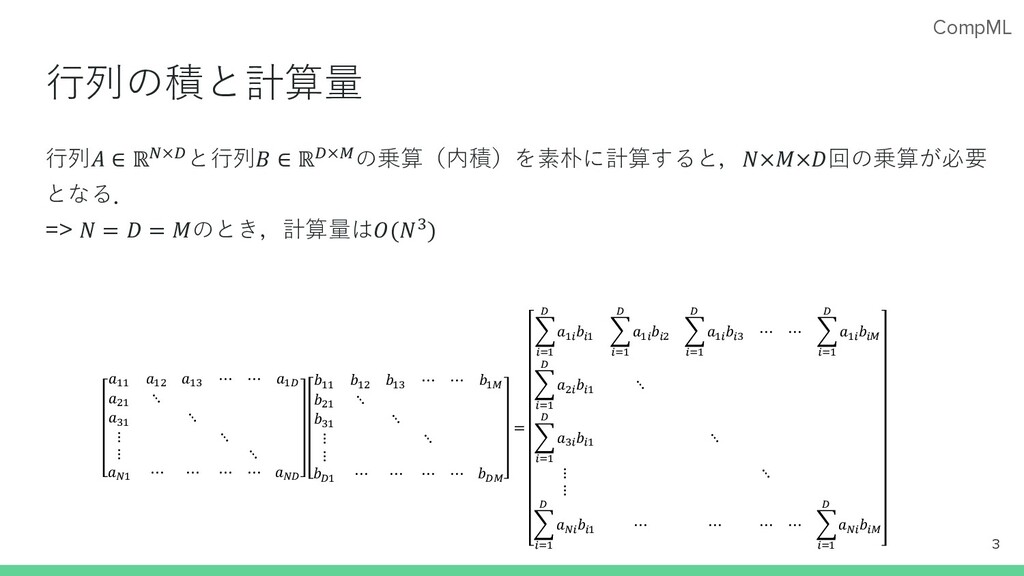
CompML ⾏列の積と計算量 ⾏列𝐴 ∈ ℝ!×#と⾏列𝐵 ∈ ℝ#×$の乗算(内積)を素朴に計算すると,𝑁×𝑀×𝐷回の乗算が必要 となる. => 𝑁
= 𝐷 = 𝑀のとき,計算量は𝑂(𝑁%) 3 𝑎!! 𝑎!" 𝑎!# ⋯ ⋯ 𝑎!$ 𝑎"! ⋱ 𝑎#! ⋱ ⋮ ⋱ ⋮ ⋱ 𝑎%! ⋯ ⋯ ⋯ ⋯ 𝑎%$ 𝑏!! 𝑏!" 𝑏!# ⋯ ⋯ 𝑏!& 𝑏"! ⋱ 𝑏#! ⋱ ⋮ ⋱ ⋮ 𝑏$! ⋯ ⋯ ⋯ ⋯ 𝑏$& = ' '(! $ 𝑎!' 𝑏'! ' '(! $ 𝑎!' 𝑏'" ' '(! $ 𝑎!' 𝑏'# ⋯ ⋯ ' '(! $ 𝑎!' 𝑏'& ' '(! $ 𝑎"' 𝑏'! ⋱ ' '(! $ 𝑎#' 𝑏'! ⋱ ⋮ ⋱ ⋮ ' '(! $ 𝑎%' 𝑏'! ⋯ ⋯ ⋯ ⋯ ' '(! $ 𝑎%' 𝑏'&
CompML 近似⾏列乗算(AMM) ⾏列の乗算を近似的に求めるため,⾏列の圧縮やハッシュ関数を⽤いて計算コストを削減す る⽅法. • Linear Approximation ⾏列𝐴,𝐵を低次元空間に圧縮した上で乗算を⾏う⼿法. (e.g. 𝐴の列と𝐵の⾏をランダムにサンプリングして圧縮)
• Hashing to Avoid Linear Operations Lookup tableを事前に⽤意しておき,近似探索により計算を⾏う. ⇨ MADDNESSはこちらの⼿法 4 𝐴𝐵 ≈ 𝐴𝑉! 𝑉" #𝐵 , 𝑤ℎ𝑒𝑟𝑒 𝑉! , 𝑉" ∈ ℝ$×&, 𝑑 ≪ 𝐷
CompML MADDNESS
CompML 問題の定式化 ⾏列𝐴 ∈ ℝ!×#,⾏列𝐵 ∈ ℝ#×$が与えられ,𝑁 ≫ 𝐷 ≥
𝑀のとき,定数𝛼, 𝛽のもとで誤差𝜀(𝜏)が ⼩さくなるように以下の𝑔 6 , ℎ 6 , 𝑓(6)を求める. 6 𝛼𝑓(𝑔 𝐴 , ℎ 𝐵 ) + 𝛽 − 𝐴𝐵 ' < 𝜀(𝜏) 𝐴𝐵 ' 𝑔 𝐴 : ⼊⼒⾏列𝐴の各⾏の部分空間(サブベクトル)に近似するプロトタイプのインデックスの集まり. ℎ(𝐵): 既知の⾏列𝐵の各列の部分空間とそれに対応するプロトタイプごとの内積が格納されたテーブル. 𝑓(𝑔 𝐴 , ℎ 𝐴 ): 部分空間ごとの内積の和.⼩さいbit幅で量⼦化しているため,定数𝛼, 𝛽で元のbit幅の値に戻す.
