same key • Reducer pseudocode reducer (word, values): sum = 0 for each value in values: sum = sum + value emit (word, sum) • Output of mapper stage (hello, 1) (this, 1) (is, 1) (the, 1) (first, 1) (file, 1) (this, 1) (is, 1) (the, 1) (second, 1) (file, 1) • Input to reducer stage (hello, [1]) (this, [1, 1]) (is, [1, 1]) (the, [1,1]) (first, [1]) (file, [1, 1]) (second, [1]) • Output of reducer stage (hello, 1) (this, 2) (is, 2) (the, 2) (first, 1) (file, 2) (second, 1)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
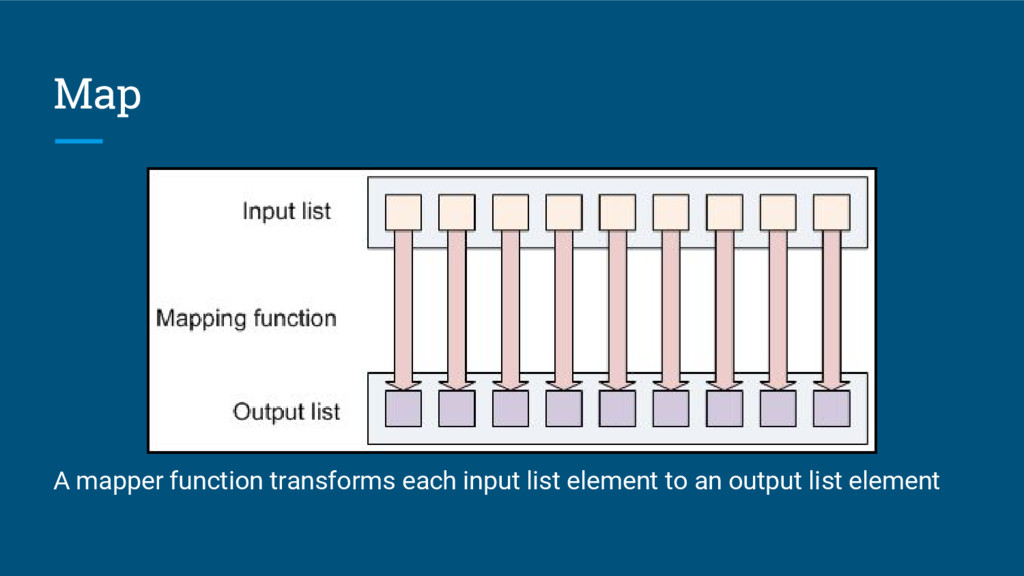{kind=link}
![Examples of Map • Square [3, 6, 5, 9, 