Scalar DB: A library that makes non-ACID databases ACID-compliant
Scalar DB is a library that makes non-ACID databases ACID-compliant. It not only supports strongly-consistent ACID transactions but also scales linearly and achieves high availability when it is deployed with distributed databases such as Cassandra.
Yamada – Passionate about Database Systems and Distributed Systems – Ph.D. in Computer Science, the University of Tokyo – IIS the University of Tokyo, Yahoo! Japan, IBM Japan – https://github.com/feeblefakie 2
universal transaction manager – A Java library that makes non-ACID databases ACID-compliant – The architecture is inspired by Deuteronomy [CIDR’09,11] 4 https://github.com/scalar-labs/scalardb
Recovery management, Java API • Many distributed databases (NoSQLs) are non-transactional – Cassandra, HBase, Amazon Dynamo DB, Azure Cosmos DB – Scalability and availability are chosen over safety • New scratch-built distributed databases (NewSQLs) are emerging – Cockroach DB, TiDB, YugaByte, FaunaDB, Google Spanner – No sacrifice for safety. ACID is guaranteed – Relatively less matured compared with NoSQLs • Scalar DB is yet another approach to solve the issues
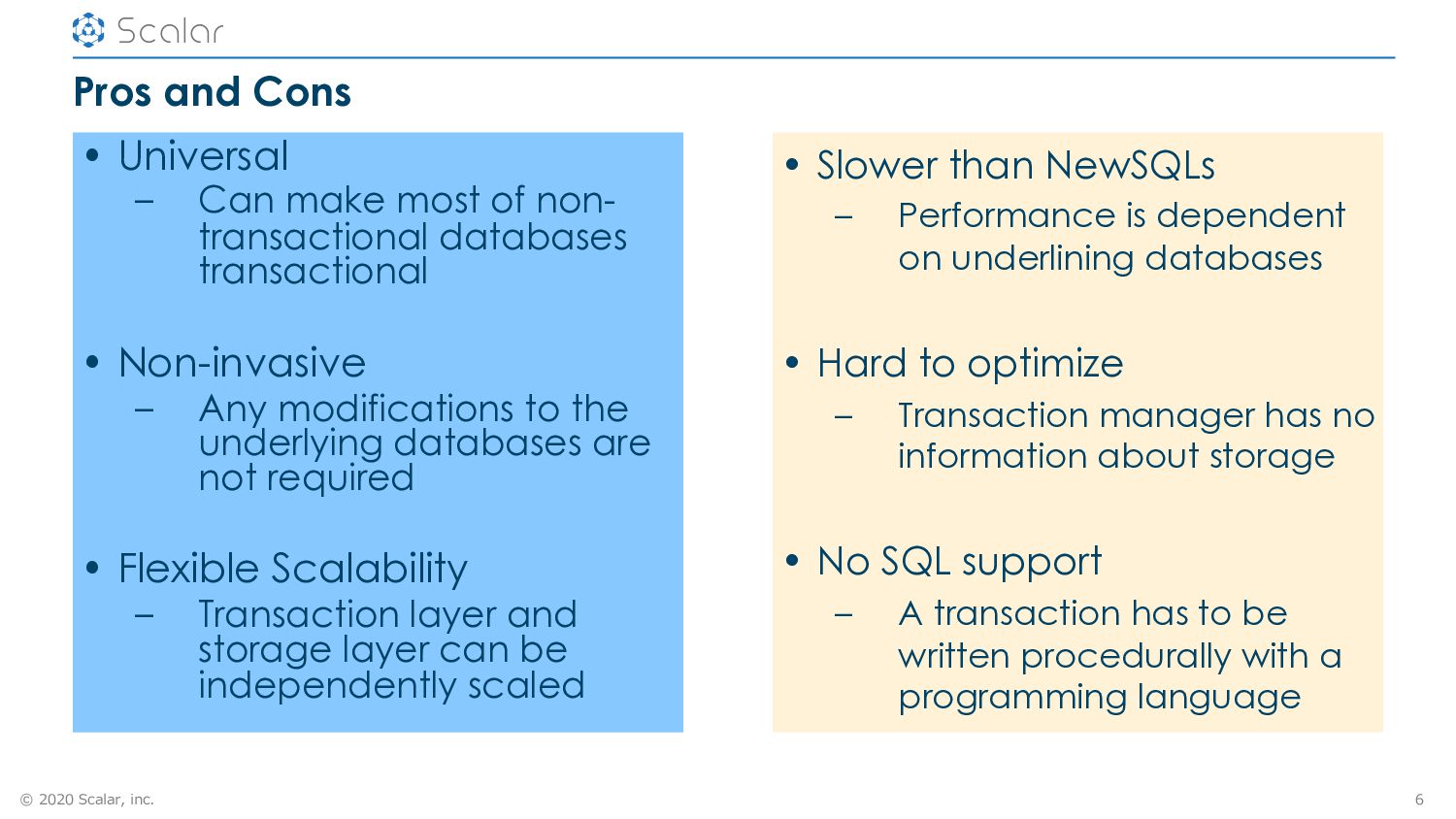
Can make most of non- transactional databases transactional • Non-invasive – Any modifications to the underlying databases are not required • Flexible Scalability – Transaction layer and storage layer can be independently scaled 6 • Slower than NewSQLs – Performance is dependent on underlining databases • Hard to optimize – Transaction manager has no information about storage • No SQL support – A transaction has to be written procedurally with a programming language
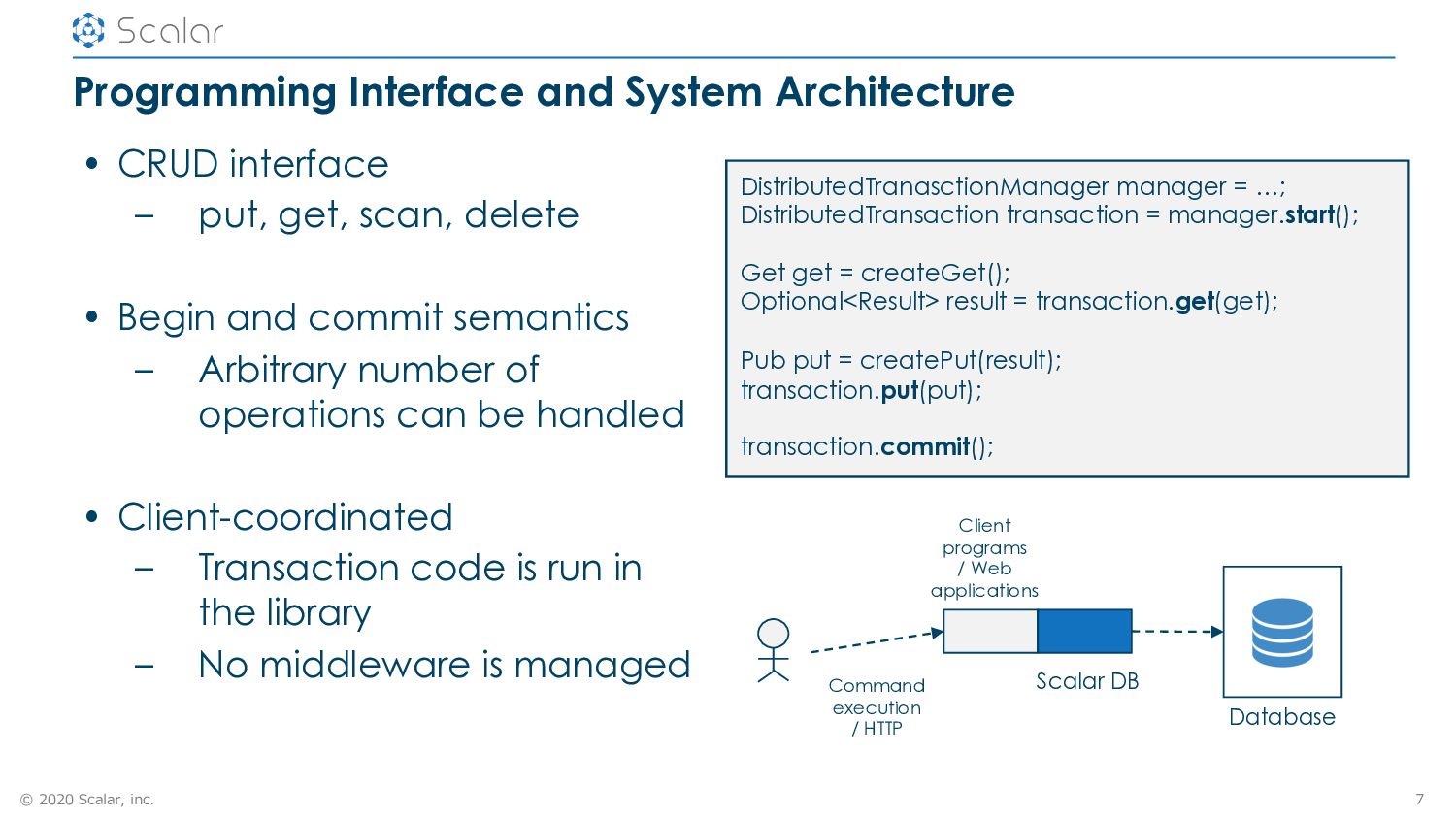
CRUD interface – put, get, scan, delete • Begin and commit semantics – Arbitrary number of operations can be handled • Client-coordinated – Transaction code is run in the library – No middleware is managed 7 DistributedTranasctionManager manager = …; DistributedTransaction transaction = manager.start(); Get get = createGet(); Optional<Result> result = transaction.get(get); Pub put = createPut(result); transaction.put(put); transaction.commit(); Client programs / Web applications Scalar DB Command execution / HTTP Database
