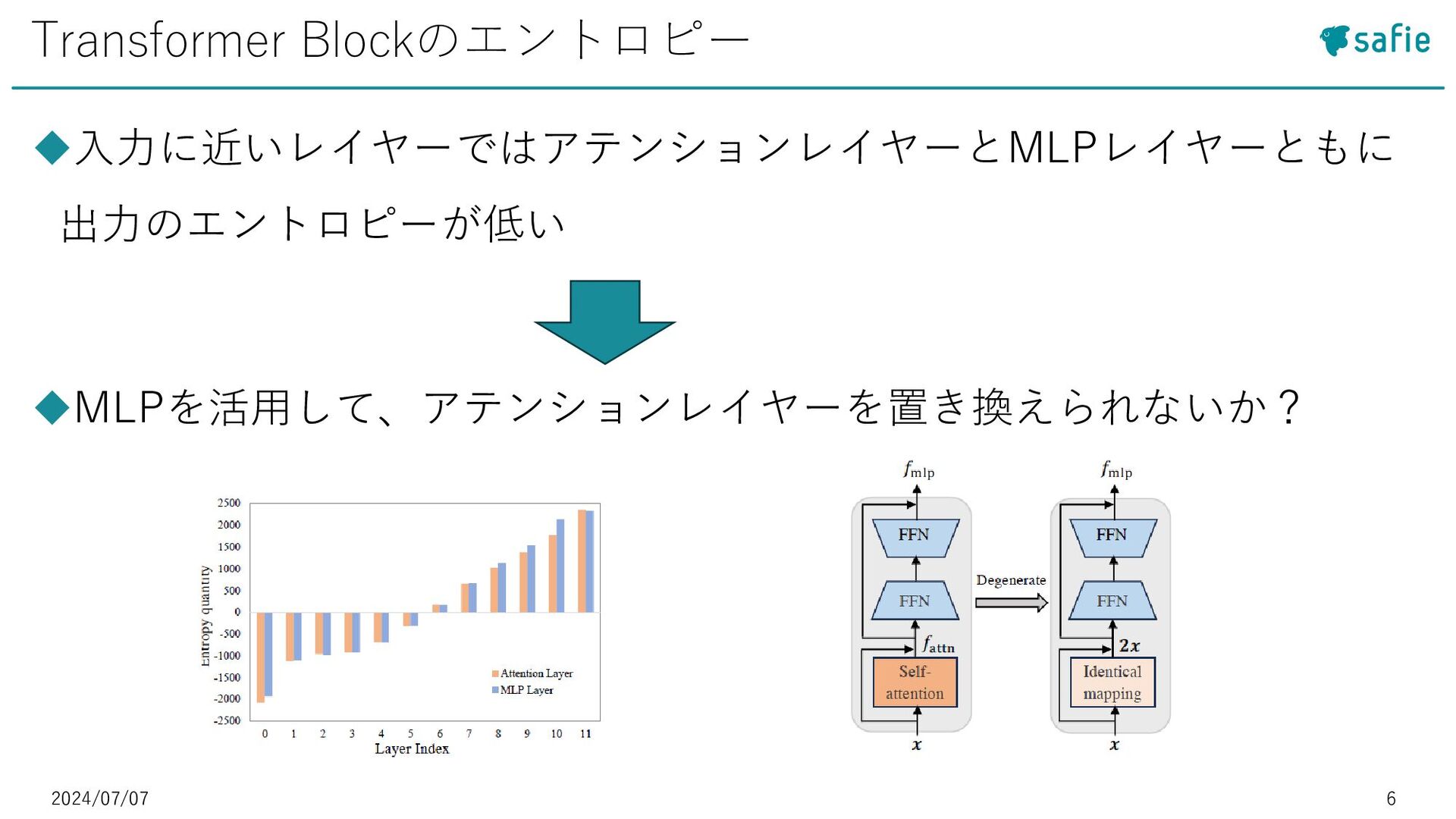
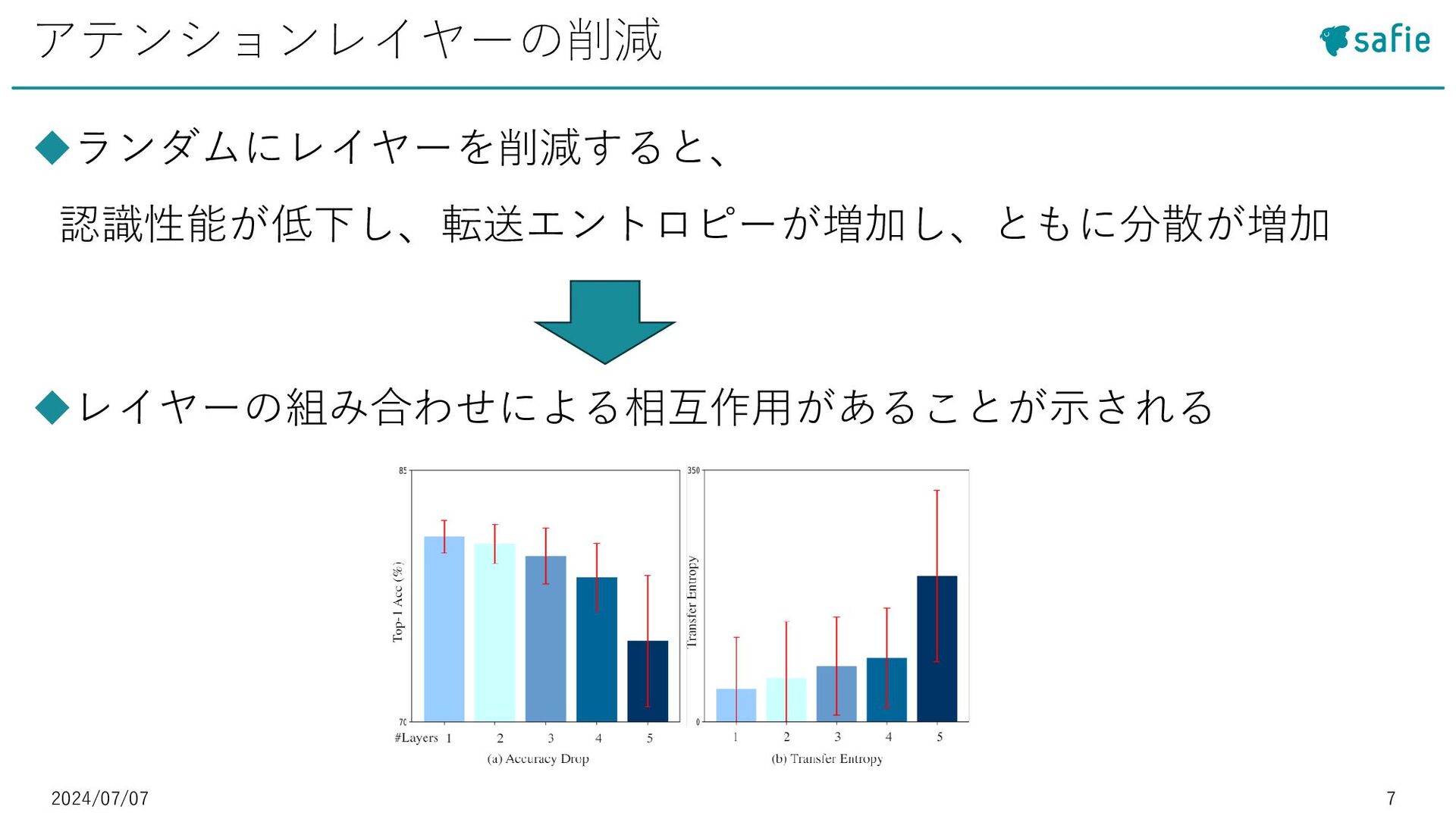
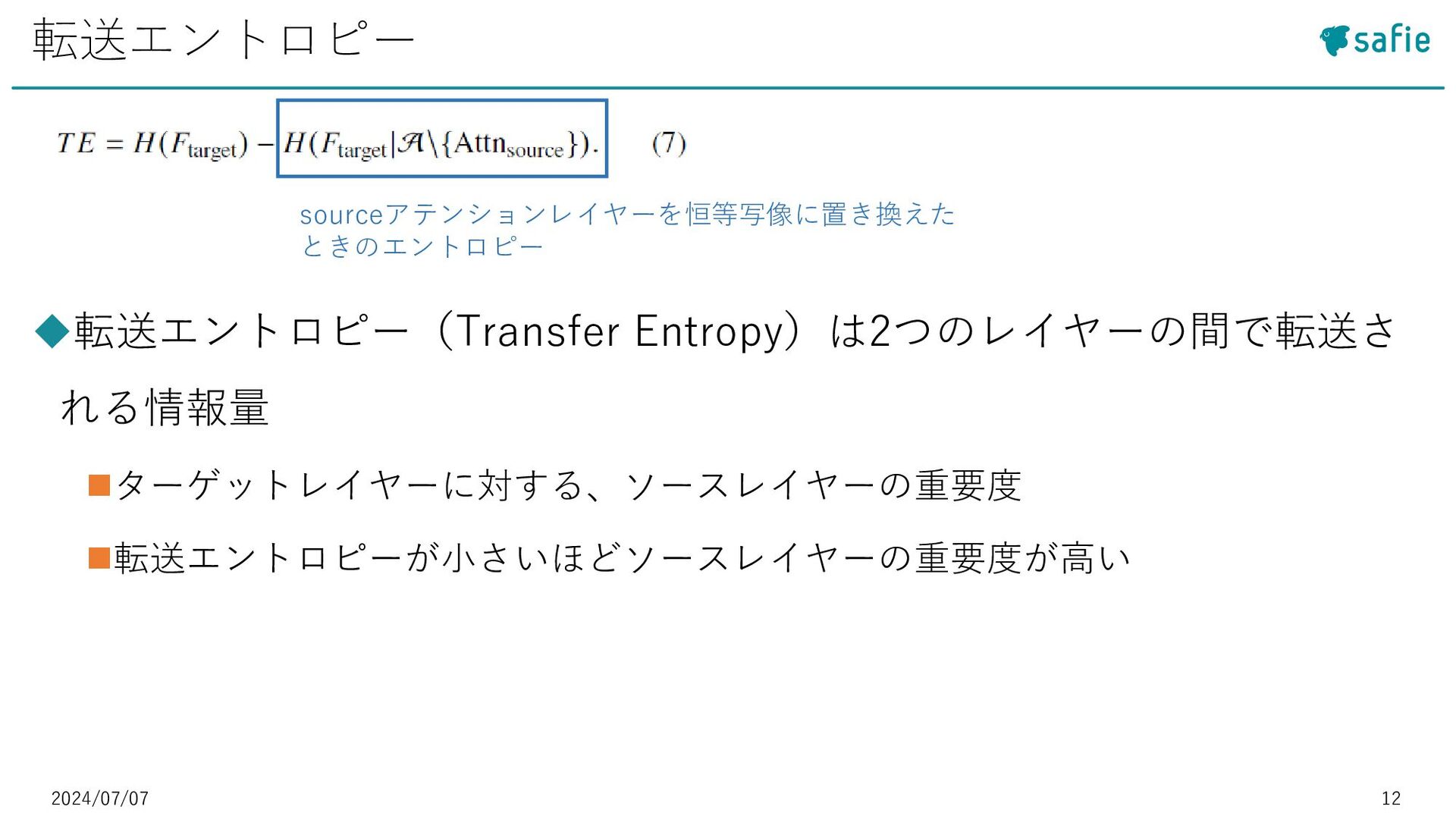
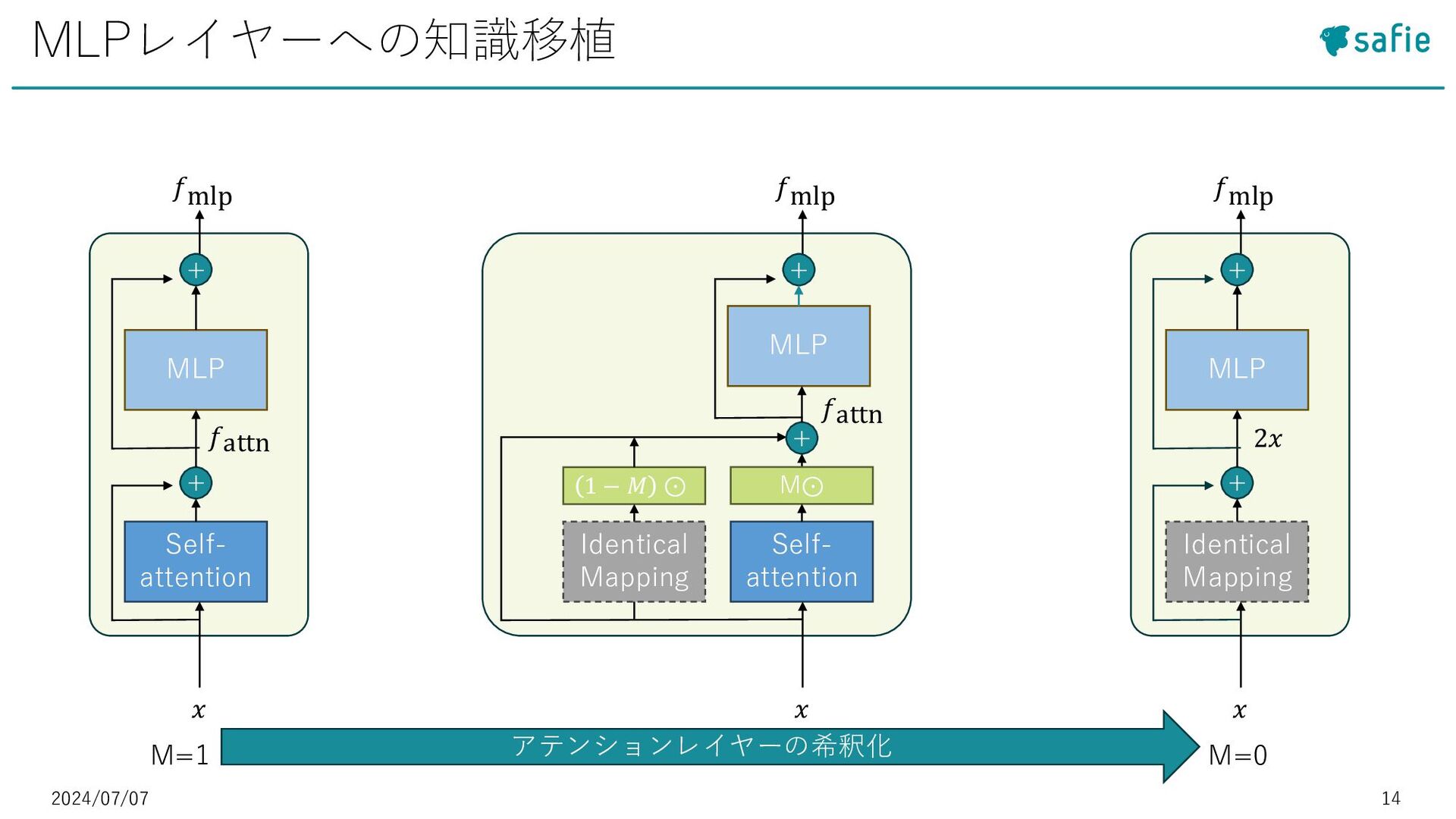
