Mit Realtime-Sprachmodellen wie GPT-realtime oder Gemini-Live entsteht eine neue Generation von Interfaces: Sprache wird zum sofort reagierenden, latenzarmen Interaktionskanal – ohne Prompting, ohne Wartezeiten, hands-free.
In diesem Talk zeigt Sascha Lehmann, wie Realtime-Modelle technisch funktionieren, wie man Kontextgrenzen, Rollen und Sicherheit zuverlässig kontrolliert und wie sich Realtime-AI gezielt in Web- und Mobile-Anwendungen integrieren lässt – von Architektur über Kostenoptimierung bis hin zur UX, die Nutzer transparent durch den Dialog führt.
{kind=link}
![Consultant @ Thinktecture AG Sascha Lehmann @derLehmann_S https://www.linkedin.com/in/sascha-lehmann [email protected] https://www.thinktecture.com/thinktects/sascha-lehmann/](https://files.speakerdeck.com/presentations/0da438b9dcb249089931354400f7a56d/slide_1.jpg){kind=link}
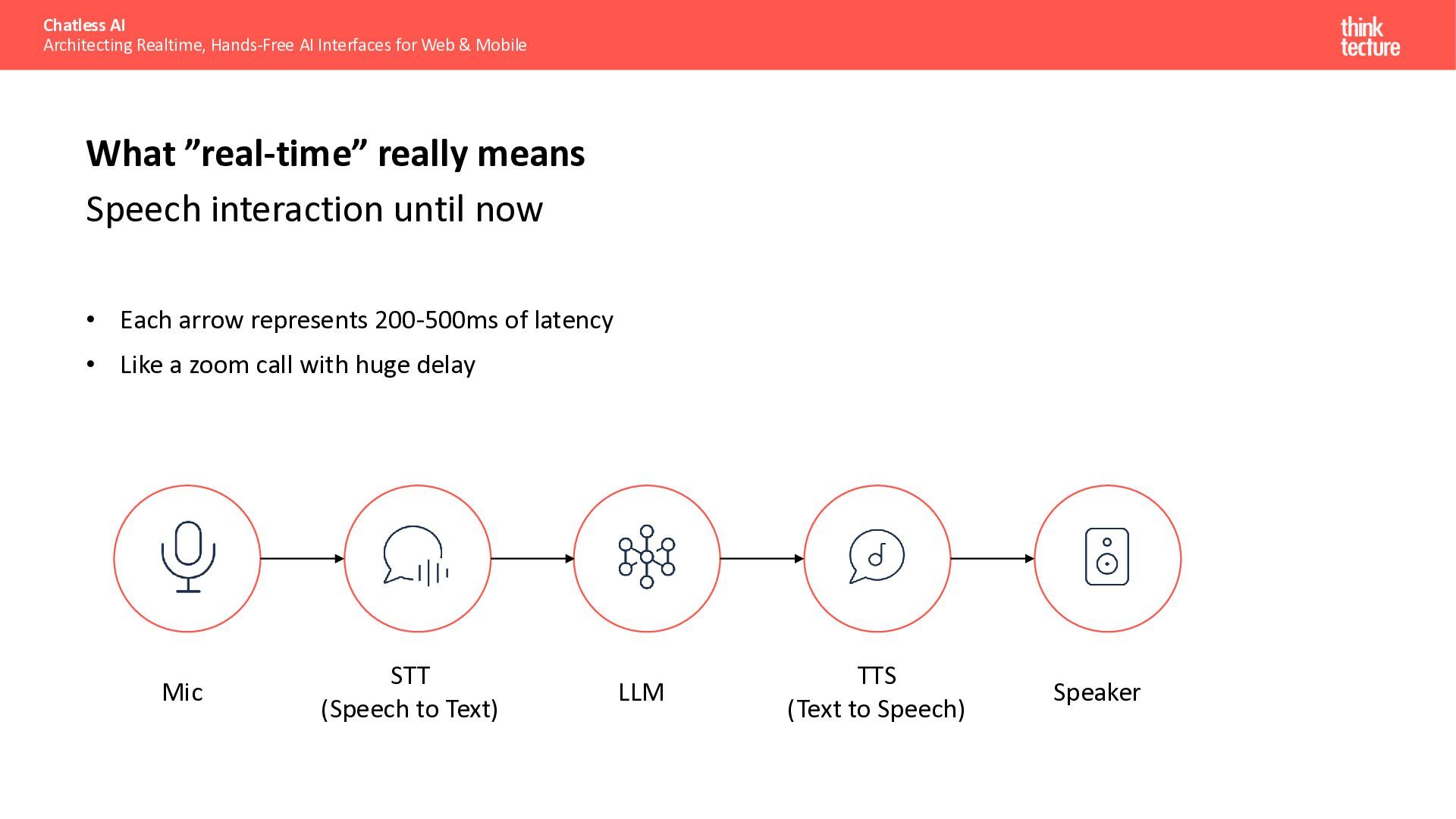
{kind=link}
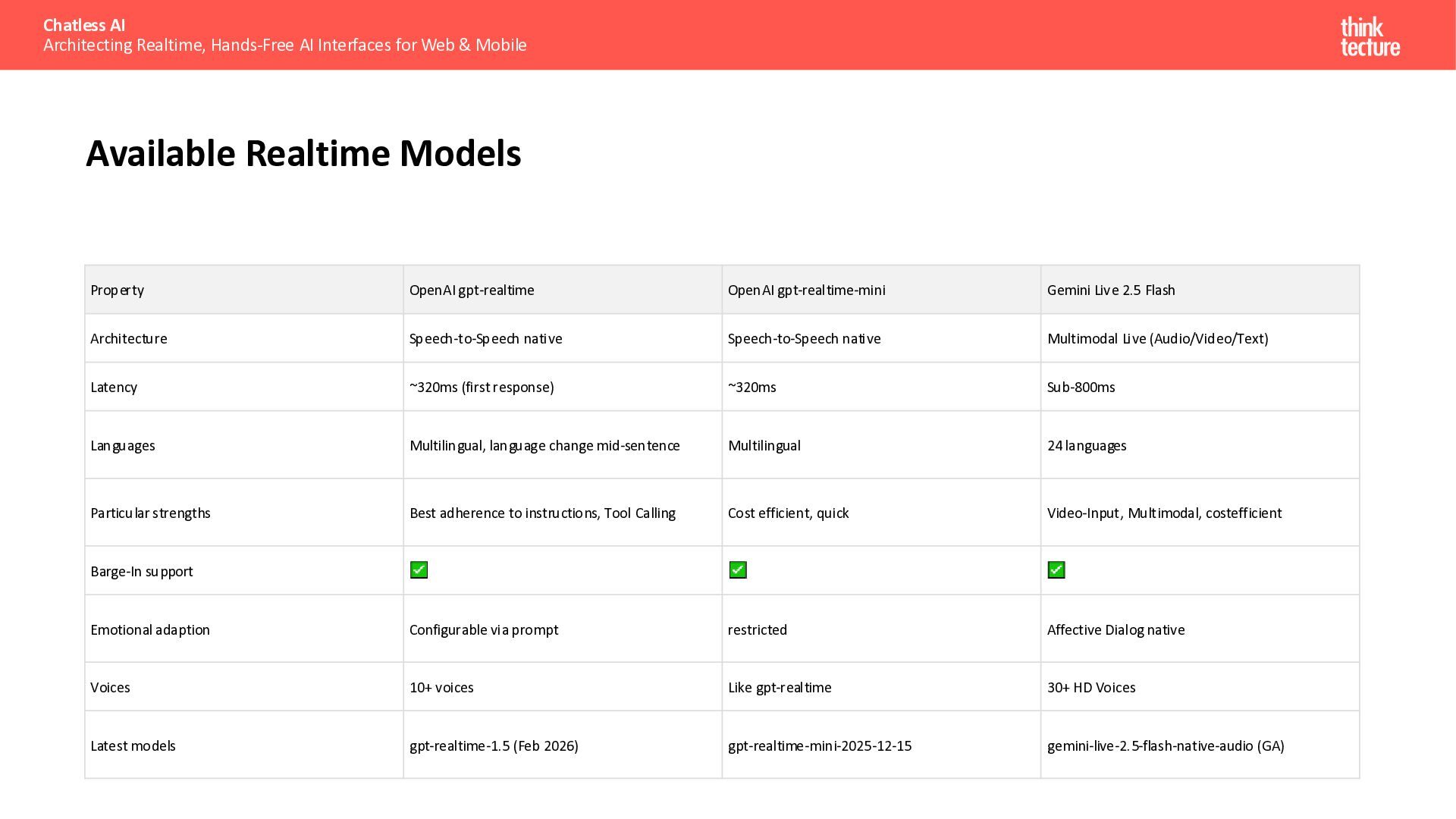
{kind=link}
{kind=link}
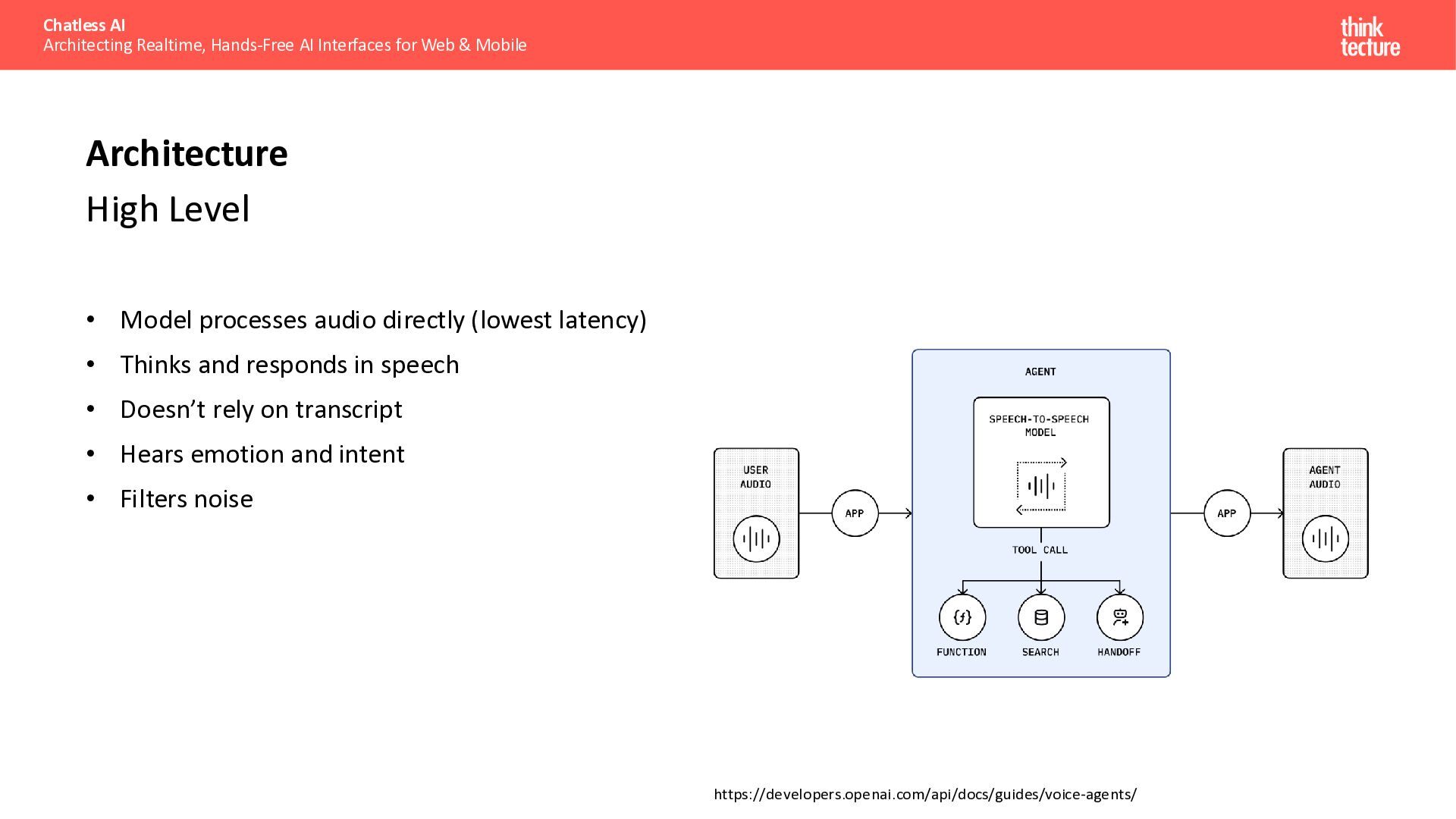
{kind=link}
{kind=link}
