Лекция курса "Большие данные и машинное обучение" (v2.0-МОТ)
Лекция-5: категории и тексты
- Категориальные признаки: порядковые и номинальные
- Варианты кодирования: Pandas:Series.map
- Варианты кодирования: sklearn:LabelEncoder
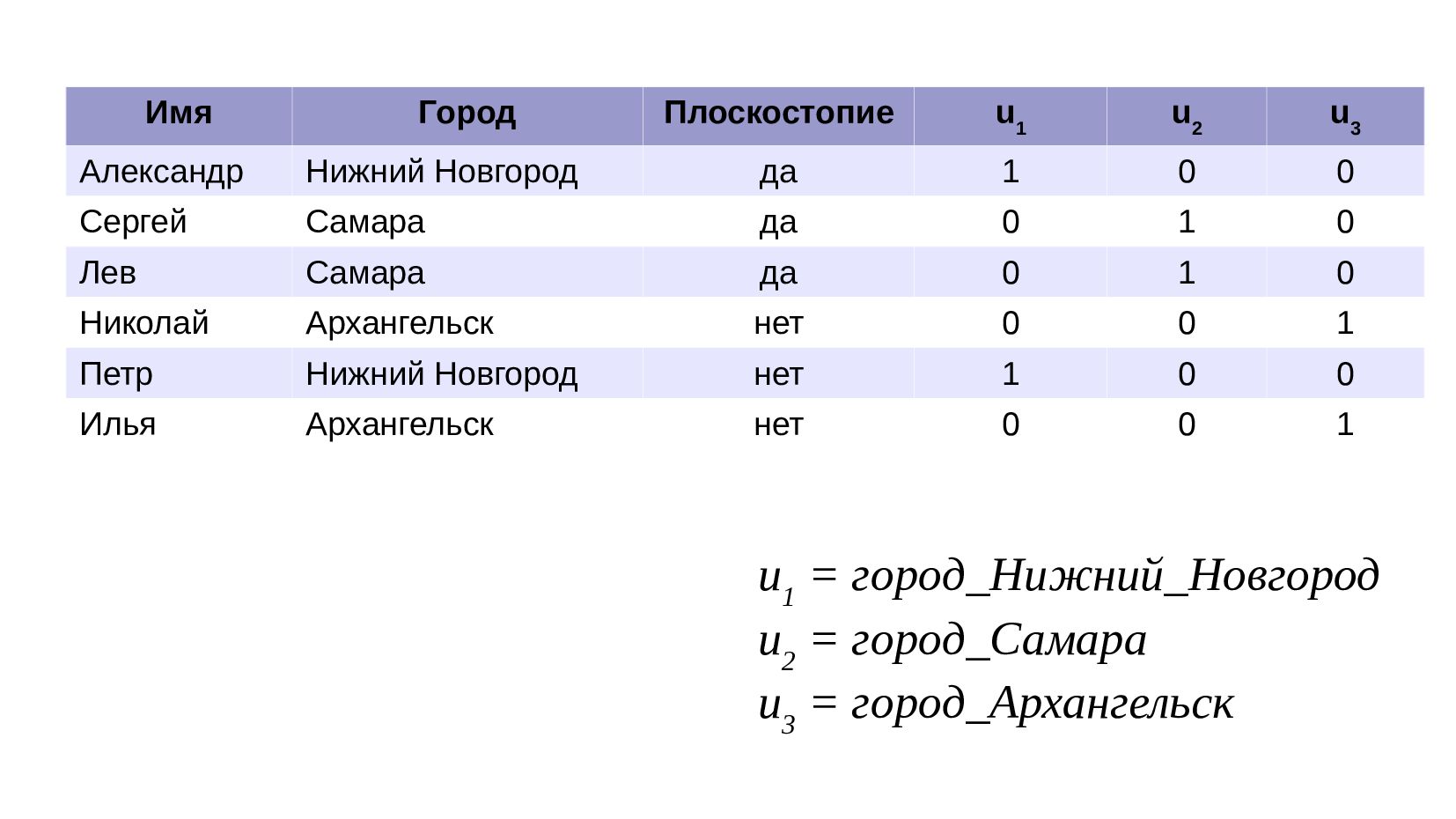
- Варианты кодирования: дамми-кодирование, Pandas:get_dummies
- Варианты кодирования: sklearn:OneHotEncoder
- Варианты кодирования: Pandas:DataFrame.pivot_table
- ЕЯ — естественные языки (NLP — Natural language processing)
- Текстовые признаки
- Мешок слов
- Извлечение мешка слов из текстового признака: sklearn:CountVectorizer
- Превращение текстового признака в набор категориальных
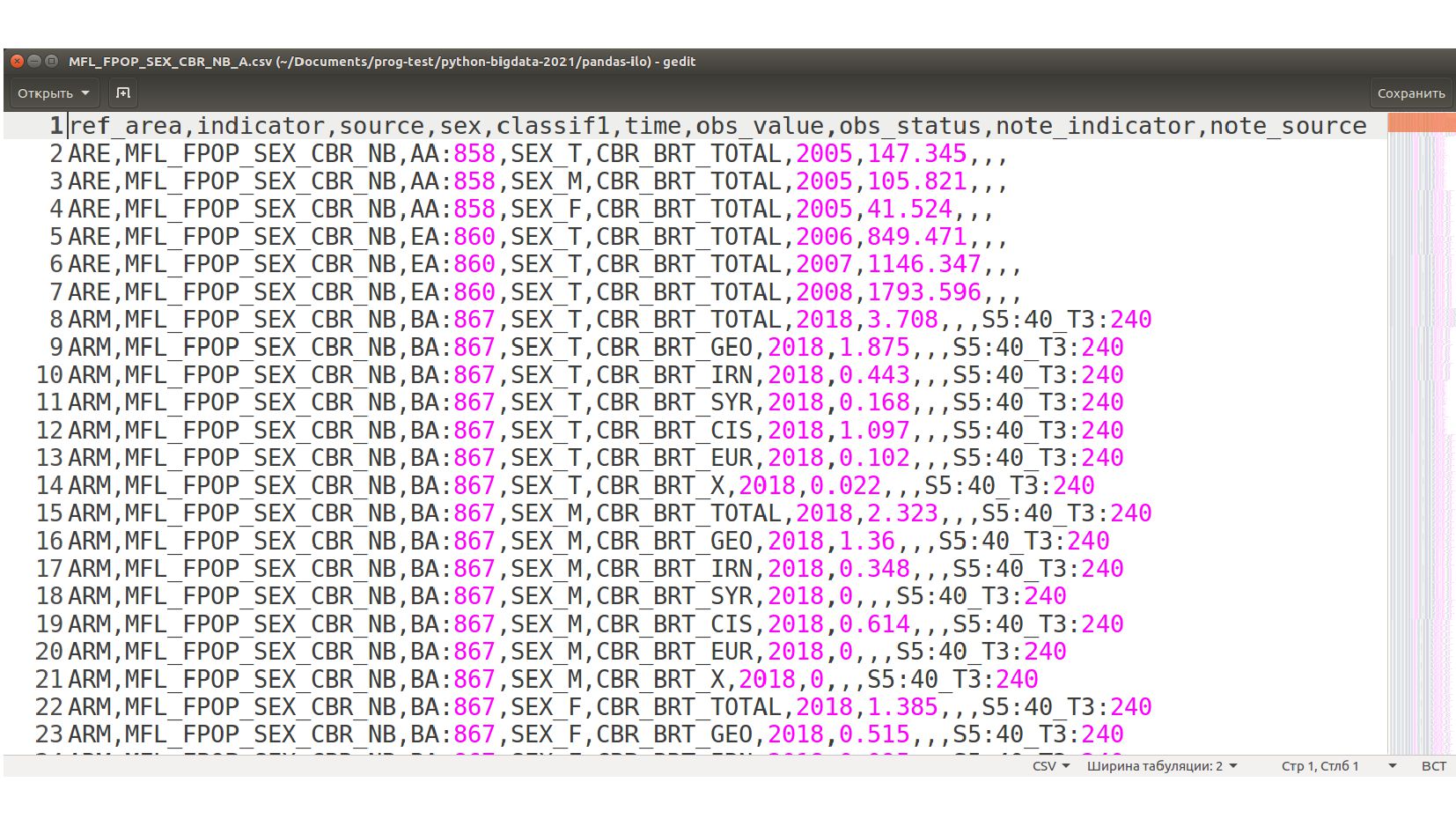
- Пример: работа с категориями в датасете ILO (МОТ - Международная организация труда) ilostat.ilo.org