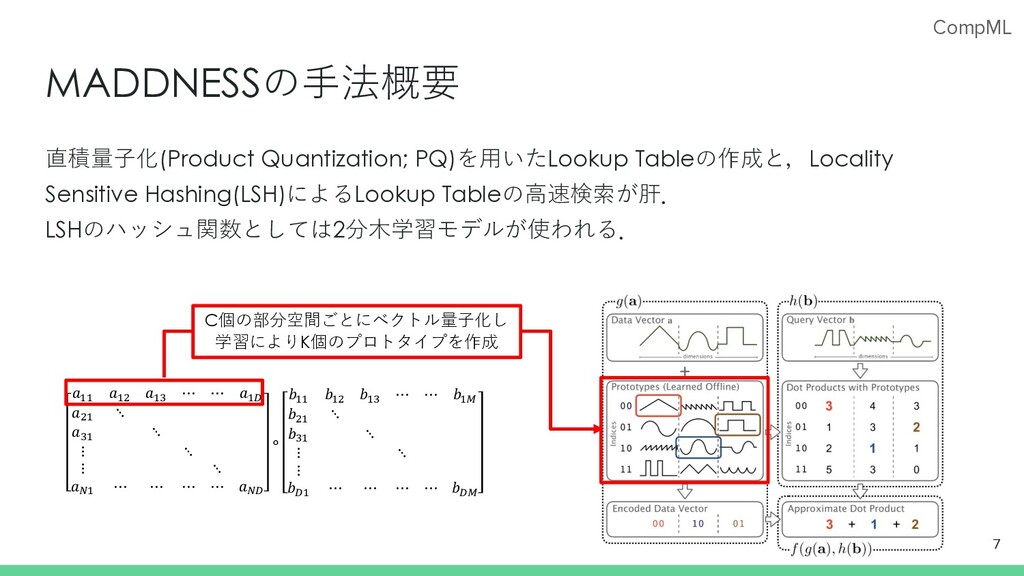
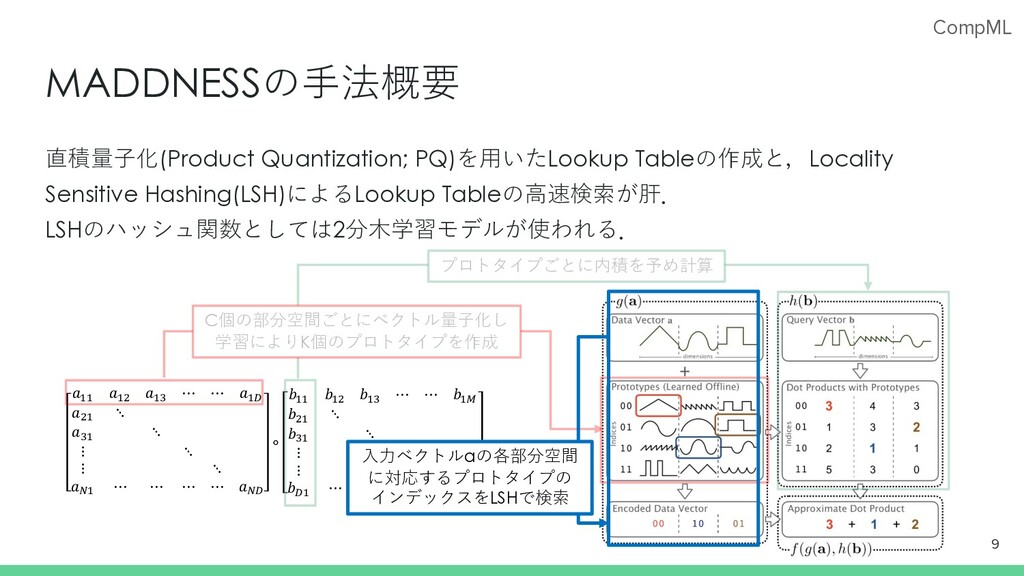
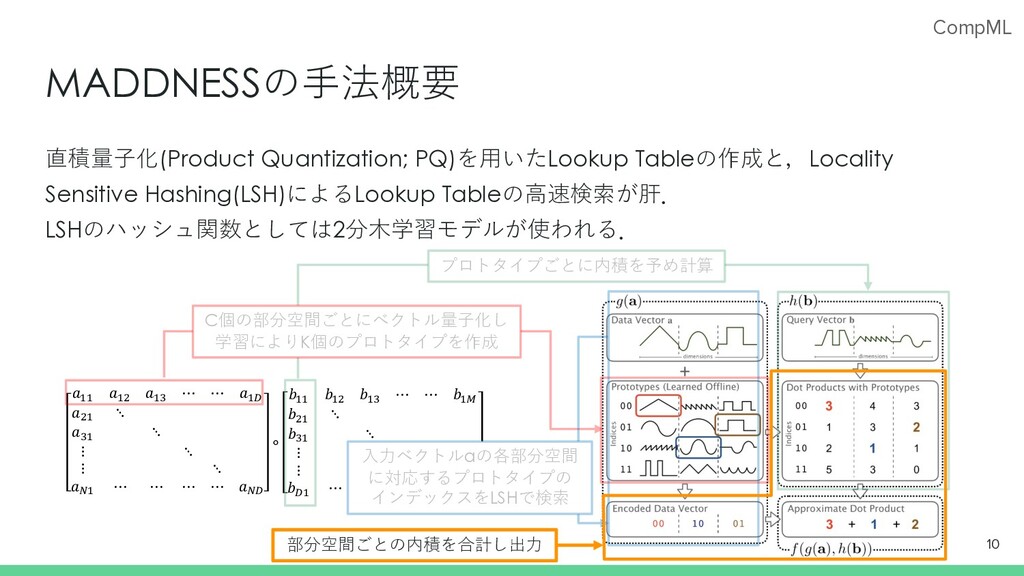
CompML MADDNESSの⼿法概要 直積量⼦化(Product Quantization; PQ)を⽤いたLookup Tableの作成と,Locality Sensitive Hashing(LSH)によるLookup Tableの⾼速検索が肝. LSHのハッシュ関数としては2分⽊学習モデルが使われる.
7 𝑎!! 𝑎!" 𝑎!# ⋯ ⋯ 𝑎!$ 𝑎"! ⋱ 𝑎#! ⋱ ⋮ ⋱ ⋮ ⋱ 𝑎%! ⋯ ⋯ ⋯ ⋯ 𝑎%$ ∘ 𝑏!! 𝑏!" 𝑏!# ⋯ ⋯ 𝑏!& 𝑏"! ⋱ 𝑏#! ⋱ ⋮ ⋱ ⋮ 𝑏$! ⋯ ⋯ ⋯ ⋯ 𝑏$& C個の部分空間ごとにベクトル量⼦化し 学習によりK個のプロトタイプを作成
CompML 𝑎!! 𝑎!" 𝑎!# ⋯ ⋯ 𝑎!$ 𝑎"! ⋱ 𝑎#!