on Cherry Garcia [ICDE’15] – Two phase commit on linearizable operations (for Atomicity) – Protocol correction is our extended work – Distributed WAL records (for Atomicity and Durability) – Single version optimistic concurrency control (for Isolation) – Serializability support is our extended work • Requirements in underlining databases/storages – Linearizable read and linearizable conditional/CAS write – An ability to store metadata for each record 9
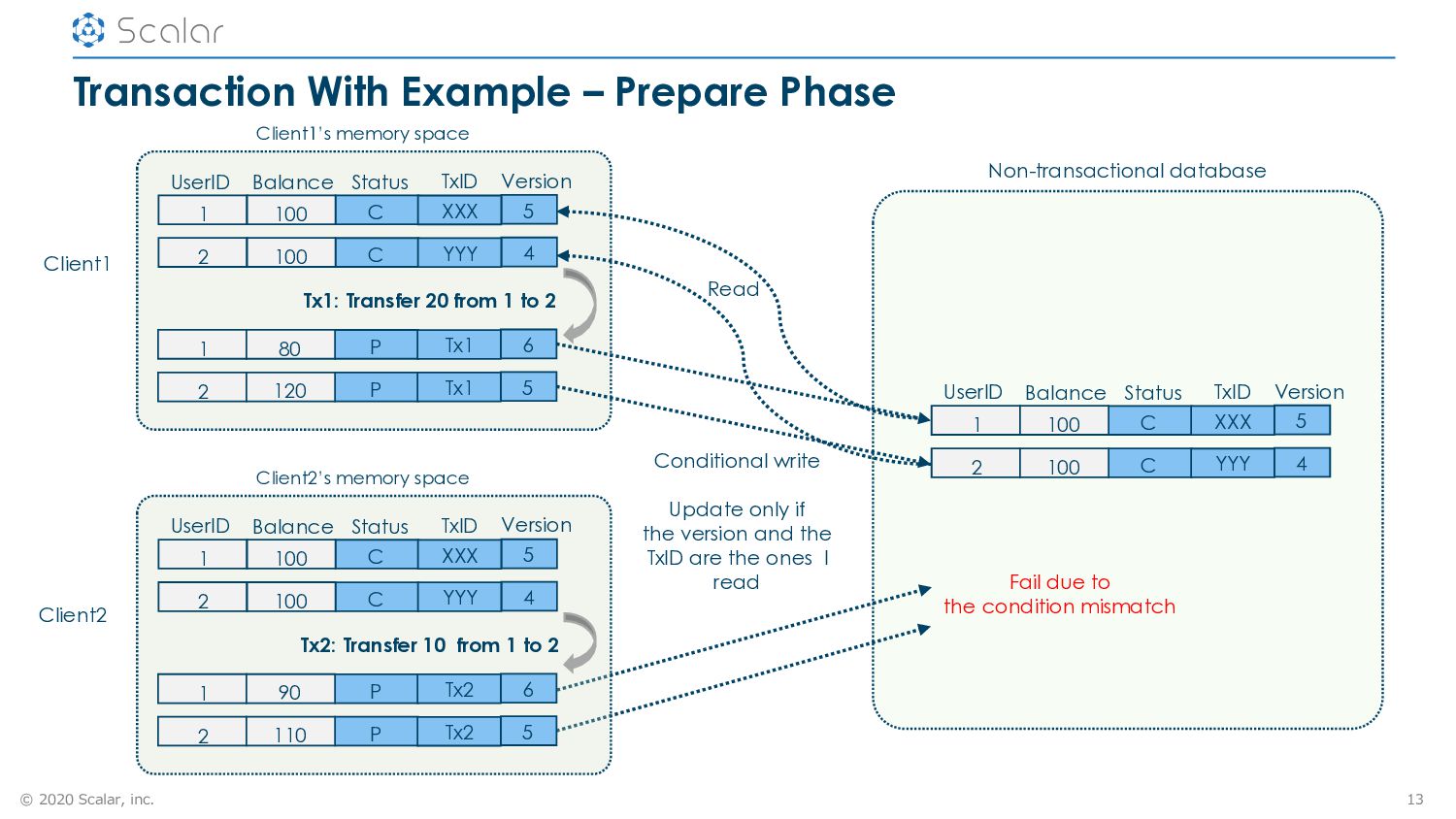
Two phase commit protocol on linearizable operations – Similar to Paxos Commit [TODS’06] when linearizability is achieved with Paxos – Data records are assumed to be distributed • The protocol – Prepare phase: prepare records – Commit phase 1: commit status record – This is where a transaction is regarded as committed or aborted – Commit phase 2: commit records • Lazy recovery – Uncommitted records will be rollforwarded or rollbacked based on the status of a transaction when the records are read 10