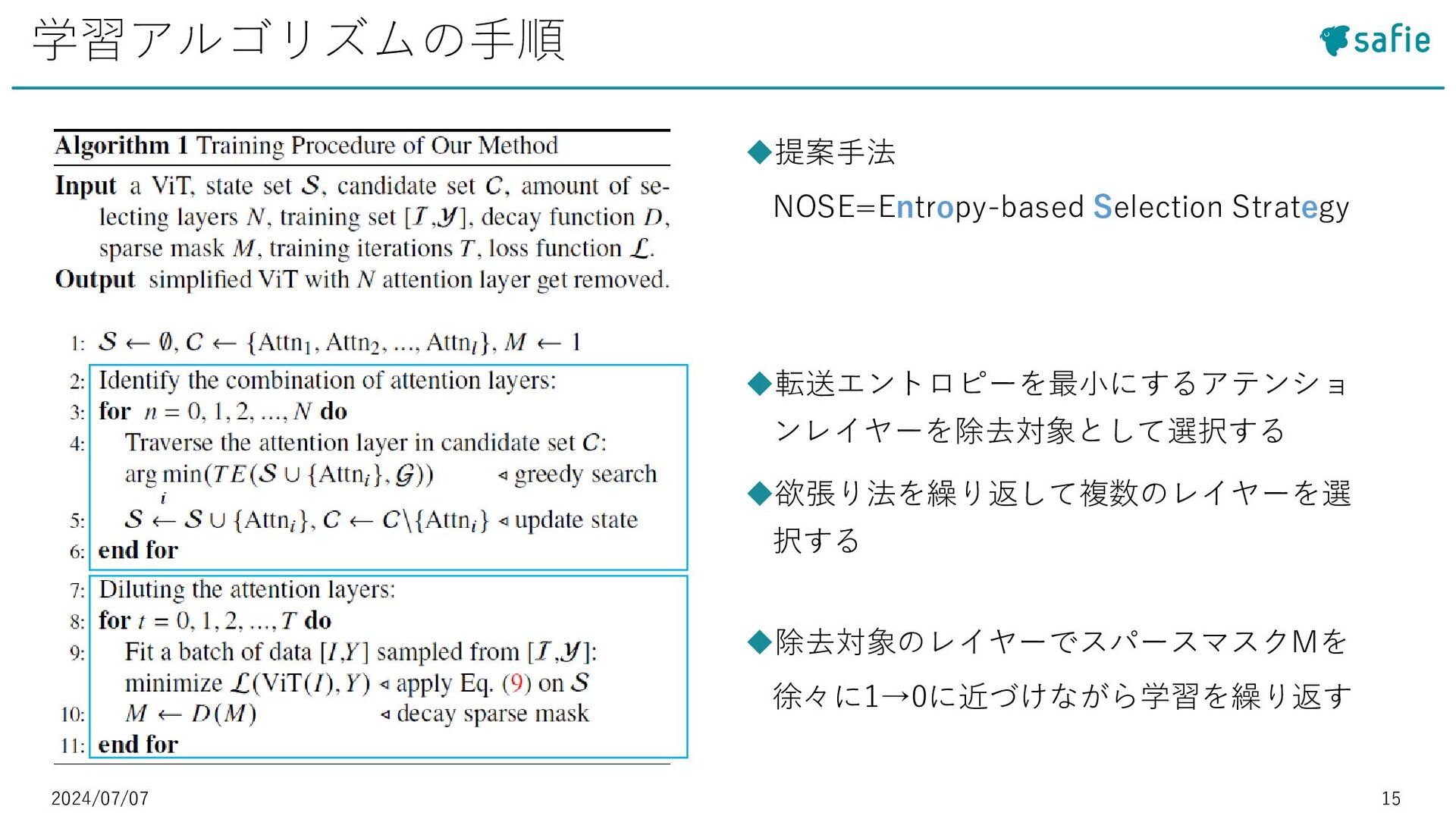
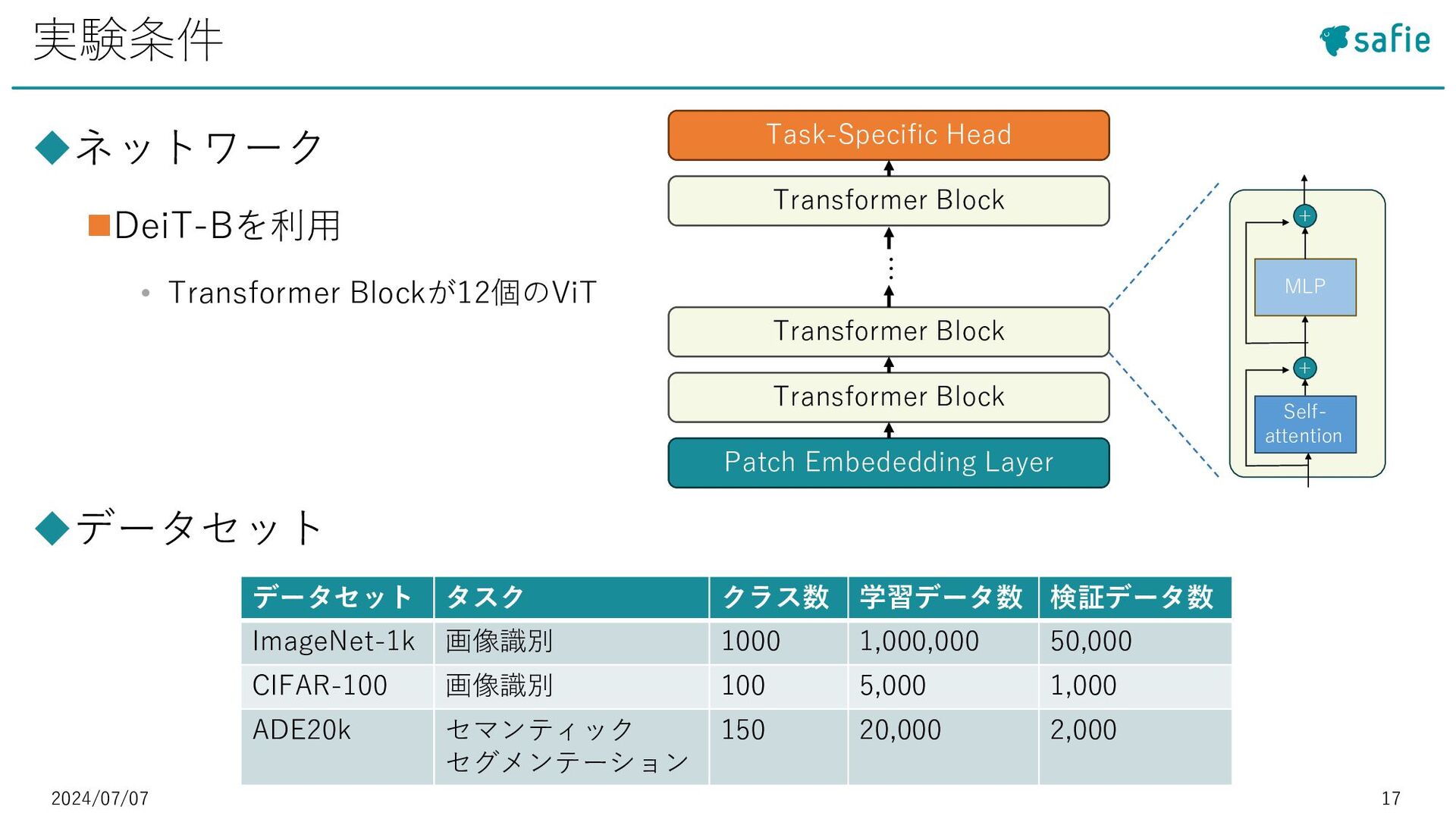
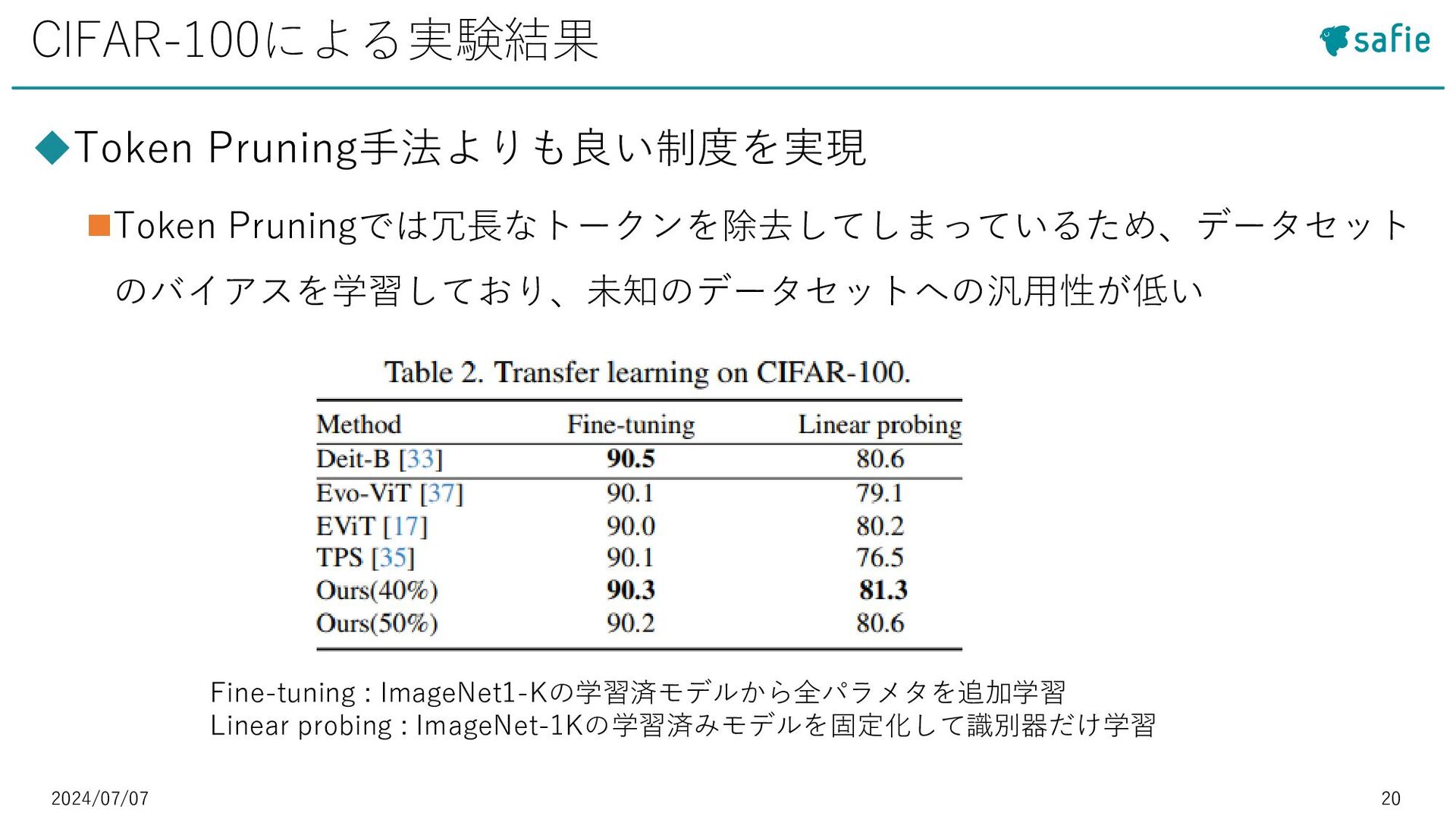
• [5] Daniel Bolya et al. : “Token Merging: