EuroPython 2015 Talk
You need to download data from lots and lots of URLs stored in a text file and then save them on your machine. Sure, you could write a loop and get each URL in sequence, but imagine that there are so many URLs that the sun may burn out before that loop is finished; or, you’re just too impatient.
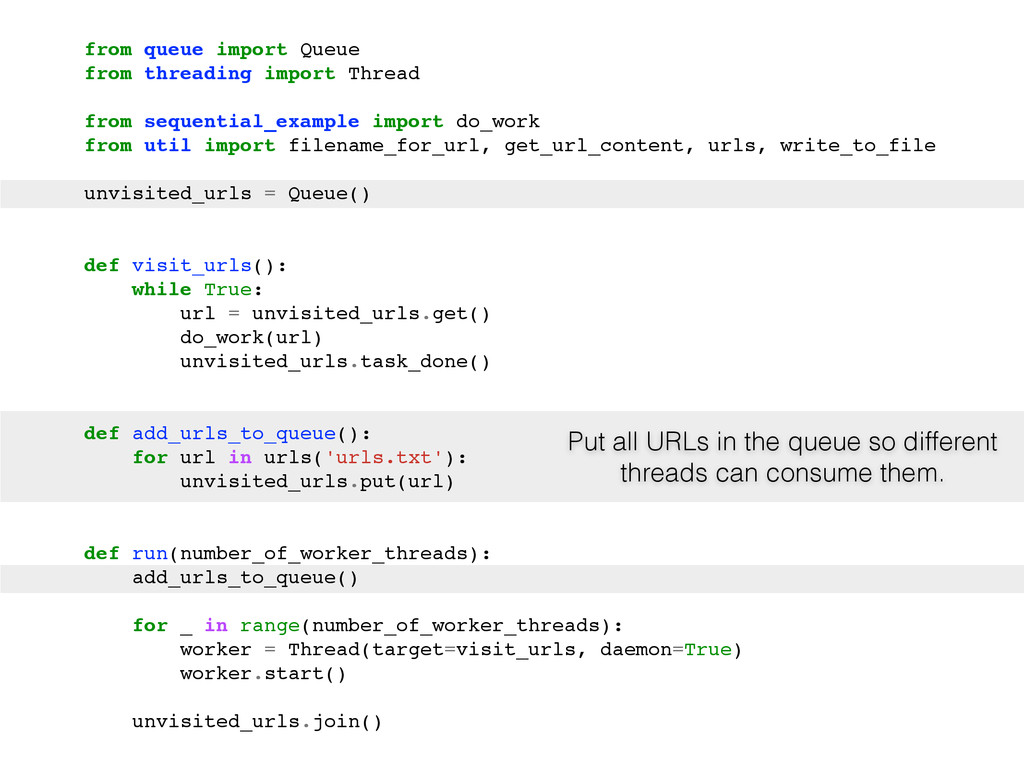