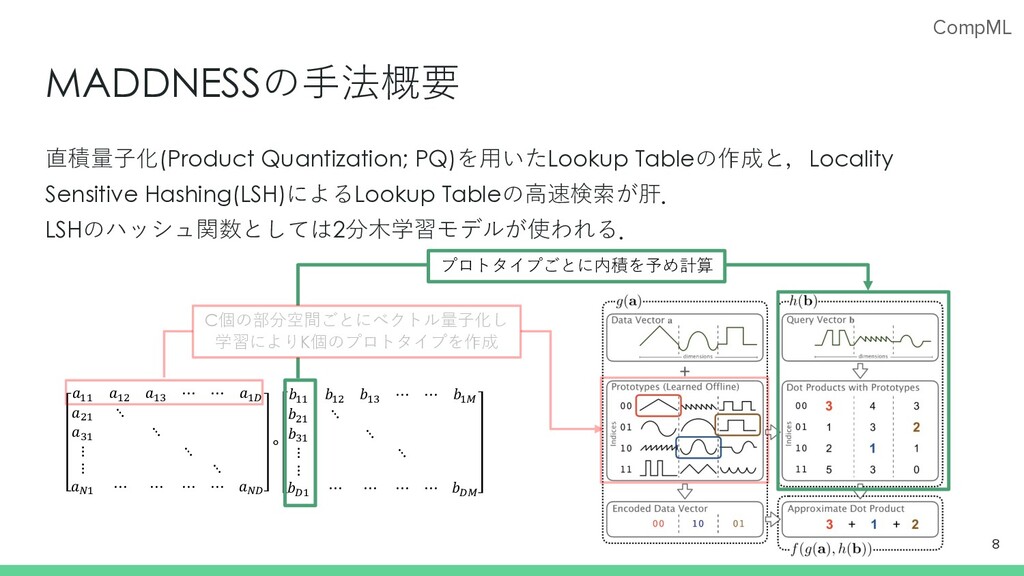
⋱ ⋮ ⋱ ⋮ ⋱ 𝑎%! ⋯ ⋯ ⋯ ⋯ 𝑎%$ ∘ 𝑏!! 𝑏!" 𝑏!# ⋯ ⋯ 𝑏!& 𝑏"! ⋱ 𝑏#! ⋱ ⋮ ⋱ ⋮ 𝑏$! ⋯ ⋯ ⋯ ⋯ 𝑏$& MADDNESSの⼿法概要 直積量⼦化(Product Quantization; PQ)を⽤いたLookup Tableの作成と,Locality Sensitive Hashing(LSH)によるLookup Tableの⾼速検索が肝. LSHのハッシュ関数としては2分⽊学習モデルが使われる. 8 プロトタイプごとに内積を予め計算 C個の部分空間ごとにベクトル量⼦化し 学習によりK個のプロトタイプを作成
CompML 𝑎!! 𝑎!" 𝑎!# ⋯ ⋯ 𝑎!$ 𝑎"! ⋱ 𝑎#!
⋱ ⋮ ⋱ ⋮ ⋱ 𝑎%! ⋯ ⋯ ⋯ ⋯ 𝑎%$ ∘ 𝑏!! 𝑏!" 𝑏!# ⋯ ⋯ 𝑏!& 𝑏"! ⋱ 𝑏#! ⋱ ⋮ ⋱ ⋮ 𝑏$! ⋯ ⋯ ⋯ ⋯ 𝑏$& MADDNESSの⼿法概要 直積量⼦化(Product Quantization; PQ)を⽤いたLookup Tableの作成と,Locality Sensitive Hashing(LSH)によるLookup Tableの⾼速検索が肝. LSHのハッシュ関数としては2分⽊学習モデルが使われる. 9 プロトタイプごとに内積を予め計算 C個の部分空間ごとにベクトル量⼦化し 学習によりK個のプロトタイプを作成 ⼊⼒ベクトルaの各部分空間 に対応するプロトタイプの インデックスをLSHで検索
CompML 𝑎!! 𝑎!" 𝑎!# ⋯ ⋯ 𝑎!$ 𝑎"! ⋱ 𝑎#!
⋱ ⋮ ⋱ ⋮ ⋱ 𝑎%! ⋯ ⋯ ⋯ ⋯ 𝑎%$ ∘ 𝑏!! 𝑏!" 𝑏!# ⋯ ⋯ 𝑏!& 𝑏"! ⋱ 𝑏#! ⋱ ⋮ ⋱ ⋮ 𝑏$! ⋯ ⋯ ⋯ ⋯ 𝑏$& MADDNESSの⼿法概要 直積量⼦化(Product Quantization; PQ)を⽤いたLookup Tableの作成と,Locality Sensitive Hashing(LSH)によるLookup Tableの⾼速検索が肝. LSHのハッシュ関数としては2分⽊学習モデルが使われる. 10 プロトタイプごとに内積を予め計算 C個の部分空間ごとにベクトル量⼦化し 学習によりK個のプロトタイプを作成 ⼊⼒ベクトルaの各部分空間 に対応するプロトタイプの インデックスをLSHで検索 部分空間ごとの内積を合計し出⼒
CompML MADDNESSの⼿法概要 PQで得られた𝑓(𝑔(𝐴), ℎ(𝐵))は,元の⾏列𝐴,𝐵よりも少ないbit幅で表現しているため,定数 𝛼,𝛽を⽤いて元のbit幅に戻す. 𝛼𝑓 𝑔 𝐴 , ℎ
𝐵 + 𝛽 11 ただし, • 𝑔(𝐴)は⼊⼒⾏列𝐴の各⾏の部分空間(サブベクトル)に近似するプロトタイプのインデックスの集まり • ℎ(𝐵)は既知の⾏列𝐵の各列の部分空間とそれに対応するプロトタイプごとの内積が格納されたテーブル を返す.
