8年連続 受賞 AWS資格 保有数 2800 以上 日本一 SI Partner of the Year 支援中の顧客 3600 以上 AWS プレミアティア パートナー 2023年 APJ一 SI Partner of the Year 2018,2020,2021年 会社紹介 クラスメソッド株式会社 AWSなら私たちといっしょに
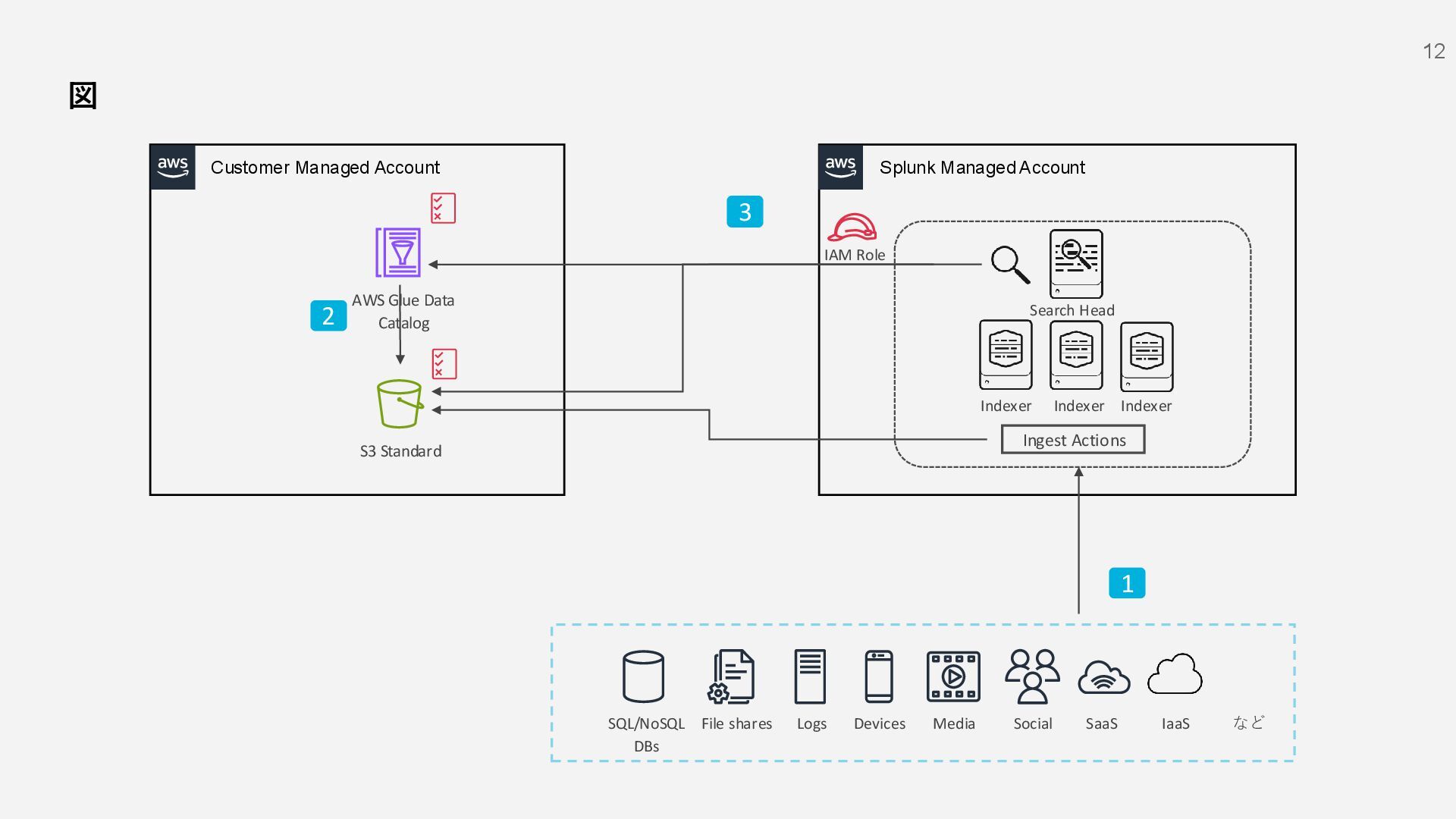
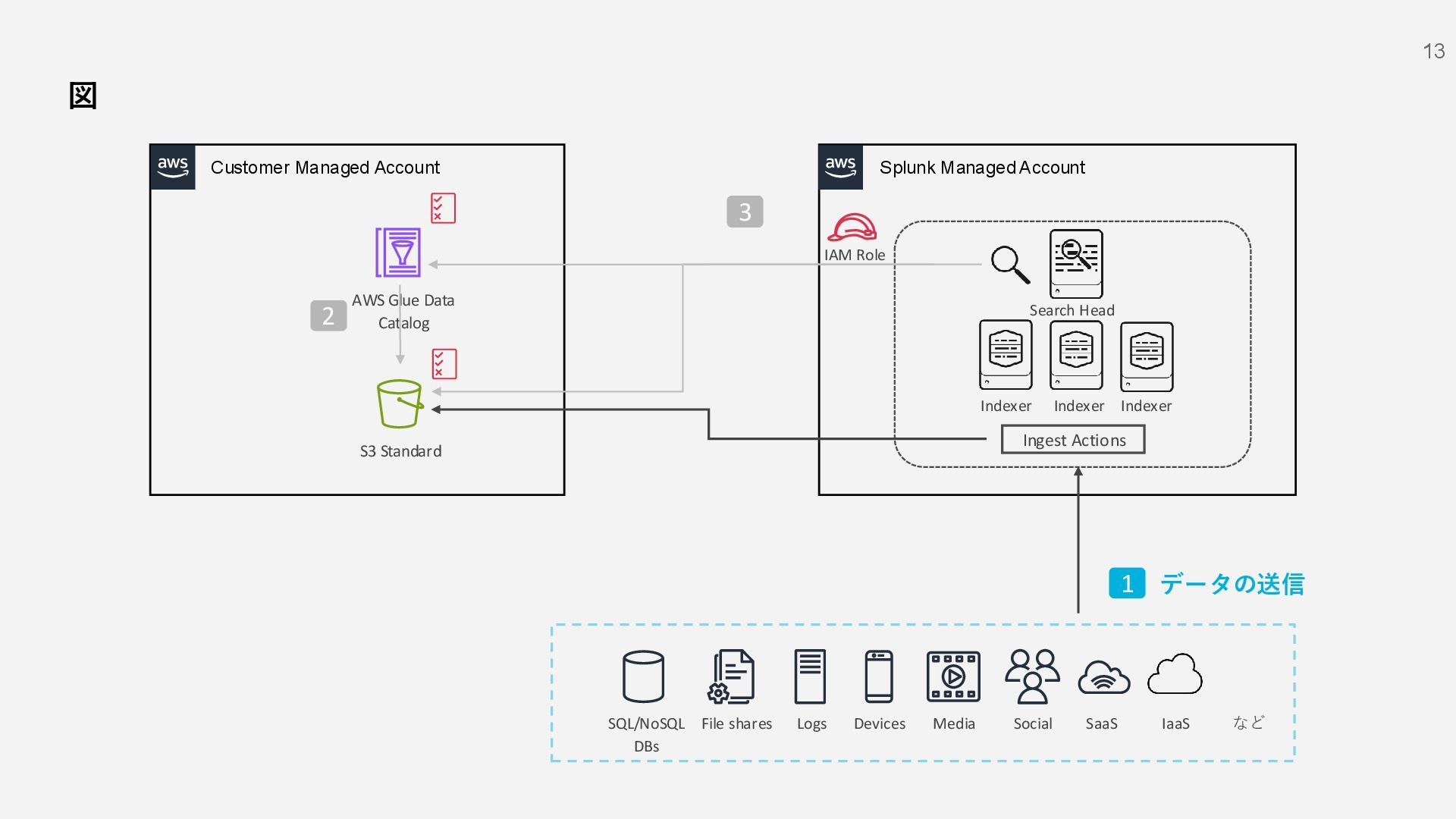
