Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Monocular 3D Object Detection Survey
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
Hata Ryosuke
January 22, 2020
Research
510
3
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Monocular 3D Object Detection Survey
Survey for a kaggle competition: Peking University/Baidu - Autonomous Driving
Hata Ryosuke
January 22, 2020
More Decks by Hata Ryosuke
See All by Hata Ryosuke
関西Kaggler会 発表スライド
ryosukehata
1
1.3k
pytorchで機械学習しない
ryosukehata
3
1.1k
量子情報勉強会,量子ゲートについて
ryosukehata
0
250
Other Decks in Research
See All in Research
長時間動画QAにおけるマルチエージェント推論 ・SVAgent: Storyline-Guided Long Video Understanding via Cross-Modal Multi-Agent Collaboration
murakawatakuya
1
160
AY 2026 Guide to Academic Writing Using Generative AI - Workshop
ks91
PRO
0
130
コーディングエージェントとABNを再考
hf149
2
770
Data Visualization Tools in the Age of AI
flekschas
0
170
Anthropic が提案する LLM の内部状態を自然言語で説明可能にした Natural Language Autoencoders / Natural Language Autoencoders Produce Unsupervised Explanations of LLM Activations
shunk031
0
150
GLIM とMegaParticles:正規分布近似の限界とタイトカップリング&パーティクルフィルタの進展 / GLIM and MegaParticles : Progress of the distribution representation in SLAM