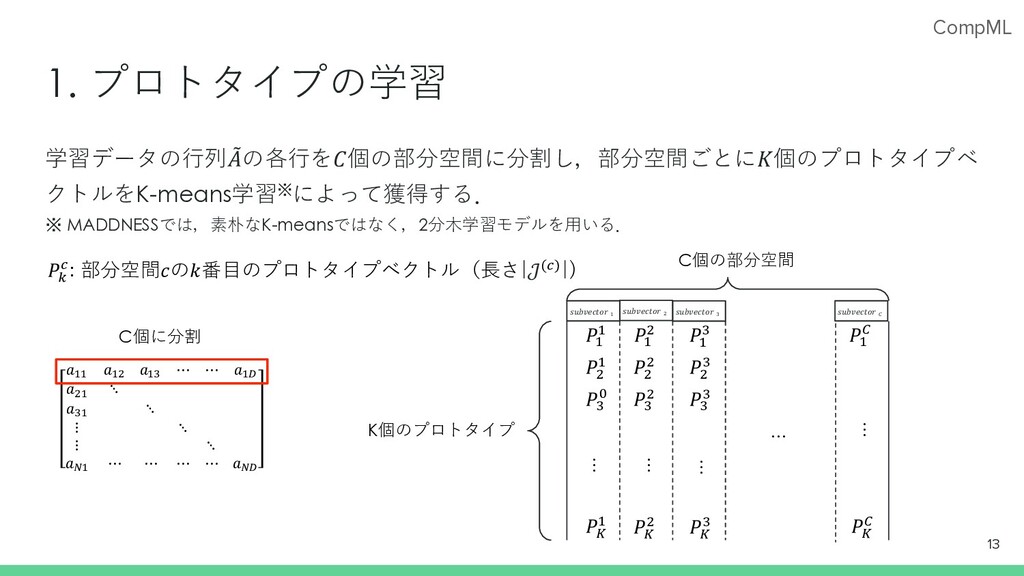
CompML Product Quantization 直積量⼦化(Product Quantization; PQ)の⼿順; 12 1. プロトタイプの学習 学習⽤の⾏列
: 𝐴の⾏ベクトルを𝐶個の部分ベクトルに 分割し, 部分ベクトルごとに𝐾個のプロトタイプを 学習により獲得 2. ⼊⼒ベクトル𝑎のエンコード:𝑔(𝑎) ⼊⼒ベクトル𝑎の部分空間ごとに最も近いプロトタイ プを選択 3. 内積Lookup Tableの構築:ℎ(𝑏) 学習で獲得したプロトタイプと既知の⾏列𝐵の列ベク トル𝑏の部分空間ごとの内積を予め計算 4. アグリゲーション ℎ(𝑏)から𝑔 𝑎 で得たインデックスで部分空間ごとの 内積を取得し,⾜し合わせて出⼒とする
CompML 1. プロトタイプの学習 学習データの⾏列 : 𝐴の各⾏を𝐶個の部分空間に分割し,部分空間ごとに𝐾個のプロトタイプベ クトルをK-means学習※によって獲得する. ※ MADDNESSでは,素朴なK-meansではなく,2分⽊学習モデルを⽤いる. 13
𝑎!! 𝑎!" 𝑎!# ⋯ ⋯ 𝑎!$ 𝑎"! ⋱ 𝑎#! ⋱ ⋮ ⋱ ⋮ ⋱ 𝑎%! ⋯ ⋯ ⋯ ⋯ 𝑎%$ C個に分割 K個のプロトタイプ … C個の部分空間 𝑃( ( 𝑃) ( 𝑃* + 𝑃( ) 𝑃, ( 𝑃( * 𝑃( - 𝑃, - … … … … 𝑃) ) 𝑃* ) 𝑃) * 𝑃* * 𝑃, ) 𝑃, * 𝑃. /: 部分空間𝑐の𝑘番⽬のプロトタイプベクトル(⻑さ|𝒥(/)|) 𝑠𝑢𝑏𝑣𝑒𝑐𝑡𝑜𝑟 ! 𝑠𝑢𝑏𝑣𝑒𝑐𝑡𝑜𝑟 " 𝑠𝑢𝑏𝑣𝑒𝑐𝑡𝑜𝑟 # 𝑠𝑢𝑏𝑣𝑒𝑐𝑡𝑜𝑟 $
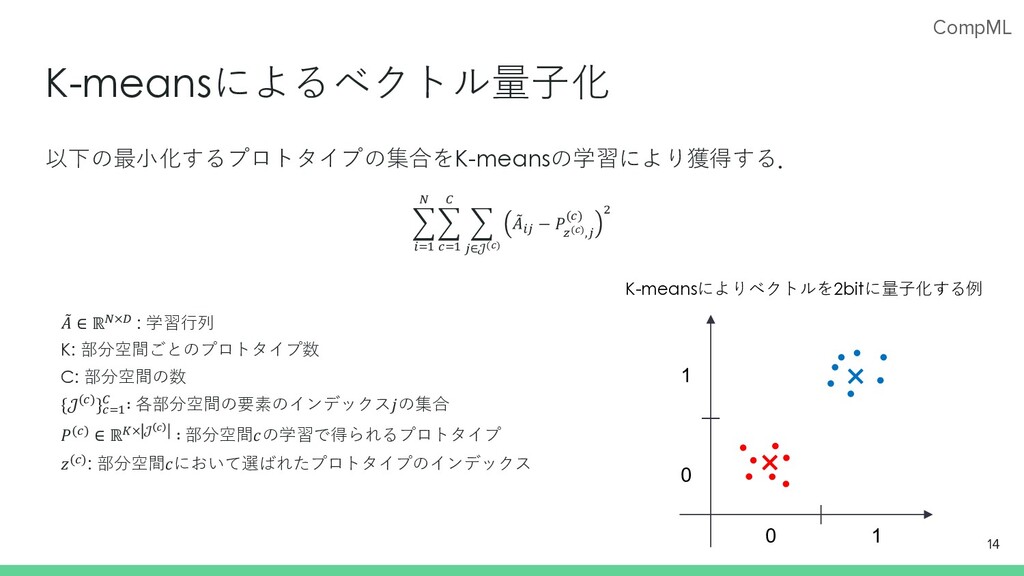
CompML K-meansによるベクトル量⼦化 1 𝐴 ∈ ℝ!×# : 学習⾏列 K: 部分空間ごとのプロトタイプ数
C: 部分空間の数 {𝒥(%)}%'( ) ∶ 各部分空間の要素のインデックス𝑗の集合 𝑃(%) ∈ ℝ*× 𝒥 ! ∶ 部分空間𝑐の学習で得られるプロトタイプ 𝑧(%): 部分空間𝑐において選ばれたプロトタイプのインデックス 14 0 1 1 0 K-meansによりベクトルを2bitに量⼦化する例 以下の最⼩化するプロトタイプの集合をK-meansの学習により獲得する. < ,'( ! < %'( ) < -∈𝒥(!) 1 𝐴,- − 𝑃 /(!),- (%) 1