S3 Standard File shares Social Devices Media Logs SQL/NoSQL DBs IaaS など SaaS 1 AWS Glue Data Catalog IAM Role Indexer Indexer Indexer Search Head 2 3 データの送信
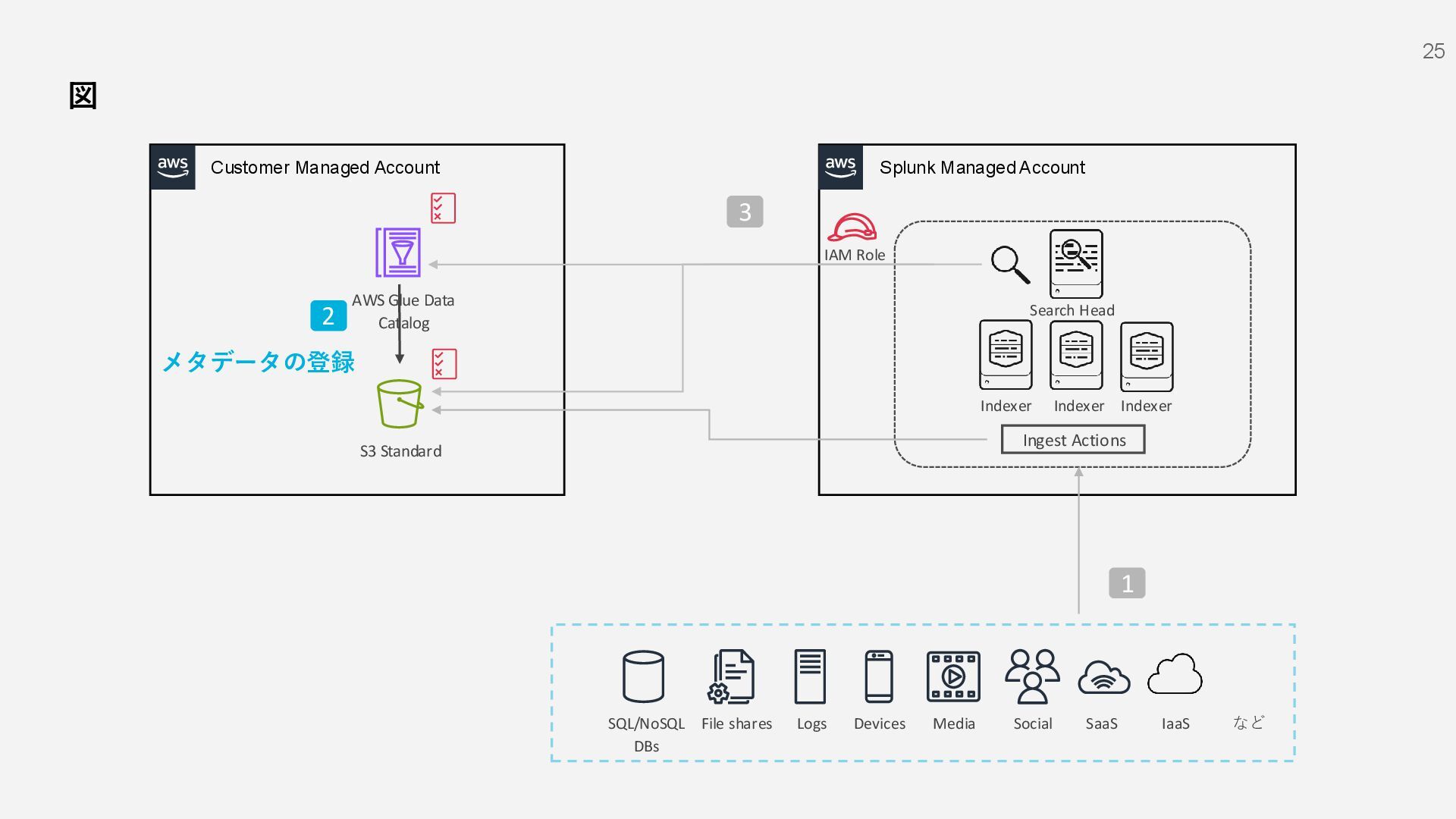
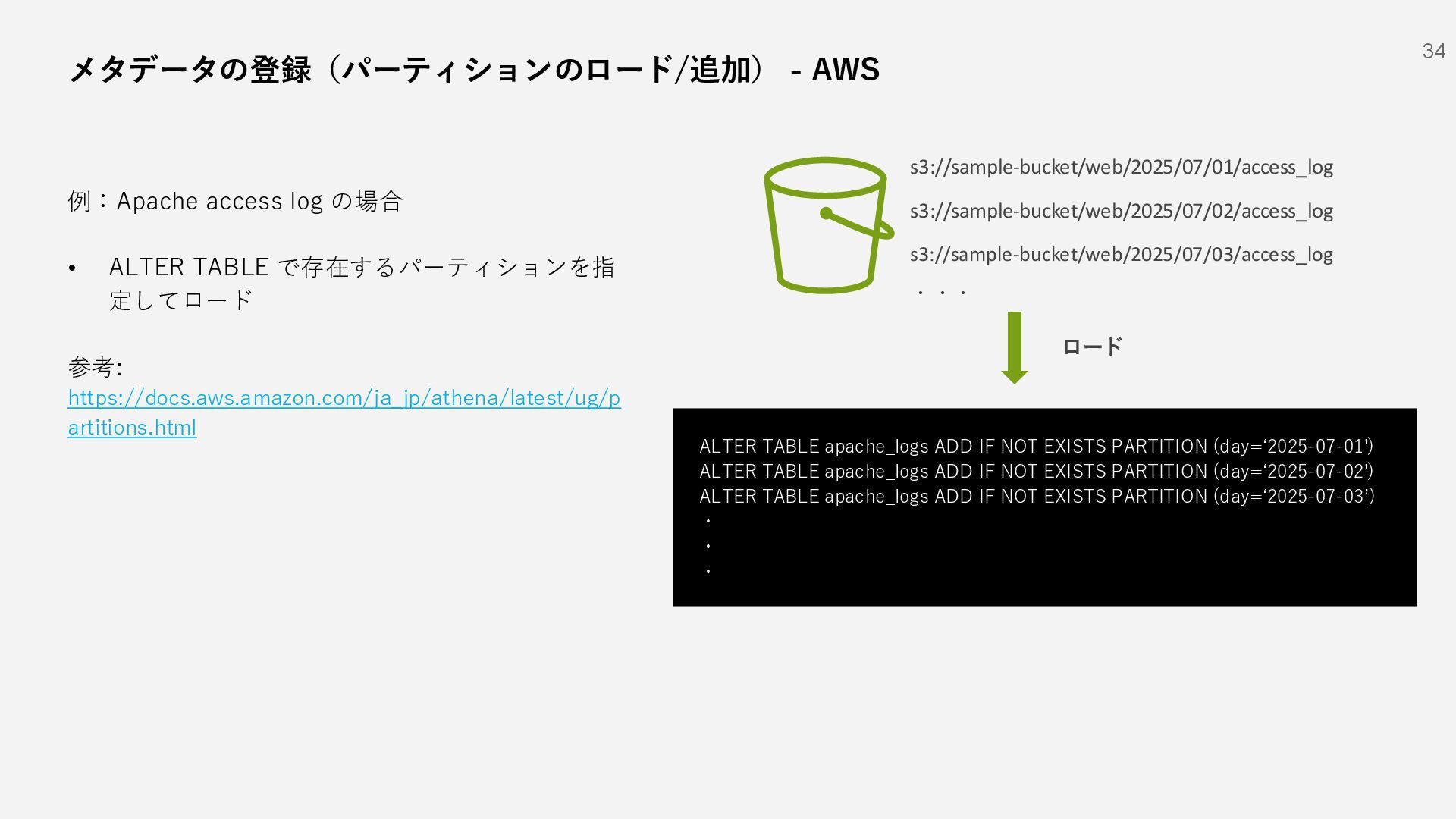