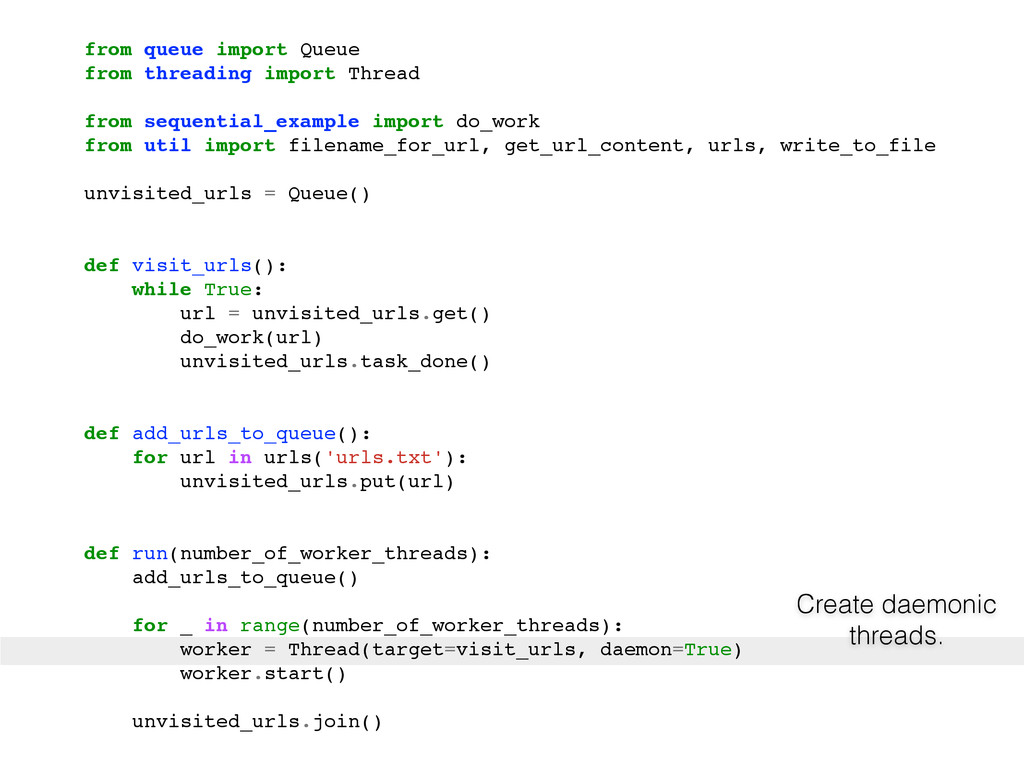
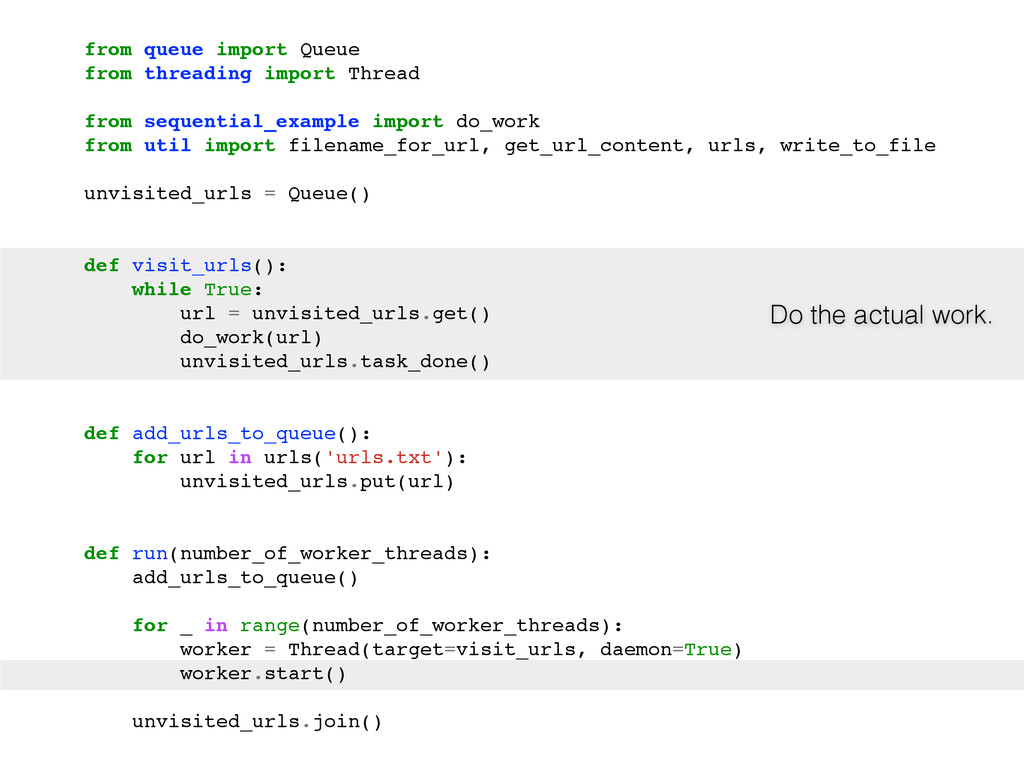
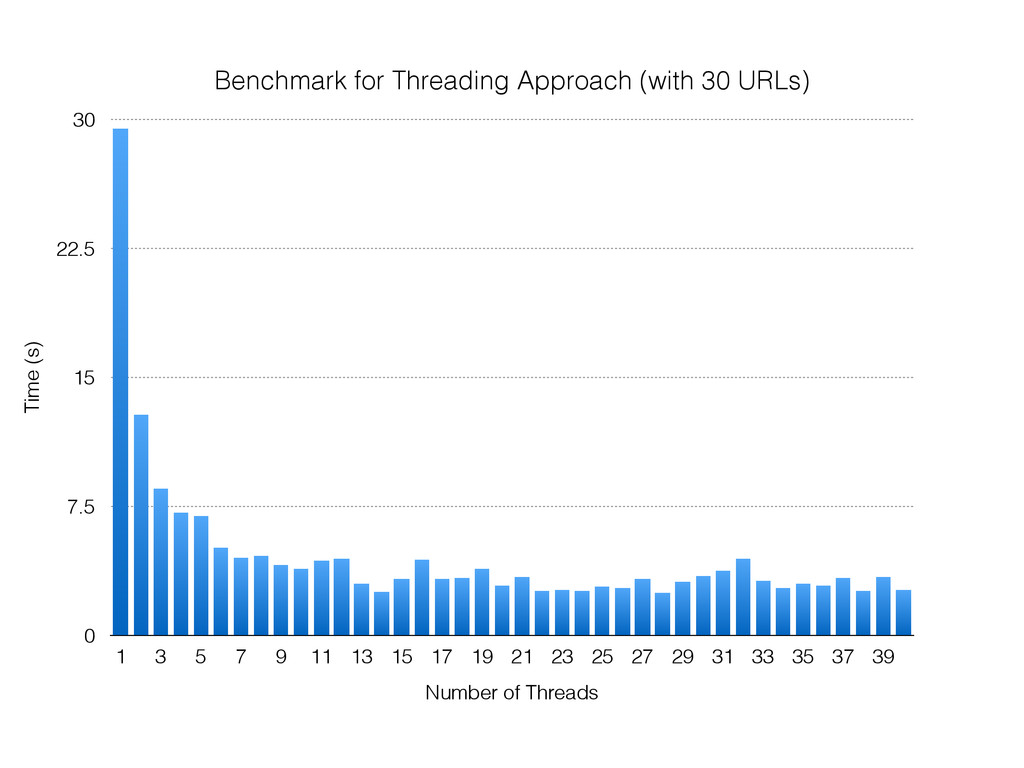
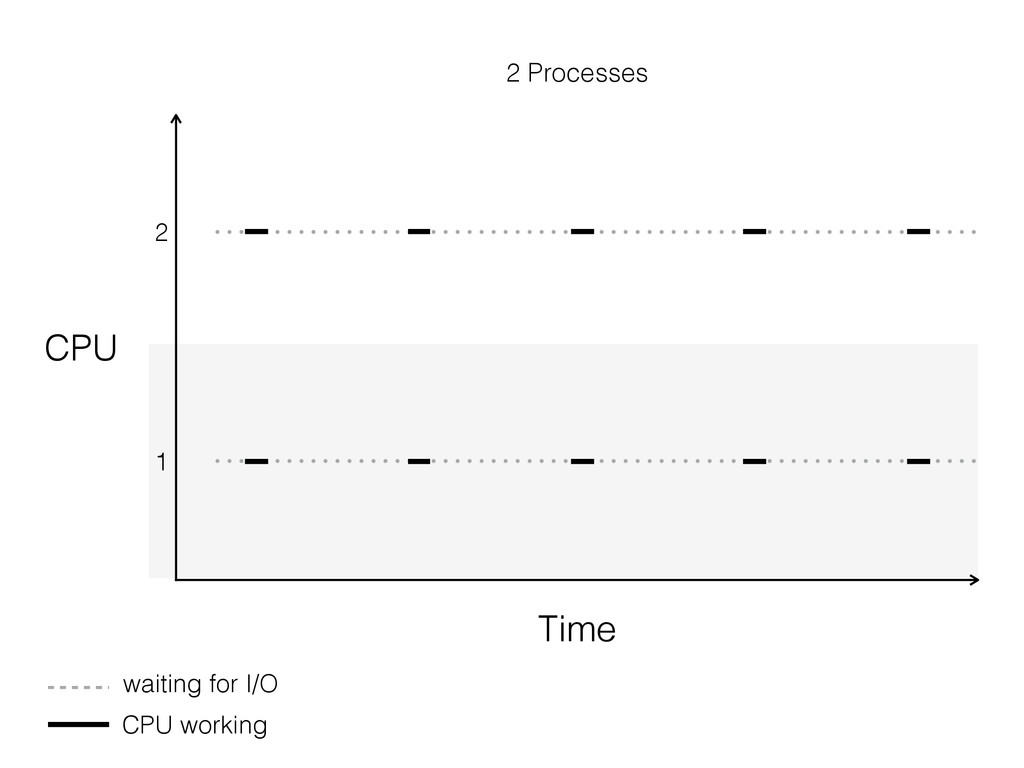
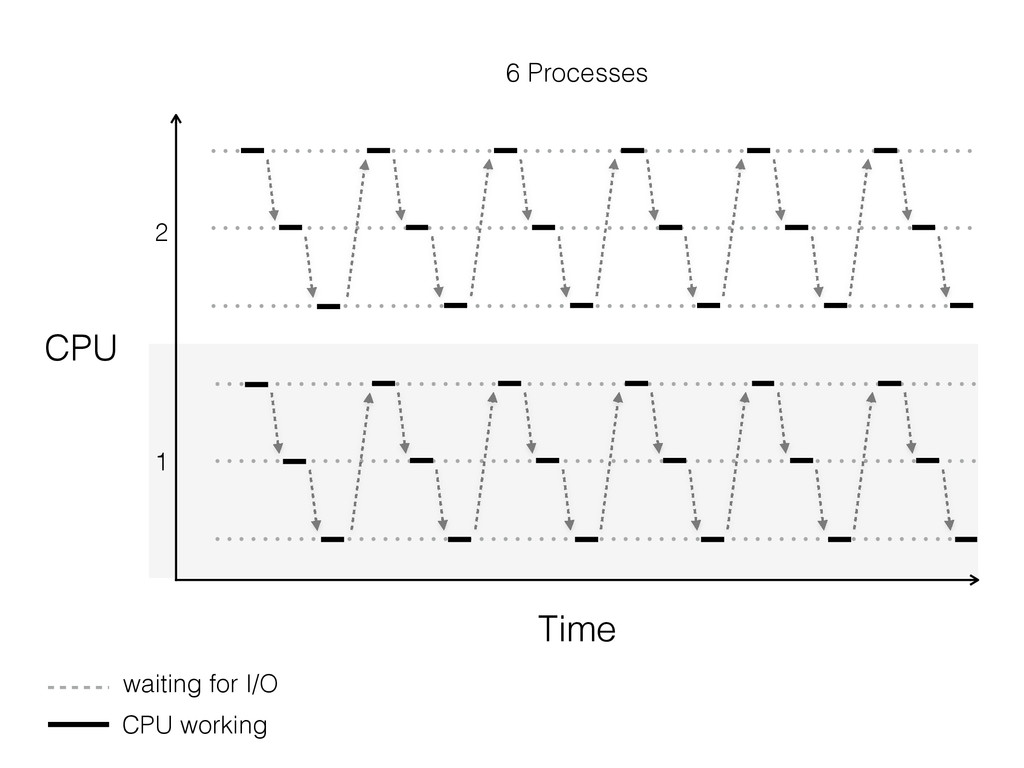
