Text Recognition Model Comparisons? Dataset and Model Analysis,” in Proc. ICCV, 2019, pp. 4714–4722. [Chen+ 2020] Chen et al., “A Simple Framework for Contrastive Learning of Visual Representations,” in Proc. ICML, PMLR 119, 2020, pp. 1597–1607. [Aberdam+ 2021] Aberdam et al., “Sequence-to-Sequence Contrastive Learning for Text Recognition,” in Proc. CVPR, 2021, pp. 15302–15312. [Chen+ 2021] Chen et al., “Benchmarking Chinese Text Recognition: Datasets, Baselines, and an Empirical Study,” arXiv:2112.15093, 2021. [He+ 2022] He et al., “Masked Autoencoders Are Scalable Vision Learners,” in Proc. CVPR, 2022, pp. 16000–16009. [Yang+ 2022] Yang et al., “Reading and Writing: Discriminative and Generative Modeling for Self-Supervised Text Recognition,” in Proc. ACM MM, 2022, pp. 4214–4223. 参考文献
{kind=link}
{kind=link}
{kind=link}
{kind=link}
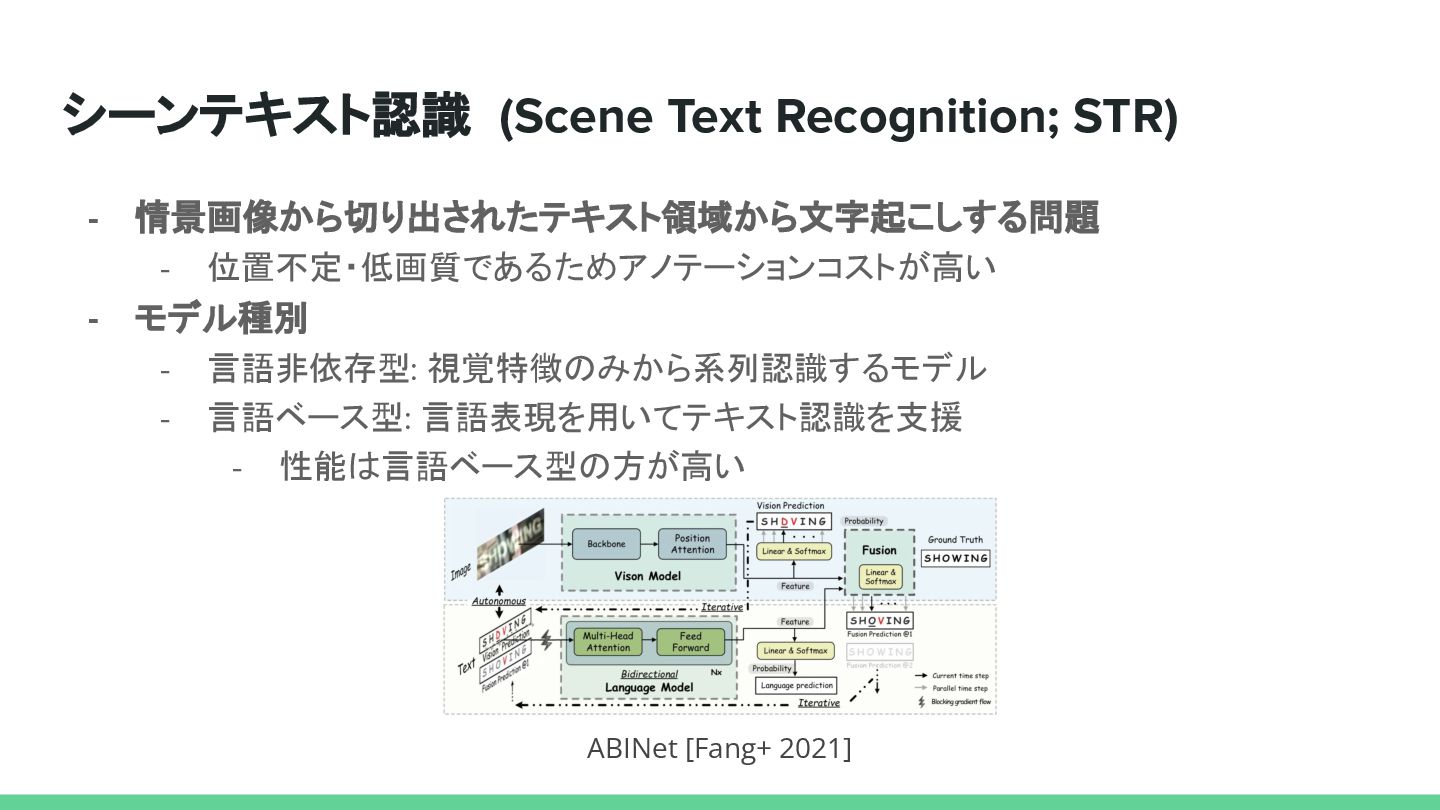{kind=link}