S3 Standard File shares Social Devices Media Logs SQL/NoSQL DBs IaaS など SaaS 1 AWS Glue Data Catalog IAM Role Indexer Indexer Indexer Search Head 2 3 メタデータの登録
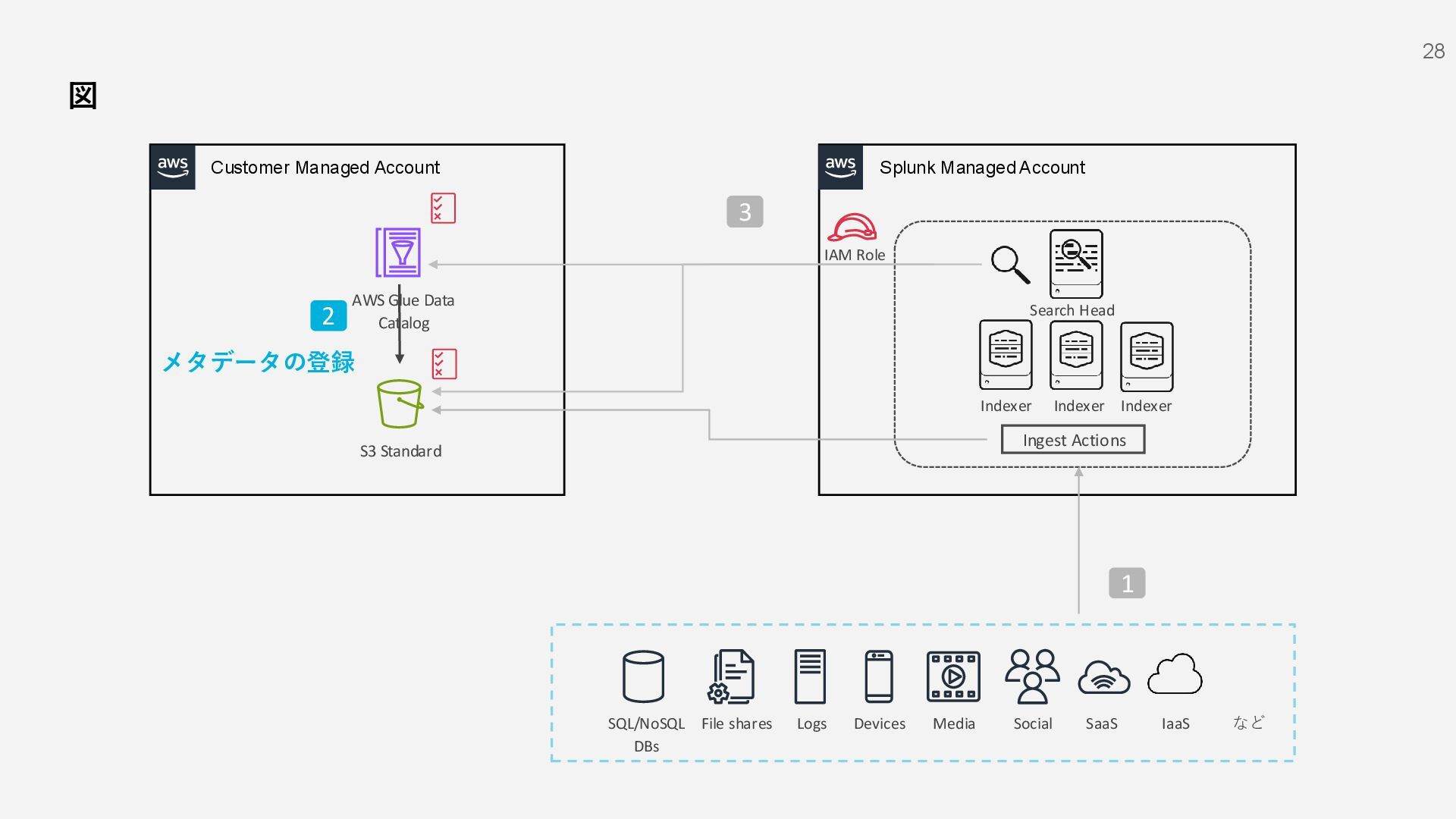
