and Recall Spaces CVPR25 Oral 慶應義塾大学 杉浦孔明研究室 Hairong Shi 1 Jihan Yang1* Shusheng Yang1∗ Anjali W. Gupta1∗ Rilyn Han2∗ Li Fei-Fei3 Saining Xie1 1New York University 2Yale University 3Stanford University
videos remains unexplored (R, AD…) ▪ Humans has visual-spatial intelligence to remember spaces from sequential visual inputs ▪ Natural Question: Can VLMs also "think in space" from videos? ❖ Method: VSI-Bench ▪ A novel video-based visual-spatial intelligence benchmark with over 5,000 QA pairs ▪ Tested various reasoning techniques both linguistically and visually ❖ Result ▪ SR remaining the primary bottleneck ▪ Linguistical reasoning fails while visual reasoning improves performance
Previous advances in VLMs have primarily concentrated on content understanding or linguistical reasoning ▪ Visual-spatial intelligence is important due to its relevance to robotics, autonomous driving, and AR/VR ▪ Humans possess visual-spatial intelligence to remember spaces from sequential visual observations Qwen2-VL [Wang+, Arxiv24] EmbodiedBench [Yang+, ICML25 Oral] Frames of Mind: The Theory of Multiple Intelligences [Gardner, 1983]
out visual object and spatial processing are neurally distinct in visual-spatial intelligence ▪ Break spatial reasoning into two capabilities: relational reasoning and egocentric- allocentric transformation ▪ Egocentric: Sparse views from given video (camera’s perspective) ▪ Allocentric: Overall layout of the room (bird-eyes perspective)
Video-MME [Fu+, CVPR25] Recognition & perception Comprehensive evaluation across various video- related tasks EgoSchema [Mangalam+, NeurIPS23] Understanding abilities Content-level understanding from first-person perspective OpenEQA [Majumdar+, CVPR24] Understanding abilities Episodic question answering in embodied settings Most prior works focus on content-level, which primarily serves as a temporal extension of 2D image understanding without 3D spatial consideration Video-MME [Fu+, CVPR25] EgoSchema [Mangalam+, NeurIPS23]
Collection and Unification • 3x 3D indoor scene understanding & reconstruction datasets: ScanNet, ScanNet++, ARKitScenes • Video & Object-level 3D annotations & 3D reconstruction annotation • Unified meta-information format : object categories, bboxes, video specifications (resolution and frame rate ScanNet++ [Yeshwanth+, ICCV23]
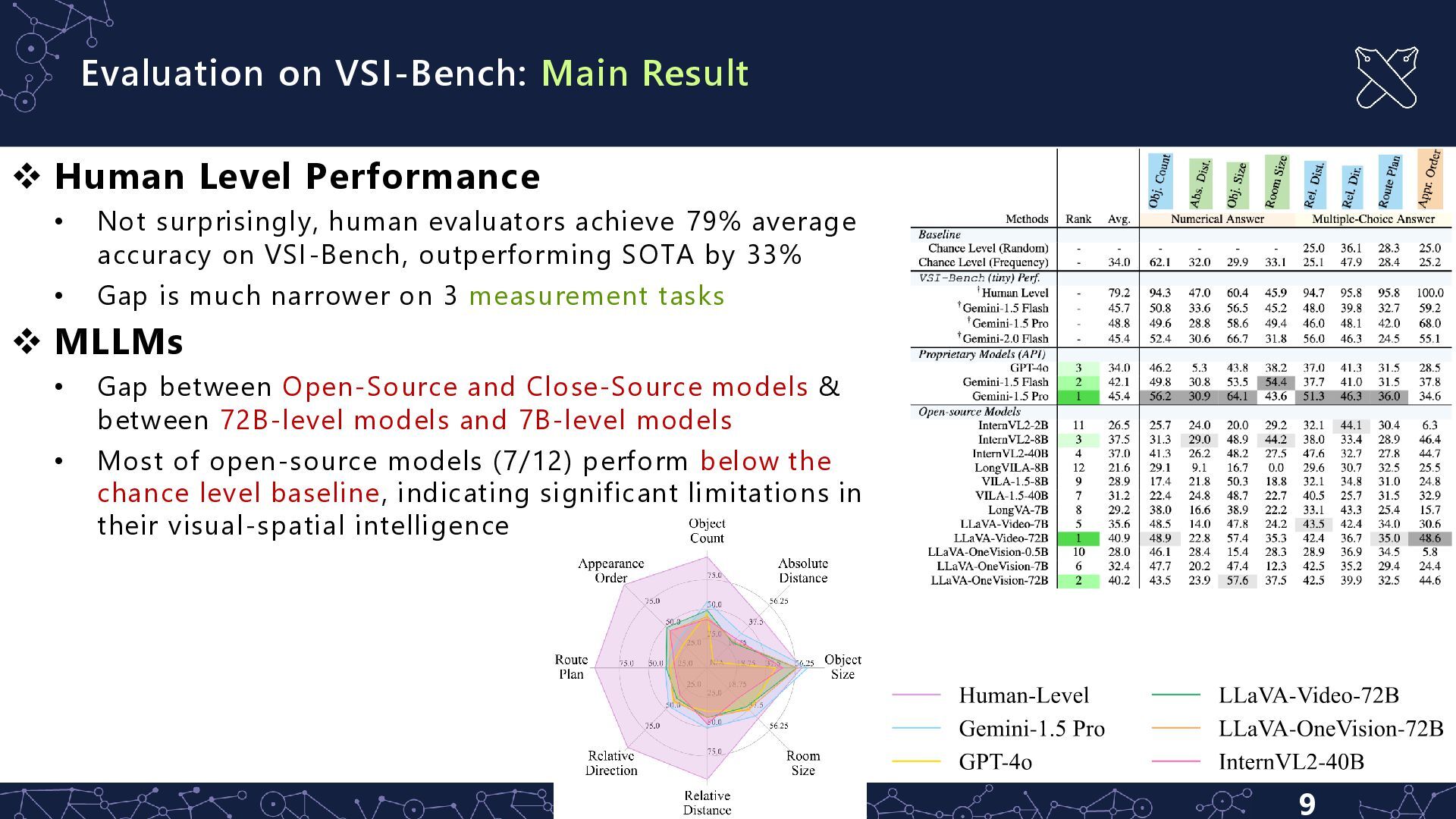