Your ViT But Faster”, ICLR 2023など ◼Token Pruning:冗長なトークンを除去 • [27] Yongming Rao et al. : “Efficient vision transformers with dynamic token sparsification”, Advances in neural information processing systems 2021など モチベーション・既存研究
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
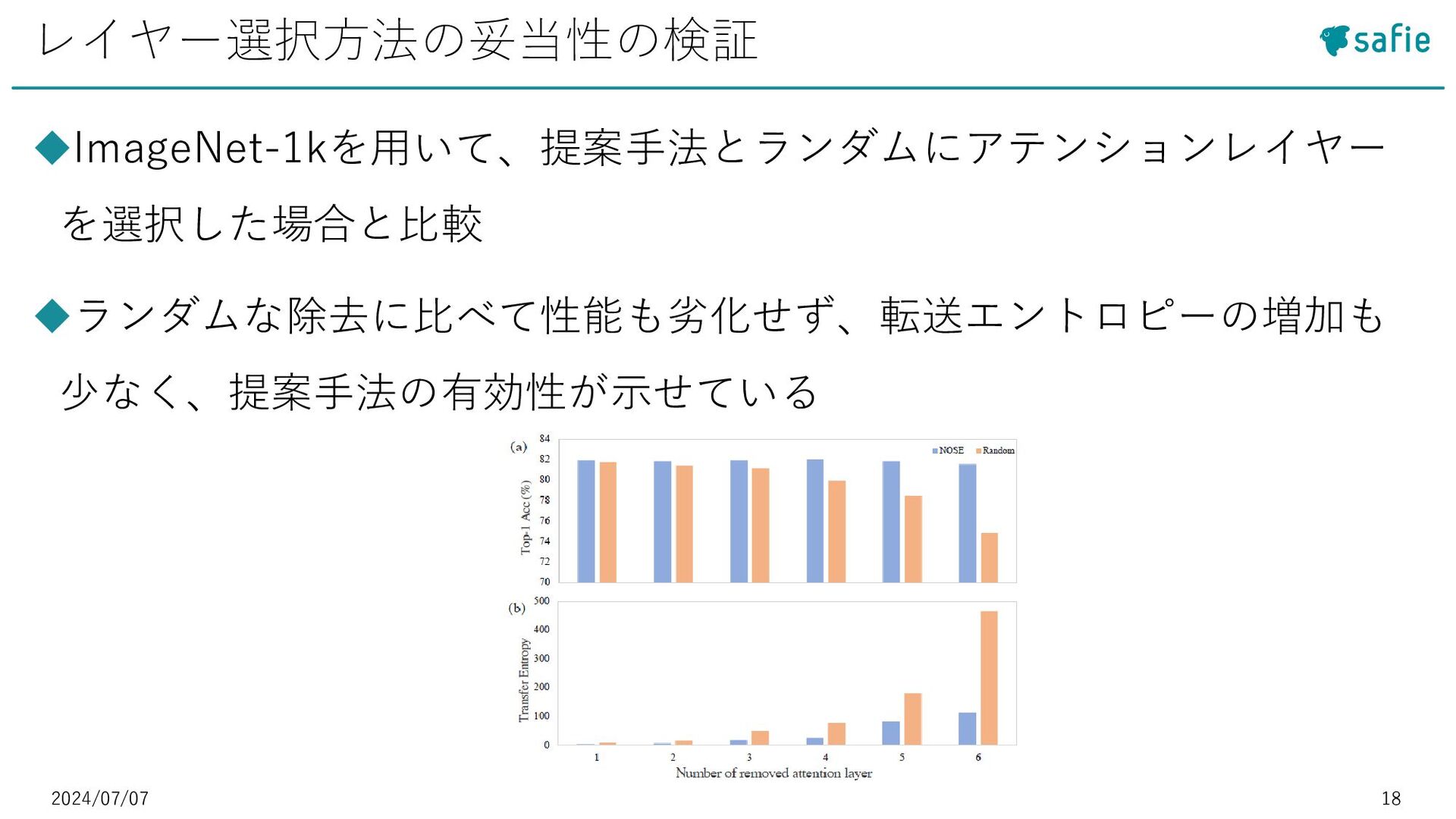