CompML 2. ⼊⼒ベクトル𝑎のエンコード:𝑔(𝑎) ⼊⼒ベクトル𝑎に対し,各部分空間に対応するプロトタイプのインデックスの集合を返す. 各インデックスは,𝑙𝑜𝑔> 𝐾 𝑏𝑖𝑡でエンコードされる(𝐾 = 16のとき4𝑏𝑖𝑡) 15
𝑔 / 𝑎 ≜ 𝑎𝑟𝑔𝑚𝑖𝑛. G 2∈𝒥(*) 𝑎2 − 𝑃.,2 (/) ) ベクトル𝑎の部分空間𝑐に対応するインデックスの取得
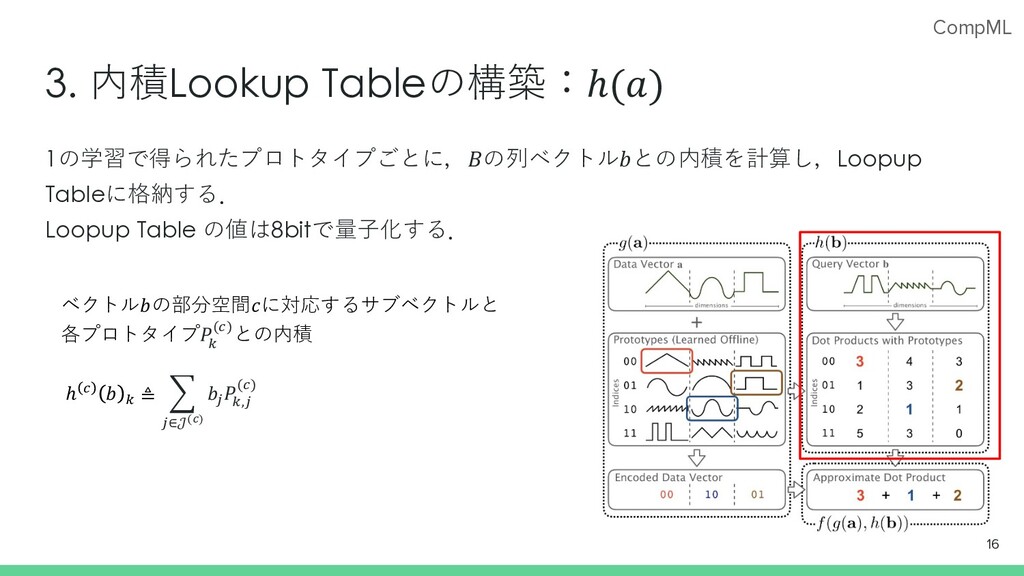
CompML 3. 内積Lookup Tableの構築:ℎ(𝑎) 16 1の学習で得られたプロトタイプごとに,𝐵の列ベクトル𝑏との内積を計算し,Loopup Tableに格納する. Loopup Table の値は8bitで量⼦化する.
ℎ / 𝑏 . ≜ G 2∈𝒥(*) 𝑏2 𝑃 .,2 (/) ベクトル𝑏の部分空間𝑐に対応するサブベクトルと 各プロトタイプ𝑃 . (/)との内積
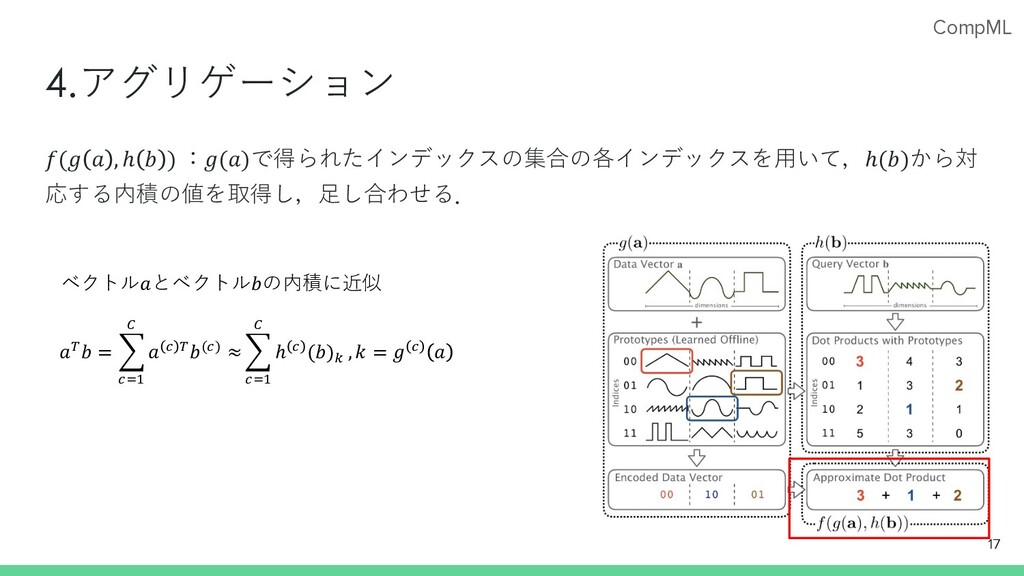
CompML 4.アグリゲーション 17 𝑓(𝑔 𝑎 , ℎ 𝑏 ) :𝑔(𝑎)で得られたインデックスの集合の各インデックスを⽤いて,ℎ(𝑏)から対
応する内積の値を取得し,⾜し合わせる. 𝑎#𝑏 = G /6( - 𝑎 / #𝑏(/) ≈ G /6( - ℎ / (𝑏). , 𝑘 = 𝑔 / 𝑎 ベクトル𝑎とベクトル𝑏の内積に近似
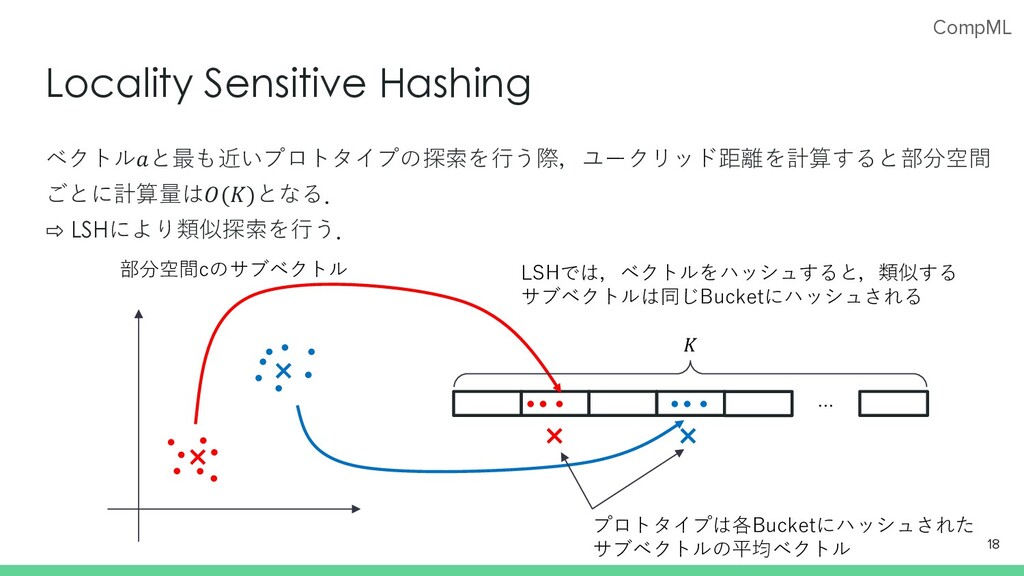
CompML Locality Sensitive Hashing ベクトル𝑎と最も近いプロトタイプの探索を⾏う際,ユークリッド距離を計算すると部分空間 ごとに計算量は𝑂(𝐾)となる. ⇨ LSHにより類似探索を⾏う. 18 …
LSHでは,ベクトルをハッシュすると,類似する サブベクトルは同じBucketにハッシュされる プロトタイプは各Bucketにハッシュされた サブベクトルの平均ベクトル 𝐾 部分空間cのサブベクトル
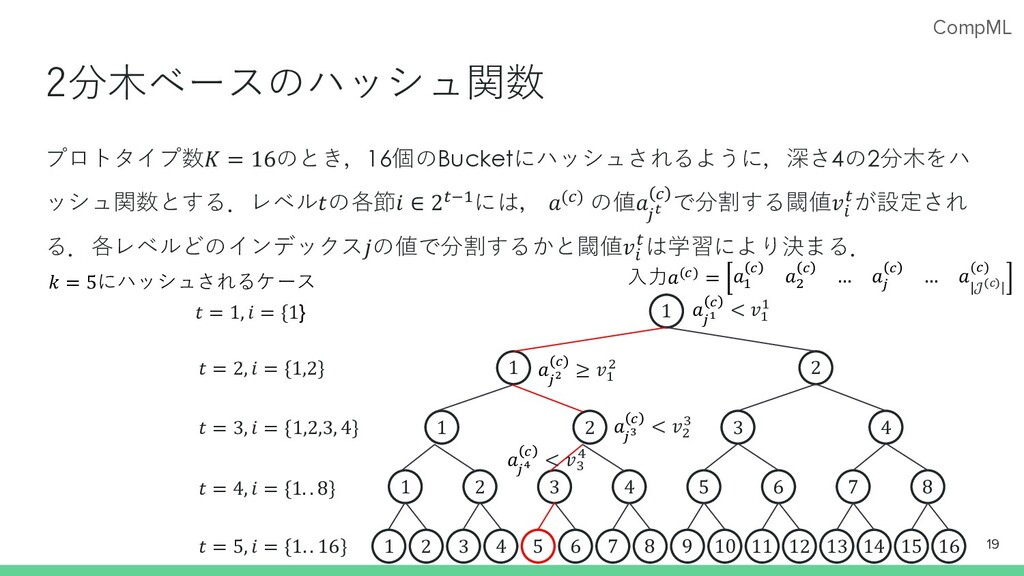
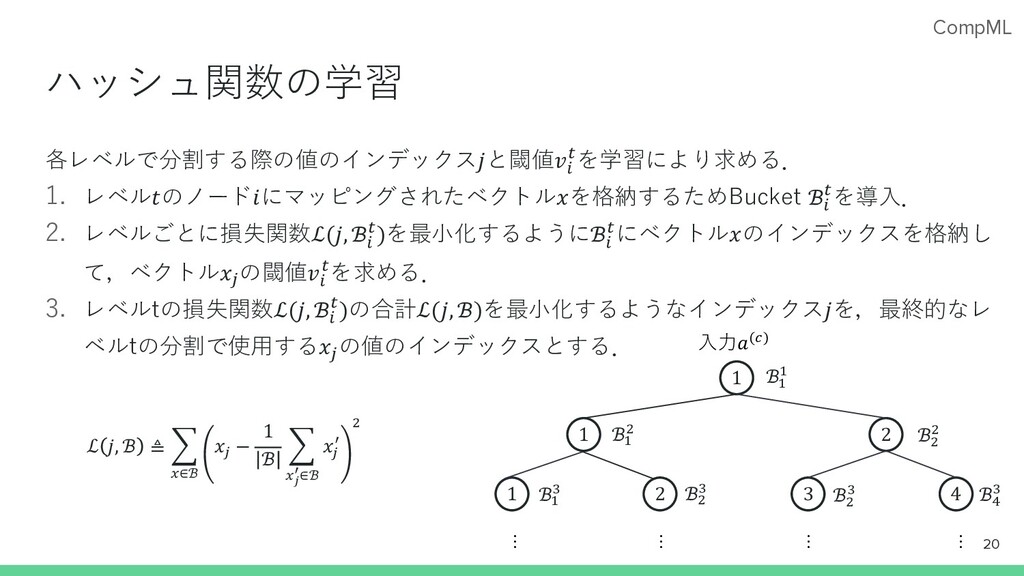
