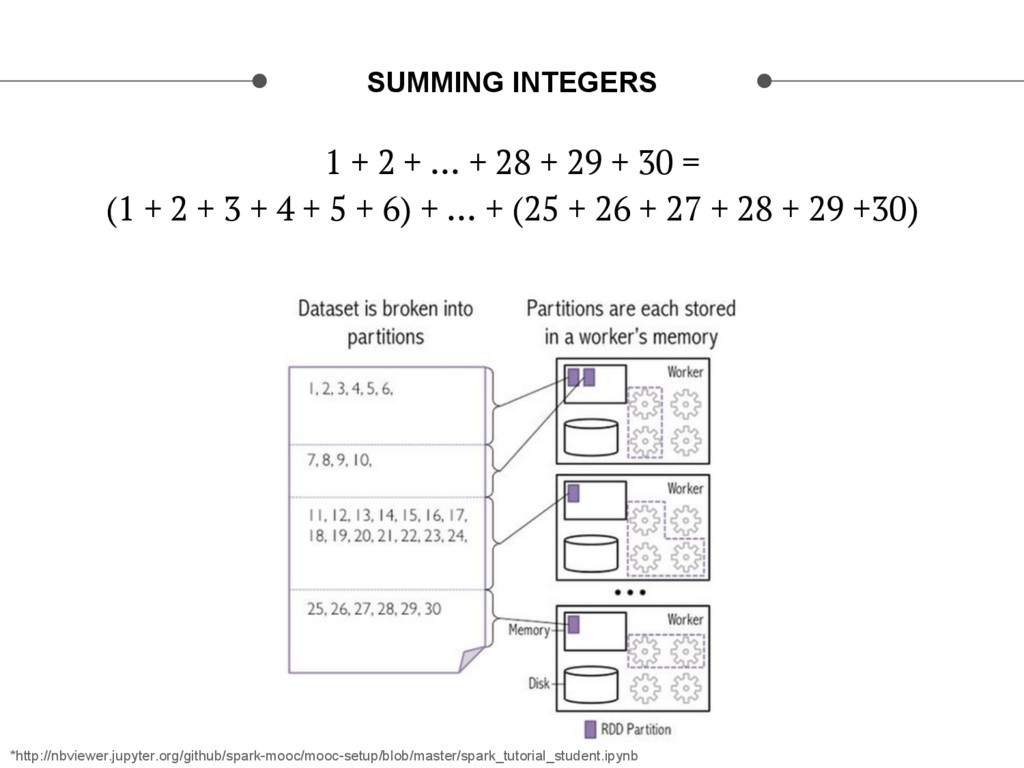
This talk will go over the architecture we’ve built to fully scale recommendations for the new television service we are building at Verizon. Scala has been helpful to our group to scale up models as we have learned to apply functional programming patterns along with Big Data patterns in Spark to build our models. We’ll highlight some use cases for building large similarity matrices
{kind=link}
{kind=link}
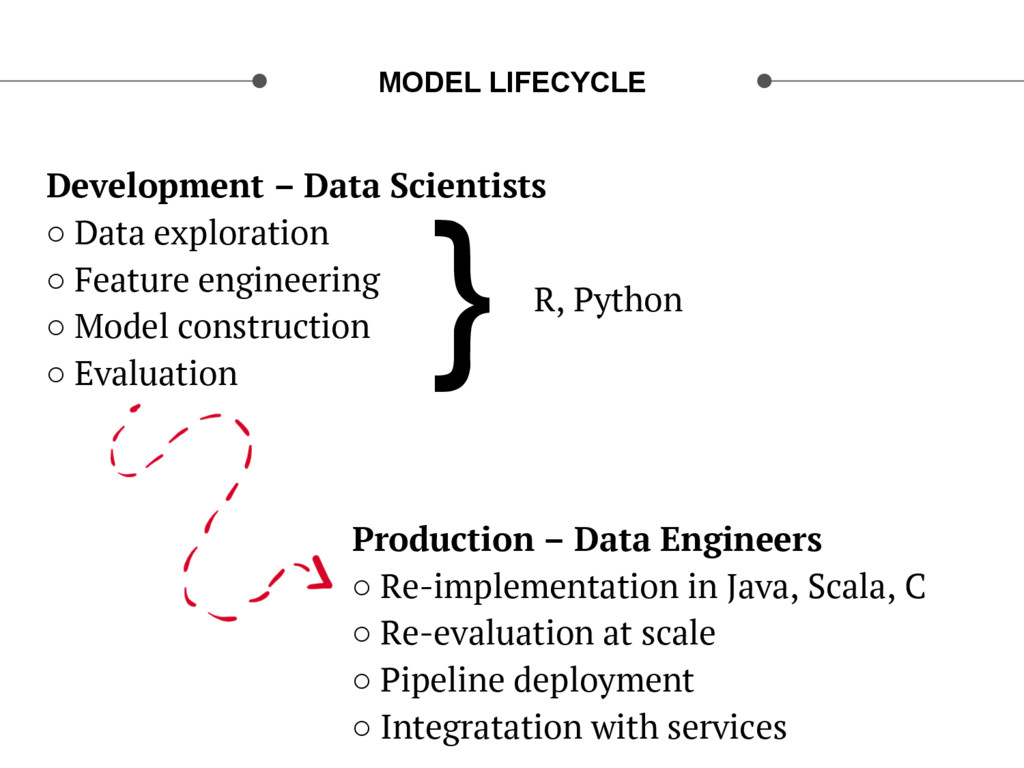{kind=link}