![2024/07/07 19 ◆アテンションレイヤーを除去することで、スループットとメモリー限界を改善しつ つ、認識精度を実現 ◆Token Merging手法(ToMe[5])と合わせると更に性能向上 ◼ [5] Daniel Bolya](https://files.speakerdeck.com/presentations/622f45216f124709acfbecc9ecbc3ec6/slide_18.jpg){kind=link}
{kind=link}
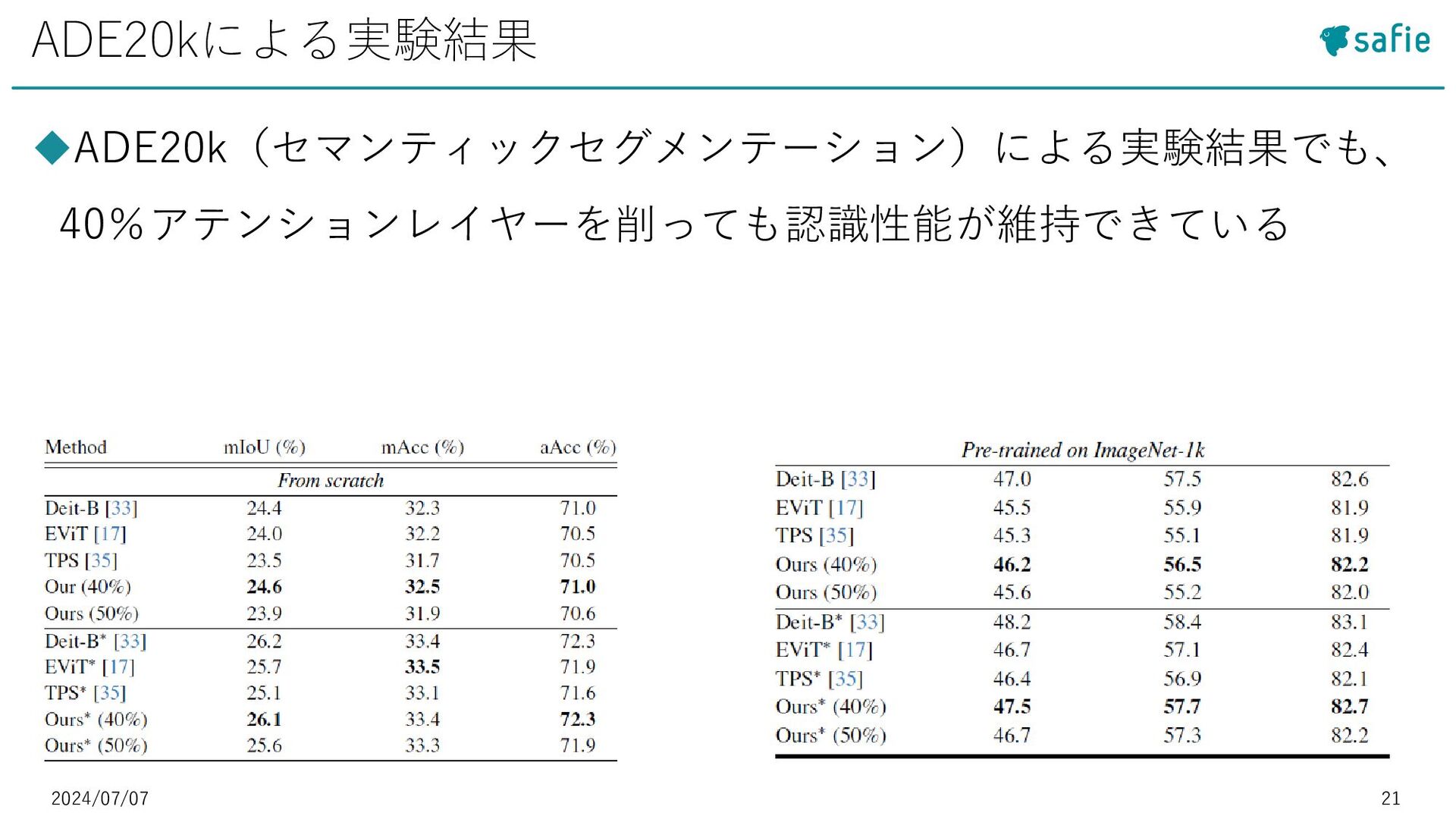{kind=link}
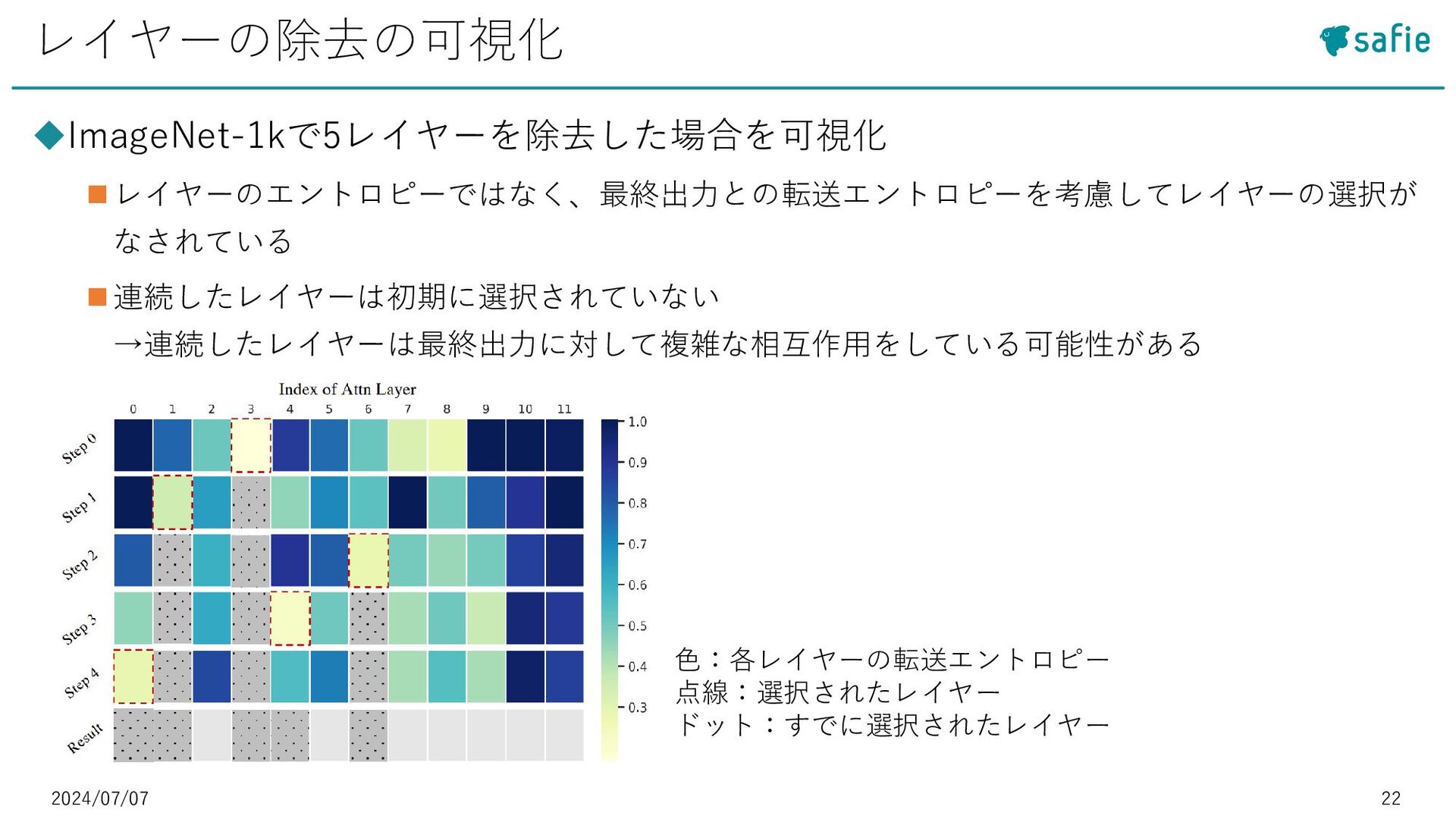{kind=link}
