Sorting: string vs numeric – No ranges • Defines fields, types and properties • Defines unique key field, default search field • schema.xml – Defines types used in the webapp – Defines fields and types – Define copyfields
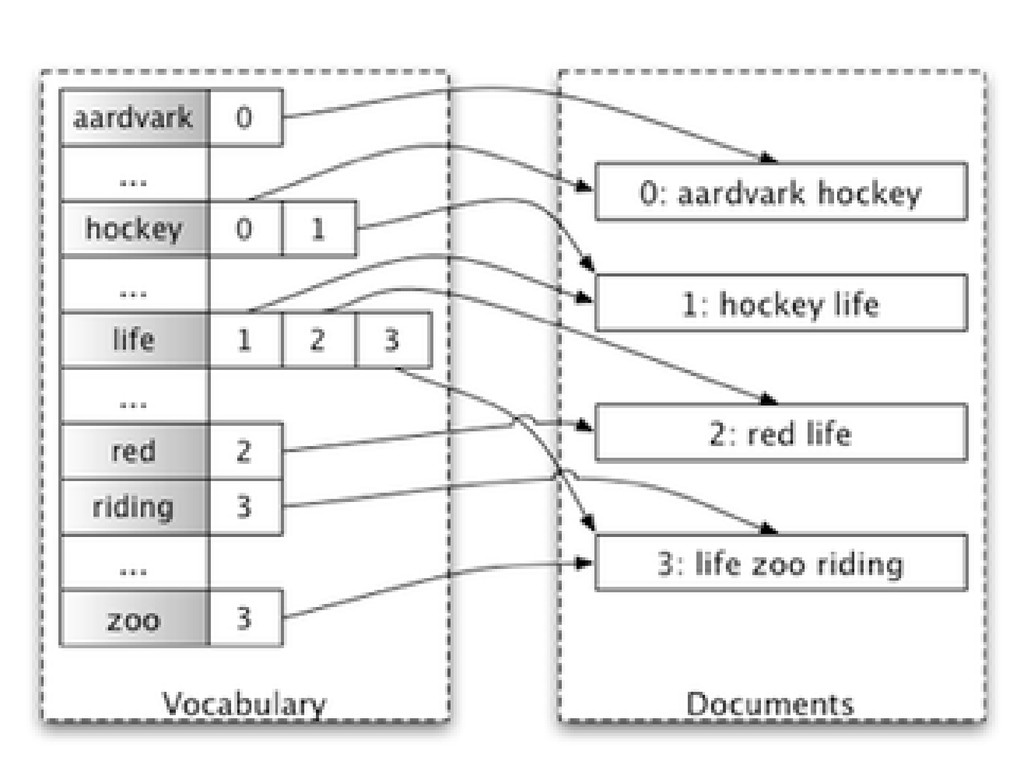
• A document is a collection of fields & values • A field can occur multiple times in a document • Documents are inmutable – They can be deleted, and a new version added, however.
row! • A solr Index store only ONE kind of document definition • A document has typed properties: string, date, integer • Static definition or dynamic type • May be indexed or stored • De-normalize your database into a structured document optimized for the search requirements