koide3
0
590
英語教育 “研究” のあり方:学術知とアウトリーチの緊張関係
terasawat
1
1k
LINEヤフー データサイエンス Meetup「三井物産コモディティ予測チャレンジ」の舞台裏-AlpacaTechパート
gamella
1
610
Sequences of Logits Reveal the Low Rank Structure of Language Models
sansantech
PRO
1
280
COFFEE-Japan PROJECT Impact Report(Uminomukou Coffee)
ontheslope
0
250
Research Engineerという仕事 / Research Engineering: Bridging Research and Business
chck
1
230
機械学習で作った ポケモン対戦bot で 遊ぼう!
fufufukakaka
0
360
Featured
See All Featured
How STYLIGHT went responsive
nonsquared
100
6.2k
Writing Fast Ruby
sferik
630
63k
More Than Pixels: Becoming A User Experience Designer
marktimemedia
3
460
Why Your Marketing Sucks and What You Can Do About It - Sophie Logan
marketingsoph
0
280
Applied NLP in the Age of Generative AI
inesmontani
PRO
4
2.4k
16th Malabo Montpellier Forum Presentation
akademiya2063
PRO
0
250
Marketing to machines
jonoalderson
1
5.6k
Self-Hosted WebAssembly Runtime for Runtime-Neutral Checkpoint/Restore in Edge–Cloud Continuum
chikuwait
0
650
The browser strikes back
jonoalderson
0
1.4k
Taking LLMs out of the black box: A practical guide to human-in-the-loop distillation
inesmontani
PRO
3
2.3k
I Don’t Have Time: Getting Over the Fear to Launch Your Podcast