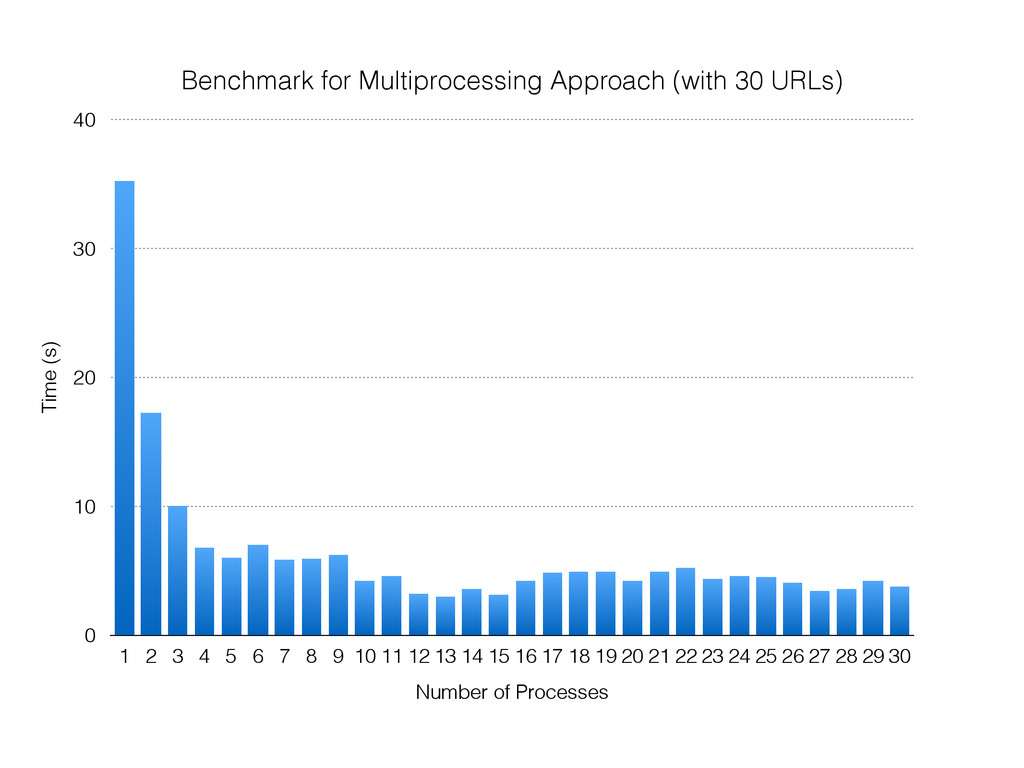
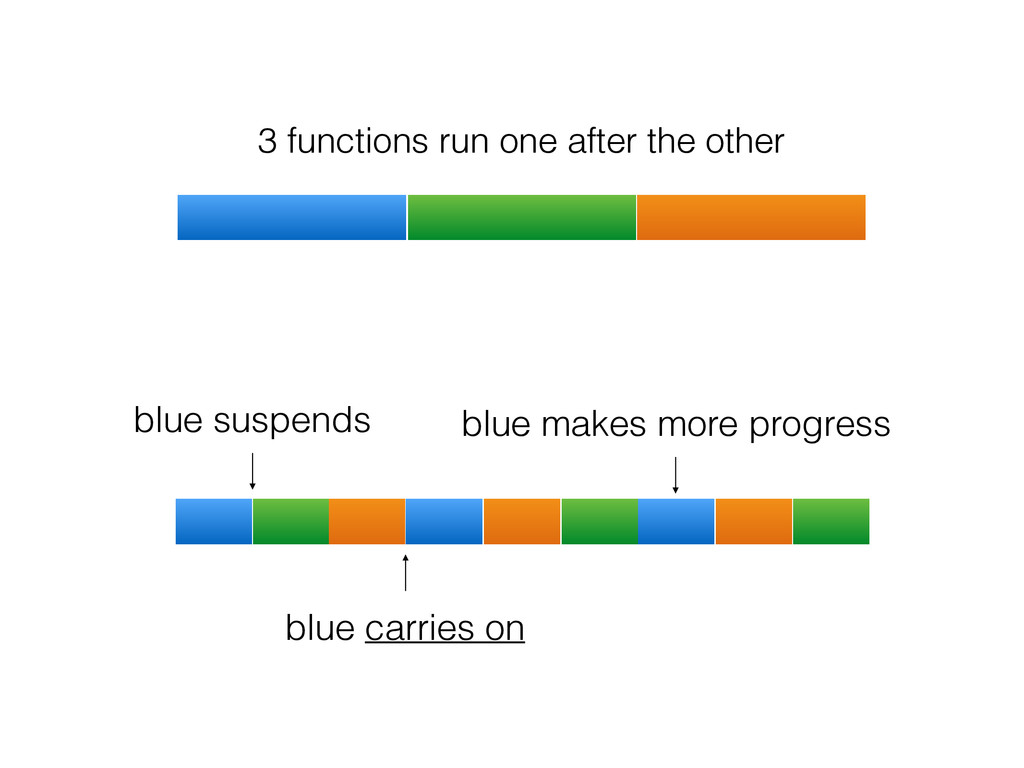
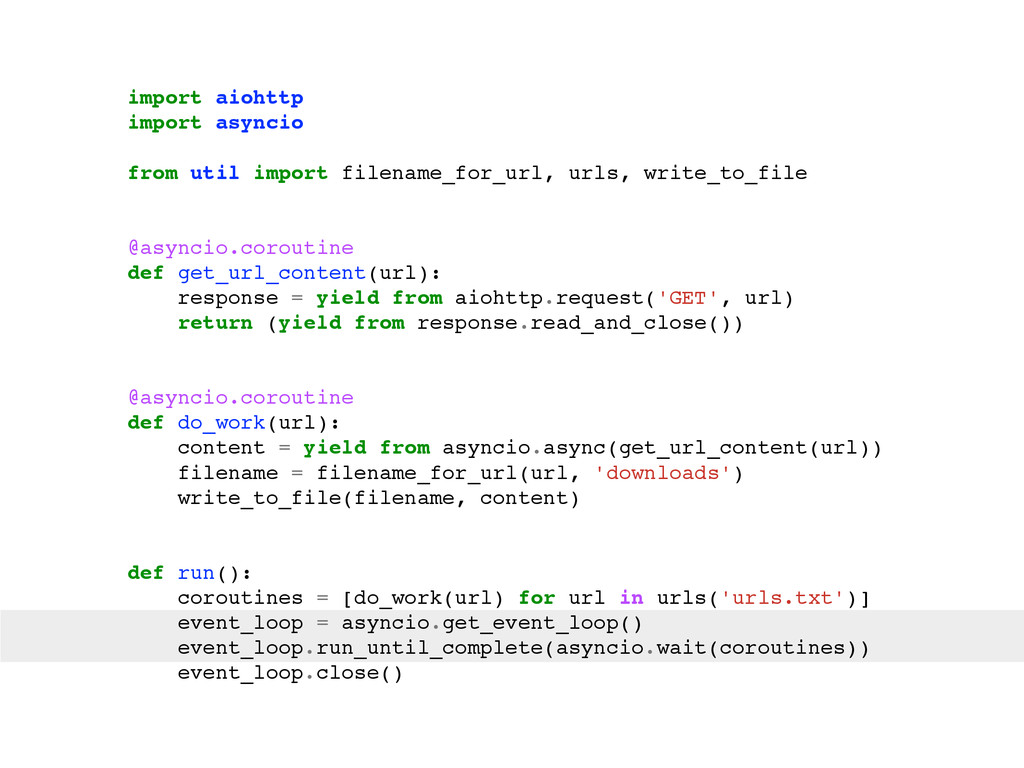
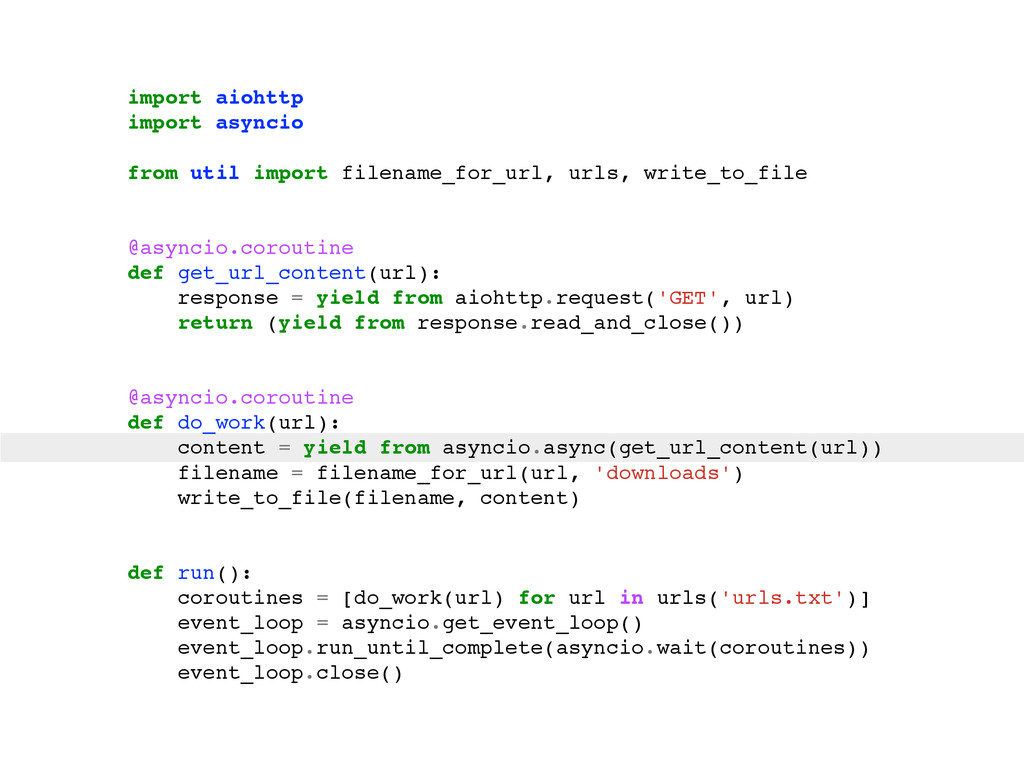