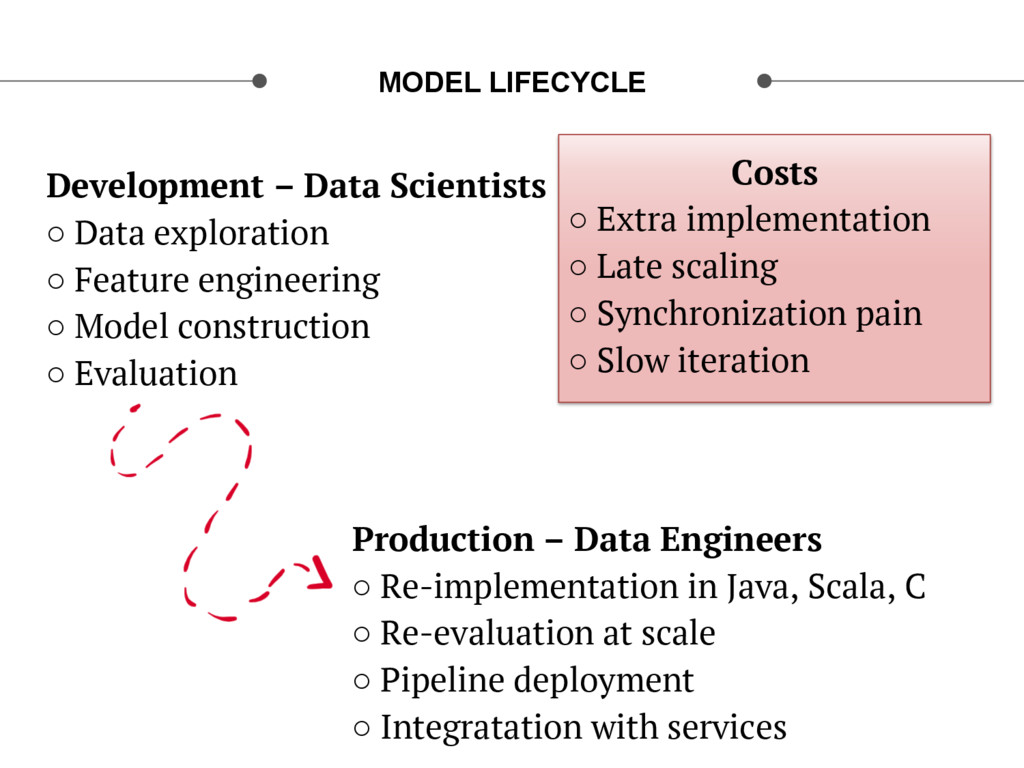{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![TOPK WITH ABSTRACT ALGEBRA class PiorityQueueMonoid[T] (max : Int)](https://files.speakerdeck.com/presentations/2097f1ab39294efd84f87d1a1f2b4d5b/slide_24.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![THANKS! Any questions? You can find us at: @sdianahu [email protected]](https://files.speakerdeck.com/presentations/2097f1ab39294efd84f87d1a1f2b4d5b/slide_28.jpg){kind=link}
{kind=link}