• 5 years at Yandex, search quality department: social and QA search, snippets. • 2 years at Avast! antivirus, research team: automatic false positive solving, large scale prediction of malicious download attempts. Hola a todos! 2
• Focused crawls & Broad crawls We help turn web content into useful data 3 { "content": [ { "title": { "text": "'Extreme poverty' to fall below 10% of world population for first time", "href": "http:// www.theguardian.com/society/2015/ oct/05/world-bank-extreme-poverty- to-fall-below-10-of-world- population-for-first-time" }, "points": "9 points",
and their sizes. • Limit crawl to .es zone. • Breadth-first strategy: first crawl 1-click distance documents, next 2-clicks, and so on, • Finishing condition: absence of hosts with less than 100 crawled documents. • Low costs. 5
1,56М (39% growth per year) • Web server in zone - 283,4K (33,1%) • Hosts - 4,2M (21%) • Spanish web sites in DMOZ catalog - 22043 * - отчет OECD Communications Outlook 2013 6
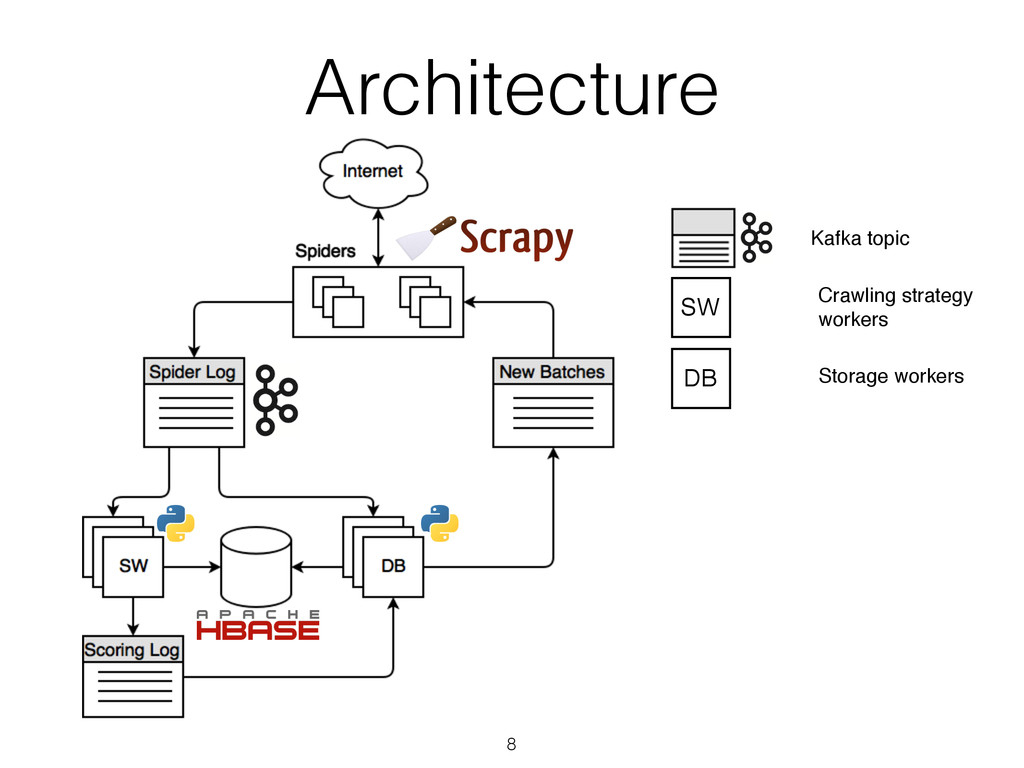
data bus (offsets, partitioning). • Apache HBase - storage (random access, linear scanning, scalability). • Twisted.Internet - library for async primitives for use in workers. • Snappy - efficient compression algorithm for IO-bounded applications. * - network operations in Scrapy are implemented asynchronously, based on the same Twisted.Internet 7
to huge number of links from some host, along with usage of simple prioritization models, it turns out queue is flooded with URLs from the same host. • That causes underuse of spider resources. • We adopted additional per- host (optionally per-IP) queue and metering algorithm: URLs from big hosts are cached in memory. 9
first visiting of previously unknown hosts, therefore generating huge amount of DNS request. • Recursive DNS server on each downloading node, with upstream set to Verizon and OpenDNS. • We used dnsmasq. 10