- Таблица данных vs таблица объектов
- Превращение таблицы сырых данных в таблицу объектов группировкой по категориям с преобразованием численных признаков: Pandas:DataFrame.groupby
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![from sklearn.preprocessing import LabelEncoder lenc = LabelEncoder() print( lenc.fit_transform(data['город'].values) )](https://files.speakerdeck.com/presentations/5089a35e2d3f472f978bcdedee4779c2/slide_12.jpg){kind=link}
![data['город_enc'] = lenc.fit_transform(data['город'].values) print(data) sklearn.preprocessing.LabelEncoder имя город плоскостопие код_города город_enc](https://files.speakerdeck.com/presentations/5089a35e2d3f472f978bcdedee4779c2/slide_13.jpg){kind=link}
![data['город_enc_inv'] = lenc.inverse_transform(data['город_enc'].values) print(data) Исходная метка по коду имя город](https://files.speakerdeck.com/presentations/5089a35e2d3f472f978bcdedee4779c2/slide_14.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![print( pd.get_dummies(data['город']) ) Архангельск Нижний Новгород Самара 0 0 1](https://files.speakerdeck.com/presentations/5089a35e2d3f472f978bcdedee4779c2/slide_19.jpg){kind=link}
![print( pd.get_dummies(data, columns=['город']) ) имя плоскостопие город_Архангельск город_Нижний Новгород город_Самара](https://files.speakerdeck.com/presentations/5089a35e2d3f472f978bcdedee4779c2/slide_20.jpg){kind=link}
{kind=link}
{kind=link}
![# выбранная колонка - таблица из одной колонки print( ohenc.fit_transform(data[['город']]).toarray()](https://files.speakerdeck.com/presentations/5089a35e2d3f472f978bcdedee4779c2/slide_23.jpg){kind=link}
