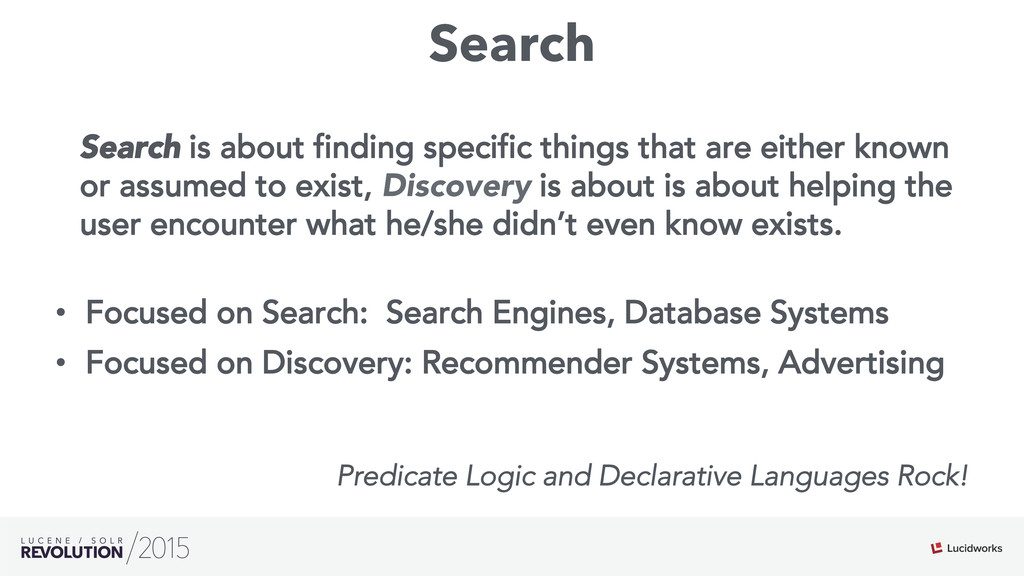
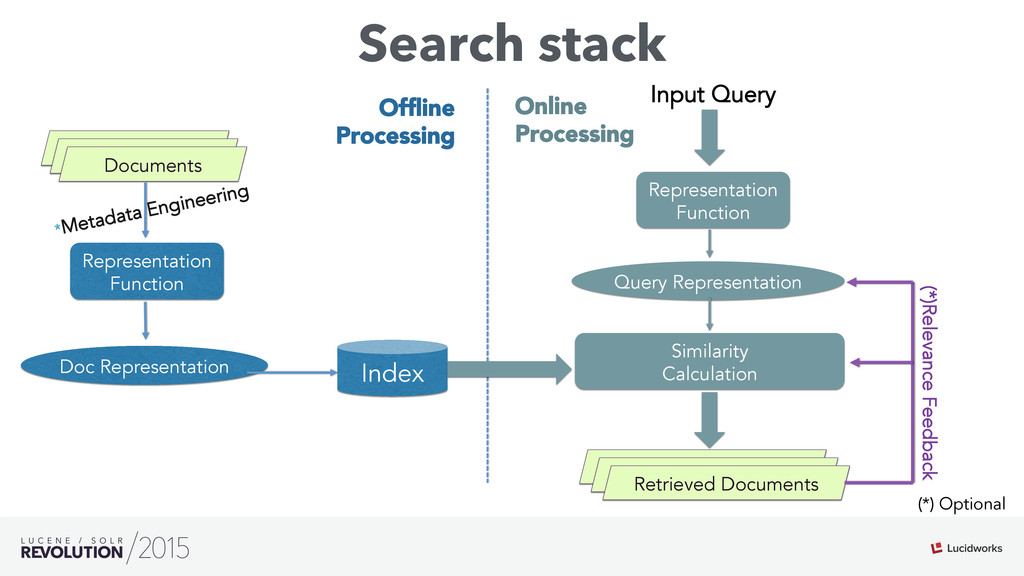
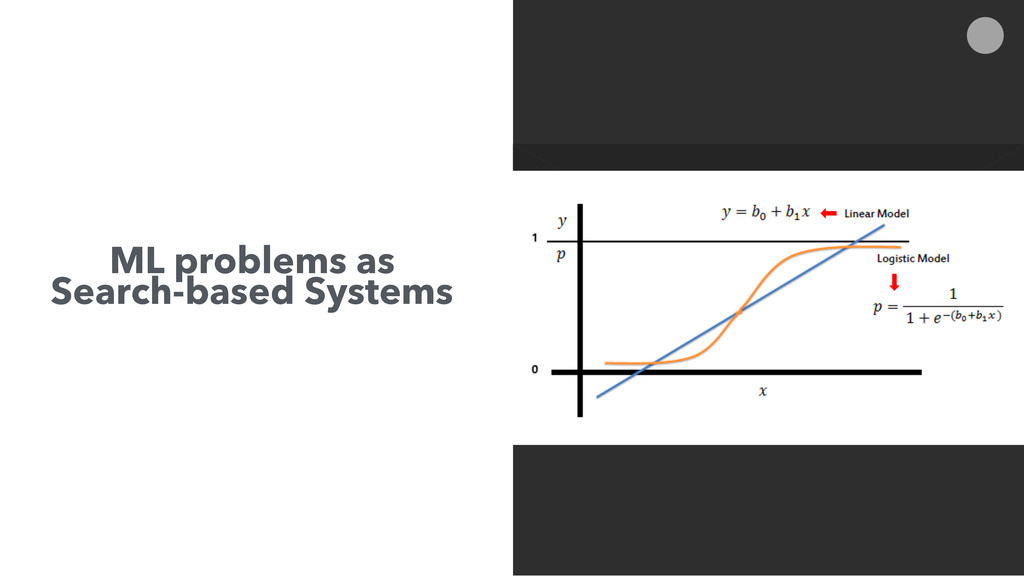
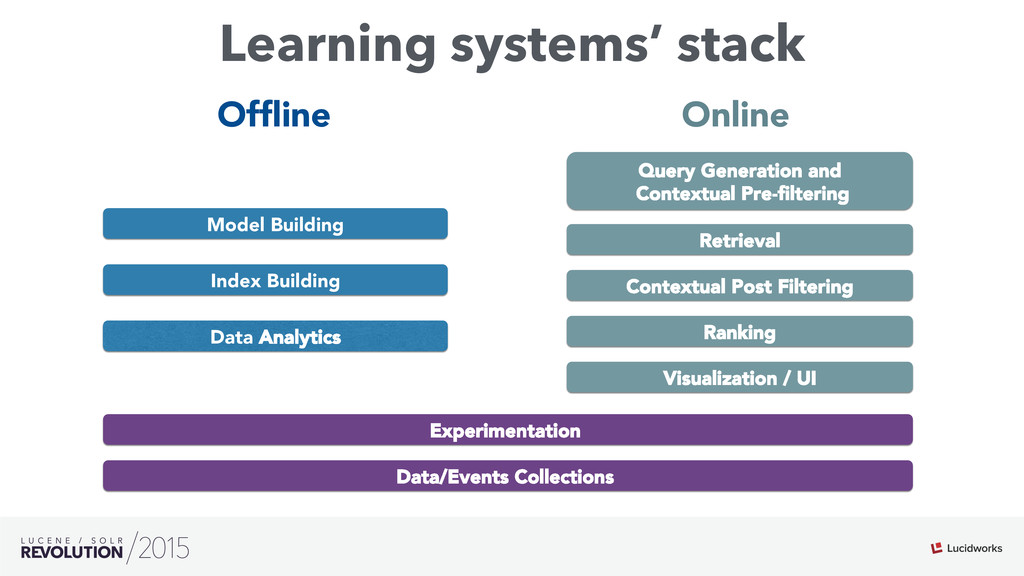
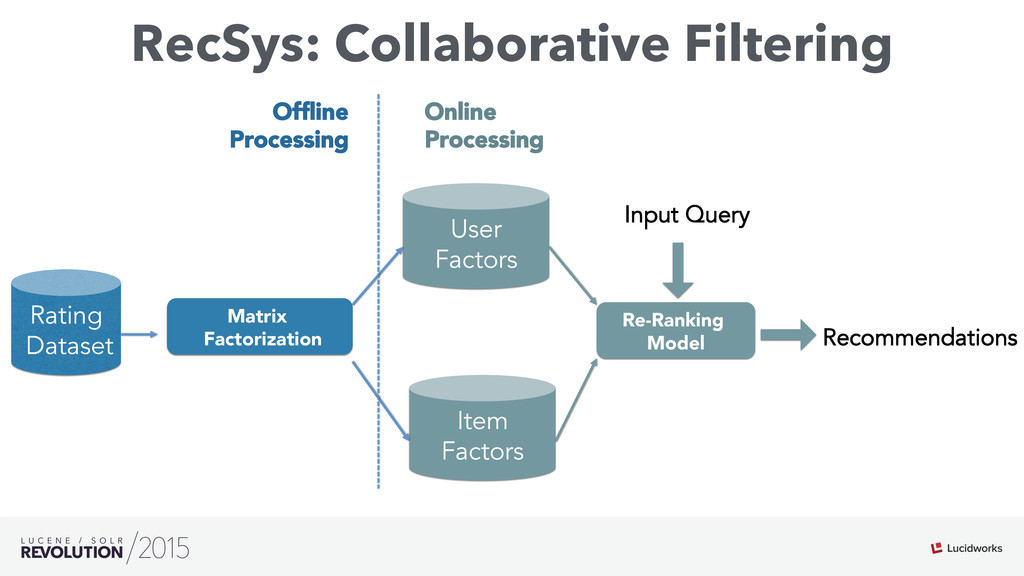
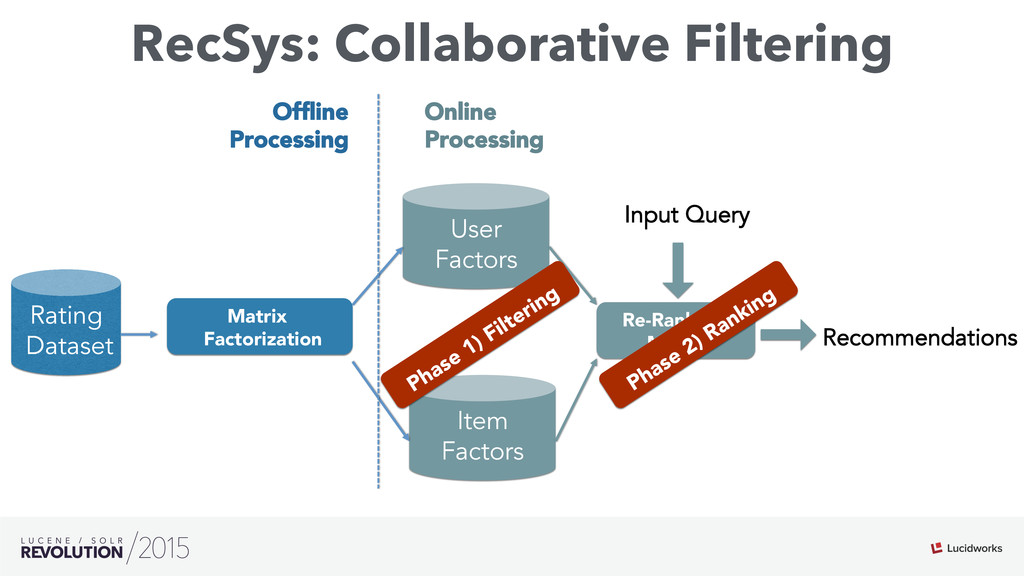
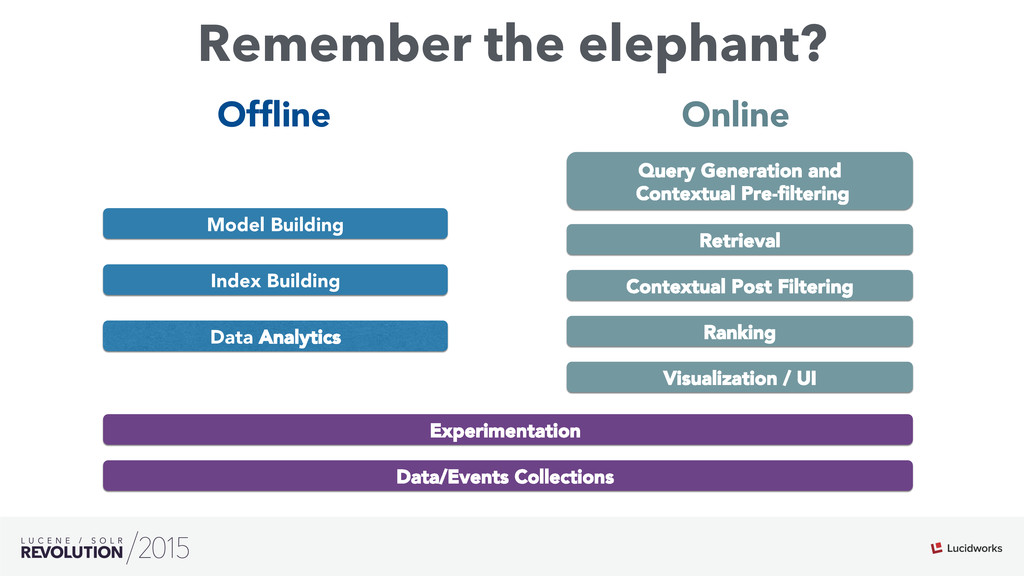
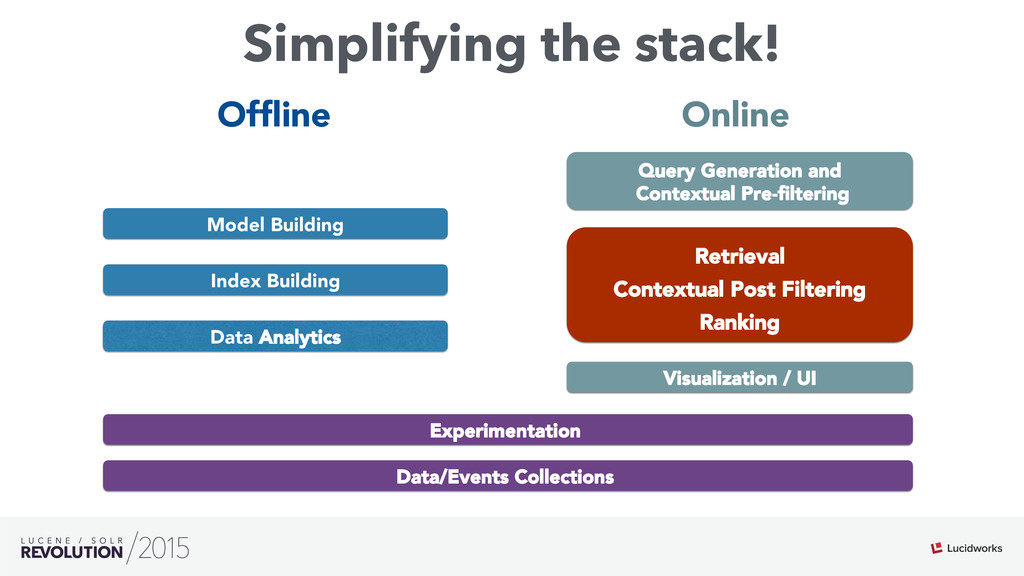
