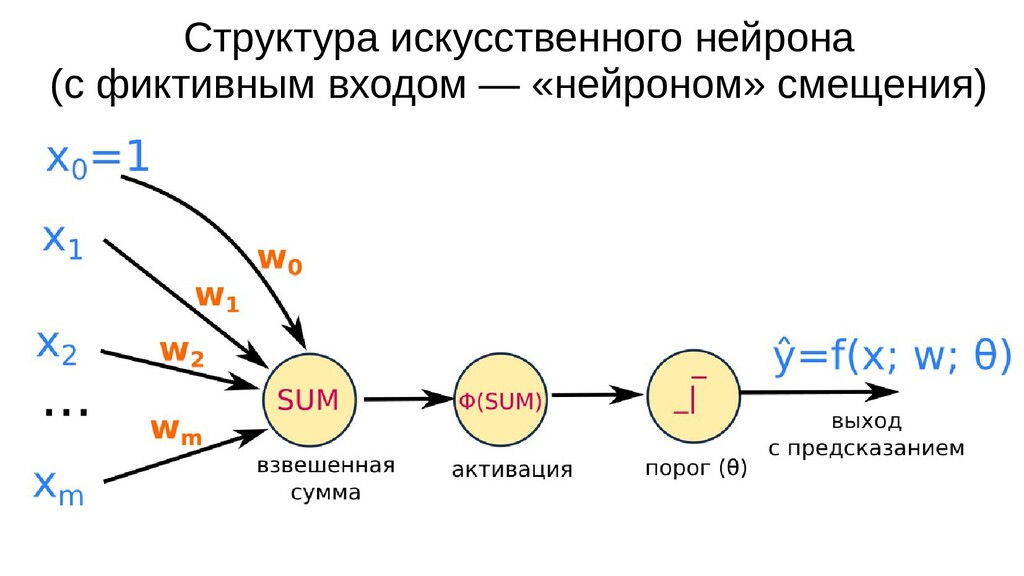
Обучение нейронной сети: обратное распространение ошибки, дифференцирование сложной функции.
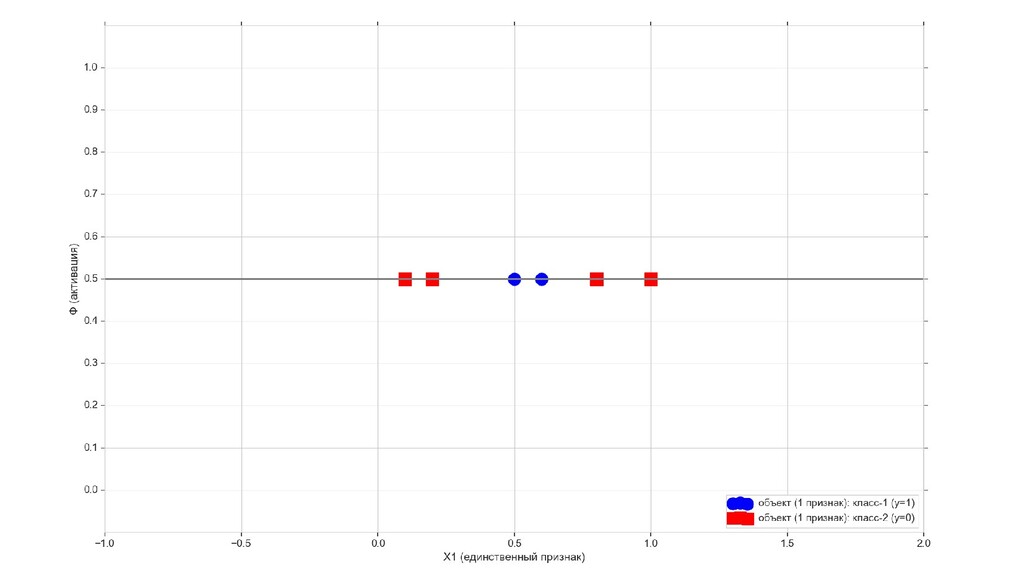
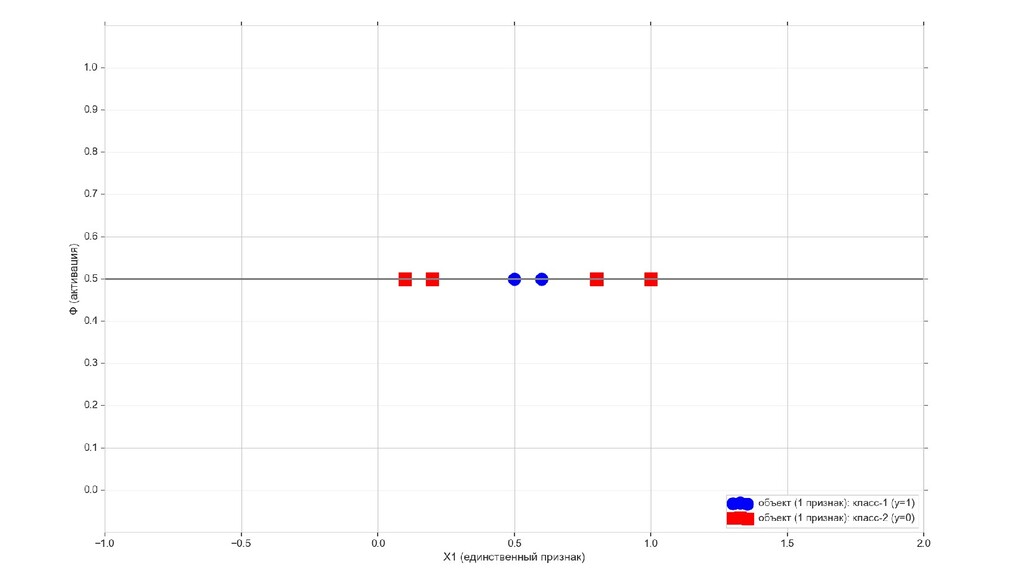
- Линейно неразделимое множество: попробуем отделить то, что снаружи, от того, что внутри
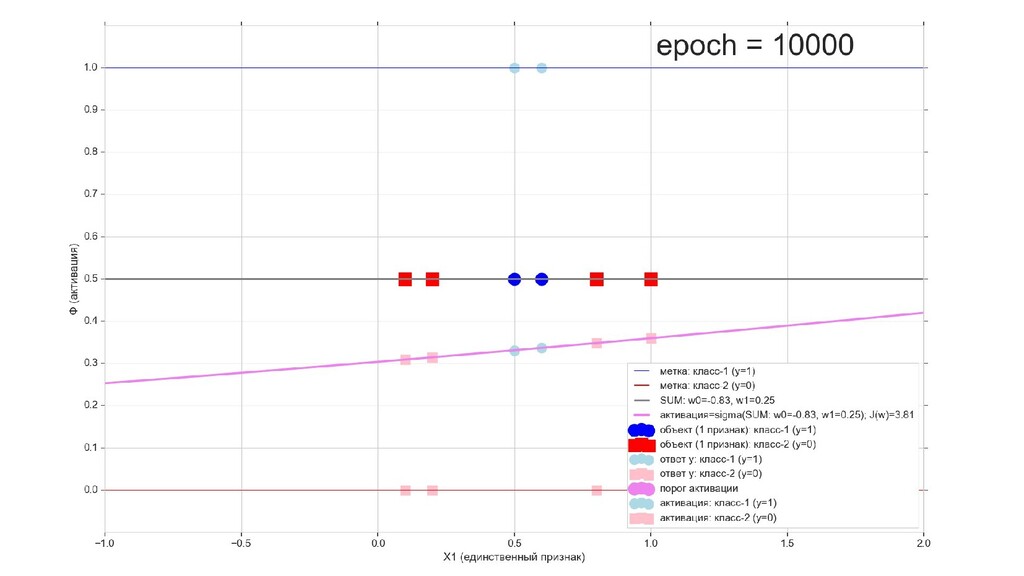
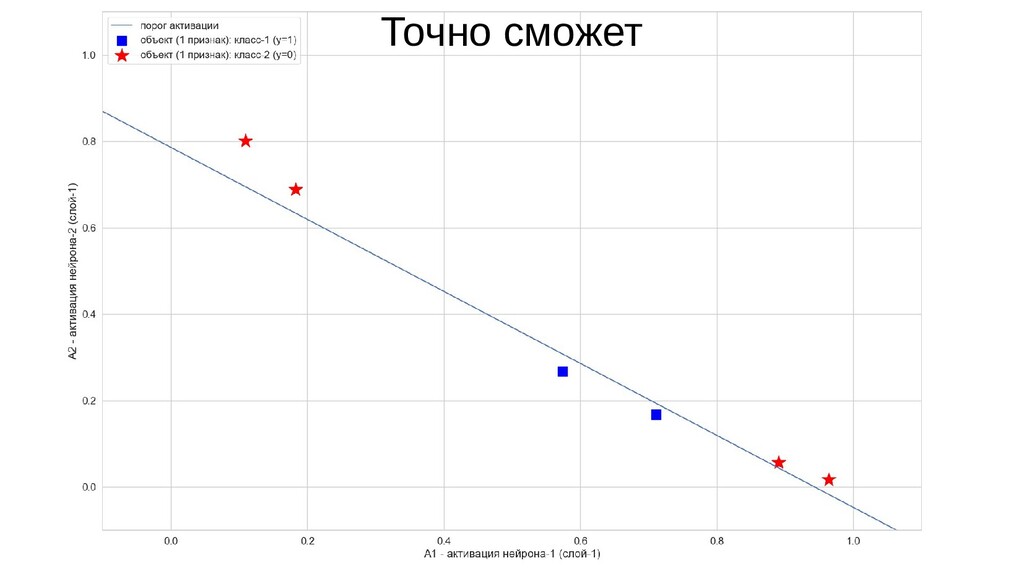
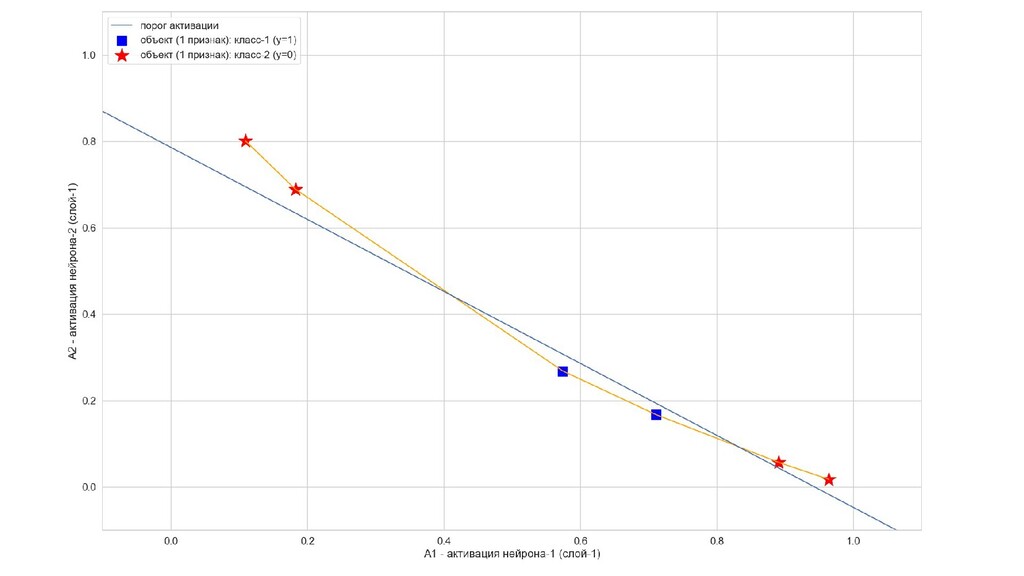
- Получится ли разделить линейно неразделимое единичным нейроном? (очевидно, нет, но все равно попробуем. спойлер: не получилось)
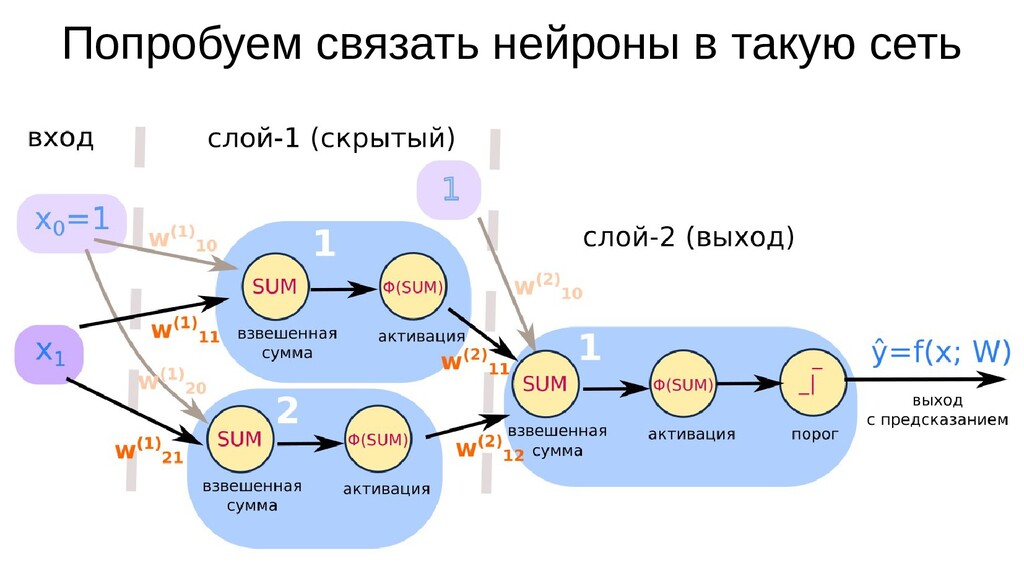
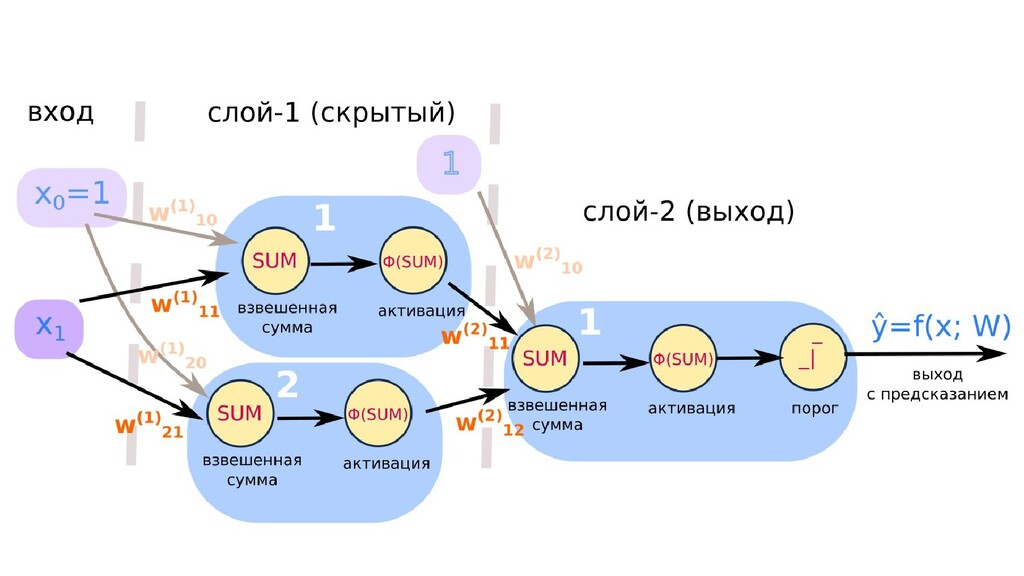
- Свяжем нейроны в сеть из 3-х нейронов: один скрытый слой из 2-х нейронов, один нейрон на выходе, на входе объект с единственным признаком, активации - сигмоиды, порог-классификатор только на выходе
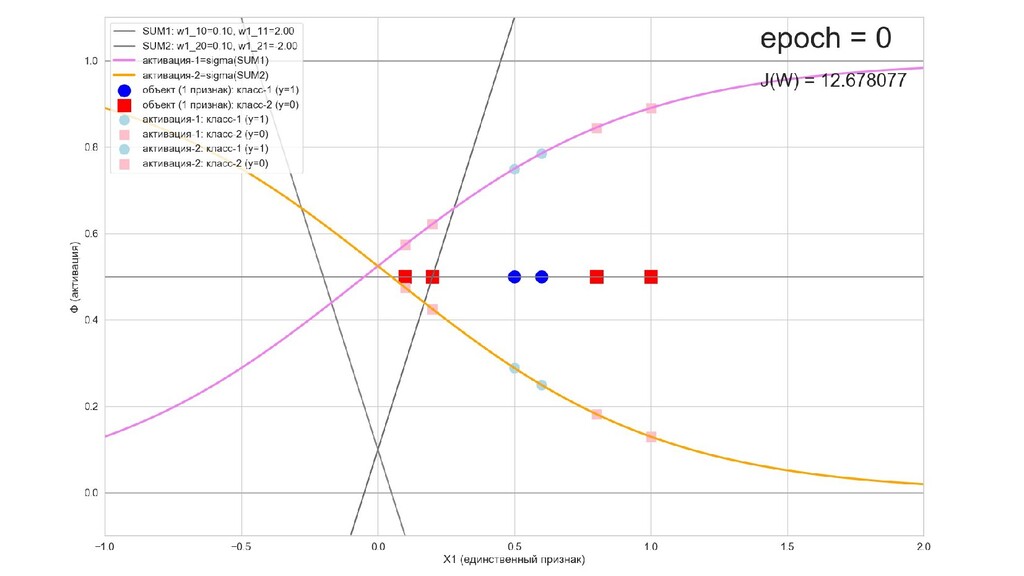
- Математическое представление сети, формулы активаций
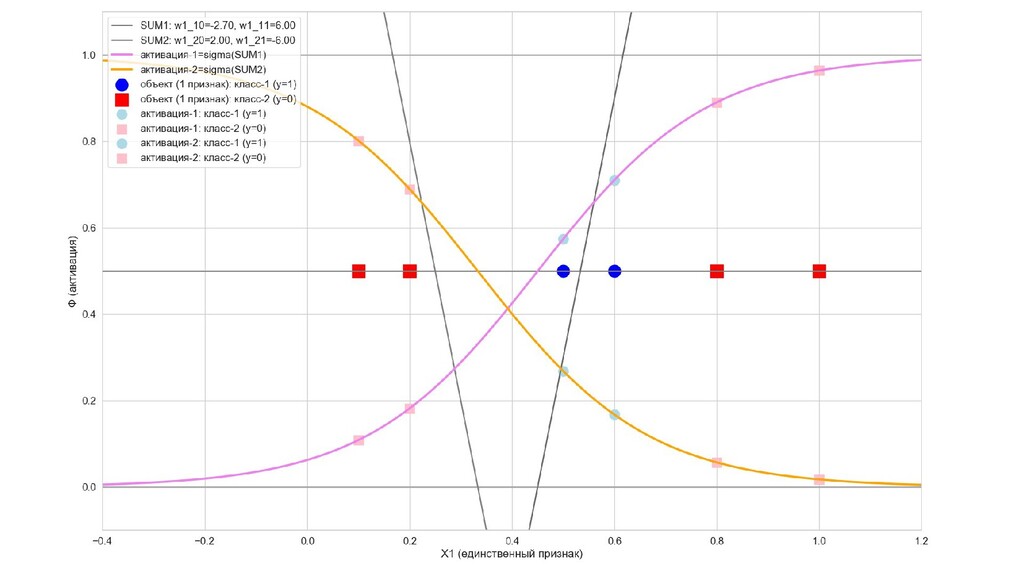
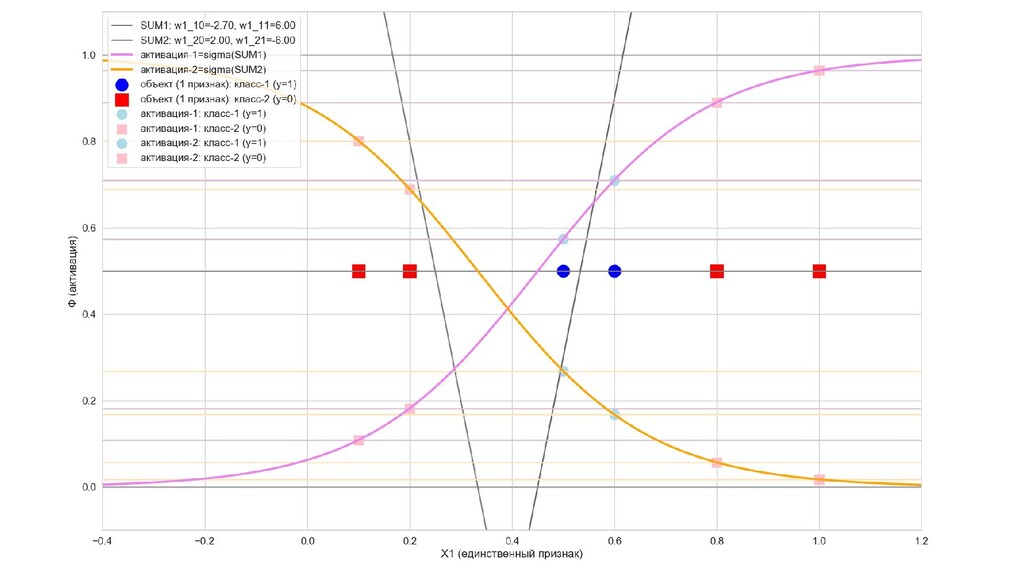
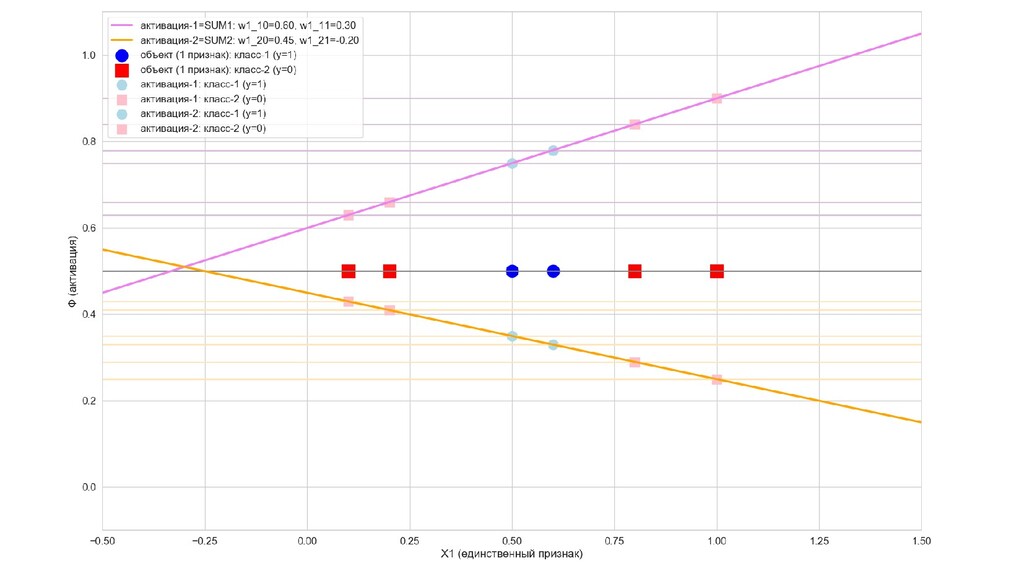