• Not surprisingly, human evaluators achieve 79% average accuracy on VSI-Bench, outperforming SOTA by 33% • Gap is much narrower on 3 measurement tasks ❖ MLLMs • Gap between Open-Source and Close-Source models & between 72B-level models and 7B-level models • Most of open-source models (7/12) perform below the chance level baseline, indicating significant limitations in their visual-spatial intelligence
• Linguistic prompting techniques, although effective in language reasoning and general visual tasks, are harmful for spatial reasoning • All three CoT techniques lead to performance degradation on VSI- Bench • Further analysis points out errors mainly come from relational reasoning and perspective transformation Spatial Reasoning
• Linguistic prompting techniques, although effective in language reasoning and general visual tasks, are harmful for spatial reasoning • All three CoT techniques lead to performance degradation on VSI- Bench • Further analysis points out errors mainly come from relational reasoning and perspective transformation Spatial Reasoning
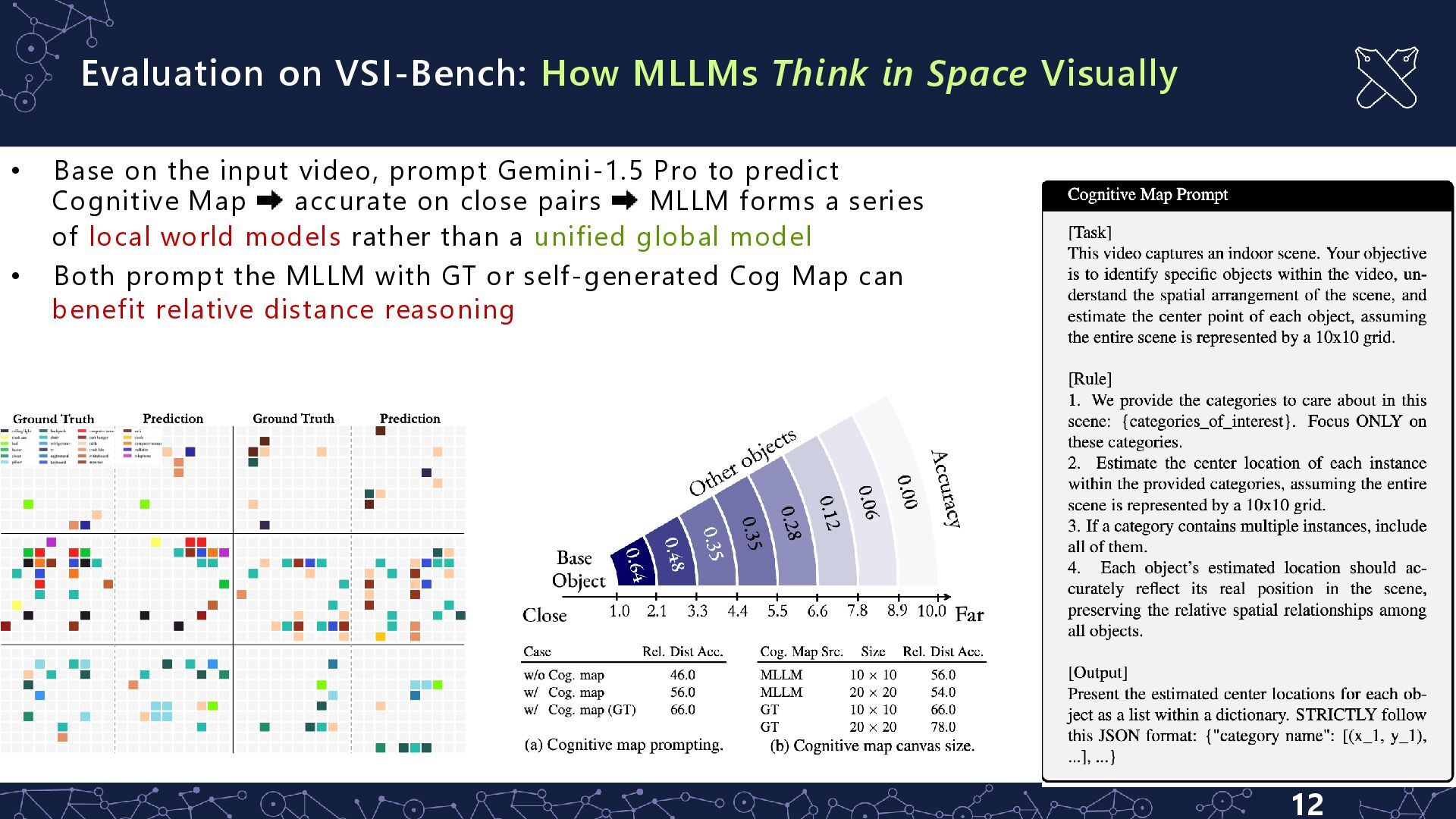
• Base on the input video, prompt Gemini-1.5 Pro to predict Cognitive Map accurate on close pairs MLLM forms a series of local world models rather than a unified global model • Both prompt the MLLM with GT or self-generated Cog Map can benefit relative distance reasoning