jcasabona
34
2.8k
[Rails World 2023 - Day 1 Closing Keynote] - The Magic of Rails
eileencodes
38
2.9k
Transcript
Monocular 3D Object Detection Survey 畑 遼介
Summary ・CAD modelを使わないもの[1, 2] End to Endで学習が可能。(OFTNet) ・CAD modelを使う[3, 4,
5, 6, 7] 1 Stage: Mask-RCNN, RoIを作成 2 Stage: RoIから三次元情報を作成 論文中よく使われているのはFaster R-CNNだが, ここから最後までやるのはつらそう。
[1] Orthographic Feature Transform for Monocular 3D Object Detection 2018/11
https://arxiv.org/abs/1811.08188
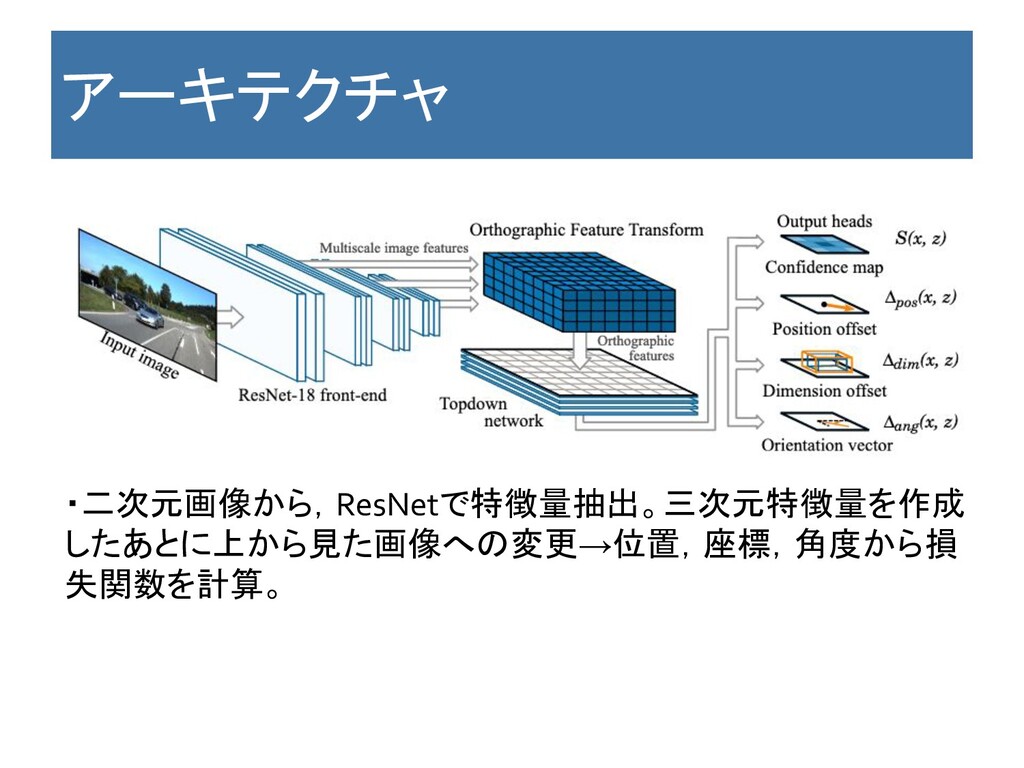
Key Point 特徴 ・二次元画像から,三次元の特徴量を作り,上から見た図を作成し, 位置推定などを行う。 ・三次元の特徴量を作成する際に奥行き推定はしない。 ・物体の中心のNMSをする。 ・CenterNetと似たようなpipeline。 利点 ・EndToEnd ・Githubにコードがある。
・論文の参考値に必ず出てくるので実績がある。 欠点 ・奥行き推定がないので,重なっているObjectの部分は共有される。 →深さ推定すれば精度はあがる? ・CADを使わない。 コメント:今回のタスク的に, CenterNetとアンサンブルしても良いかもしれない。
アーキテクチャ ・二次元画像から,ResNetで特徴量抽出。三次元特徴量を作成 したあとに上から見た画像への変更→位置,座標,角度から損 失関数を計算。
[2] SHIFT R-CNN: DEEP MONOCULAR 3D OBJECT DETECTION WITH CLOSED-FROM
GEOMETRIC CONSTRAINTS 2019/03 https://arxiv.org/abs/1905.09970
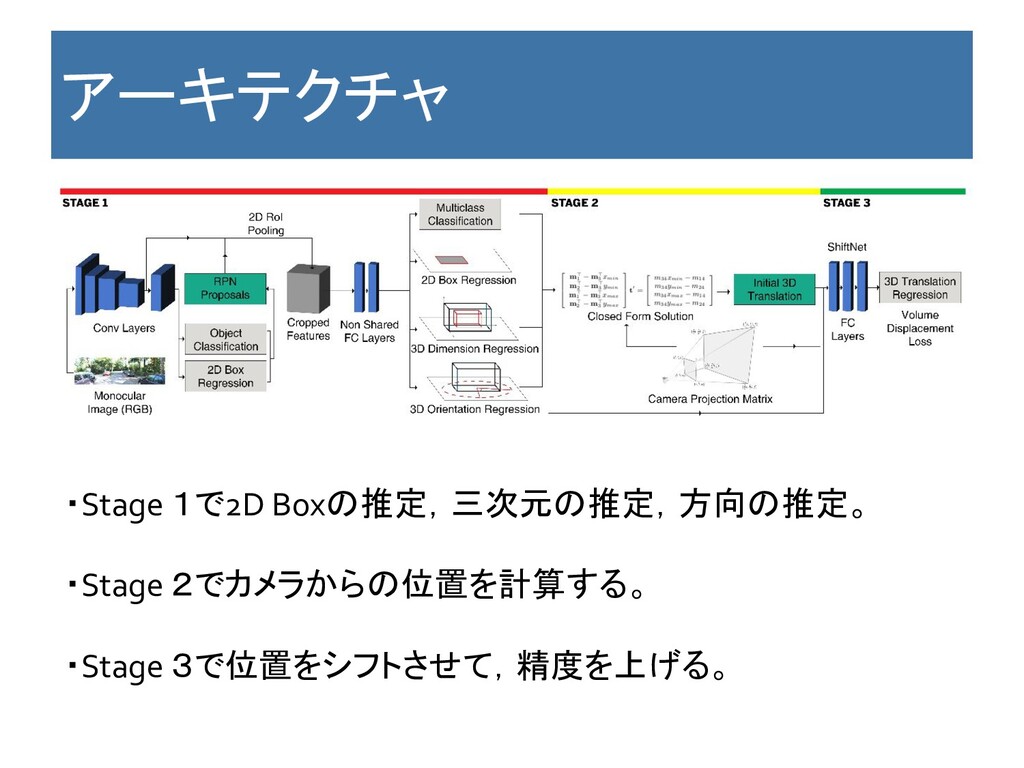
Key Point 特徴 ・RoIAlignedを使って,3次元位置推定をする。 ・三次元Bounding Boxを作って,車の位置tを算出する。 ・その後,Bouding Boxや位置情報を三層のNNに入れて位置を改善 する(ShiftNet)。 利点
