Public talk presented at the ServerlessDays meetup in Amsterdam.
While observability empowers developers to be in full control over their owned services, resiliency relies on observability to automate failure handling.
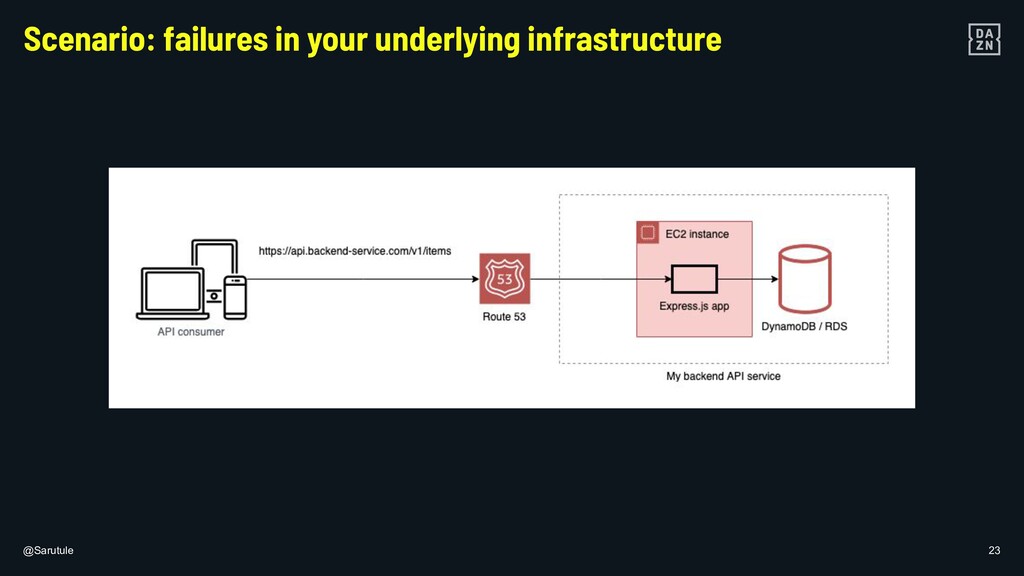
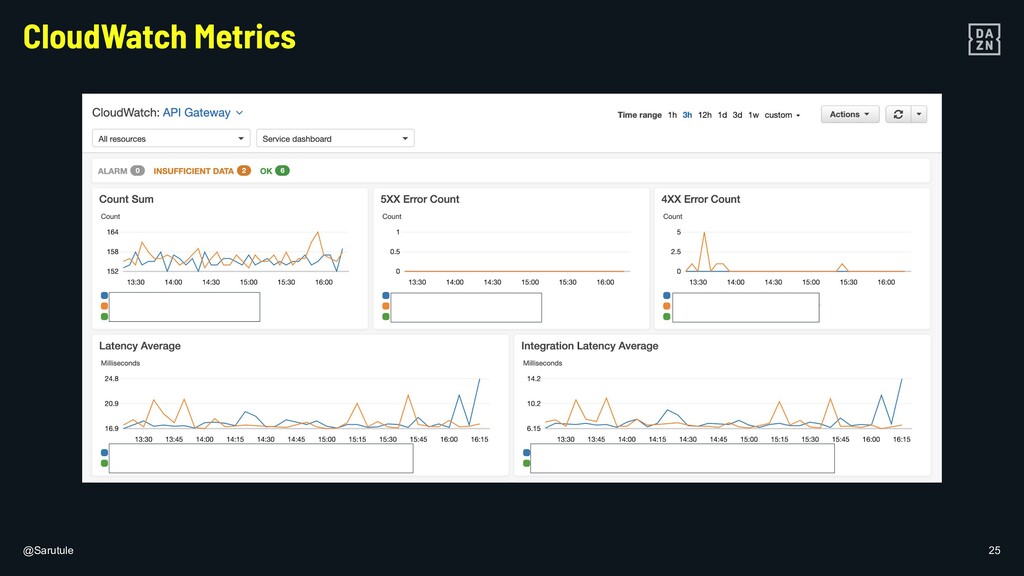
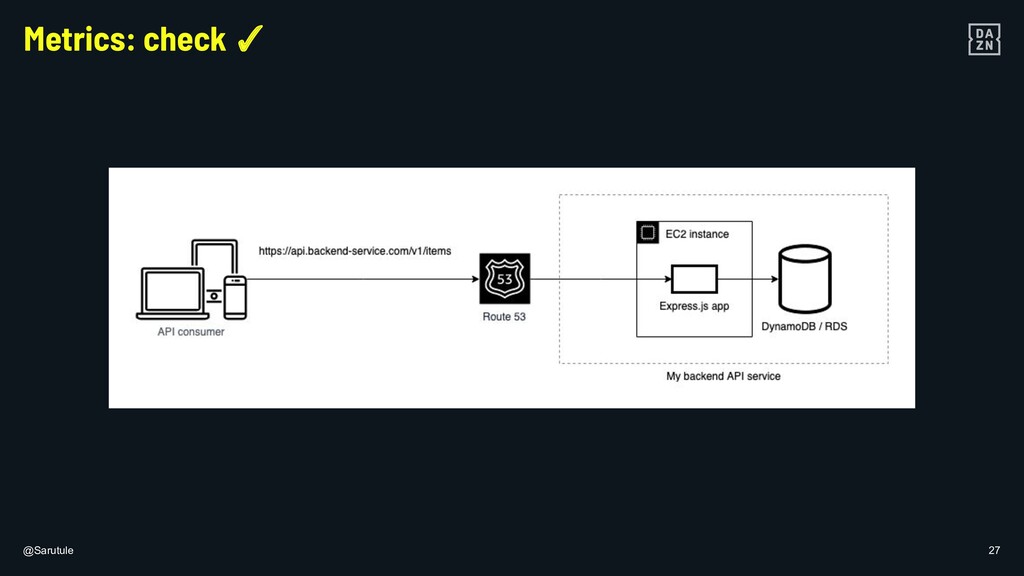
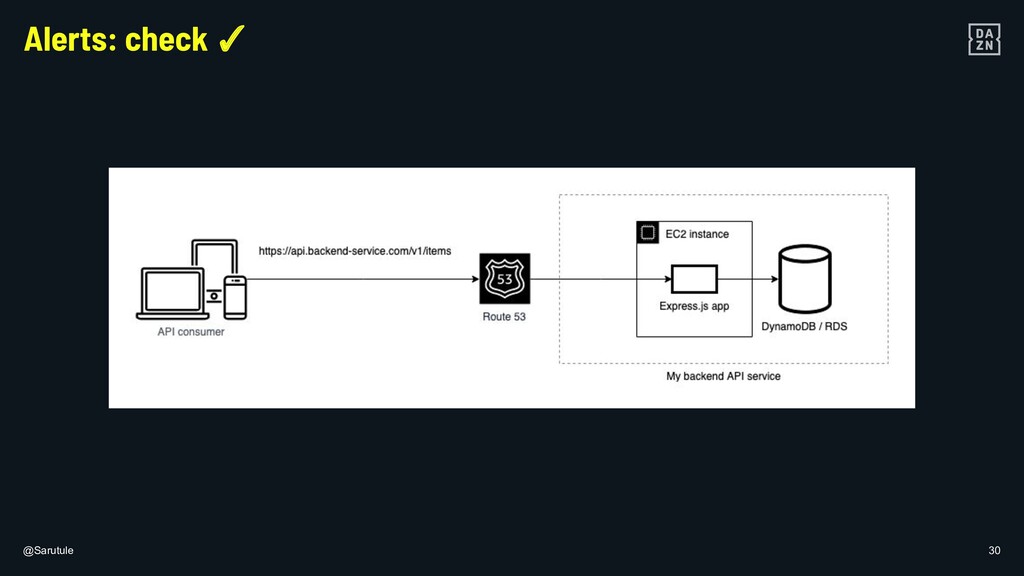
In DAZN, using metrics to monitor