indexación y búsqueda de texto • No es un servidor • No tiene ficheros de configuración – Analizadores de texto (de frases a términos) – Sintáxis de búsqueda – Algoritmo de puntuación
de indexación y búsqueda mediante HTTP • Varios niveles de cache • Administración Web • Ficheros de configuración para el esquema y el servidor • Conteos (faceting), Spellchecker, Morelikethis • Escalable
coleccion de documentos NO relacional • Los documentos son inmutables • Búsqueda por términos, no por texto • Resultados ordenados por nivel de coincidencia • Commits lentos (modelo NoSQL)
fecha, numero, moneda • a_begin_date:[1990-01-01T00:00:00.000Z TO 1999-12- 31T24:59:99.999Z] • r_event_date:[* TO NOW-2YEAR] • t_duration:[300000 TO *] • somefield:[B TO C]
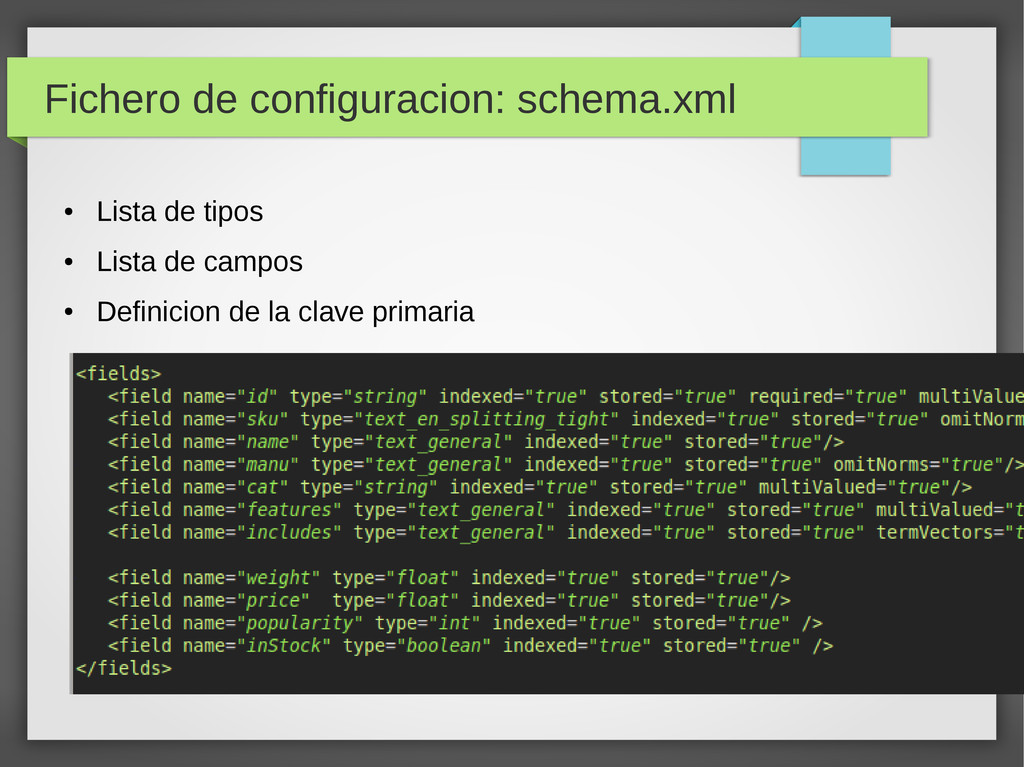
La estructura de datos (tipos, analizadores, etc) – solrconfig.xml Configuracion principal (componentes, controladores) • http://.../update • http://.../select • data: El indice de Lucene • lib: Librerias Java basicas y adicionales
(may/minusc) • Raizes • Sinonimos • Objetivo: Convertir frases en terminos • Esencial porque las personas no buscan de la misma forma en que los datos estan indexados
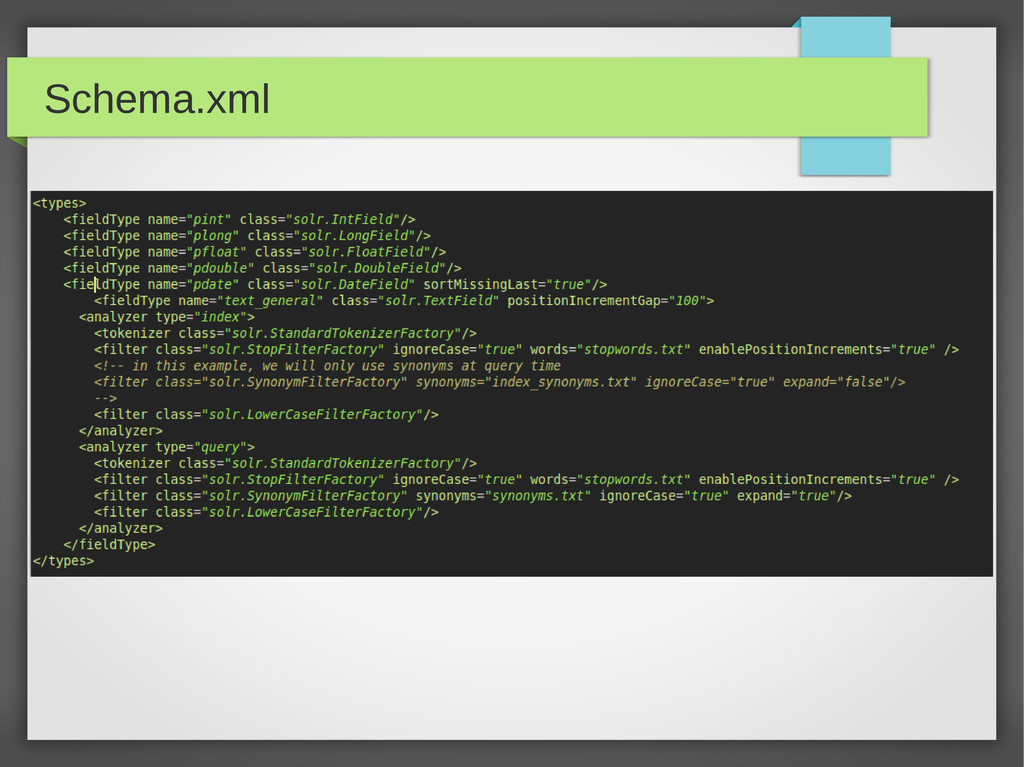
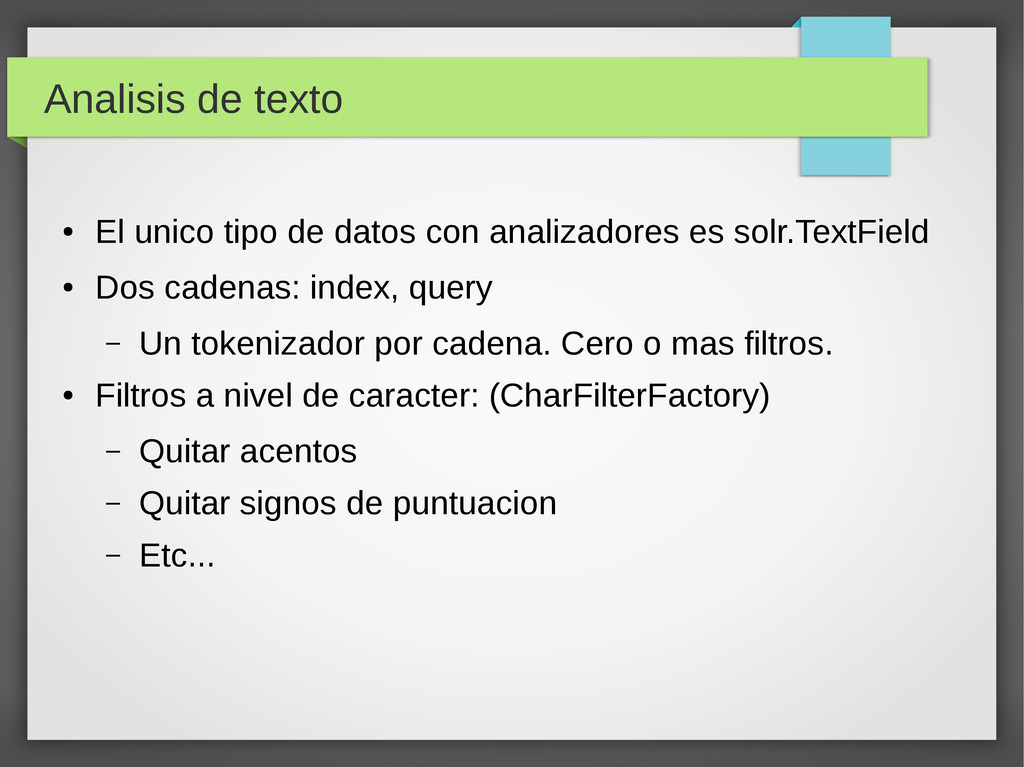
analizadores es solr.TextField • Dos cadenas: index, query – Un tokenizador por cadena. Cero o mas filtros. • Filtros a nivel de caracter: (CharFilterFactory) – Quitar acentos – Quitar signos de puntuacion – Etc...