![[[0. 1. 0.] [0. 0. 1.] [0. 0. 1.] [1.](https://files.speakerdeck.com/presentations/5089a35e2d3f472f978bcdedee4779c2/slide_24.jpg){kind=link}
![# сначала fit, потом transform print( data[['город']] ) ohenc.fit( data[['город']]](https://files.speakerdeck.com/presentations/5089a35e2d3f472f978bcdedee4779c2/slide_25.jpg){kind=link}
{kind=link}
![# указать категории вручную ohenc.fit( [['Нижний Новгород'], ['Самара'], ['Архангельск']] )](https://files.speakerdeck.com/presentations/5089a35e2d3f472f978bcdedee4779c2/slide_27.jpg){kind=link}
![[[0. 1. 0.] [0. 0. 1.] [0. 0. 1.] [1.](https://files.speakerdeck.com/presentations/5089a35e2d3f472f978bcdedee4779c2/slide_28.jpg){kind=link}
{kind=link}
![[[0. 0. 1. 0.] [0. 0. 0. 1.] [0. 0.](https://files.speakerdeck.com/presentations/5089a35e2d3f472f978bcdedee4779c2/slide_30.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![data['город_1'] = data['город'] print( data.pivot_table( index=data.index, columns='город', values='город_1', aggfunc='count') )](https://files.speakerdeck.com/presentations/5089a35e2d3f472f978bcdedee4779c2/slide_37.jpg){kind=link}
![data['город_1'] = data['город'] print( data.pivot_table( index=data.index, columns='город', values='город_1', aggfunc='count', fill_value=0)](https://files.speakerdeck.com/presentations/5089a35e2d3f472f978bcdedee4779c2/slide_38.jpg){kind=link}
{kind=link}
![data['город_1'] = data['город'] data_pivot_dummy = data.pivot_table( index=data.index, columns='город', values='город_1', aggfunc='count',](https://files.speakerdeck.com/presentations/5089a35e2d3f472f978bcdedee4779c2/slide_40.