the known and, even more importantly the unknown is fundamental to build resilient applications. I will show some examples of the steps that can be taken to ensure that your own micro-services are healthy and resilient on different layers of your (serverless) architecture.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
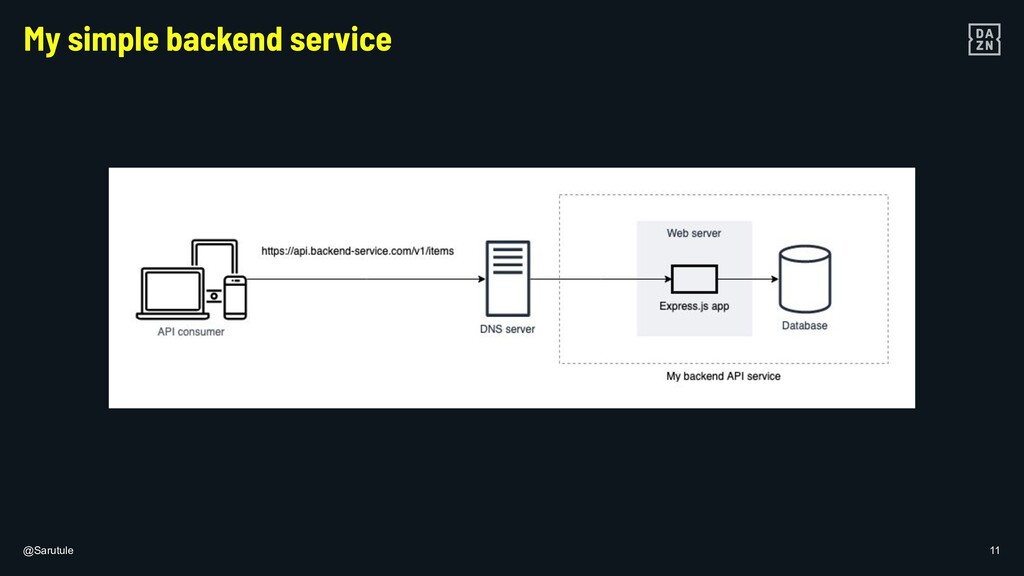{kind=link}
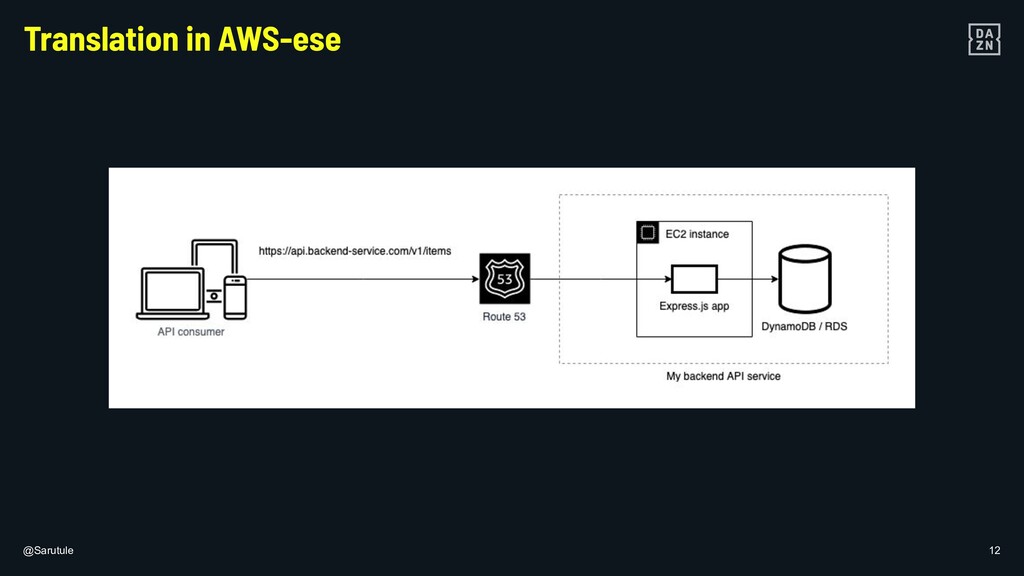{kind=link}