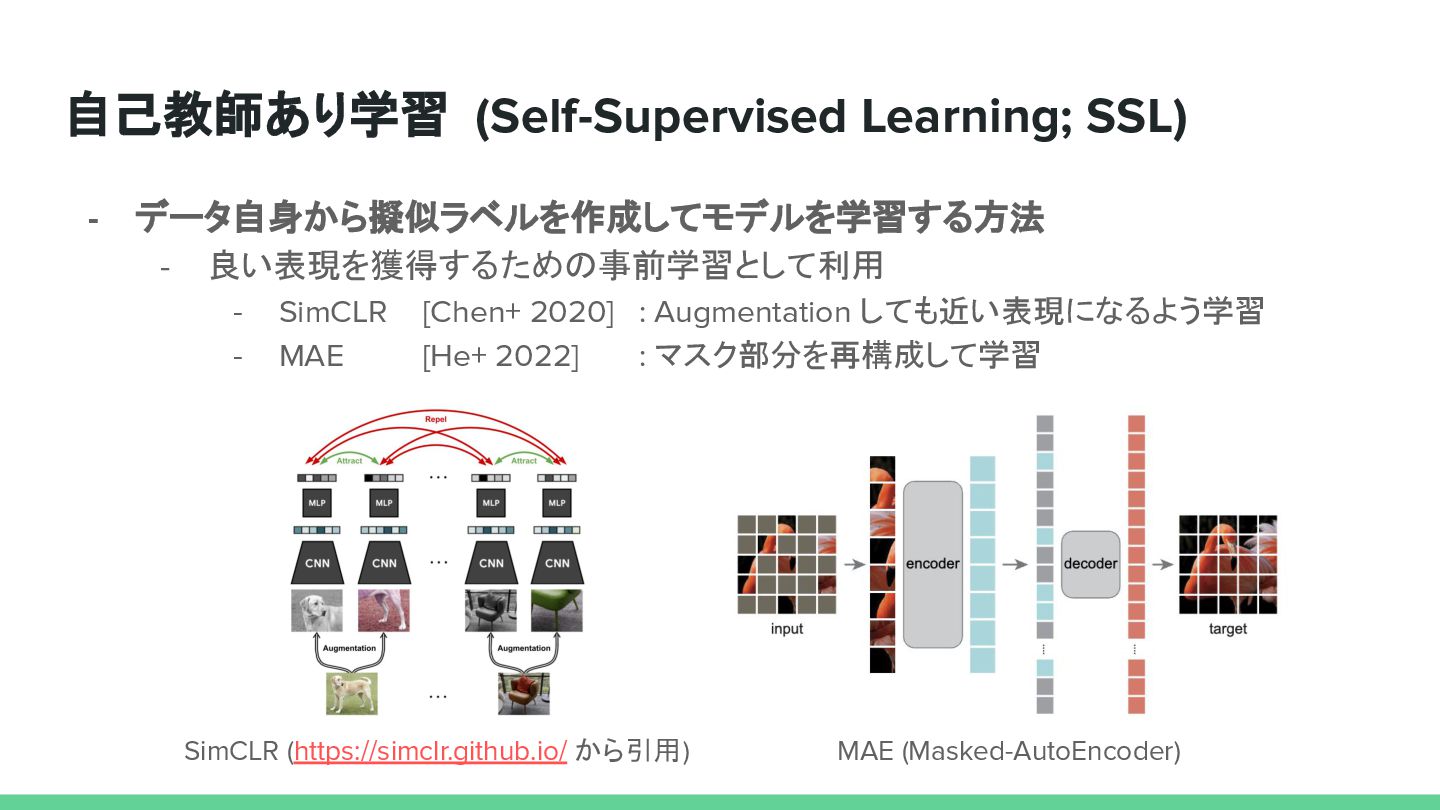{kind=link}
![STR×SSL: SeqCLR [Aberdam+ 2021] - 系列インスタンス間の表現が近くなるように学習 - 対応する系列インスタンス間の位置関係を保持するように工夫 - テキストがはみ出ない](https://files.speakerdeck.com/presentations/a714814c578c4223a9afcd88c232fe4f/slide_6.jpg){kind=link}
