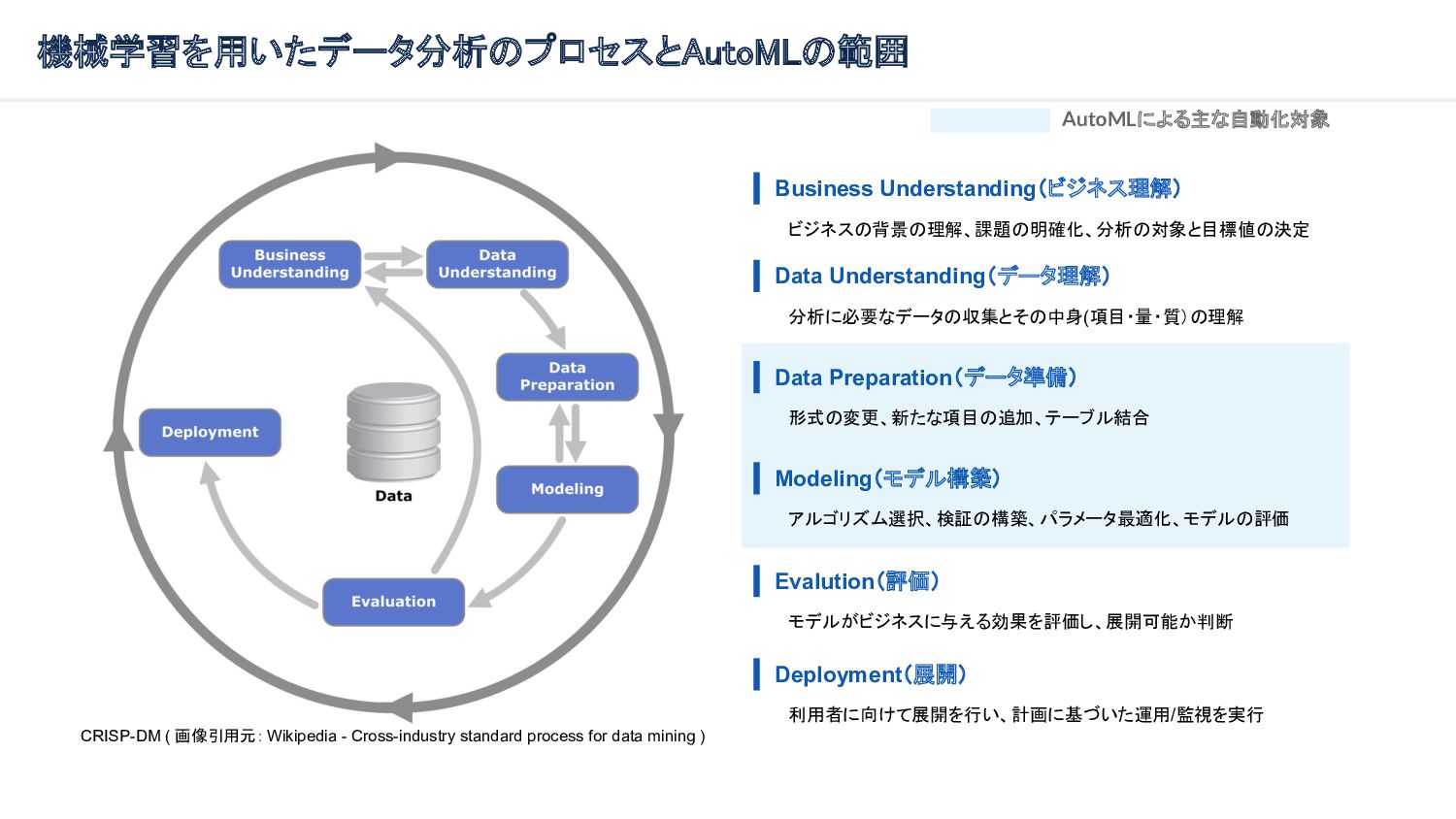
data mining ) Business Understanding(ビジネス理解) ビジネスの背景の理解、課題の明確化、分析の対象と目標値の決定 Data Understanding(データ理解) 