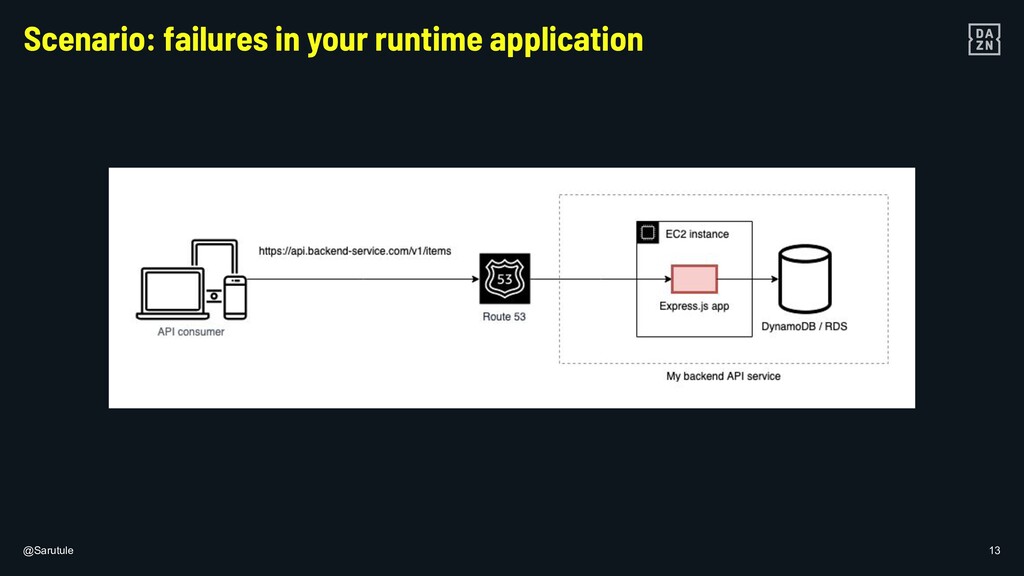{kind=link}
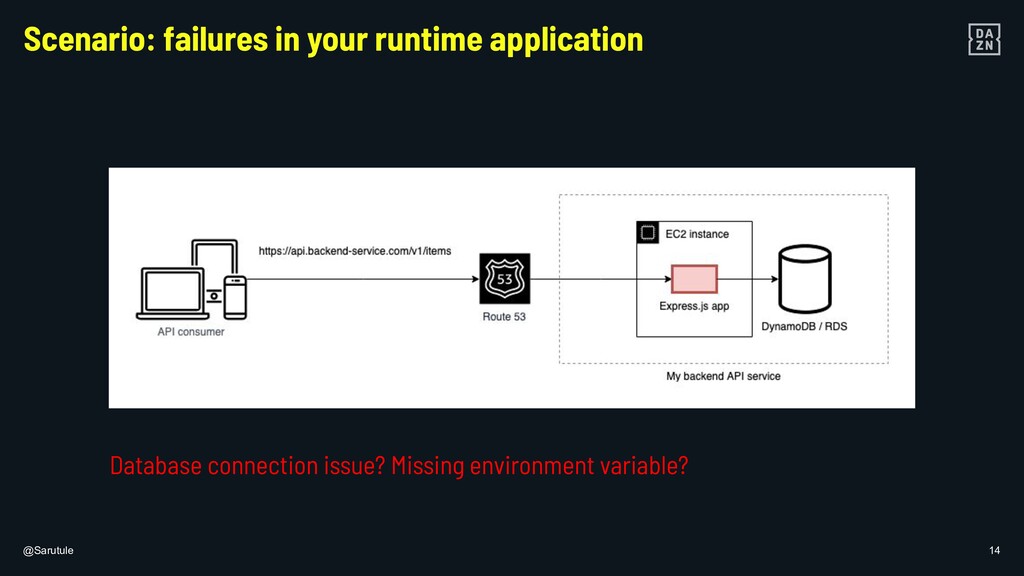{kind=link}
{kind=link}
{kind=link}
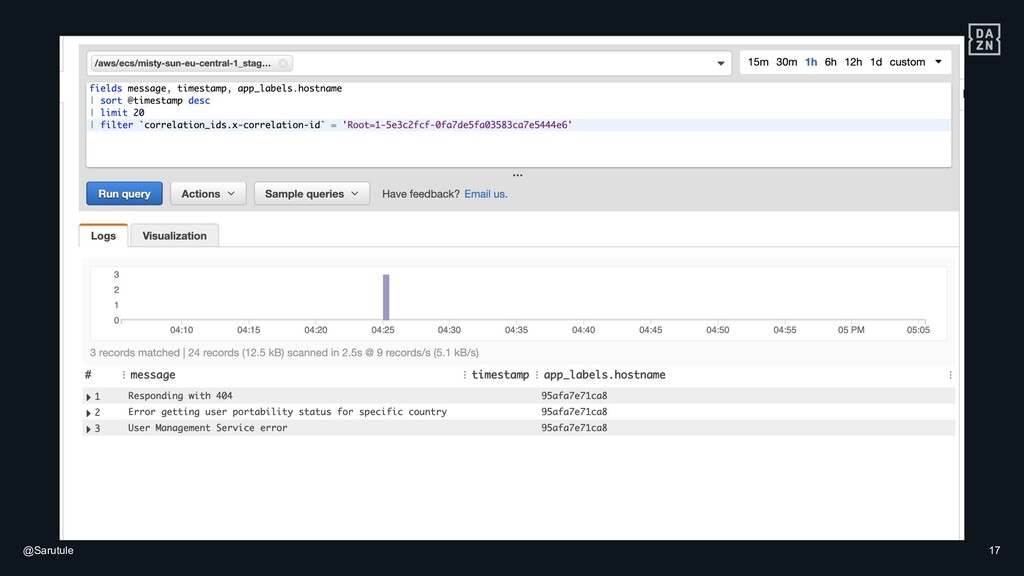{kind=link}