Scrapy uses a thread pool to resolve DNS name to IP. • When ip is absent in cache, request is sent to DNS server in it’s own thread, which is blocking. • Scrapy reported numerous errors related to DNS name resolution and timeouts. • We added option to Scrapy for thread pool size and timeout adjustment. 11
extracts from document hundreds of links in average. • Before adding this links to queue, they needs to be checked if they weren’t already crawled (to avoid repetitive visiting). • On small volumes SSDs were just fine. After increase of table size, we had to move to HDDs, and response times dramatically grew up. • Host-local fingerprint function for keys in HBase. • Tuning HBase block cache to fit average host states into one block. 12
noticed throughput between workers Kafka and HBase up to 1Gbit/s. • Switched to Thrift compact protocol for HBase communication. • Message compression in Kafka using Snappy. 13
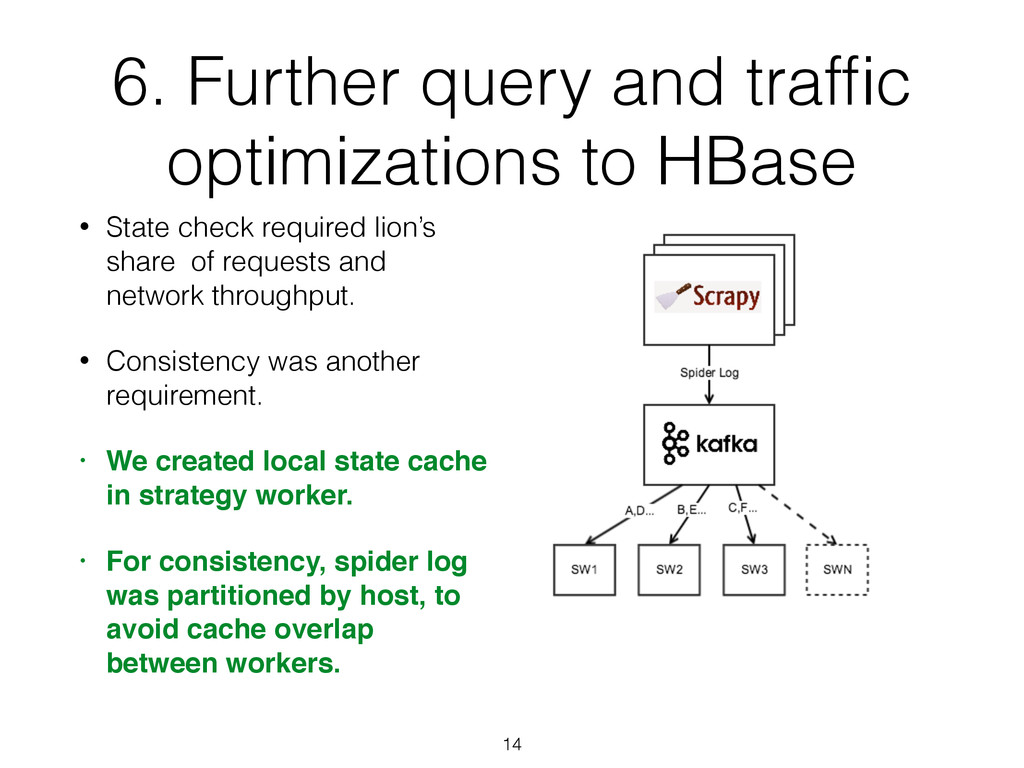
check required lion’s share of requests and network throughput. • Consistency was another requirement. • We created local state cache in strategy worker. • For consistency, spider log was partitioned by host, to avoid cache overlap between workers. 14
is absent in cache, it’s requested from HBase, • every ~4K documents cache is flushed to HBase. • When achieving 3M (~1Гб) elements, flush and cleanup happens. • It seems Least-Recently-Used (LRU) algorithm is a good fit there. 15
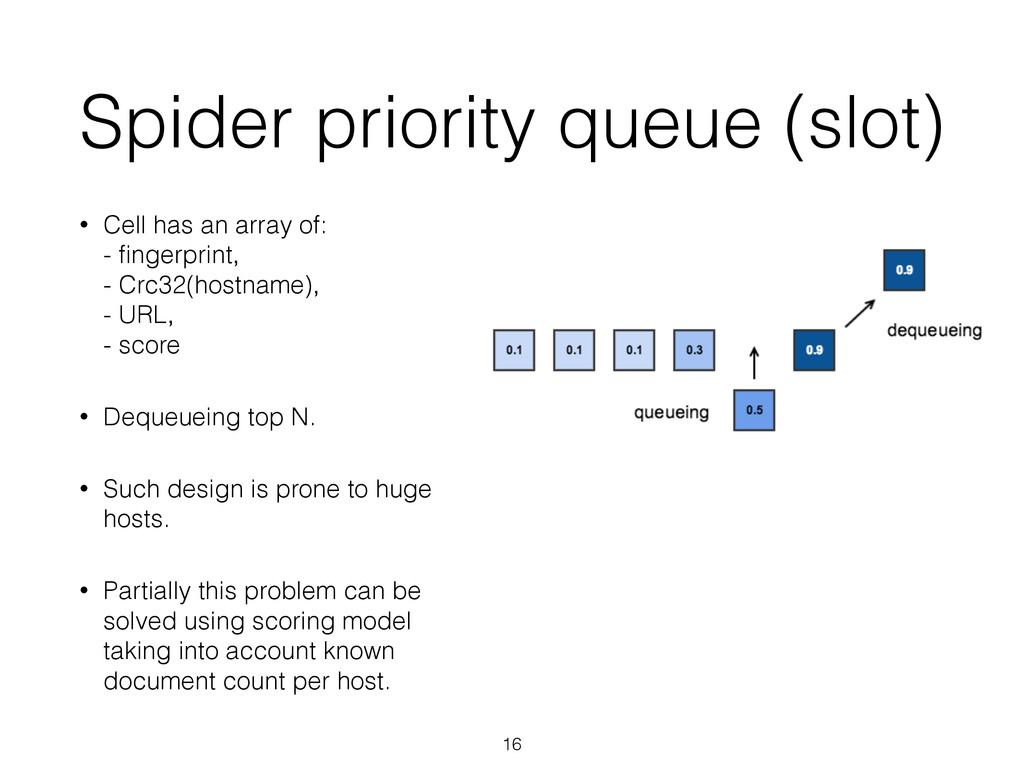
- fingerprint, - Crc32(hostname), - URL, - score • Dequeueing top N. • Such design is prone to huge hosts. • Partially this problem can be solved using scoring model taking into account known document count per host. 16
During crawling we’ve found few very huge hosts (>20M docs) • All queue partitions were flooded with pages from few huge hosts, because of queue design and scoring model used. • We made two MapReduce jobs: • queue shuffling, • limiting all hosts to no more than 100 documents. 17