• Use case: Analyze same field different ways – Copy into a field with a different analyzer – Boost exact-case, exact-punctuation matches – Language translations, thesaurus, soundex • Use case 2: Index multiple fields into single searchable field
your friend • Returns scoring information • Returns parsed form of query • Includes parsed query, explanations, and • search component timings in response
after all – Some Curl, XML, Json or native PHP array parsing • Using existing libraries – PECL – http://us.php.net/manual/en/book.solr.php – Solr-php-client (follows ZF Coding Standards) – Ez Components ezcSearch
= new SolrInputDocument(); doc.addField("id", "EXAMPLEDOC01"); doc.addField("title", "NOVAJUG SolrJ Example"); solr.add(doc); solr.commit(); // after a batch, not per document solr.optimize(); // periodically, if/when needed
which field apply the highlighting (comma/space separated) hl.snippets => max number of snippets http://localhost:8983/solr/select?q=apple&hl=on&hl.fl=*
documents such as Word, PDF, HTML, and many other types curl http://localhost:8983/solr/update/extract?literal.id=doc1&commit=true' –F [email protected]
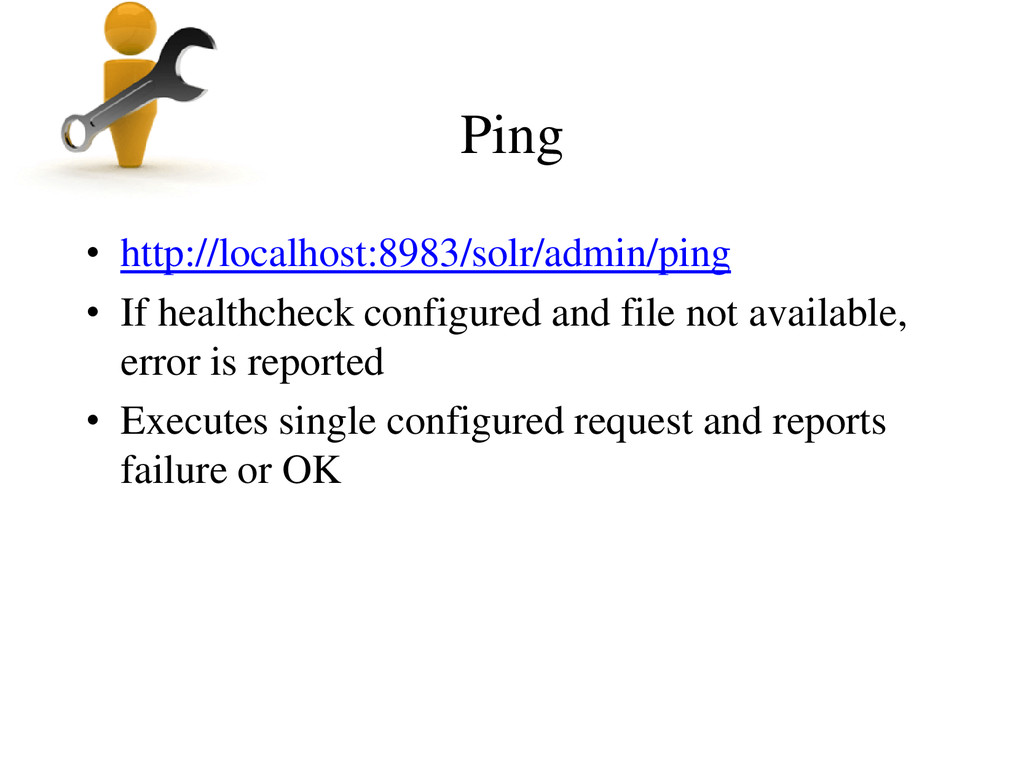
web context • Careful with content stream enabled, client could retrieve contents of any file on server or accessible network! [Solution: disable dump request handler]
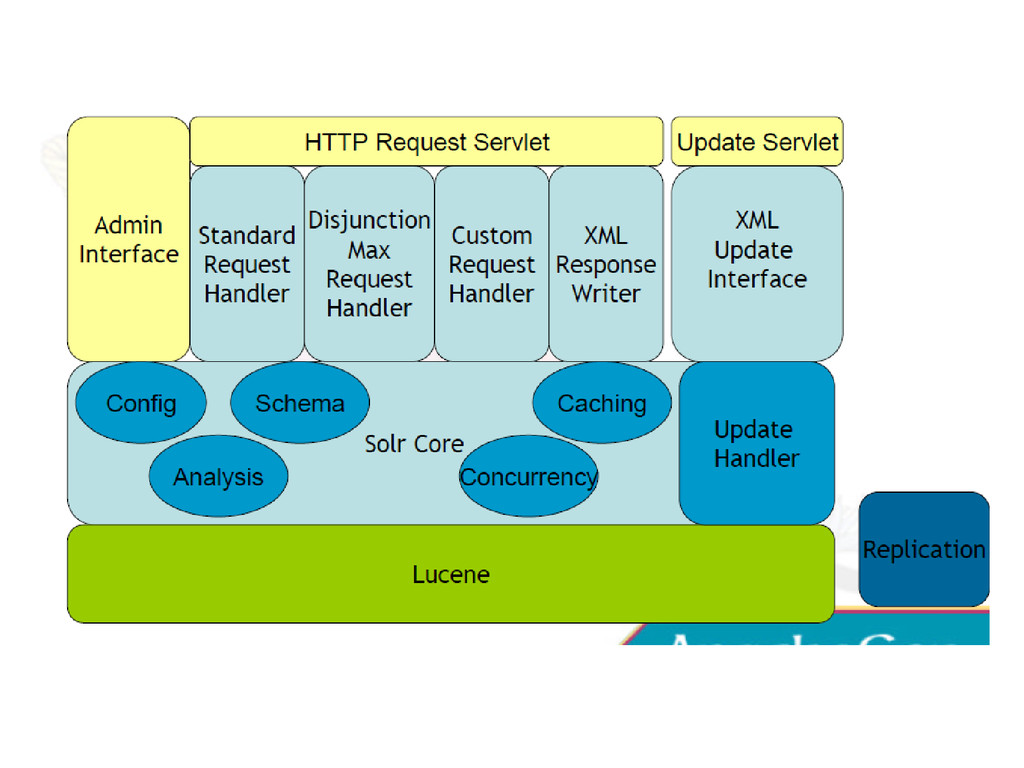
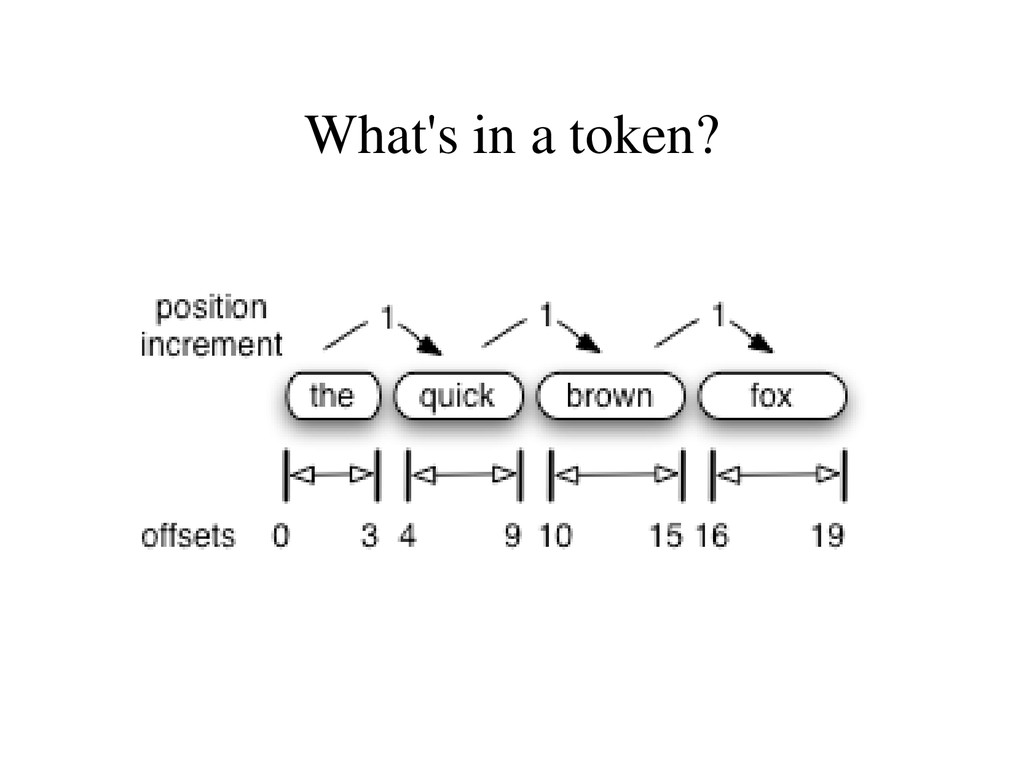