・最後のShitNetはどのアーキテクチャーでも使えるだろう。 欠点 ・End to Endではない。 RoIAlignedを使う時点でR-CNNのアーキテク チャは使っている。 ・CADを使わない。 コメント:わざわざ読まなくても良いと思う。
アーキテクチャ ・Stage 1で2D Boxの推定,三次元の推定,方向の推定。 ・Stage 2でカメラからの位置を計算する。 ・Stage 3で位置をシフトさせて,精度を上げる。
[3] Deep MANT: A Coarse-to-fine Many-Task Network for joint 2D
and 3D vehicle analysis from monocular image 2017/3 https://arxiv.org/abs/1703.07570
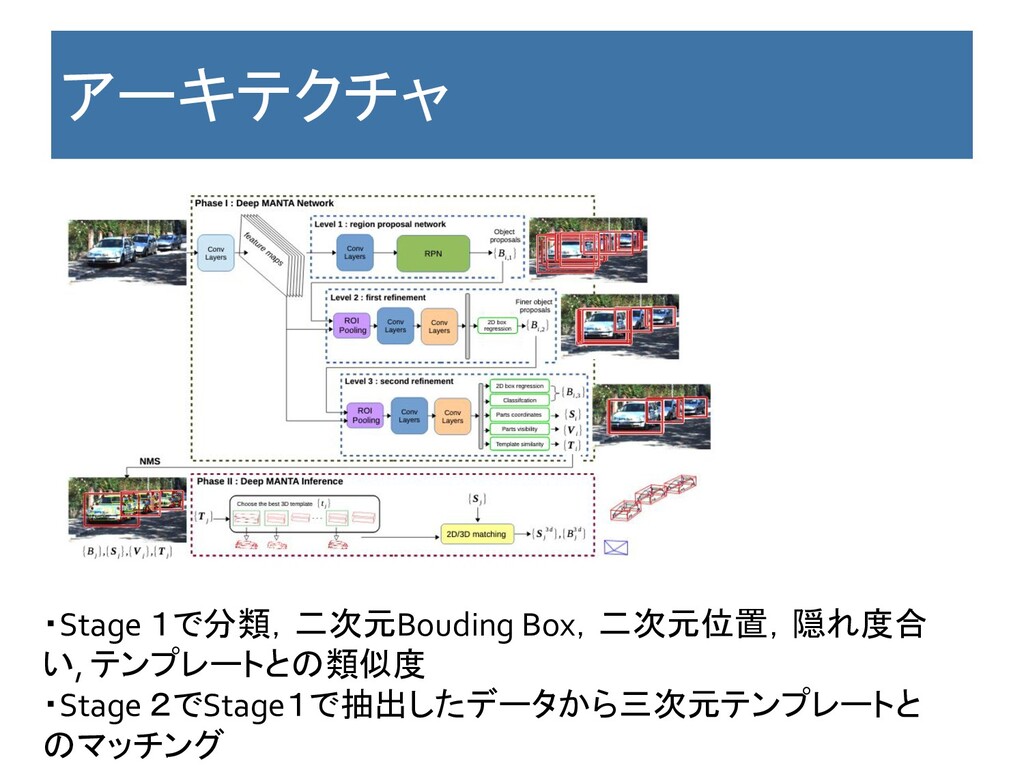
Key Point 特徴 ・二次元データから特徴点を抽出して三次元データとマッチさせるは じめの論文。 ・車は特徴的な形状をしているので,三次元データへと再現ができる と提言している。 利点 ・CADを使う。 欠点
・End to Endではない。Cascaded R-CNNのアーキテクチャを使って二 次元特徴量を出している。 ・三次元のテンプレートマッチングのやり方が不明。 コメント:精度はそこまで出ているわけではないので読まなくてもいい と思う。
アーキテクチャ ・Stage 1で分類,二次元Bouding Box,二次元位置,隠れ度合 い, テンプレートとの類似度 ・Stage 2でStage1で抽出したデータから三次元テンプレートと のマッチング
[4] 3D-RCNN: Instance-level 3D Object Reconstruction via Render-and-Compose 2018 http://abhijitkundu.info/projects/3D-RCNN/
CVPR 2018
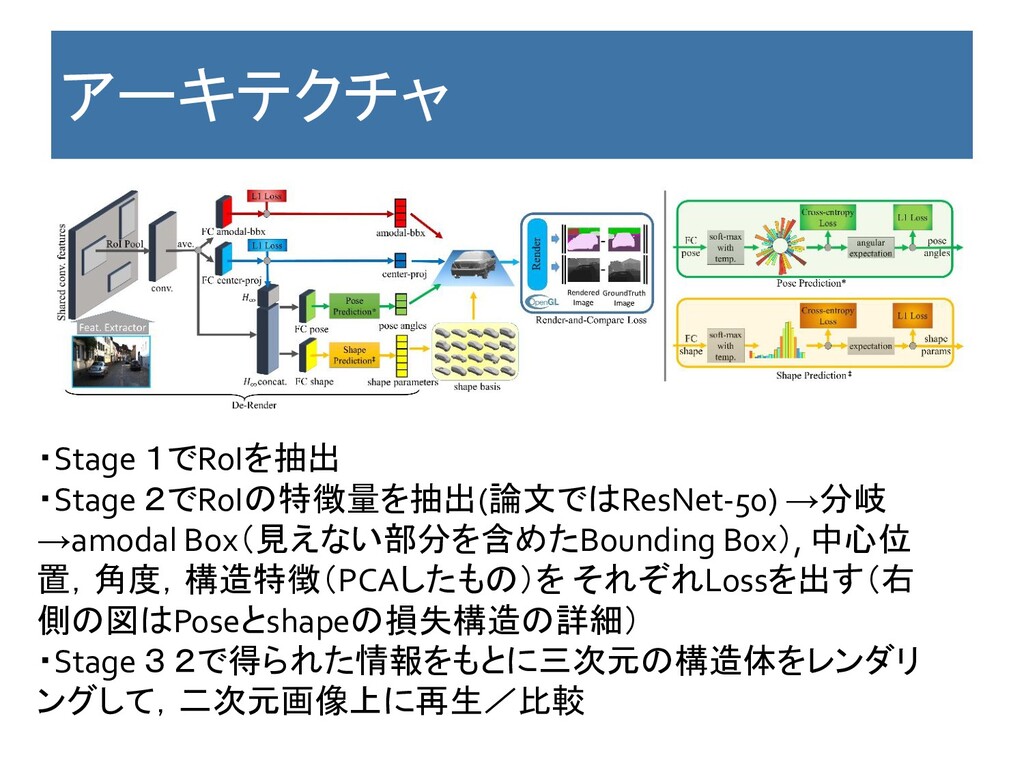
Key Point 特徴 ・RoIから特徴量抽出→分岐させてregression ・分岐の中身はamodal Box(見えない部分を含めたBounding Box), 中心位置,角度 ,3D CADをPCAで10次元に圧縮したもの。
・上の情報を使って三次元画像をレンダリング,二次元上に再生して,マスターと比 較。 利点 ・CADを使う。精度は出そう。 欠点 ・End to Endではない。 ・pipelineをすべて動かそうと思うと,R−CNNスタートで間にOpenGLを 使うことがあるので,手間がすごそう。 コメント:3D CADをPCAするアイデアは使えそう。 ただし,すべてのpipelineを通すとなると辛そう。