![STR×SSL: MAERec [Jiang+ 2023] - 大量のラベルなしデータを活用して SOTA - リアルデータのみで構成された Union14M](https://files.speakerdeck.com/presentations/a714814c578c4223a9afcd88c232fe4f/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
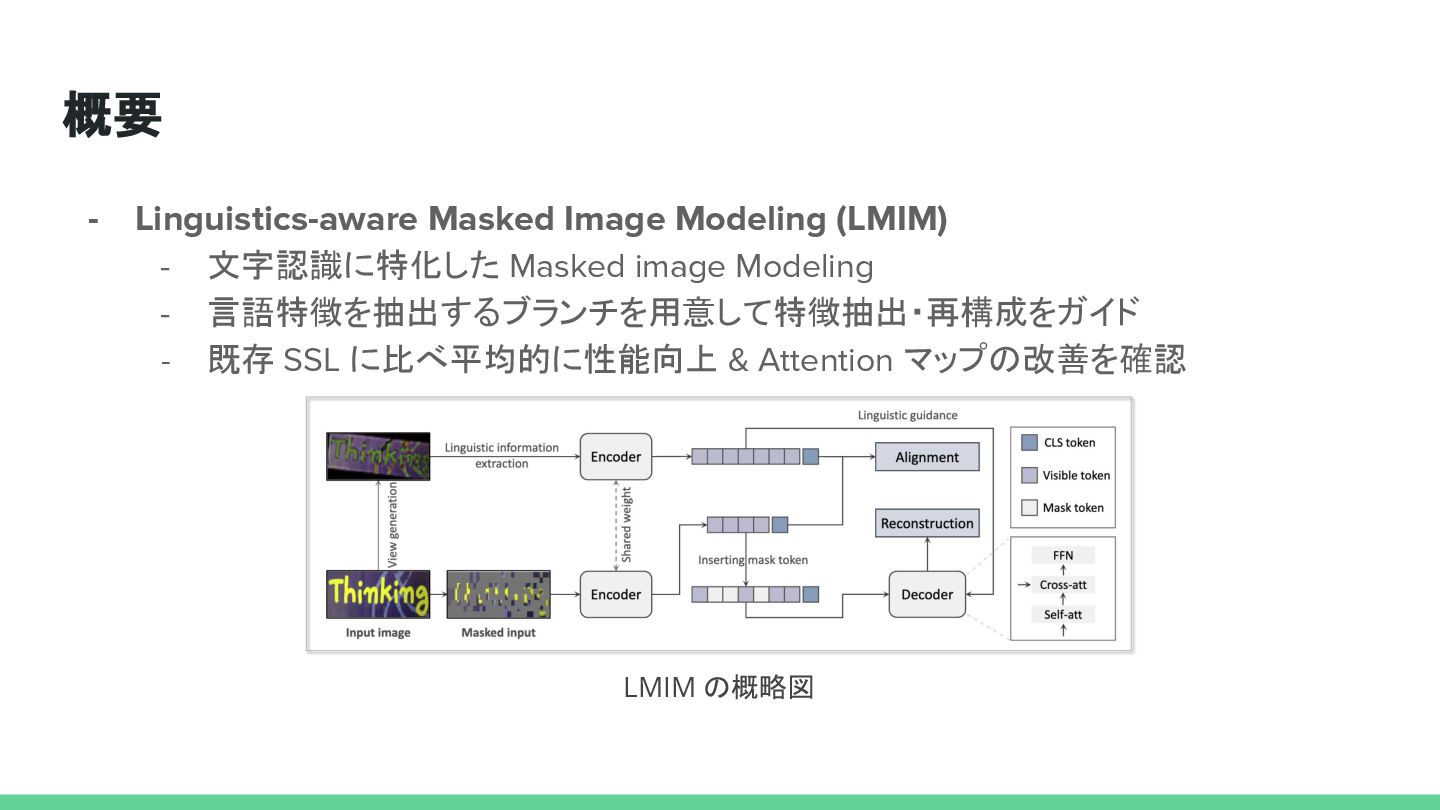{kind=link}
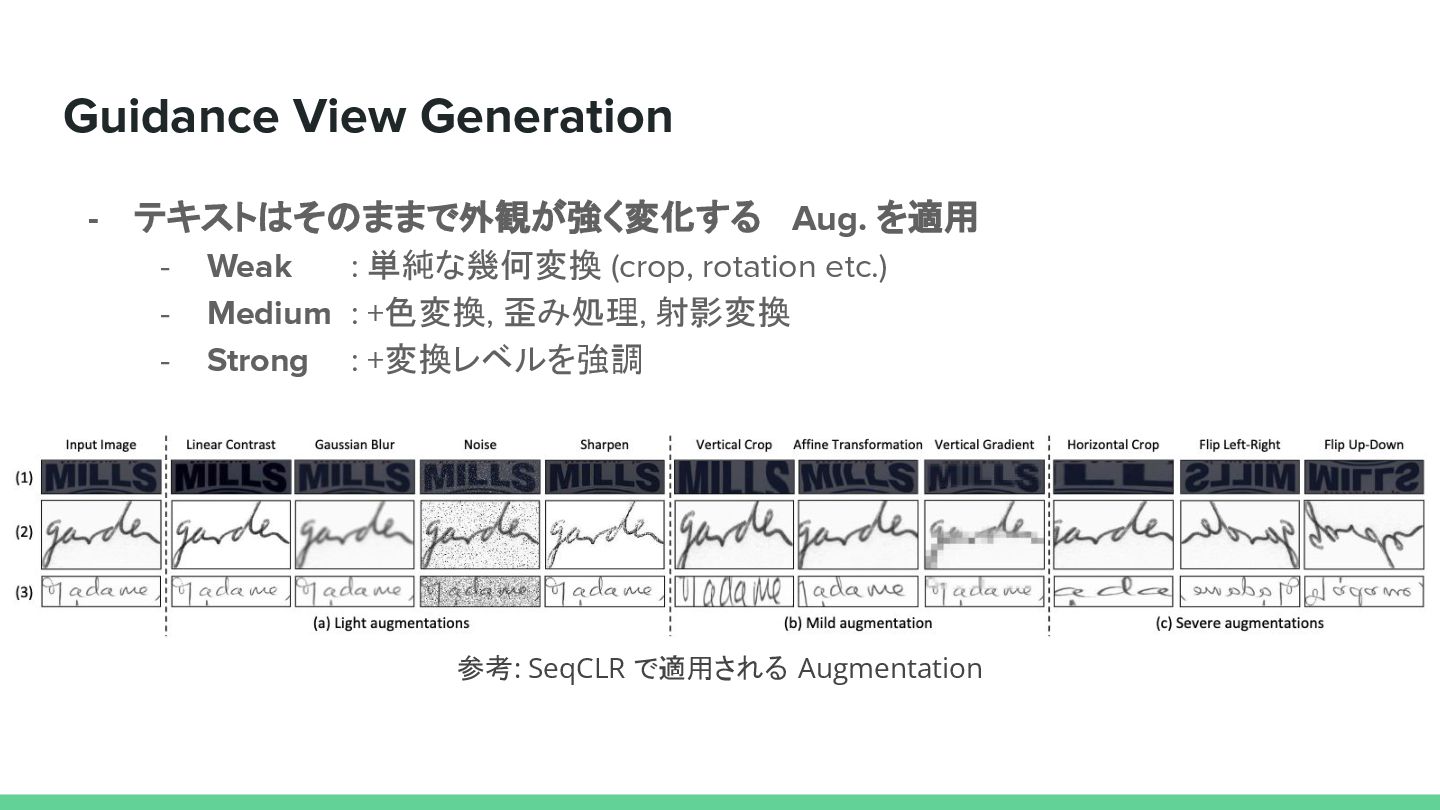{kind=link}