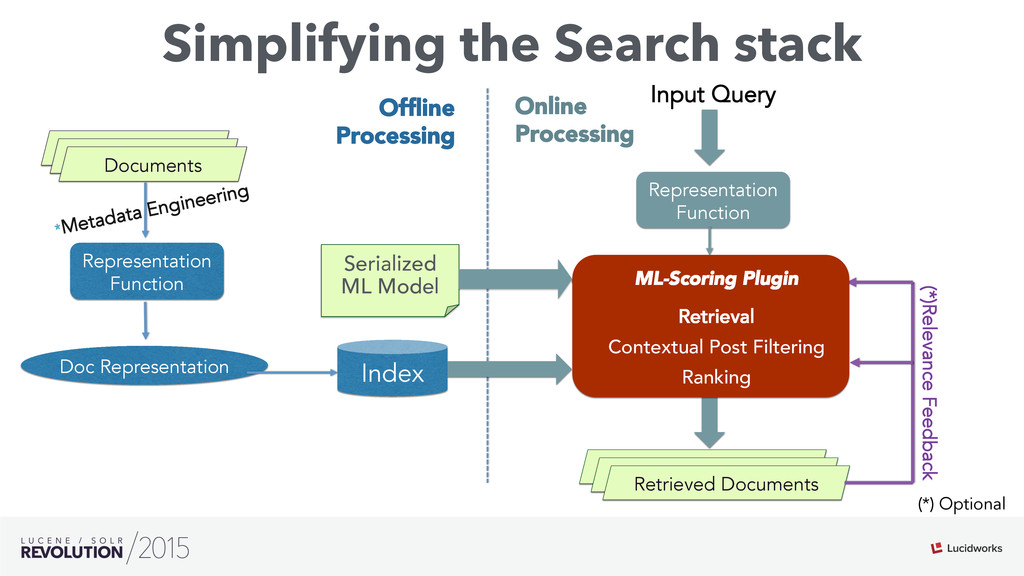
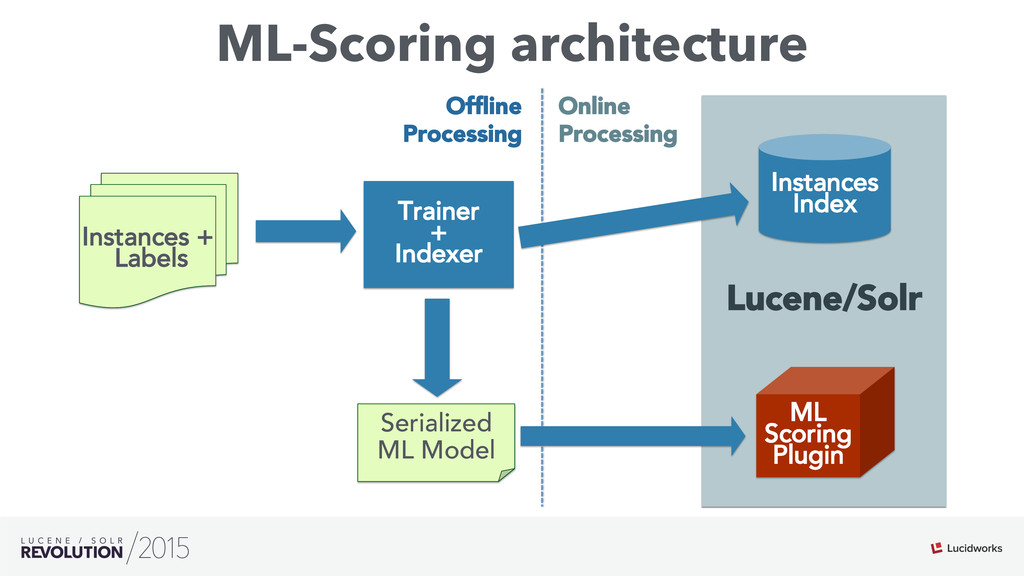
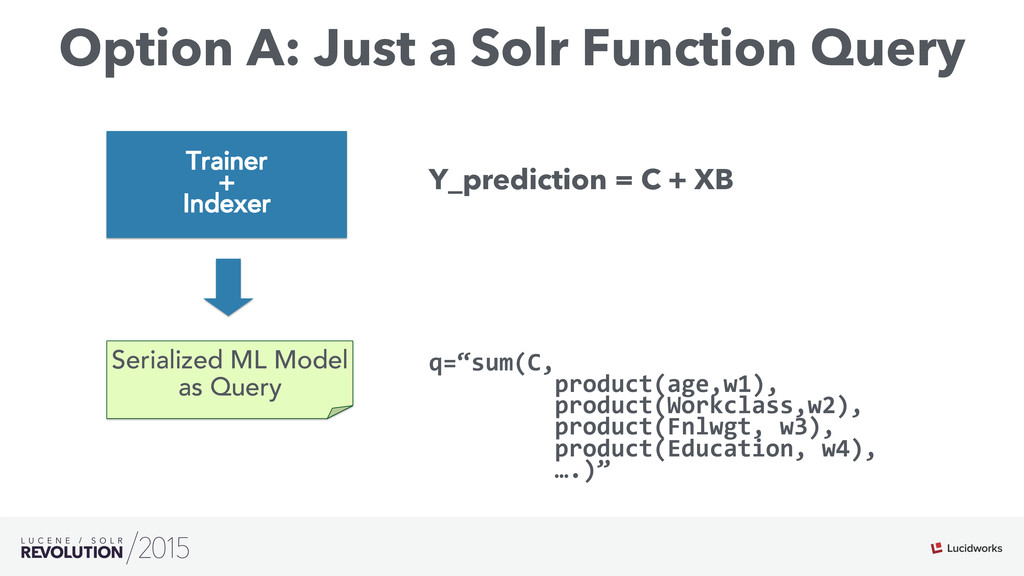
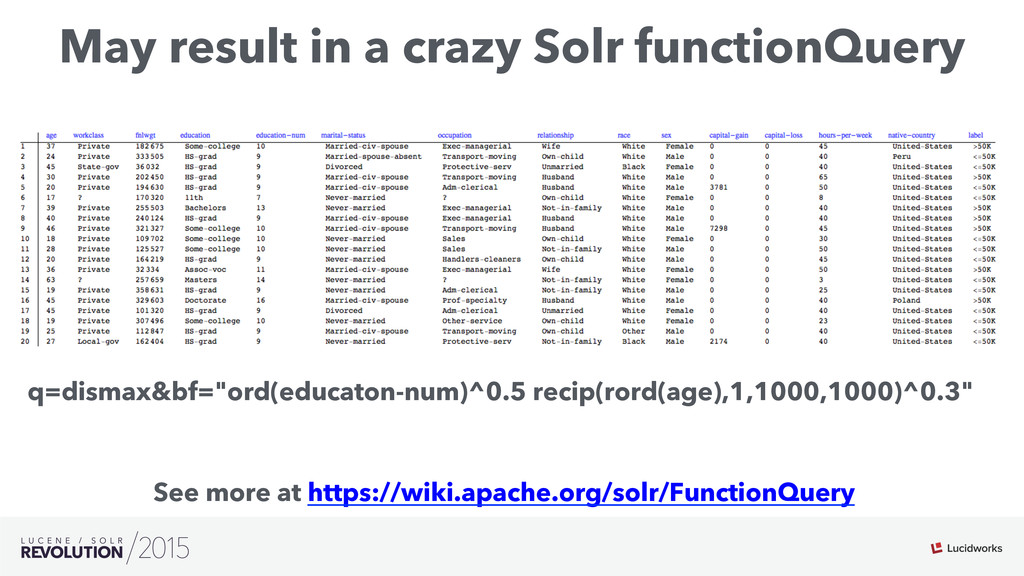
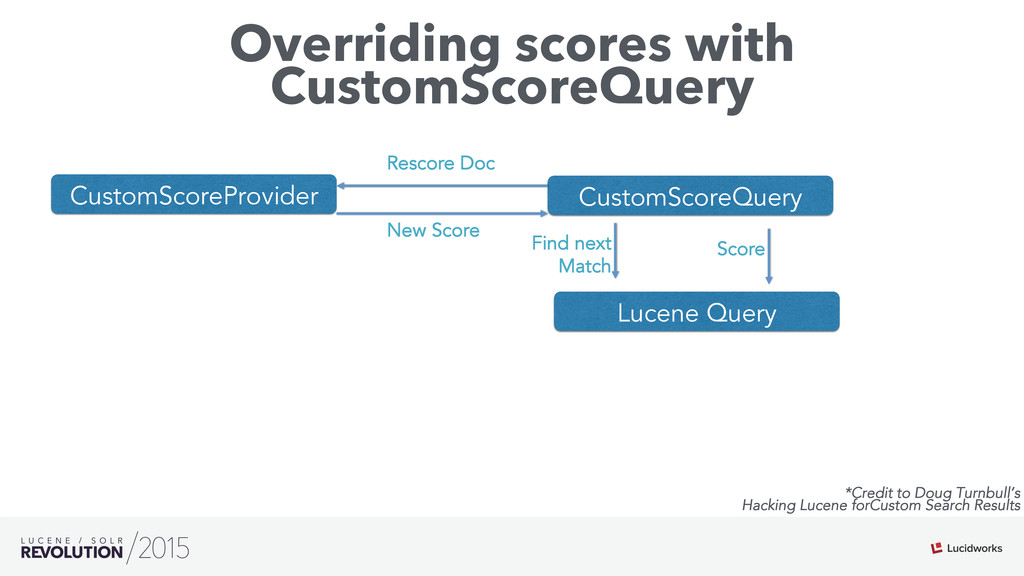
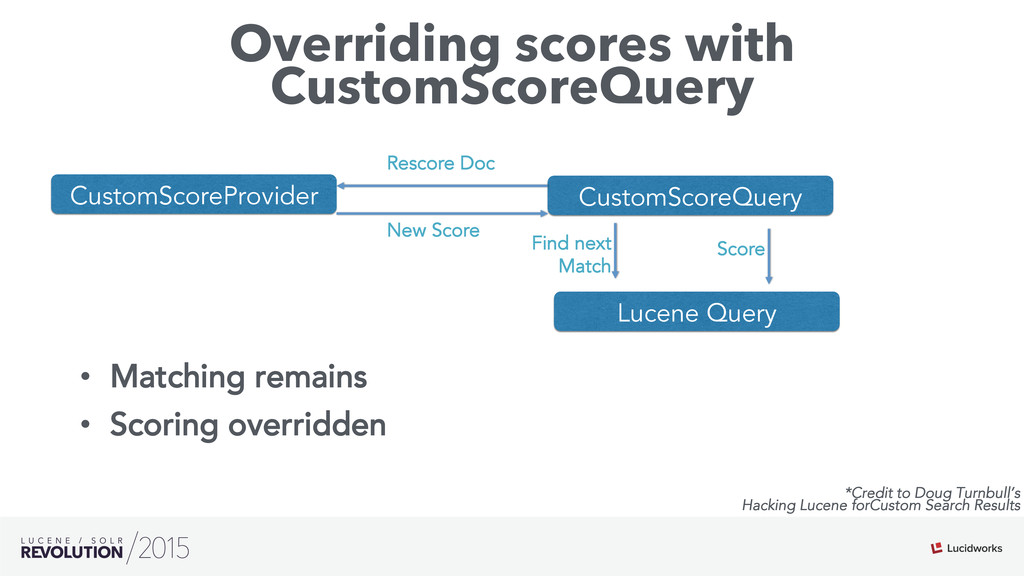
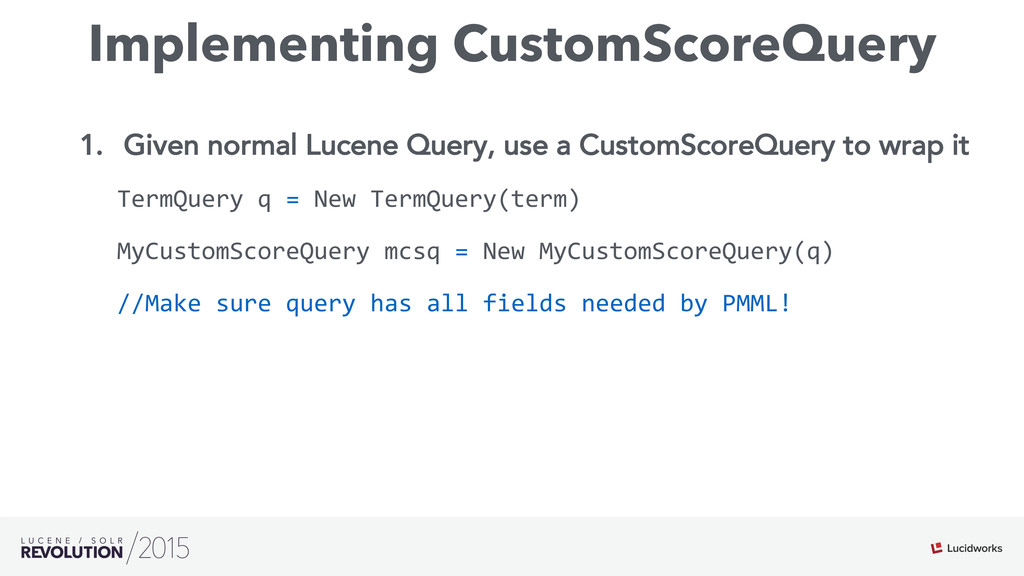
Search engines have focused on solving the document retrieval problem, so their scoring functions do not handle naturally non-traditional IR data types, such as numerical or categorical. Therefore, on domains beyond traditional search, scores representing strengths of associations or matches may vary widely. As such, the original model doesn’t suffice, so relevance ranking is performed as a two-phase approach with 1) regular search 2) external model to re-rank the filtered items. Metrics such as click-through and conversion rates are associated with the users’ response to items served. The predicted selection rates that arise in real-time can be critical for optimal matching. For example, in recommender systems, predicted performance of a recommended item in a given context, also called response prediction, is often used in determining a set of recommendations to serve in relation to a given serving opportunity. Similar techniques are used in the advertising domain. To address this issue the authors have created ML-Scoring, an open source framework that tightly integrates machine learning models into a popular search engine (SOLR/Elasticsearch), replacing the default IR-based ranking function. A custom model is trained through either Weka or Spark and it is loaded as a plugin used at query time to compute custom scores.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![We are Hiring! Contact me at [email protected] @sdianahu Q&A](https://files.speakerdeck.com/presentations/e82103ab72ef4de280b0b96ce4e66ef5/slide_48.jpg){kind=link}
{kind=link}
{kind=link}