{kind=link}
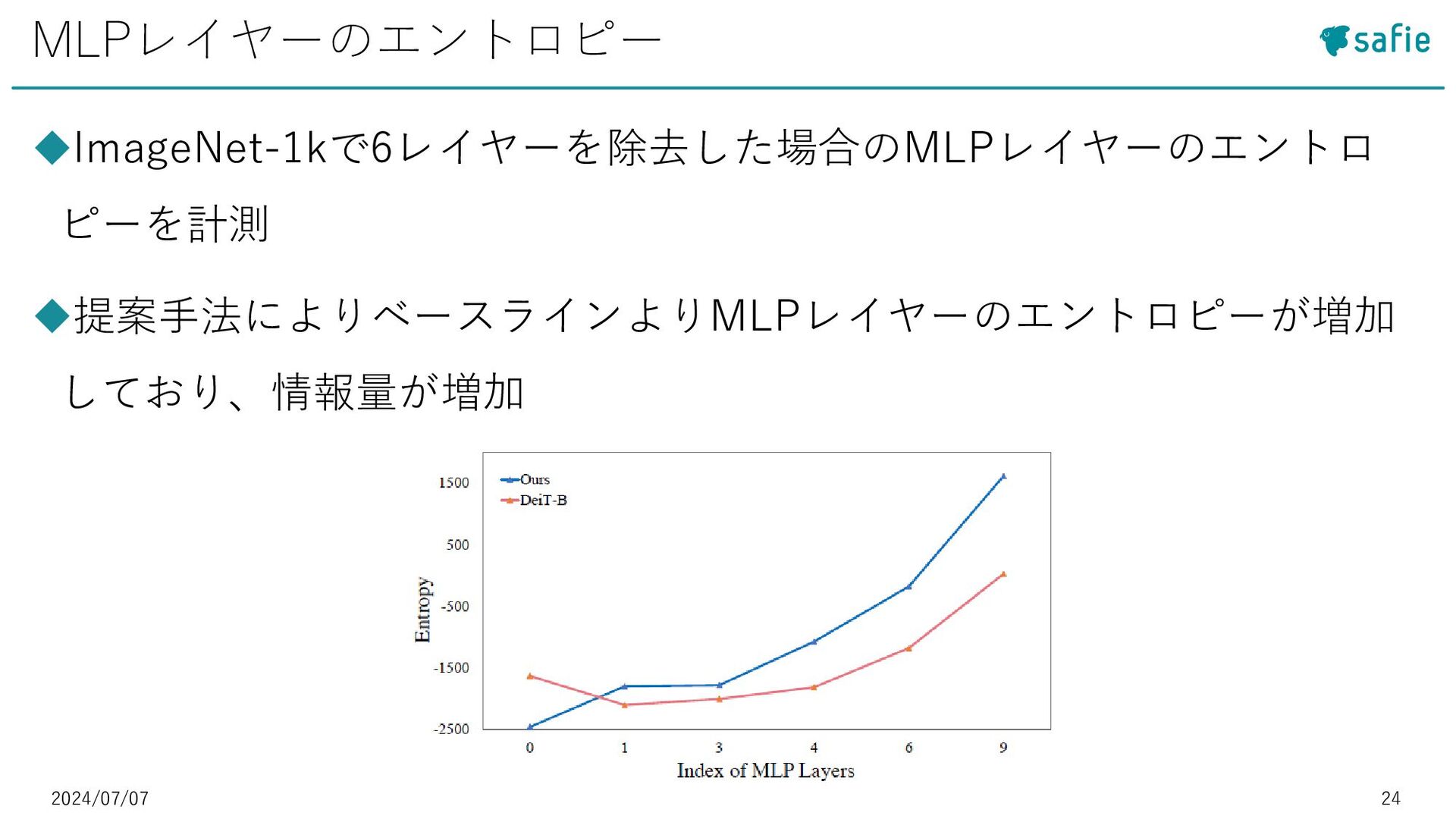{kind=link}
![2024/07/07 25 ◆各Transformer Blockの出力を周波数分析 ◼高周波成分は汎化性に寄与しており[2, 12]、高周波成分が増えることで性能低 下を回避できていると説明できる 