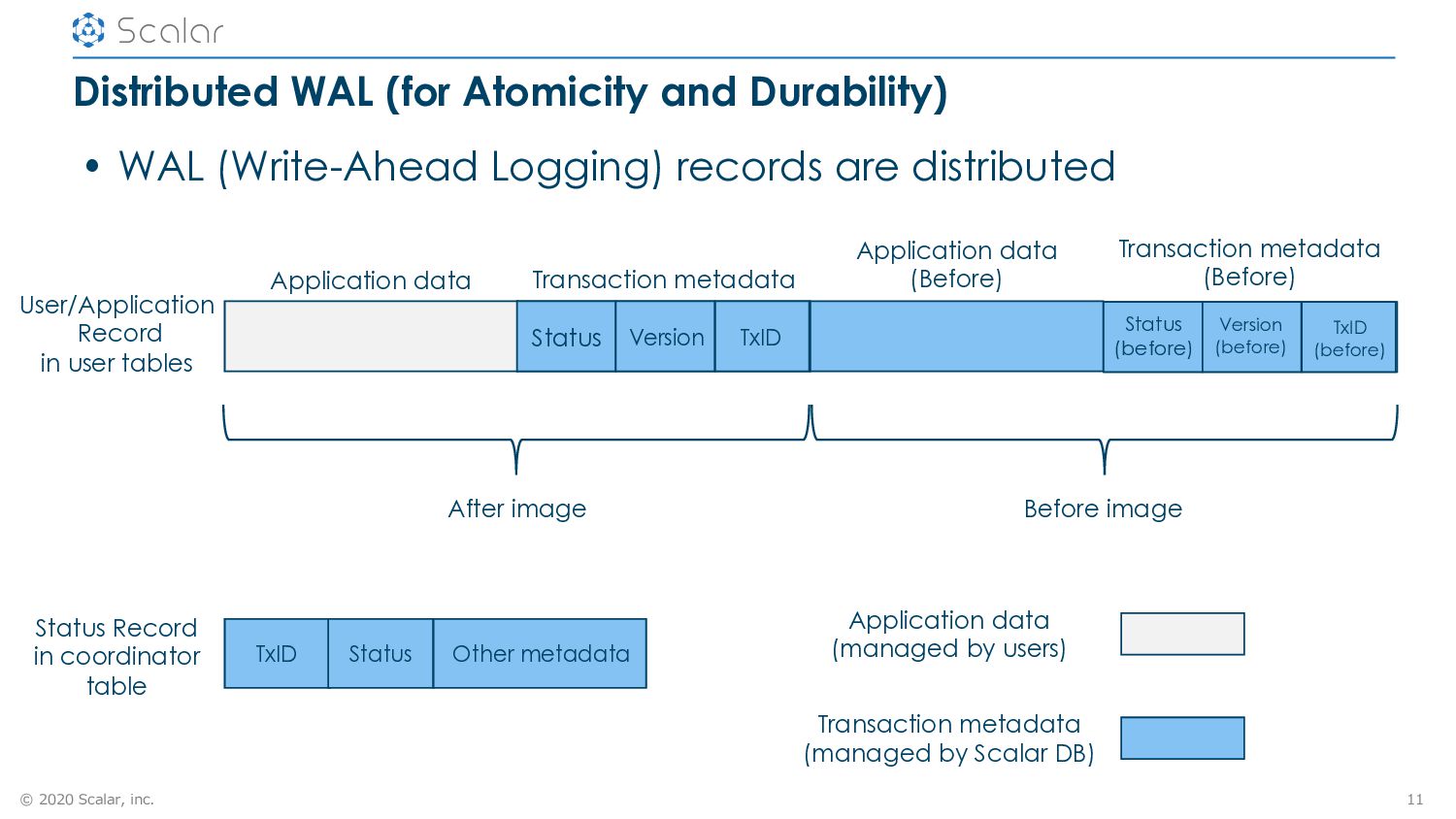
• WAL (Write-Ahead Logging) records are distributed 11 Application data Transaction metadata After image Before image Application data (Before) Transaction metadata (Before) Status Version TxID Status (before) Version (before) TxID (before) TxID Status Other metadata Status Record in coordinator table User/Application Record in user tables Application data (managed by users) Transaction metadata (managed by Scalar DB)
version OCC – Simple implementation of Snapshot Isolation – Conflicts are detected by linearizable conditional write – No clock dependency, no use of HLC (Hybrid Logical Clock) • Supported isolation level – Read-committed Snapshot Isolation (RCSI) – Read-skew, write-skew, read-only, phantom anomalies could happen – Serializable – No anomalies – RCSI-based but non-serializable schedules are aborted 12
13 Client1 Client1’s memory space Non-transactional database Read Conditional write Update only if the version and the TxID are the ones I read Fail due to the condition mismatch UserID