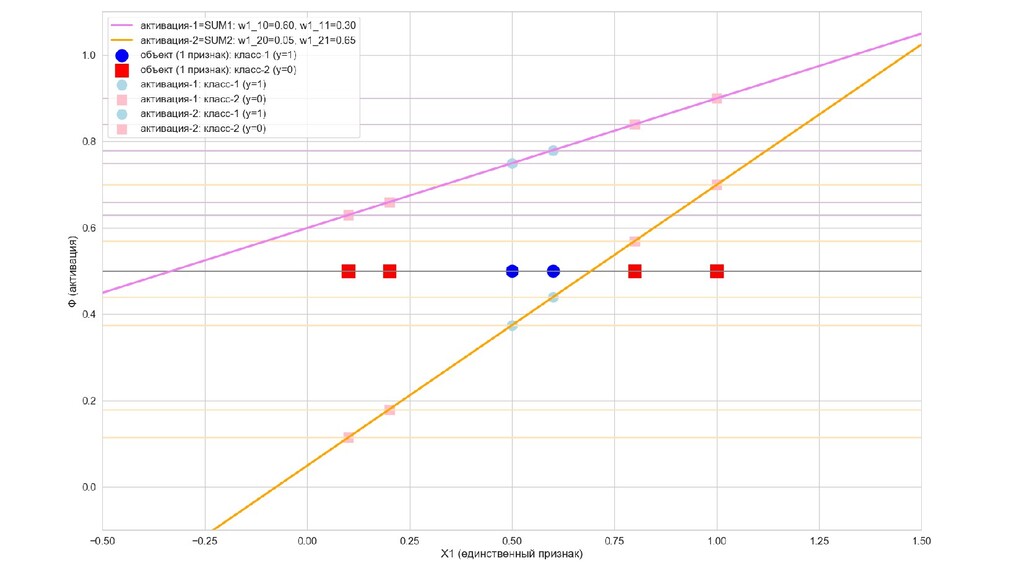
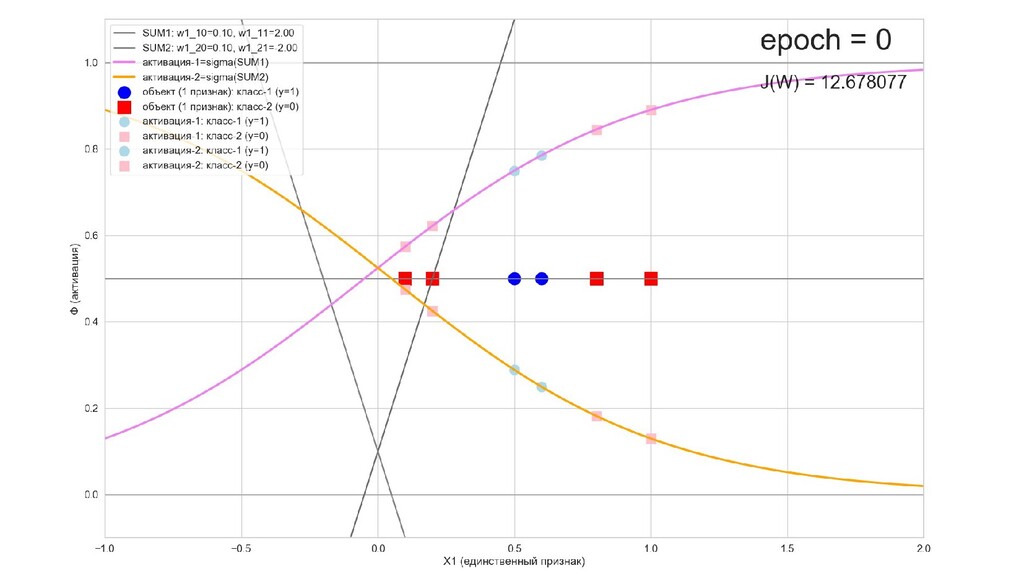
- Интуитивный смысл происходящего на 1-м слое: один нейрон разбивает выборку так, другой нейрон разбивает выборку эдак
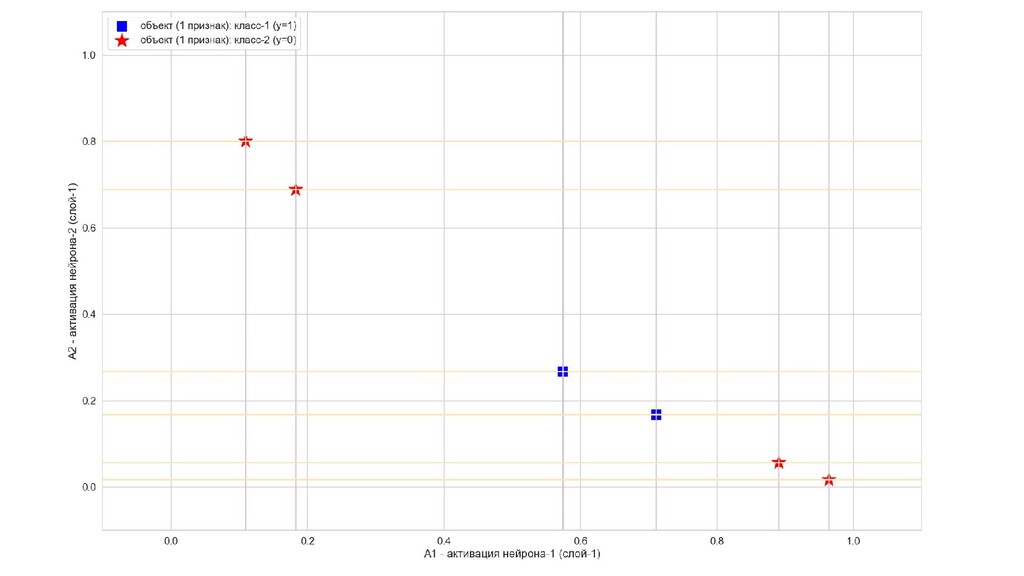
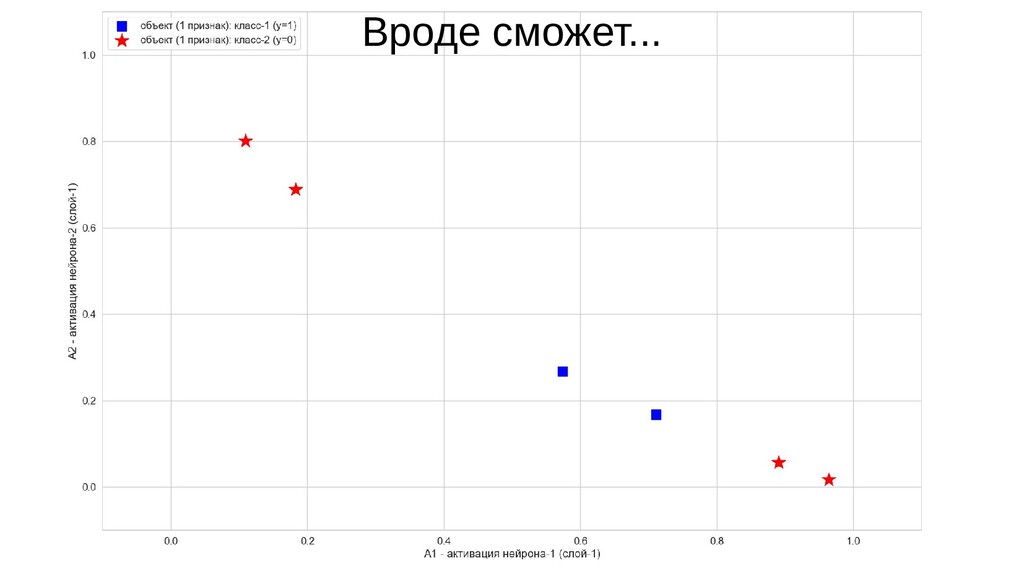
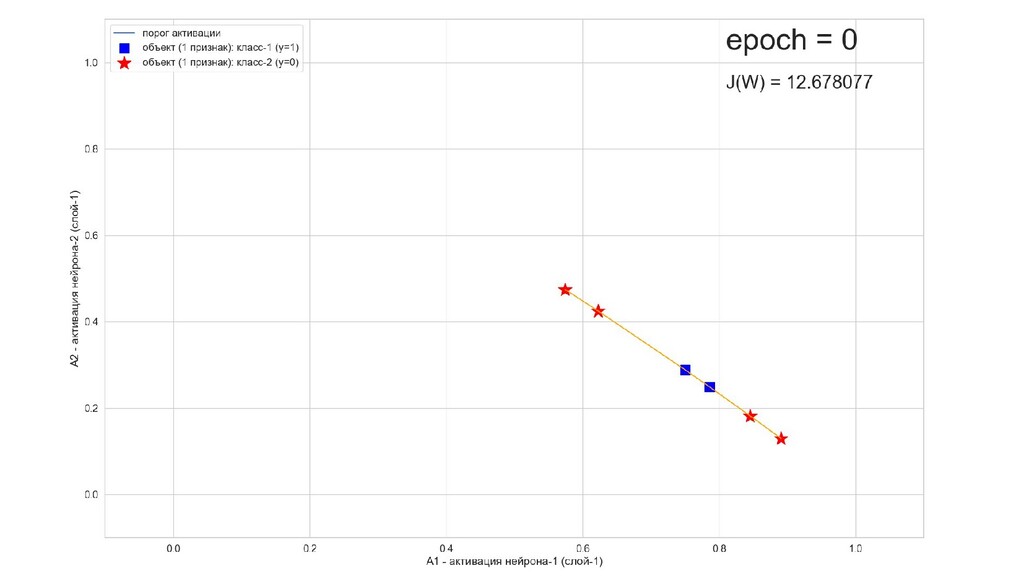
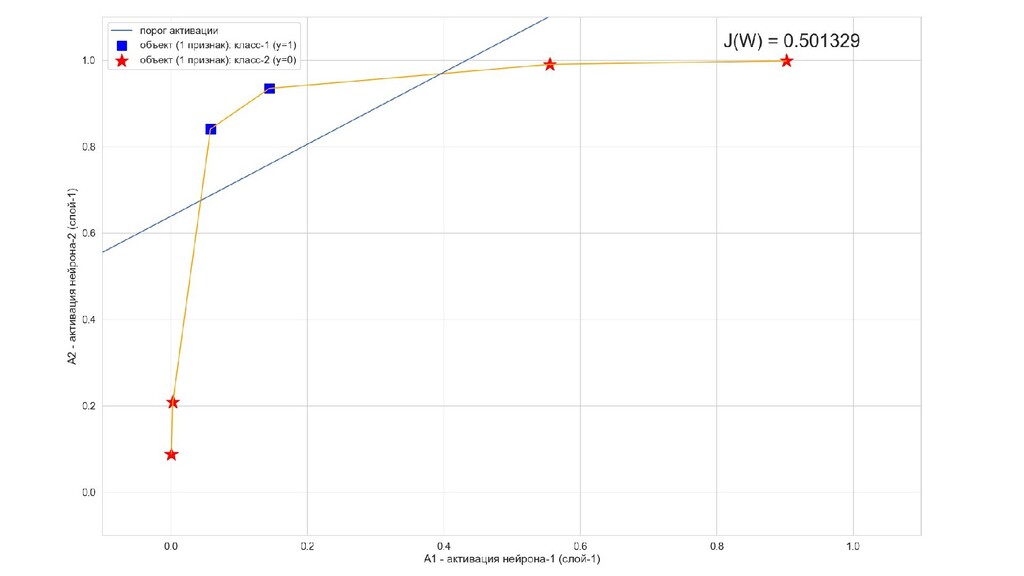
- Значения выходов нейронов 1-го слоя как признаки объекта-проекции, попадающего на выходной нейрон
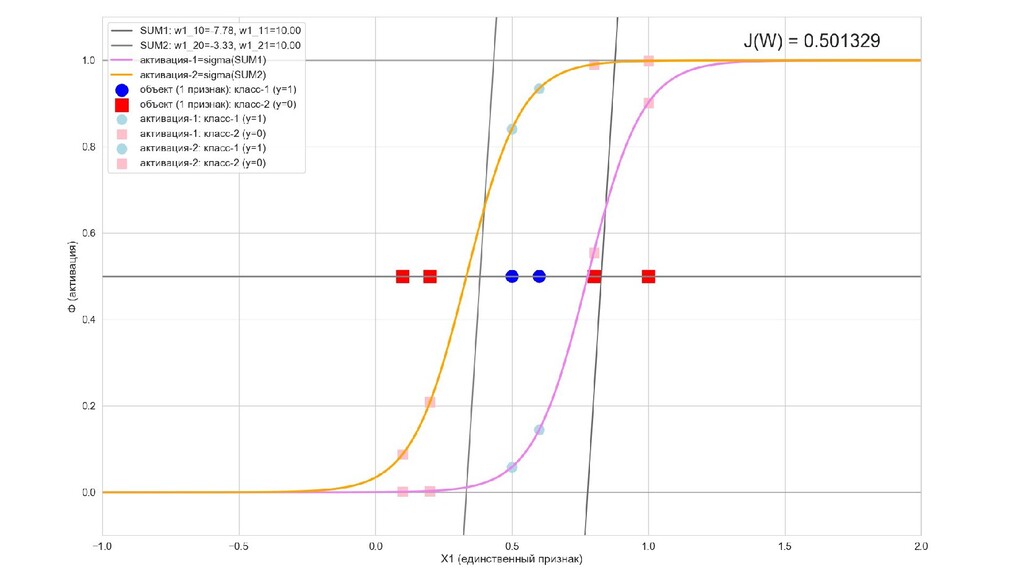
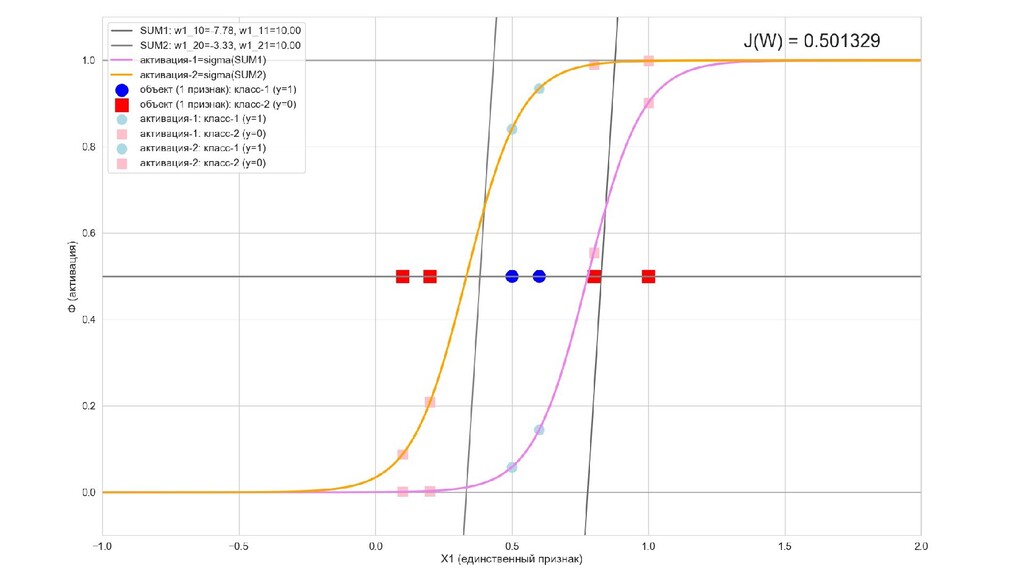
- Графическое представление активаций на 1-м слое и входов нейрона на 2-м слое
- Разделимость объектов-проекций на выходном слое
- Отступление: целесообразно ли строить сеть из нейронов с линейной активацией? (спойлер: нет)
- Критерий оптимальности коэффициентов-параметров нейросети: функция стоимости (она же: функция потерь) на основе функции правдоподобия
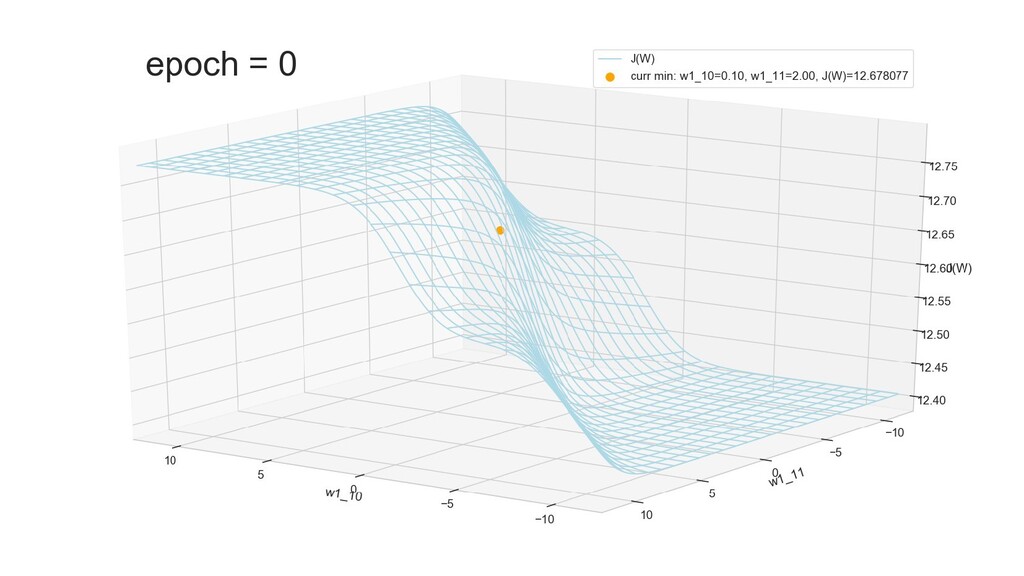
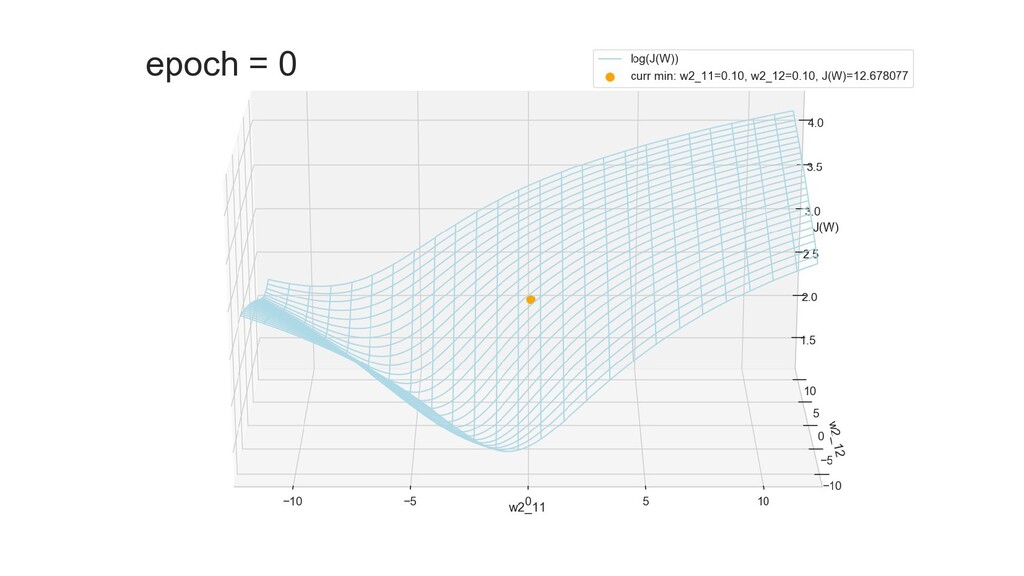
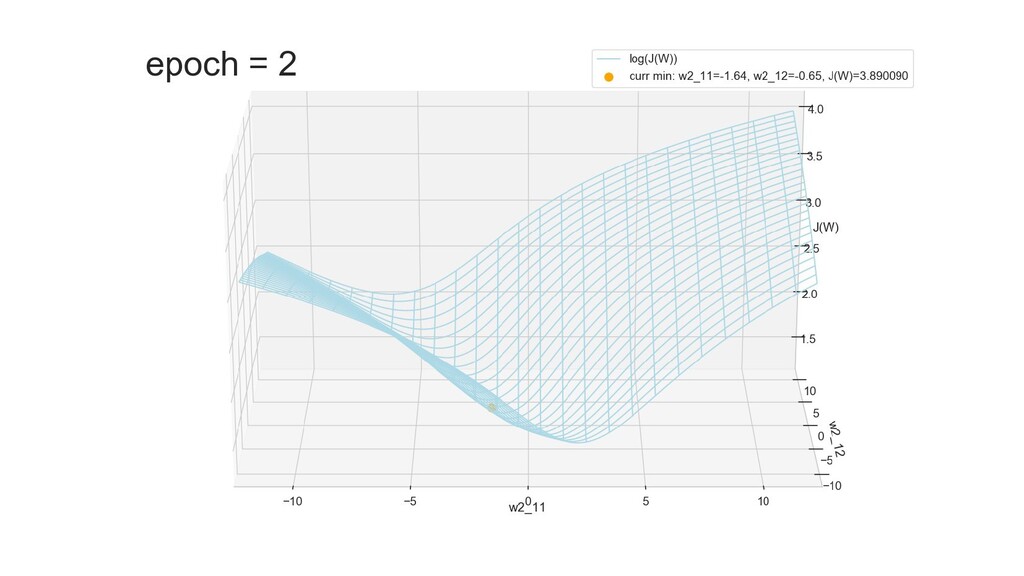