S3 Standard File shares Social Devices Media Logs SQL/NoSQL DBs IaaS など SaaS 1 AWS Glue Data Catalog IAM Role Indexer Indexer Indexer Search Head 2 3 メタデータの登録
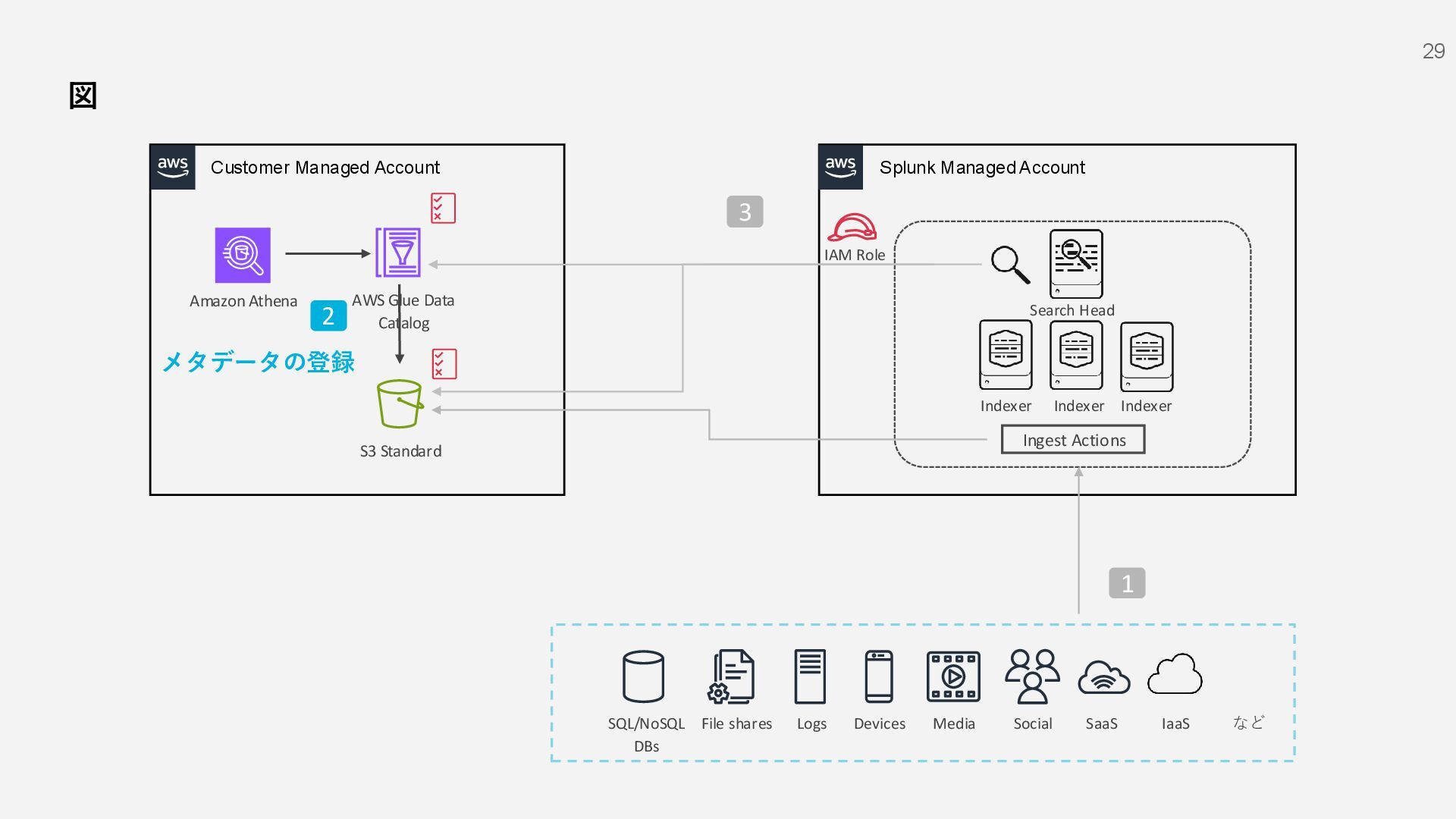
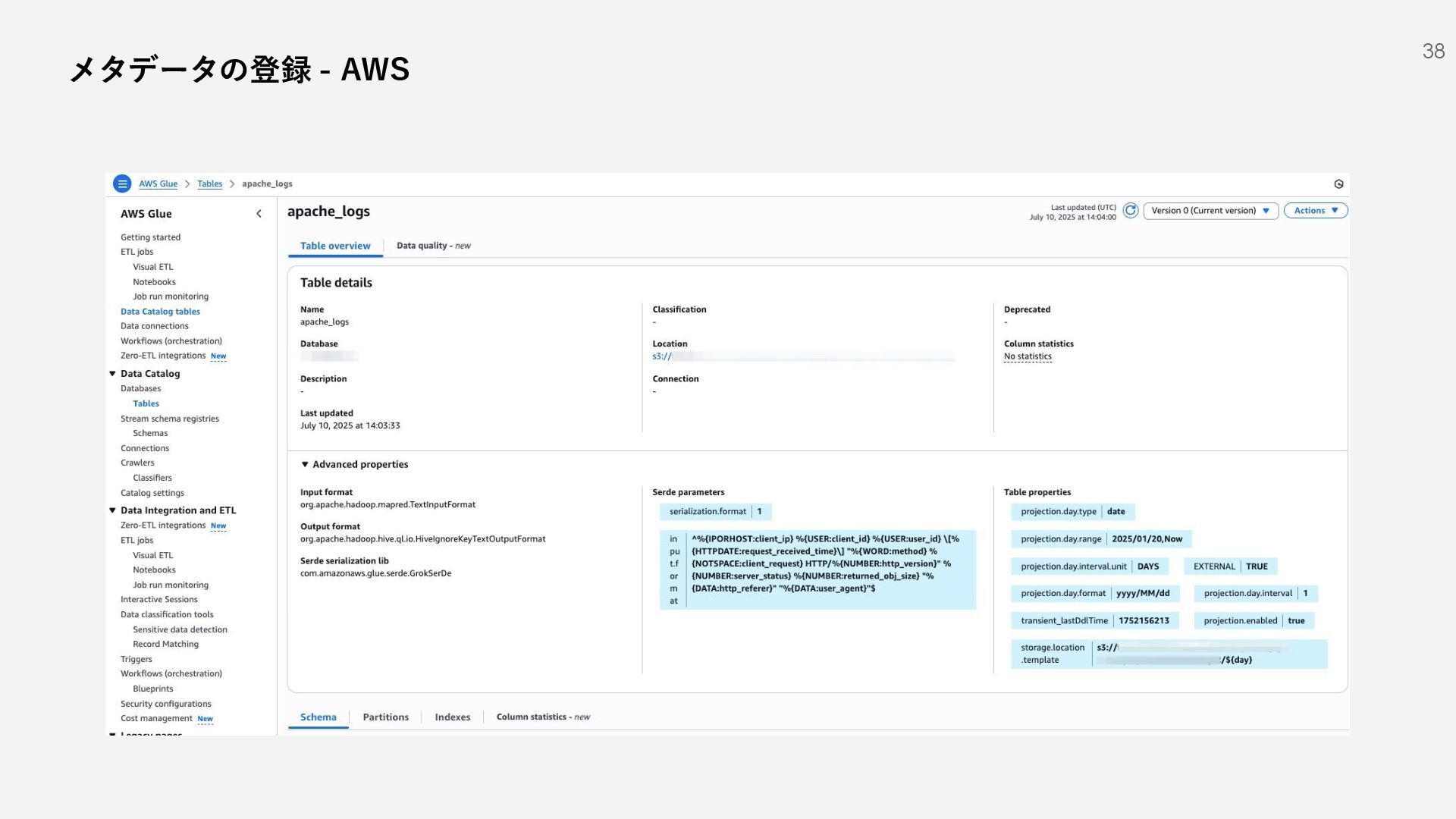