Balance Status Version 1 100 C 5 TxID XXX 2 100 C 4 YYY 1 80 P 6 Tx1 2 120 P 5 Tx1 Tx1: Transfer 20 from 1 to 2 Client2 UserID Balance Status Version 1 100 C 5 Client2’s memory space Tx2: Transfer 10 from 1 to 2 TxID XXX 2 100 C 4 YYY 1 90 P 6 Tx2 2 110 P 5 Tx2 UserID Balance Status Version 1 100 C 5 TxID XXX 2 100 C 4 YYY
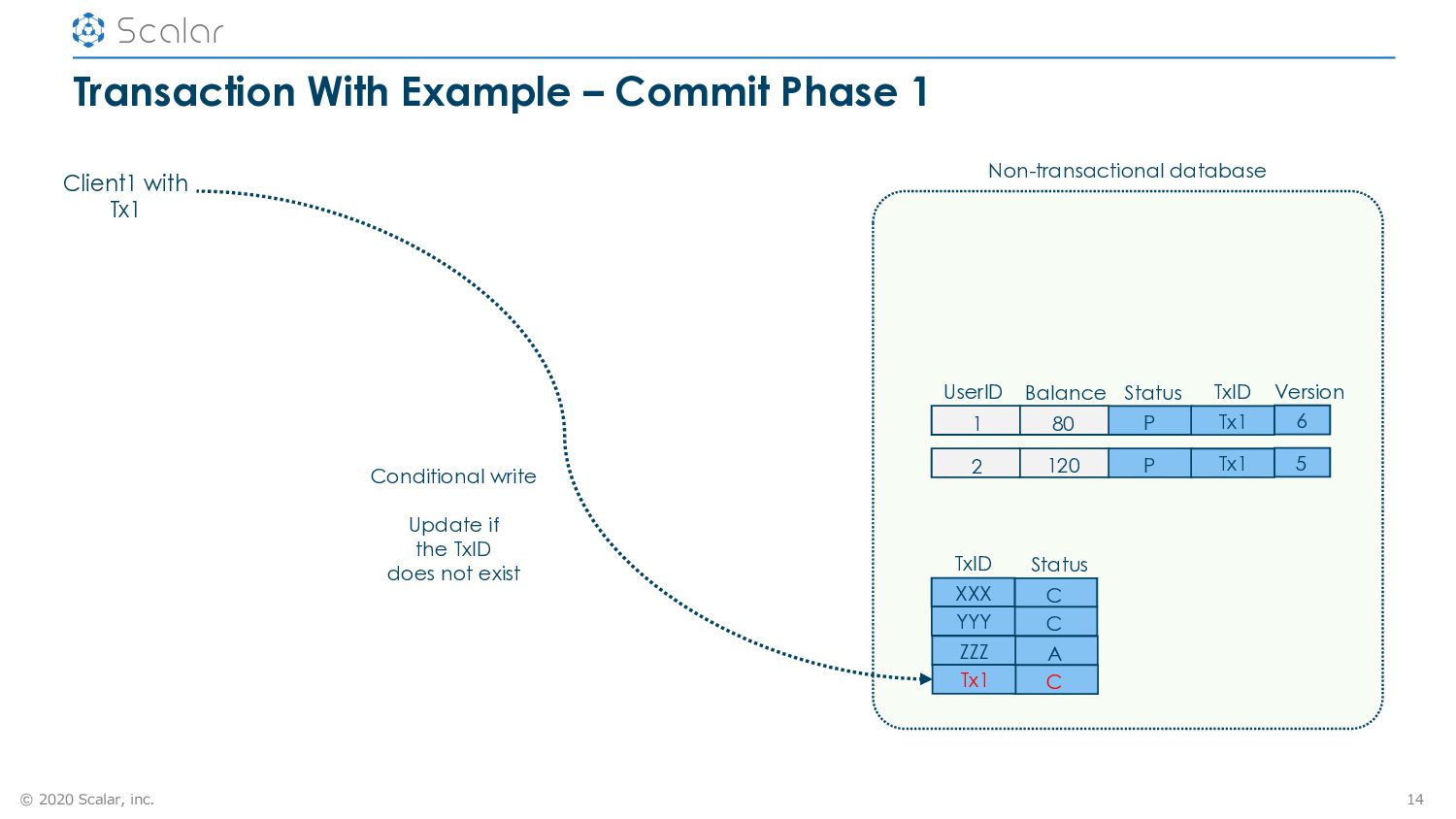
1 14 UserID Balance Status Version 1 80 P 6 TxID Tx1 2 120 P 5 Tx1 Status C TxID XXX C YYY A ZZZ C Tx1 Conditional write Update if the TxID does not exist Client1 with Tx1 Non-transactional database
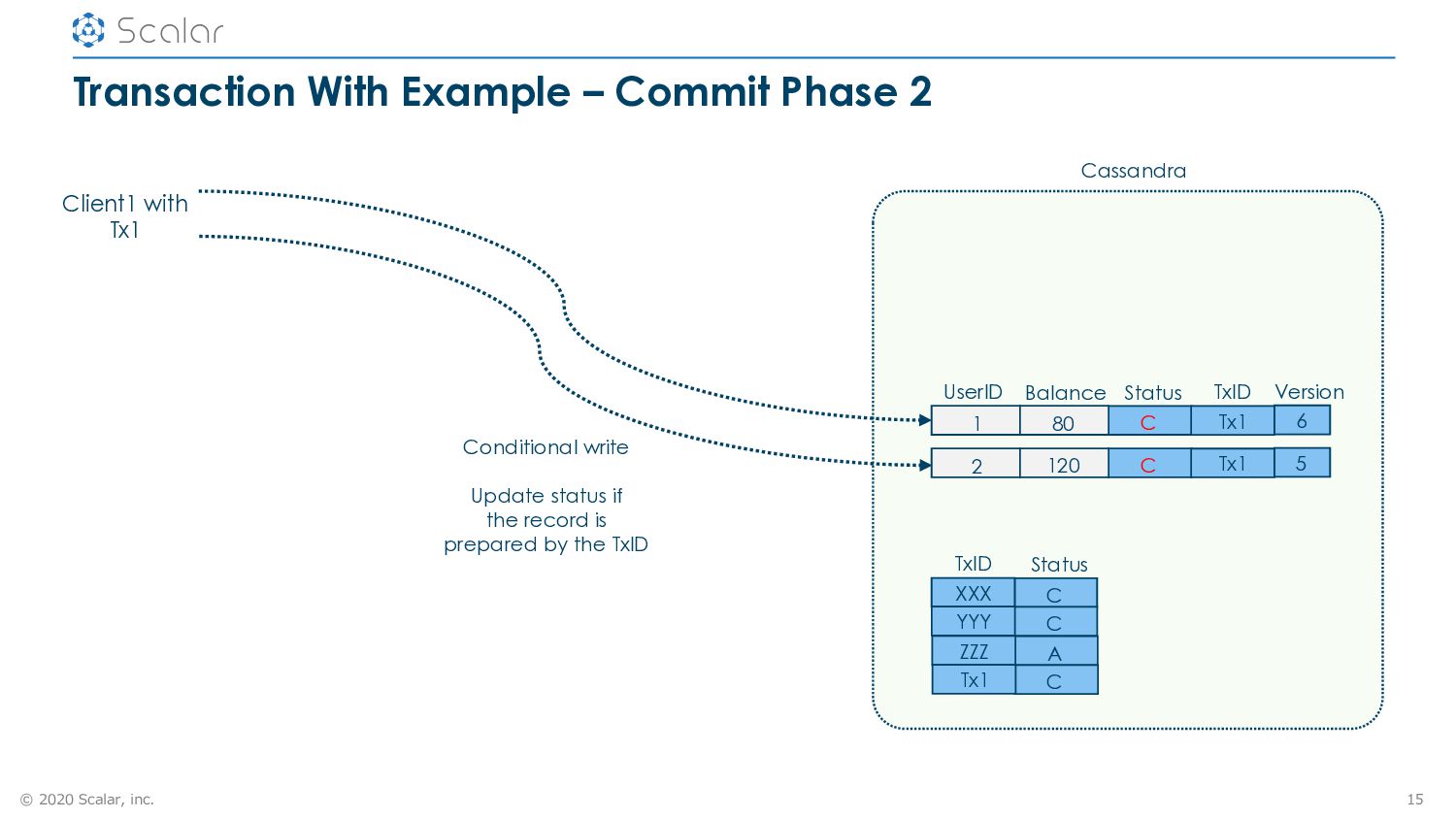
2 15 Cassandra UserID Balance Status Version 1 80 C 6 TxID Tx1 2 120 C 5 Tx1 Status C TxID XXX C YYY A ZZZ C Tx1 Conditional write Update status if the record is prepared by the TxID Client1 with Tx1
crashes before prepare phase – Just clear the memory space for TX1 • If TX1 crashes after prepare phase and before commit phase 1 (no status is written in Status table) – Another transaction (TX3) reads the records and notices that the records are prepared and there is no status