- Поиск минимума функции стоимости полным перебором коэффициентов, подтверждение того, что сеть разделяет объекты при минимальном значении функции стоимости
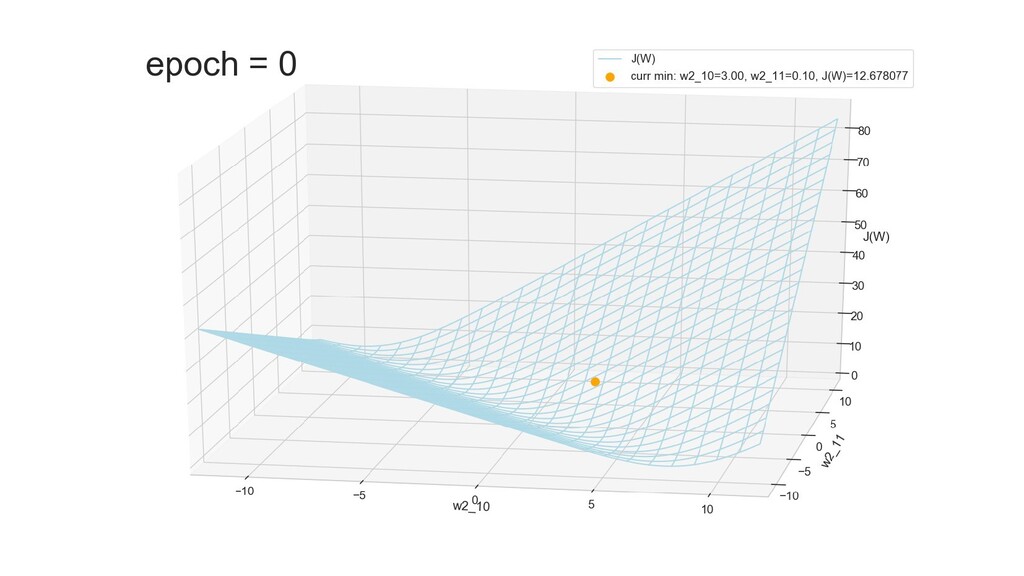
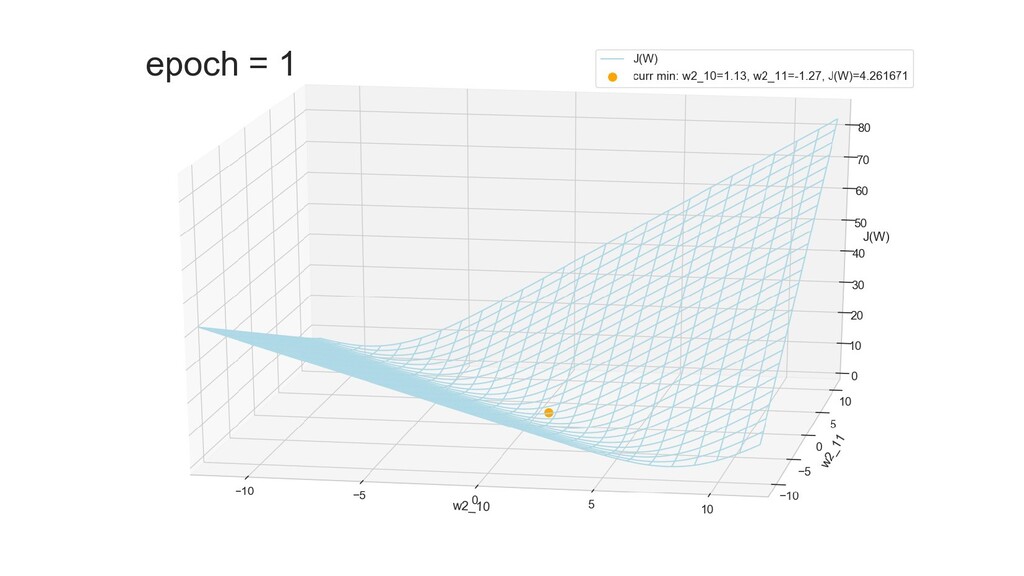
- Поиск минимума функции стоимости градиентным спуском
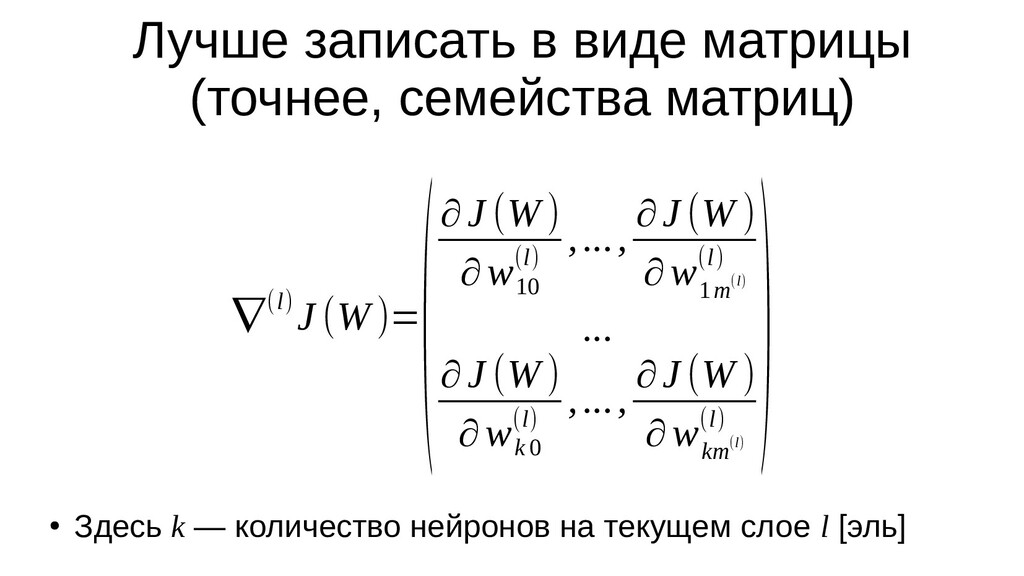
- Частная производная функции стоимости в общем виде
- Частные производные функции стоимости по каждому из параметров
- Замечание: аналитическое вычисление производной сложной функции vs библиотеки автоматического дифференцирования
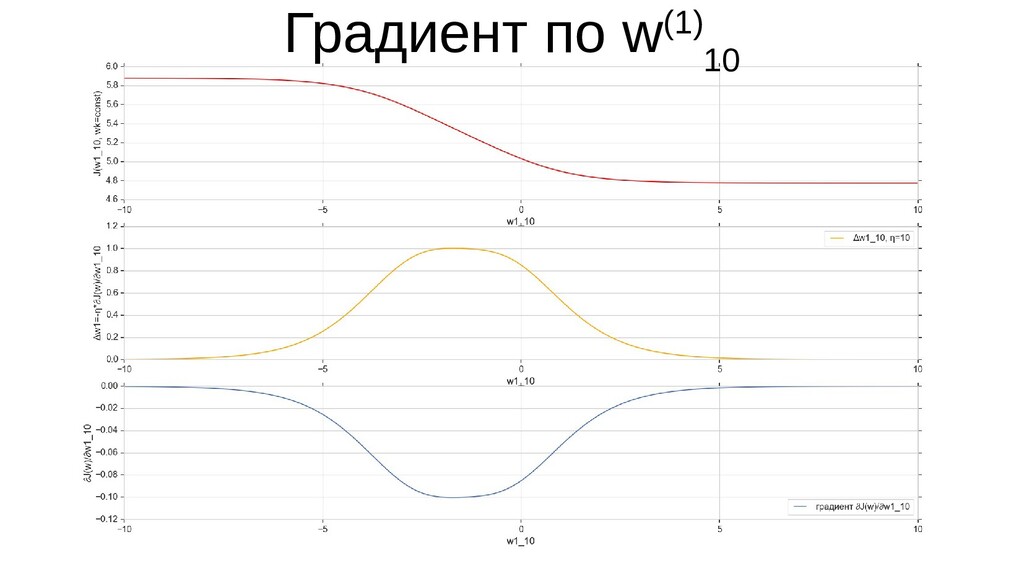
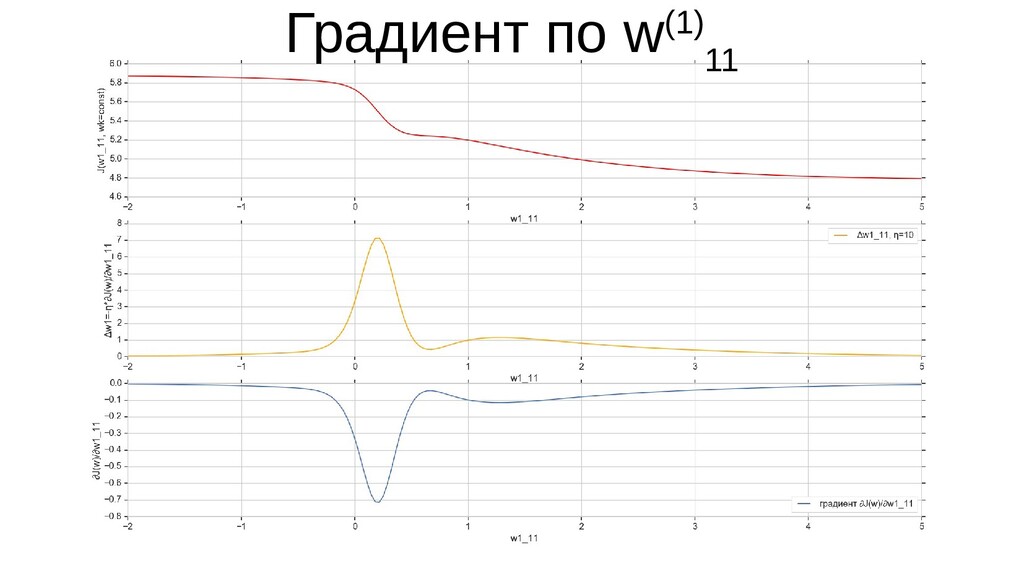
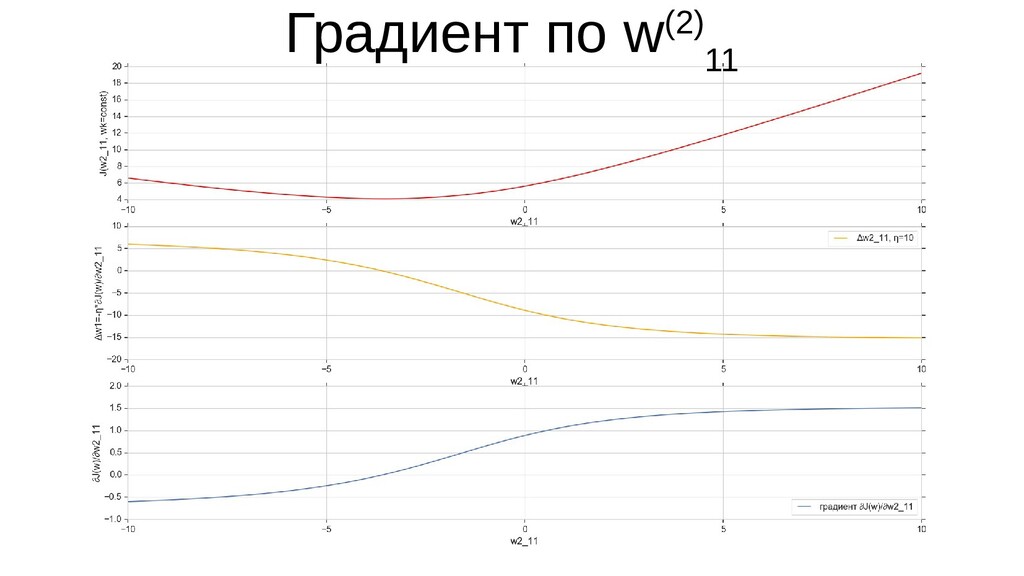
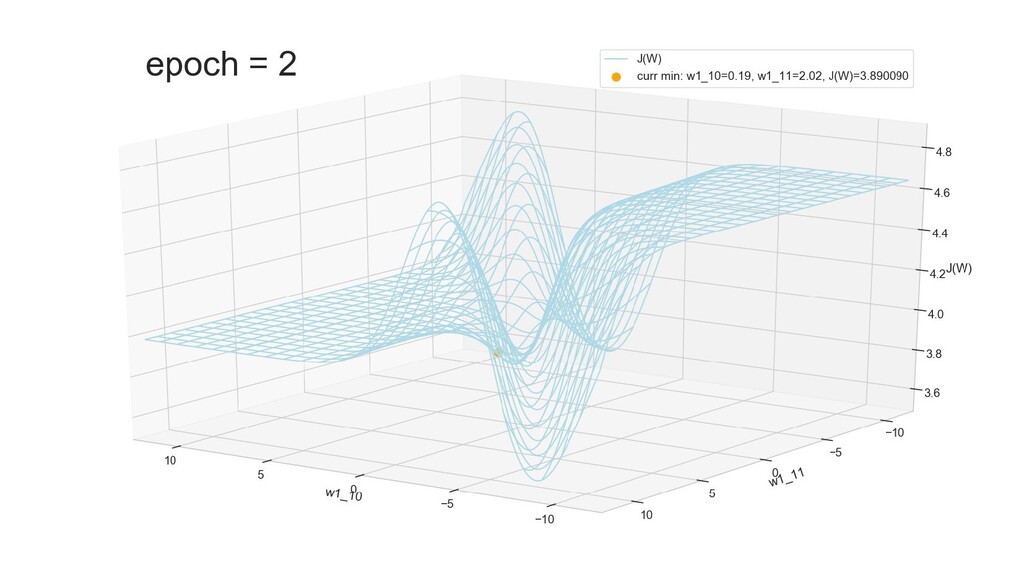
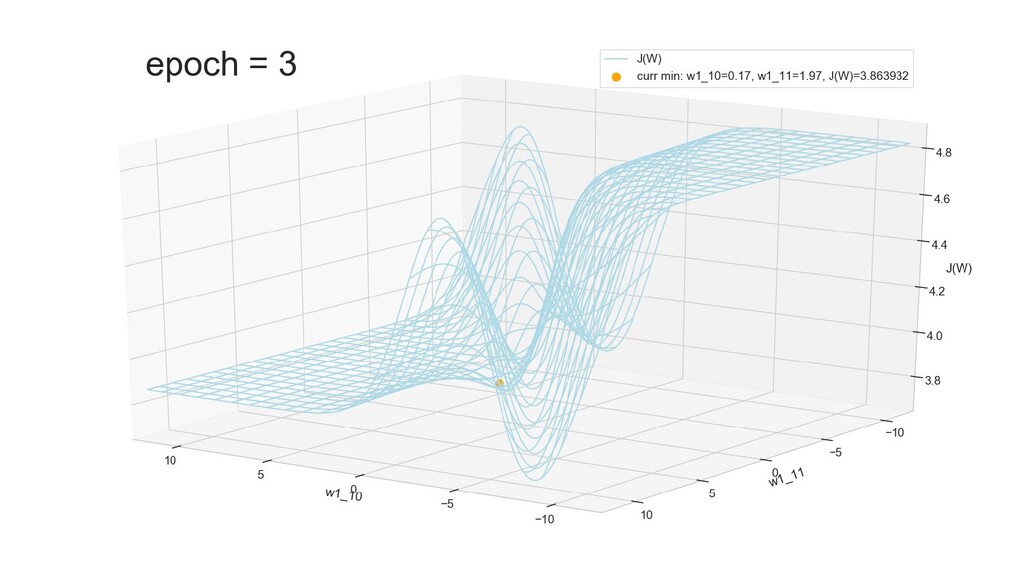
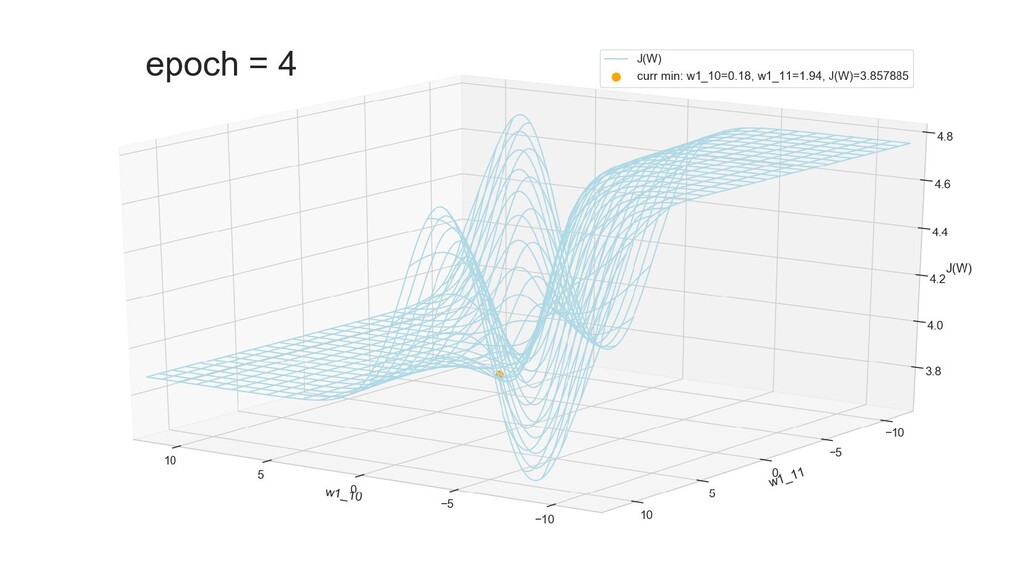
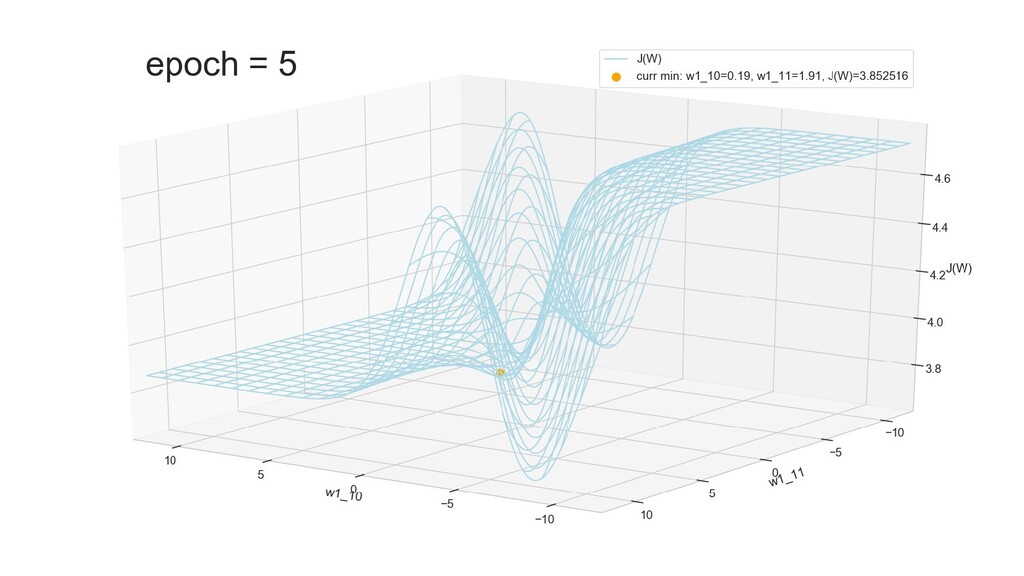
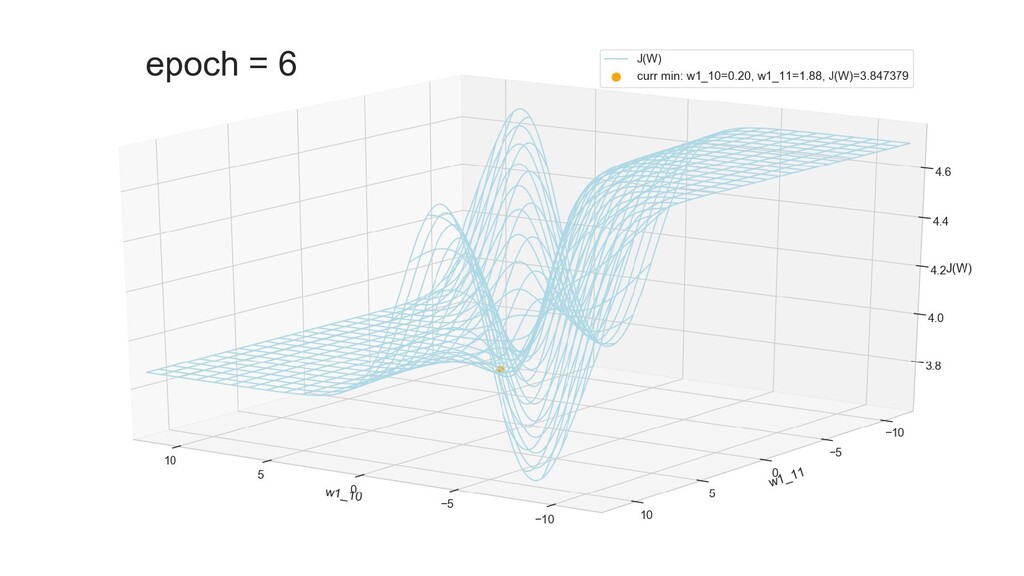
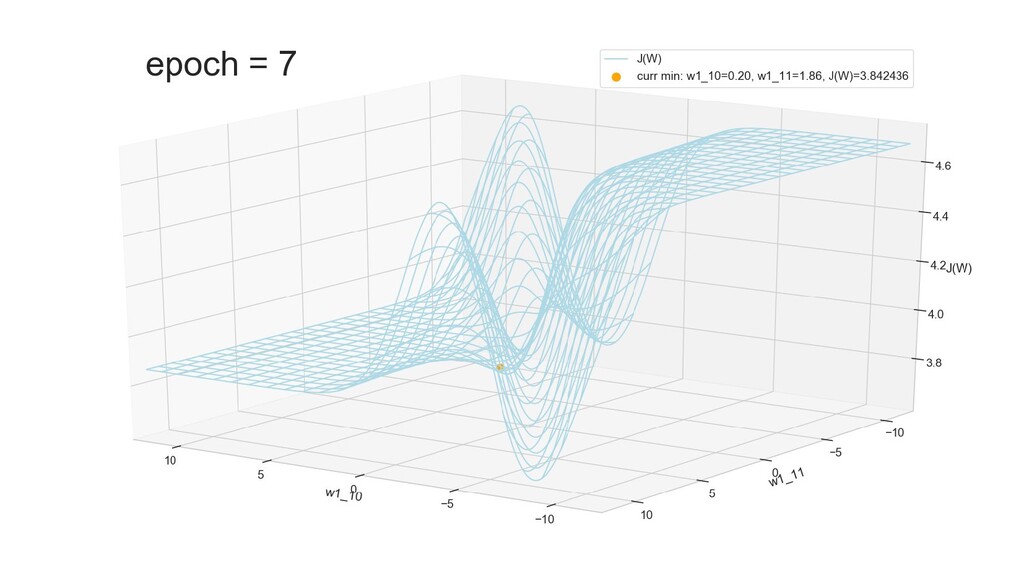
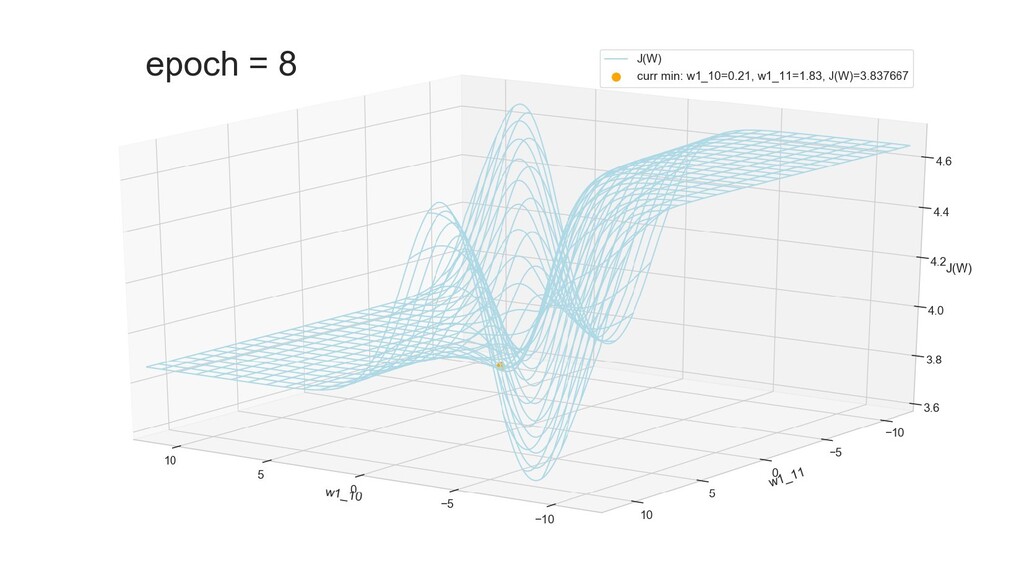
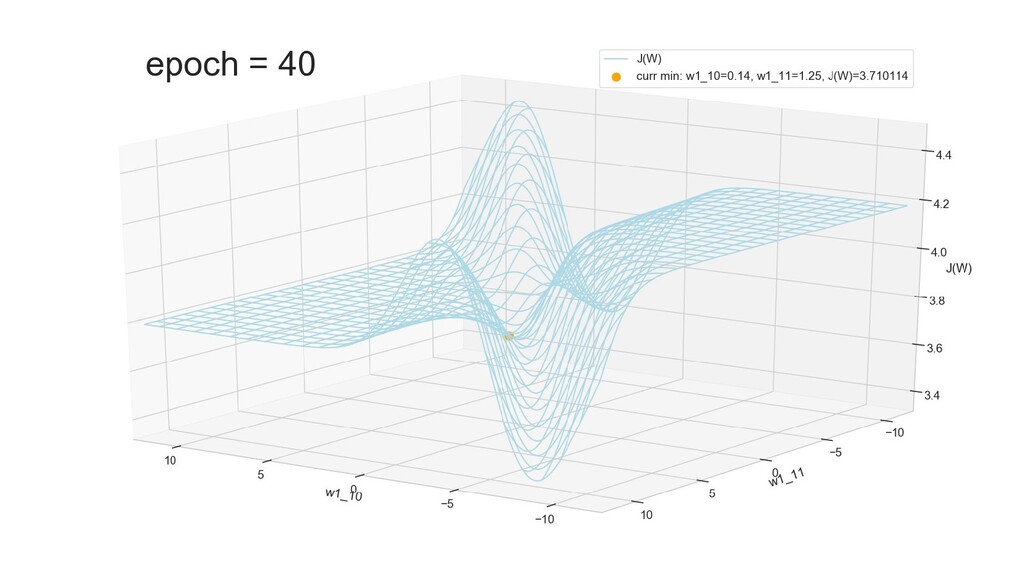
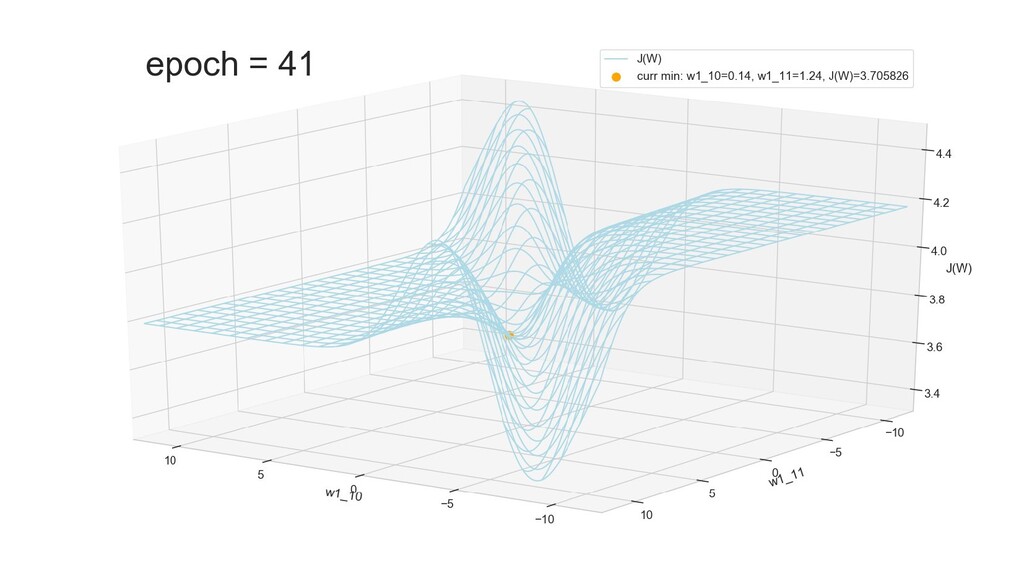
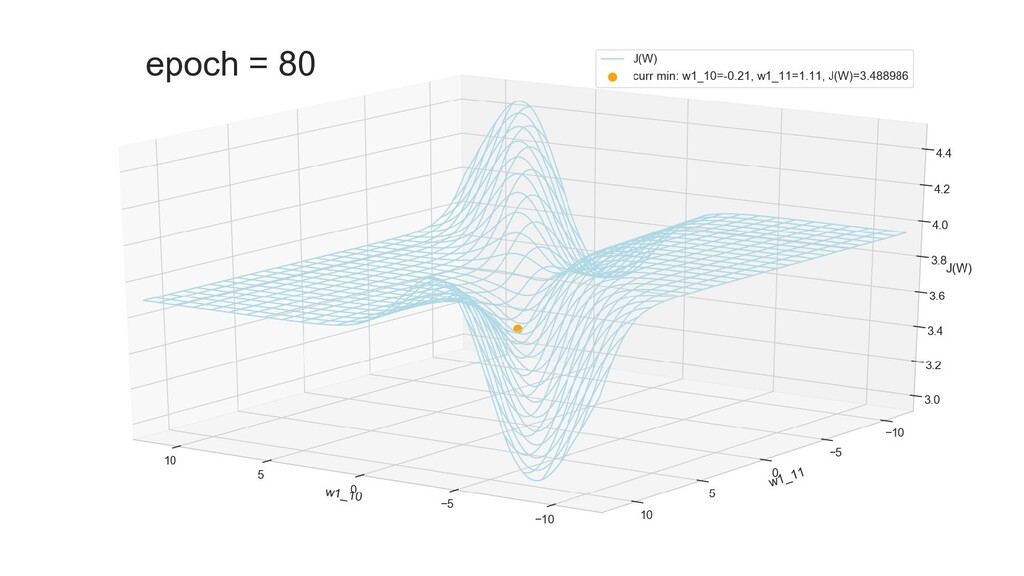