websites in parallel. • Spiders to workers ratio is 4:1 (without content) • 1 Gb of RAM for every SW (state cache, tunable). • Example: • 12 spiders ~ 14.4K pages/min., • 3 SW and 3 DB workers, • Total 18 cores. Hardware requirements 18
sensitive to free space on root partition, parcels, and storage of Cloudera Manager. • We’ve moved it using symbolic links to separate EBS partition. • EBS should be at least 30Gb, base IOPS should be enough. • Initial hardware was 3 x m3.xlarge (4 CPU, 15Gb, 2x40 SSD). • After one week of crawling, we ran out of space, and started to move DataNodes to d2.xlarge (4 CPU, 30.5Gb, 3x2Tb HDD). 20
druni.es, docentesconeducacion.es - are the biggest websites • 68.7K domains found (~600K expected), • 46.5M crawled pages overall, • 1.5 months, • 22 websites with more than 50M pages 21
state. • Storage abstraction: write your own backend (sqlalchemy, HBase is included). • Canonical URLs resolution abstraction: each document has many URLs, which to use? • Scrapy ecosystem: good documentation, big community, ease of customization. Main features 26
• Crawling strategy abstraction: crawling goal, url ordering, scoring model is coded in separate module. • Polite by design: each website is downloaded by at most one spider. • Python: workers, spiders. Distributed Frontera features 27
using sockets. • Revisiting strategy out-of-box. • Watchdog solution: tracking website content changes. • PageRank or HITS strategy. • Own HTML and URL parsers. • Integration into Scrapinghub services. • Testing on larger volumes. 29
implement web scale web crawler using Python. • Truly resource-intensive task: CPU, network, disks. • Made in Scrapinghub, a company where Scrapy was created. • A plans to become an Apache Software Foundation project. 30
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Gracias! Thank you! Alexander Sibiryakov, [email protected]](https://files.speakerdeck.com/presentations/64d73a8a499a4041974b404b88401430/slide_32.jpg){kind=link}