![Linguistics Alignment - [CLS] トークンの特徴を整合 - [CLS] トークンを導入することで大域的特徴を表現 - 再構成ブランチに大域的言語特徴の学習を強制](https://files.speakerdeck.com/presentations/a714814c578c4223a9afcd88c232fe4f/slide_13.jpg){kind=link}
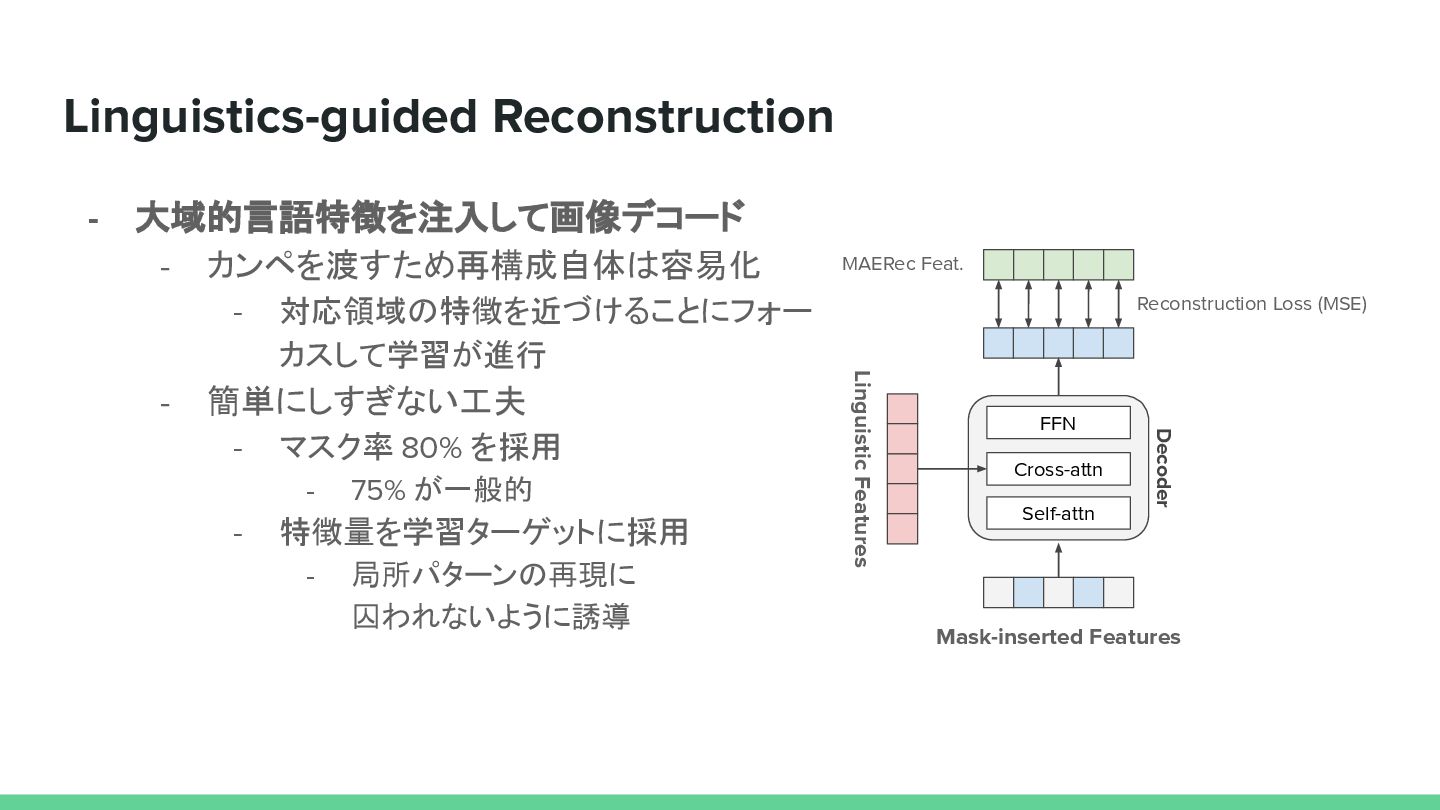{kind=link}
![実験設定 - データセット - 事前学習 - Union14M-U [Jiang+ 