分析に必要なデータの収集とその中身(項目・量・質)の理解 Data Preparation(データ準備) 形式の変更、新たな項目の追加、テーブル結合 Modeling(モデル構築) アルゴリズム選択、検証の構築、パラメータ最適化、モデルの評価 Evalution(評価) モデルがビジネスに与える効果を評価し、展開可能か判断 Deployment(展開) 利用者に向けて展開を行い、計画に基づいた運用/監視を実行 AutoMLによる主な自動化対象
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
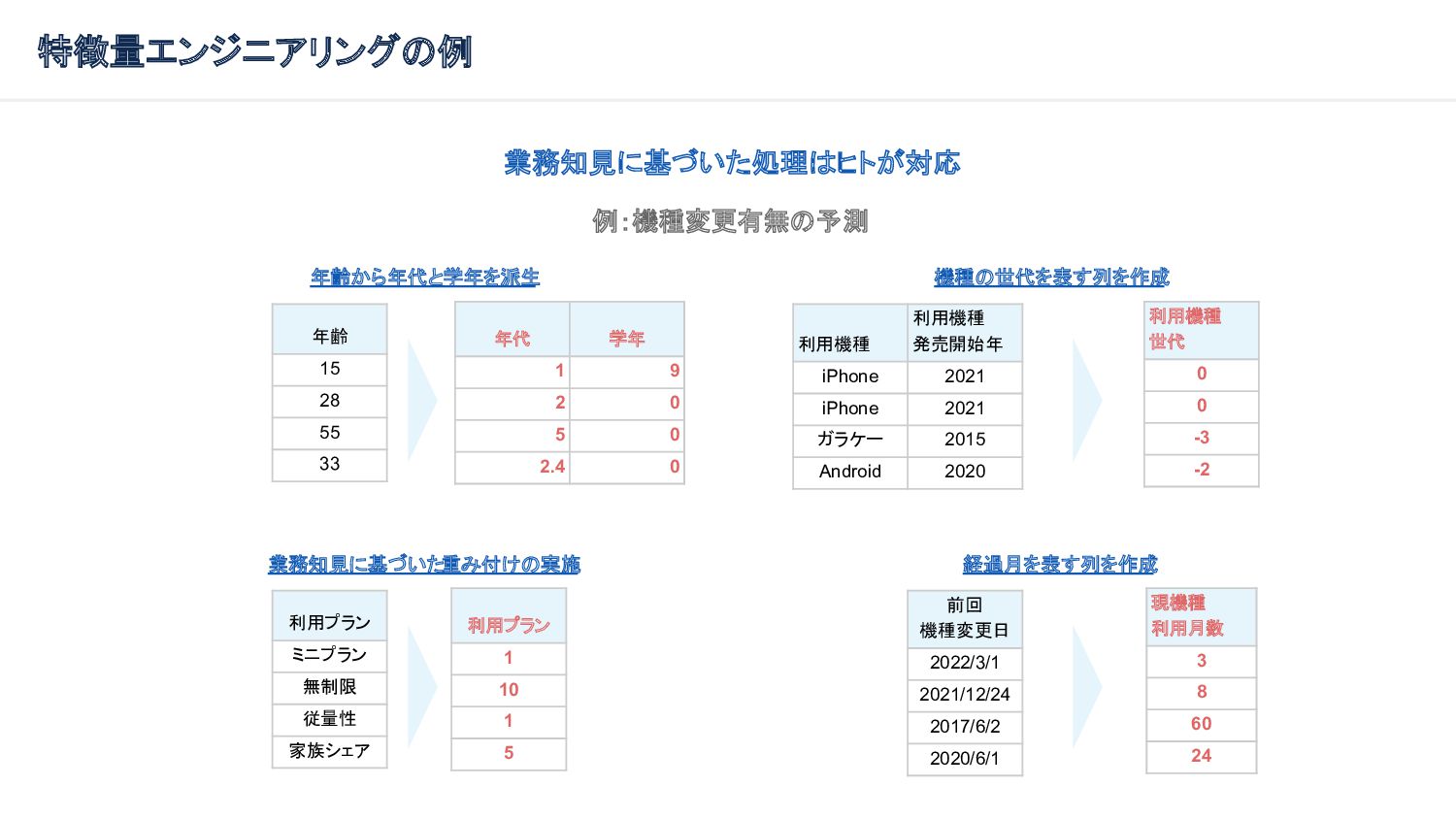{kind=link}
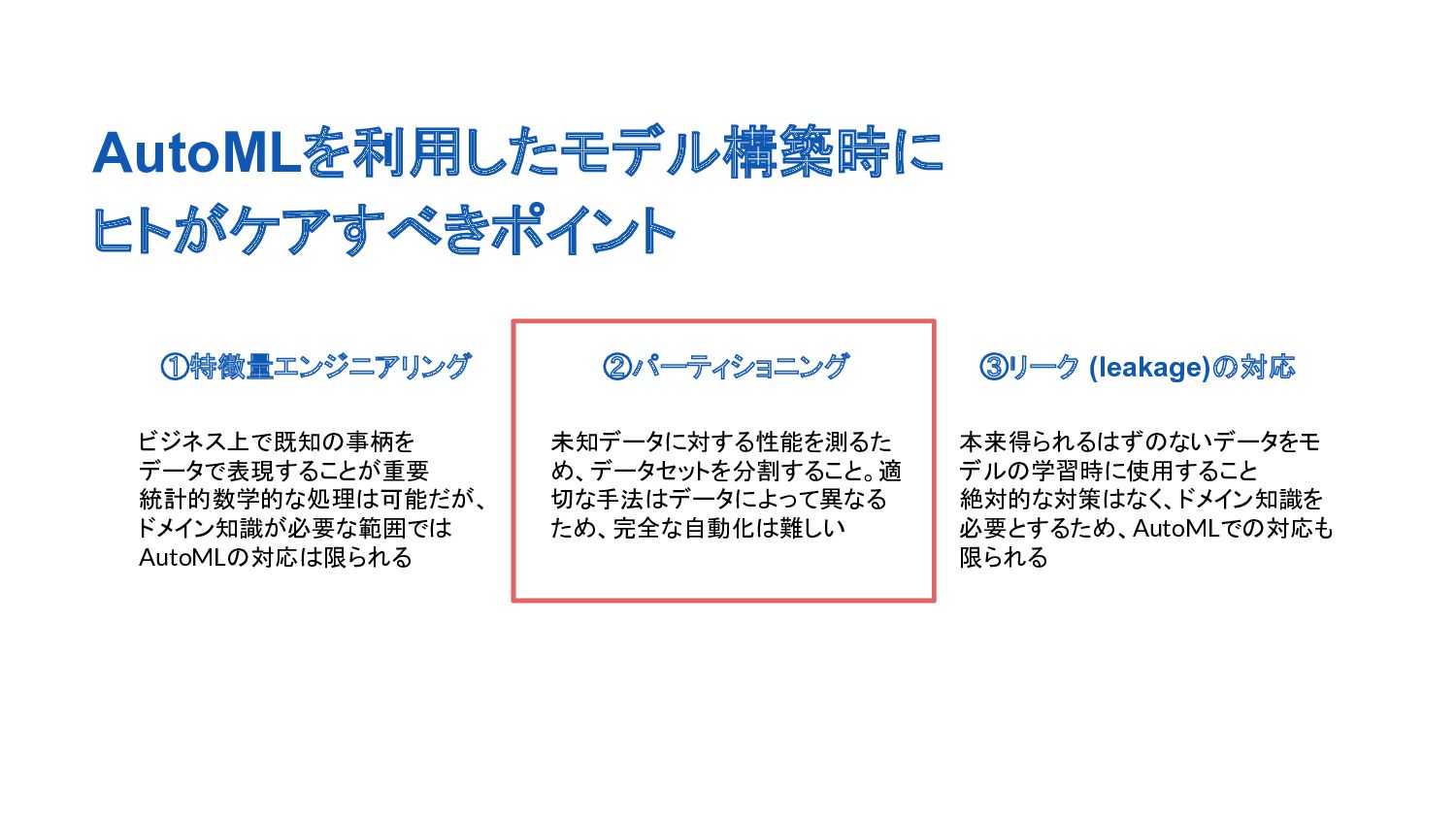{kind=link}
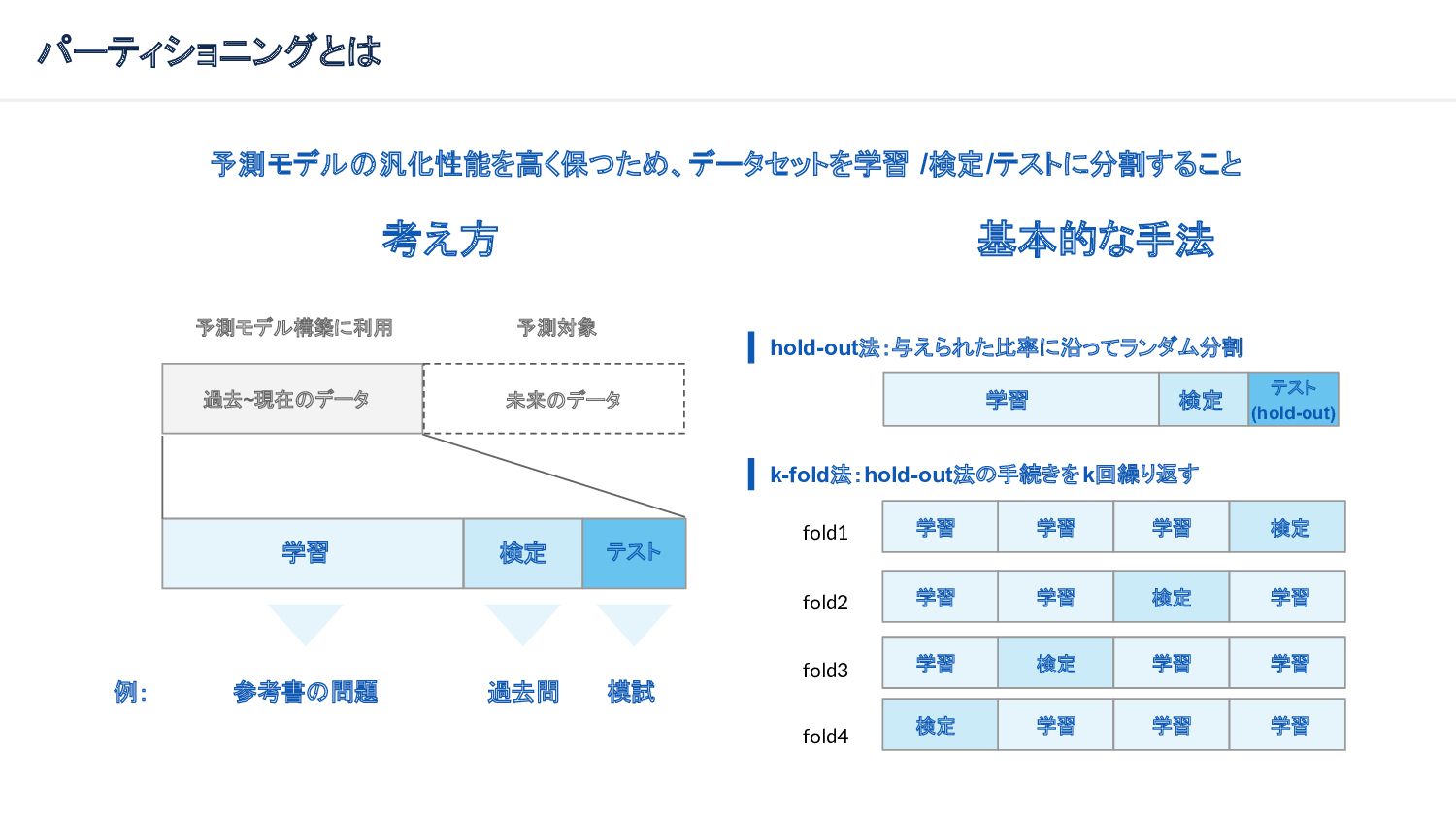