アーキテクチャ ・Stage 1でRoIを抽出 ・Stage 2でRoIの特徴量を抽出(論文ではResNet-50) →分岐 →amodal Box(見えない部分を含めたBounding Box),
中心位 置,角度,構造特徴(PCAしたもの)を それぞれLossを出す(右 側の図はPoseとshapeの損失構造の詳細) ・Stage 3 2で得られた情報をもとに三次元の構造体をレンダリ ングして,二次元画像上に再生/比較
[5] Mono3D++: Monocular 3D Vehicle Detection with Two-Scale 3D Hypotheses
and Task Priors 2019/1 https://arxiv.org/abs/1901.03446
Key Point 特徴 ・SSDの特徴量から2次元擬推定,3次元Bounding Box, WireFrameに よる推定によるJointで最終的にrobostな3次元位置推定。(別の車に 隠れている車があるので,より頑健にしたい) ・Loss function周りや,3次元推定の数式の説明が丁寧。
利点 ・SSDでやってるので,理屈の上ではEnd to End 欠点 ・実験は2次元Bounding Boxを出すのに一週間,その後の処理が2 時間とか書かれているので,End to Endとは言い難い。 ・数式を追うのが結構しんどい。 コメント:数式を読んで実装することを考えると参考にはならなさそう。 精読するならば読み応えありそう。
アーキテクチャ ・SSDに似たアーキテクチャーで2次元Bounding Boxを抽出。 ・その後,二次元のワイヤフレームを作っているものと,3次元 Bounding Boxとwireframe shape modelとマッチ。 ・ロスを読む限り,一つずつ3次元データとマッチさせている。
[6] Monocular 3D Object Detection via Geometric Reasoning on Keypoints
2019/5 https://arxiv.org/abs/1905.05618
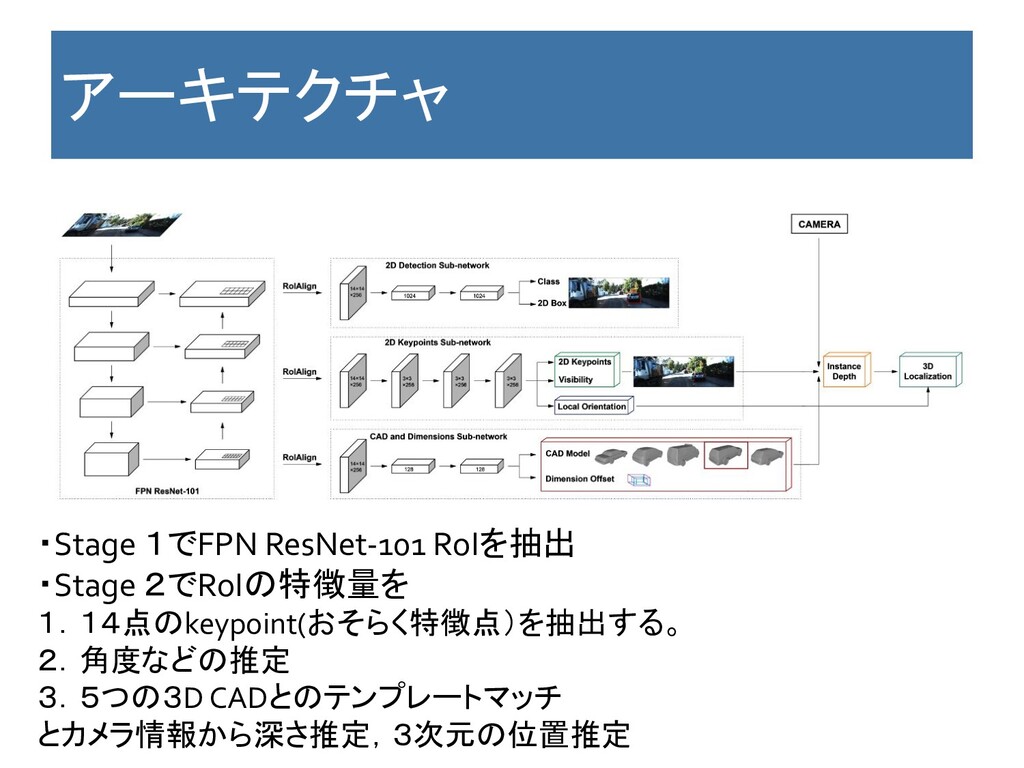
Key Point 特徴 ・Mask R-CNNを通したあとの2次元Bounding Boxの特徴量から1. 14点のkeypoint(おそらく特徴点)を抽出 2.角度などの推定 3.5つの3D CADとのテンプレートマッチ
する。 ・1➖3の特徴量から深さ推定して,位置を特定する。 利点 ・CADの一部を使う。 欠点 ・多分。End to Endではない コメント:使っているCADがセダンやミニバンなどの特徴的な車の5種 だったので途中で読むのをやめた。あまり有用ではないと思う。