10]](https://files.speakerdeck.com/presentations/fcd47c2fa02648b686006aa5afb0a19b/slide_9.jpg){kind=link}
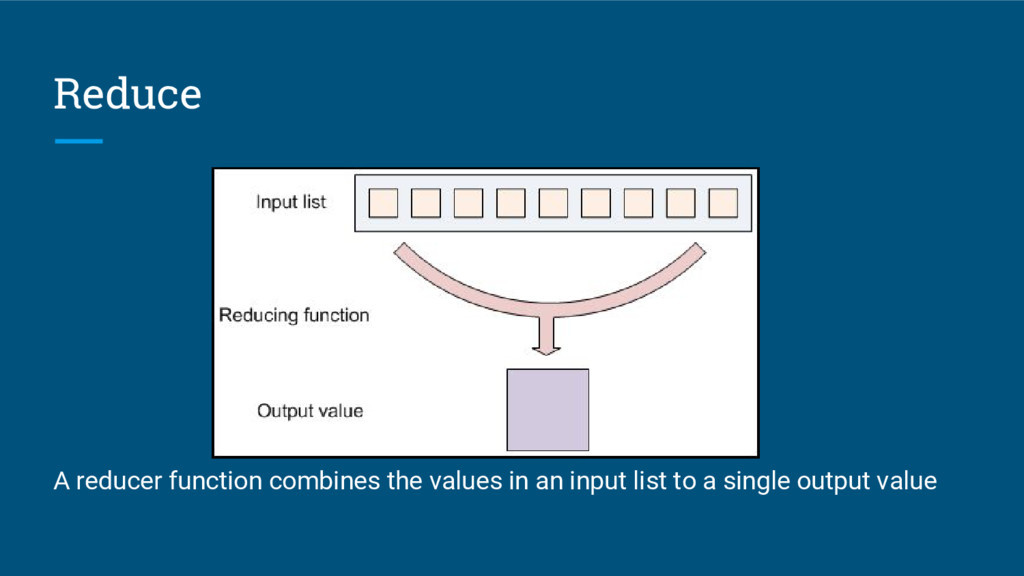{kind=link}
![Examples of Reduce • Summation [3, 6, 5, 9, 10]](https://files.speakerdeck.com/presentations/fcd47c2fa02648b686006aa5afb0a19b/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