S3 Standard File shares Social Devices Media Logs SQL/NoSQL DBs IaaS など SaaS 1 AWS Glue Data Catalog IAM Role Indexer Indexer Indexer Search Head 2 3 Amazon Athena メタデータの登録
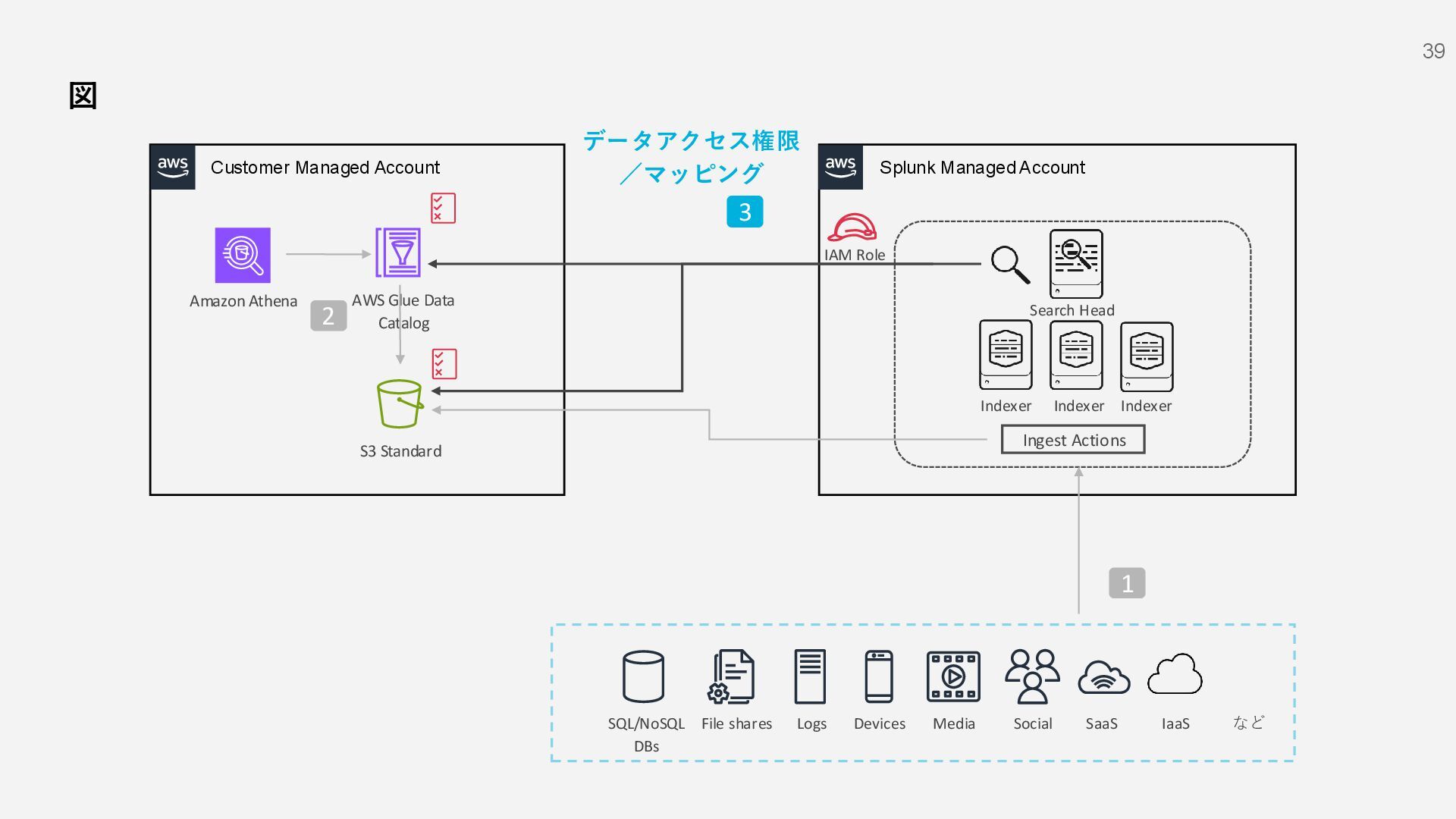
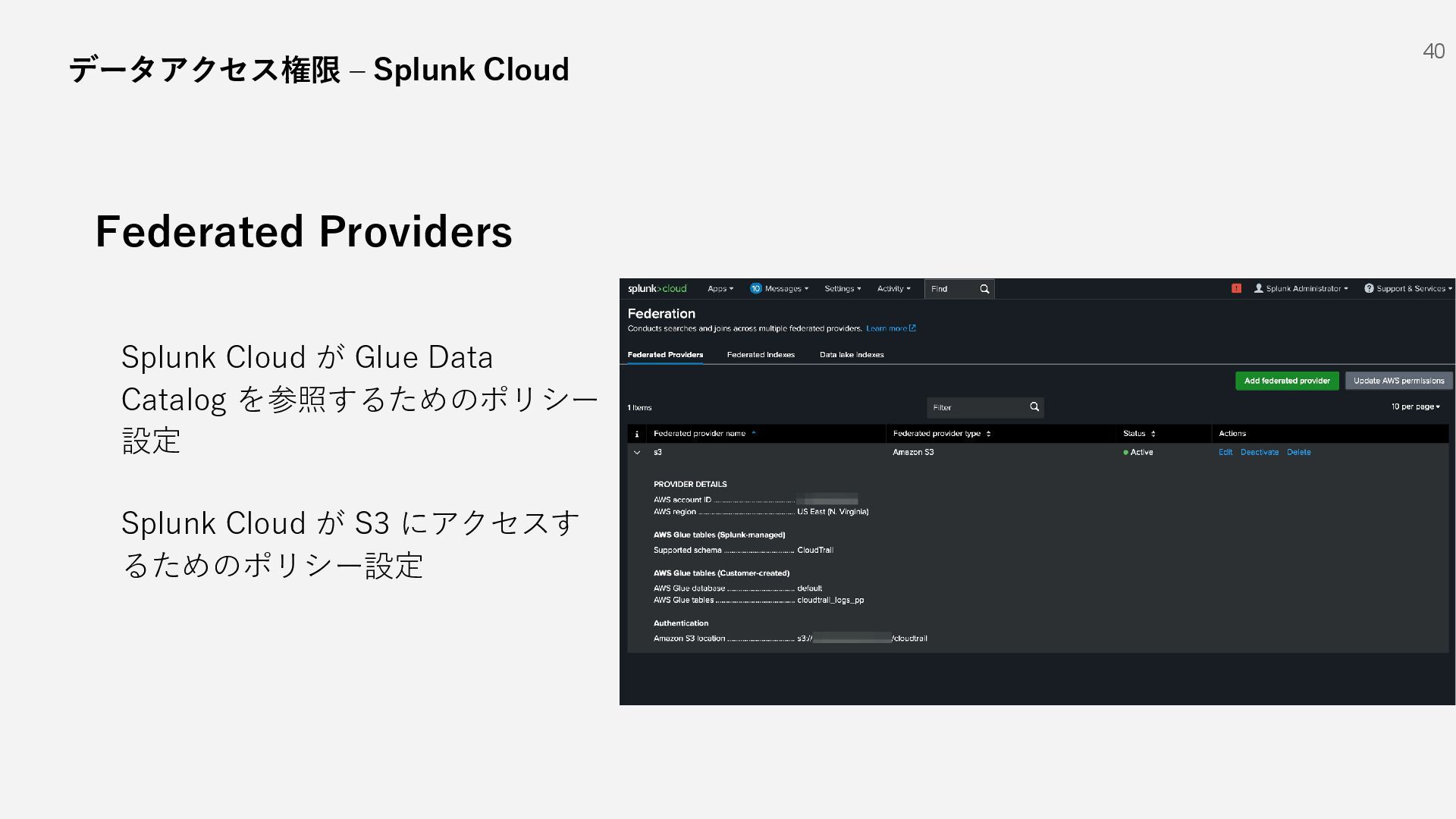