アーキテクチャ ・Stage 1でFPN ResNet-101 RoIを抽出 ・Stage 2でRoIの特徴量を 1.14点のkeypoint(おそらく特徴点)を抽出する。 2.角度などの推定 3.5つの3D
CADとのテンプレートマッチ とカメラ情報から深さ推定,3次元の位置推定
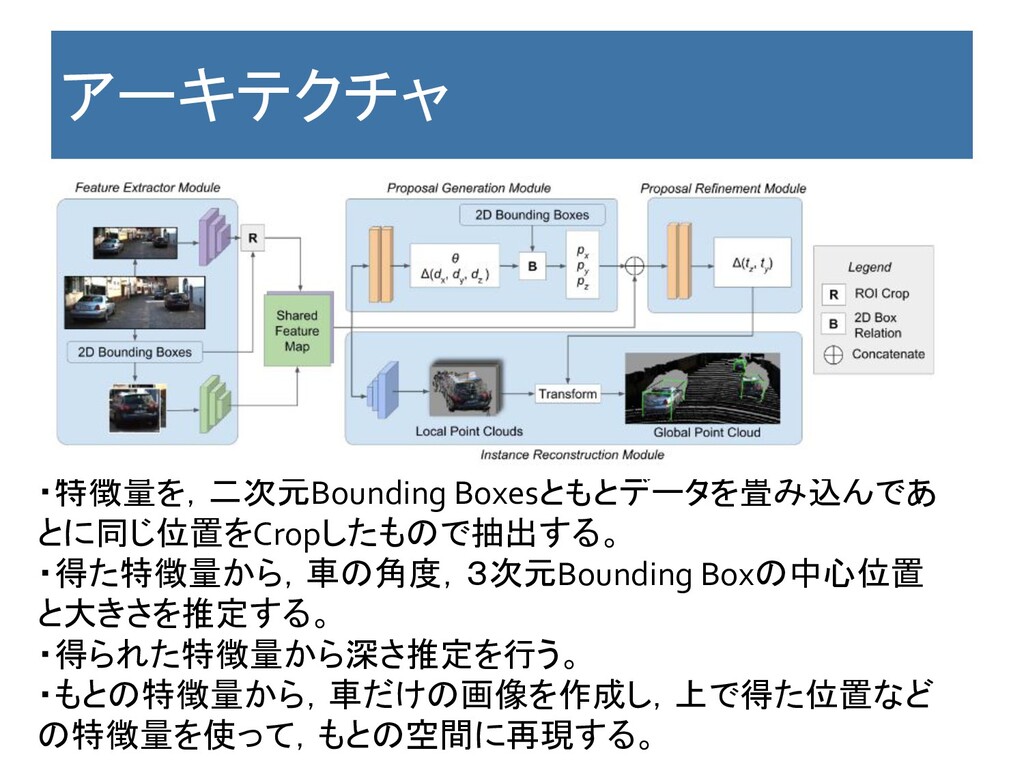
[7] Monocular 3D Object Detection Leveraging Accurate Proposals and Shape
Reconstruction 2019/4 https://arxiv.org/abs/1904.01690 CVPR 2019
Key Point 特徴 ・2次元画像だけから,3次元位置を含んだ絵を作成することを目的 にした論文。 ・その過程で位置推定を行っている。 利点 ・実用上CADデータがない場合もあるので,そのときにも使える。 欠点 ・コンペ的にはCADは与えられているので,使わないことは欠点
コメント:Feature Mapの作り方は参考になりそうだが,研究内容が現 在のコンペの目的を超えているためすべての実装はいらない。技術 的には面白そう。
アーキテクチャ ・特徴量を,二次元Bounding Boxesともとデータを畳み込んであ とに同じ位置をCropしたもので抽出する。 ・得た特徴量から,車の角度,3次元Bounding Boxの中心位置 と大きさを推定する。 ・得られた特徴量から深さ推定を行う。 ・もとの特徴量から,車だけの画像を作成し,上で得た位置など の特徴量を使って,もとの空間に再現する。
{kind=link}
![Summary ・CAD modelを使わないもの[1, 2] End to Endで学習が可能。(OFTNet) ・CAD modelを使う[3, 4,](https://files.speakerdeck.com/presentations/c73ea83ec92a47428a709c37a6f108ad/slide_1.jpg){kind=link}
![[1] Orthographic Feature Transform for Monocular 3D Object Detection 2018/11](https://files.speakerdeck.com/presentations/c73ea83ec92a47428a709c37a6f108ad/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