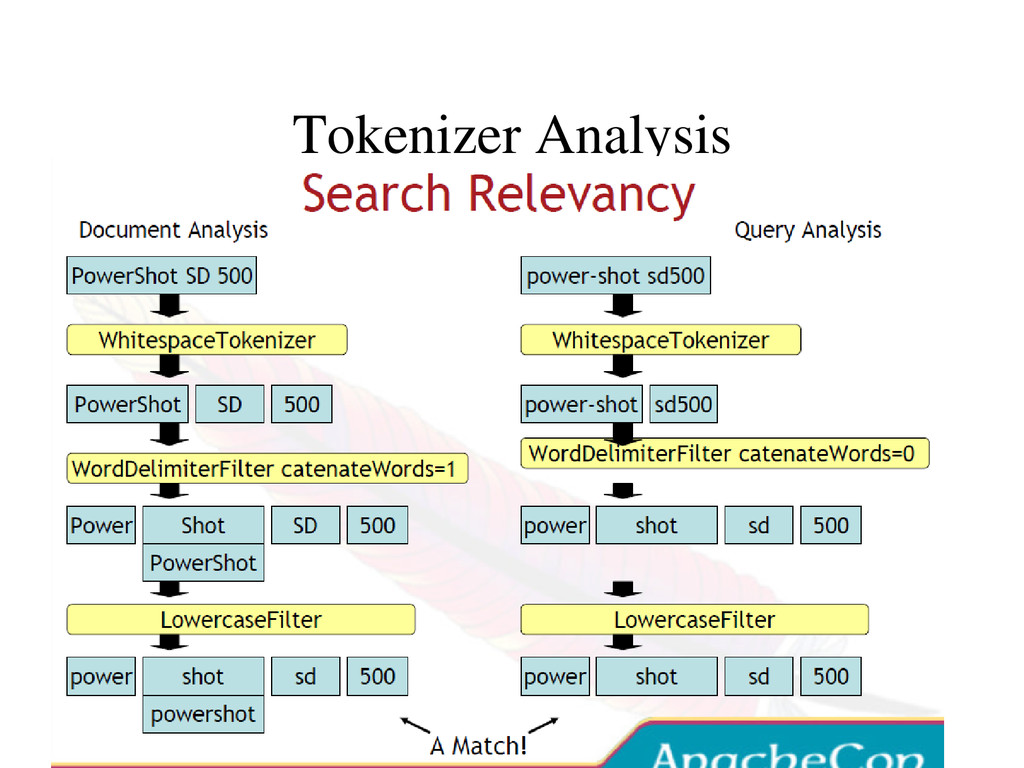
And TokenFilters • Tokenizer: Controls How Your Text Is Tokenized • TokenFilter: Mutates And Manipulates The Stream Of Tokens • Solr Lets You Mix And Match Tokenizers and TokenFilters • In Your schema.xml To Define Analyzers On The Fly • OOTB Solr Has Factories For 17 Tokenizers and 45 TokenFilters • Many Factories Have Customization Options – Limitless Combinations
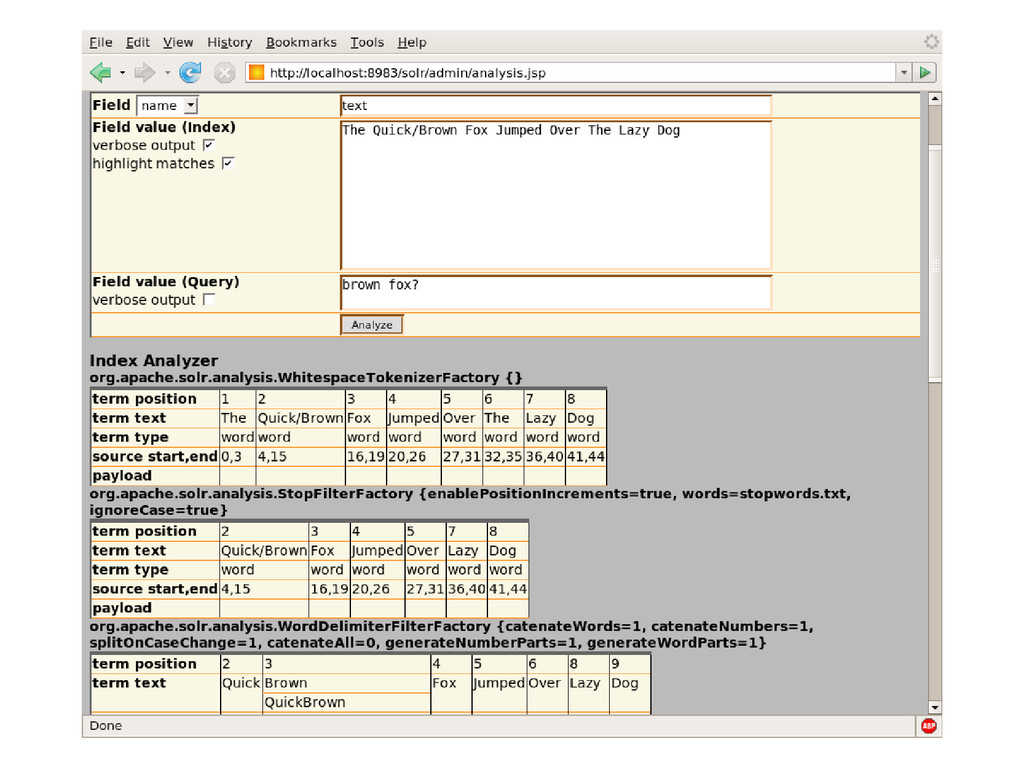
Text And See How It • Would Be Analyzed For A Given Field (Or Field Type) • Displays Step By Step Information For Analyzers • Configured Using Solr Factories... • Token Stream Produced By The Tokenizer • How The Token Stream Is Modified By Each TokenFilter • How The Tokens Produced When