S3 Standard File shares Social Devices Media Logs SQL/NoSQL DBs IaaS など SaaS 1 AWS Glue Data Catalog IAM Role Indexer Indexer Indexer Search Head 2 3 Amazon Athena データアクセス権限 /マッピング
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
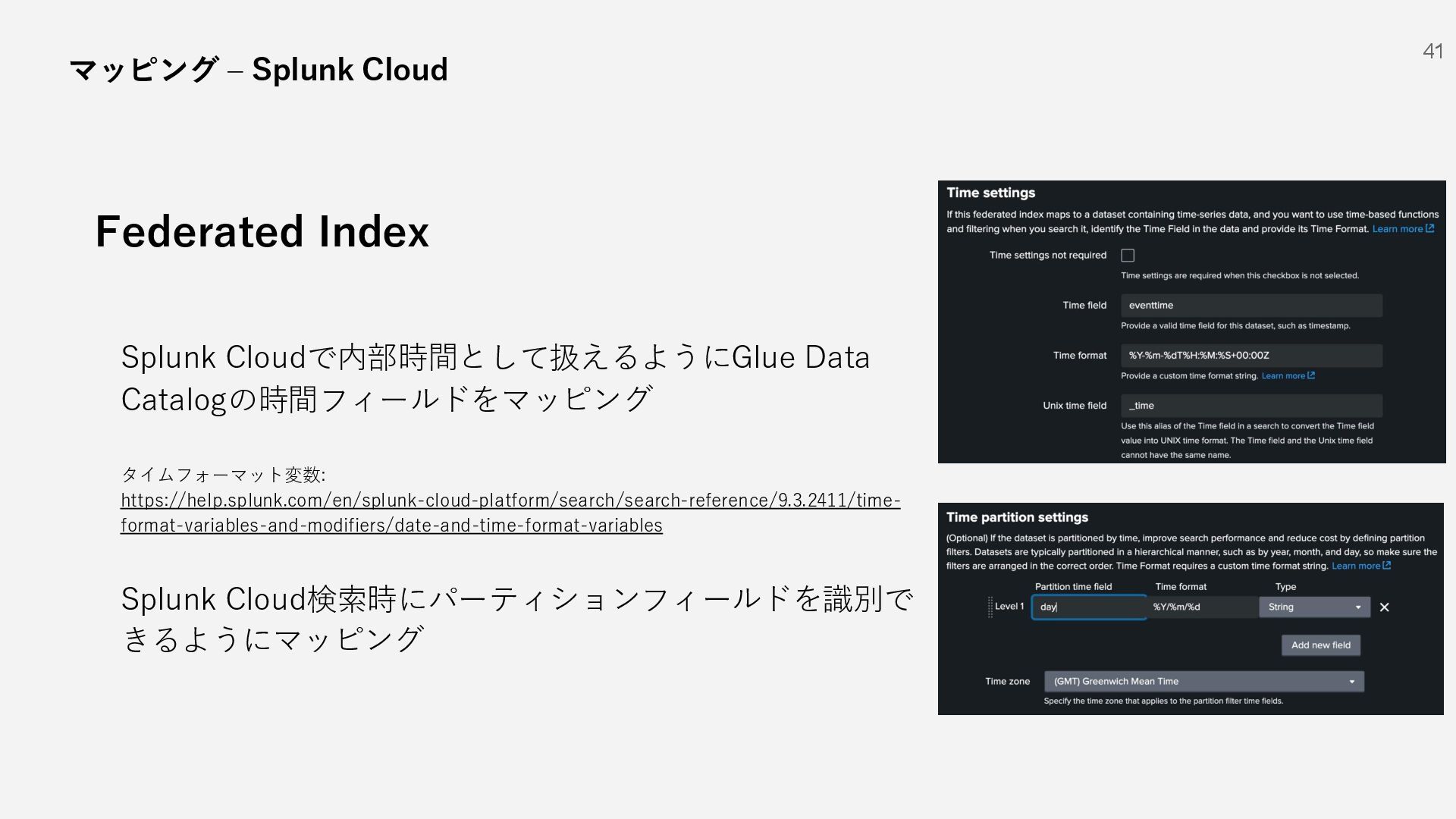{kind=link}
{kind=link}
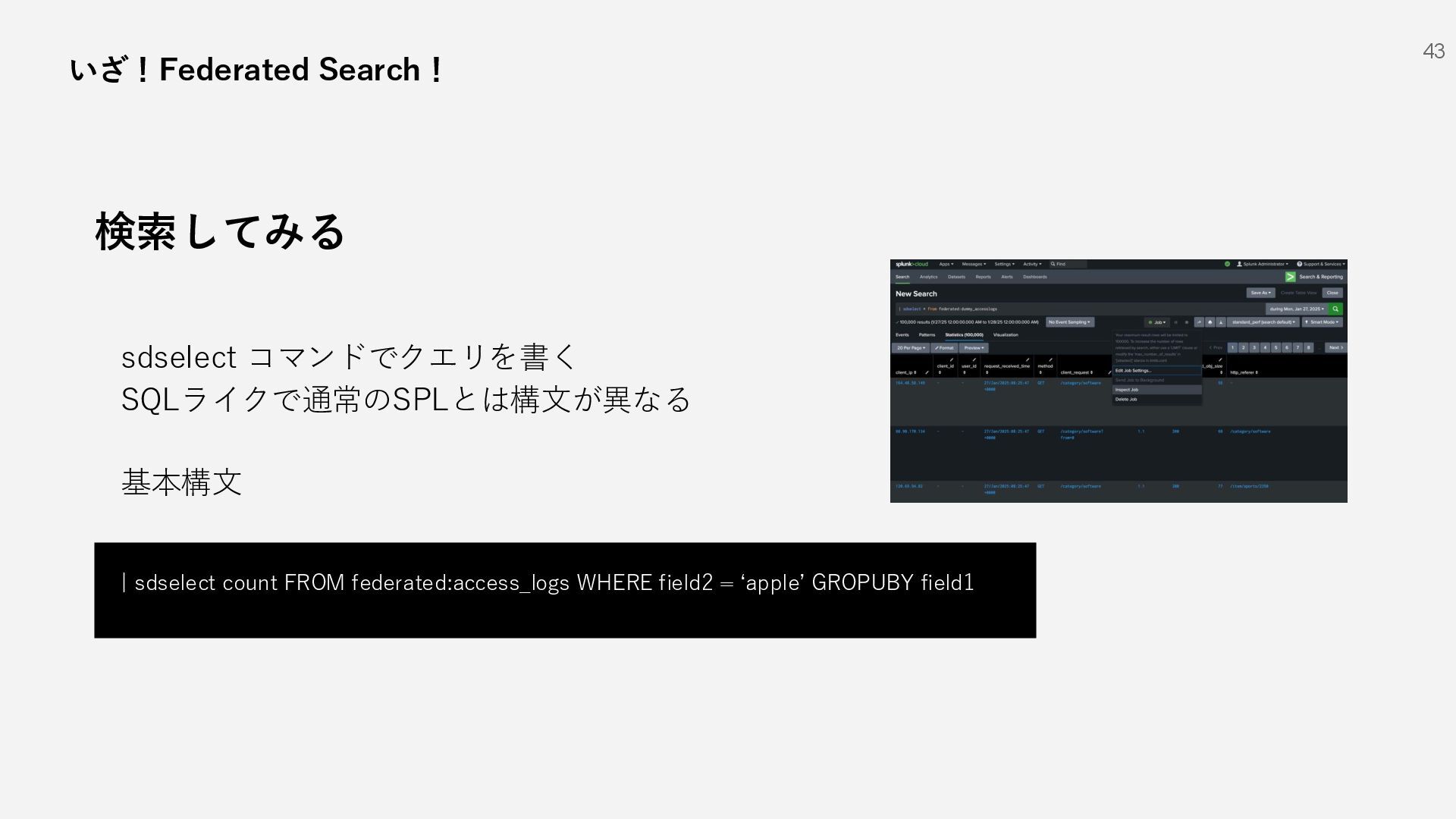{kind=link}
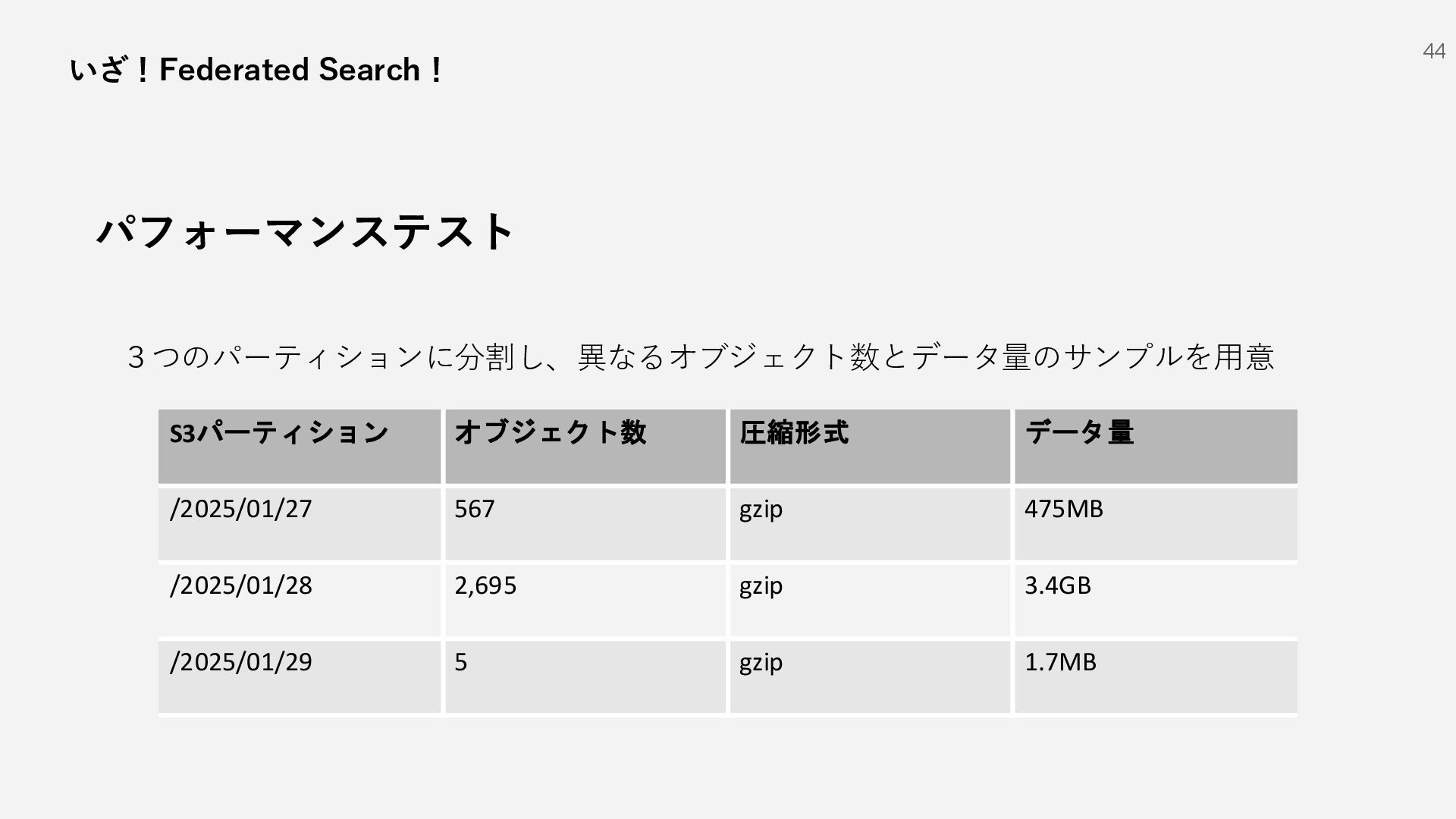{kind=link}
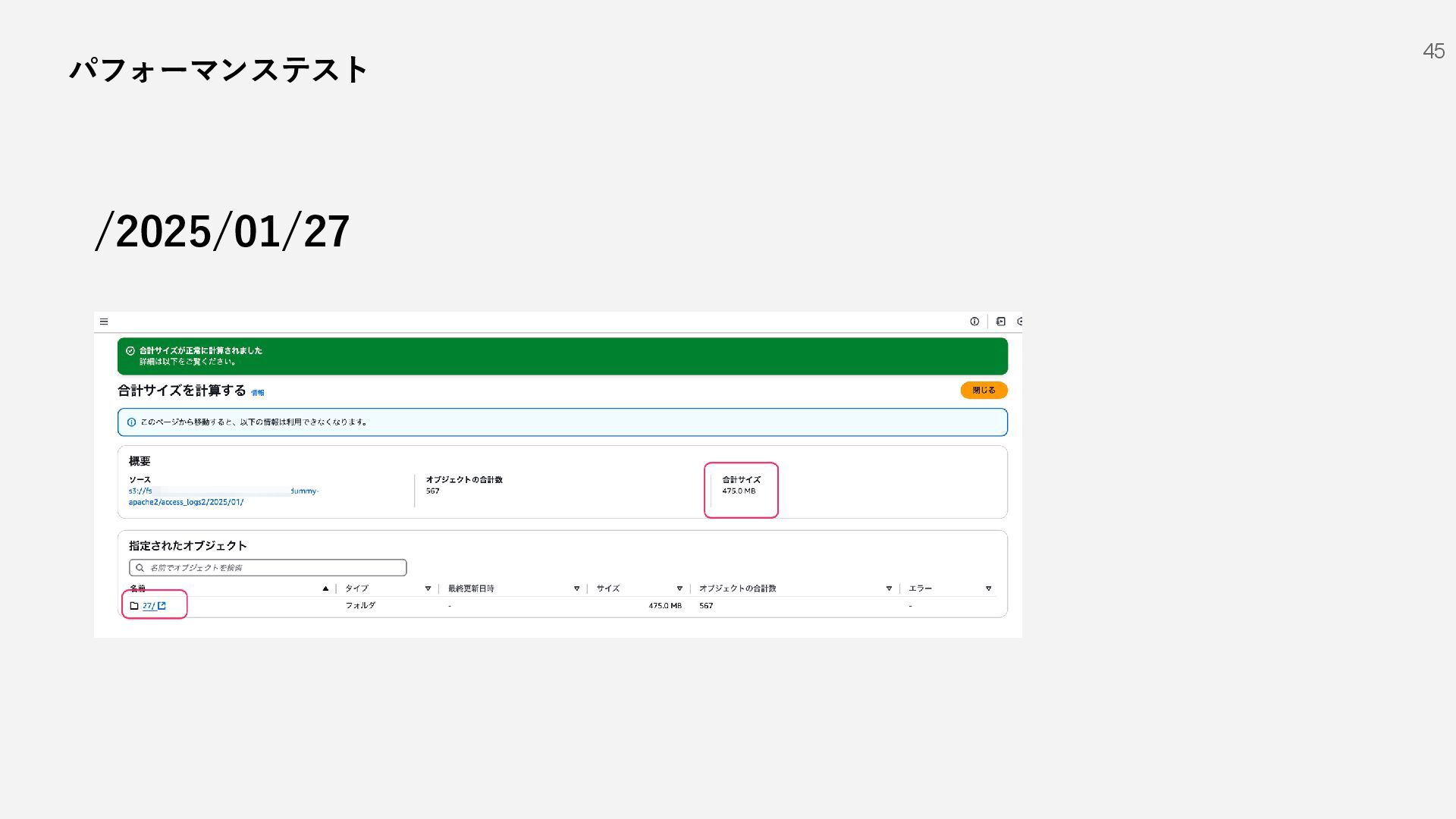{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