CompML 2分⽊ベースのハッシュ関数 プロトタイプ数𝐾 = 16のとき,16個のBucketにハッシュされるように,深さ4の2分⽊をハ ッシュ関数とする.レベル𝑡の各節𝑖 ∈ 2?@Aには, 𝑎(B) の値𝑎
C7 B で分割する閾値𝑣D ?が設定され る.各レベルどのインデックス𝑗の値で分割するかと閾値𝑣D ?は学習により決まる. 19 1 5 2 7 3 9 4 11 6 13 8 14 10 15 12 16 1 5 2 7 3 4 6 8 1 2 3 4 1 2 1 𝑎 2, / ≥ 𝑣( ) 𝑡 = 1, 𝑖 = {1} 𝑡 = 2, 𝑖 = {1,2} 𝑡 = 3, 𝑖 = {1,2,3, 4} 𝑡 = 4, 𝑖 = {1. . 8} 𝑡 = 5, 𝑖 = {1. . 16} ⼊⼒𝑎(/) = 𝑎( / 𝑎) / … 𝑎2 / … 𝑎 |𝒥 * | (/) 𝑎 2- / < 𝑣( ( 𝑘 = 5にハッシュされるケース 𝑎 2. / < 𝑣) * 𝑎 2/ / < 𝑣* 9
CompML ハッシュ関数の学習 各レベルで分割する際の値のインデックス𝑗と閾値𝑣D ?を学習により求める. 1. レベル𝑡のノード𝑖にマッピングされたベクトル𝑥を格納するためBucket ℬD ?を導⼊. 2. レベルごとに損失関数ℒ(𝑗,
ℬD ?)を最⼩化するようにℬD ?にベクトル𝑥のインデックスを格納し て,ベクトル𝑥C の閾値𝑣D ?を求める. 3. レベルtの損失関数ℒ(𝑗, ℬD ?)の合計ℒ(𝑗, ℬ)を最⼩化するようなインデックス𝑗を,最終的なレ ベルtの分割で使⽤する𝑥C の値のインデックスとする. 20 1 2 3 4 1 2 1 ⼊⼒𝑎(/) … … … … ℬ( ( ℬ( ) ℬ) ) ℬ( * ℬ) * ℬ) * ℬ9 * ℒ 𝑗, ℬ ≜ G :∈ℬ 𝑥2 − 1 ℬ G :0 1∈ℬ 𝑥2 < )
CompML ハッシュ関数の学習アルゴリズム xx 21
CompML プロトタイプの最適化 再構成した⾏列 : 𝐴の2乗誤差をさらに⼩さくするため,リッジ回帰によりプロトタイプ𝑃を最 適化する. 22 1 𝐴 ∈
ℝ!×# : 学習⾏列 𝐾: 部分空間ごとのプロトタイプ数 𝐶: 部分空間の数 𝑃 ∈ ℝ*)×# ∶ 各部分空間𝑐における𝐾個の学習されたプロトタイプで構成される⾏列 𝐺 ∈ ℝ!×*) : 1 𝐴 ≈ 𝐺𝑃となるように部分空間ごとにプロトタイプを選択するone-hotベクトルが格納された⾏列 𝑃 ≜ (𝐺I𝐺 + 𝜆𝐼)@A𝐺I : 𝐴