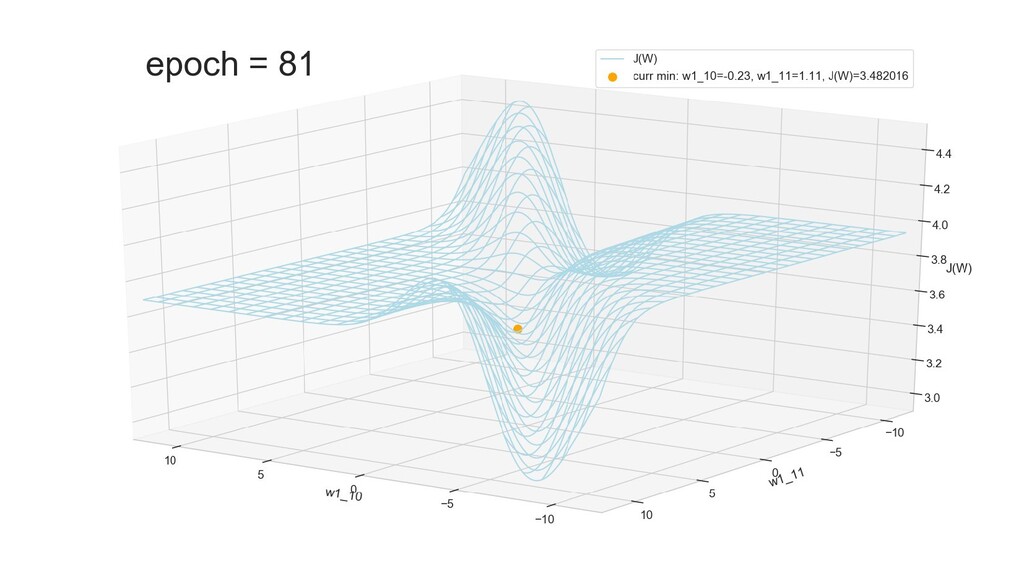
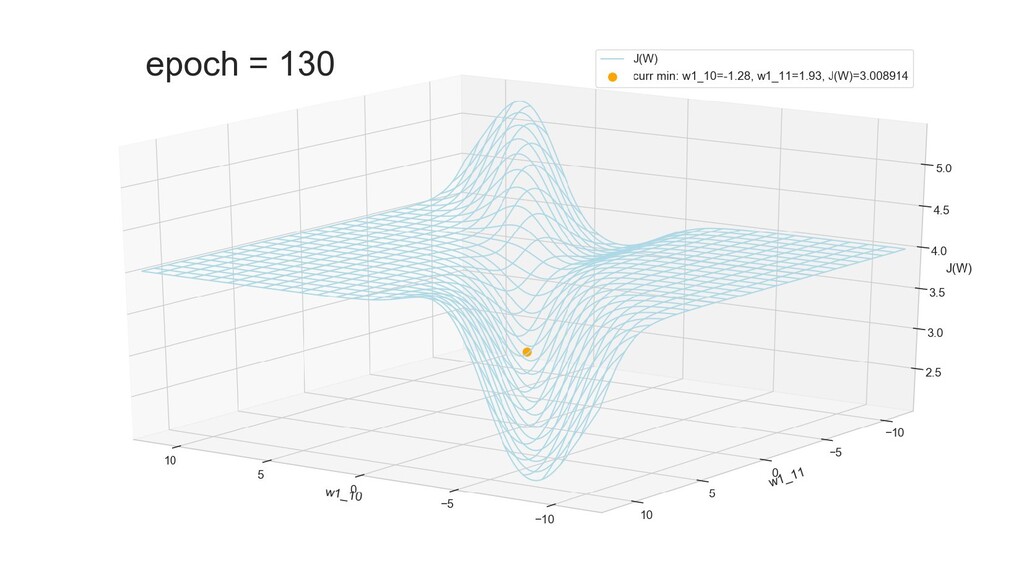
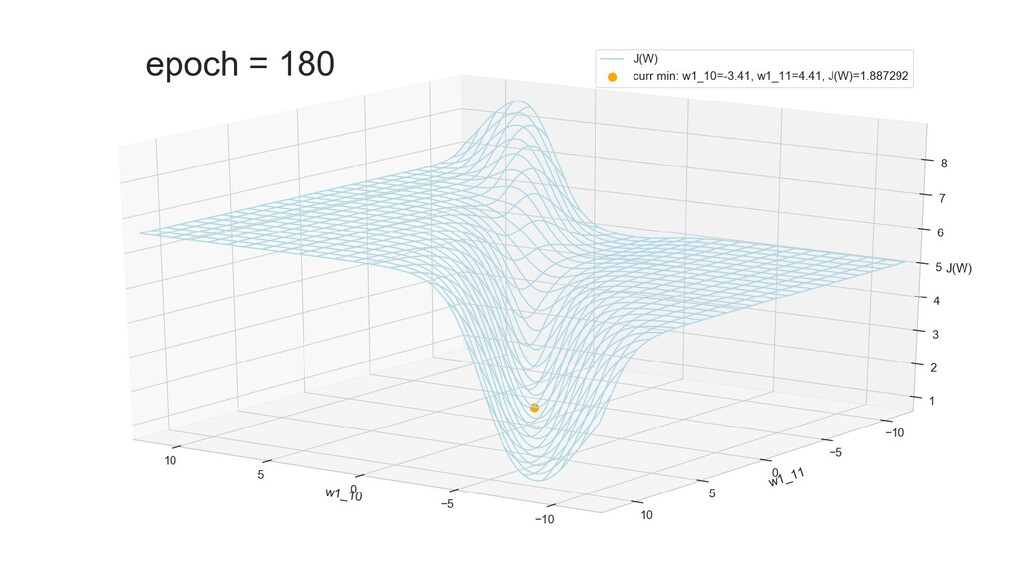
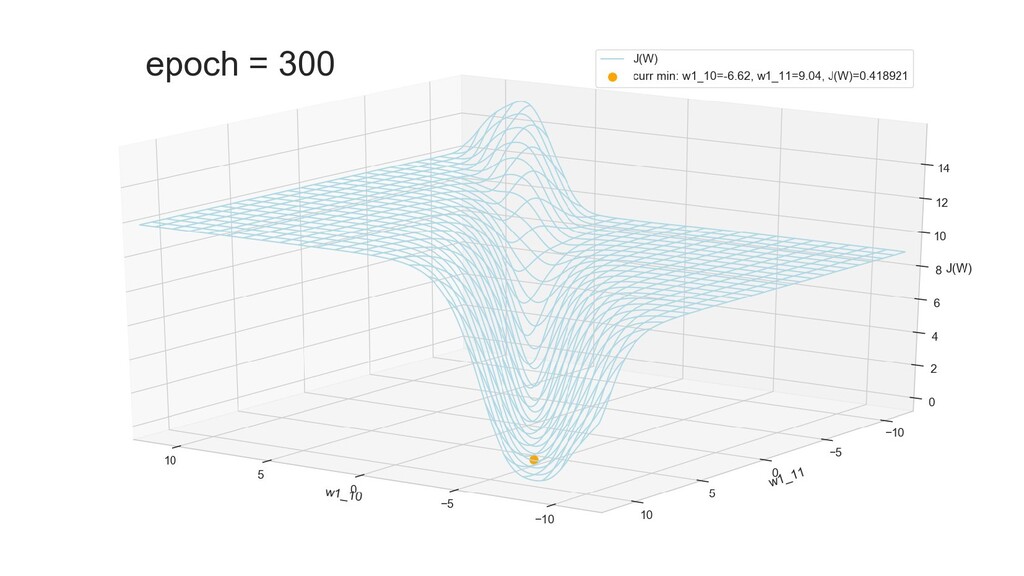
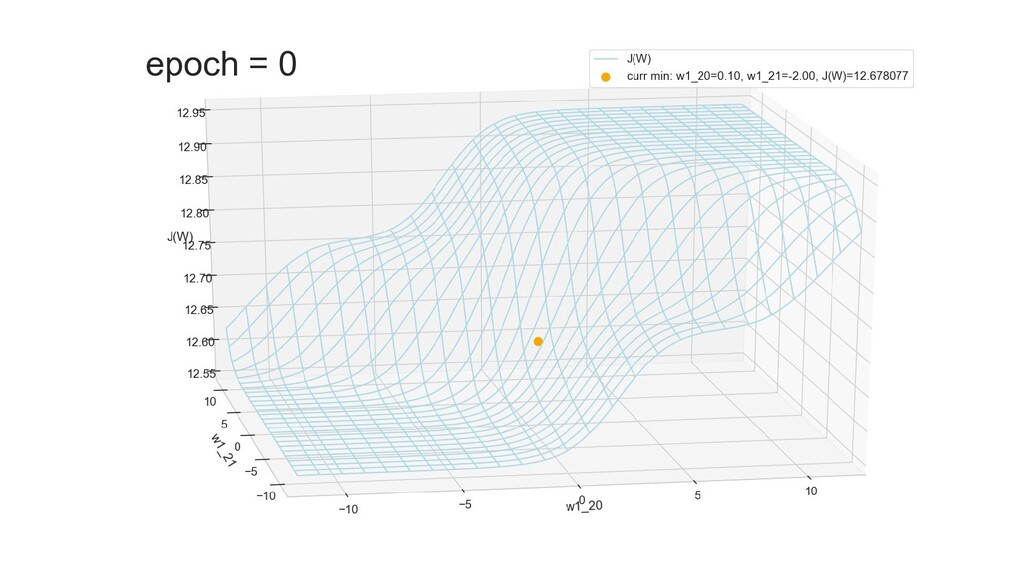
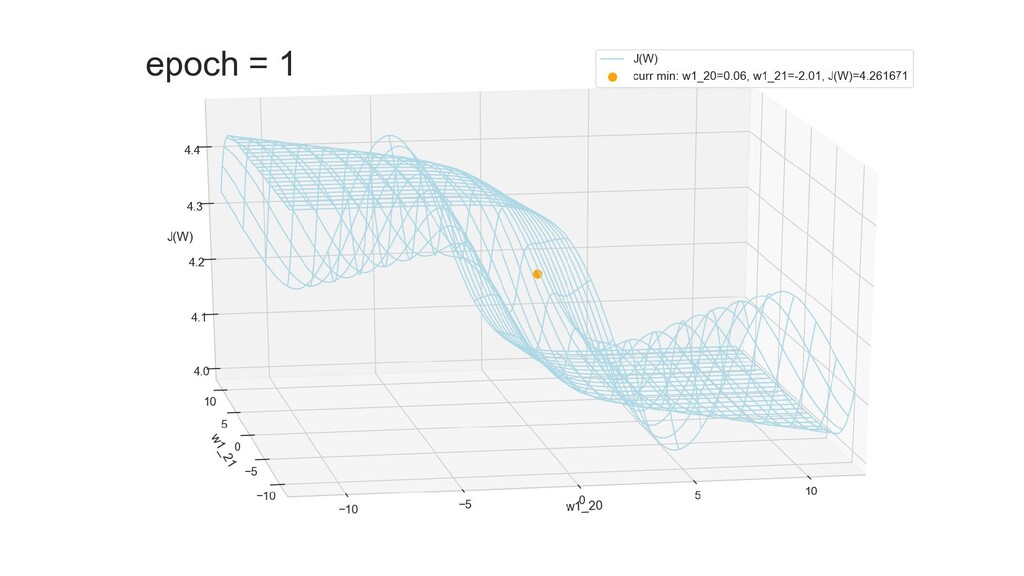
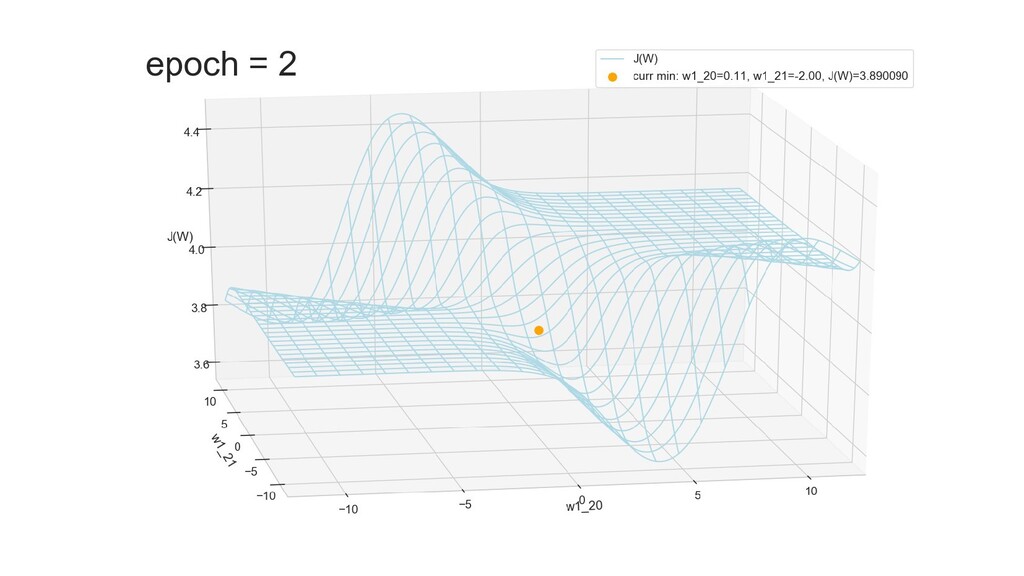
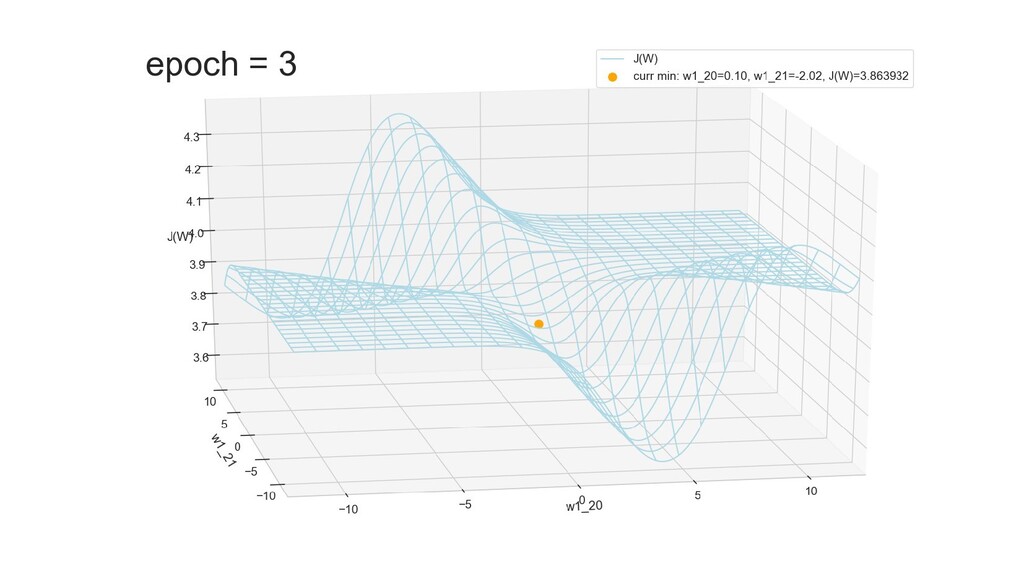
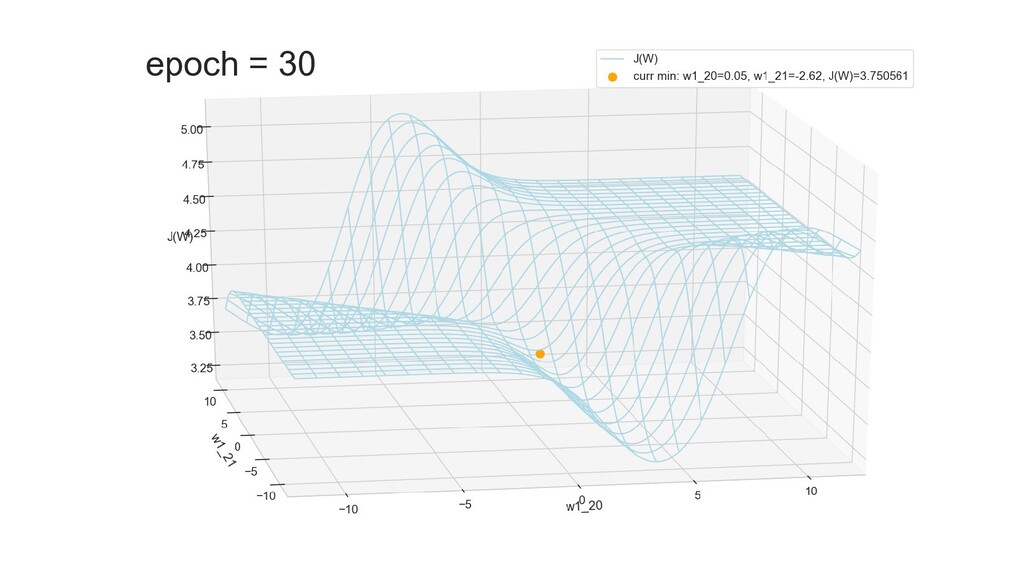
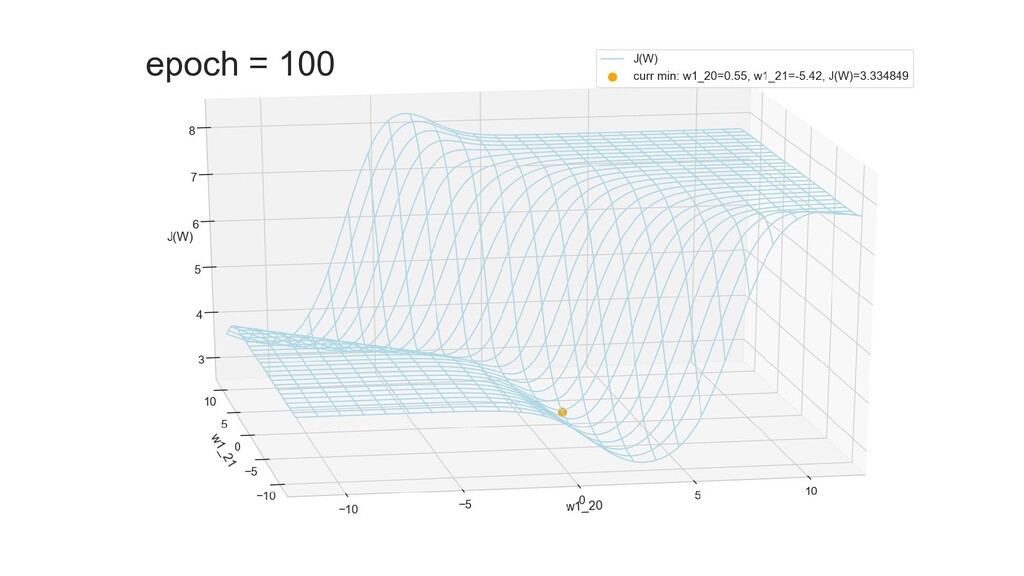
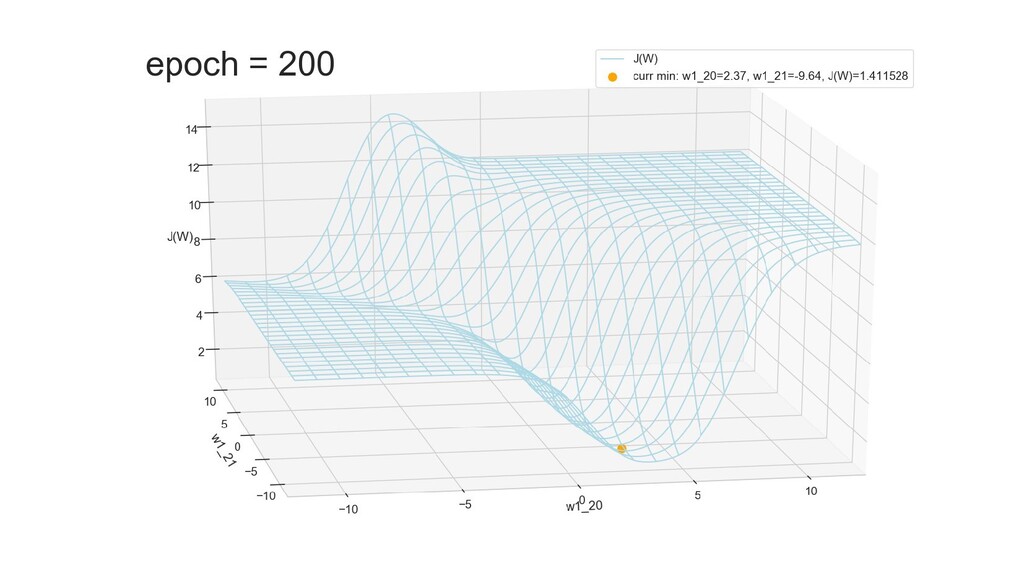
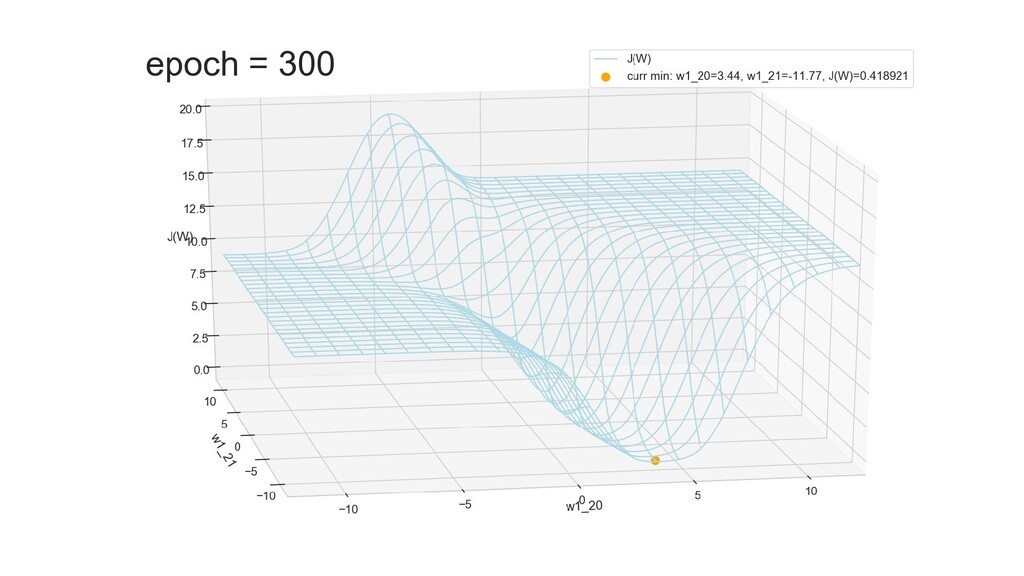
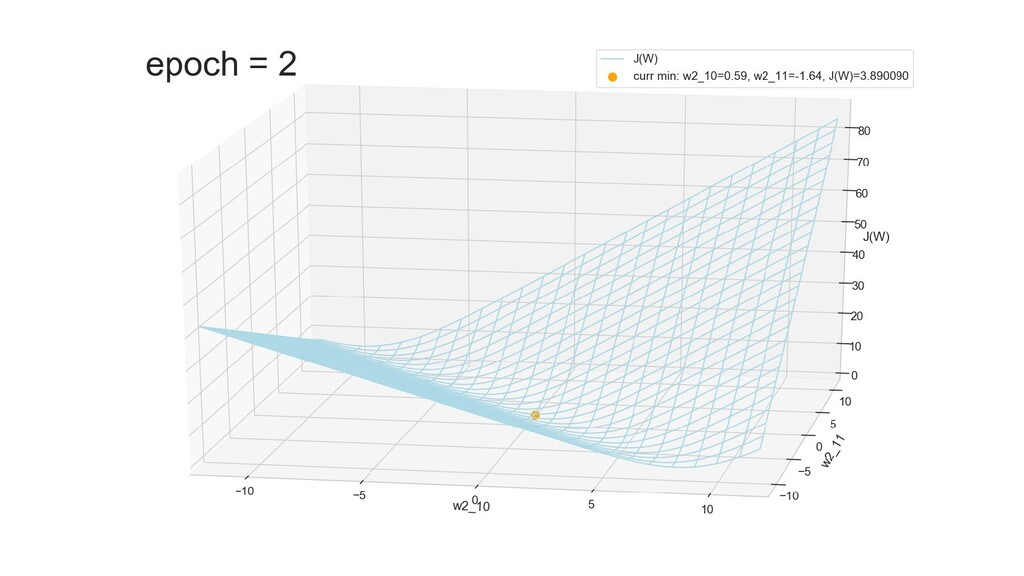
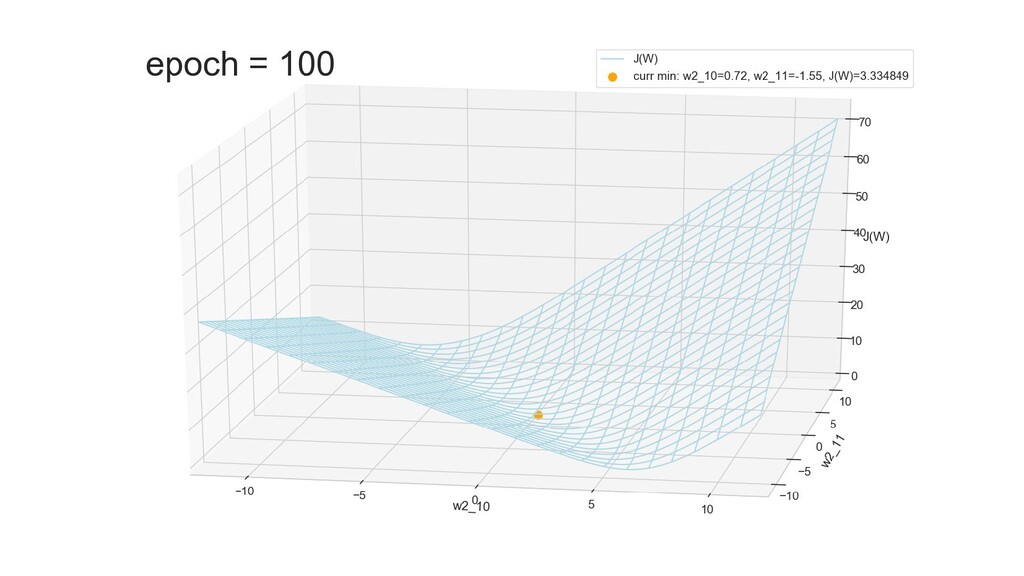
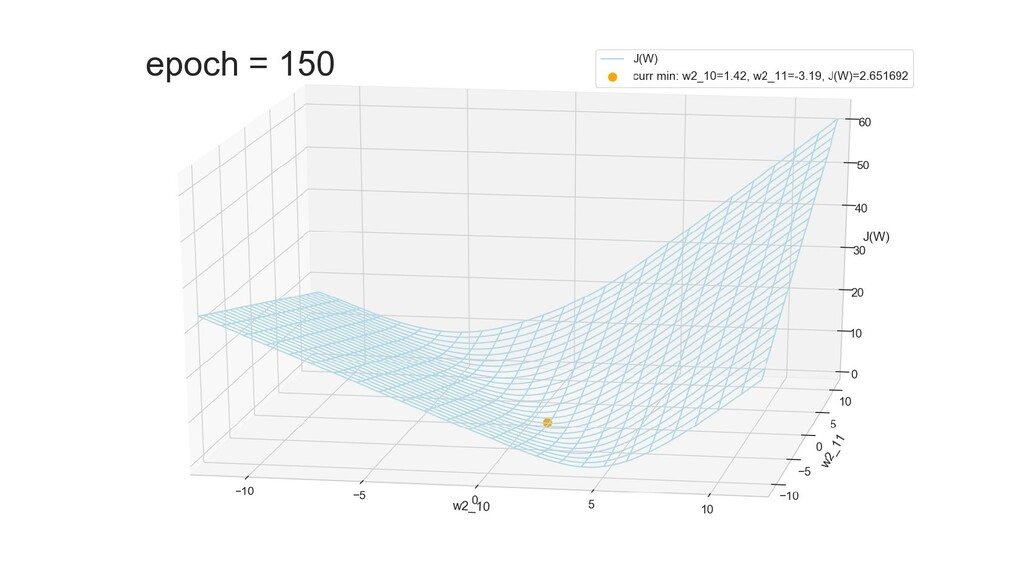
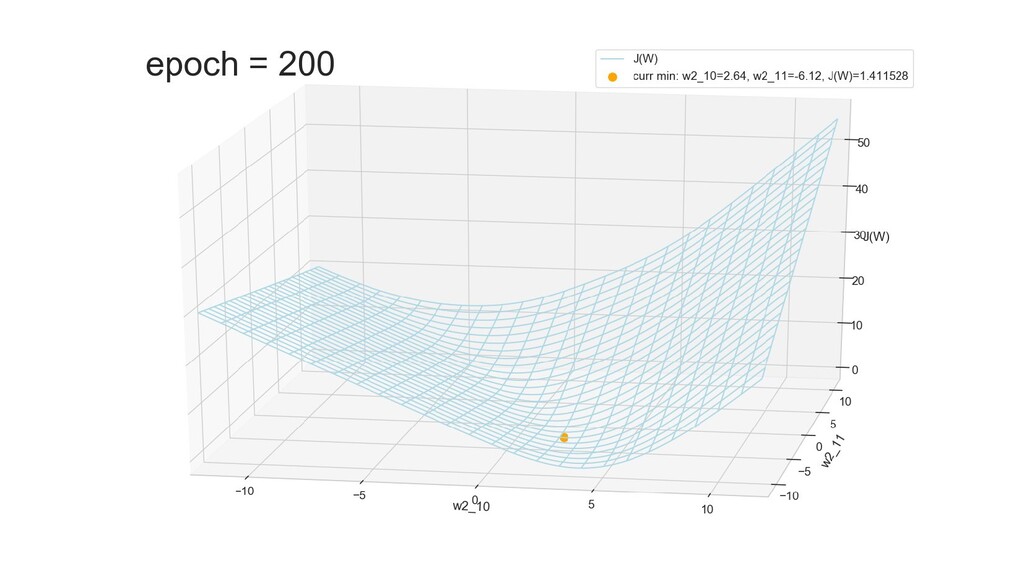
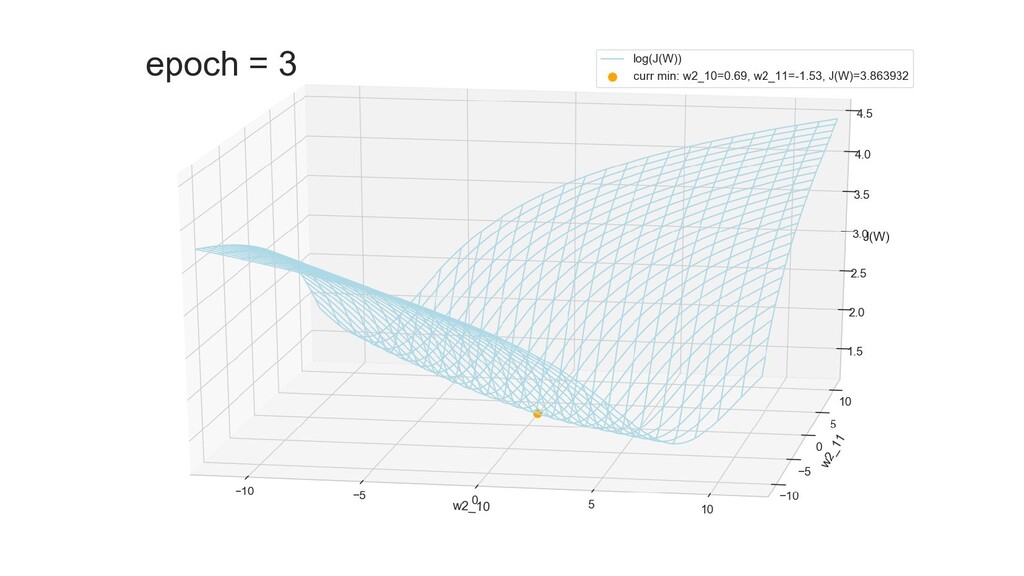
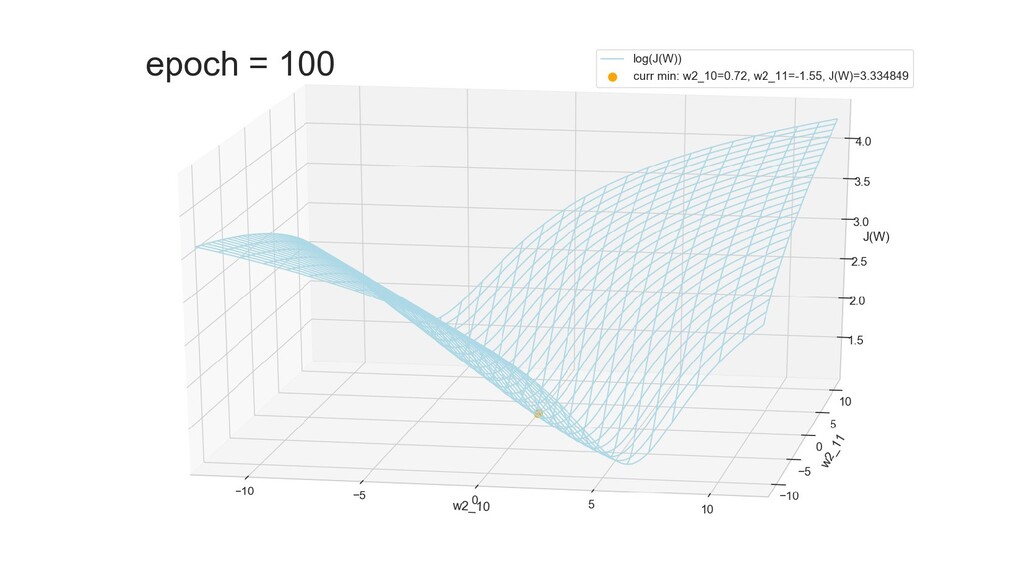
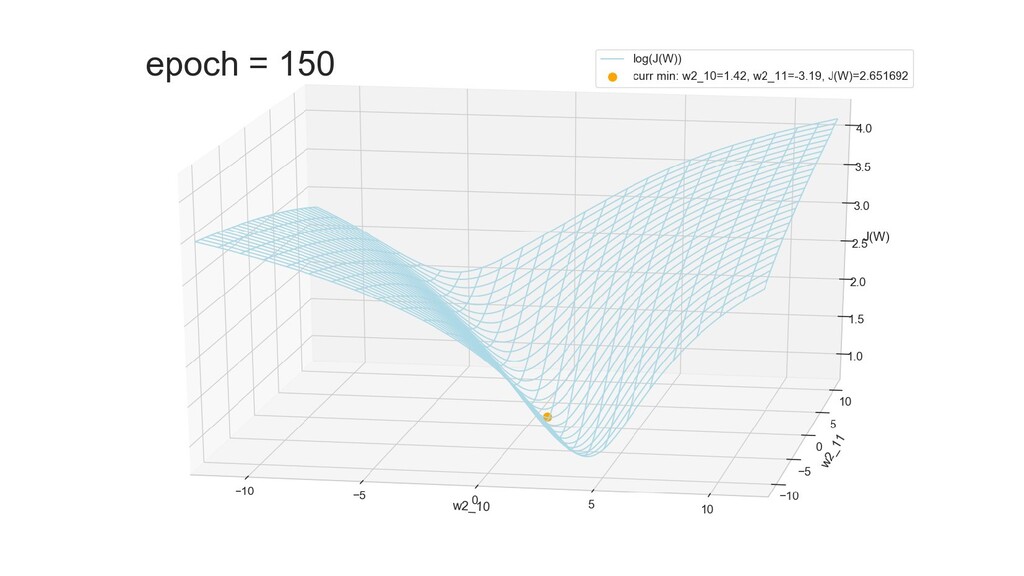
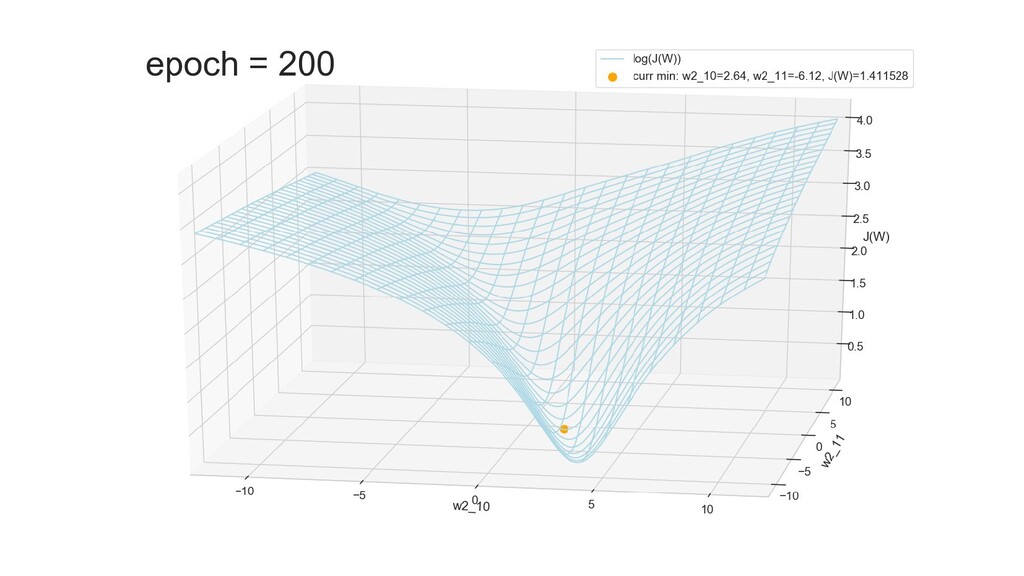
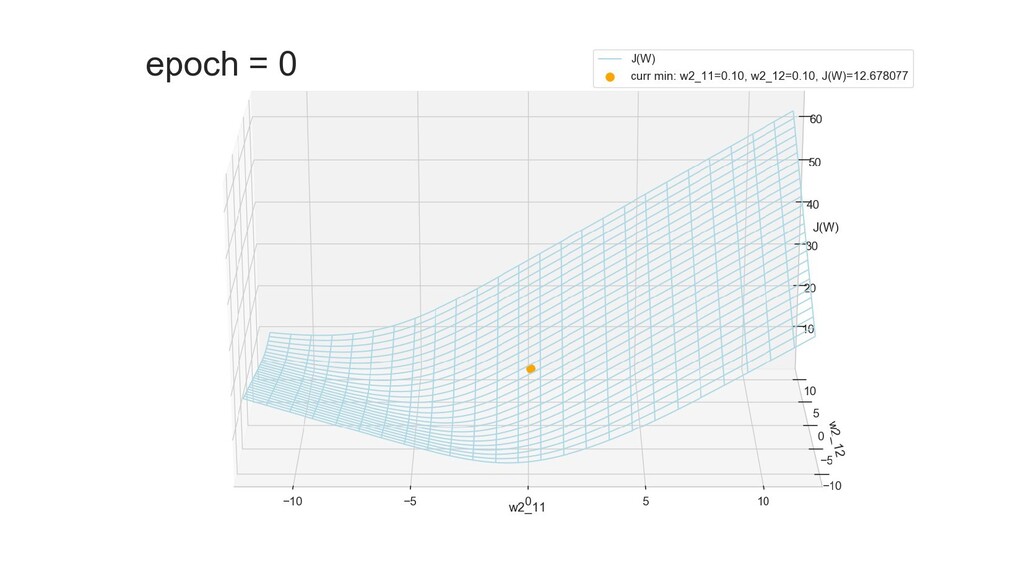
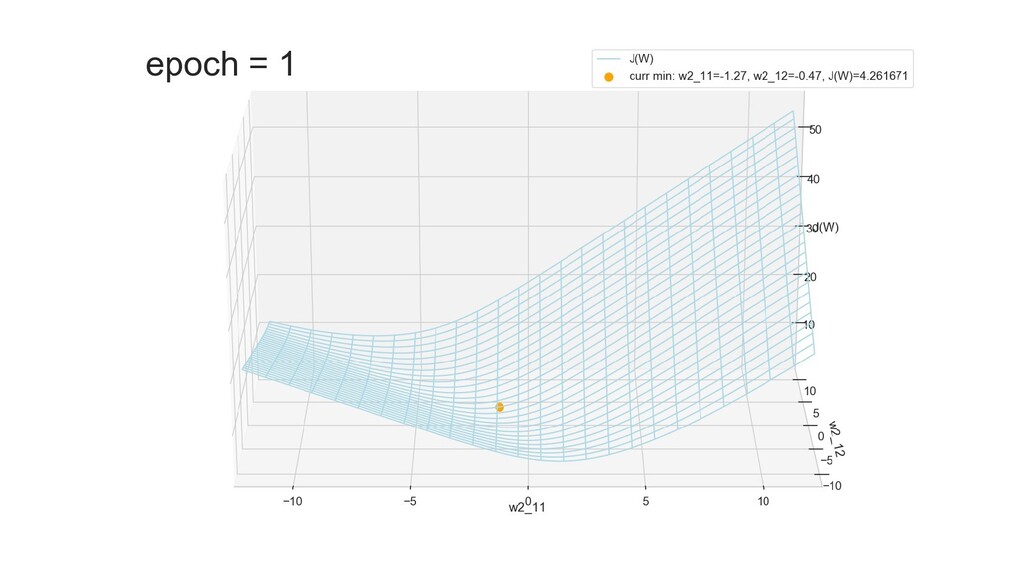
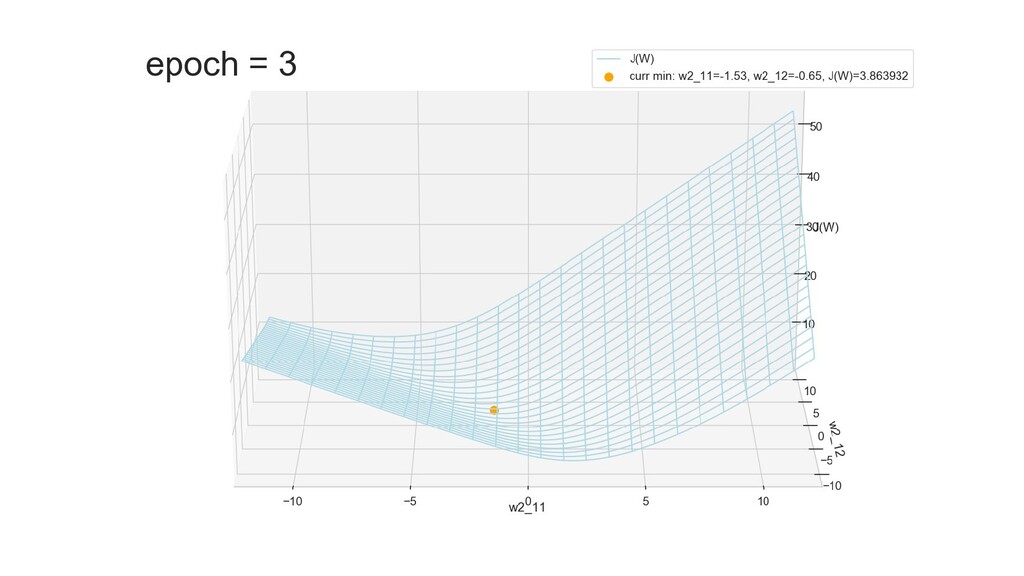
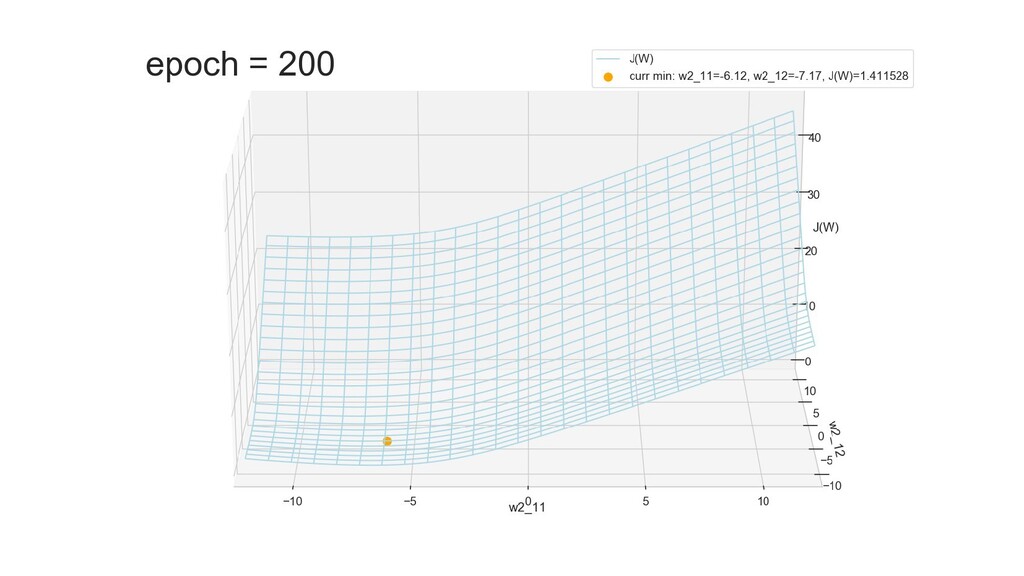
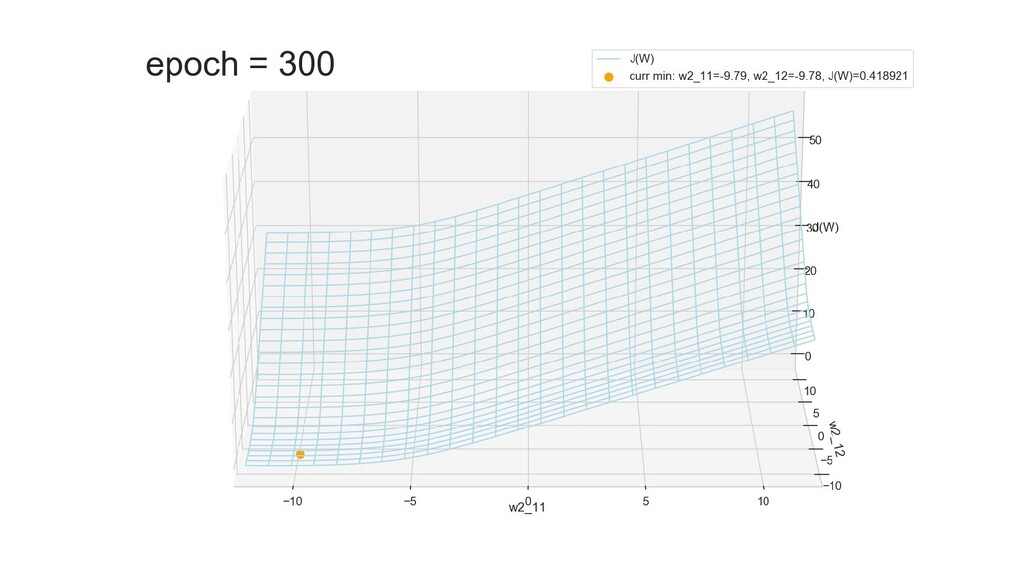