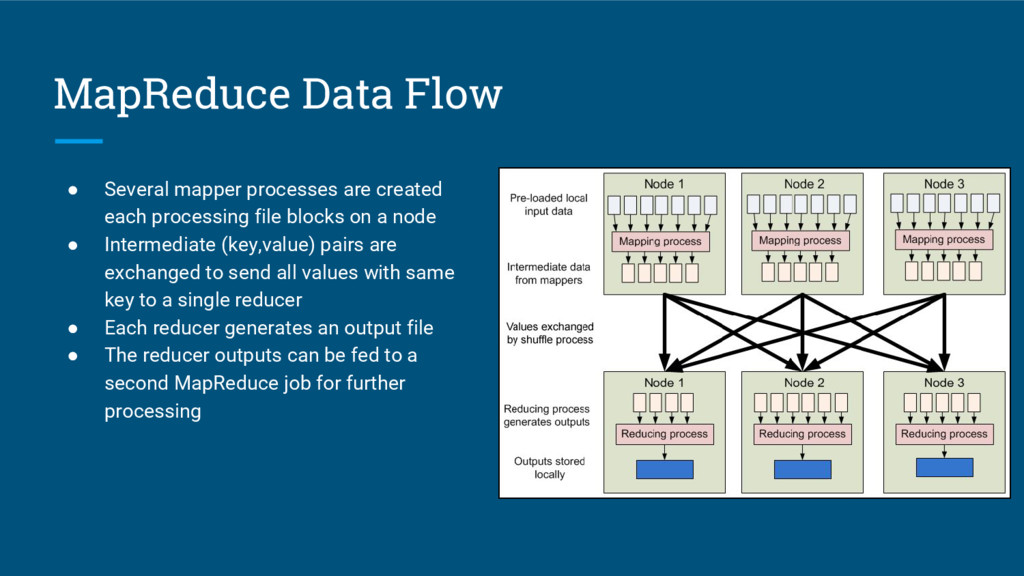{kind=link}
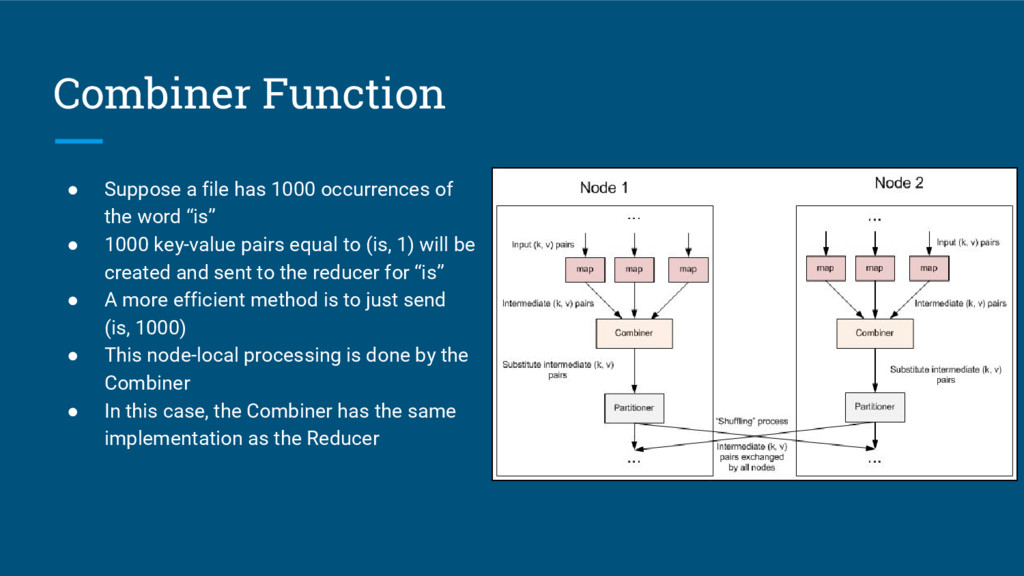{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
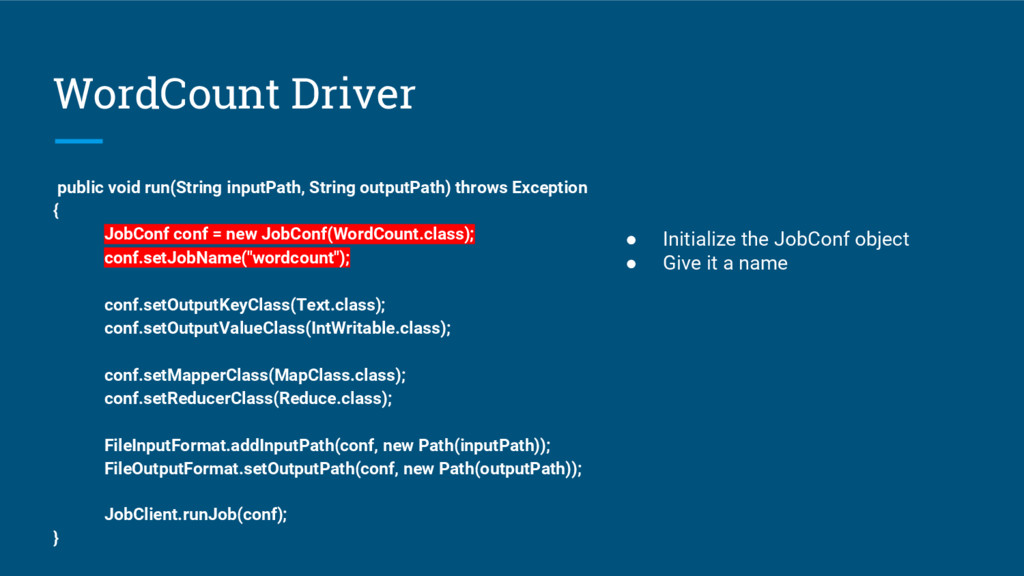{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
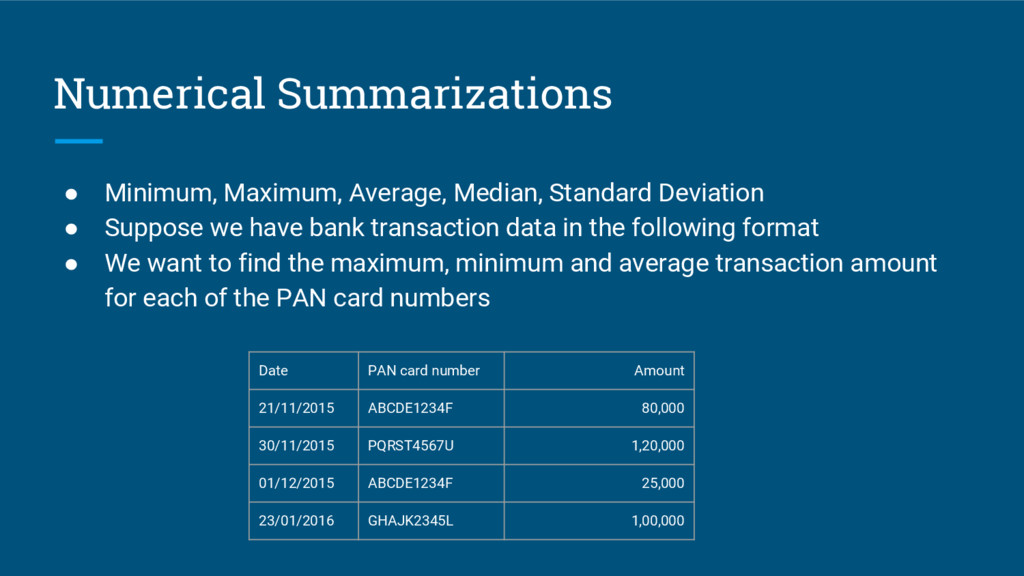{kind=link}
{kind=link}
{kind=link}