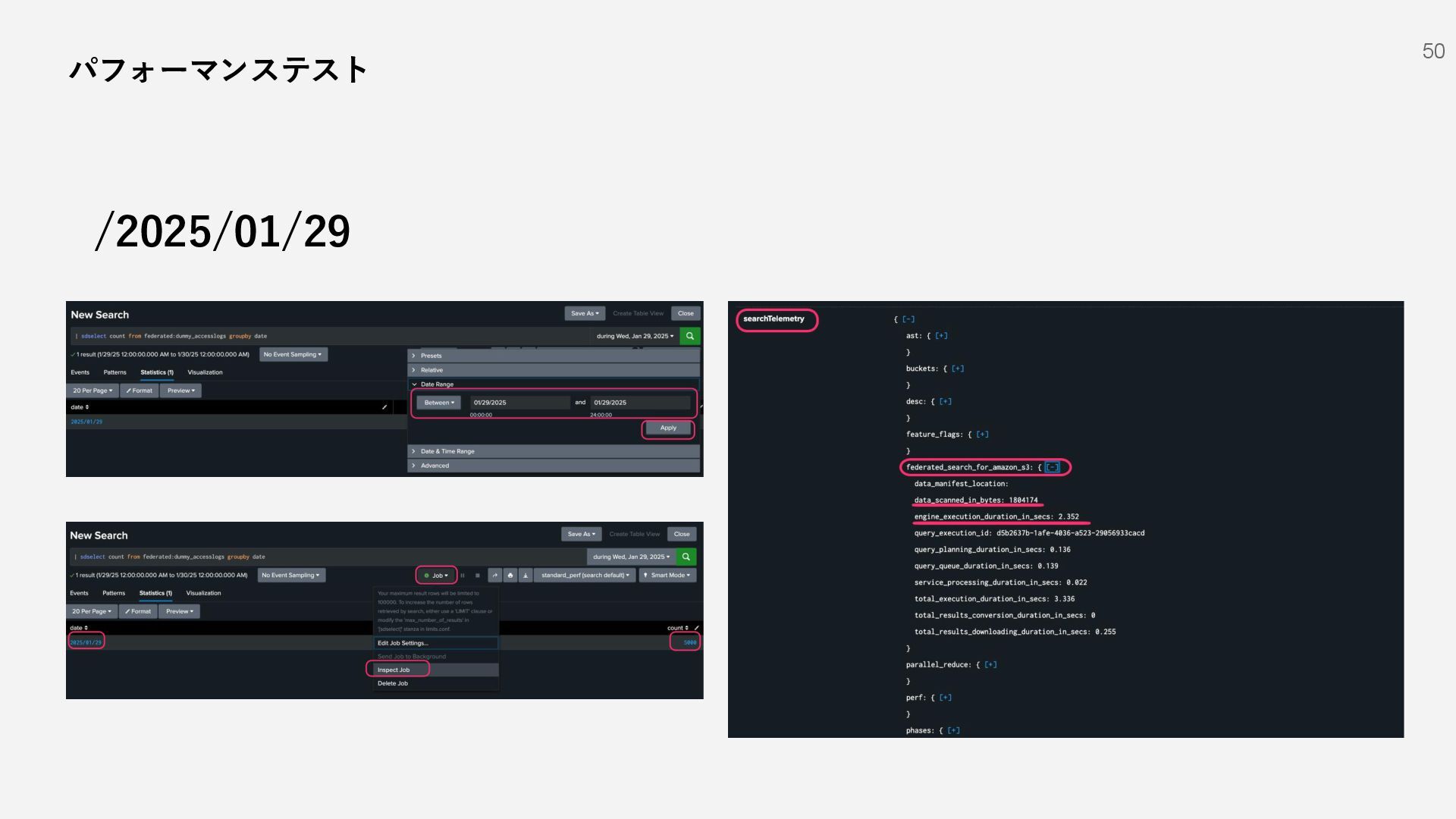{kind=link}
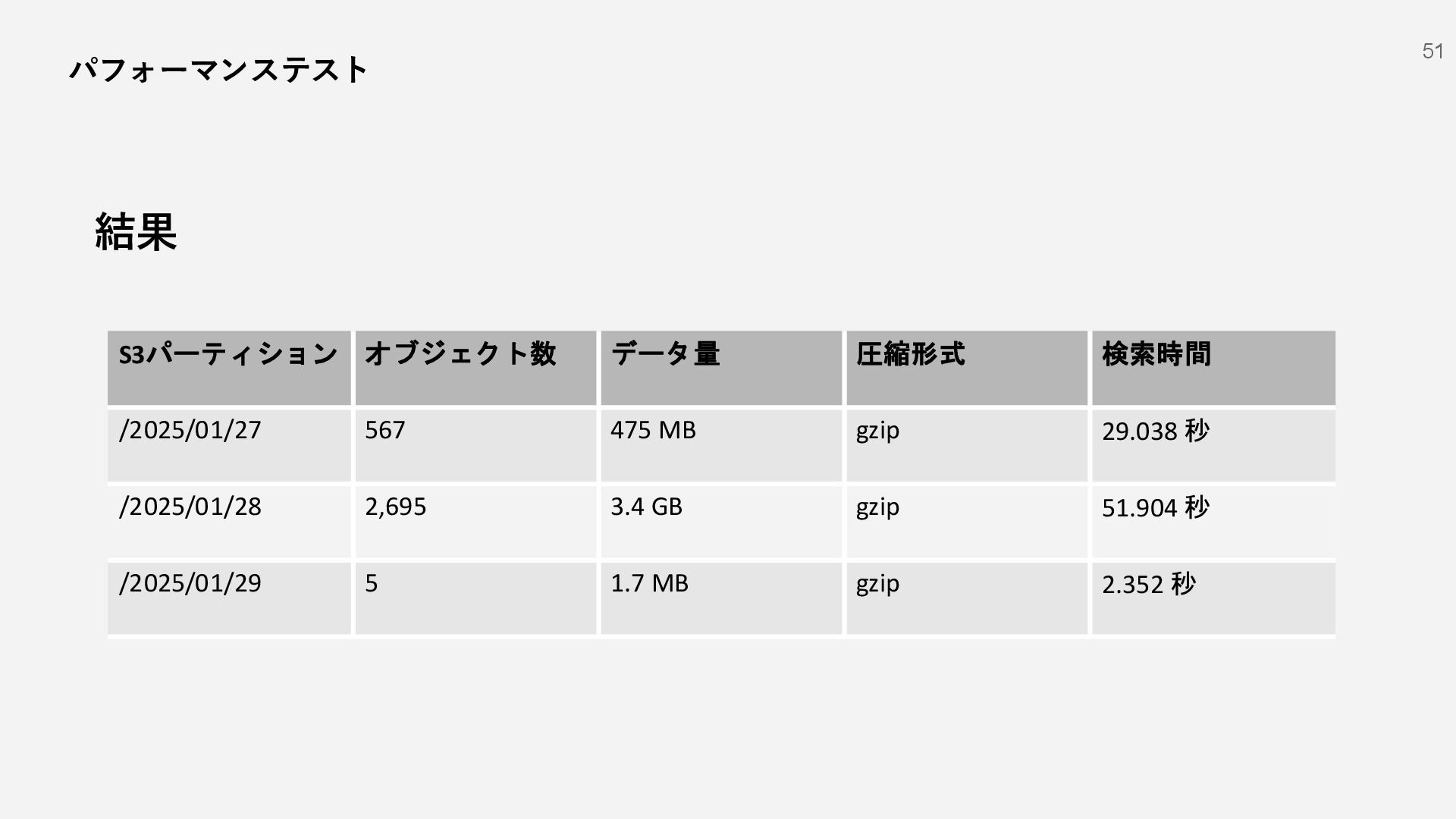{kind=link}
{kind=link}
{kind=link}
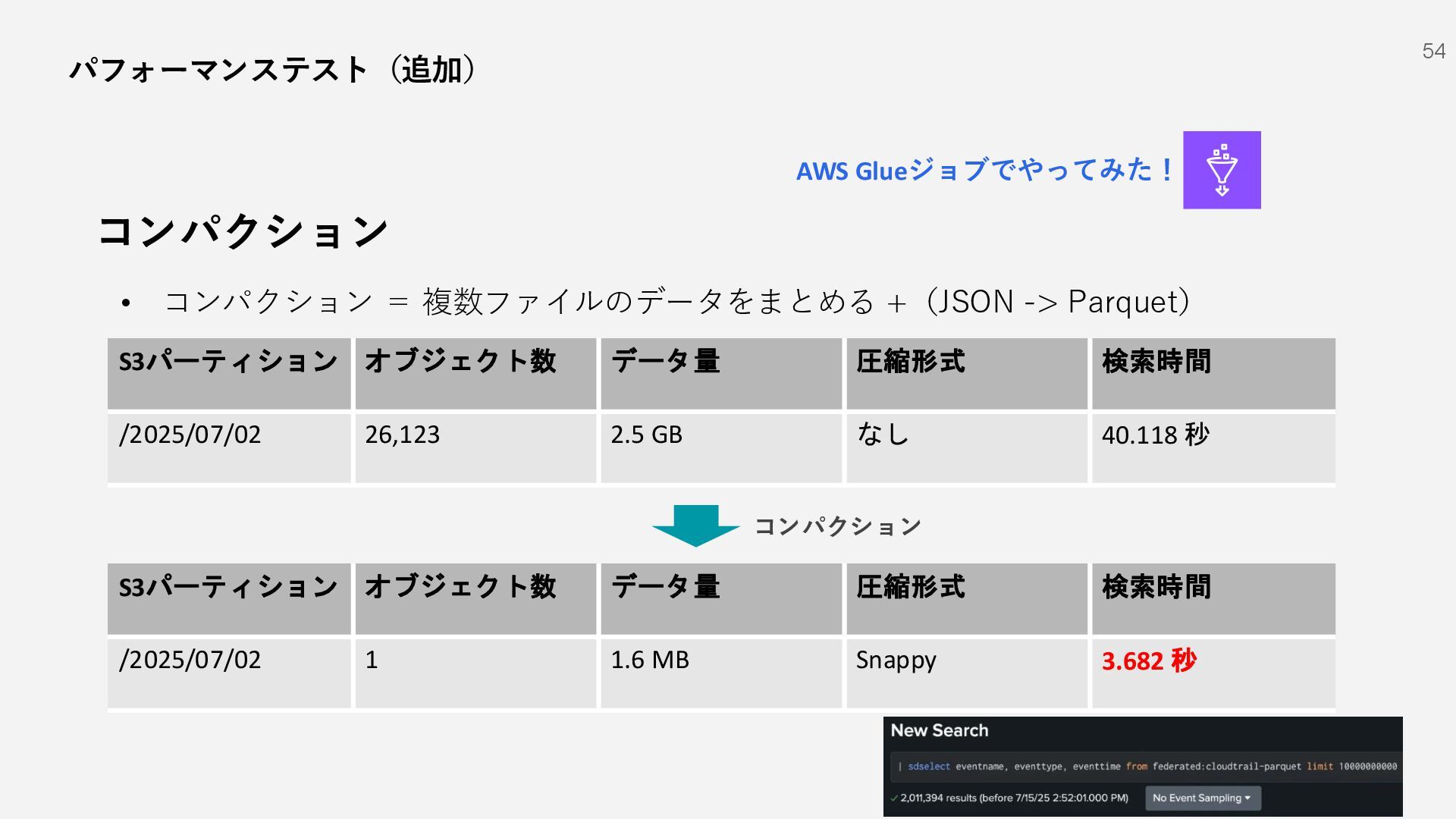{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}