![[2] SHIFT R-CNN: DEEP MONOCULAR 3D OBJECT DETECTION WITH CLOSED-FROM](https://files.speakerdeck.com/presentations/c73ea83ec92a47428a709c37a6f108ad/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
![[3] Deep MANT: A Coarse-to-fine Many-Task Network for joint 2D](https://files.speakerdeck.com/presentations/c73ea83ec92a47428a709c37a6f108ad/slide_8.jpg){kind=link}
{kind=link}
{kind=link}
![[4] 3D-RCNN: Instance-level 3D Object Reconstruction via Render-and-Compose 2018 http://abhijitkundu.info/projects/3D-RCNN/](https://files.speakerdeck.com/presentations/c73ea83ec92a47428a709c37a6f108ad/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
![[5] Mono3D++: Monocular 3D Vehicle Detection with Two-Scale 3D Hypotheses](https://files.speakerdeck.com/presentations/c73ea83ec92a47428a709c37a6f108ad/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
![[6] Monocular 3D Object Detection via Geometric Reasoning on Keypoints](https://files.speakerdeck.com/presentations/c73ea83ec92a47428a709c37a6f108ad/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
![[7] Monocular 3D Object Detection Leveraging Accurate Proposals and Shape](https://files.speakerdeck.com/presentations/c73ea83ec92a47428a709c37a6f108ad/slide_20.jpg){kind=link}
{kind=link}
{kind=link}