Share
Talk given at PyCon APAC 2013 on Cassandra drivers for Python with a focus on cassandra-driver.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
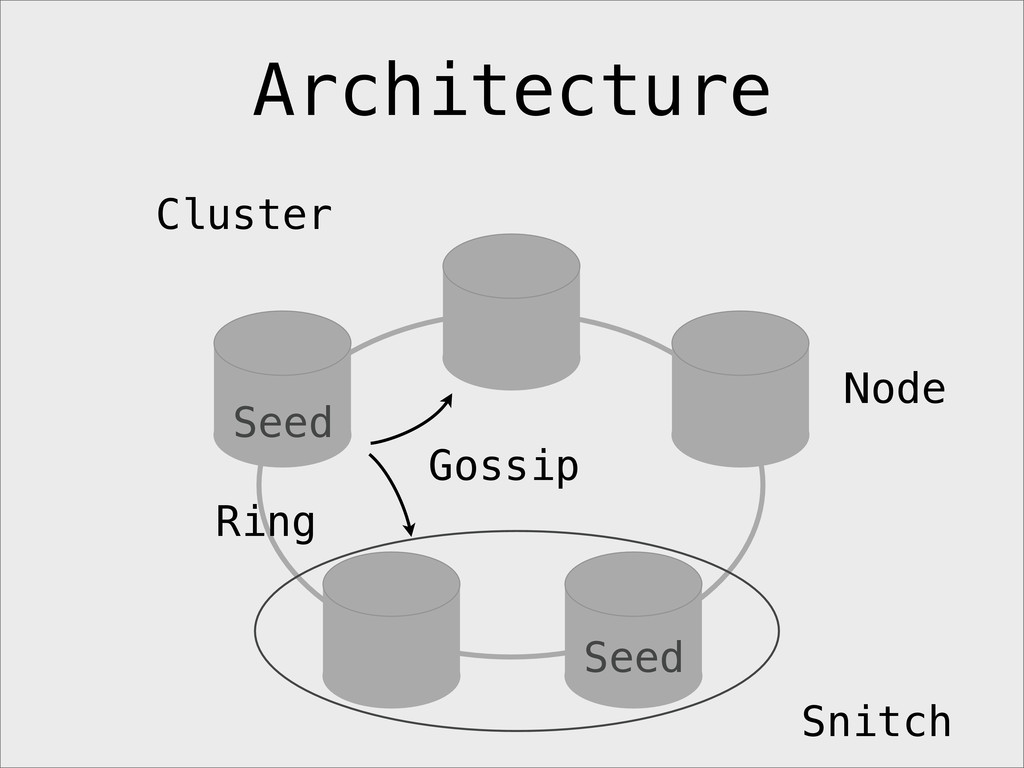{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Decoder session.execute("SELECT * FROM users") # [Row(username=u'seb', birth_year=1984, gender=u'M', session_token=None)]](https://files.speakerdeck.com/presentations/24fc5680ff380130bc714e1c8beefb1f/slide_21.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}