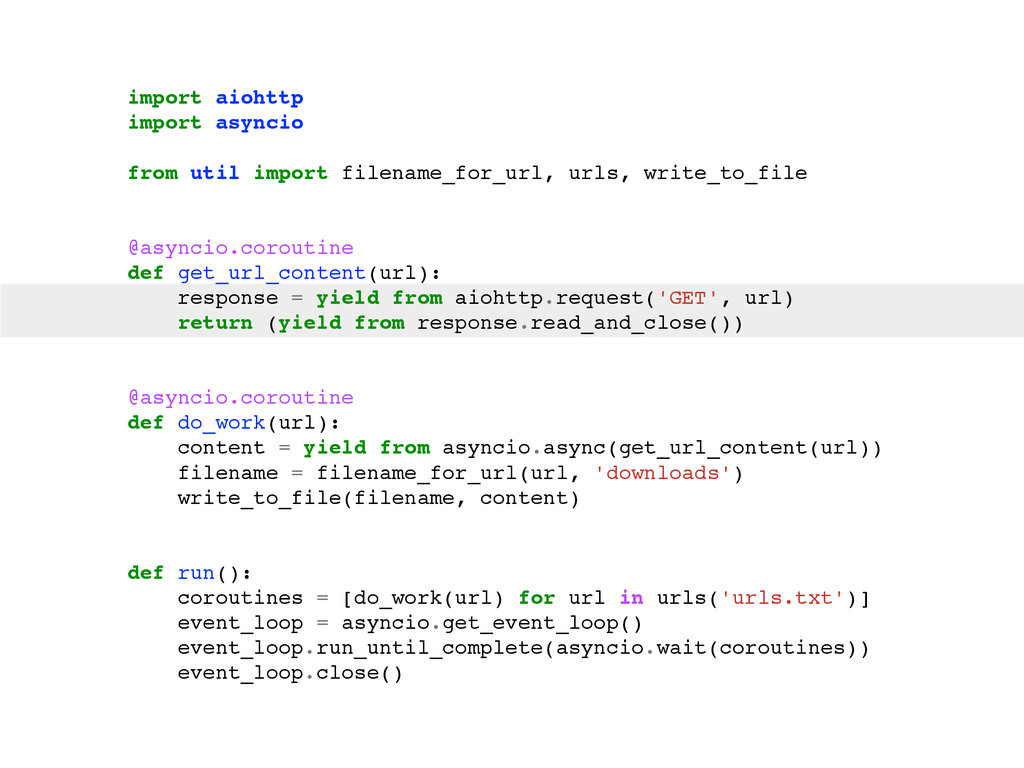
For the sake of making this instructive, pretend you can only use one box. So, what do you do? Here are some typical solutions: Use a single process that creates lots of threads. Use many processes. Use a single process and a library like asyncio, gevent or eventlet to yield between coroutines when the OS blocks on IO.