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![bag = count_vect.fit_transform(data_txt['текст']) print( data_txt ) print( count_vect.get_feature_names() ) print(](https://files.speakerdeck.com/presentations/5089a35e2d3f472f978bcdedee4779c2/slide_47.jpg){kind=link}
{kind=link}
![bag = count_vect.fit_transform(data_txt['текст']) print( data_txt ) print( count_vect.get_feature_names() ) print(](https://files.speakerdeck.com/presentations/5089a35e2d3f472f978bcdedee4779c2/slide_49.jpg){kind=link}
{kind=link}
![print( pd.concat([data_txt, data_vect.add_prefix('w_')], axis=1) ) текст w_игрушки w_книжки w_спят w_усталые](https://files.speakerdeck.com/presentations/5089a35e2d3f472f978bcdedee4779c2/slide_51.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
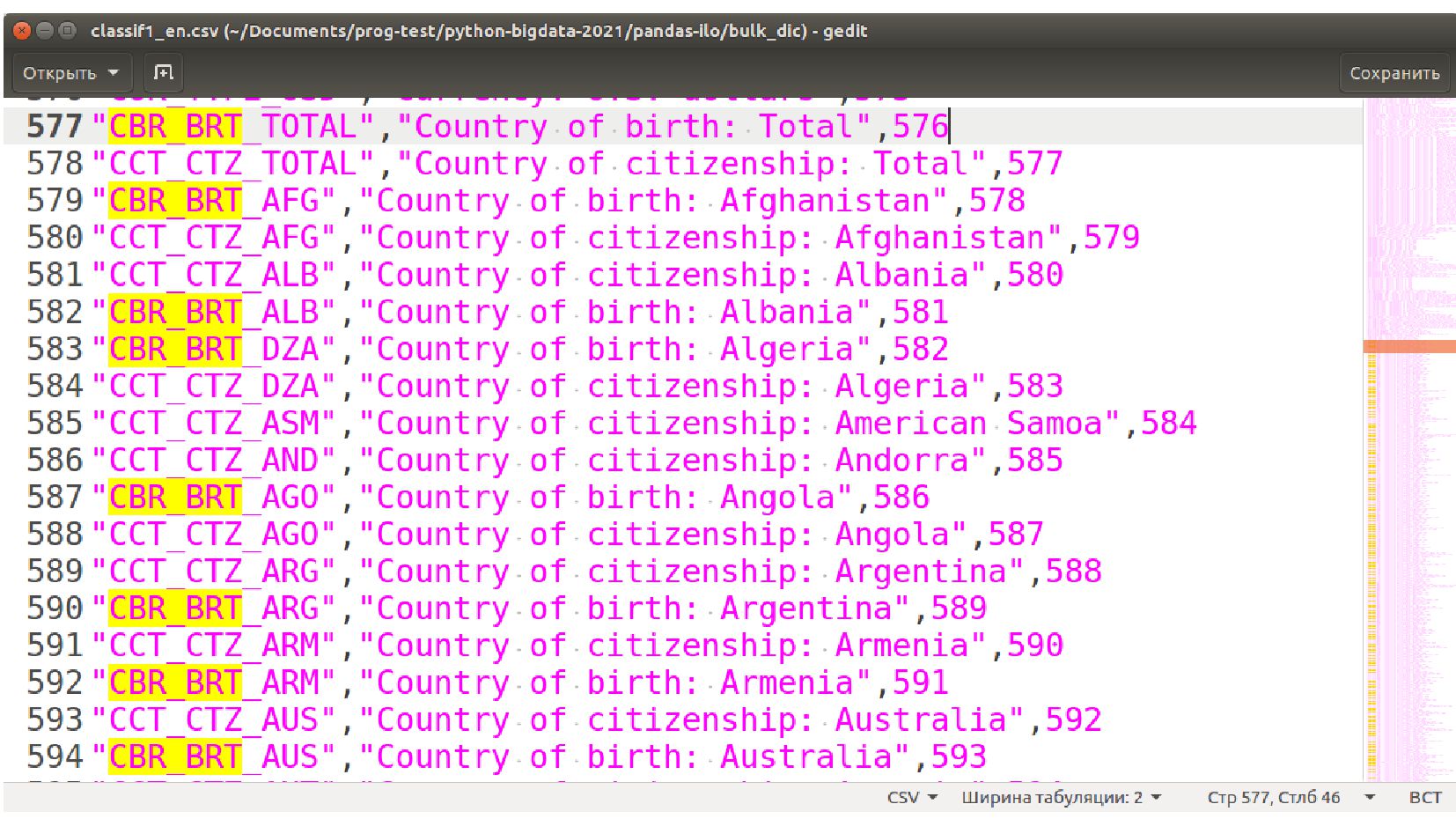{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![data = data[data.sex == 'SEX_T'] data = data[ ['ref_area', 'time',](https://files.speakerdeck.com/presentations/5089a35e2d3f472f978bcdedee4779c2/slide_72.jpg){kind=link}
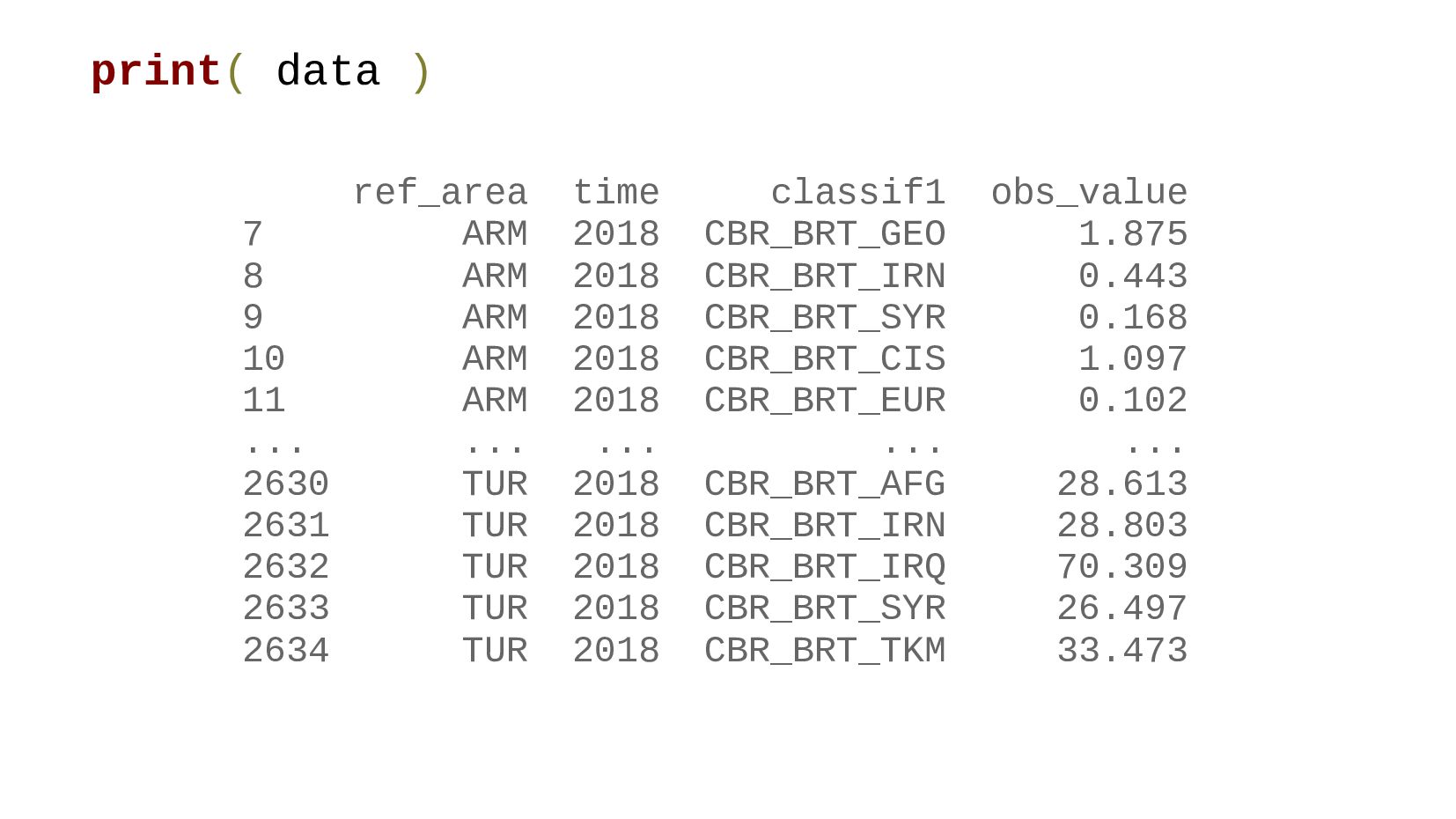{kind=link}
![print( data.loc[ data.groupby(by=['ref_area', 'time']) ['obs_value'].idxmax() ] )](https://files.speakerdeck.com/presentations/5089a35e2d3f472f978bcdedee4779c2/slide_74.jpg){kind=link}
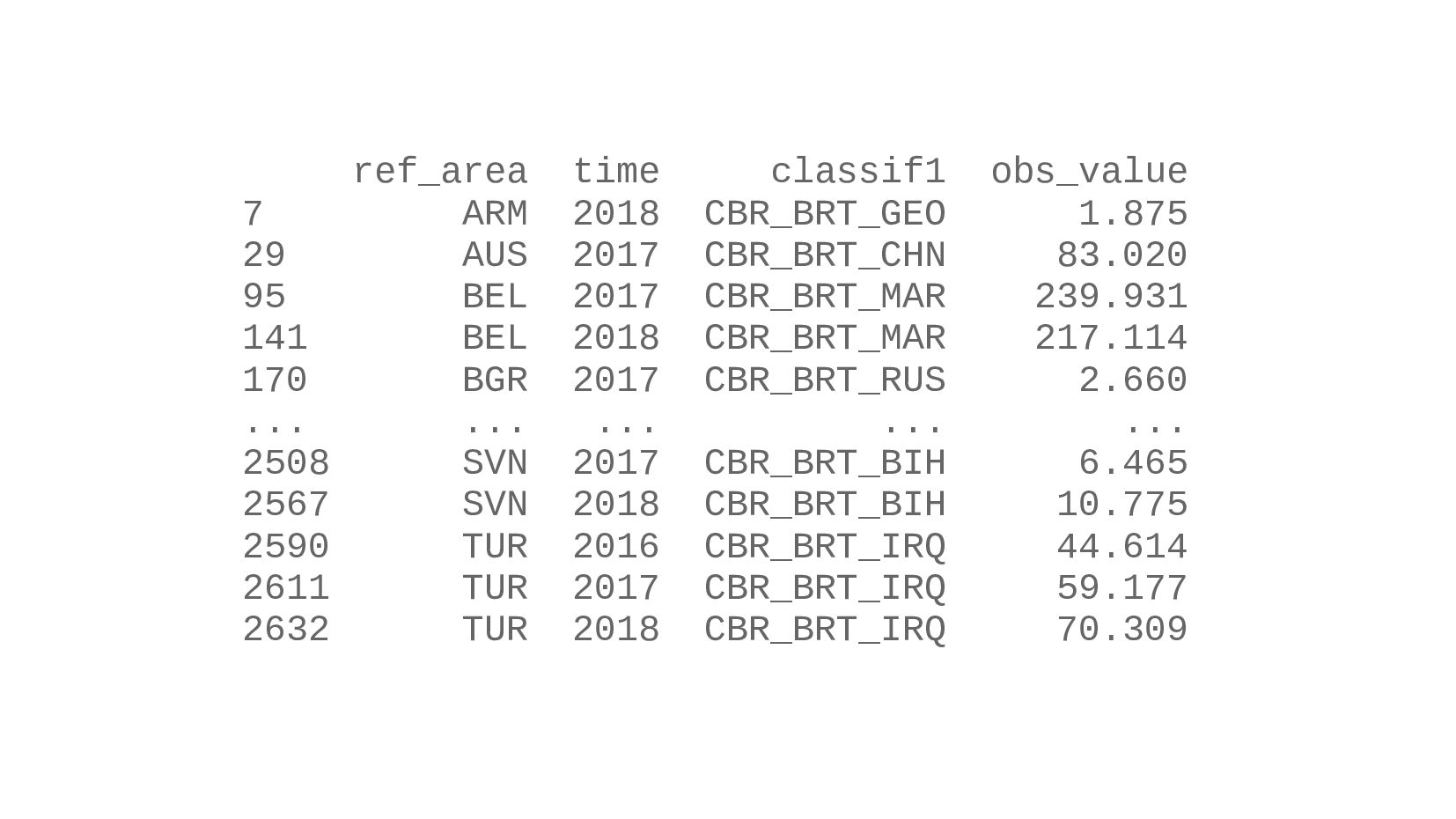{kind=link}
![data1 = data.loc[ data.groupby(by=['ref_area', 'time']) ['obs_value'].idxmax()] data1 = data1.rename(columns={ 'classif1':](https://files.speakerdeck.com/presentations/5089a35e2d3f472f978bcdedee4779c2/slide_76.jpg){kind=link}
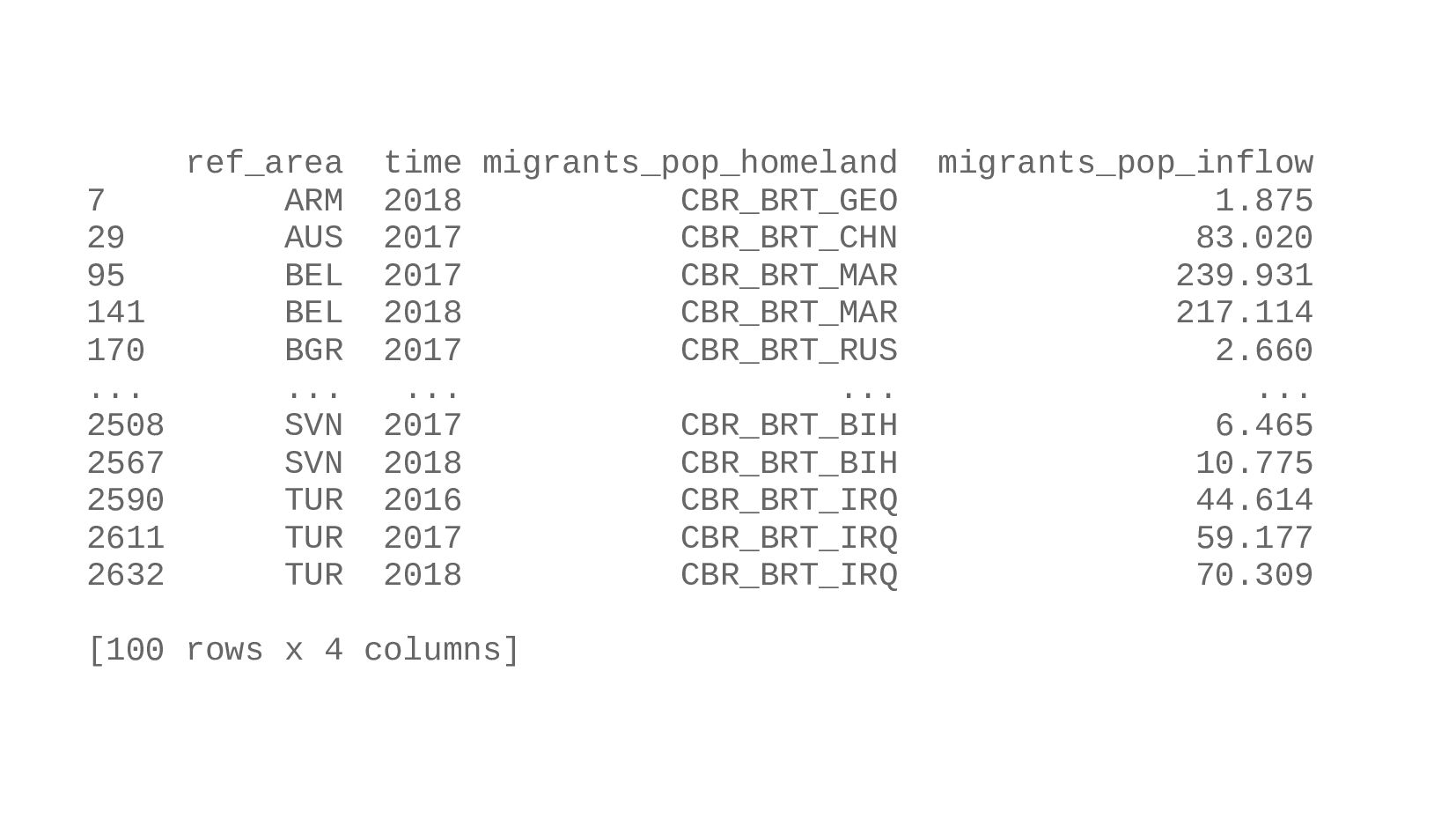{kind=link}
![print( data1[data1.ref_area == 'RUS'] ) ref_area time migrants_pop_homeland migrants_pop_inflow 2439](https://files.speakerdeck.com/presentations/5089a35e2d3f472f978bcdedee4779c2/slide_78.jpg){kind=link}
![print( data1[ data1.migrants_pop_homeland == 'CBR_BRT_RUS' ] ) ref_area time migrants_pop_homeland](https://files.speakerdeck.com/presentations/5089a35e2d3f472f978bcdedee4779c2/slide_79.jpg){kind=link}
{kind=link}
![print( data[data.classif1 == 'CBR_BRT_USA'] ) ref_area time classif1 obs_value 44](https://files.speakerdeck.com/presentations/5089a35e2d3f472f978bcdedee4779c2/slide_81.jpg){kind=link}
![print( data[data.classif1 == 'CBR_BRT_RUS'] ) ref_area time classif1 obs_value 170](https://files.speakerdeck.com/presentations/5089a35e2d3f472f978bcdedee4779c2/slide_82.jpg){kind=link}
{kind=link}
{kind=link}