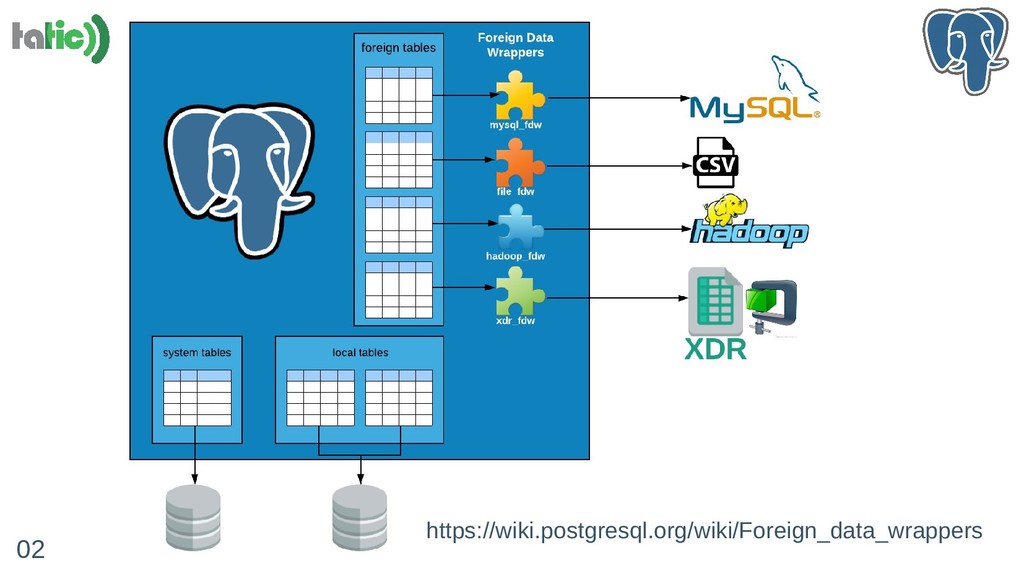
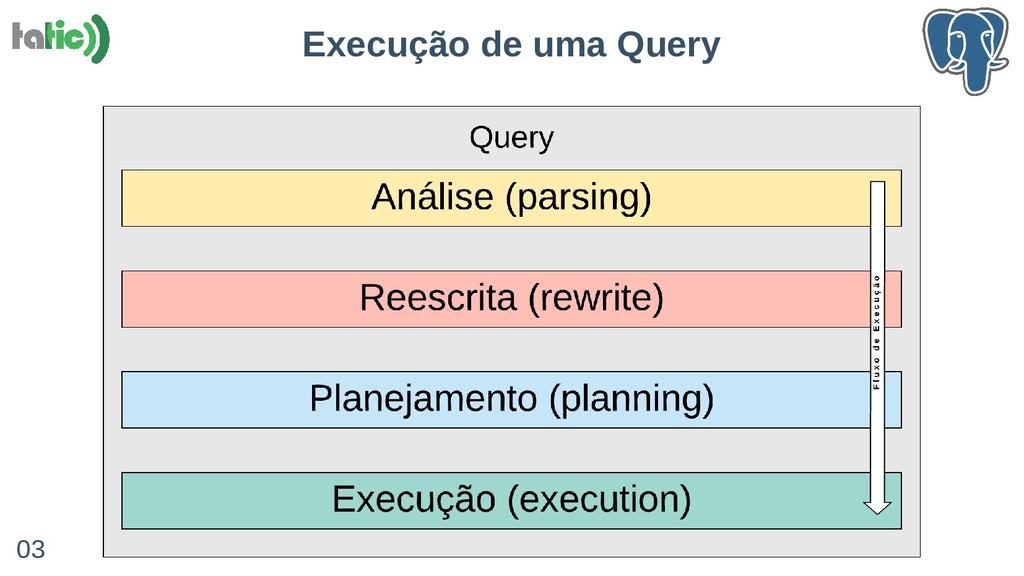
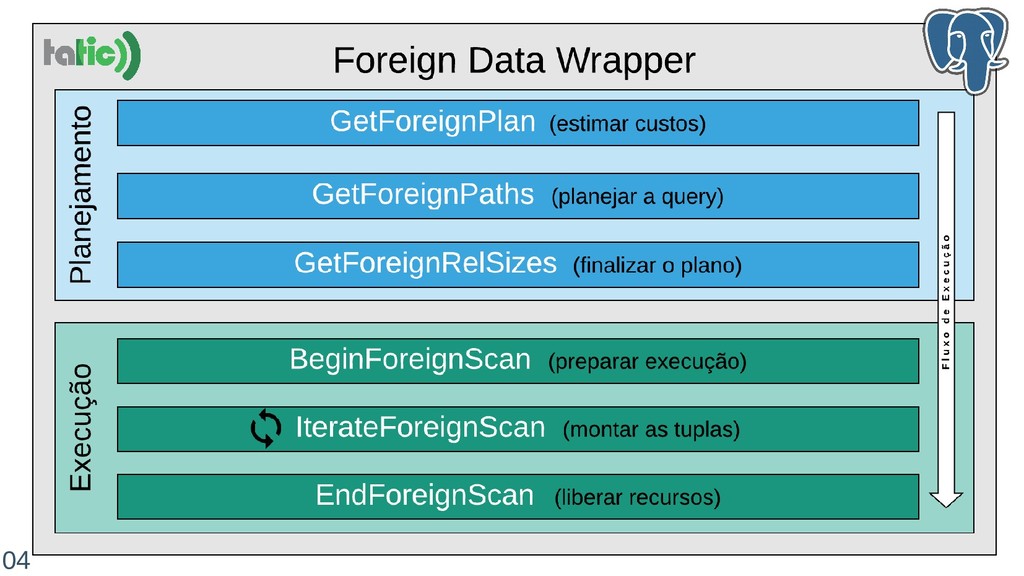
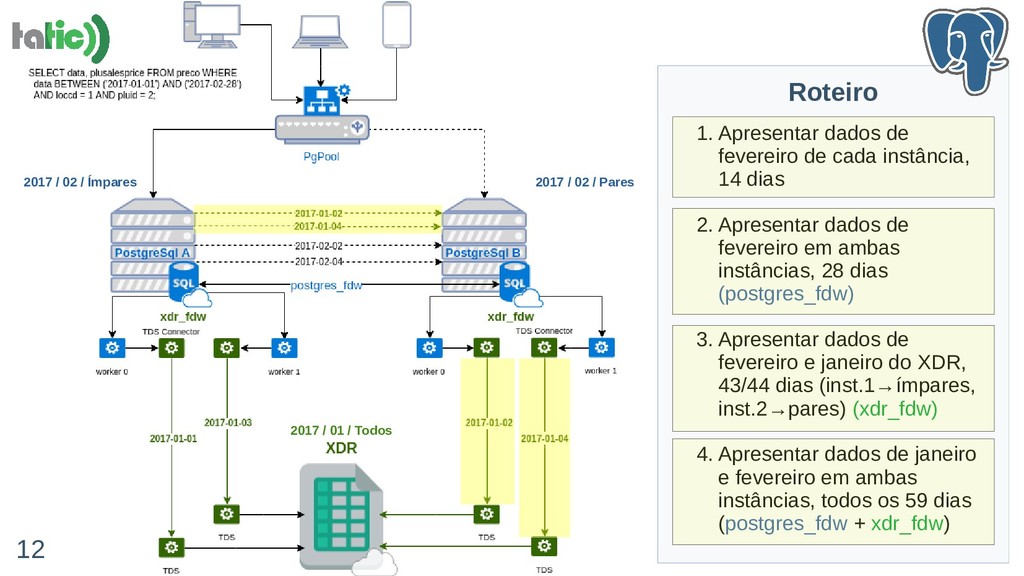
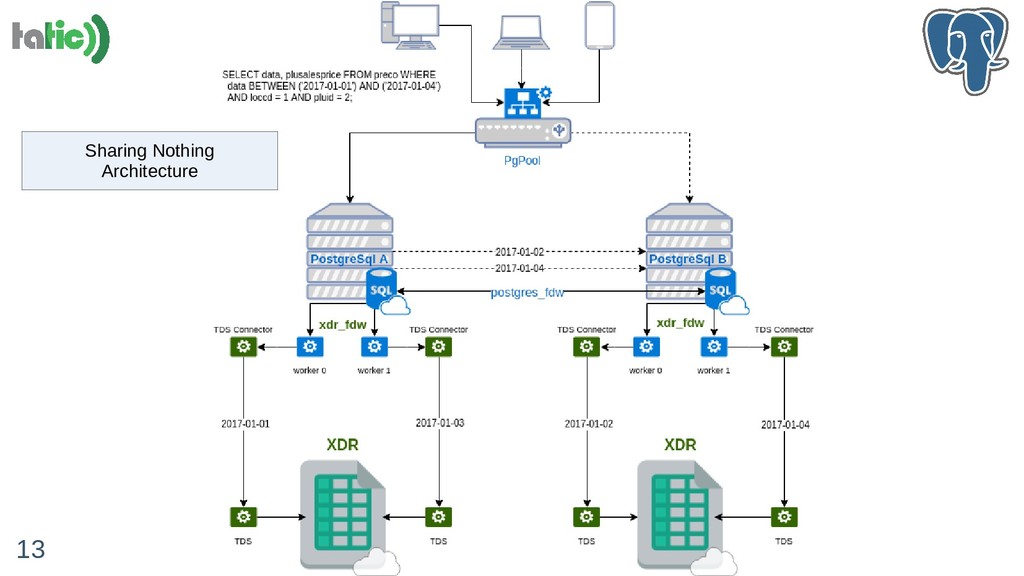
A compressão em bancos de dados pode trazer benefícios relevantes como