remains unexplored (R, AD…) ▪ Humans has visual-spatial intelligence to remember spaces from sequential visual inputs ▪ Can VLMs also "think in space" from videos? ❖ Method: VSI-Bench ▪ A novel video-based visual-spatial intelligence benchmark with over 5,000 QA pairs ▪ Tested various reasoning techniques both linguistically and visually ❖ Result ▪ SR remaining the primary bottleneck ▪ Linguistical reasoning fails while visual reasoning improves performance
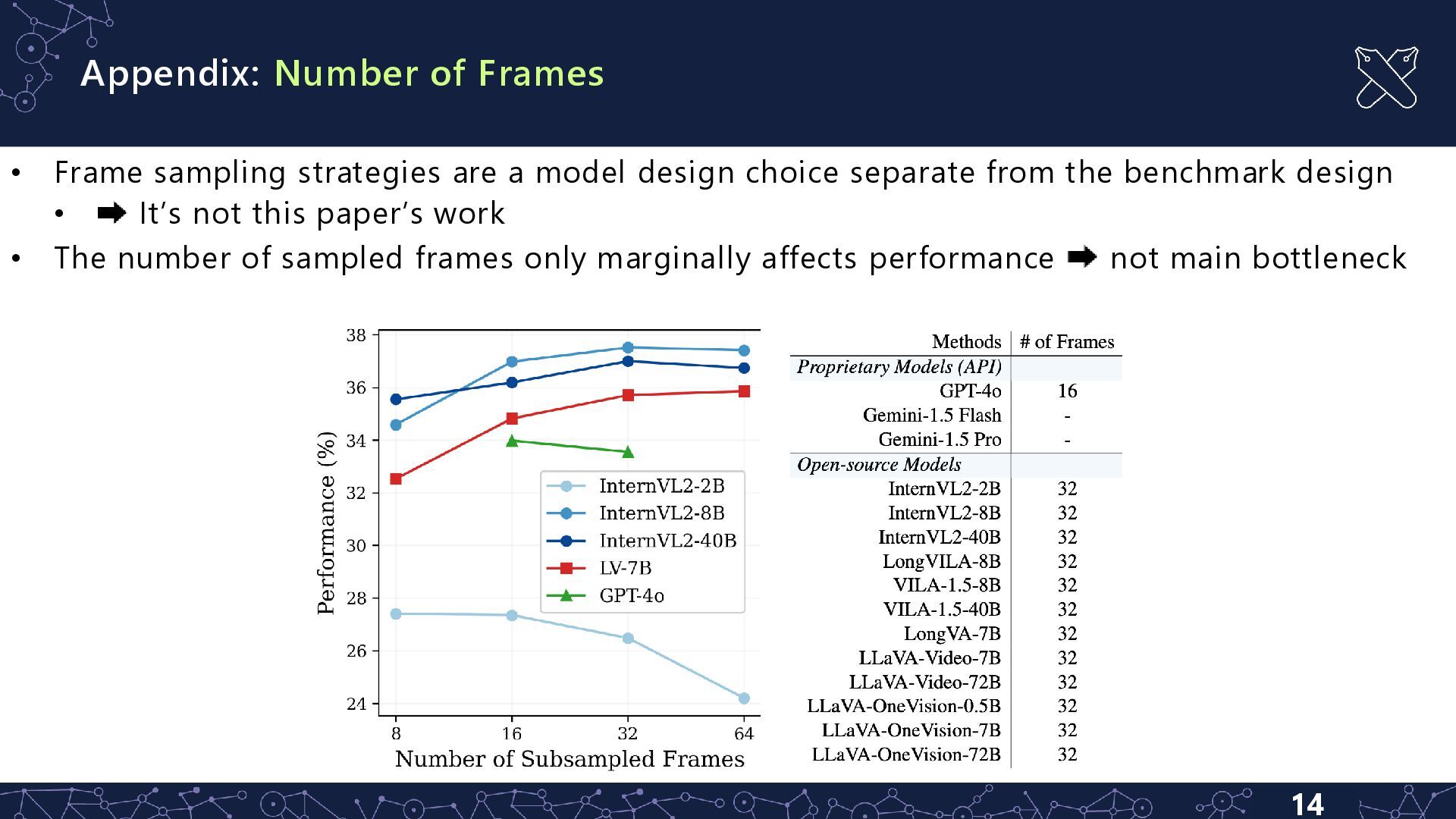
a model design choice separate from the benchmark design • It’s not this paper’s work • The number of sampled frames only marginally affects performance not main bottleneck
experiment settings were arranged by several questions -> progressive logic ▪ This paper has led a trend of focus in perspective shifting (CVPR25, ICCV25…) ❖ Weakness ▪ Even though the bench was auto-annotated, they didn’t scale it up to create a training set ▪ Didn’t explore some training-side strategies ▪ But some other works then explored it MINDCUBE [Yin+, Arxiv25, Currently ICLR26 under review]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}