Indexing Compare With • The Tokens Produced When Querying • Helpful In Deciding Which Tokenizer/TokenFilters You • Want To Use For Each Field Based On Your Goals
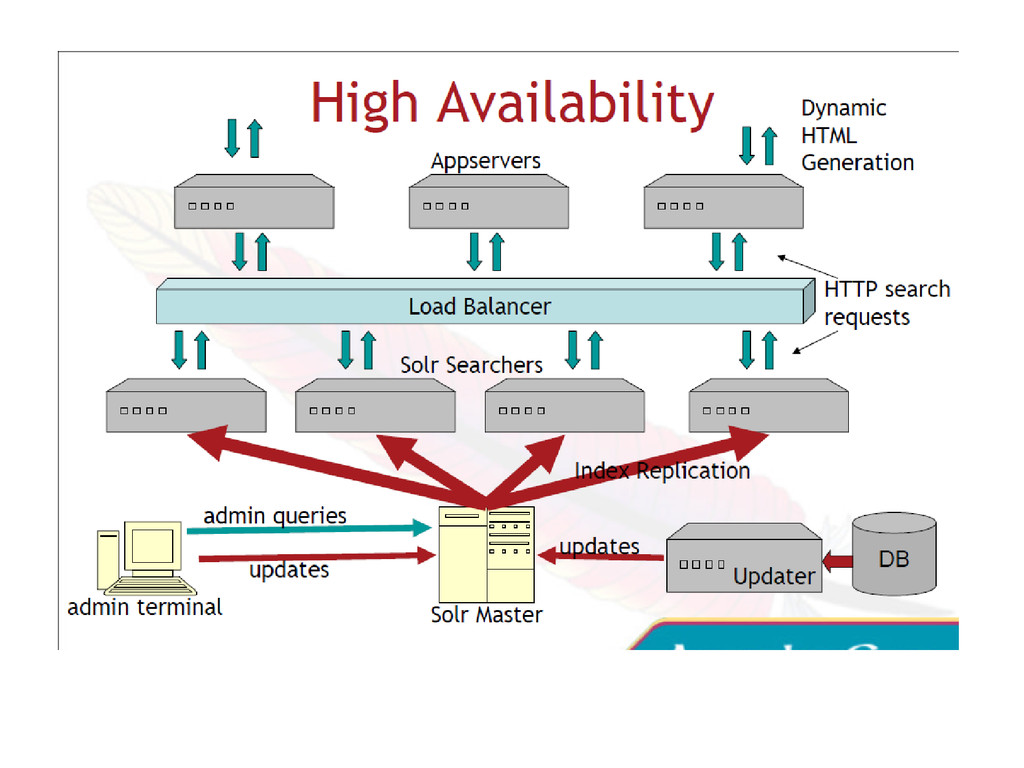
bodies of data efficiently. • Both have a long list of high-traffic sites using them • Both offer commercial support. • Both offer client API bindings for several platforms/languages • Both can be distributed to increase speed and capacity First round! Similarities
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Solr Query syntax • Range searching – Timestamp:[2006-01-01 TO *]](https://files.speakerdeck.com/presentations/6b061c7a35224efeb8ad09490ba8ef41/slide_30.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}