redução do uso de STORAGE e melhoria de performance em certas situações em que o I/O é o gargalo. Nessa palestra, vamos compartilhar nossa experiência de integrar uma ferramenta de compressão de dados no PostgreSQL através da extensão FDW (Foreign Data Wraper) de forma eficiente. Na verdade, "de forma eficiente" será a nossa grande contribuição. Vamos detalhar aspectos como:
- Melhores práticas para pesquisar dados comprimidos em repositórios externos (possivelmente remotos)
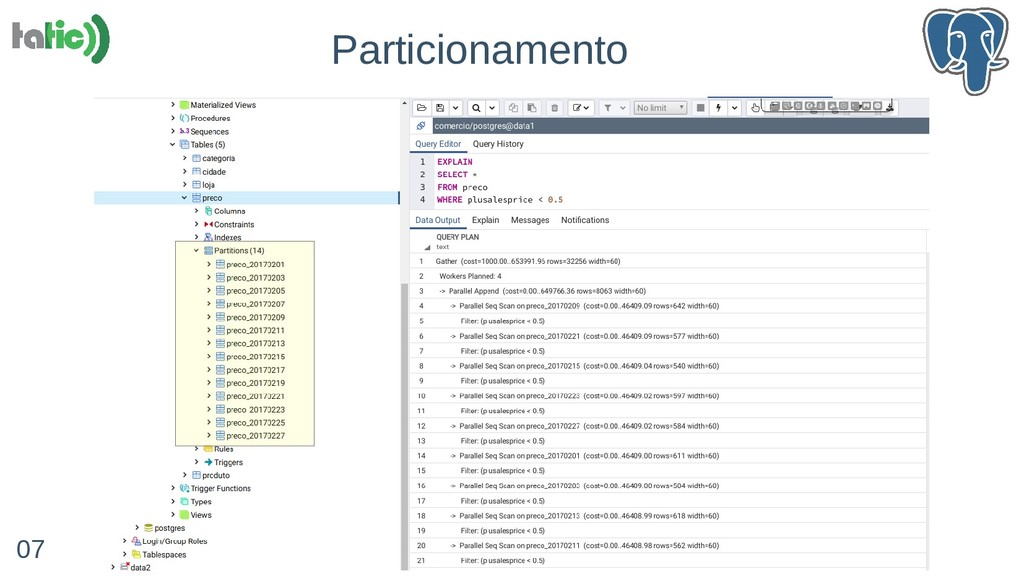
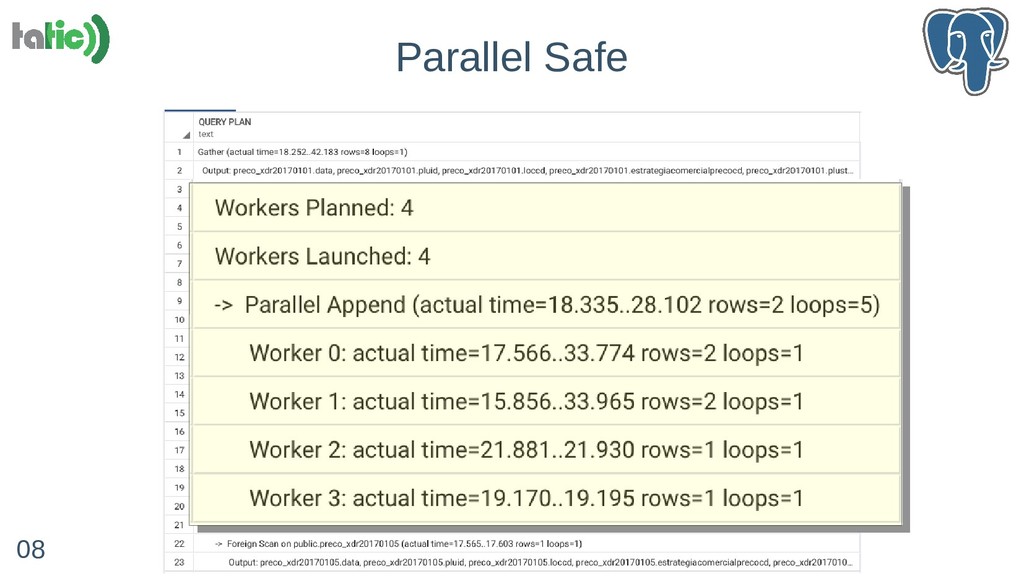