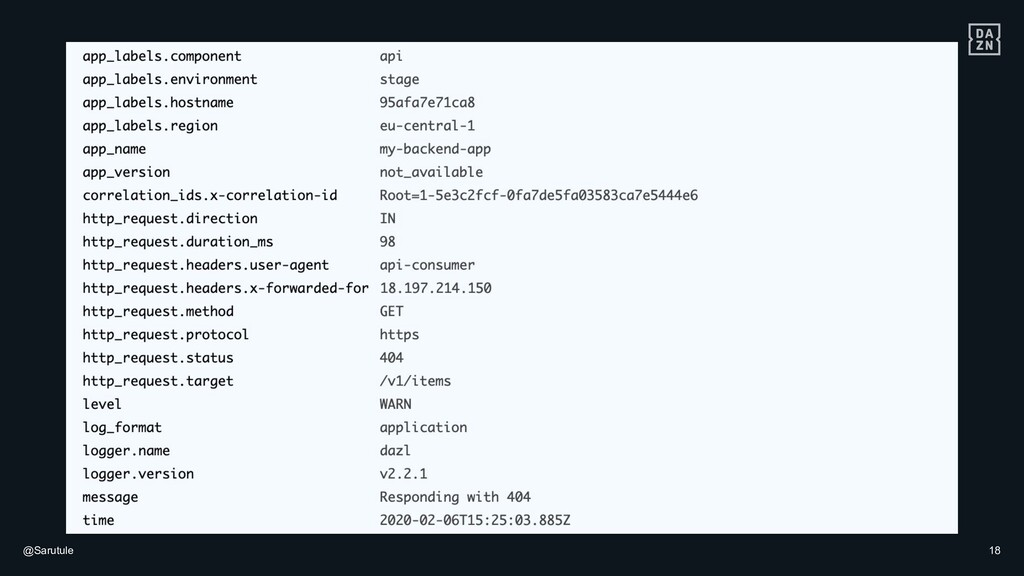{kind=link}
{kind=link}
{kind=link}
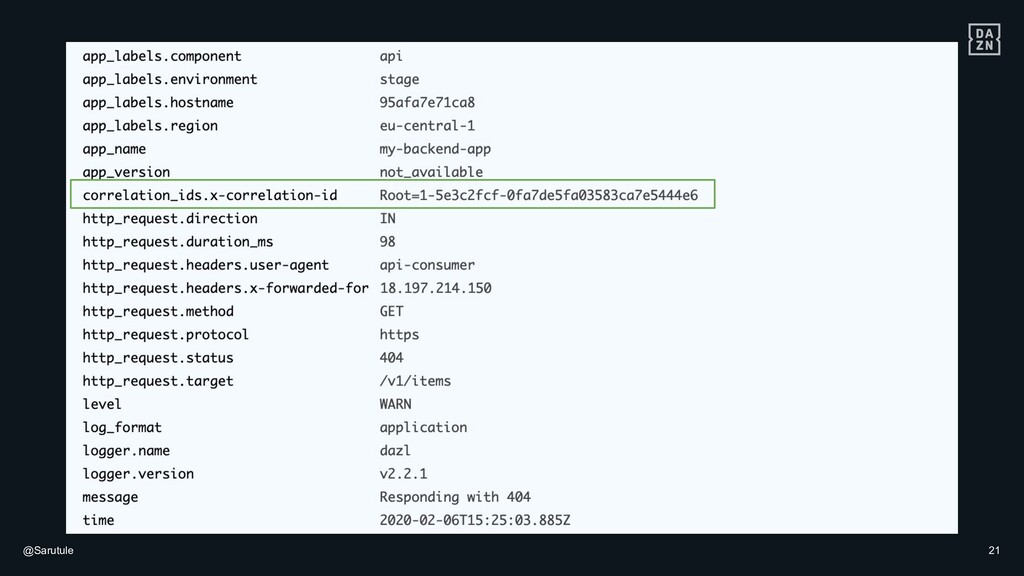{kind=link}
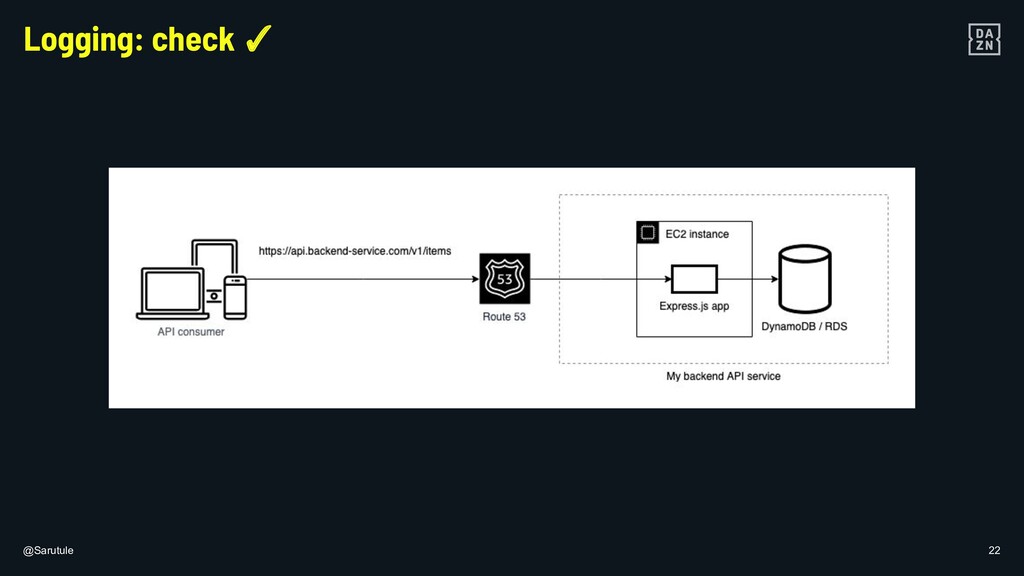{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}