周波数分析](https://files.speakerdeck.com/presentations/622f45216f124709acfbecc9ecbc3ec6/slide_24.jpg){kind=link}
{kind=link}
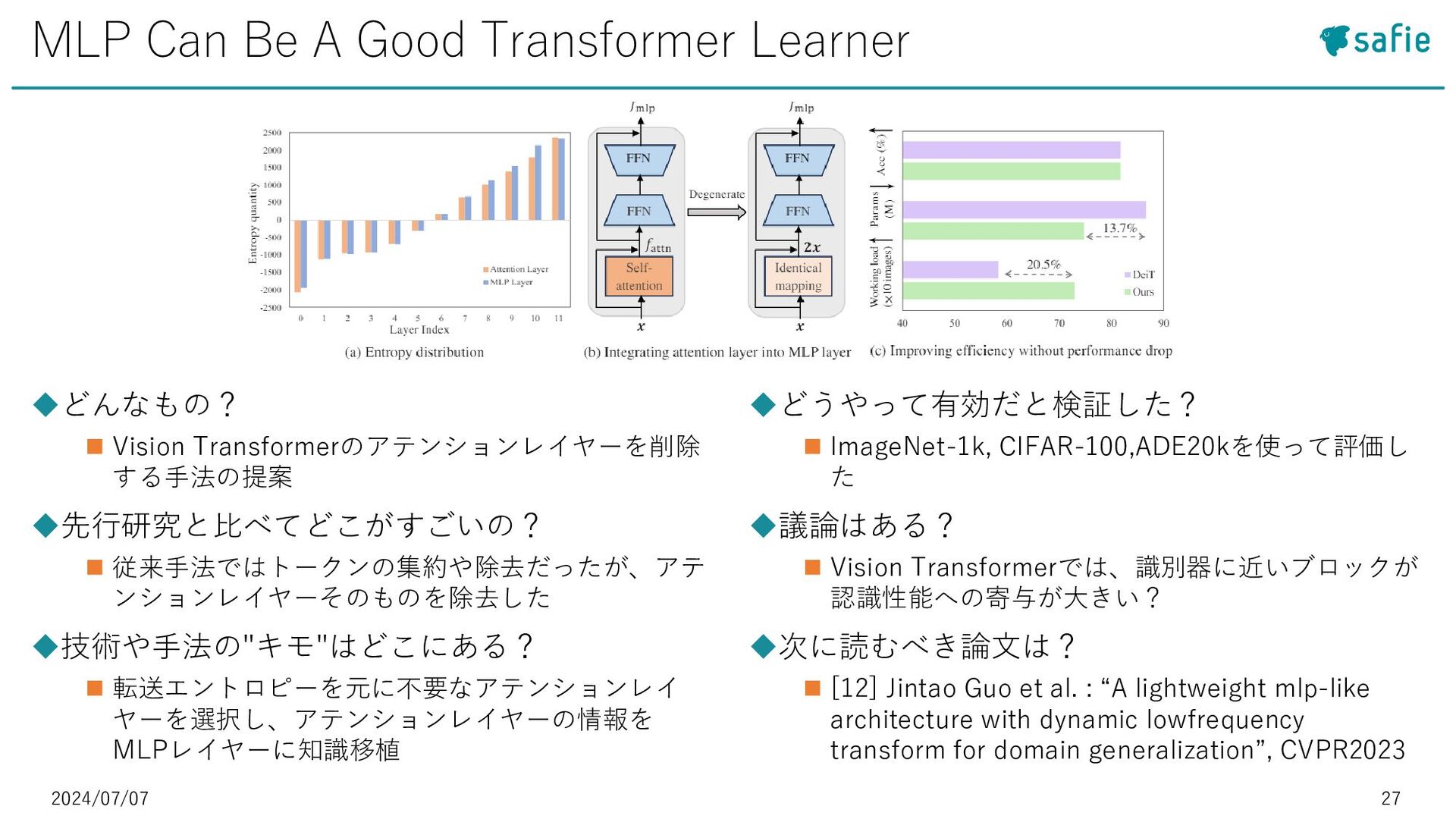{kind=link}