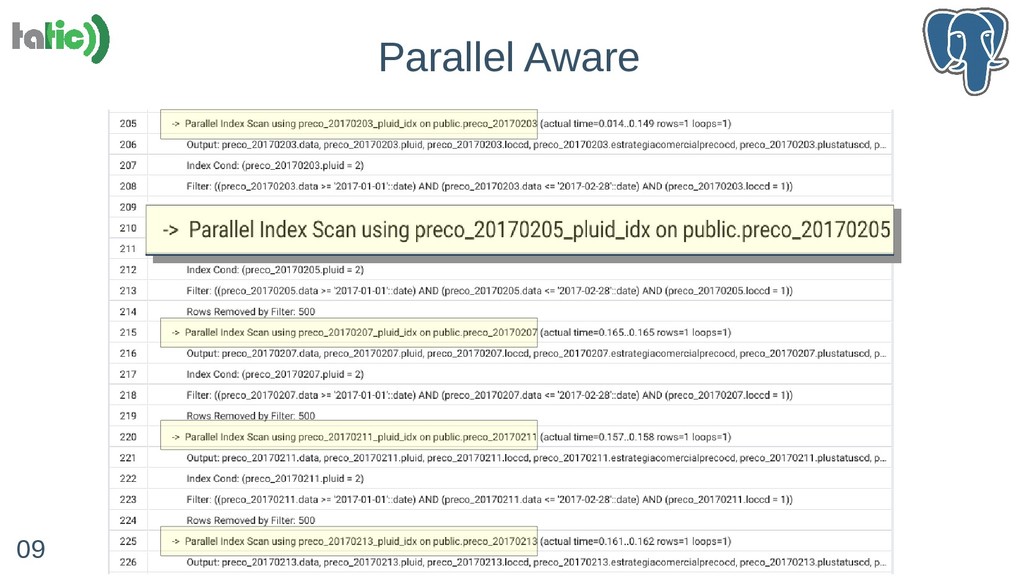
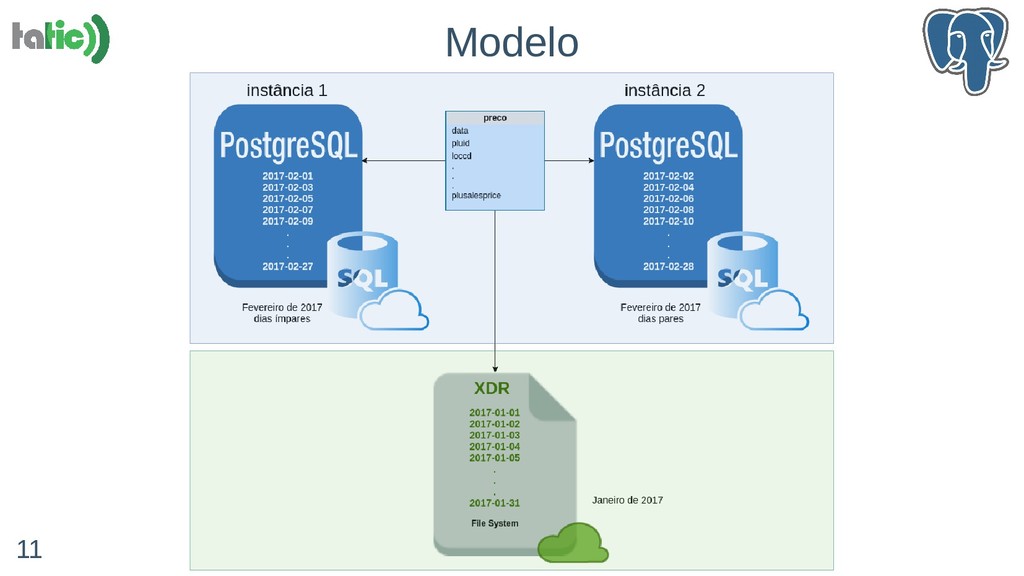
- Particionamento, sharding e paralelismo: 'Parallel Safe' e 'Parallel Aware'
- Como superar certos desafios no uso do FDW;
---
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}