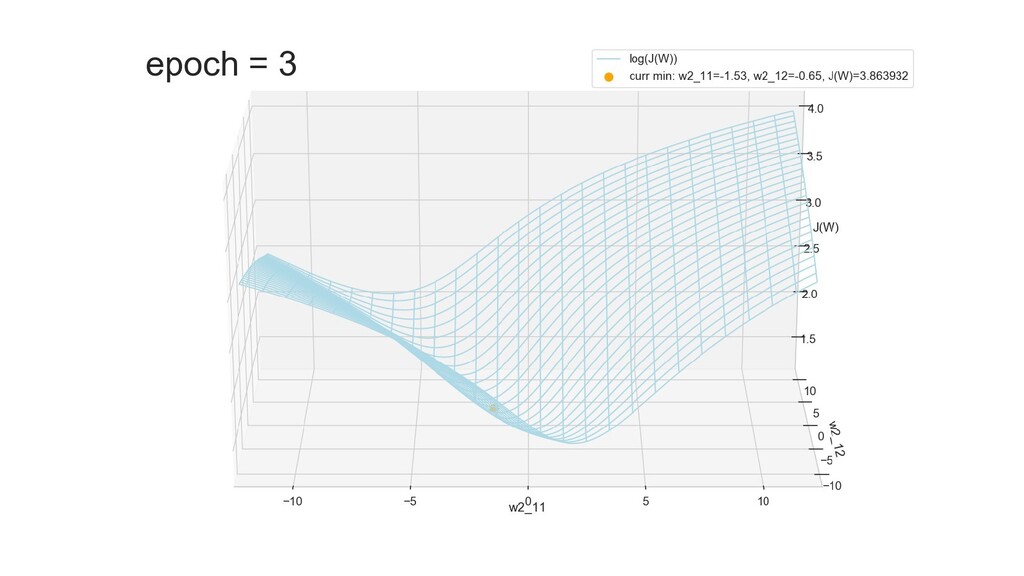
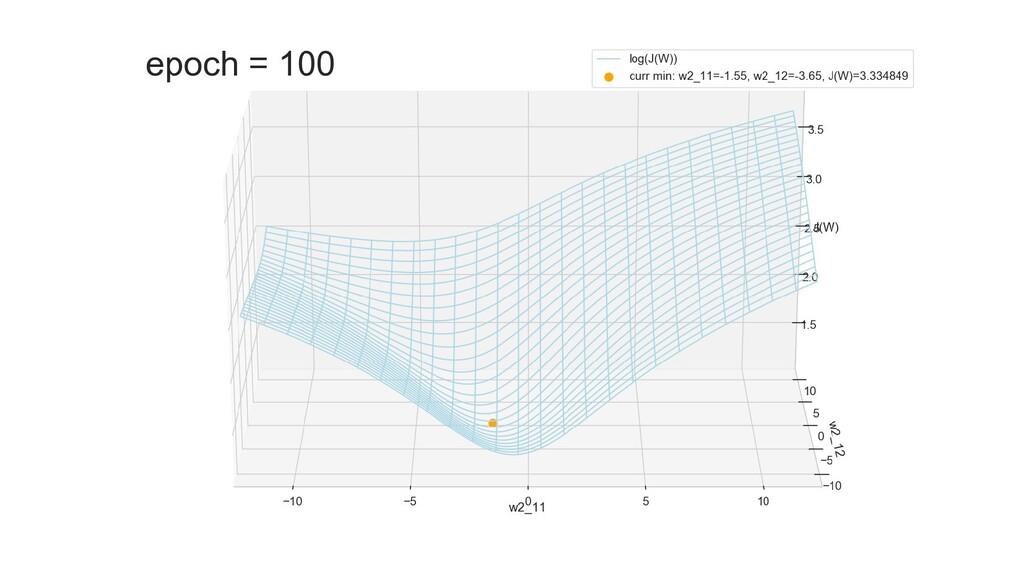
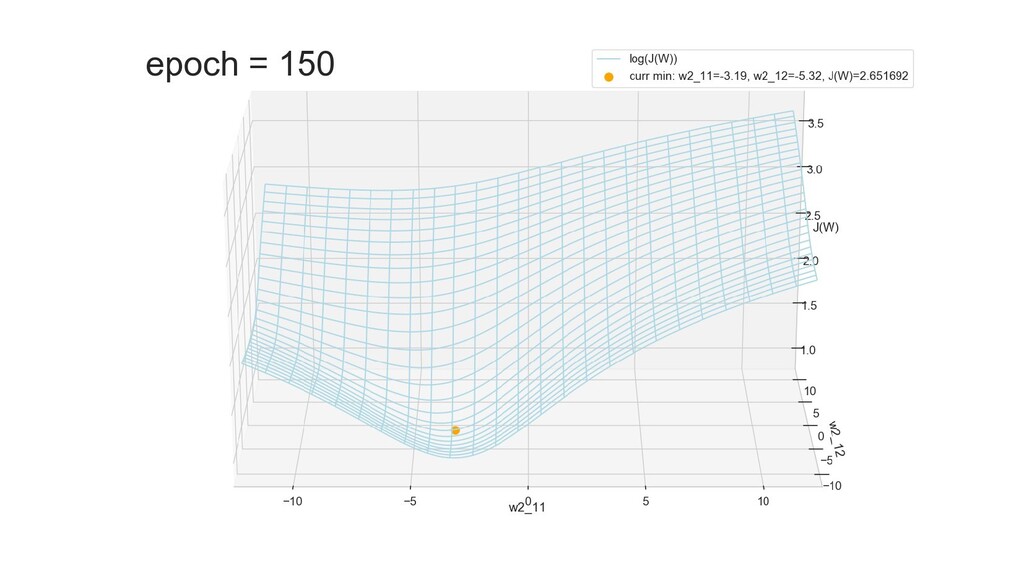
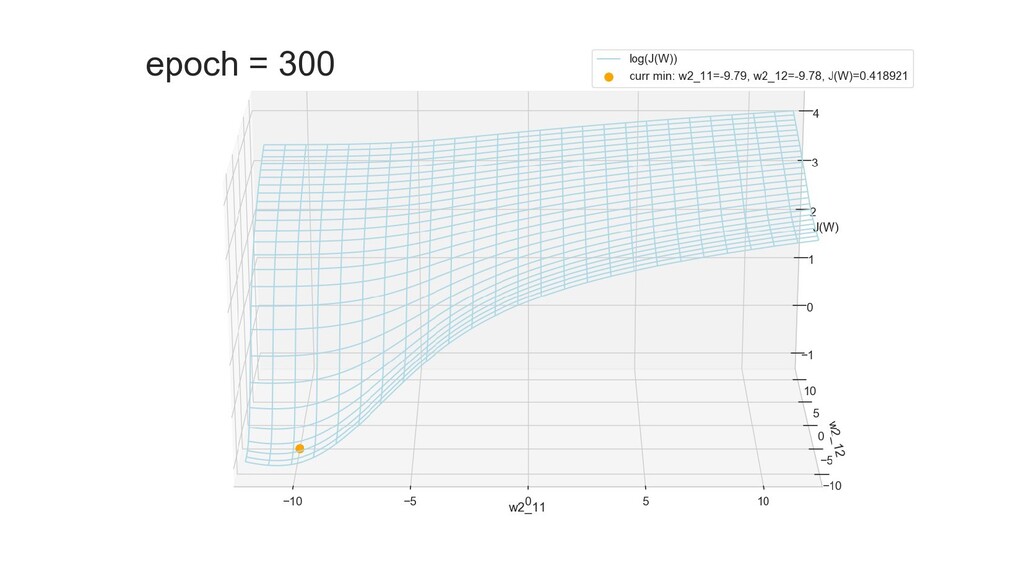
- Графическое представление спуска по каждому из параметров - особенности функции стоимости на каждом из срезов
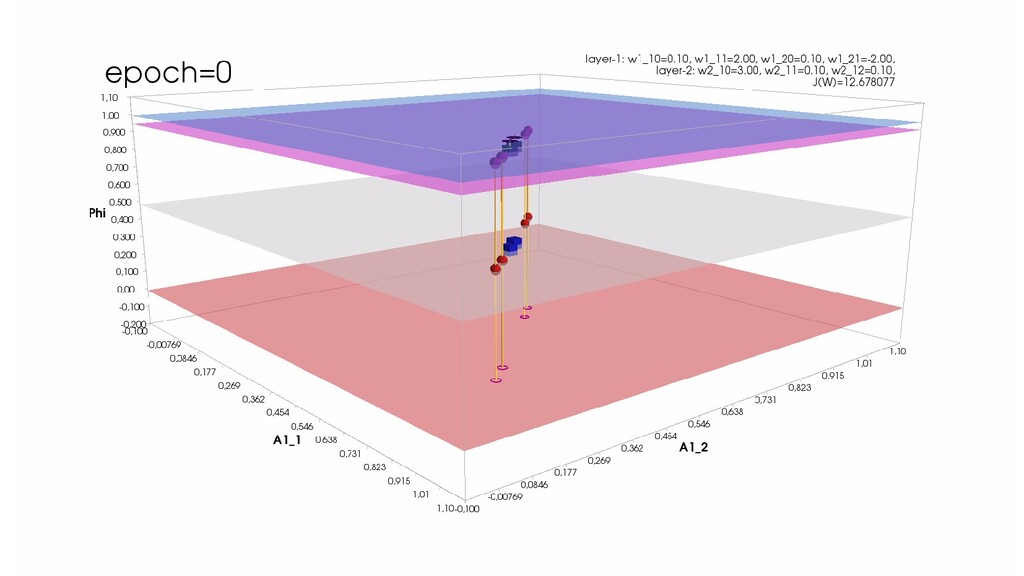
- Положение активаций на нейронах 1-го слоя
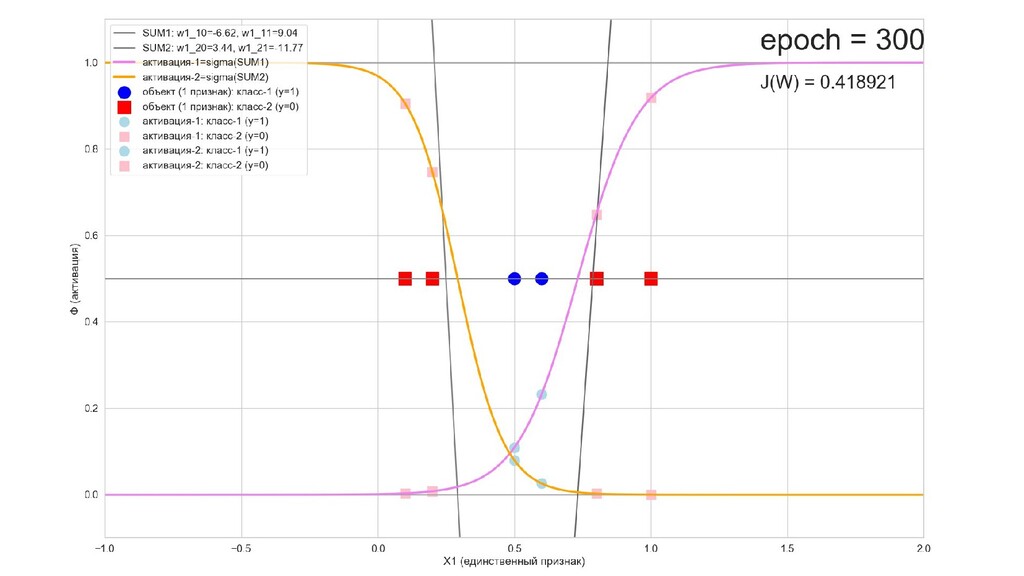
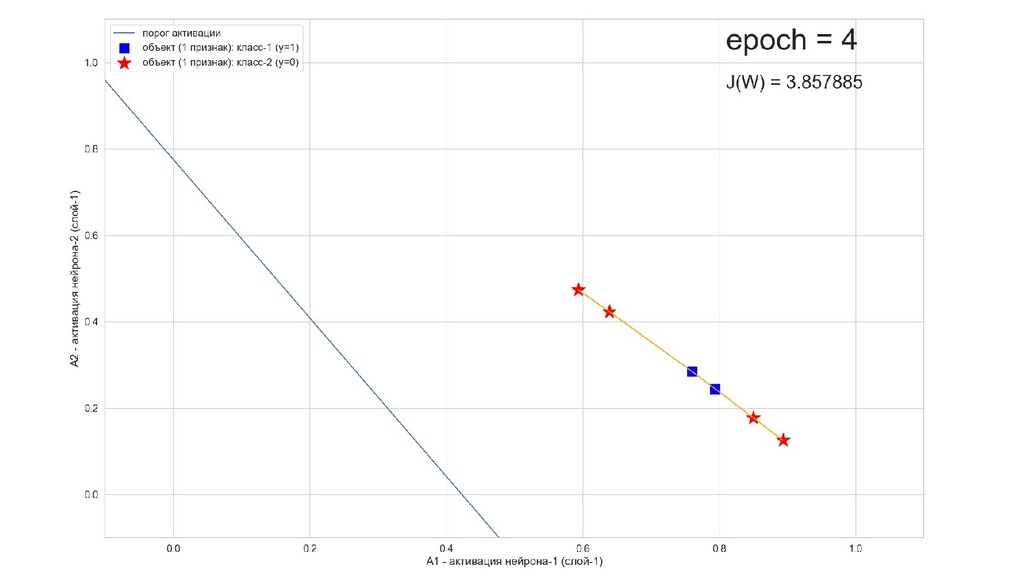
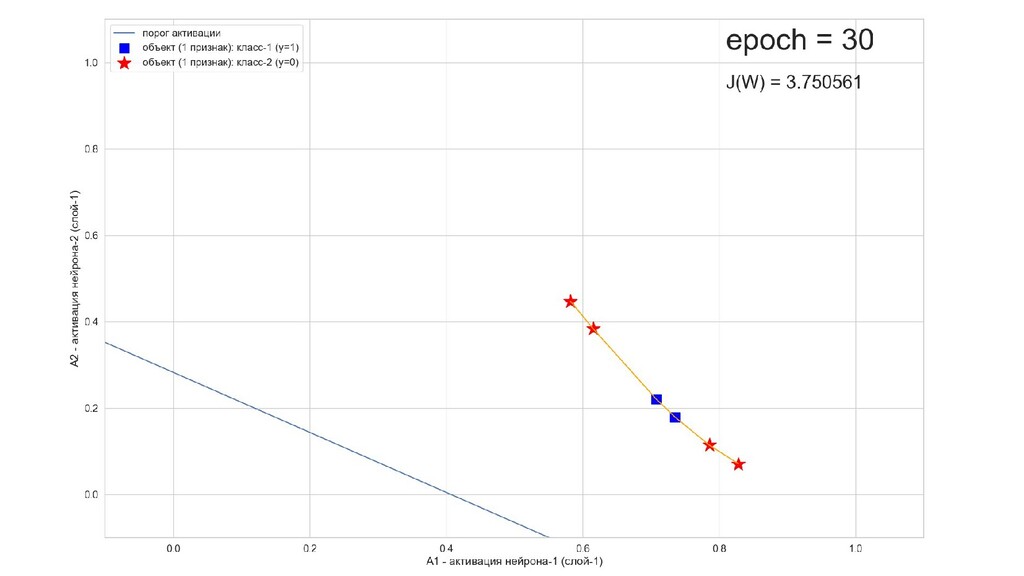
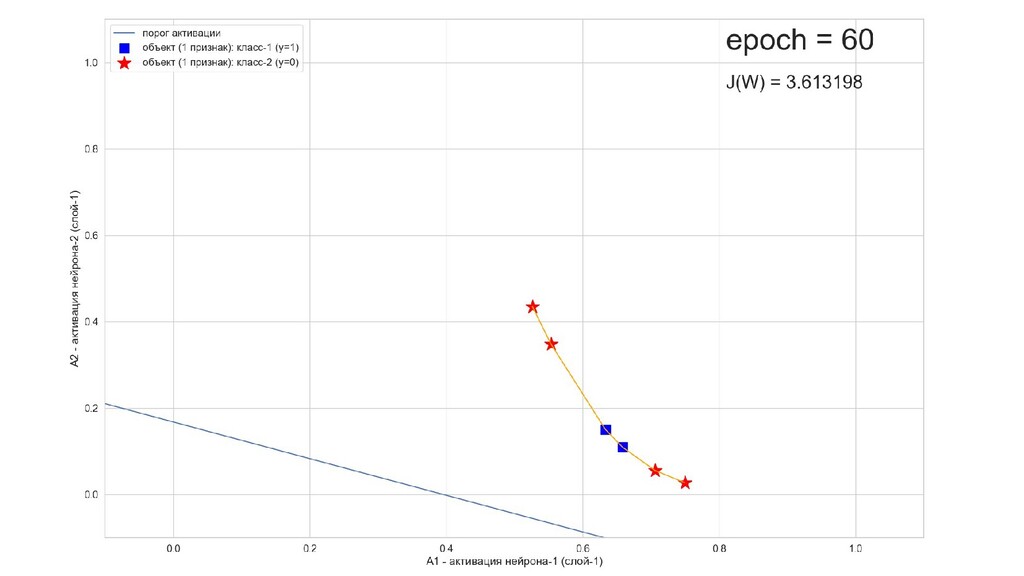
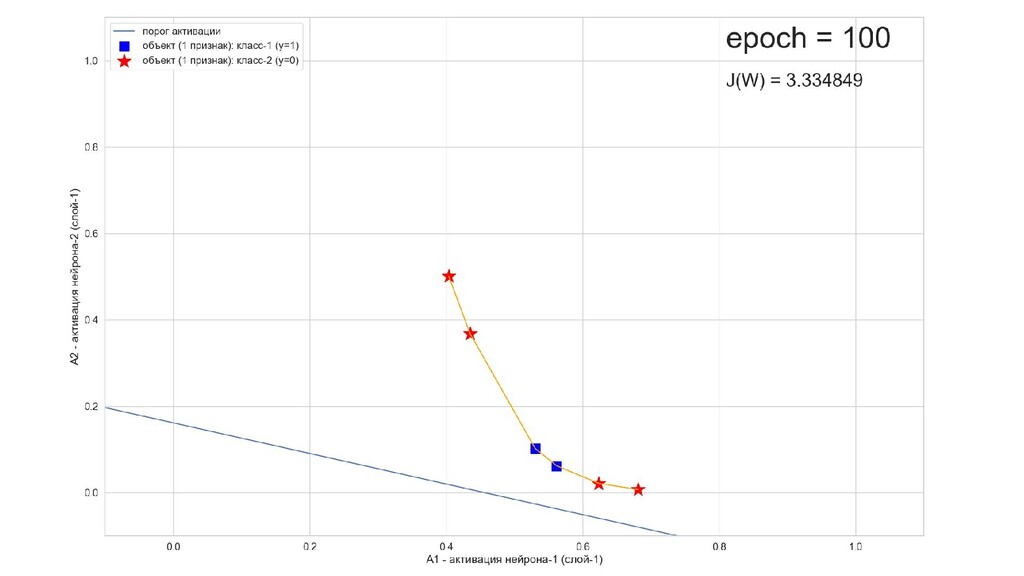
- Активация на выходном нейроне, представление 2-д: разделяющая линия - пересечение активации с плоскостью объектов-проекций на входе выходного нейрона
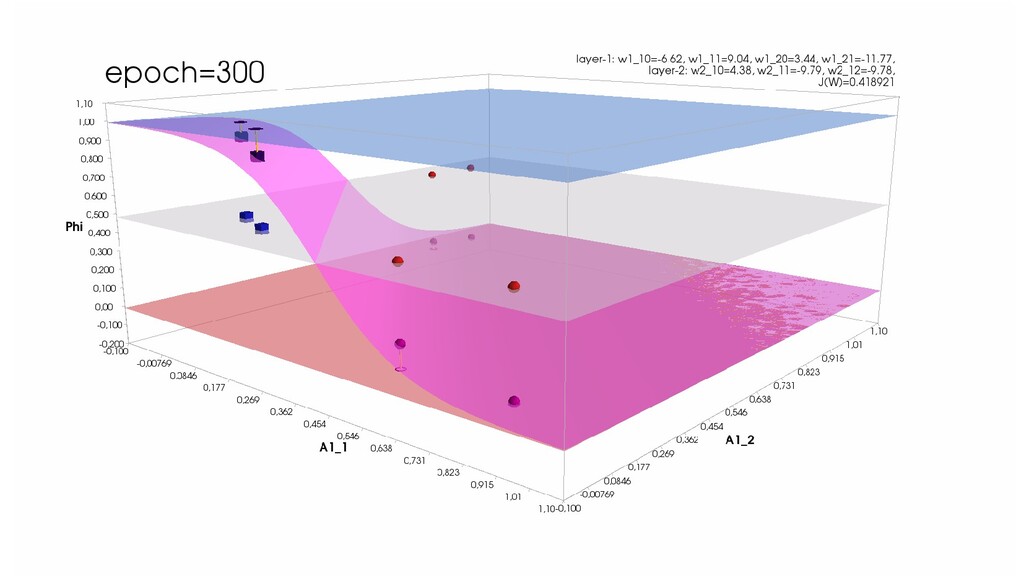
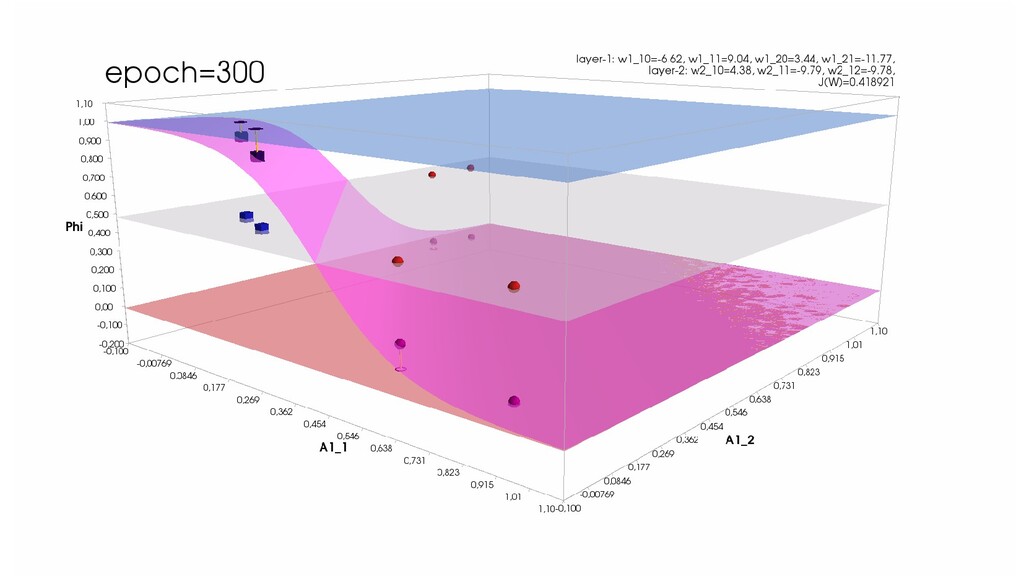
- Активация на выходном нейроне, представление 3-д: изогнутая сигмой поверхность активации пересекает плоскость объектов-проекций и назначает им классы
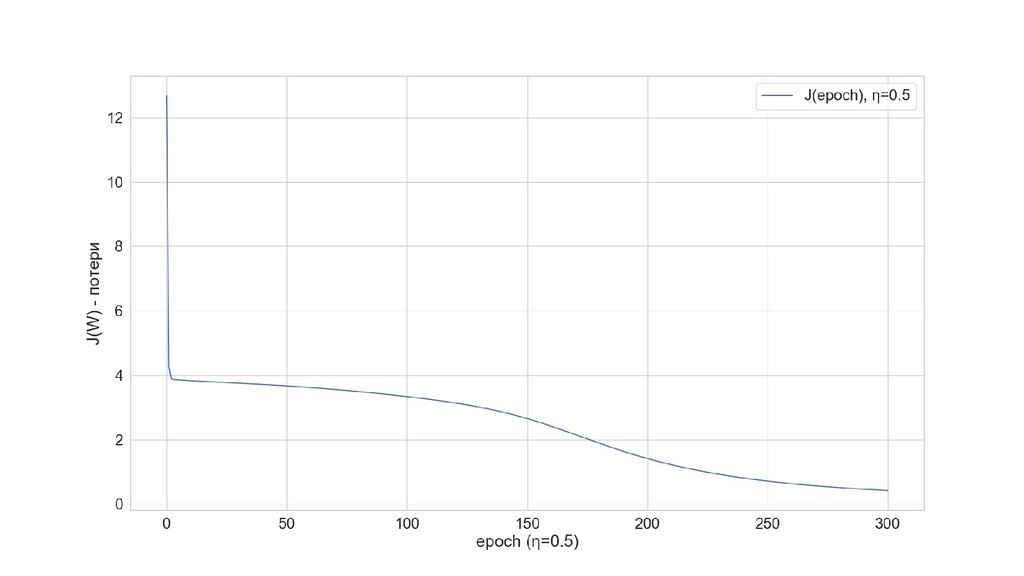
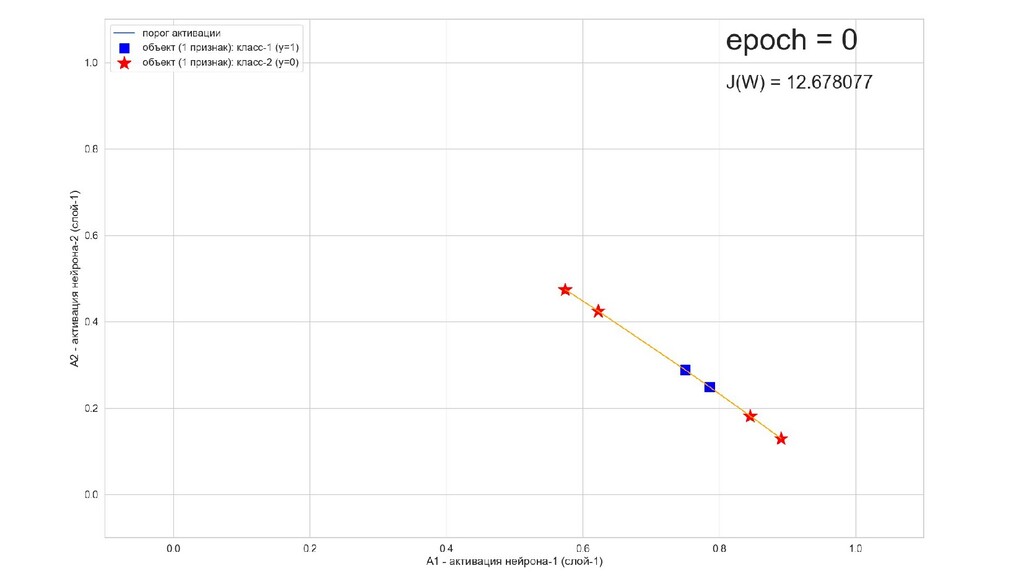
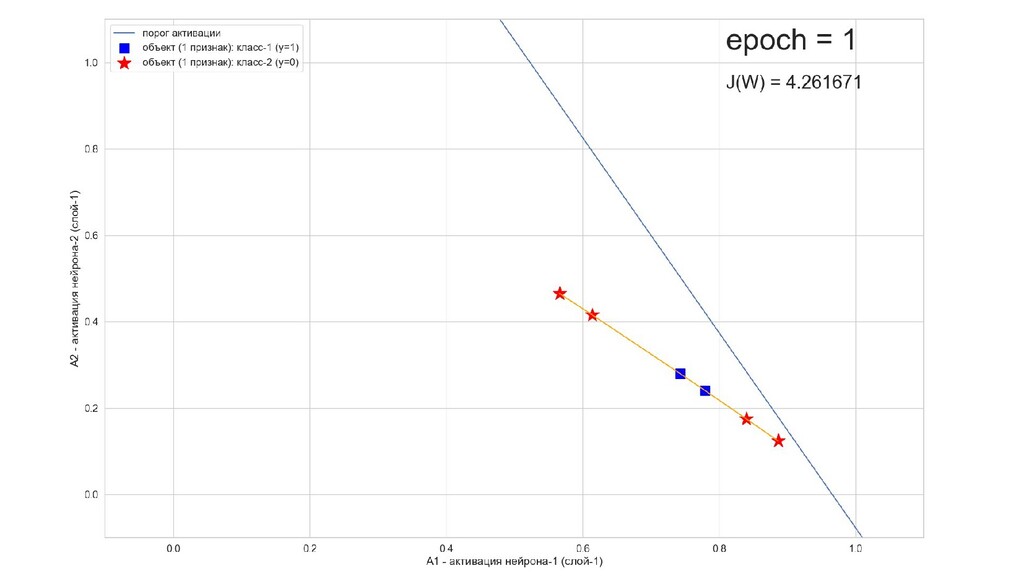