2023] :](https://files.speakerdeck.com/presentations/a714814c578c4223a9afcd88c232fe4f/slide_15.jpg){kind=link}
{kind=link}
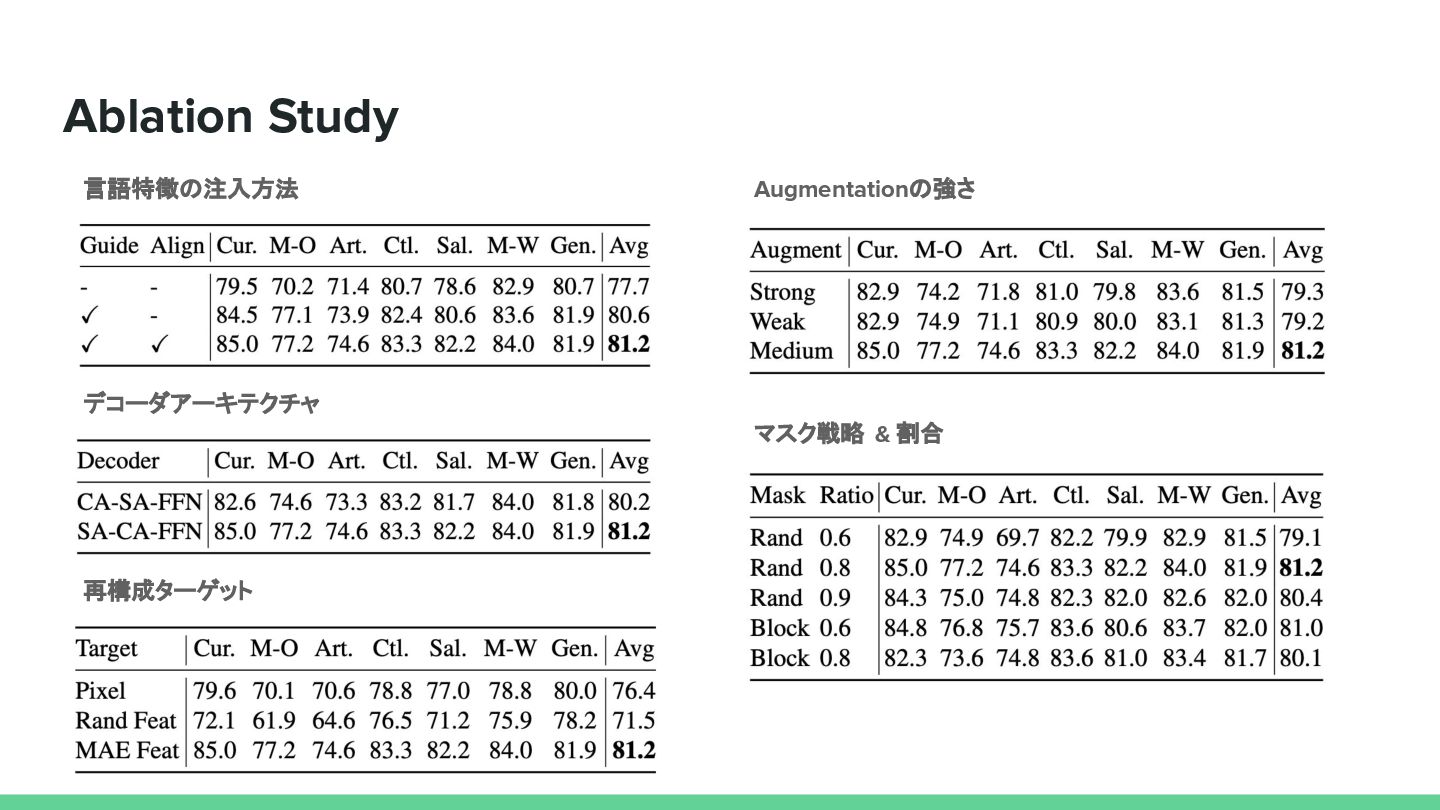{kind=link}
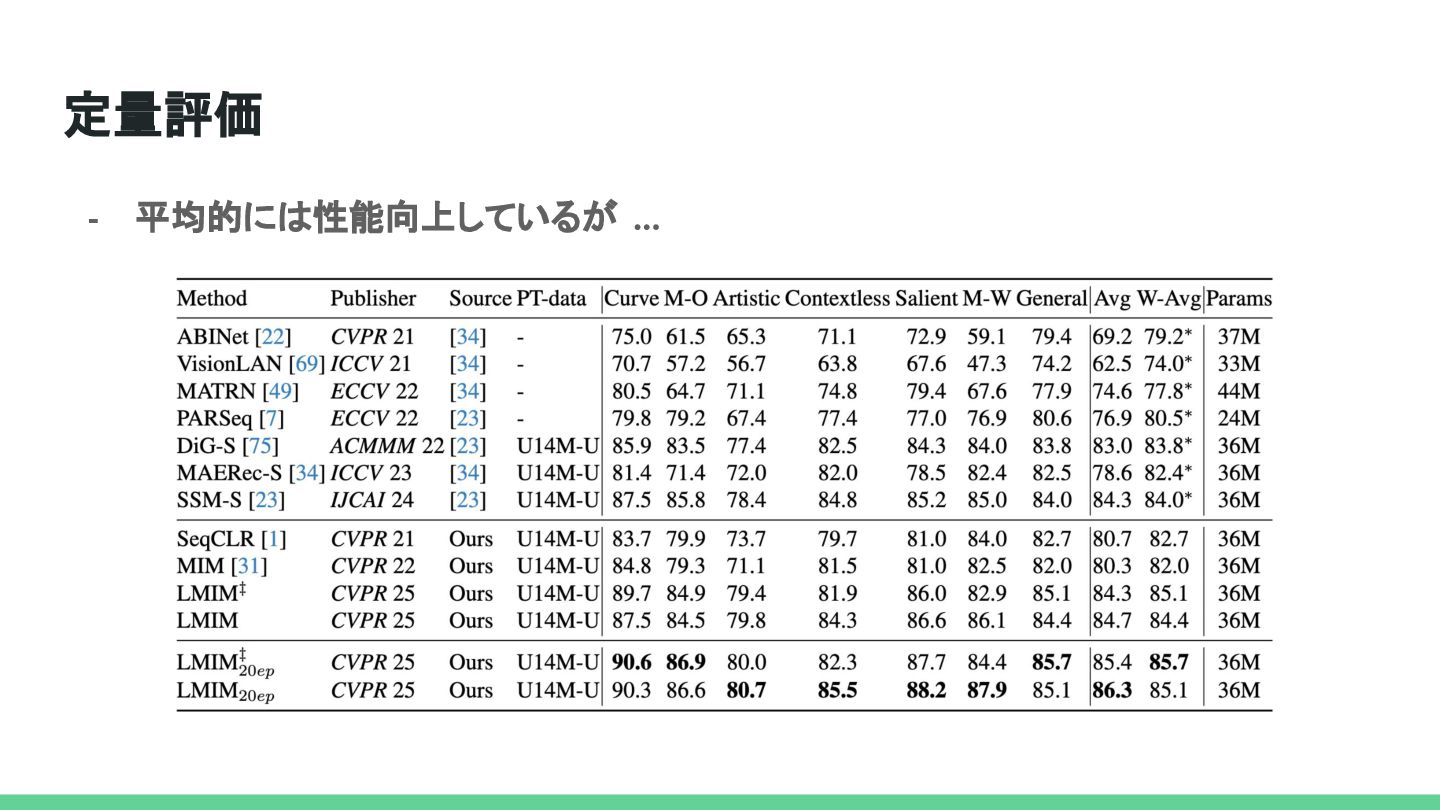{kind=link}
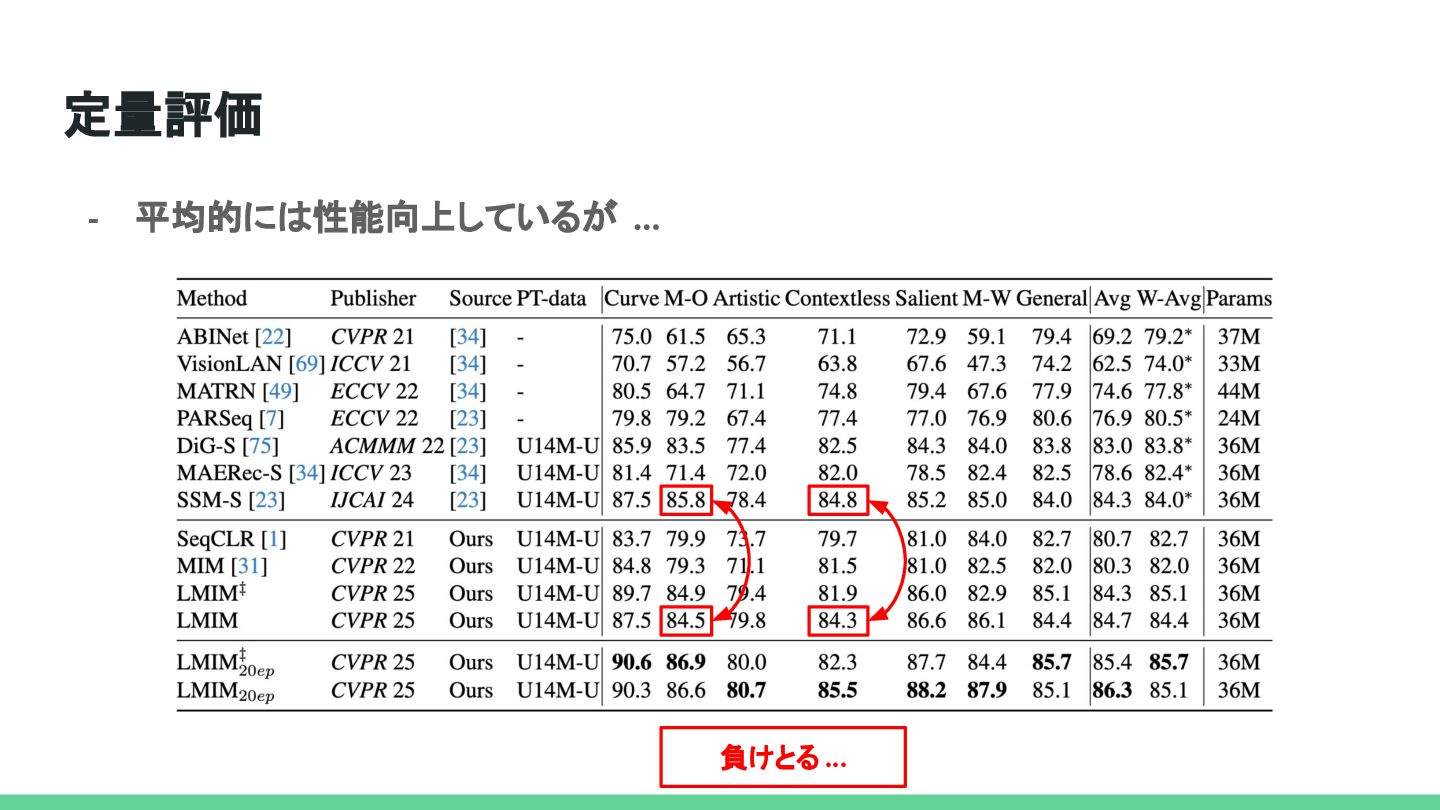{kind=link}
{kind=link}
{kind=link}
![[Baek+ 2019] Baek et al., “What Is Wrong with Scene](https://files.speakerdeck.com/presentations/a714814c578c4223a9afcd88c232fe4f/slide_22.jpg){kind=link}
![参考文献 [Fang+ 2021] Fang et al., “Read Like Humans: Autonomous,](https://files.speakerdeck.com/presentations/a714814c578c4223a9afcd88c232fe4f/slide_23.jpg){kind=link}