for it – TX3 tries to abort TX1 (TX3 tries to write ABORTED to Status with TX1’s TXID and rolls back the records) – TX1 might be on its way to commit status, but only one can win, not both. • If TX1 crashes (right) after commit phase 1 – Another transaction (TX3) tries to commit the records (rollforward) on behalf of TX1 when TX3 reads the same records as TX1 – TX1 might be on its way to commit records, but only one can win, not both 16
Avoid anti-dependency dangerous structure [TODS’05] – No use of SSI [SIGMOD’08] or its variant [EuroSys’12] – Many linearizable operations for managing in/outConflicts or correct clock are required • Two implementations – Extra-write – Convert read into write – Extra care is done if a record doesn’t exist (Delete the record) – Extra-read – Check read-set after prepared to see if it is the same as before 17
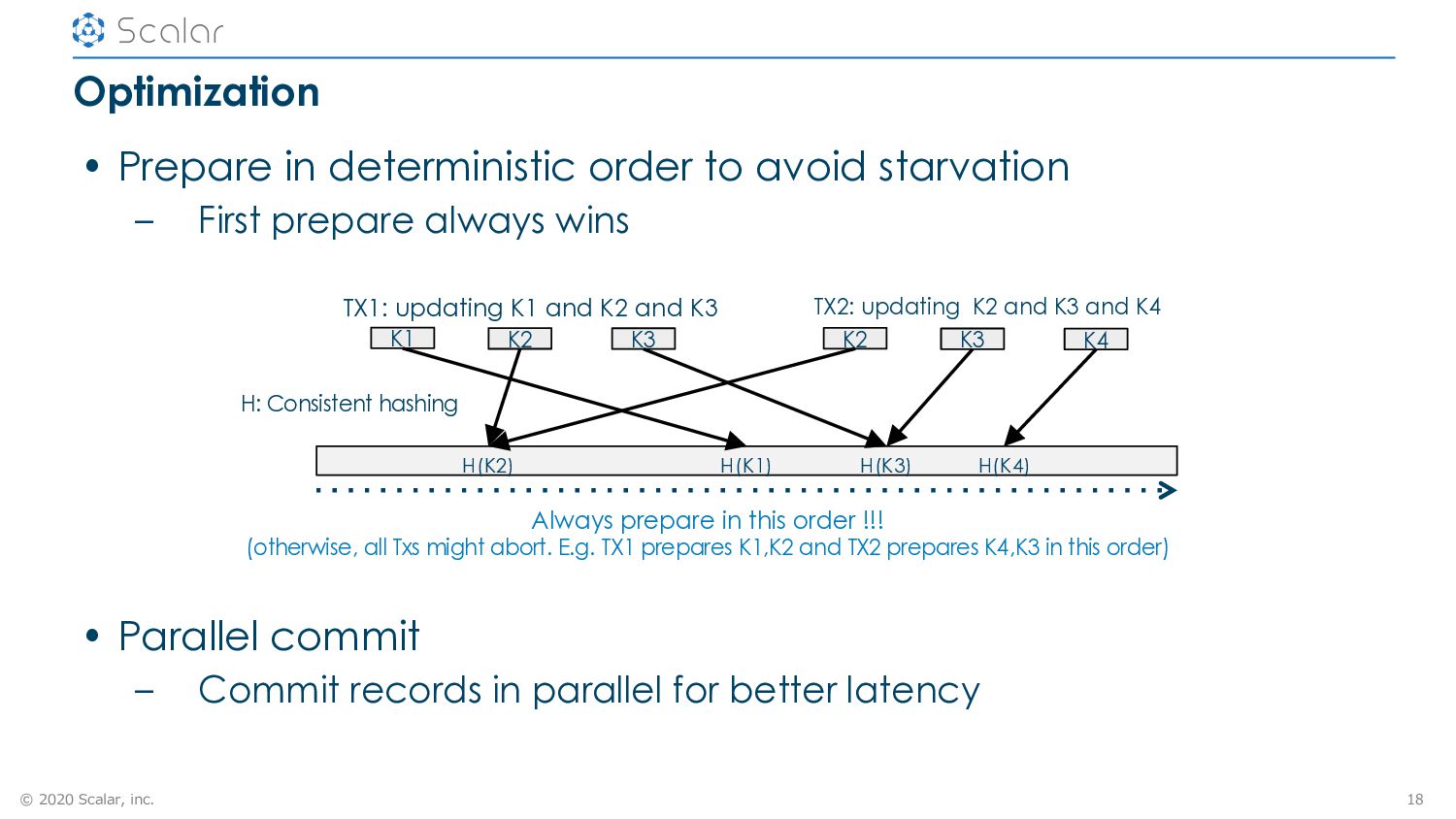
to avoid starvation – First prepare always wins 18 TX1: updating K1 and K2 and K3 TX2: updating K2 and K3 and K4 H: Consistent hashing K1 K2 K3 K2 K3 K4 Always prepare in this order !!! (otherwise, all Txs might abort. E.g. TX1 prepares K1,K2 and TX2 prepares K4,K3 in this order) H(K2) H(K1) H(K3) H(K4) • Parallel commit – Commit records in parallel for better latency
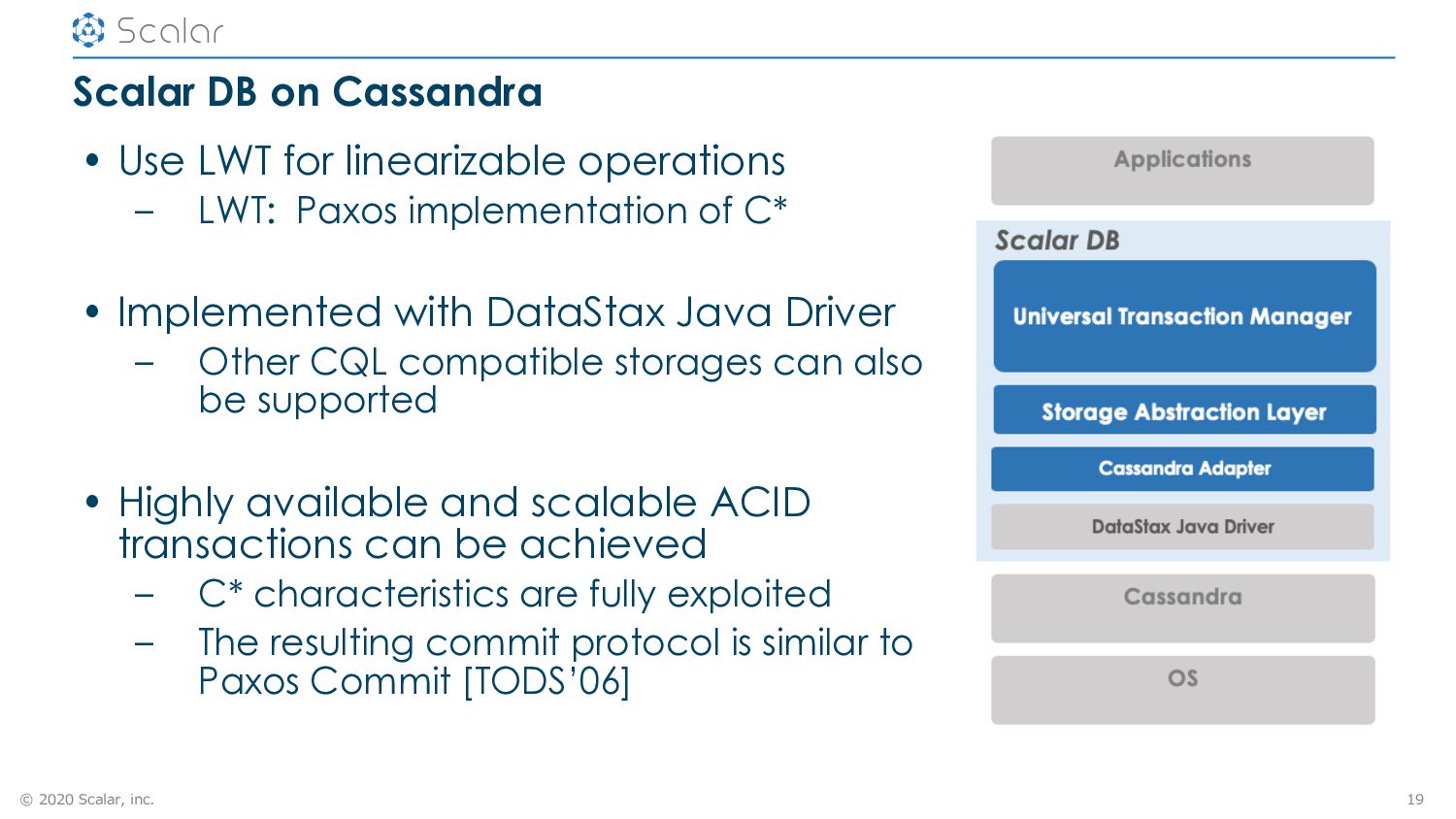
LWT for linearizable operations – LWT: Paxos implementation of C* • Implemented with DataStax Java Driver – Other CQL compatible storages can also be supported • Highly available and scalable ACID transactions can be achieved – C* characteristics are fully exploited – The resulting commit protocol is similar to Paxos Commit [TODS’06] 19
ScyllaDB – Works without any modifications (since ScyllaDB talks CQL) – Benchmarked but wasn’t stable at the time (Tested with ScyllaDB 3.2.0) • Phoenix/HBase – PoC version is publicly available – https://github.com/scalar-labs/scalardb-phoenix – Suppl. HBase doesn’t support transaction by itself • Azure Cosmos DB – Under development (plan to release in Sep) – Suppl. Cosmos DB can’t do a multi-partition transaction • AWS Dynamo DB – Under planning (plan to release in Dec) – Suppl. Dynamo DB can’t mix read and write in a transaction 20