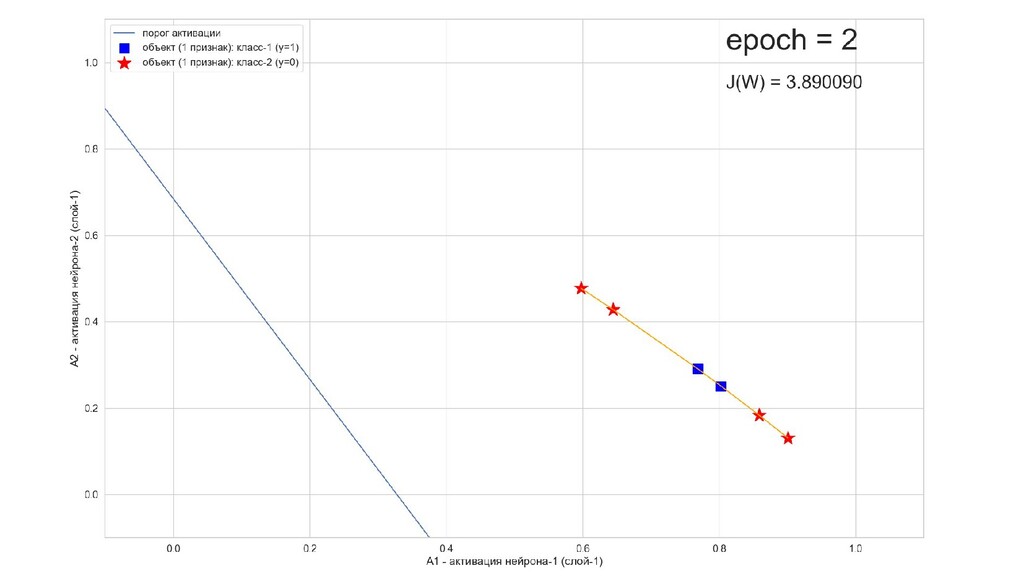
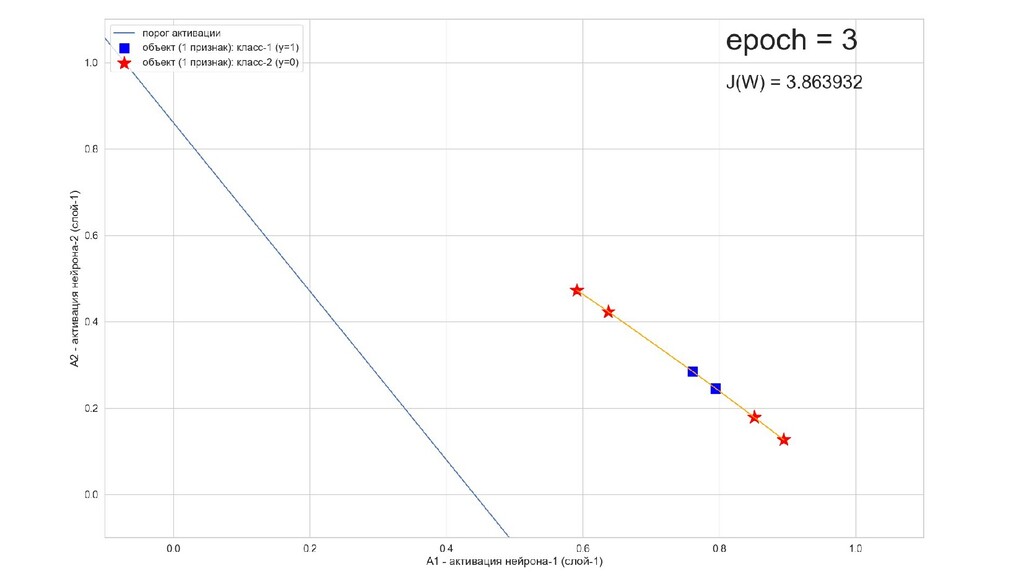
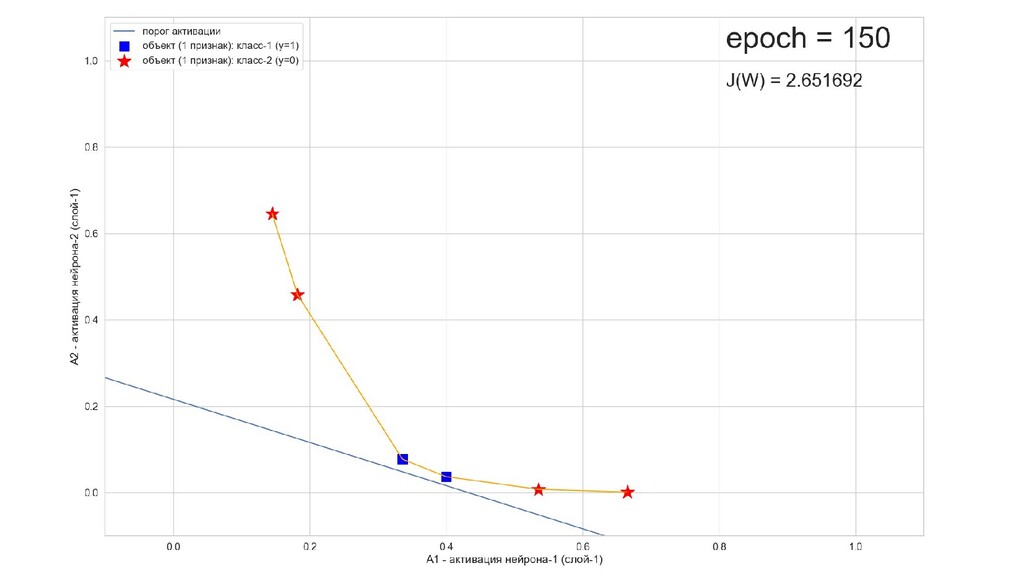
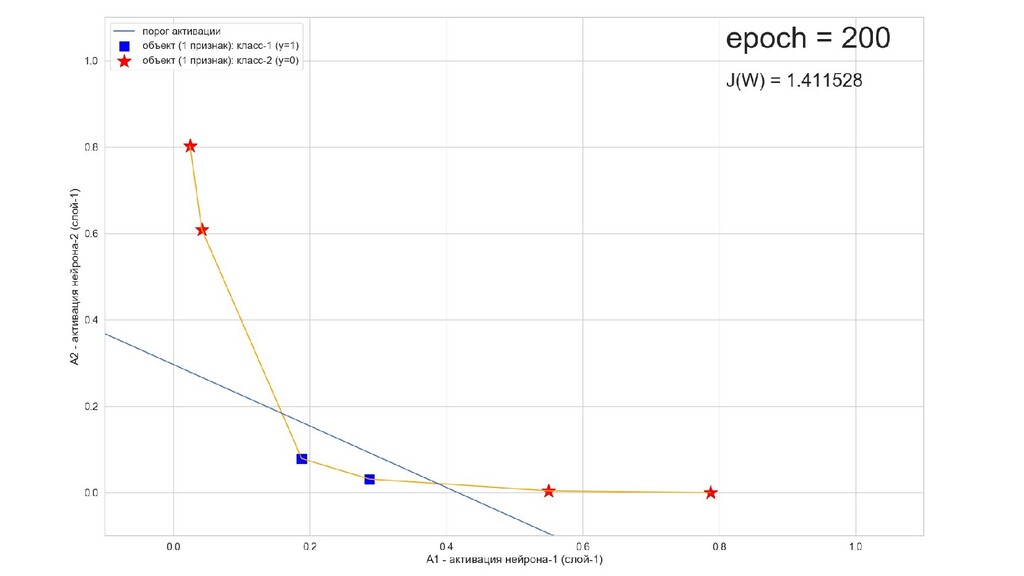
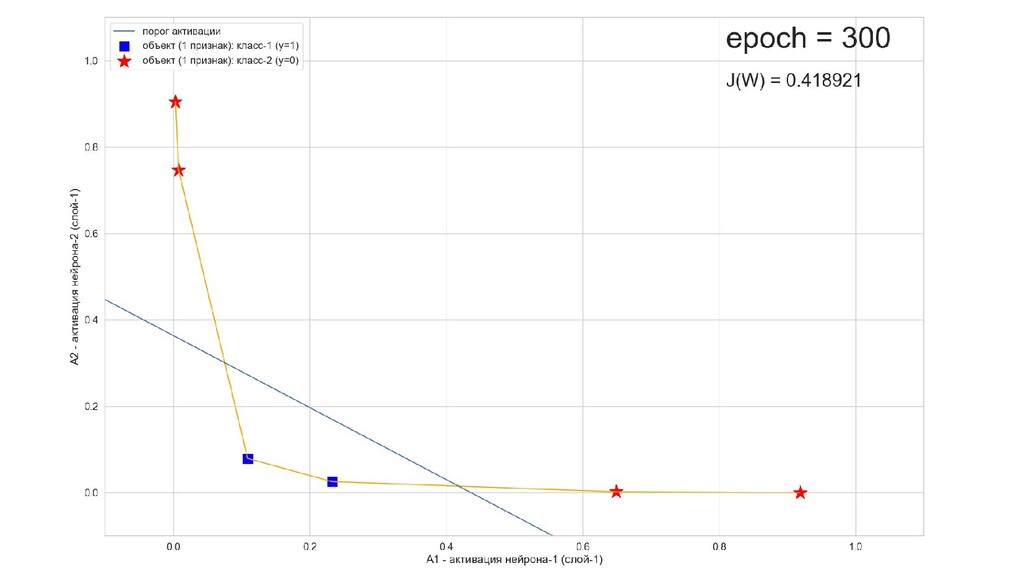
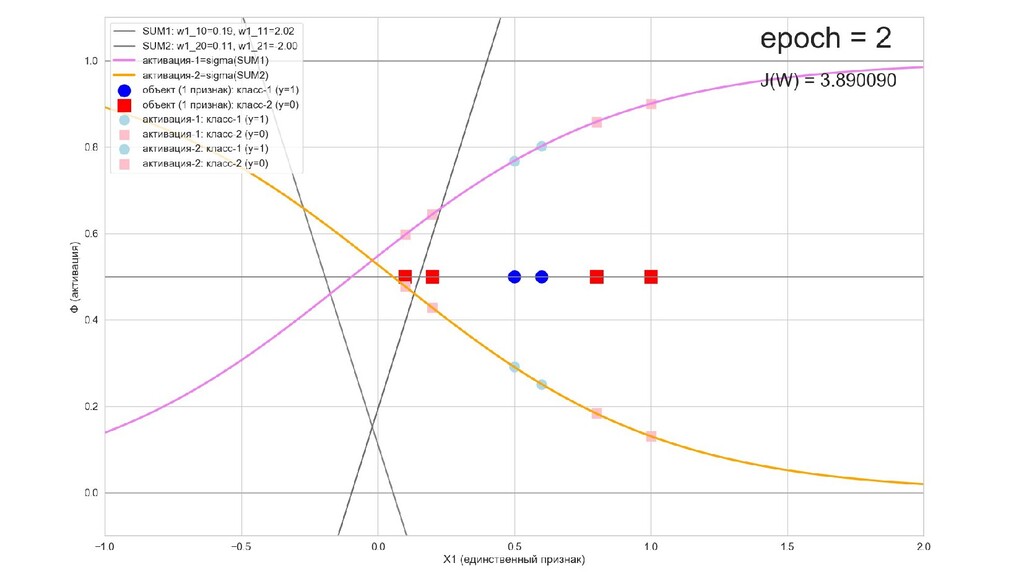
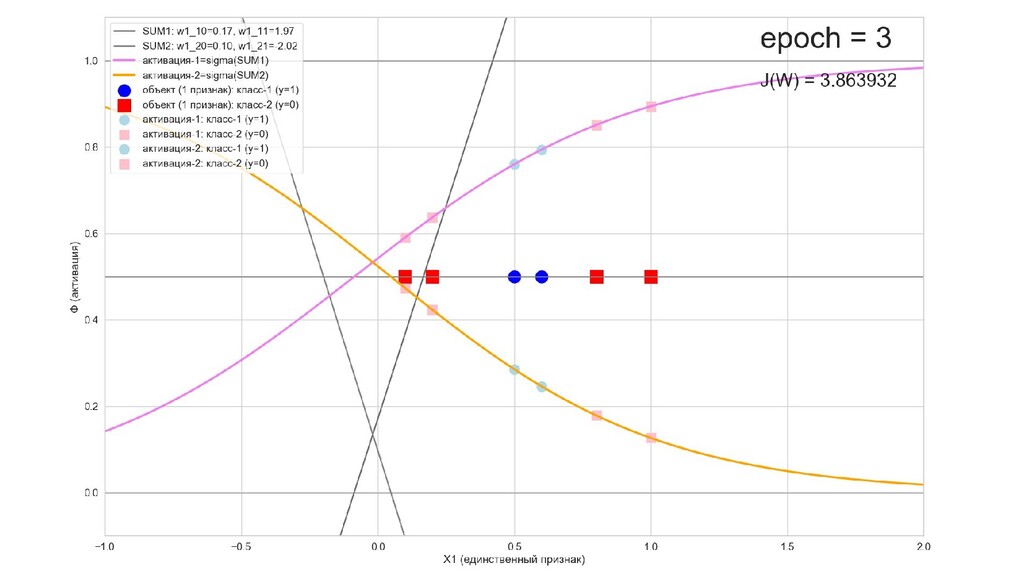
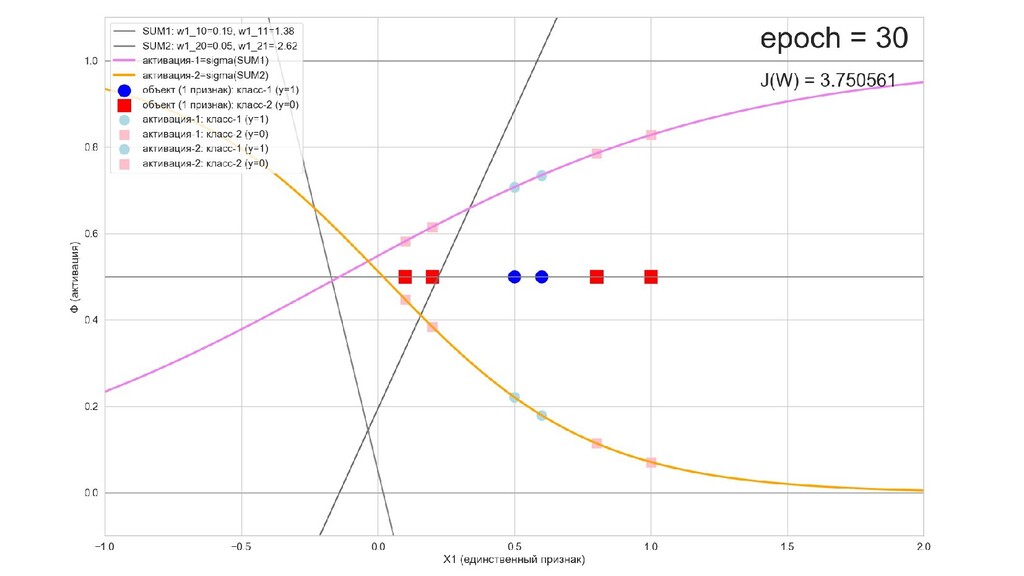
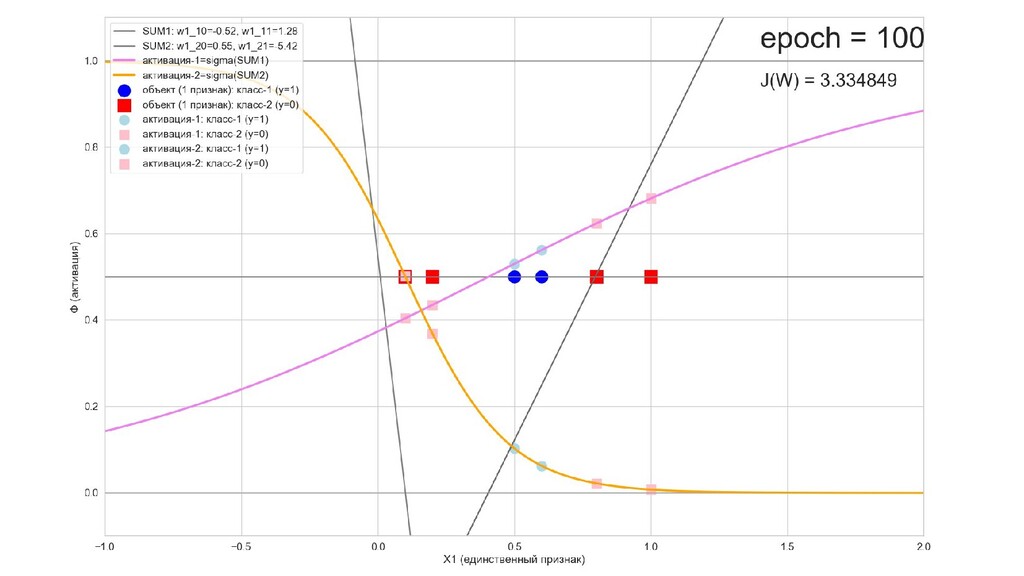
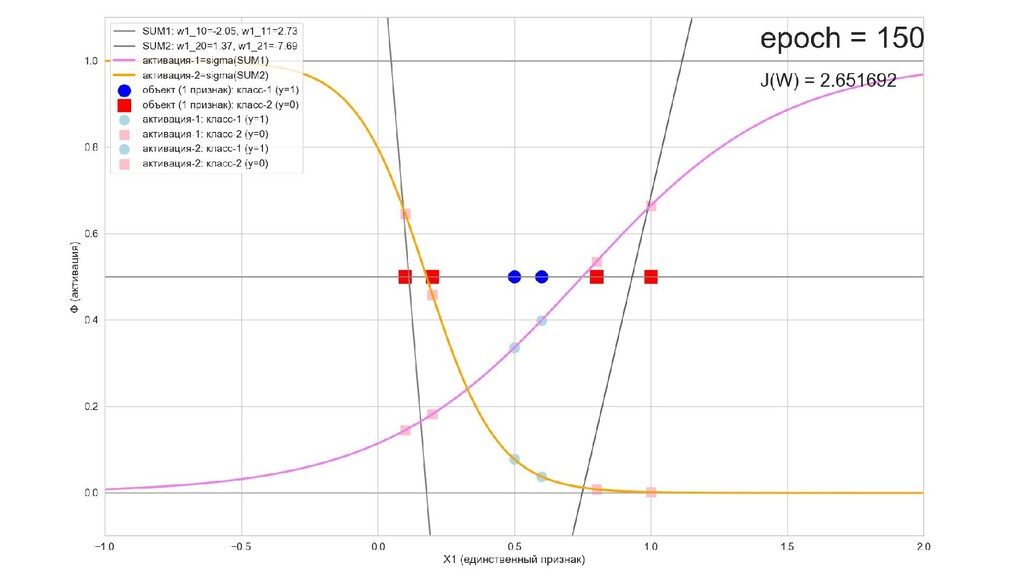
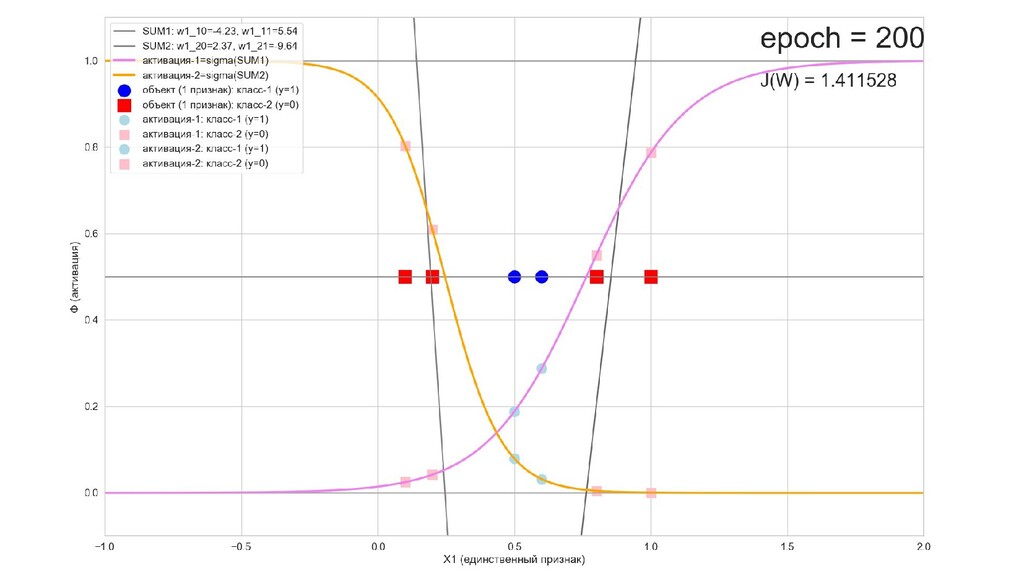
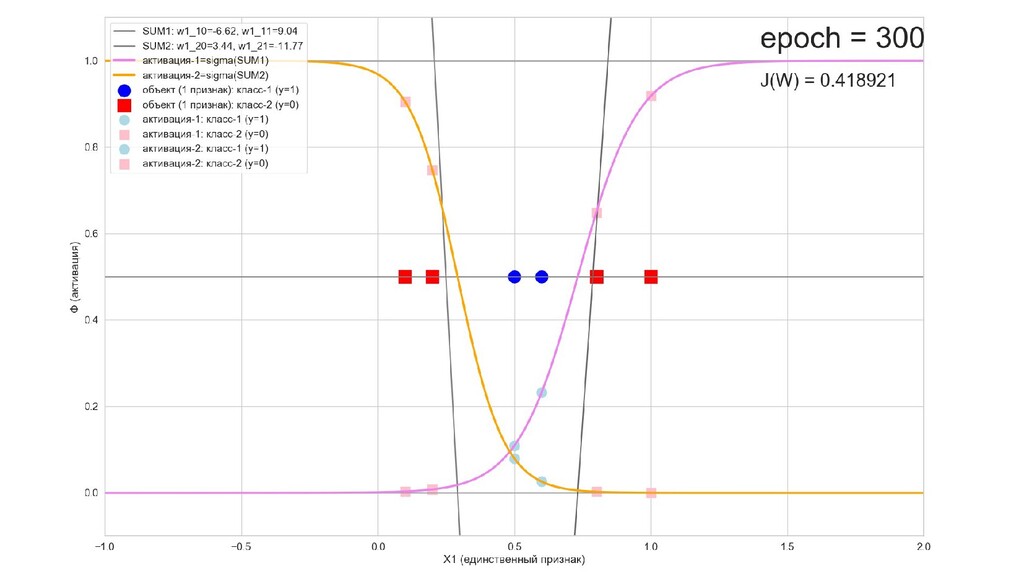
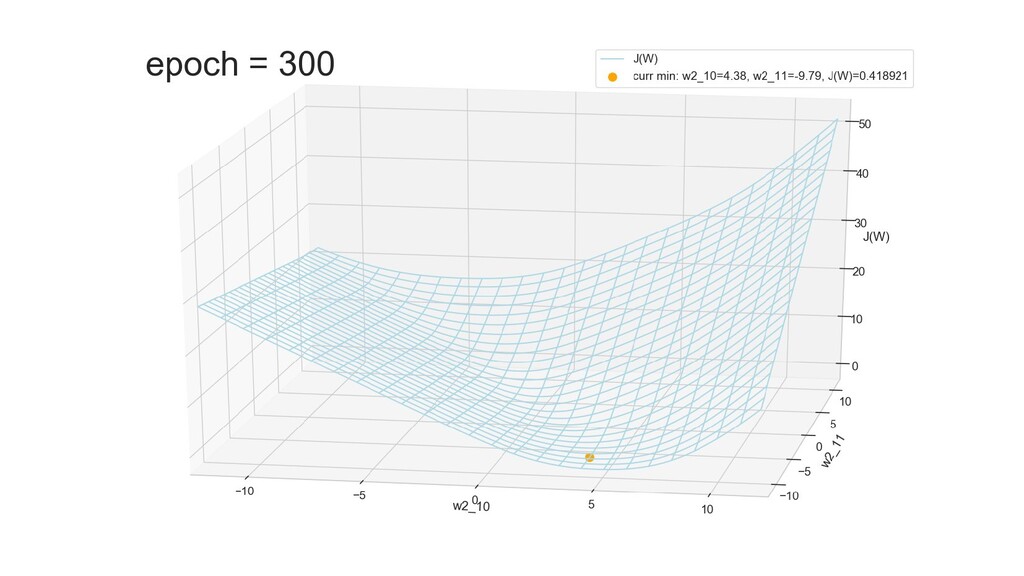
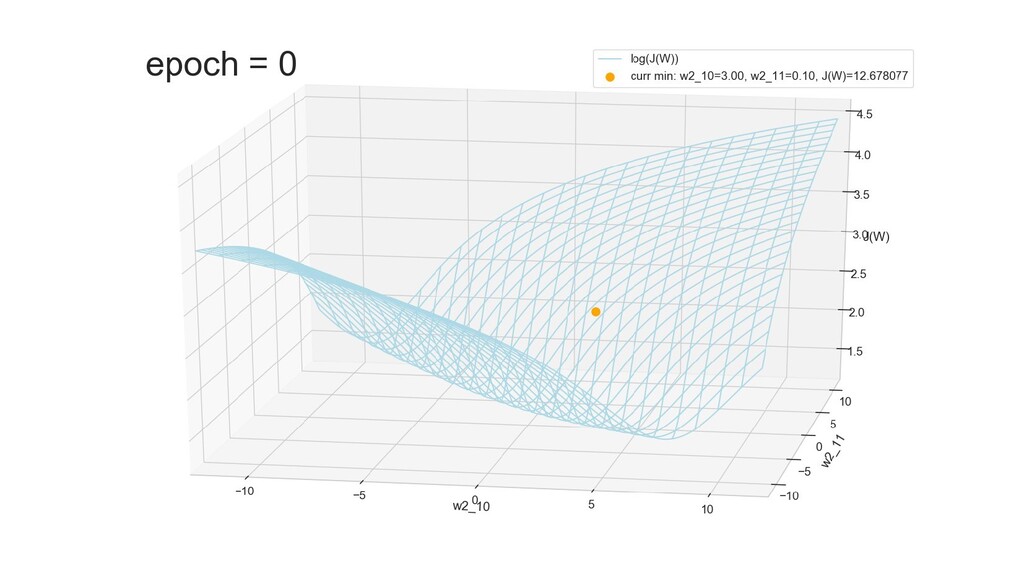
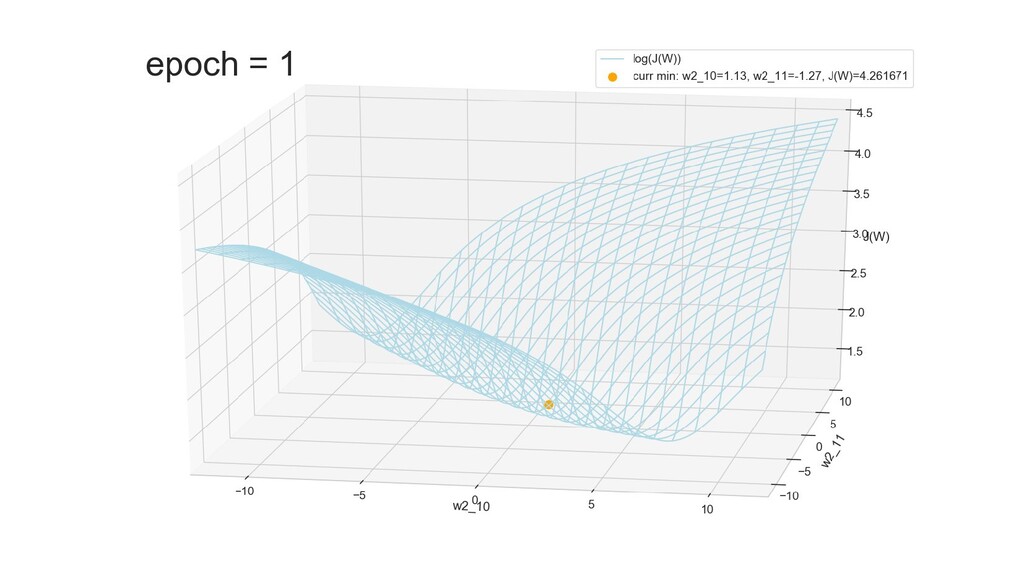
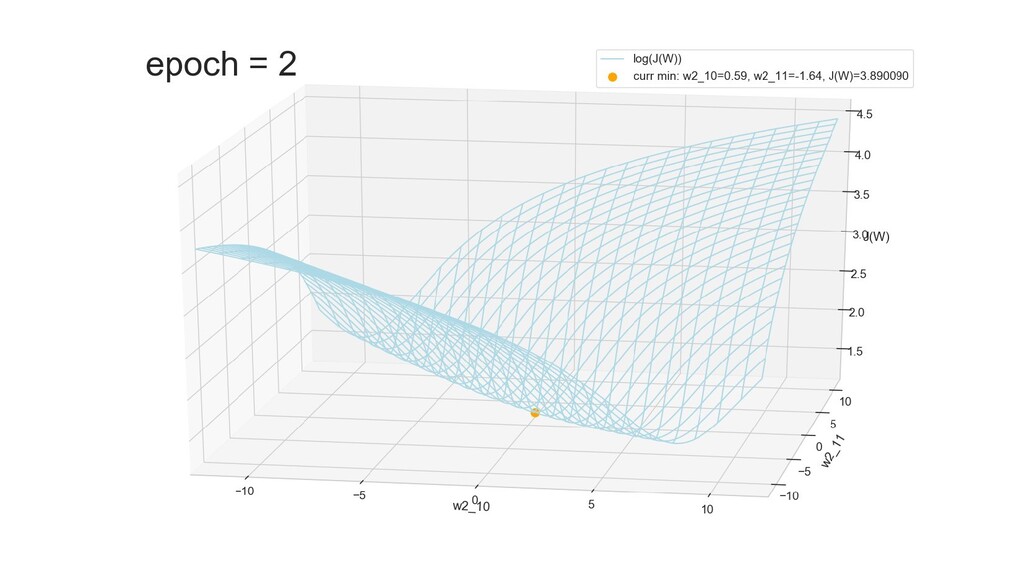
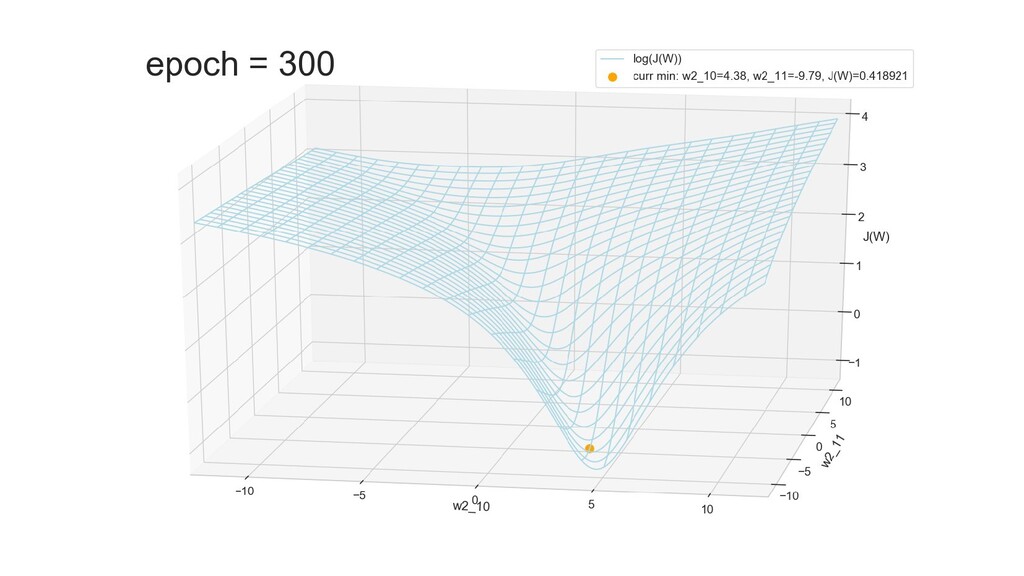
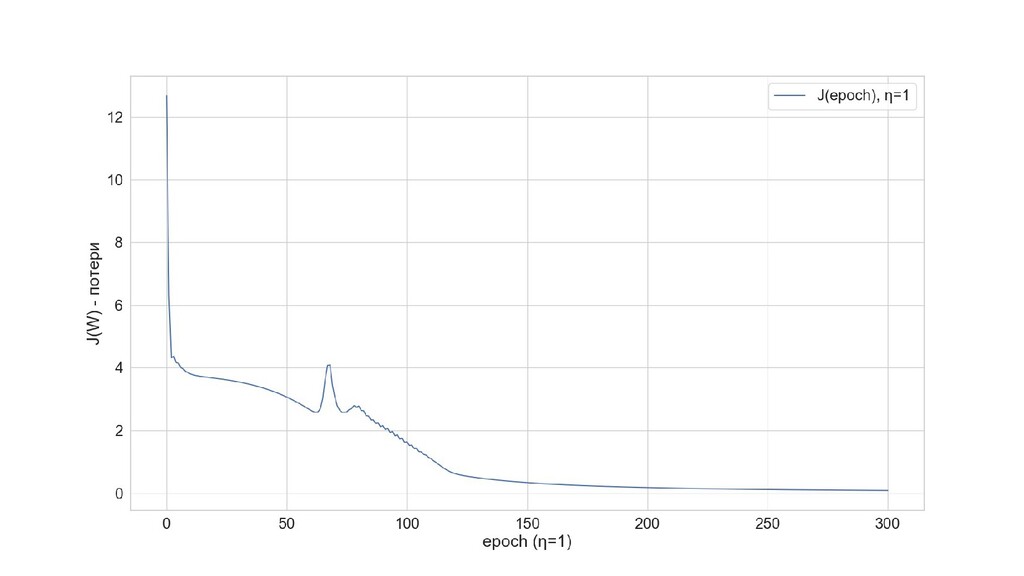
- Результат обучения: график потерь по эпохам
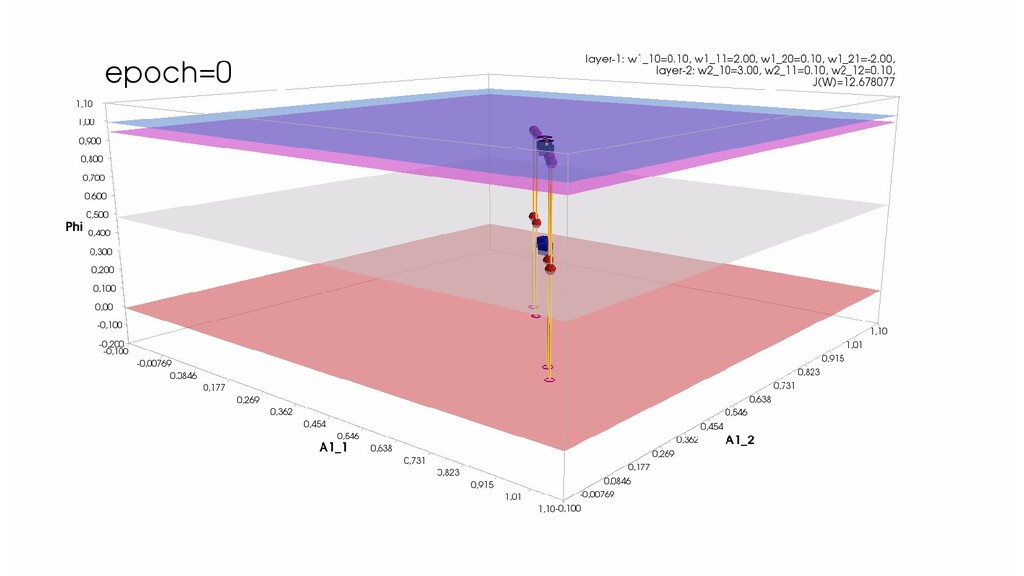
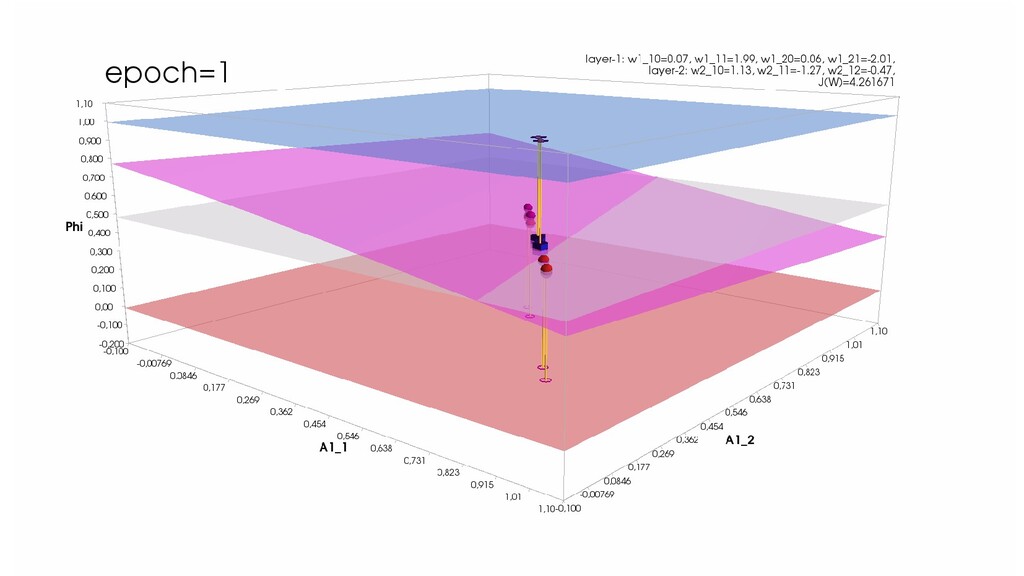
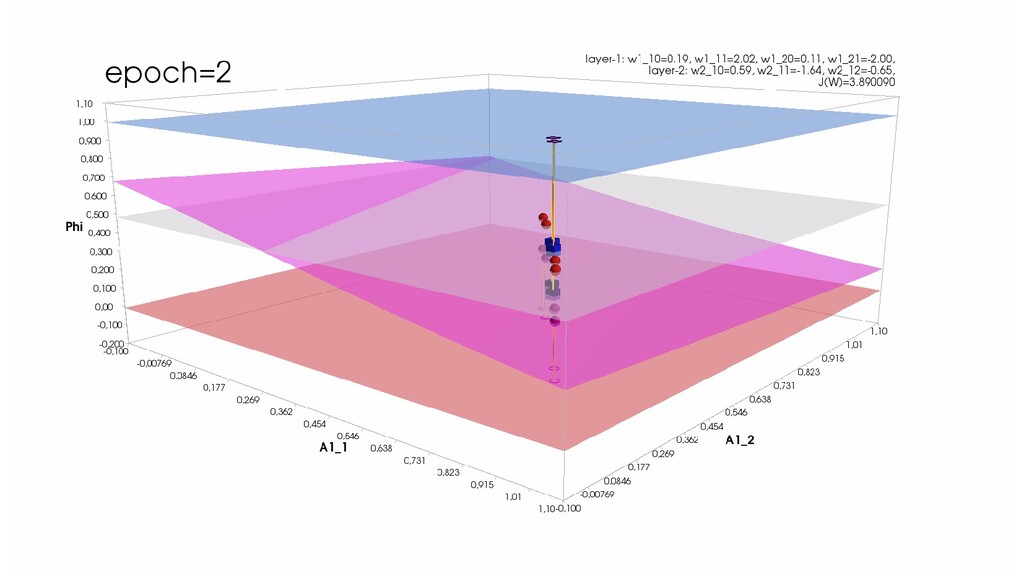
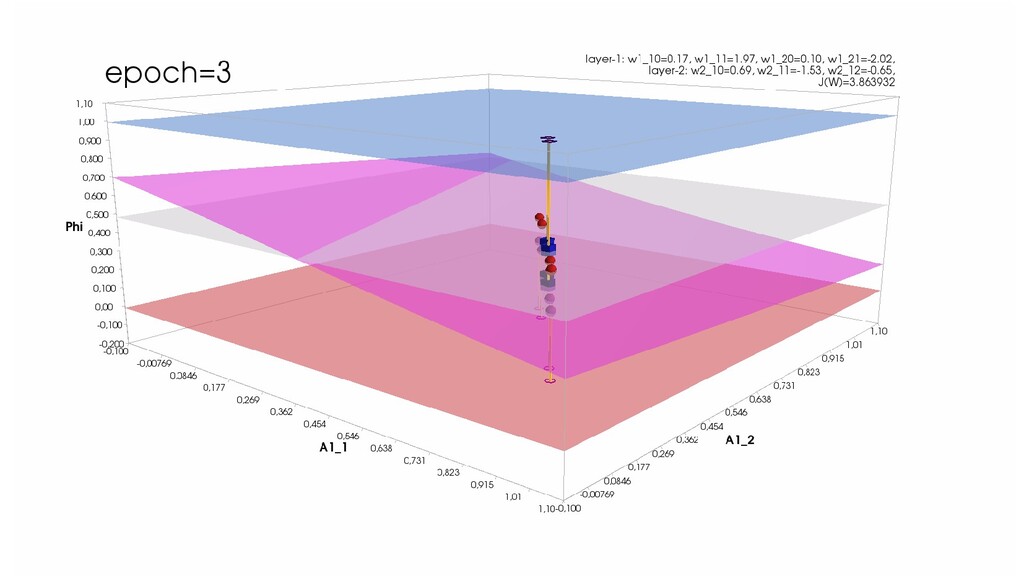
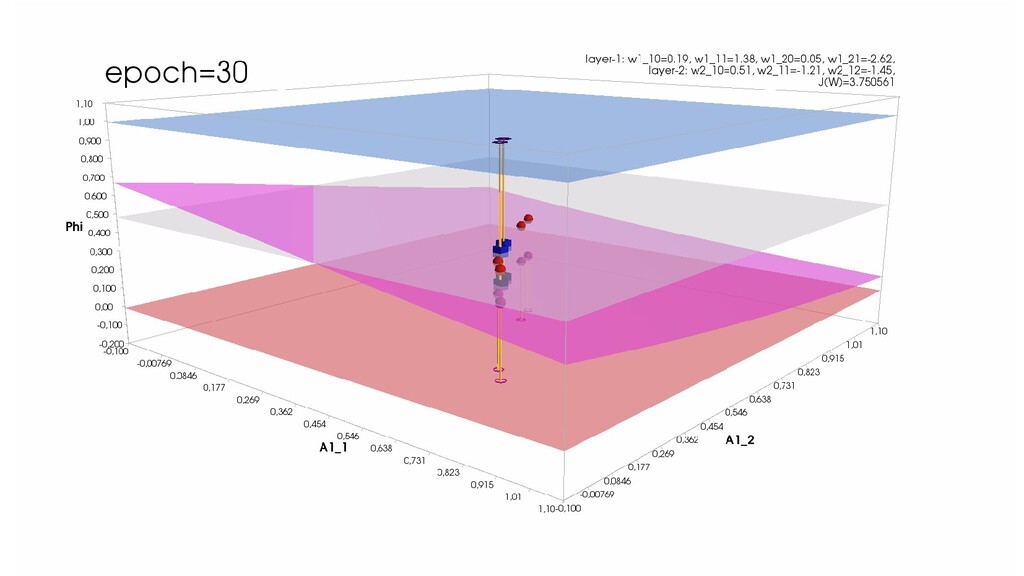
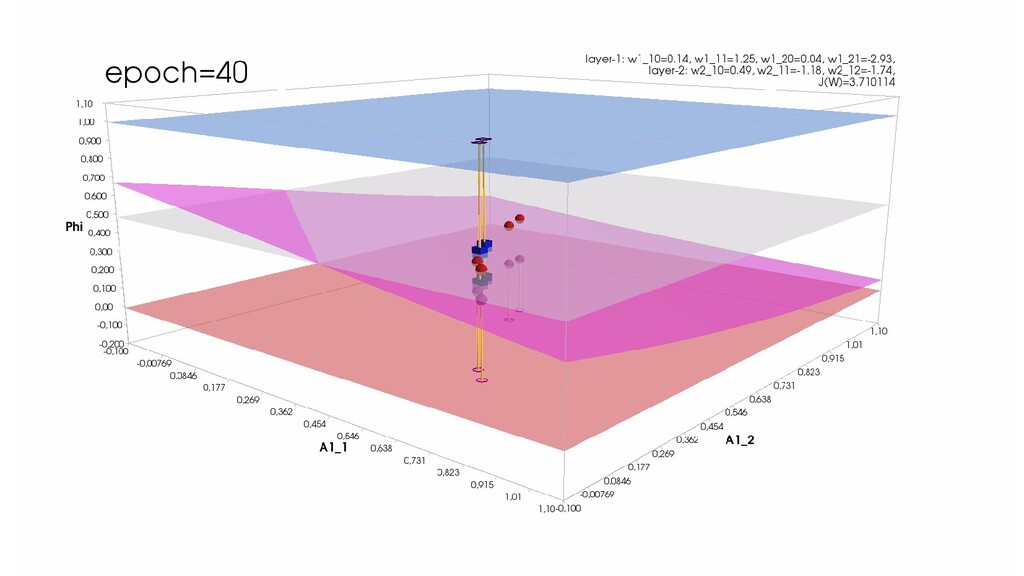
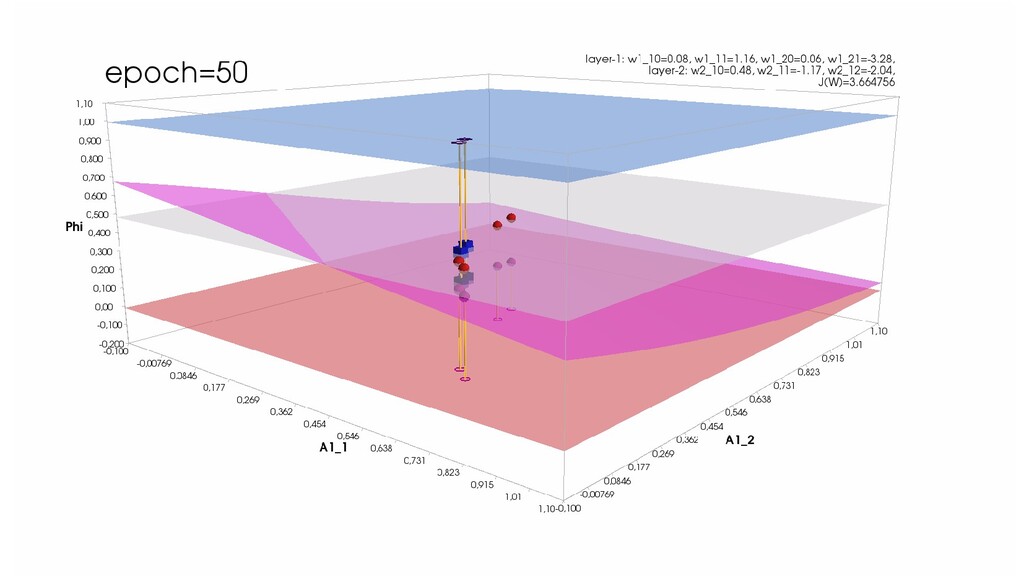