CompML 𝑓(𝑔(𝐴), ℎ(𝐵))の加算における課題 𝑓(𝑔(𝐴), ℎ(𝐵))の加算において正確な加算を⾏うためには,8bitで値が格納されているℎ(𝐵)か ら検索された各エントリを16bitにアップキャストしてから加算命令を⾏う必要がある. ⇨ オーバーヘッドの発⽣やスループットの半減 23 𝑓(𝑔
𝐴 , ℎ 𝐵 )J,K ≜ Q BLA M 𝑇K,B,N , 𝑘 = 𝑔 B (𝑎J ) 𝑇 ∈ ℝ2×)×* : ⾏列𝐵の全ての列の内積Lookup Table 𝑓(𝑔(𝐴), ℎ(𝐵))の加算
CompML ⾼速な8bit加算⼿法 加算命令ではなく,平均化命令を使⽤することで,若⼲の精度損失と引き換えに計算速度を 向上させる. 24 Pairwise Integer Sum and Sum
Estimator 𝑠 𝑎, 𝑏 ≜ 𝑎 + 𝑏 ̂ 𝑠 𝑎, 𝑏 ≜ 2𝜇 𝑎, 𝑏 𝑤ℎ𝑒𝑟𝑒 𝜇 𝑎, 𝑏 ≜ Z [ 1 2 (𝑎 + 𝑏 + 1)
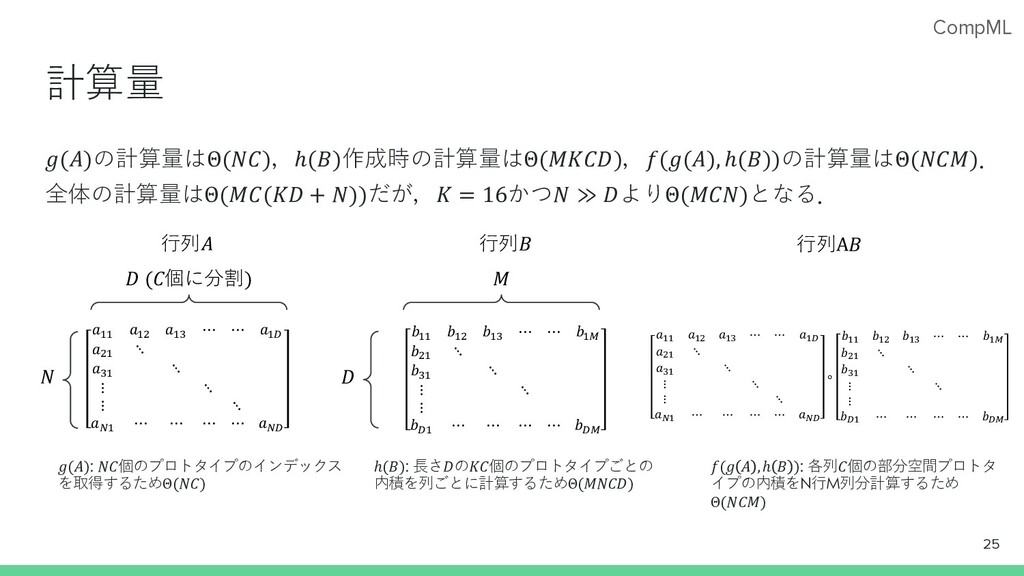
CompML 計算量 𝑔(𝐴)の計算量はΘ(𝑁𝐶),ℎ(𝐵)作成時の計算量はΘ(𝑀𝐾𝐶𝐷),𝑓(𝑔(𝐴), ℎ(𝐵))の計算量はΘ(𝑁𝐶𝑀). 全体の計算量はΘ(𝑀𝐶(𝐾𝐷 + 𝑁))だが,𝐾 = 16かつ𝑁 ≫
𝐷よりΘ(𝑀𝐶𝑁)となる. 25 𝑎!! 𝑎!" 𝑎!# ⋯ ⋯ 𝑎!$ 𝑎"! ⋱ 𝑎#! ⋱ ⋮ ⋱ ⋮ ⋱ 𝑎%! ⋯ ⋯ ⋯ ⋯ 𝑎%$ 𝑏!! 𝑏!" 𝑏!# ⋯ ⋯ 𝑏!& 𝑏"! ⋱ 𝑏#! ⋱ ⋮ ⋱ ⋮ 𝑏$! ⋯ ⋯ ⋯ ⋯ 𝑏$& ⾏列𝐴 ⾏列𝐵 𝑁 𝐷 (𝐶個に分割) 𝐷 𝑀 𝑔(𝐴): 𝑁𝐶個のプロトタイプのインデックス を取得するためΘ(𝑁𝐶) ℎ(𝐵): ⻑さ𝐷の𝐾𝐶個のプロトタイプごとの 内積を列ごとに計算するためΘ(𝑀𝑁𝐶𝐷) 𝑓(𝑔 𝐴 ,ℎ 𝐵 ): 各列𝐶個の部分空間プロトタ イプの内積をN⾏M列分計算するため Θ(𝑁𝐶𝑀) 𝑎$$ 𝑎$% 𝑎$& ⋯ ⋯ 𝑎$' 𝑎%$ ⋱ 𝑎&$ ⋱ ⋮ ⋱ ⋮ ⋱ 𝑎($ ⋯ ⋯ ⋯ ⋯ 𝑎(' ∘ 𝑏$$ 𝑏$% 𝑏$& ⋯ ⋯ 𝑏$) 𝑏%$ ⋱ 𝑏&$ ⋱ ⋮ ⋱ ⋮ 𝑏'$ ⋯ ⋯ ⋯ ⋯ 𝑏') ⾏列A𝐵
CompML 近似誤差の⼀般化保証 近似誤差に以下の上界を与える. 26 𝔼𝒟 ℒ(𝑎, 𝑏) ≤ 𝔼> !