IBM) • LowerCaseFilterFactory: Pone en minusculas todo el texto • KeepWordFilterFactory: Solo indexa/busca las palabras en el listado • LengthFilterFactory: Filtra palabras por longitud • RemoveDuplicatesTokenFilterFactory • ISOLatin1AccentFilterFactory
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
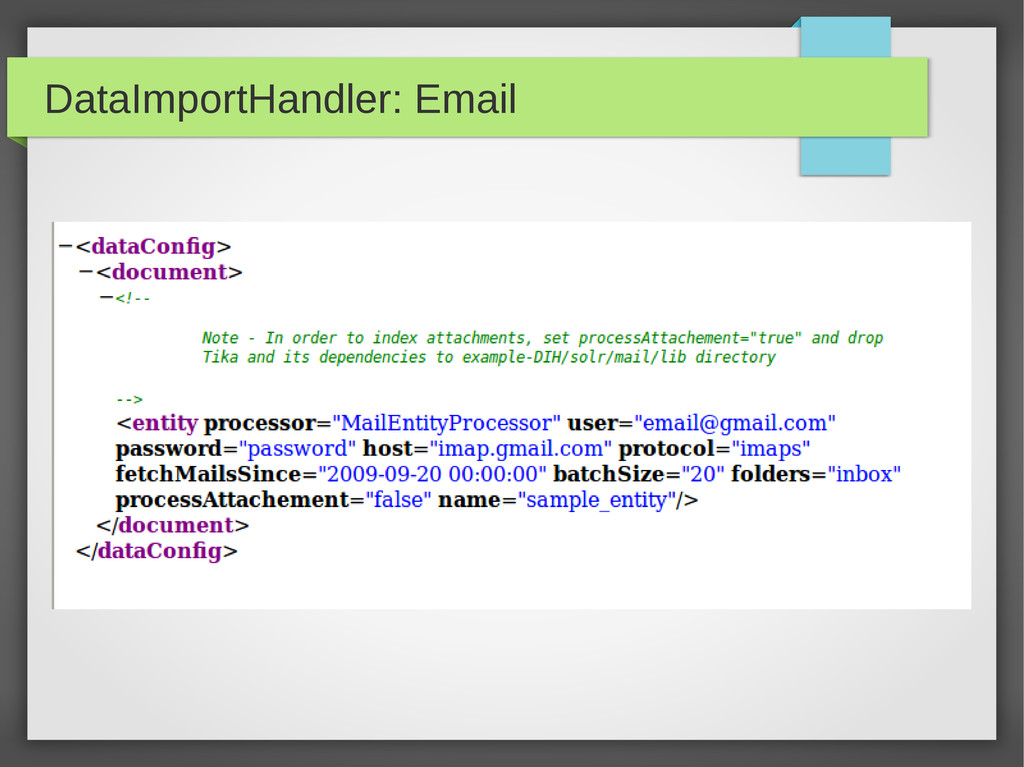{kind=link}
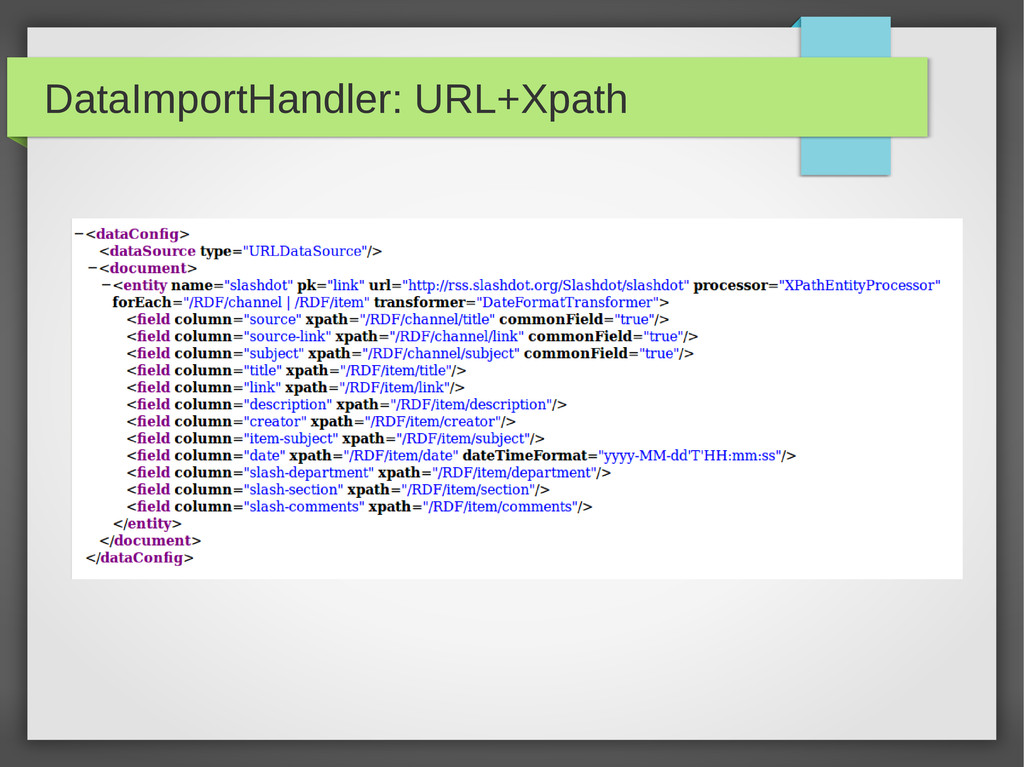{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}