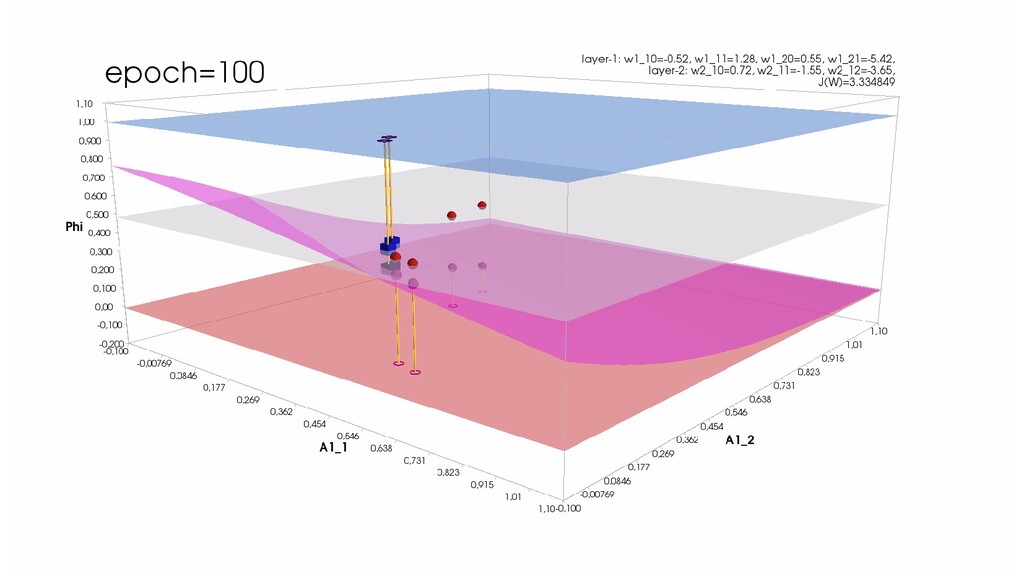
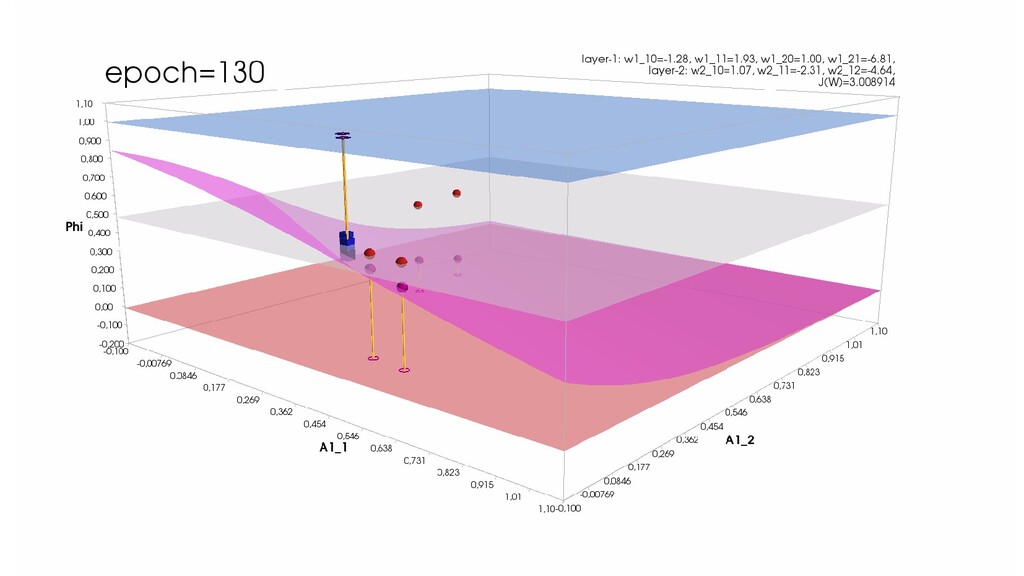
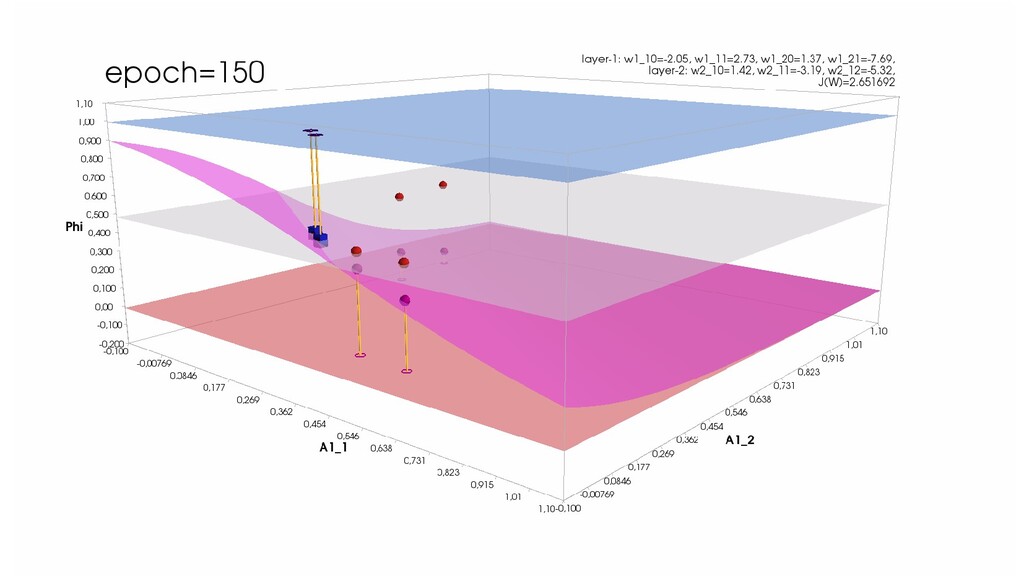
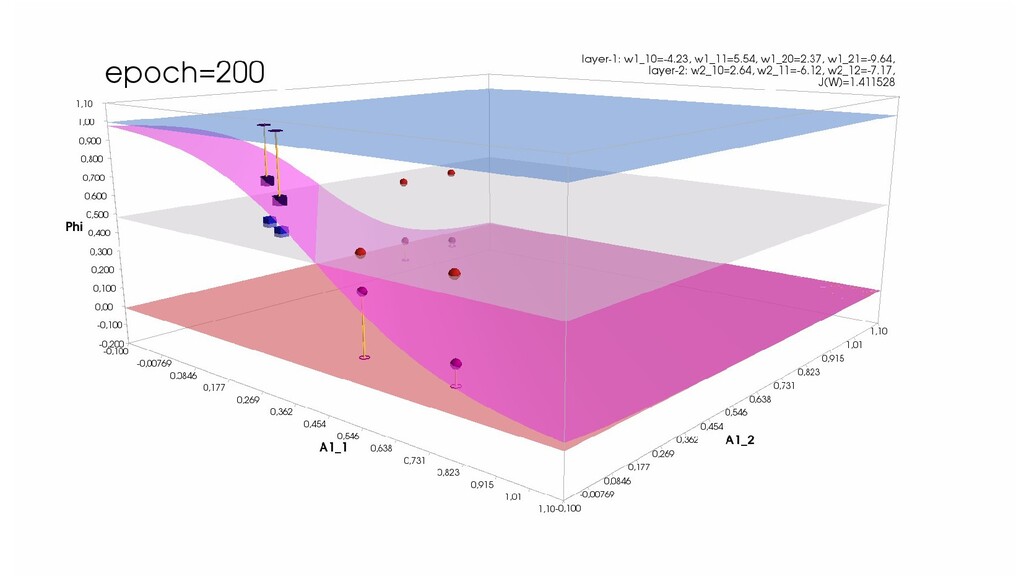
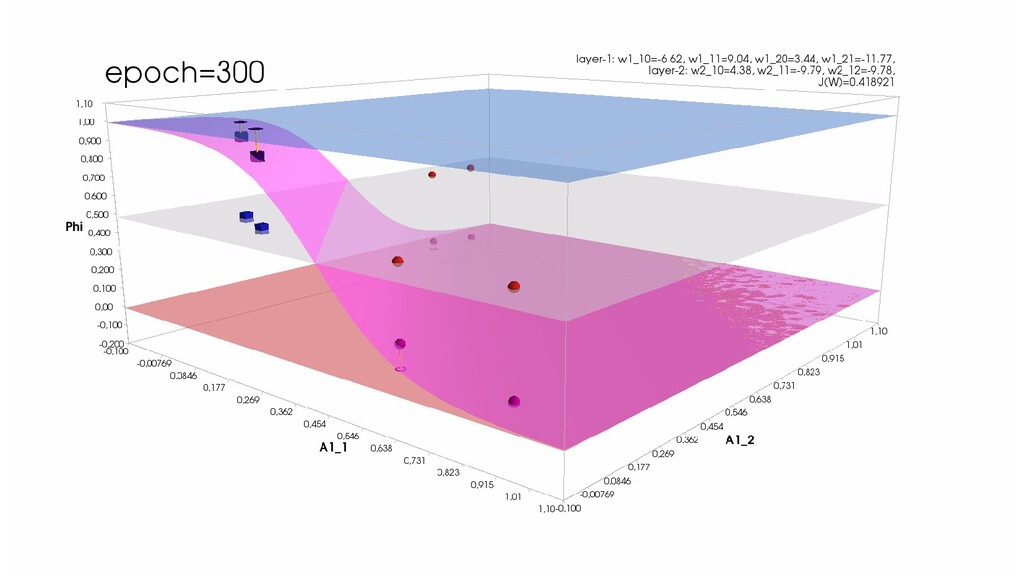
- Обучение в динамике, 2-д: движение разделяющей линии-пересечения активации и объектов-проекций на выходном нейроне в сторону оптимального положения
- Обучение в динамике, 3-д: движение поверхности активации и объектов-проекций на выходном нейроне в сторону оптимального положения
- График функции ошибки, визуализация спуска по отдельным срезам: пока противник рисует карты наступления, мы меняем ландшафты, причем вручную. Когда приходит время атаки, противник теряется на незнакомой местности и приходит в полную небоеготовность.
- Подытожим: мы обучили нейронную сеть отличать то, что снаружи от того, что внутри, при этом решили задачу аналитически
- Проверка результата: классифицировать несколько значений вручную
- Несколько равнозначных минимумов, т.е. направлений спуска сети. В какой попадем, зависит от начальных коэффициентов.
- Дополнительные замечания и темы для самостоятельного изучения
Обновлено: 22.05.2020
https://vk.com/video53223390_456239475
https://www.youtube.com/watch?v=cWxwXXKbSG4
https://www.youtube.com/playlist?list=PLSu-UfrQJjQky3LrVLb3hnJ7cnPxjZUQP
https://1i7.livejournal.com/154527.html
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Попробуем разделить [линейно]-неразделимое](https://files.speakerdeck.com/presentations/a9c29a2d1787449da762fb329e73ea85/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[вспоминаем из прошлой лекции]](https://files.speakerdeck.com/presentations/a9c29a2d1787449da762fb329e73ea85/slide_46.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![[и здесь стоп]](https://files.speakerdeck.com/presentations/a9c29a2d1787449da762fb329e73ea85/slide_50.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Градиент — вектор частных производных • ∇ [набла] (перевернутая дельта)](https://files.speakerdeck.com/presentations/a9c29a2d1787449da762fb329e73ea85/slide_57.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}