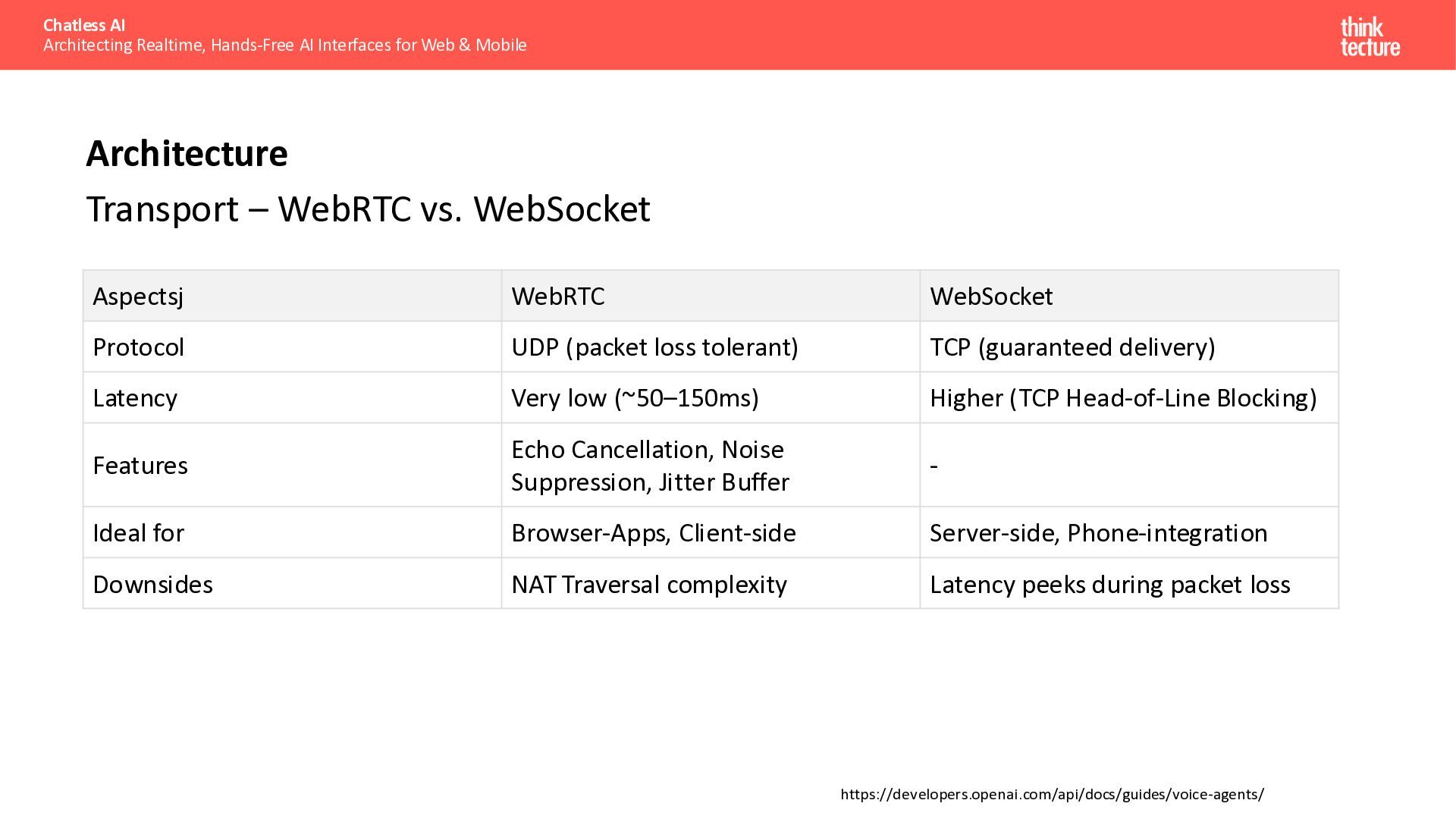{kind=link}
{kind=link}
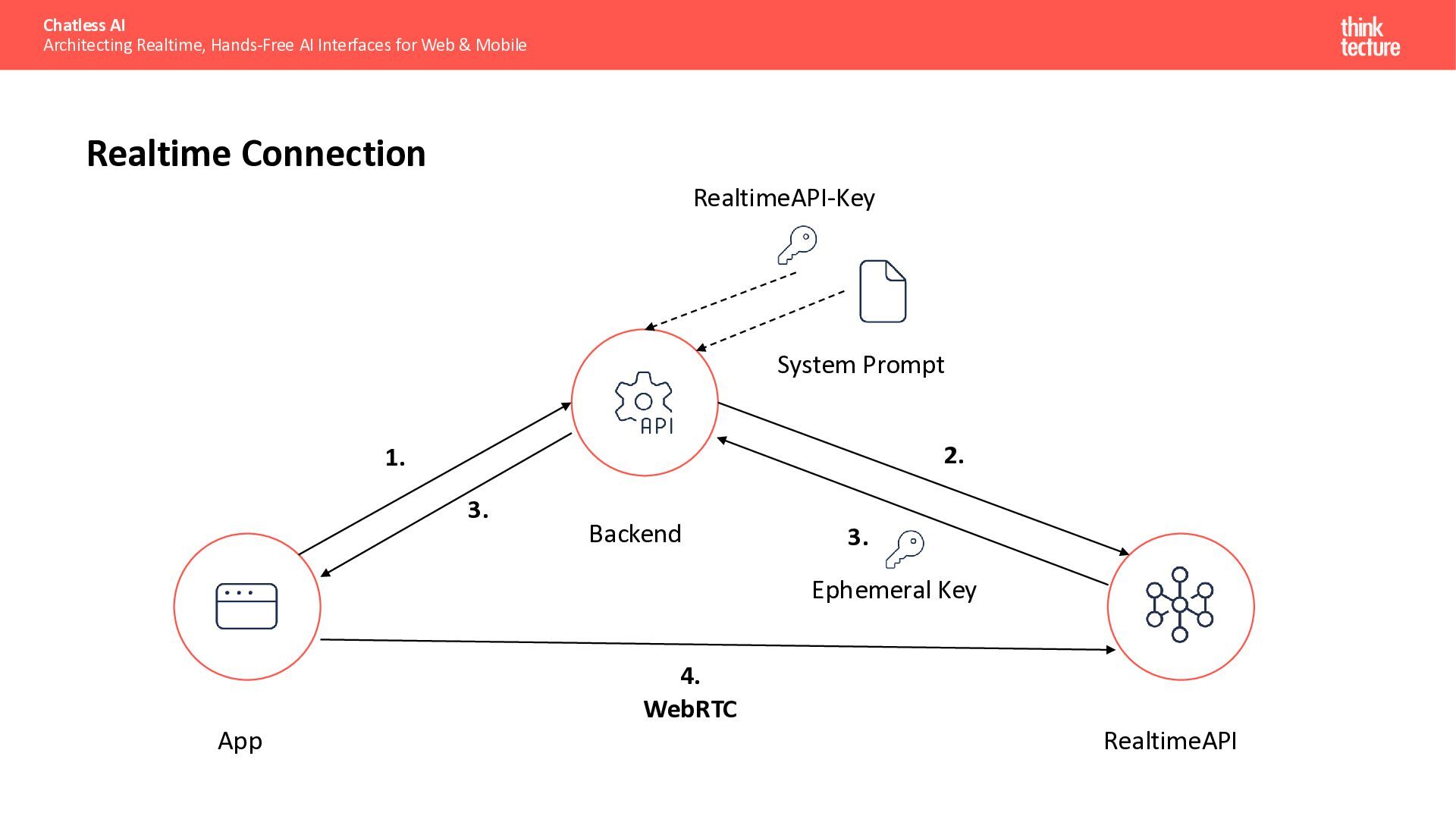{kind=link}
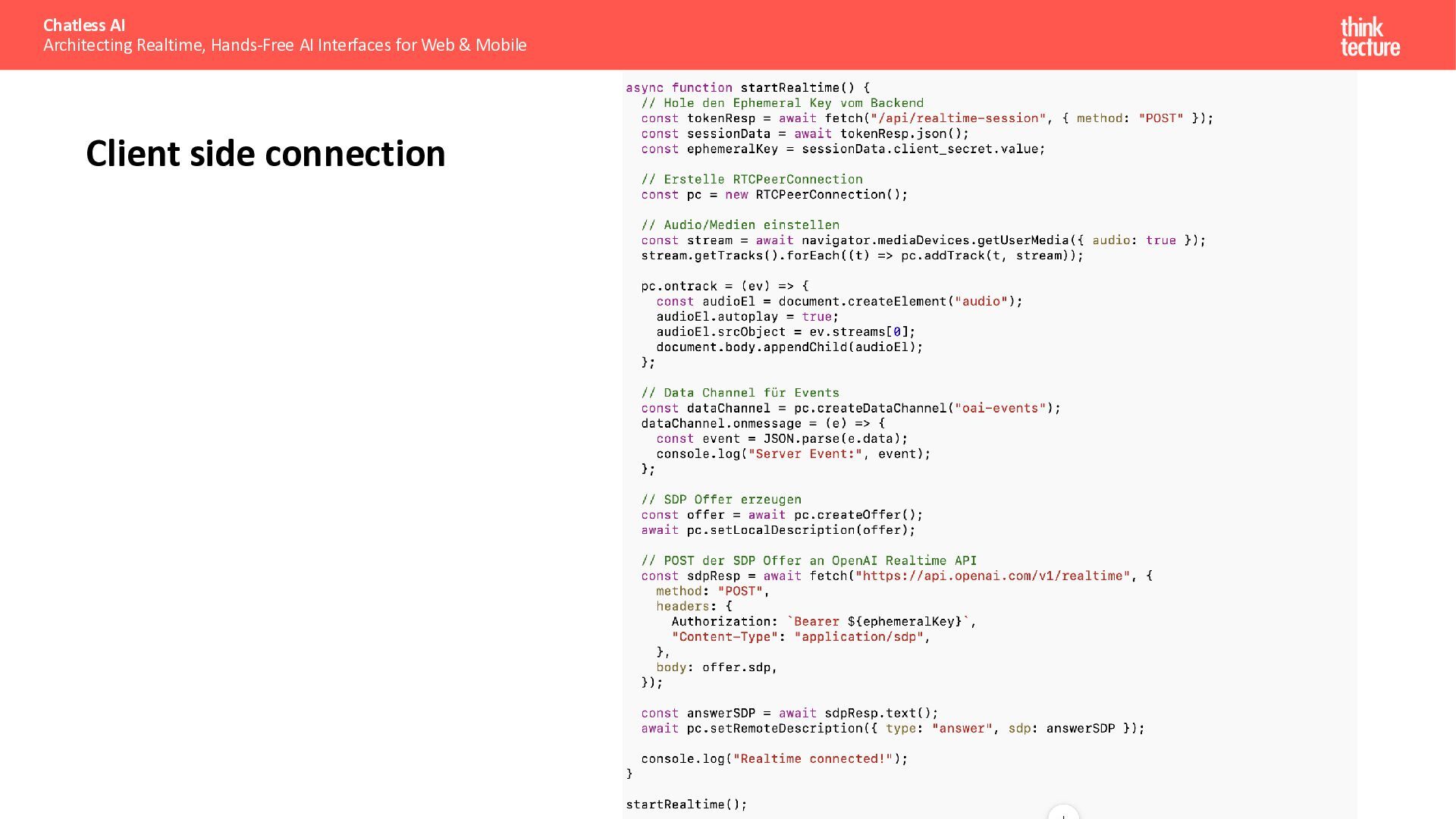{kind=link}
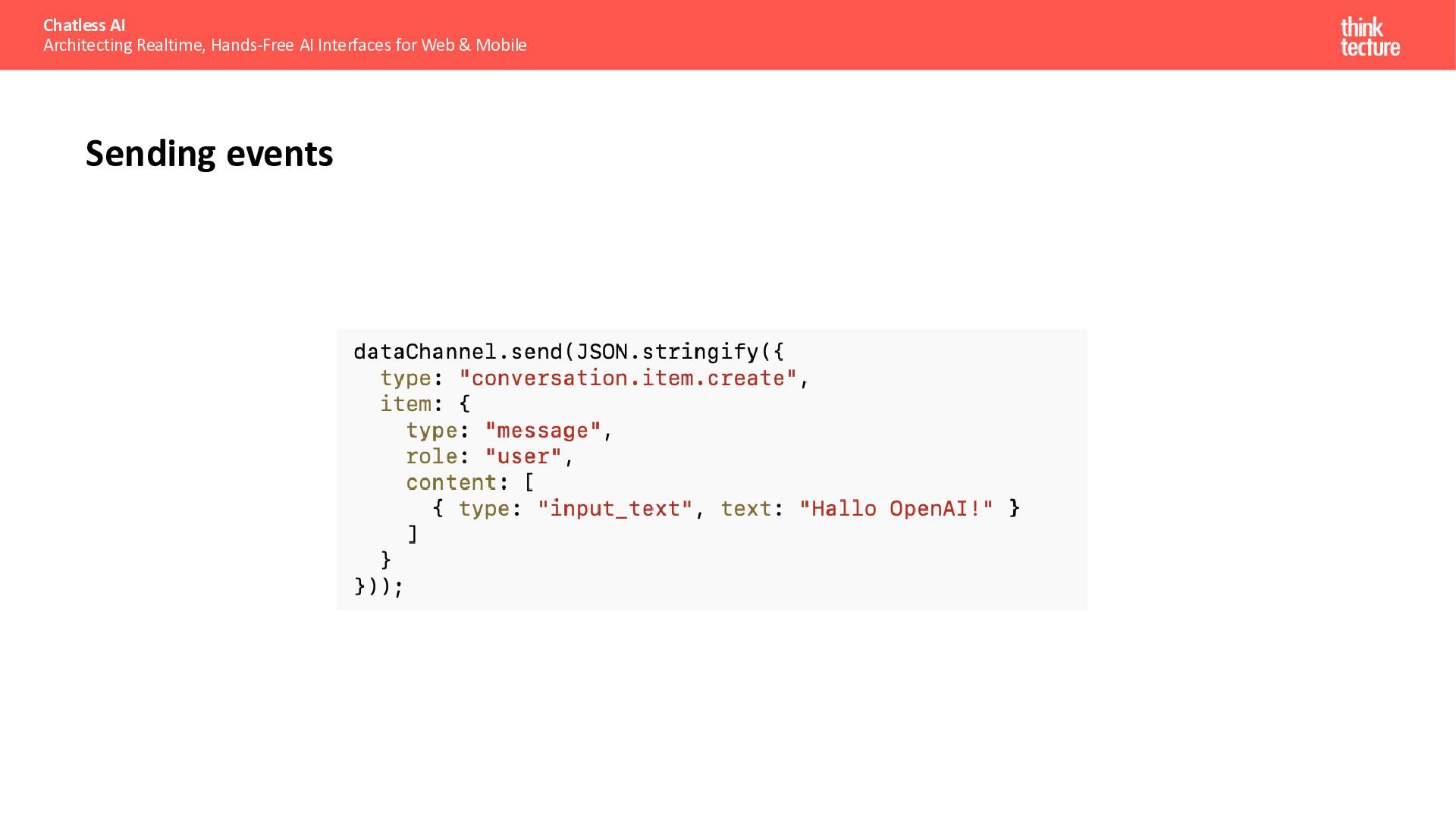{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Sascha Lehmann [email protected] Thank you!](https://files.speakerdeck.com/presentations/0da438b9dcb249089931354400f7a56d/slide_28.jpg){kind=link}