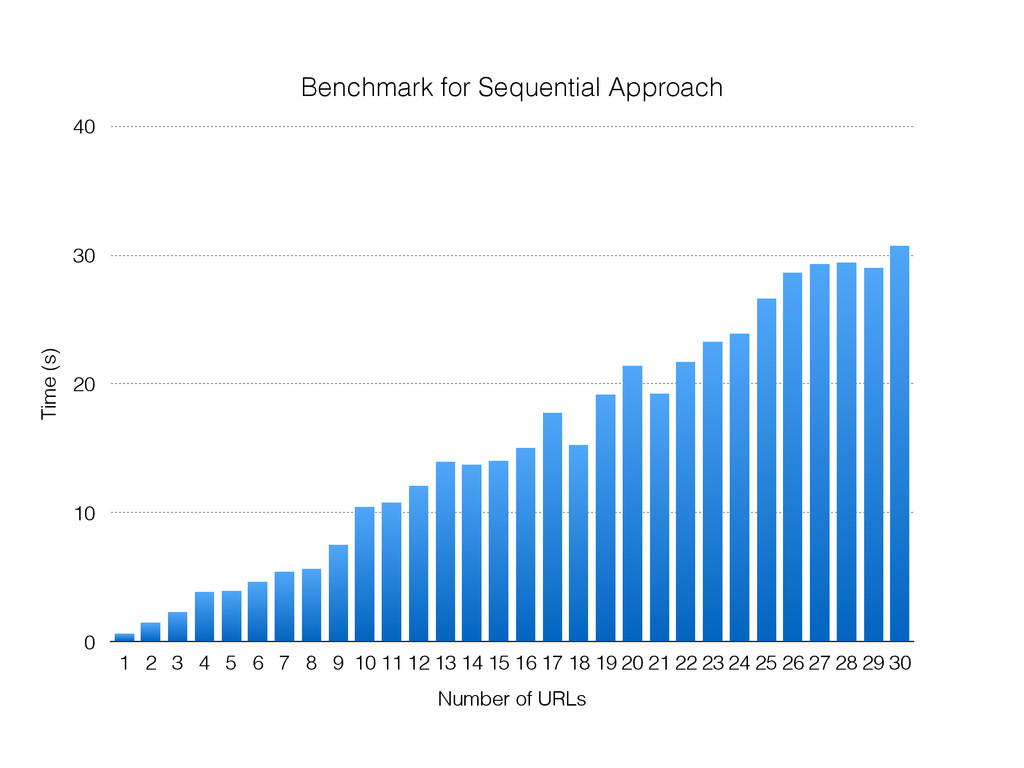
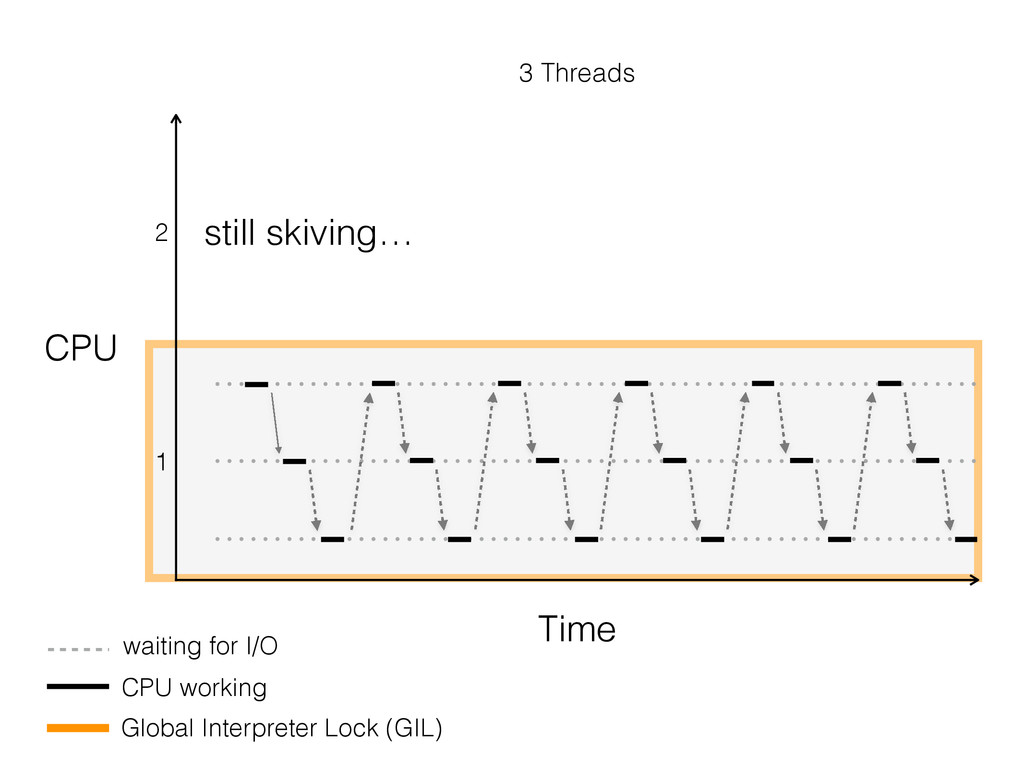
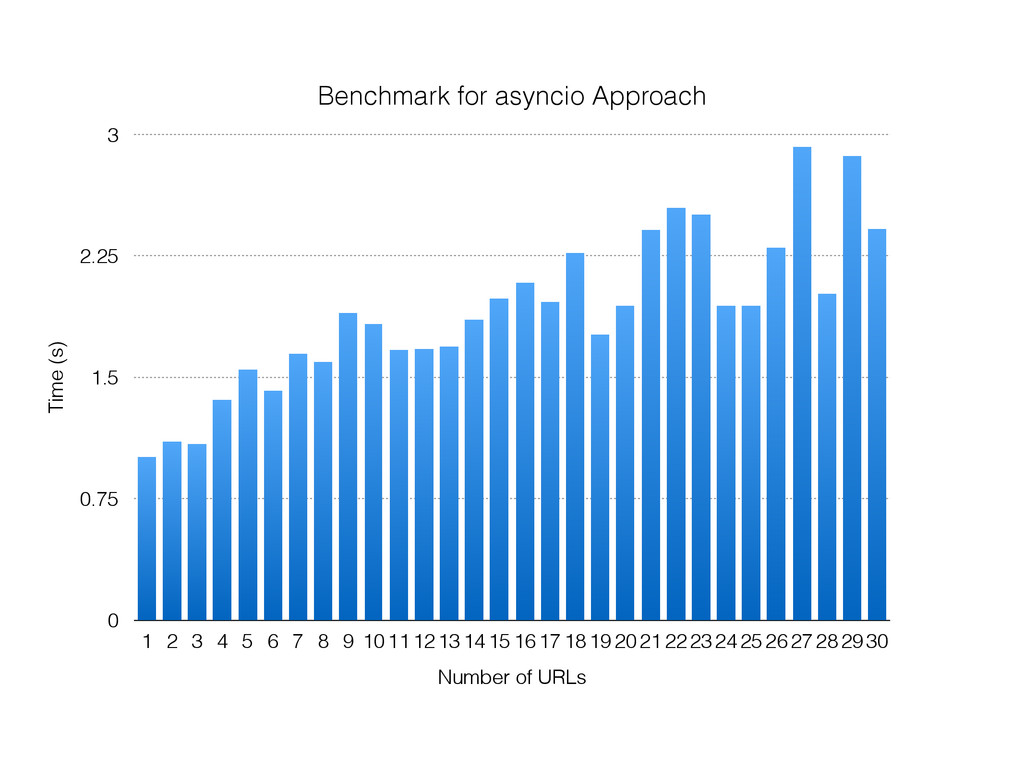
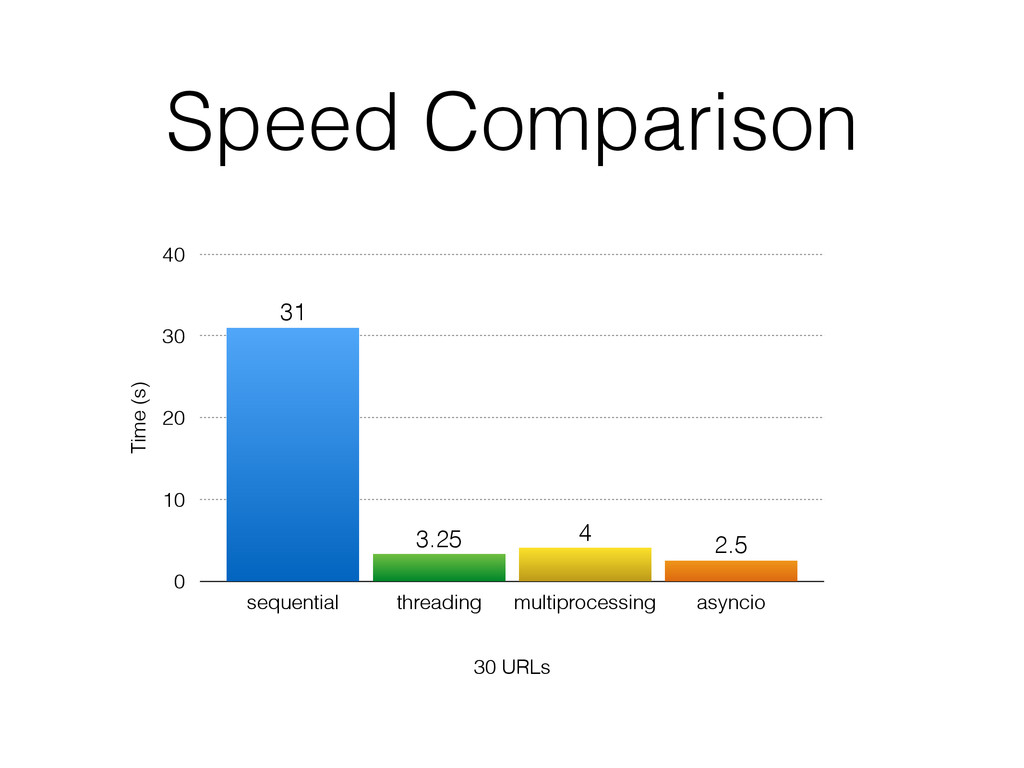
The talk will walk through the mechanics of each approach, and then show benchmarks of the three different approaches.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}