been heavily tested with Jepsen and our destructive tools – Jepsen tests are created and conducted by Scalar – See https://github.com/scalar-labs/scalar-jepsen for more detail • Transaction commit protocol is verified with TLA+ – See https://github.com/scalar-labs/scalardb/tree/master/tla%2B/consensus-commit 22 Jepsen Passed TLA+ Passed
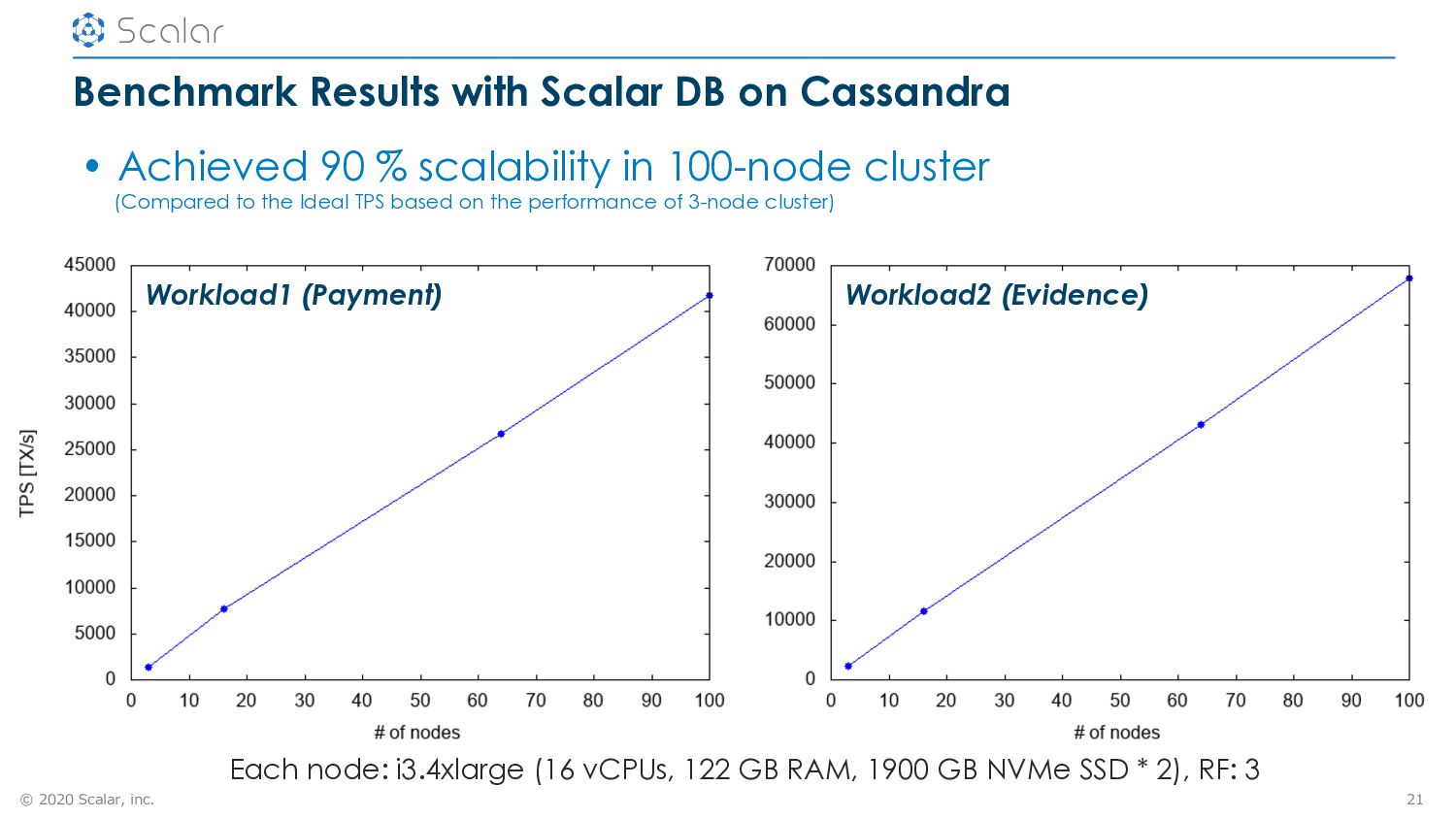
DB is a universal transaction manager – Can make non-ACID databases ACID-compliant – Based on previous research works such as Deuteronomy, Cherry Garcia, Paxos Commit, BigTable • Scalability and Serializability is intensively verified – 90 % scalability is achieved in 100-node cluster – Jepsen and TLA+ are passed • Future work – More extensive verification around Serializability – Integration with other databases than C* 23
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![© 2020 Scalar, inc. Data Model • Multi-dimensional map [OSDI’06]](https://files.speakerdeck.com/presentations/d320fcf9c90b4292ba1eaaafa0a3df83/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}