ℒ 𝑎, 𝑏 + 𝐶?2 𝑏 ) 2 𝜆 1 256 + 8 + 𝜈(𝐶, 𝐷, 𝛿) 2𝑛 𝑤ℎ𝑒𝑟𝑒 ℒ 𝑎, 𝑏 ≜ 𝑎#𝑏 − 𝛼𝑓 𝑔 𝑎 , ℎ 𝑏 − 𝛽 , 𝛼 𝑖𝑠 𝑡ℎ𝑒 𝑠𝑐𝑎𝑙𝑒 𝑢𝑠𝑒𝑑 𝑓𝑜𝑟 𝑞𝑢𝑎𝑛𝑡𝑖𝑧𝑖𝑛𝑔 𝑡ℎ𝑒 𝑙𝑜𝑜𝑘𝑢𝑝 𝑡𝑎𝑏𝑙𝑒𝑠, 𝛽 𝑖𝑠 𝑡ℎ𝑒 𝑐𝑜𝑛𝑠𝑡𝑎𝑛𝑡𝑠 𝑢𝑠𝑒𝑑 𝑖𝑛 𝑞𝑢𝑎𝑛𝑡𝑖𝑧𝑖𝑛𝑔 𝑡ℎ𝑒 𝑙𝑜𝑜𝑘𝑢𝑝 𝑡𝑎𝑏𝑙𝑒𝑠 𝑝𝑙𝑢𝑠 𝑡ℎ𝑒 𝑑𝑒𝑏𝑖𝑎𝑠𝑖𝑛𝑔 𝑐𝑜𝑛𝑠𝑡𝑎𝑛𝑡 𝑓𝑜𝑟 𝑓𝑎𝑠𝑡 8𝑏𝑖𝑡 𝑎𝑔𝑔𝑟𝑒𝑔𝑎𝑡𝑖𝑜𝑛, 𝑎𝑛𝑑 𝜈 𝐶, 𝐷, 𝛿 ≜ 𝐶 4 log) 𝐷 + 256 log 2 − log 𝛿 𝐷: ℝ#に対する確率分布 1 𝐴 ∈ ℝ!×#: 各⾏がDから独⽴に得られた学習⾏列. 𝜎9 で最⼤特異値がバウンドされている. 𝐶: 部分空間の数 𝜆: 正則化パラメータ 𝛿: 0 < 𝛿 < 1の値
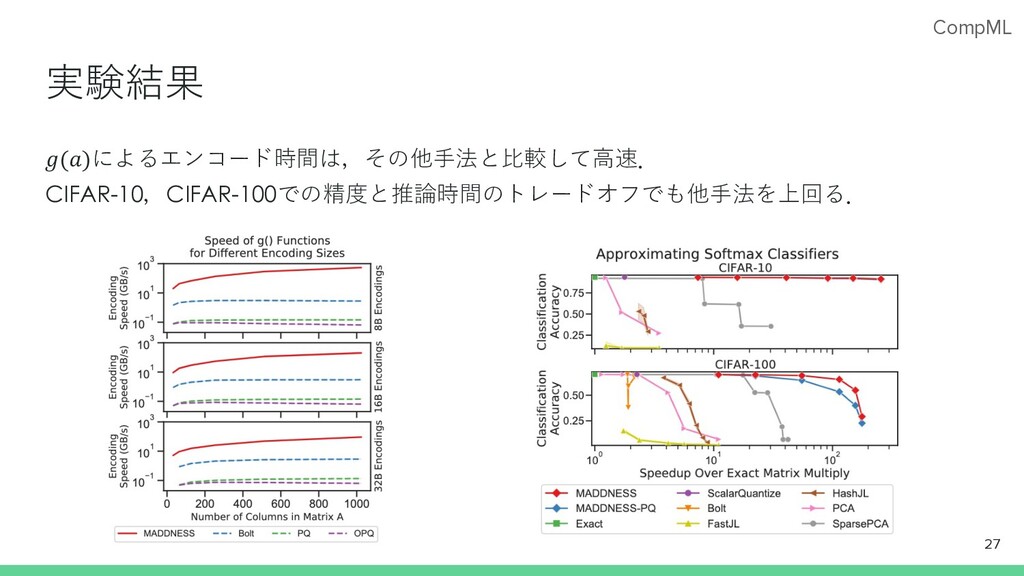
CompML 実験結果 𝑔(𝑎)によるエンコード時間は,その他⼿法と⽐較して⾼速. CIFAR-10,CIFAR-100での精度と推論時間のトレードオフでも他⼿法を上回る. 27
CompML まとめ(再掲) 28 • 計算時に乗算を⾏わない,近似⾏列乗算(Approximate Matrix Multiplication; AMM)の ⼿法であるMADDNESS※を提案. •
直積量⼦化(Product Quantization; PQ)と,その近似探索のハッシュ関数に学習した2 分⽊ハッシュ関数を⽤いたLocality Senstive Hashing(LSH)によって計算を⾼速化. • 素直な⾏列乗算よりも100倍⾼速,最新の近似⼿法よりも10倍⾼速. ※ Multiply-ADDitioN-lESS
CompML Reference
CompML 30 [1] Blalock, D., & Guttag, J. (2021). Multiplying
Matrices Without Multiplying. arXiv preprint arXiv:2106.10860. [2] Manne, S., & Pal, M. (2014). Fast approximate matrix multiplication by solving linear systems. arXiv preprint arXiv:1408.4230.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![CompML 30 [1] Blalock, D., & Guttag, J. (2021). Multiplying](https://files.speakerdeck.com/presentations/2226baa41f2a419398da76d012fd4ac1/slide_30.jpg){kind=link}