{kind=link}
{kind=link}
{kind=link}
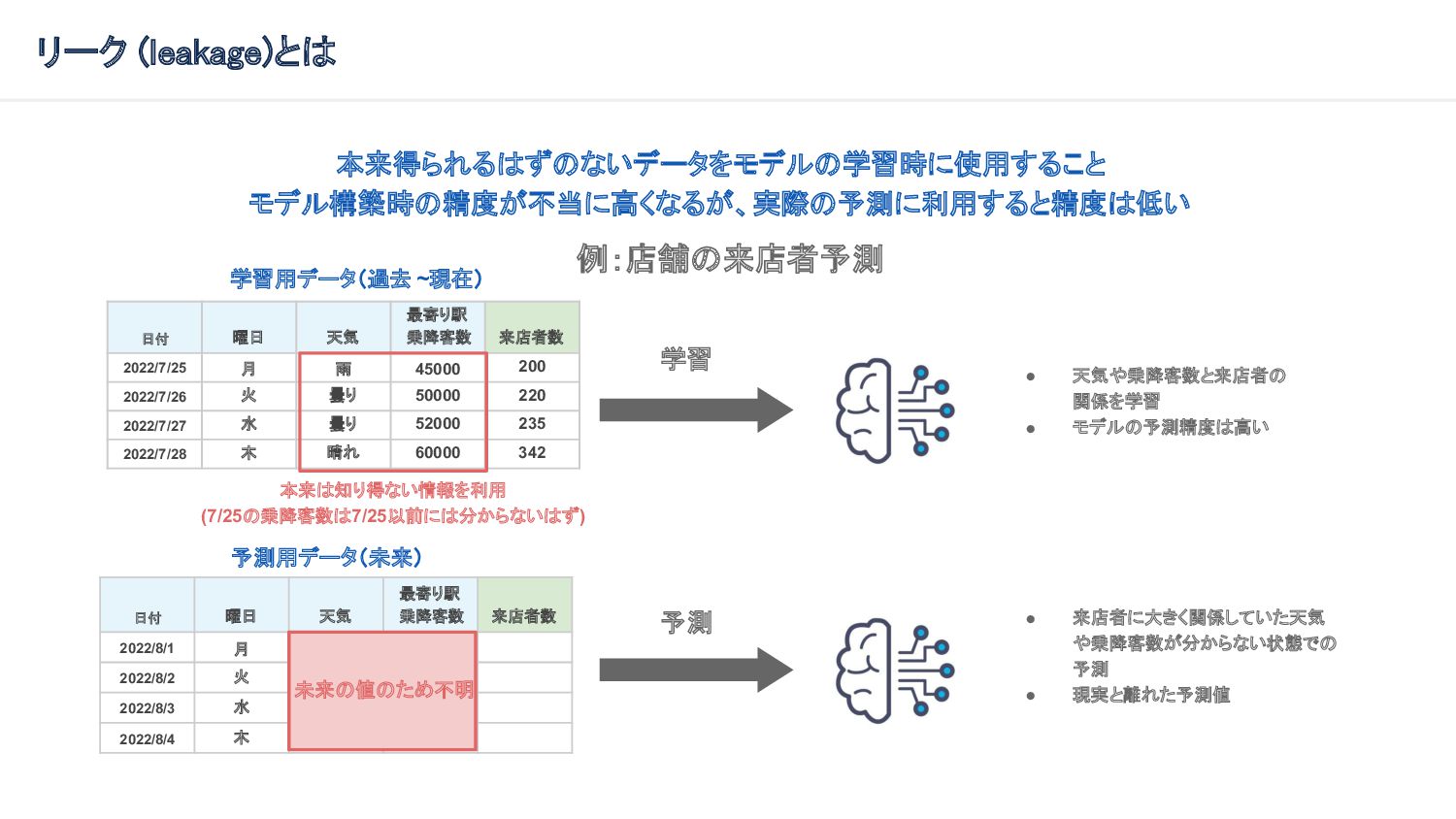{kind=link}
{kind=link}
{kind=link}
{kind=link}