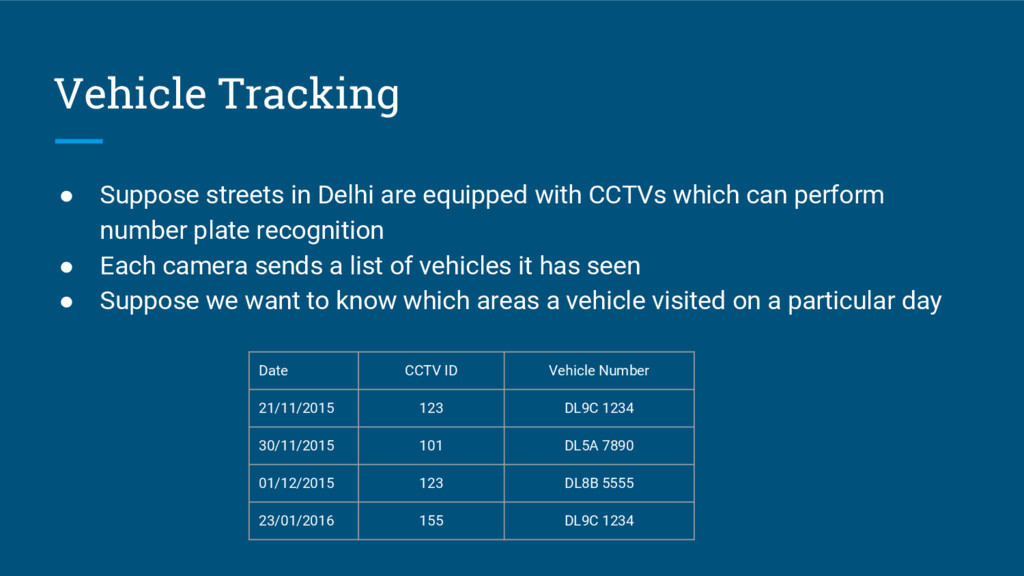{kind=link}
{kind=link}
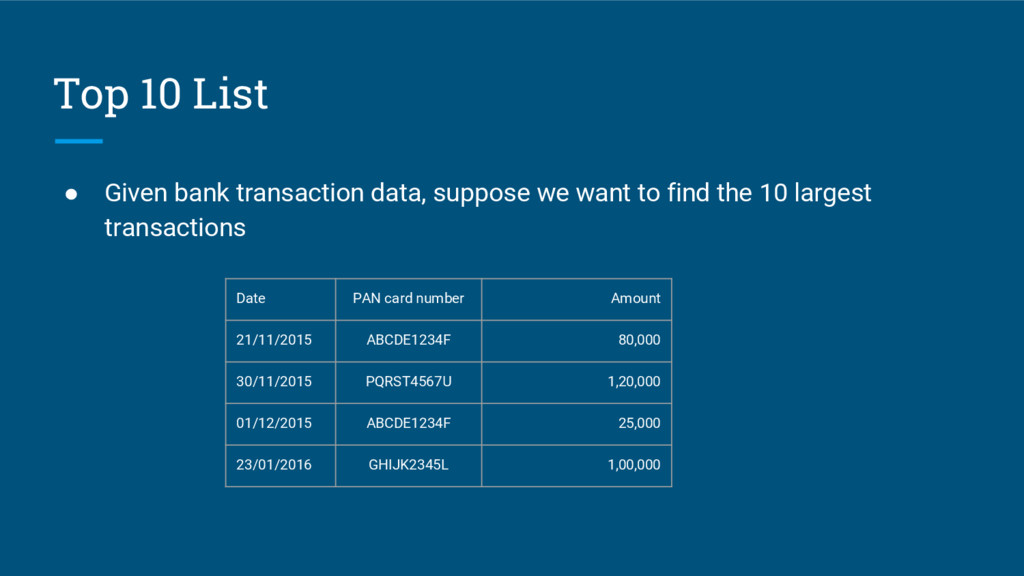{kind=link}
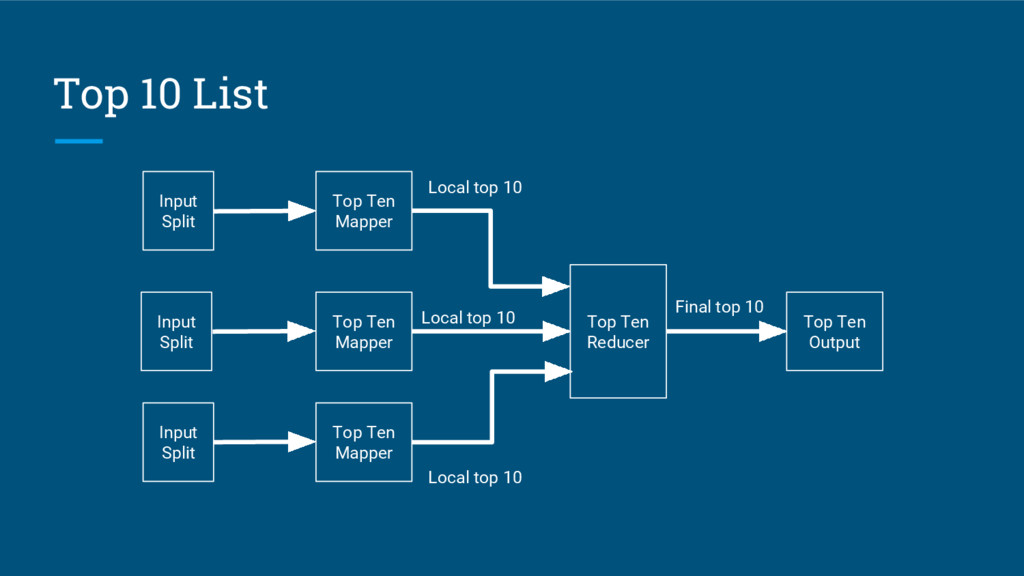{kind=link}
{kind=link}
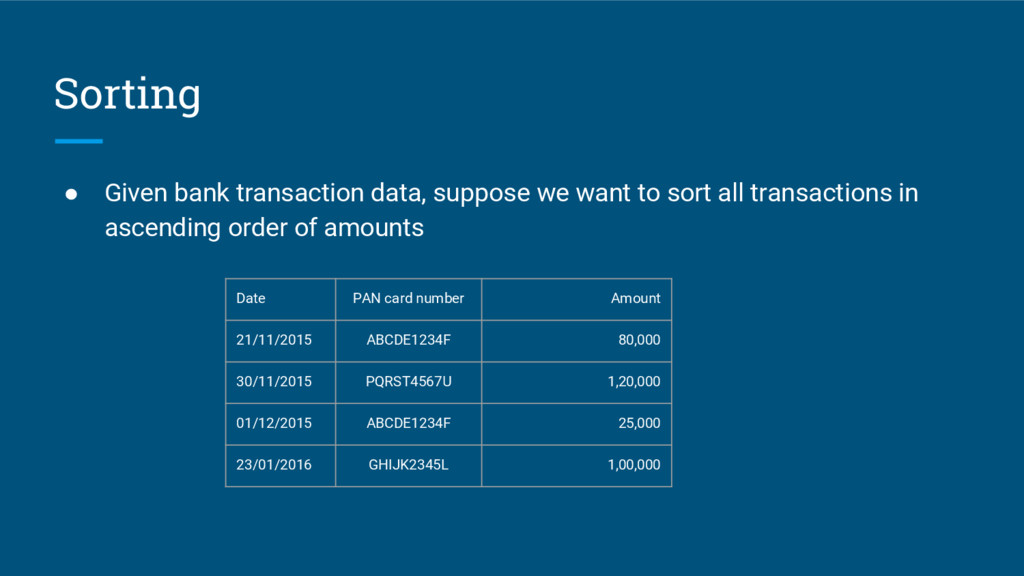{kind=link}
{kind=link}
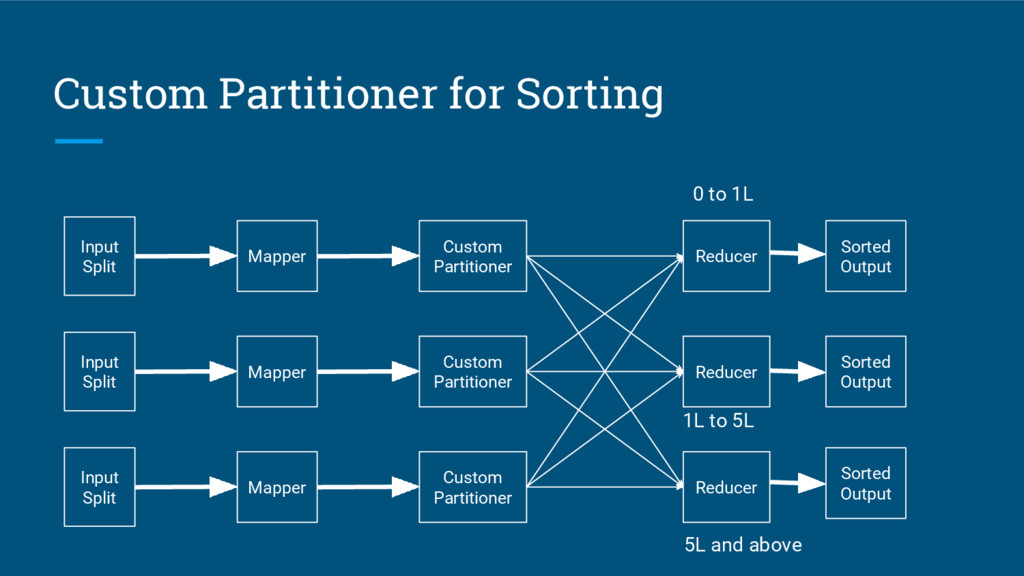{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}